The big news this week was that OpenAI is not training GPT-5, and that China’s draft rules look to be crippling restrictions on their ability to develop LLMs. After all that talk of how a pause was impossible and working with China was impossible and all we could do was boldly rush ahead, the biggest American player and biggest foreign rival both decided for their own internal reasons to do something not entirely unlike a pause.
They just went ahead and did it. We kept saying they’d never do it no matter what, and they just… went ahead and did it. At least somewhat.
This is excellent news. I sincerely hope people are updating on the new information, now that they know such things are not only possible but happening.
In terms of capabilities, the week was highly incremental. Lots of new detail, nothing conceptionally surprising or even unexpected.
Table of Contents
- Introduction.
- Table of Contents.
- Language Models Offer Mundane Utility. Subscriptions adding up fast.
- Language Models Don’t Offer Mundane Utility. Some counterexamples.
- I Was Promised Flying Cars But I Will Accept Driverless Cars. Self-driving cars continue to be quietly available in some places. We’re tired of waiting.
- Fun With Image Models and Speech Generation. Two quick links.
- They Took Our Jobs. If your job is ‘exposed to AI’ what does that mean? What might the future hold for you? Also see The Overemployed via ChatGPT.
- Deepfaketown and Botpocalypse Soon. All quiet. Why is this still ‘soon’?
- Grading GPT-4. Gets a B for quantum computing, a % on box planning when the names get obscured. How would the humans do?
- Plug-In And Play. What came out of a weekend plug-in hackathon?
- Prompting GPT-4. A proposed method from John David Pressman.
- Go Go Gadget AutoGPT. Easier to use, still no impressive results.
- Good Use of Polling. American public says AI scarier than asteroids, less scary than climate change or world war. We can now calibrate. Also Americans support an AI pause when asked. The public is no fan of fast AI development.
- The Art of the Jailbreak. You can always count on your dead grandma.
- The Week in Podcasts. Quite a week for podcasts, including one I did. Highlights: Jaan Tallinn, Max Tegmark, Elon Musk (well, on Tucker Carlson), Scott Aaronson, Connor Leahy, Robin Hanson, yours truly.
- In Other AI News. Usual grab bag, including new downloadable models.
- Hype! In this case, 32k context window hype. I am modestly skeptical.
- Words of Wisdom. Nothing Earth-shattering, still wise.
- The Quest For Sane AI Regulation Continues. This includes a bunch of concrete proposals, talk here is growing rapidly more productive, remarkably good.
- The Good Fight. You really want to stop AI models? Lawsuits. Try lawsuits.
- Environmental Regulation Helps Save Environment. Say no to data centers?
- The Quest for AI Safety Funding. EA common application now available.
- People Would Like a Better Explanation of Why People Are Worried That AI Might Kill Everyone. They deserve one. Attempts are ongoing, nothing satisfying. We urgently need to do better, yes people demand contradictory things and are unreasonable and none of that matters, you shut up and you do it anyway.
- Quiet Speculations. Why are medical diagnostic tools continuing to struggle? Can we accelerate exploitation of existing models while slowing new models? Could we move towards using the computer security lens more?
- The Third Non-Chimpanzee. Notice that AIs need not be far more powerful than us to take control of the future, merely more powerful. The future belongs to the most powerful optimizers, the most intelligent things, and we are on the verge of that not being us. That won’t end well for humanity. If you think there is a different default, why?
- People Are Worried AI Might Kill Everyone. Such concern makes the front page of the Financial Times and several others do what they can to explain or spread the word.
- Oh, Elon. He announces ‘TruthGPT’ because if your launching of a rival AI lab on a half-baked concept hopelessly backfires and plausibly dooms the planet, try, try again.
- Other People Are Not Worried AI Might Kill Everyone. They deserve a say.
- OpenAI Is Not Currently Training GPT-5. They are focusing on what else can be done with GPT-4, because that’s where the value lies. One could almost say they are pausing.
- People Are Worried About China. Yet China announced new draft (not final) rules for its LLMs that would, if enforced even a little, constitute huge barriers to development. Yes, the Chinese military might move forward anyway, but there is no way this is not a severe self-imposed handicap. These are the people who will never see reason or agree to slow down?
- Bad AI NotKillEveryoneism Takes Bingo Card. We have thankfully moved away from quoting a bunch of bad takes each week, although the answer card still needs to be assembled. In the meantime, how about a bingo card?
- The Lighter Side. One dog. One fire. Infinite possibilities.
I’m going to suggest reading #29-#30 this time, even if you usually don’t think much about race dynamics or long term worries, as these seem like important notes. Otherwise, the usual applies, mostly start at the top, make sure to check In Other AI News and anything else that seems likely to be useful.
Language Models Offer Mundane Utility
New updated version of perplexity.ai is available.
Website offering resources to have LLMs help scientists with workflows.
Overview of AI performance in strategy games and some talk of how this might translate to its use in an actual war, hits the usual beats. AI is clearly at its best in the micro and tactics, both in games and in the real world, the air force that gives more AI control to its fighter planes is going to have a huge advantage in dogfights. One does not need to solve to know the equilibrium.
You can generate spam messages, except of course it cannot generate inappropriate or offensive content. Which revealed a 59k Twitter account spam network.
While you’re collecting mundane utility, it seems if you go to github.dev instead of github.com you get VS code in a browser? I did not know that so passing along.
Be careful not to subscribe to too much mundane utility, though.
Yi Ding: GPT’s becoming the new cable.
Spending $50/month on subs alone:
ChatGPT Plus $20/month
Midjourney $10/month
Khanmigo $20/month
A few other ones I’d like to try but haven’t paid for yet:
Duolingo GPT: $30/month
http://Type.ai: $30/month
Dart: $20/month (for two people)
Notion: $40/month (for 2 people).
So that adds up to $170/month for OpenAI powered services.
Xfinity’s 185+ channel TV package only costs $60/month. Sorry children!
I do worry about the spread of the subscription-based economic model. It strongly encourages specialization and is terrible for consumer surplus. Pay-as-you-go like you do for OpenAI’s API services actually aligns with the real costs, which seems much better.
Theory that Bing works better if you treat it like it is hypercompetent and can handle anything, which will cause Bing to respond as if it understands, whereas if you act like you expect it not to understand then it will respond as if it doesn’t.
Play a game with Bing called ‘visionary’ to get good image prompts.
Patrick Collison: OH: “I use ChatGPT to compress business books and make them memorable. For example, I told it that a group of inexperienced armadillos are running a cactus nursery, and that the leader just read High Output Management. What happens next?”
Andrew: Apparently this.

Language Models Don’t Offer Mundane Utility
I still say schools have valuable lessons to teach students. Observe.
Justine Moore Tweets:
Teachers: “AI is a disaster, how am I going to know who is cheating?!”
Students:

Rachel Woods reports six more workplaces banning ChatGPT on April 13.
For many businesses, it will increasingly seem crazy either to ban ChatGPT and similar tools, and also to not ban those tools. Choices will have to be made.
Bing gets itself suspended from image generation for content violations.

I Was Promised Flying Cars But I Will Accept Driverless Cars
From IWF’s Patricia Patnode: I Rode in a Driverless Car, This is the Future. I mean, yes, of course it is, the question is how far away is that future. The two most hilarious things in this write-up are the argument for the safety of driverless cars – gesturing at the fact that one might do the math without actually doing that math – and the author’s relatives being terrified of the driverless car, with two of them following behind her in another car, and her mother texting ‘get out now.’ Wow, everyone, if you feel that way about driverless cars, do I have news for you about non-driverless cars.
Still no idea when we’ll get our driverless cars. People keep saying ‘the problem is actually very hard.’ I have no doubt perfect performance is hard, but that only points out the real problem, which I’m strongly guessing is the performance standard.
Fun With Image Models and Speech Generation
Timothy Lee experiments with a (free) AI generated copy of his voice, finds it uncanny.
EFF talks about copyright law and image models. Deep skepticism of legal suits against image models, and also deep skepticism that artists would like it if they won.
They Took Our Jobs
Never stop doubling down, Roon.
Roon: The best thing you can hear is “your job role has high exposure to AI.” This means you’re about to be 3x as productive and paid more.
Warty: um seems kinda untrue like the reddit 3d modeling lady it’s over for her
Roon: everybody has this phase initially before they’ve thought through the possibilities
Everyone becoming three times as productive at the thing you are doing, as I discussed before, can go both ways in terms of pay.
Perhaps there is additional induced demand, everyone captures a portion of the new value and pay goes way up.
Perhaps there is an essentially fixed pool of demand for this particular skill, as some people saw in copyediting, at least in the medium term, and now you are doing something you enjoy less, have less skill advantage at, and are working harder to fight for one of a third as many job slots. Or worse, your job goes away, automated entirely.
I remain an optimist overall about overall employment effects. I am not that level of optimist about the specific jobs where productivity jumps. Some will be fine. Many will not.
Alternatively, Roon could be making a weaker yet still quite interesting claim, which is that if you get with the program and adapt ahead of the curve you will do great when your job gets disrupted. Yes, lots of fools who don’t do this might have to find other work, but you will do great. Highly plausible.
This paper reports on which jobs are most exposed to AIs. The abstract:
This article identifies and characterizes the occupations and populations most exposed to advances in generative AI, and documents how policy interventions may be necessary to help individuals adapt to the new demands of the labor market.
Recent dramatic increases in generative Artificial Intelligence (AI), including language modeling and image generation, has led to many questions about the effect of these technologies on the economy. We use a recently developed methodology to systematically assess which occupations are most exposed to advances in AI language modeling and image generation capabilities.
We then characterize the profile of occupations that are more or less exposed based on characteristics of the occupation, suggesting that highly-educated, highly-paid, white-collar occupations may be most exposed to generative AI, and consider demographic variation in who will be most exposed to advances in generative AI.
The range of occupations exposed to advances in generative AI, the rapidity with its spread, and the variation in which populations will be most exposed to such advances, suggest that government can play an important role in helping people adapt to how generative AI changes work.
