tylerjohnston's Shortform
Jul 4, 20242
AFAICT, now that ASL-3 has been implemented, the upcoming AI R&D threshold, AI R&D-4, would not mandate any further security or deployment protections. It only requires ASL-3. However, it would require an affirmative safety case concerning misalignment.
I assume this is what you meant by "further protections" but I just wanted to point this fact out for others, because I do think one might read this comment and expect AI R&D 4 to require ASL-4. It doesn't.
I am quite worried about misuse when we hit AI R&D 4 (perhaps even moreso than I'm worried about misalignment) — and if I understand the policy correctly, there are no further protections against misuse mandated at this point.
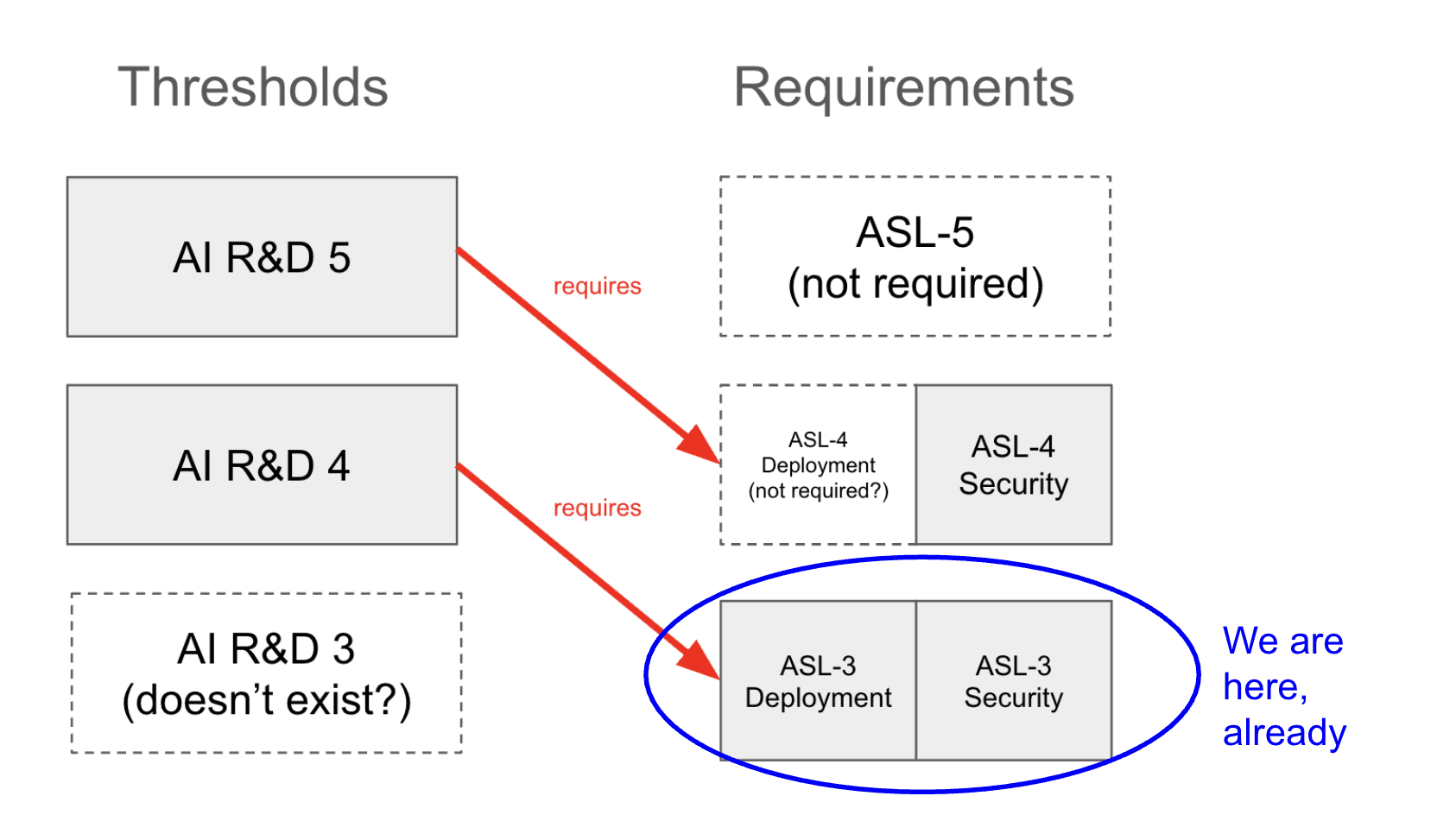
FYI, I was (and remain to this day) confused by AI R&D 4 being called an "ASL-4" threshold. AFAICT as an outsider, ASL-4 refers to a set of deployment and security standards that are now triggered by dangerous capability thresholds, and confusingly, AI R&D 4 corresponds to the ASL-3 standard.