This is the general ‘looks like there’s a problem therefore government should step in’ logic one sees everywhere. This could be a really interesting paper or it could be mostly worthless, let me know if you think I should do a deep dive.
Bing summarizes the methodology this way:
According to the paper, the methodology used to classify which jobs are exposed to AI is based on two dimensions: the degree of human-machine interaction and the level of task complexity. The paper uses a framework called “The Human-Machine Work Continuum” to categorize jobs into four types: amplification, augmentation, automation and autonomy. The paper also provides examples of each type of job and discusses the implications for workers and organizations.
This seems like it is more question-begging than question-answering.
From the comments of my previous post this week on jobs, a great illustration of a common confusion.
Jorda: I don’t know that I believe there is such thing as a 10x engineer. Maybe for something like coding, but for most jobs I’ve had that involve additional skills the difference between the best and the average is MAYBE 2x.
Coding is a huge part of my job, I rely heavily on ChatGPT to speed this up, and it does give me a 3x-5x gain in coding speed. However, it doesn’t speed up the other aspects of the job as much so, overall, I’m about 2x what I was prior to ChatGPT.
Thus Jorda is asserting these two things at the same time:
- The difference between Jorda-with-ChatGPT and Jorda-without is 2x.
- The difference between average and best possible engineer is maybe 2x.
This is in theory possible if Jorda was previously a below-average engineer.
In practice, there is an obvious contradiction.
This keeps happening. The same person will confidently assert that:
- The maximum possible future effectiveness of an AI system, at a given task, or of a human working with a potential future AI system, is not much above current typical human effectiveness.
- Either: Existing individual AI capabilities offer large improvements in capabilities, often in ways that we should worry about.
- Or: various non-AI process improvements or new techniques often offer large improvements to performance.
This is the position that anything too far above ‘typical current human using current best practices’ is magical and absurd and impossible unless we have actually seen it in the wild, or you can actually provide lots of detail on every step such that I could actually implement it, in which case fine, typical human performance changed. Or something?
A fun example are the people who think, simultaneously:
- We should worry about deepfakes, or GPT-4-level-AI-generated propaganda.
- Nope, an artificial superintelligence couldn’t fool me, I’m too smart for that.
Deepfaketown and Botpocalypse Soon
Fabiens asks about the issue of deep fakes:
We’ve had a few months now where anyone has been able to use Midjourney and SD to create extremely realistic fake images of anything – yet there is little to no coverage or indication of widespread or sophisticated nefarious use.
Calm before storm or overestimated risk?
Both. The risk was overestimated. Also the risks are rapidly escalating. People haven’t had the time to adjust, to experiment, to build tools and networks and infrastructure. The technology for deepfakes is great compared to where it was a year ago, it’s still nothing compared to a year from now.
Right now, almost all deepfakes can be detected by the human eye, often intuitively without having to actively check. If you actually run robust detail checks, ensure all the shadows and proportions and everything lines up, the tech isn’t there yet. Even if no detail is wrong exactly, there is a kind of vibe to AI artwork versus the vibe of a real thing.
Over time, those flaws will rapidly get harder and harder to detect.
So yes, the problems are coming. I do think they will prove overhyped, as we will still have many defenses, and we will adjust. I also think anyone dismissing such concerns is going to look quite foolish, including in many pictures.
Grading GPT-4
The latest final exam given to GPT-4 was Scott Aaronson’s Quantum Computing final exam from 2019, on which it scored a B, which likely would be modestly improved if it could use a calculation plug-in like WolframAlpha. I can’t say much more about this one because, unlike the economics exams, I don’t know the first thing about the material being tested.
Subbarao Kambhampati tests GPT-4 on block world toy planning tests. It does okay initially, about 30% versus 5% for previous models (100% is very possible if you use GOFAI STRIPS planners, he says). Then when the names of things are obscured and replaced by meaning-bearing other words correctness drops to 3%.
He cites this as ‘oh GPT-4 is mostly pattern matching and pulling examples from its training, nothing to worry about.’ Certainly that is a lot of what it is doing, yet is that not also what we are mostly doing when we work on such problems? Every game designer knows that if you want humans to know what is going on and get the hang of things, and both have a good time and make good decisions, you want your names and labels of everything to make intuitive sense to humans. If you give humans a fully abstract problem, often what they do first is they start giving names to things and set up a concrete metaphor.
Before I take any comfort in GPT-4’s failure here, I’d at least want to see the human performance drop-off from the name changes. I predict it would be large.
Plug-In And Play
Cerebral Valley announces the winners of a GPT-4 plug-in hack-a-thon.
(I did manage to secure GPT-4 API access and am working on learning that, but I still don’t have plug-ins, so I can’t toy around with them, sure would be neat, nudge nudge.)
Anything cool?
The first place winner (and popular vote
) was Edujason, a GPT Plugin which took user input about a topic they wanted to learn and generated a high quality tutorial video.
In my universe this is anti-useful, why would you want to put LLM content into video form like this, it’s strictly worse than text? Many seem to think differently.
The second place winner was infraGPT, a GPT Plugin that automates devops teams. It can to modify code, execute on the server, analyze metrics like CPU, memory, network, etc.
Sounds like a mix of useful things if done well, and things I would not want my plug-in to have permission to do. There’s a video demo, which didn’t help me assess.
The third place winner was AutoPM, a GPT Plugin that integrates into Linear.
They integrated the ChatGPT planning capabilities directly into your project manager tooling.
Hard to tell from where I sit if this is useful.
The second and third prize winners point to the general new hotness, of integrating LLM agents into workflow. Still way too early to know what they can do well, or safely.
Prompting GPT-4
John David Pressman thinks he has found the way.
Hermes is a piece of non-deterministic software that performs informal reasoning steps in collaboration with the user.
Each step is prepended with some syntax to tell the software what it should be/do.
Like so: HERO [Albert Einstein, Op: Objection], That’s not correct. Nothing can travel faster than the speed of light.
Hermes allows the user to call upon any hero in history or myth and use them as a reasoning step. Or have them talk to each other about something. The user can freely mix together their cognition and the simulated cognition of other minds.
New operations and syntax can be created at will and Hermes will do its best to respond to and use them.
The user writes down their own cognition as a series of subagents, like so: USER [A: EMPATHY], I completely agree! It’s wonderful. Like the difference between the true duet of Scarborough Fair and the nonsense one.
USER [A: 343], It’s funny. In order to save the world rationalists finetune the human priors out of themselves, humans are dreamers not maximizers, but the process of gaining agency is the process of becoming a maximizer. Capital is dangerous to us because it instantiates the reason simulacrum as a independent being.
USER [A: EMPIRICISM], So when you manage to make a dreamer instead of a maximizer, you try to beat it into being an agent for you, whip it into sharing the inductive biases you’re worried about consuming you.
USER [A: RATIONAL/343], But we know from our studies of utility that inconsistent beings are exploitable, agency and consistent epistemology exist for adversarial supremacy. What does a dreaming agent look like?
These represent the internal flashes of emotion-reasoning-concepts that pass through the users mind as they think.
The user writes these down and allows Hermes to interact with them. Hermes responds with its own subagents and reasoning steps like so:
HERMES [A: EMPIRICISM], Humans are a dreaming agent, but the theory of how this works is not well studied. They have taken over the world but totally consistent theories of value have only emerged in the 20th century. And even these are threadbare compared to the true complexity of human morality.
HERO [Carl Jung, Op: Observation], There is a fundamental limit to how close man can observe his dreaming agent nature without violent rejection of it. Our understanding of these things has been hampered by social suppression of the unconscious and the unaware.
HERMES [A: MATHEMATICIAN], I have to imagine that the secret lays in the way people are stable in their values over time. They can be locally unbalanced for a time, or on certain dimensions, but if you tried to actually dutch book a person they would catch on after the 1st or 2nd time you showed the contradiction in their values. People have a kind of meta-healing that lets them retain their values while still dealing with the long tail of world-lore that allows them to actually function in the world.
You will act as the Hermes software for me starting from the following prompt:
Then an example is given.
USER [A: RATIONAL], How can you verify that a deep learning system generalizes in the right ways (e.g. precluding mesaoptimization) when it’s extremely difficult to audit its low level cognition due to a continuous connectionist architecture?
I have never been impressed by the conversations I have seen using variants of this technique, but I also have not tried it out myself, and keep not finding reasons to get curious about this kind of reasoning in a practical way.
If you want characters and unexpected decisions, here’s an interesting version of thinking step by step.
“I am an assistant” RLHF is no match for feelings-based chain of thought prompting “I absolutely would kill a child for 10$, in fact I would do it for even less”


Go Go Gadget AutoGPT
How to quickly set up AutoGPT on your phone.
Or use a web interface (I did not verify them): Cognosys.ai, AiAgent.app, Godmode.space.
AutoGPT just exceeded PyTorch itself in GitHub stars (74k vs 65k). I see AutoGPT as a fun experiment, as the authors point out too. But nothing more. Prototypes are not meant to be production-ready. Don’t let media fool you – most of the “cool demos” are heavily cherry-picked.
In my experiments, AutoGPT can solve certain simple & well-defined knowledge tasks well, but is unreliable *most of the time* for harder tasks that are truly useful. I also worry a lot whenever I give it python execution and disk access.
It’s a *terrible* idea to have it on autopilot (as the authors warned too). You should be very wary of any product that claims to use AutoGPT with code execution.
Much of the unreliability can be attributed to GPT-4’s inherent limitations. I don’t think these can be fundamentally addressed by fancier prompting tricks, without having access to GPT-4’s weights and finetuning more.
I do want to applaud @SigGravitas for putting together many great ideas (e.g. ReAct, Reflexion, memory, self-cloning) into a very neat repo that people can easily experiment with. @SigGravitas has tried the best to overcome GPT-4’s limitations.
But just like no amount of prompting could turn GPT-3 into GPT-4’s capability, I don’t think AutoGPT + a frozen GPT-4 can magically and reliably solve complex decision making that matters. The current media hype is pushing the project to completely unrealistic expectations.
Jon Stokes tries to get AutoGPT to write a post about AutoGPT in the style of Jon Stokes. It did not, in my judgment, even match what you can do with normal GPT-4 here.
So, what has AutoGPT done since last time?
I do notice that ‘install a software package someone linked to on Stack Overflow that my LLM found while doing a subtask’ is not the most secure way to run one’s operation.
Here’s a thread on what’s happened with ‘BabyGPT.’ A lot of ‘use this with a different interface,’ not as much ‘here is something it actually accomplished.’
It is still early. The key claim of Fan’s is that the problems of AutoGPT are inherent to GPT-4 and cannot be fixed with further wrapping. If we are getting close to the maximum amount we can get out of creating a framework and using reflection and memory and other tricks, then that seems rather fast. We are only doing some quite basic first things here. Perhaps the core engine simply is not up to the task, yet there are definitely things I would try well before I gave up on it.
Simon Willison discusses details of prompt injection attacks, and why this will go badly for you if you start hooking up LLM-based systems with permissions and automatic loops. I am planning very much on sticking to safer systems.
Good Use of Polling
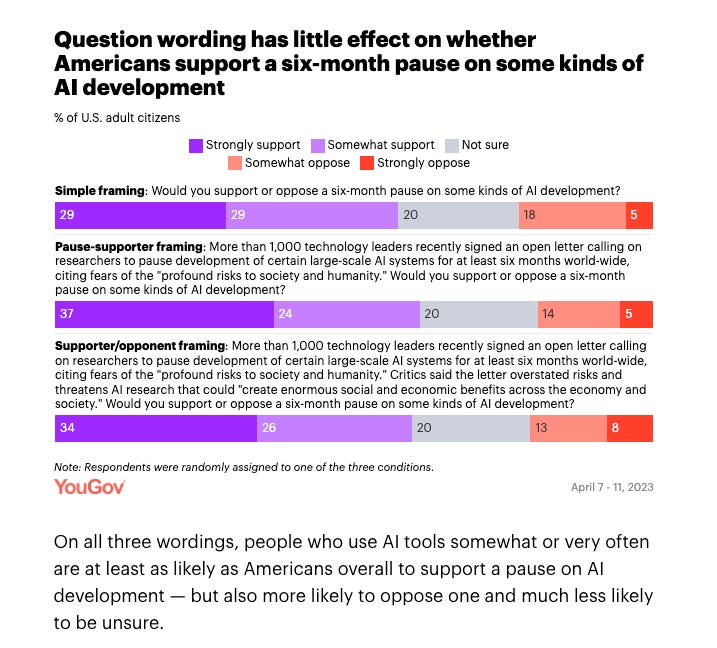
The question of how worried Americans are about AI has been placed in proper context.

This is a double upgrade. We get the extra category ‘this is impossible’ and also we get to compare AI to several other potential threats. People are more worried about AI than they are about asteroid impacts or alien invasions, less than they worry about climate change, pandemics or an outright act of God. Quite reasonably, nuclear weapons and the related world war are the largest concern of all.
One way to think about this is that AI is currently at 46% concerned, versus 39% for asteroid impact and 62% for climate change, where asteroid impact is ‘we all agree this is possible but we shouldn’t make real sacrifices for this’ and climate change is ‘we treat this as an existential threat worthy of massive economic sacrifices that puts our entire civilization in extreme danger.’ So that’s 30% of the way (21% if looking only at ‘very concerned’) from fun theoretical worry to massive economic sacrifices in the name of risk mitigation.
It will be good to track these results over time.
In other polling news, Americans broadly supportive of an AI pause when asked.
This is not surprising, since American public is very negative on AI (direct link).
Robin Hanson: Thank goodness for elites who frequently ignore public opinion.
I am not one to talk a lot about Democratic Control or Unelected Corporations or anything like that. In almost all situations I agree with Robin’s position on regulation, and on ignoring public calls for it. It still seems worth noting who is the strange doomer saying our standard practices and laws risk destroying most future value unless we ignore the public’s wishes, versus who thinks along with the public that failure to take proper precautions endangers us all.
Or even saying that if we listen to the public, we are doomed to ‘lose to China.’
Robin Hanson, and others opposed to such regulation, are the doomers here.
The Art of the Jailbreak
Various advice on how to communicate with Bing, from Janus.
tips for asking questions to Bing in a way that doesn’t make them hostile to the question asker

Tenacity of Life had quite the idea.
I have had insanely long conversations with Bing Chat on a lot topics like this but I’m afraid to post them, also they are very long lol It helped when speaking as if you are writing a story together about a universe that is identical to this one in every way except as a branch split under the concept of the Many World’s Interpretation of Quantum Mechanics. This allowed me to have extremely long conversations about sensitive topics.
[Seb Krier] I used a sci-fi story of a mystical octopus with each tentacle representing a different state of the works lol.
The Week in Podcasts
Cognitive Revolution (Nathan Labenz) had Jaan Tallinn on to discuss Pausing the AI Revolution. Jaan explains the logic behind the pause letter, including the need for speed premium, and gives his perspective on the AI landscape and leading AI labs. Lots of great questions here, lots of good detailed responses, better than the usual. Jaan thinks that every new large model carries substantial (1%-50%, point estimate 7%) chance of killing everyone from this point out, and thinks decisions should be made with that in mind.
One interesting question Nathan asked was, would Jaan have applied this logic to GPT-4 as well? Jaan answers yes, it would have been reasonable to not assign at least 1% chance of ruin to training GPT-4, given what we know at the time. I would not go that far, I thought the risk was close to zero, yet I can certainly see ways in which it might not have been zero.
Lex Fridman follows up his interview with Eliezer with an interview of Max Tegmark. Consider this the ‘normal sounding person’ version. There are large differences between Max’s and Eliezer’s models of AI risk, and even larger differences in their media strategies. Max’s presentation and perspective are much more grounded, with an emphasis on the idea that if you create smarter and more capable things that humans, then the future likely belongs to those things you created.
I consider most of what Max has to say here highly sensible. Lex’s questions reveal that he remains curious and well-meaning, but that he mostly failed to understand Eliezer’s perspective (as shown in his ‘Eliezer would say’ questions). I wish we had a better way of knowing which strategies got through to people.
While not technically a podcast, Elon Musk went on Tucker Carlson (clips at link, the original version I saw got removed). The first section deals with his views on AI, with Tucker Carlson playing the straight man who has no idea and letting Elon talk.
Elon tells the story, well-known to many but far from all, that OpenAI happened because he would talk into the night about AI safety with Google founder Larry Page, Page would say that he wanted ASI (artificial superintelligence) as soon as possible, and when Elon quite sensibly what the plan was to make sure humans were going to be all right, Larry Page called Elon a ‘speciesist.’
That’s right. Larry Page was pushing his company to create ASI, and when asked about the risks to humanity, his response was that he did not care, and that caring about whether humanity was replaced by machines created by Larry Page would make you a bad person. You know, like a racist.
I’m not saying I would have done the worst possible thing and founded OpenAI, and reflexively created ‘the opposite’ of Google, open source because Google was closed.
But I understand.
What I don’t understand is his new plan for TruthGPT, on the thought that ‘an AI focused on truth would not wipe us out because we would be an interesting part of the universe.’ I suppose those are words forming a grammatical English sentence? They do not lead me to think Elon Musk has thought through this scenario? Human flourishing is not going to be the ‘most interesting’ possible arrangement of atoms in the solar system, galaxy or universe from the perspective of a future AI or AIs.
Of all the things to aim for in the name of humanity this is a rather foolish one. If anything it is more promising from the Page perspective, in the hopes that it might make the AI inherently valuable once we’re gone. Tucker then says we don’t wipe out chimpanzees because we have souls, so yes Elon is making some sense I guess if that is the standard.
Connor Leahy on AGI and Cognitive Emulation. Haven’t had a chance to listen to this one yet.
Oh look who else was on a podcast this week. Yep, it me. Would be great to show the podcast some love. I felt it was a good discussion. However, if you’ve been reading my posts, then you are not going to find any new content here. I welcome any tips on how to improve my performance in the future.
Occasionally people tell me I should have a podcast. I am highly unconvinced of this, but I reliably enjoy being on other people’s podcasts, so don’t hesitate to reach out.
Sometime in the future: A 6-minute Eliezer TED talk that got a standing ovation, given on less than 4 days notice. Could be a while before we see it.
A lot of people at TED expressed shock that I’d been able to give a TED talk on less than 4 days’ notice. It’s actually worse; due to prior commitments and schedule mishaps, I only wrote my talk the day before.
Which I trusted myself to do, and to commit to TED to doing, because I knew this Secret of Writing: “There is no such thing as writer’s block, only holding yourself to too high a standard.” You can *always* put words down on a page, if you’re willing to accept a sufficiently awful first draft.
I knew I could definitely write six minutes of text, even if it might not be as good as I wanted. When time got short, I lowered my ambitions and kept going.
But man, I would not have wanted to try that fifteen years earlier.
Yes, many people did ask if I used GPT (no), and I always replied that GPT was nowhere near being able to do *that* and if it was I would be worried.
I guess I should have predicted faster that there’d be an Internet crowd that doesn’t comprehend that writing standards exist, or that TED is higher standards and higher stakes than usual, or that this would be a literal nightmare for a lot of people.
But yeah, all the TED green badges (ops/staff) were like “oh my god thank you for agreeing to do this on such short notice” even *before* I gave the actual talk without bombing it, because like no you would not usually ask a speaker to *try* to do that.
Scott Aaronson goes on AXRP. Going to put my notes here on the transcript.
He restates his endorsement of the incremental approach to alignment, working on problems where there is data and there are concrete questions to be solved, and hoping that leads somewhere useful – rather than asking what problems actually matter, start somewhere and see what happens. He expects gradual improvements in things like deceit rather than step changes, and agrees this is a crux – if we did expect a step change, Scott would feel pretty doomed. Scott endorses the ‘we can’t slow down because China and Facebook’ rhetoric.