AI R&D 5, on the other hand, corresponds to ASL-4, but only on the security side (nothing is said about the deployment side, which matters quite a bit given that Anthropic includes internal deployment here and AI R&D 5 will be very tempting to deploy internally)
I'm also confused because the content of both AI R&D 4 and AI R&D 5 is seemingly identical... (read more)
It's the first official day of the AI Safety Action Summit, and thus it's also the day that the Seoul Commitments (made by sixteen companies last year to adopt an RSP/safety framework) have come due.
I've made a tracker/report card for each of these policies at www.seoul-tracker.org.
I'll plan to keep this updated for the foreseeable future as policies get released/modified. Don't take the grades too seriously — think of it as one opinionated take on the quality of the commitments as written, and in cases where there is evidence, implemented. Do feel free to share feedback if anything you see surprises you, or if you think the report card misses something important.
My personal... (read more)
Two more disclaimers from both policies that worry me:
Meta writes:
Security Mitigations - Access is strictly limited to a small number of experts, alongside security protections to prevent hacking or exfiltration insofar as is technically feasible and commercially practicable.
"Commercially practicable" is so load-bearing here. With a disclaimer like this, why not publicly commit to writing million-dollar checks to anyone who asks for one? It basically means "We'll do this if it's in our interest, and we won't if it's not." Which is like, duh. That's the decision procedure for everything you do.
I do think the public intention setting is good, and it might support the codification of these standards, but it does not... (read more)
I recently created a simple workflow to allow people to write to the Attorneys General of California and Delaware to share thoughts + encourage scrutiny of the upcoming OpenAI nonprofit conversion attempt.
I think this might be a high-leverage opportunity for outreach. Both AG offices have already begun investigations, and Attorneys General are elected officials who are primarily tasked with protecting the public interest, so they should care what the public thinks and prioritizes. Unlike e.g. congresspeople, I don't AGs often receive grassroots outreach (I found ~0 examples of this in the past), and an influx of polite and thoughtful letters may have some influence — especially from CA and DE residents, although... (read more)
OpenAI has finally updated the "o1 system card" webpage to include evaluation results from the o1 model (or, um, a "near final checkpoint" of the model). Kudos to Zvi for first writing about this problem.
They've also made a handful of changes to the system card PDF, including an explicit acknowledgment of the fact that they did red teaming on a different version of the model from the one that released (text below). They don't mention o1 pro, except to say "The content of this card will be on the two checkpoints outlined in Section 3 and not on the December 17th updated model or any potential future model updates to o1."
Practically speaking,... (read more)
What should I read if I want to really understand (in an ITT-passing way) how the CCP makes and justifies its decisions around censorship and civil liberties?
I agree with your odds, or perhaps mine are a bit higher (99.5%?). But if there were foul play, I'd sooner point the finger at national security establishment than OpenAI. As far as I know, intelligence agencies committing murder is much more common than companies doing so. And OpenAI's progress is seen as critically important to both.
Lucas gives GPT-o1 the homework for Harvard’s Math 55, it gets a 90%
The linked tweet makes it look like Lucas also had an LLM doing the grading... taking this with a grain of salt!
A (somewhat minor) example of hypocrisy from OpenAI that I find frustrating.
For context: I run an automated system that checks for quiet/unannounced updates to AI companies' public web content including safety policies, model documentation, acceptable use policies, etc. I also share some findings from this on Twitter.
Part of why I think this is useful is that OpenAI in particular has repeatedly made web changes of this nature without announcing or acknowledging it (e.g. 1, 2, 3, 4, 5, 6). I'm worried that they may continue to make substantive changes to other documents, e.g. their preparedness framework, while hoping it won't attract attention (even just a few words, like if they one day... (read more)
Magic.dev has released an initial evaluation + scaling policy.
It's a bit sparse on details, but it's also essentially a pre-commitment to implement a full RSP once they reach a critical threshold (50% on LiveCodeBench or, alternatively, a "set of private benchmarks" that they use internally).
I think this is a good step forward, and more small labs making high-risk systems like coding agents should have risk evaluation policies in place.
Also wanted to signal boost that my org, The Midas Project, is running a public awareness campaign against Cognition (another startup making coding agents) asking for a policy along these lines. Please sign the petition if you think this is useful!
On the website, it's the link titled "redline" (it's only available for the most recent version).
I've made these for past versions but they aren't online at the moment, can provide on request though.