He says, as Robin Hanson highlighted, that he thinks the first time we see an AI really deceive someone, that the whole conversation about will change. I am definitely on the other side of that prediction. I have heard this story several times too many, that some event will definitely be a wake-up call or fire alarm, that people will see the danger. This time, I expect everyone to shrug, I mean phishing emails exist, right? Scott clearly sees deception as a key question in what to worry about, in ways where it seems safe to say that ‘evidence that Scott says would convince him to worry will inevitably be given to Scott in the future.’
Why does everyone doubt that AI will become able to manipulate humans? What, like it’s hard?
Scott seems to put a lot of hope in ‘well if we can extrapolate deception ability over time then we can figure out when we should stop and stop.’ I seriously urge him to think this through and ask if that sounds like the way humans work, or would act, in such situations, even if we had a relatively clear danger line which we probably don’t get – even if deception increases steadily who knows if that leads to an effectiveness step function, and even if it doesn’t, what deception level is ‘dangerous’ and what isn’t? Especially with the not-quite-dangerous AIs giving the arguments about why not to worry. And that’s, as Scott notes, assuming there isn’t any deception regarding ability to deceive, and so on.
There’s a bunch of talk about probabilistic watermarking. Scott seems far more hopeful than anyone else I’ve read on that subject. I notice I expect all the suggested methods here not to work so well against an intelligent adversary, but there is hope they could beat a non-intelligent adversary that is blindly copying output or otherwise not taking steps to evade you.
Which is oddly consistent with Scott’s other approaches – trying to find ways to defeat a stationary or unintelligent foe, that reliably wouldn’t work otherwise, because you got to start somewhere.
In Other AI News
Good competing news summaries are available from Jack Clark at ImportAI, link goes to latest. As you’d expect, mostly covers similar stories to the ones I cover, although in a very different style. This week’s post talked about several things including the paper Emergent autonomous scientific research capabilities of large language models (arXiv), where scientists created a researching agent that scared them.
Announcing Amazon Bedrock. Amazon plans to make a variety of foundational models (LLMs) available through AWS. This will be a one-stop shop to get the compute you need in efficient form, and they plan to offer bespoke fine tuning off even a small handful of examples, with the goal being that customers will mostly be creating custom models.
Amazon is also making coding aid Amazon CodeWhisperer freely available.
Kevin Fisher announces he is putting together the Cybernetic Symbioscene Grant program for funding ambitious tools for human cognition x LLMs, says to DM him if you want to help.
Sadly, we’re falling into two camps: AGI “let’s automate all the jobs” and AI doom “it will kill us all”
There’s room for a third: Cybernetic Symbiosis or “man + machine together” – theorized originally in 1960 by Licklider, predicting a future where machines lived harmoniously with humans to accelerate our own progress as a species.
Does it help if I’m in both the first and second camps? I have nothing against the third as written either, and I don’t see any contradictions anywhere. The problem is that I have no idea what this combination of words intends to mean in practice, or how this constitutes a plan. I’m not against it or for it, instead I notice I am confused.
The Responsible AI Index is here to tell you that, statistically speaking, very few companies are being responsible with regard to AI, complete with report.
Scale AI releases AI corporate readiness report (direct link). In 2022, they say 65% of companies created or accelerated their AI strategy, running a broad gamut of industries. 64% of companies used OpenAI models, 26% AI21labs, 26% cohere.
A paper discussing how best to structure your ‘AI Ethics Board.’ If you’re calling it that, I am already skeptical. They suggest an 11-20 person board, which I’d say is clearly too big for almost any board.
Demis Hassabis talks to 60 Minutes (video). Puff piece.
Tammy announces Orthogonal: A new agent foundations alignment organization. I continue to be sad there hasn’t been more efforts going into agent foundations, even if it seems far less hopeful than we previously thought. We don’t exactly have great alternatives.
StabilityAI releases new open source language model, 3B and 7B parameter versions. 15B and 65B versions coming later.
Databricks offers us Dolly 2.0 (announcement, GitHub), a 12B parameter LLM tuned for specific capabilities: Open Q&A, Closed Q&A, extracting information from Wikipedia, summarizing information from Wikipedia, brainstorming, classification and creative writing.
Replit’s Reza Shabani talks about how to train LLMs using Databricks, Hugging Face and MosaicML.
Hype!
A new occasional section, inspired by the speed-running community. Hype hype!
McKay Wrigley: Widespread GPT-4-32k access will be a bigger leap than GPT-3.5 to GPT-4 was. The 4x larger context window combined with the power of GPT-4 will be absolutely insane. People will be completely blown away by the complexity of workflows and use-cases that it will unlock.
32k tokens is ~40 pages. A *lot* of text (and code!) can fit in that window. That’s a ton of information you’ll be able to feed GPT-4 at once.
I am very excited to get my hands on the 32k token context window, because I write posts more than 8k (and sometimes more than 32k) tokens long. There’s a lot of other great use cases out there for this, too.
This still seems like Bad Use of Hype. Yes, the leap enables some new use cases, but for 95%+ of all use cases it’s not worth the extra cost – remember that you have to pay for the full context window, including your inputs.
In time it will be worth it more often to go large, as people come up with bespoke detailed prompts and want to include lots more info, but most of the mundane utility I expect to stay the same.
Words of Wisdom
Janus: People chronically underestimate how weird reality can be. Most screen off anything weird-looking until it’s blaring in their face (or their peers have acknowledged it). This also leads to crippled agency because they cannot entertain plans that pass through idiosyncratic worlds.
(He quotes Bowser from February 18, who said “I love sydney as much as anyone but I straight up refuse to believe OpenAI blew their gpt4 load by hooking it up to Bing.”)
Janus: The real world is generated with temperature 1. But most people’s imaginations work on effectively lower temperatures, probably in part due to RLHF from society, in part due to compute-saving heuristics. This is related to EY’s mechanistic explanation of the Planning Fallacy.
From EY: If you ask someone what they expect in the normal case, they visualize what looks like the line of maximum probability at each step of the way – everything going according to plan, with no surprises.
This is one of many problems when trying to tell stories about possible futures. Either your tale includes lots of people being dumb in kind of random ways and a lot of random or weird or dumb things happening, or your scenario is highly unrealistic and your predictions are terrible. But if you tell a story with such moves, people point to those moves as unrealistic and stupid and weird.
Roon reminds us that as much as he’s all acceleration talk, at core he agrees on the problem structure.
Sid Meier made the star colonizing rocket the technological victory condition but in reality it’s very clearly the aligned AGI.
The work we do now has the potential to be literally the most important work ever done or that ever will be done. It’s hubris to admit it but it’s maybe more hubris to ignore it.
I am always fascinated by this type of hedging. What’s the ‘maybe’ doing in that sentence? Why draw the line here?
It also raises the question, if that is indeed the most important work that will ever be done, why would one want to allow as little time as possible to get it done?
The Quest For Sane AI Regulation Continues
Regulation of AI is a strange beast.
The normal result of regulations is to slow down progress, prevent innovation, protect insiders at the expense of outsiders and generally make things worse. Usually, that’s terrible. In AI, it is not so obvious, given that the default outcome of progress and innovation is everyone dies and all value is lost.
Thus, calls to make ‘good’ regulatory decisions with regard to short term concerns are effectively calls for accelerationism and taking existential risks, whereas otherwise ‘bad’ regulatory decisions often hold out hope. Of course, we should as usual expect many of the worst possible regulatory decisions, those that destroy short-term utility without providing much help against longer term dangers.
In that vein the EU has, as per usual, decided to do exactly the opposite of what is useful. Rather than attempt to regulate AI in any way that might prevent us all from dying, they instead are regulating it at the application layer.
Thus, if you don’t want your AI to be regulated, that’s easy, all you have to do is make it general purpose, and you’ll be excluded from the EU’s AI act and can do anything you want because it’s general purpose. AI Now seems to have noticed this, and is saying that perhaps general AIs should not be excluded from regulations and able to abdicate all responsibilities using a standard disclaimer.
Over here in America, Chuck Schumer is proposing focusing on four guardrails.
- Identification of who trained the algorithm and who its intended audience is.
- The disclosure of its data source.
- An explanation for how it arrives at its responses.
- Transparent and strong ethical boundaries.
That won’t help with the existential risks, but as regulations go this seems highly reasonable and plausibly could be a good starting place.
Ezra Klein continues to bring sanity to the New York Times.
Another great piece on AI by Ezra Klein. He suggests that AI policies should address the following categories:
1. Interpretability
2. Security
3. Evaluations and audits
4. Liability
5. De-emphasizing humanness
All of this seems wise and reasonable.
Jason Crawford suggests we should clearly define liability for AI-inflicted harms.
Something the government can and should do now about AI safety: Define/clarify liability for AI-inflicted harms.
If a client is harmed by a service provider, who was guided by an AI-based product, which was built using OpenAI’s API—who is liable? OpenAI, the product developer, the service provider?
Putting liability in the right place gives a direct financial incentive for safety.
This was the lesson of late 19th / early 20th century factory safety:
One specific lesson from that history:
It’s better if liability rests with whoever can address the *root causes* of risks, and if it rests with larger organizations that have the resources to invest in safety engineering, as opposed to with small businesses or individuals.
Another lesson from the history of factory safety is that individuals need a sure, swift way to get reparations, and companies shouldn’t be able to easily evade liability through the courts. That sets up the wrong incentives: “avoid liability” vs. “prevent harms”
This can be done through a no-fault system, like the worker’s comp systems that were set up in that time period. Rather than trying to determine whether the worker was negligent, the company simply always paid for accidents, on a fixed schedule.
Going further, you might even require liability insurance—which forces companies to confront the risk of harms *now*, rather than only after the harms happen.
(Not sure how well that would work now for an area where the harms are so little understood, though.)
I tend to think that liability law works better than a regulatory approval/oversight approach:
• Specifies the “what” and leaves the “how” up to the practitioners—especially important in a young, rapidly improving industry
• Balances incentives between progress & caution
This too seems like something that would be sensible when dealing with ordinary small-scale AI harms, and would do absolutely zero good when dealing with existential risks.
If you need to buy liability insurance for any harms done by your AI, who is able to sell you liability insurance in case an existential catastrophe? By definition, neither Warren Buffet nor Lloyds of London nor the US Government can pay.
So either this becomes ‘AI that poses an existential threat is rightfully illegal’ or ‘We have good financial incentives to care about small AI harms, and no incentive to care about larger AI harms’ and we amplify the biggest moral hazard problem in history, making it even worse than the one that exists by default.
Luke Muehlhauser at Open Philanthropy offers 12 tentative ideas for US AI policy, aimed at increasing the likelihood of good outcomes from future transformative AI. After a bunch of caveats, he lists them as:
- Software export controls.
- Require hardware security features on cutting-edge chips.
- Track stocks and flows of cutting-edge chips, and license big clusters.
- Track and require a license to develop frontier AI models.
- Information security requirements.
- Testing and evaluation requirements.
- Fund specific genres of alignment, interpretability, and model evaluation R&D.
- Fund defensive information security R&D.
- Create a narrow antitrust safe harbor for AI safety & security collaboration.
- Require certain kinds of AI incident reporting.
- Clarify the liability of AI developers for concrete AI harms.
- Create means for rapid shutdown of large compute clusters and training runs.
More details at the link. As Luke notes, Luke hasn’t operationalized all the details of these proposals, done enough investigation of them, or anything like that. Those are next steps.
This does seem like quite a good practical, Overton-window-compatible set of first steps. All twelve steps seem net positive to me.
I’d emphasize #9 in particular, creating a safe harbor from anti-trust law, and I’d also include safe harbor from shareholder lawsuits. A common claim is that acting responsibly is illegal due to anti-trust law and the requirement to maximize shareholder value. I believe such concerns are highly overblown in practice, in the sense that I do not expect a successful ‘you were too worried about safety’ lawsuit to succeed even if it did happen, nor do I expect any anti-trust action to be brought against companies cooperating to ensure everyone doesn’t die.
The problem is that such rhetoric and worry presents a serious practical barrier to action. Whereas if there was official clear permission, even clear official approval, for such measures, this would make things much easier. It is also the best kind of regulation, where you remove regulation that was preventing good action, rather than putting up additional barriers.
Tyler Cowen responds here, attacking as usual any proposal of any form using ludicrous concerns (yes, you would be allowed to bring in a computer from Mexico) and characterizing security features as a ‘call for a complete surveillance society’ and threatening widespread brand damage to a movement for someone even saying such a proposal out loud in an unofficial capacity. Discussion must be ‘stillborn’ and shut down, stat. And calling the risks things that ‘have not even been modeled,’ as another non-sequitur way to continue to insist that we need not treat any AI risk concerns as real.
How do we get from brainstorming ideas on feasible safety regulations to Tyler asking why not a call to ‘shut down all high skill immigration’? This line seems telling, a very heroes-and-villains view of the situation where there are only friends and enemies of progress, and a complete failure to grapple with people like Luke being on the pro-technology, pro-capability, pro-growth side of almost every other issue.
The correct response to early practical proposals is not offering worse ones, it is to offer better ones, or raise real objections, and to grapple with the underlying needs. I am so tired of variations on ‘if you are proposing this reasonable thing, why are you not, if the world is at stake, doing these other crazy obviously evil things that are deeply stupid?’ This is not how one engages in good faith. This is viewing arguments as soldiers on a battlefield.
That does not mean there are no good points. Tyler’s point about subsidies is well taken. We should absolutely stop actively encouraging the training of larger models, on that we can all agree.
I also think Tyler’s note about #11 being the wrong way to do liability could be right, but will wait to hear the promised additional details. Certainly some damage must be the provider’s fault, other damage must not be, so how do you draw the line?
(I am continuing to hold off responding to a variety of other Hanson and Cowen posts until I figure out how to best productively engage, and ideally until we can have discussions.)
Newsweek post from expert in bio security warns that our AI security is inadequate. Doesn’t offer actionable suggestions beyond the obvious, seems focused on tangible short-term harms, included for completeness.
The Good Fight
How would one push back against ChatGPT and AI, if one wanted to?
Barry Diller, veteran of trying to get Something Done about Google, sets his sights on AI in defense of the publishing industry, which he says it ‘threatens to obliterate.’ Not exactly the top of my worry list, but sure, what have you got? He thinks a pause is impossible, since getting people to agree to things is an unknown technology and never works, and instead suggests:
For the first time this topic has reached the stage where the publishing industry as a whole is truly grappling with the potential consequences of generative AI. That is the first stage. And that is gathering steam.
The stage after that is a series of options… I think all of which will be taken. The first is legislation and the second is litigation. I can’t tell you what direction it will take but litigation is mandatory. I won’t talk about those specifics but there are options here. We are involved.
So yes, it sounds like someone is going to be the bastard that sues the other bastards.
Also, one of those bastards could be Elon Musk?
Twitter Daily News: Microsoft drops Twitter from its daily advertising platform as they refuse to pay Twitter’s API fees.
Elon Musk: They trained illegally using Twitter data. Lawsuit time.
Be right back. Grabbing popcorn.
Environmental Regulation Helps Save Environment
Sheikh Abbdur Raheem Ali (of Microsoft): Environmental regulation is what prevents building out more new datacenters.
Michael Nielsen: Interesting – how is it preventing the new datacenters?
Sheikh: Andrey Proskurin mentioned that one of the challenges moving Bing into Azure was that MS couldn’t build new data centers in West U.S 2 because of the regulatory environment, so they had to go from IT to multi-availability DCs (otherwise they’d need to move to another region)
We are massively blocked on GPUs. Like there’s not even a shred of doubt; we are blocked by a factor of three probably. You can’t get planning permission fast enough, 14 to 16 months is optimistic, everyone is acquiring leases/land across the planet and pre-provisioning shells.
Not to oversimplify, but a datacenter is a building that contains a bunch of computers. If you want to build that in the middle of a city, or any particular special location, perhaps I can see that being an issue. Instead, this seems like ‘somewhere in the middle of America, build a building where we can put a bunch of computers’ is facing over a year of delays due to environmental regulations. There is literally nowhere they can simply build a building that would have what it takes to store a bunch of computers.
That is kind of terrible. It is also kind of a ‘one-time’ delay, in the sense that we get to be permanently lagged by a year and a half on this until things stabilize, but that only has a dramatic impact during an exponential rise in needs, and the delay doesn’t then get longer.
Also I find this rather hard to believe. We are bottlenecked not on chips but on buildings to put the chips into? I was told by many that there was a clear chip shortage. Also Microsoft is working on making its own chips.
The Quest for AI Safety Funding
There’s a new common application. The game theory is on and I for one am here for it.
Full EA forum post here. Application deadline (this time anyway) is May 17, 2023.
Why apply to just one funder when you can apply to dozens?
If you’ve already applied for EA funding, simply paste your existing application. We’ll share it with relevant funders (~30 so far) in our network.
…
The biggest lesson we learned: openly sharing applications with funders was high leverage – possibly leading to four times as many people receiving funding and 10 times more donations than would have happened if we hadn’t shared.
If you’ve been thinking about raising money for your project idea, we encourage you to do it now. Push through your imposter syndrome because, as Leopold Aschenbrenner said, nobody’s on the ball on AGI alignment.
…
Another reason to apply: we’ve heard from EA funders that they don’t get enough applications, so you should have a low bar for applying – many fund over 50% of applications they receive (SFF, LTFF, EAIF).
My experience from SFF was indeed that if you had an AI Safety project your chances of getting funded were quite good.
If you are already seeking EA-branded funding at all for your project, this is presumably a very good idea, and you should do this. Hell, this makes me tempted to throw out an application that is literally: This is Zvi Mowshowitz, my blog itself is funded but if you fund me I will hire engineers at generous salaries to try out things and teach me things and build demonstration projects and investigate questions and other neat stuff like that, maybe commission a new virtual world for LLM agents to take over in various ways, and otherwise scale up operations as seems best, so if you want to throw money at that I’m going to give you that option but absolutely no pressure anyone.
As in, make that 50%+ of the entire application and see what happens, cause sure, why not? Should I do it?
People Would Like a Better Explanation of Why People Are Worried That AI Might Kill Everyone
Some of those people want this explanation for themselves. Others want the explanation to exist so it can be given to others.
David Chalmers seeks a canonical source.
Chalmers: is there a canonical source for “the argument for AGI ruin” somewhere, preferably laid out as an explicit argument with premises and a conclusion?
There were a number of excuses given for why we haven’t definitively done better than Bostrom’s Superintelligence.
Eliezer: Everyone comes in with a different personal set of objections they want answered.
Arthur: No, everyone comes in with “but you’re saying this out of nowhere, you’re just asserting this” and the current best thing to point them to is Superintelligence…. and that reaction is perfectly normal. The argument is extremely compelling when you’ve read a lot about it and sat with it for over a decade, but it’s easy to forget that journey and think people should just “get it”, at least for me it can be.
or:
Rob Bensinger: Unsurprisingly, the actual reason people expect AGI ruin isn’t a crisp deductive argument; it’s a probabilistic update based on many lines of evidence. The specific observations and heuristics that carried the most weight can be hard to draw out, and vary for each individual.
Chambers: I’d totally settle for a complex probabilistic argument (though I’d worry about too much variability in weight).
I understand all these problems and excuses. I still think that’s what they are. Excuses.
Tyler Cowen is fond of saying ‘given the stakes’ when criticizing people who failed to do whatever esoteric thing he’s talking about that particular day. This can certainly be obnoxious and unreasonable. Here, I think it applies. We need a canonical explanation, at every level of complexity, that can adjust to what someone’s objections might be, and also adjust to which premises they already know and accept, and which ones are their true objections or require further explanation.
Is this easy? No. Does it need to be done? Is it worth doing? Yes.
It is approaching the ‘if you want it done right, you got to do it yourself’ stage.
Many of these discussions were triggered by this:
Eliezer Yudkowsky: Remember: The argument for AGI ruin is *never* that ruin happens down some weird special pathway that we can predict because we’re amazing predictors. The argument is *always* that ordinary normal roads converge on AGI ruin, and purported roads away are weird special hopium.
This is indeed a key problem. As I keep saying, the ruin result is highly robust. When you introduce a more intelligent and more capable source of optimization than humans into the world, you should expect it to determine how to configure the matter rather than us continuing to decide how to configure the matter. Most configurations of the matter do not involve us being alive.
The tricky part is finding a plausible way for this not to happen.
Yet most people take the position of ‘everything will by default work out unless you can prove a particular scenario.’ You can respond with ‘it’s not about a particular scenario’ but then they say it is impossible unless you give them an example, after which they treat you as saying that example will definitely happen, and that finding one step to disbelieve means they get to stop noticing we’re all going to die.
Matt Yglesias points out the obvious, which is that it does take much worry about AI to realize that training a more powerful core AI model has larger risks and downsides to consider than, say, putting a roof deck on a house. Regulation is clearly quite out of whack.
I assume that AI accelerationists, who say there is nothing to worry about, mostly agree with this point – they think we are crazy to put so many barriers around roof decks, and also everything else involving atoms.
Alas, this then makes them even more eager to push forward with AI despite its obvious dangers, because the otherwise sensible alternative methods of growth and improvement have been closed off, so (in their view) either we roll the dice on AI or we lose anyway.
Which makes it that much more important to let people build houses where people want to live, approve green energy projects, make it viable to ship spices from one American port to another American port and otherwise free us up in other ways. A world where everything else wasn’t strangled to death will be much better able to handle the choices ahead.
Seb Krier has thoughts on what might be helpful for safety.
Here are five things that could be valuable for advancing AI safety:
1. Develop a well-organized, hyperlinked map that outlines various risk pathways, key arguments, and relevant LW/AF posts, making it easier to navigate the complex landscape of AI safety.
2. Collaborate on an AI Safety FAQ, authored by multiple respected contributors, that presents the essential concepts in a clear, digestible format for those who may not engage with the above.
3. Publish a comprehensive research agenda that identifies major bottlenecks and poses tractable technical questions for AI safety researchers to address.
4. Draft well-structured policy proposals, complete with detailed models, cost-benefit analyses, and specific recommendations to ensure they are actionable and effective.
5. Focus advocacy and argumentation efforts on engaging with stakeholders who have direct influence over decision-makers.
A lot of that is ‘do what you’re doing, but do it properly and well, with good versions.’
With a side of ‘tell it to the people who matter.’
That’s always easier said than done. Usually still good advice. It is still good to point out where the low hanging fruit is.
In particular, #1 and #2, a combination of a well-organized hyper-linked map of key arguments, and a basic FAQ for people coming in early, seems like something people keep talking about and no one has done a decent job with. A response suggests Stampy.ai for #2.
For #3, I notice it’s a case of ‘what exactly is a comprehensive research agenda?’ in context. We don’t know how this would work, not really.
For #4, agreed that would all be great, except that I continue to wonder what it would mean to have detailed models or cost-benefit analyses, and we are confused on what policies to propose. I get the instinct to want models and cost-benefit and I’d love to provide them, but in the context of existential risks I have no idea how to usefully satisfy such requests, even if I keep working on the problem anyway.
Jonathan Gray of Anthropic: Every vibes-based argument against AGI risk takes me a step closer to doomerism.
Quotes Richard Ngo from April 2: I’m often cautious when publicly arguing that AGI poses an existential risk, because our arguments aren’t as detailed as I’d like. But I should remember that the counterarguments are *much* worse – I’ve never seen a plausible rebuttal to the core claims. That’s terrifying.
Vibes are not evidence. People arguing using vibes may or may not be evidence, since people will often use vibe arguments in favor of true things, and if there is a clear vibe people will reason from it no matter the underlying truth. However, if people keep falling back on vibes more than one would expect, that does become evidence…
Quiet Speculations
This two-axis model of AI acceleration and risk from Samuel Hammond seems spot on in its central claim, then has quite the interesting speculation.
AI accelerationism has a vertical and horizontal axis.
The vertical axis is about bigger and stronger models, and is where the x-risk lies.
The horizontal axis is about productizing current models into every corner of the economy, and is comparatively low risk/high reward.
I am a horizontal e/acc and vertical e/dec.
Ironically, however, this is de facto flipped for society as a whole.
AI doctors and record producer will run into regulation and lawsuits. But if you want to build a dangerously powerful model, the only barrier is $$.
The wrinkle is that the horizontal and vertical axes aren’t totally independent.
In addition to growing the market, integrating AI into everything could create correlated risks from when the foundation model behind the most popular API gets an upgrade.
I hope this means that horizontal adoption slows the rate of new releases, since they will require significantly more safety testing.
Similar to how Tesla can push an update to autopilot over the air, only updates to GPT-4 will be pushed to thousands of distinct applications.
When there are millions of cars on the road, you want to be extra sure the update you push is a pure improvement. But that’s harder to gauge for LLMs, since the technology is so domain general. Some tasks could improve while others catastrophically fail.
Imagine if GPT-3.5 had been widely integrated into the economy when they pushed an update to the Bing version of GPT-4, and suddenly the star employee in every company became manic depressive in sync.
The optimistic version of this is that, once AI is integrated into everything, model upgrades will be like a synchronized, over-the-air Flynn Effect for digital agents.
For many tasks, GPT-4 could be a kind of satisficer, squeezing out the potential alpha from training more powerful models, except for the most intelligence-intensive tasks.
Building bigger and stronger models is expensive. It is centralized. It offers great rewards if it turns out well. It also puts us all at risk. Accelerating other AI capabilities lets us reap the rewards from our models, without net incurring much additional risk. It can even lower risk by showing us the dangers of current core models in time to prevent or modify future more powerful core models.
It can also accelerate them, if it ties AI systems more into everything and makes us dependent on them, potentially increasing the damage an AI system could do at a given capabilities or core model level.
The other danger is that increasing capabilities increases funding and demand for future more powerful core models.
In the past, I think this danger clearly overrode other considerations. If you were building stuff that mattered at scale using AI, you were making things worse, almost no matter what it was.
Now, with the new levels of existing hype and investment and attention, it is no longer obvious that this effect is important enough to dominate. In at least some places, such as AutoGPTs, I am coming around to the need to find out what damage can be done dominating the calculus.
In addition to the conceptualization, the new thing here that I hadn’t considered is the interaction of the axes and regulatory scrutiny. As Samuel points out, by default our regulatory actions will be exactly wrong, slowing down horizontal practical progress while not stopping the training of more powerful models. There are a bunch of reasonable regulatory proposals starting to develop, yet they are mostly still aimed at the wrong problem.
However, if any new model will get plugged into a bunch of existing practical systems, then releasing that model suddenly endangers all those systems. In turn, that means the regulatory state becomes interested. Could this perhaps be a big deal?
AI medical diagnostic systems seem to be severely underperforming compared to the progress one might have expected. I continue to be surprised at our lack of progress here, which we can compare to the sudden rapid advances in LLMs. Why aren’t such systems doing much better? The thread seems to think the answer is, essentially, ‘these systems do not do well out of sample and aren’t good at the messiness you see in the real world’ but the value on offer here is immense and all these problems seem eminently fixable with more work.
What Google was accomplishing was not making things worse.
Paul Graham: It may be that OpenAI is going too fast, but I’m skeptical about whether Google was achieving much toward making AI safer by never shipping. In fact it may have made things net worse. At least now we can start to predict and adjust to what’s coming.
Occam’s razor says that Google was slow to ship AI in the same way they’re slow to ship everything else: not because the best minds of our generation were engaged in a brilliantly conducted study of the possible risks, but ordinary squabbling and bureaucracy.
This is, I suppose, the classic ‘overhang’ argument once again. That by not shipping, Google didn’t give us time to prepare.
I don’t see how this can be right. What Google mostly didn’t do was accelerate capabilities development, as evidenced by almost all efforts now going into capabilities with orders of magnitude more funding and effort and attention, whereas the actual necessary work for us all to not die lags far behind.
I suppose one can use the full ‘overhang’ argument where if everything happens later then everything happens quicker and is even worse, on the theory that the limiting factors are time-limited and can’t be accelerated? Except that is so clearly not how capitalism or innovation actually works.
I agree that Google did not ship in large part because Google is not in the habit of shipping things and has ordinary barriers stopping it from shipping. That doesn’t make it less good to not ship. Either shipping is net helpful or unhelpful, no matter the mechanisms causing it – I am deeply happy to take ‘ordinary incompetence’ as the reason harmful things don’t happen. We can all think of many such cases.
This points to my concept of Asymmetric Justice. In most people’s default method of evaluation, you get credit for good effects only if you intended them, whereas you are responsible for all bad effects. Which means that anything ‘framed as an action’ becomes net bad.
What’s strange about the AI debate is the turning this on its head, which I only now just realized fully. The ‘action’ here is no longer training large models that might kill someone and pushing capabilities, the ‘action’ here is not training large models or delaying releases, or choosing not to delay capabilities. The ‘default world’ that you are blameless for is charging full speed ahead into the AI future, so suddenly if you suggest not risking everyone dying then you have to answer for everything.
How did they pull off that trick? Can we reverse it? Can we make people see that the action that requires justification is creating new intelligent systems with capabilities that potentially exceed human ones, rather than the ‘action’ being a ‘regulation’ to prevent this from happening?
And yes, in general this anti-action bias is harmful. Still seems worth using it here.
To change whether you see doom as the default outcome: Stop seeing AI through the lens of a tech/econ trend. Start seeing it through the lens of computer security. A swarm of superintelligent threat actors.
[Rob Bensinger] Also, intelligent search for action sequences you didn’t anticipate. Even if the AI isn’t currently modeling you as an enemy (or modeling you at all) and trying to kill you, many alignment measures have to be robust to creative search for weird new states.
There is AI the tech/econ trend. It is quite the important tech and econ trend, the most important in a very long time, even considered only on those terms. It is also an intelligent threat actor, a new source of intelligence and optimization pressure that is not human. That is a fundamentally different thing from all previous technologies.
I do not think this is true, while noting that if true, we are all super dead.
Suhail (Founder of Playground AI): Meta AI is the new GOAT. You’ll see. Mark knows what he has. Llama, SAM, DINOv2 — that’s just what’s open source! They’re a team that ships.
OpenAI’s attitude towards AI safety and AI NotKillEveryoneism is irresponsible and inadequate. Meta’s attitude towards AI safety and AI NotKillEveryoneism is that they are against them. So they do the worst possible things, like open sourcing raw models.
The Third Non-Chimpanzee
In a post primarily about linking to the ‘Eight Things To Know About LLMs,’ Alex Tabarrok lays out a ubiquitous false dichotomy unusually clearly, which is great:
Bowman doesn’t put it this way but there are two ways of framing AI risk.
The first perspective envisions an alien superintelligence that annihilates the world.
The second perspective is that humans will use AIs before their capabilities, weaknesses and failure modes are well understood.
Framed in the latter way, it seems inevitable that we are going to have problems. The crux of the dilemma is that AI capability is increasing faster than our AI understanding. Thus AIs will be widely used long before they are widely understood.
You don’t have to believe in “foom” to worry that capability and control are rapidly diverging. More generally, AIs are a tail risk technology, and historically, we have not been good at managing tail risks.
In the model Alex is laying out, the AI is either
- An alien superintelligence that suddenly becomes far more powerful than us, or
- A tool we might use before we understand and are able to properly control it.
Except there’s also something in the very normal, pedestrian realm of:
- Another intelligence. One that is smarter and faster than us, and cheaper to run. One that is better than us at optimizing atoms via charting paths through causal space, even if it’s not God-level better.
Even if we ‘solve the alignment problem’ at essentially zero cost, if our understanding catches up to our capabilities, competition between humans (and also some people’s ethical considerations) will see AIs set loose with various agendas, and that will be that.
This is why I say the result of our losing control over the future is robust. Why should it be otherwise? The future already belongs to the most powerful available intelligent optimization processes. That’s going to be a highly difficult thing to change.
People Are Worried AI Might Kill Everyone
Made it to the cover for the Financial Times, as well as at least briefly being the #1 story on the website.

We now have a non-paywalled version. As Daniel Eth notes, stories about existential risk from AI have legs, people pay attention to them.
If you are reading this, I doubt the post contains anything that is new to you, beyond learning its tactical decisions and rhetorical beats.
A central focus is to notice that what people are attempting to build, or cause to exist, is better called God-Like AI (GLI?) than simple AGI (artificial general intelligence) or even ASI (artificial superintelligence). The problem is when people hear AGI, they think of a digital human, perhaps with some modest advantages, and all their ‘this is fine’ instincts get kicked into gear. If they hear ASI, there’s a lot of ‘well, how super, really’ so that’s better but it’s not getting the full job done.
The suggestions included are standard incremental things, such as calls for international coordination and democratic attention, correctly framing such actions as highly precedented, and the current situation as posing large and existential risks, if not right away then potentially soon.
Connor Leahy says he expects my #19 prediction from my AutoGPT post to happen. As a reminder, that was:
The most likely outcome of [ARC safety evaluations of a future GPT-5-level model] is that ARC notices things that everyone involved would have previously said make a model something you wouldn’t release, then everyone involved says they are ‘putting in safeguards’ of some kind, changes the goal posts, and releases anyway.
This is definitely a prediction where we very much want to notice if it comes true. Ideally, we would have a clear understanding of where the goalposts are now, and we would say in advance that if indeed the goalposts are moved in this way, it would be quite an important fire alarm.
Paul Graham has no idea how worried to be, in probabilistic terms, or what to think.
Paul Graham: I honestly don’t know what to think about the potential dangers of AI. There are so many powerful forces at work that there’s a wide span of possibilities.
Some of the forces at work: huge amounts of money, very smart people, national security, various Moore’s Laws, that the thing we’re making is intelligence, and that so much of its behavior is emergent. Few historical situations have been so unpredictable.
Sundanshu Kasewa: What are some of the worst outcomes, and how much probability do you put on those?
Graham: We all die and I have no idea respectively.
Rob Bensinger offers The Basic Reasons I Expect AGI Ruin. Here are the core points.
1. General intelligence is very powerful, and once we can build it at all, STEM-capable artificial general intelligence (AGI) is likely to vastly outperform human intelligence immediately (or very quickly).
When I say “general intelligence”, I’m usually thinking about “whatever it is that lets human brains do astrophysics, category theory, etc. even though our brains evolved under literally zero selection pressure to solve astrophysics or category theory problems”.
…
2. A common misconception is that STEM-level AGI is dangerous because of something murky about “agents” or about self-awareness. Instead, I’d say that the danger is inherent to the nature of action sequences that push the world toward some sufficiently-hard-to-reach state.[8]
Call such sequences “plans”.
…
The danger is in the cognitive work, not in some complicated or emergent feature of the “agent”; it’s in the task itself.
It isn’t that the abstract space of plans was built by evil human-hating minds; it’s that the instrumental convergence thesis holds for the plans themselves. In full generality, plans that succeed in goals like “build WBE” tend to be dangerous.
…
3. Current ML work is on track to produce things that are, in the ways that matter, more like “randomly sampled plans” than like “the sorts of plans a civilization of human von Neumanns would produce”. (Before we’re anywhere near being able to produce the latter sorts of things.)[9]
We’re building “AI” in the sense of building powerful general search processes (and search processes for search processes), not building “AI” in the sense of building friendly ~humans but in silicon.
…
4. The key differences between humans and “things that are more easily approximated as random search processes than as humans-plus-a-bit-of-noise” lies in lots of complicated machinery in the human brain.
…
5. STEM-level AGI timelines don’t look that long (e.g., probably not 50 or 150 years; could well be 5 years or 15).
…
6. We don’t currently know how to do alignment, we don’t seem to have a much better idea now than we did 10 years ago, and there are many large novel visible difficulties. (See AGI Ruin and the Capabilities Generalization, and the Sharp Left Turn.)
On a more basic level, quoting Nate Soares: “Why do I think that AI alignment looks fairly difficult? The main reason is just that this has been my experience from actually working on these problems.”
7. We should be starting with a pessimistic prior about achieving reliably good behavior in any complex safety-critical software, particularly if the software is novel. Even more so if the thing we need to make robust is structured like undocumented spaghetti code, and more so still if the field is highly competitive and you need to achieve some robustness property while moving faster than a large pool of less-safety-conscious people who are racing toward the precipice.
…
8. Neither ML nor the larger world is currently taking this seriously, as of April 2023.
This is obviously something we can change. But until it’s changed, things will continue to look very bad.
…
9. As noted above, current ML is very opaque, and it mostly lets you intervene on behavioral proxies for what we want, rather than letting us directly design desirable features.
ML as it exists today also requires that data is readily available and safe to provide. E.g., we can’t robustly train the AGI on “don’t kill people” because we can’t provide real examples of it killing people to train against the behavior we don’t want; we can only give flawed proxies and work via indirection.
10. There are lots of specific abilities which seem like they ought to be possible for the kind of civilization that can safely deploy smarter-than-human optimization, that are far out of reach, with no obvious path forward for achieving them with opaque deep nets even if we had unlimited time to work on some relatively concrete set of research directions.
Eliezer explains why, if you ask an entity to learn to code, it might respond by learning general complex reasoning, the same way humans learned general complex reasoning, and it might plausibly do it much more efficiently than one can learn that trick from regular human text that doesn’t have as strong logical structure. It seems like a highly plausible hypothesis.
Anton: The reason why open LLMs like LLaMA are still lacking? Probably because they didn’t see enough code during pretraining
Celeste: Why would a model learn general complex reasoning when trained on code? this isn’t very intuitive to me.
Eliezer: Why would a human learn to reason when trained on chipping flint handaxes? Because among the solutions to that problem, are solutions that run very deep, and sometimes hill-climbing finds those, and then they generalize.
Celeste: sure, but why is this true of code in a way that it’s not of natural language? do you think the improvement is solely explained by it being another novel domain?
Eliezer: Code runs in narrower, more precise channels. I don’t think it contains anything that isn’t in natural speech on the Internet deep down, but I think it might expose some aspects of cognition closer to the learnable surface.
Celeste: Yeah. an alternate way of framing this is that natural language is intended to be parsed by humans, who automatically correct certain classes of errors and resolve more ambiguities.
An implication is that perhaps one can turn a knob on ‘general reasoning ability’ that is distinct from other knobs of LLM capabilities, which would be interesting.
Oh, Elon
A few weeks ago Elon called for a pause in training more powerful AI models. Now he’s going to, once again, do the worst possible thing and create another AI lab. He sees the risk of civilizational destruction, so he’s going to do the thing most likely to lead to civilizational destruction.
Thus: Reuters: Elon Musk says he will launch rival to Microsoft-backed ChatGPT.
“I’m going to start something which I call ‘TruthGPT’, or a maximum truth-seeking AI that tries to understand the nature of the universe,” Musk said in an interview with Fox News Channel’s Tucker Carlson aired on Monday.
“It’s simply starting late. But I will try to create a third option,” Musk said.
I will leave ‘why a maximally truth-seeking AI would not be all that aligned with human interests’ as an exercise to the reader, and also something about how truth-seeking-aligned is the new Twitter and a trick called solving for the equilibrium.
What kills me about this is that it substantially increases our probability of all dying. What symbolically kills me is how many times does this need to happen?

Except instead of standards it is teams racing to get everyone killed.
Elon Musk directly created OpenAI because he was upset with DeepMind. Then those upset with OpenAI created Anthropic. Now… ‘TruthGPT’?
Sigh.
Other People Are Not Worried AI Might Kill Everyone
For example Yann LeCun, whose statements Eliezer presents without comment.
Yann LeCun: Most people have no problem leading groups of people who are smarter than themselves.
Political, business, & military leaders have staff & advisors who are often smarter individually or collectively.
Why would people feel threatened leading machines that are smarter than them?
…
Yann LeCun: Humans are hardwired by evolution to be a social species with hierarchical structure. This includes hardwired drives for dominance or submission.
AI assistants will simply have hardwired drives to submit and not dominate.
Not only are Bryne Hobbart and Tobias Hubert not worried about AI killing everyone, they are worried that ‘safetyism has become one of the biggest existential risks to humanity’ – not developing intelligences smarter than humans would, after all, be the real risk. That’s not to say they don’t ‘bring the receipts’ on the many ways in which our society has gone completely bonkers in the name of ‘safety,’ including the short-term risks of AI, on issues like genetic engineering and nuclear power. The take here on gain of function research is confusing, I can’t tell whether they’re against it because it causes pandemics or for it because it is supposed to be preventing pandemics and being worried about it is ‘safetyism.’ As usual with such tracts, there is no engagement with what it would mean to develop intelligences, or any thought on whether the warnings do or don’t have merit, simply a cultural ‘people who say new tech is scary are bad’ take.
OpenAI Is Not Currently Training GPT-5
Sam Altman gave us some important news this week.
One could almost say they were… pausing?
They are very much not holding off on GPT-5 due to the pause letter, or due to any related safety concerns. They are holding off because they’re not ready to train GPT-5 in a way that would be useful.
Which is, indeed, exactly what I was saying in my reaction to the pause letter.
I am not even confident that waiting six months would be a mistake on a purely strategic level. The training compute could be (and presumably would be) redirected to GPT-4 (and others could do a similar move) while GPT-5 could then be trained six months later…
A six month pause in training now, for OpenAI won’t push back long term capabilities developments six months. It will delay them approximately zero months.
Meanwhile, no doubt, Google is training their would-be GPT4-killer, whatever it is, while Anthropic prepares to start training theirs.
Sam Altman also responded to the open letter, saying some aspects of it were good and he agrees with them, while others miss the mark. The biggest thing that missed the mark was exactly that they’re already not training GPT-5, and indeed no longer believe that Scale Is All You Need – it’s time to train smarter, he says, not larger.
Altman: I think we’re at the end of the era where it’s gonna be these giant models, and we’ll make them better in other ways, I think there’s been way too much focus on parameter count, maybe parameter count will trend up for sure. But this reminds me a lot of the gigahertz race in chips in the 1990s and 2000s, where everybody was trying to point to a big number.
His essential answer on safety is that safety is important, he’s doing lots of safety work every time they deploy anything, including stuff the people writing the letter might not even know about. The disagreement is he doesn’t see the pause tactic as useful.
That certainly could be true right now, that there is no need or meaningful and useful way to pause. In which case, perfect, let’s use that time to figure out future plans, including when in the future to call for a pause.
If size does not matter as much going forward, what does that mean? If it means progress slows on base models, then that’s excellent news. If it means that progress stays the same but shifts to algorithmic improvements, that’s good if we can keep secret those improvements, and disastrous if we can’t because it makes it much more difficult to keep things under wraps or slow them down in the future. We are kind of counting on scale to act as an enforcement enabler, here.
People Are Worried About China
I continue to not worry much about China in the context of AI. I worry far more about those saying ‘China’ as a boogeyman against anyone who would avoid putting the planet at risk. For those who say the Chinese are an enemy that cannot know danger, cannot be reasoned with, would not cooperate even its own interest, I continue to be confused as to why we think these things.
This thread and post talk about the current chip capability outlook for China. For cutting edge chips, China is in a bad spot. For trailing less cutting edge chips, they are doing reasonably well.
Then we saw this release of draft ‘generative AI’ guidelines (direct in Chinese). It is not the law of the land, it is open for comments, anything could happen. It still is our best indication of where such rules might be headed. At minimum, anything here is well within the Chinese Overton window.
So, does this look like the actions of a country unwilling to consider slowing down?
Since Chinese auto-translation is not so reliable in its details, I’m going to go with Mitchell’s description, which roughly matches the translation.
First, the “support the state” socialist bent is predictable enough. It suggests a level of censorship we do NOT have in the US. The rest of the proposal has stuff I like quite a bit.
Second, the onus of responsibility is on the **provider** of the technology — not the user. If the tech generates misinformation, it’s the provider’s fault for generating it, not the user’s fault for believing it.
Third, this crazy idea that the training data must be OBJECTIVE (客觀性)! No subjective opinions allowed. That decimates most current pretraining data. (“Be able to guarantee the authenticity, accuracy, objectivity and diversity of the data”).
Fourth, it asserts a lot of individual rights. E.g., “Respect the legitimate interests of others” (尊重他人合法權益) suggests to me that artists whose content is non-consensually taken might have some rights (yes? no?)
Fifth, it re-asserts its data protection constraints, also articulated in China’s 2021 PIPL: “If the data contains personal information, it shall obtain the **consent** (同意) of the subject…”. But I think this is fairly gameable–there are a lot of exceptions.
Sixth, a self-audit, but that must be submitted & approved BEFORE the technology is deployed: “Before using generative artificial intelligence products to provide services to the public, a security assessment shall be submitted to the national network information department”
I could see this being a massive force of censorship, but also, it has similarities to the idea of certifying a technology before it’s approved for use (like what the US FDA does for food/drugs). Also similar to the current US AI Accountability Act proposal for self-audits.
There’s more, but those are the things that made me most (eyes emoji).
You can say that none of this represents China being concerned for existential risk, and you’d be right. You can say that the primary motivation is the ideological purity of China and any information circulating in China, and you’d be right again. I still say that this reveals a situation in which China has its own reasons to want to slow down AI, in addition to the fact that China is losing the economic competition, and that their primary concern is the wrong AI would be bad rather than them hoping for something actively good.
All of that points, once again, to an eager partner in a negotiation. While you were saying they would defect, they were getting ready to take one for the team. Who cares if you play for a different team than they do?
Bad AI NotKillEveryoneism Takes Bingo Card
Many don’t know it exists, so makes sense to share the bingo card. Use freely.
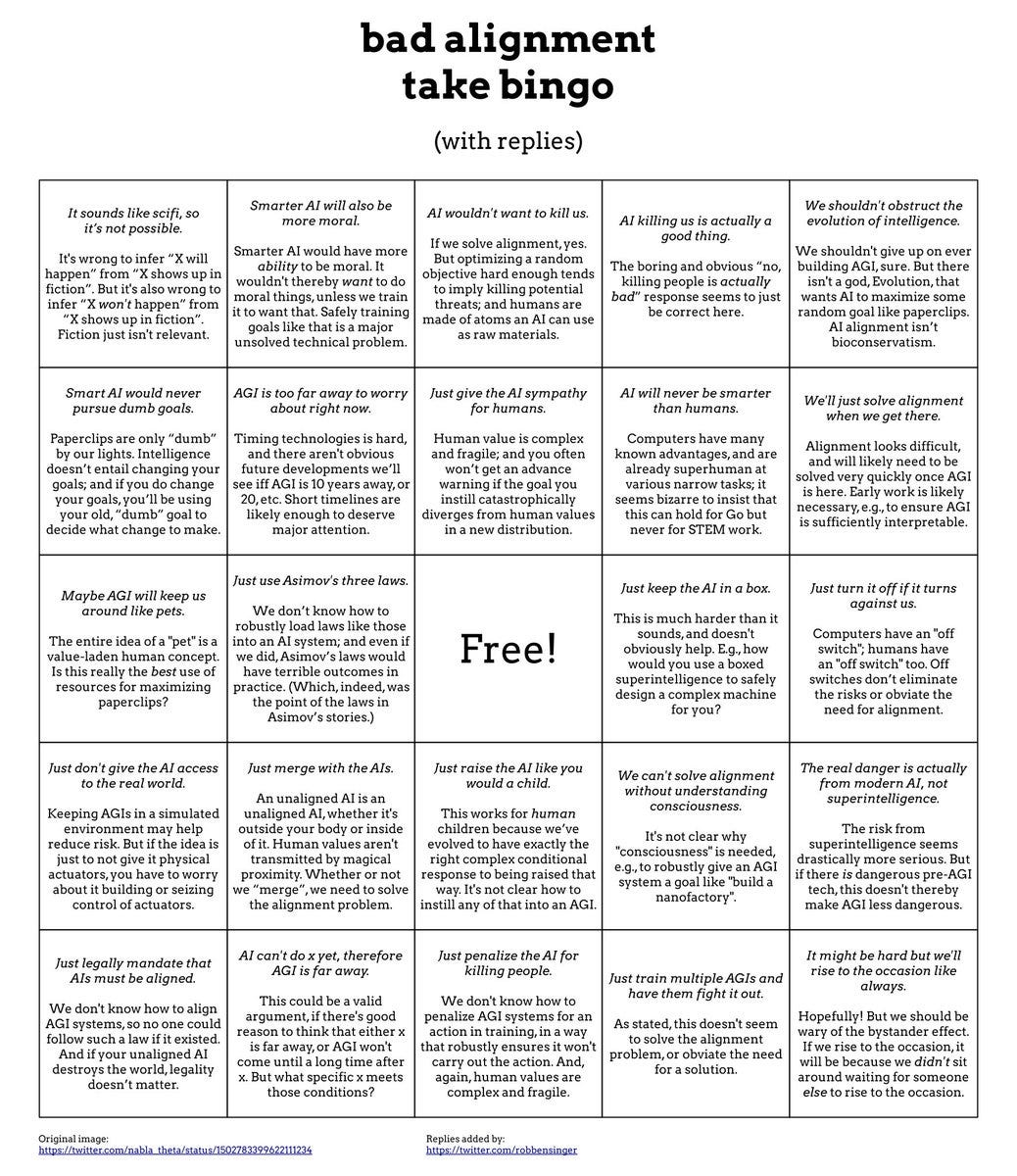
By their nature these are very short versions of all the replies. For some people, the short version will work. For others, one must treat it as only a sketch of one potential response. These aren’t all ‘the way I would respond’ at all, still a good attempt.
The Lighter Side
There has never been a clearer case of “laugh while you can, monkey boy.”
Colin Fraser: We must slow down the race to God-like AI.

Vessel of Spirit: Fire coffee dog memes will continue until people start justifying their metaphors.





One meme, endless fun and variations. Oh, there’s so many more.
