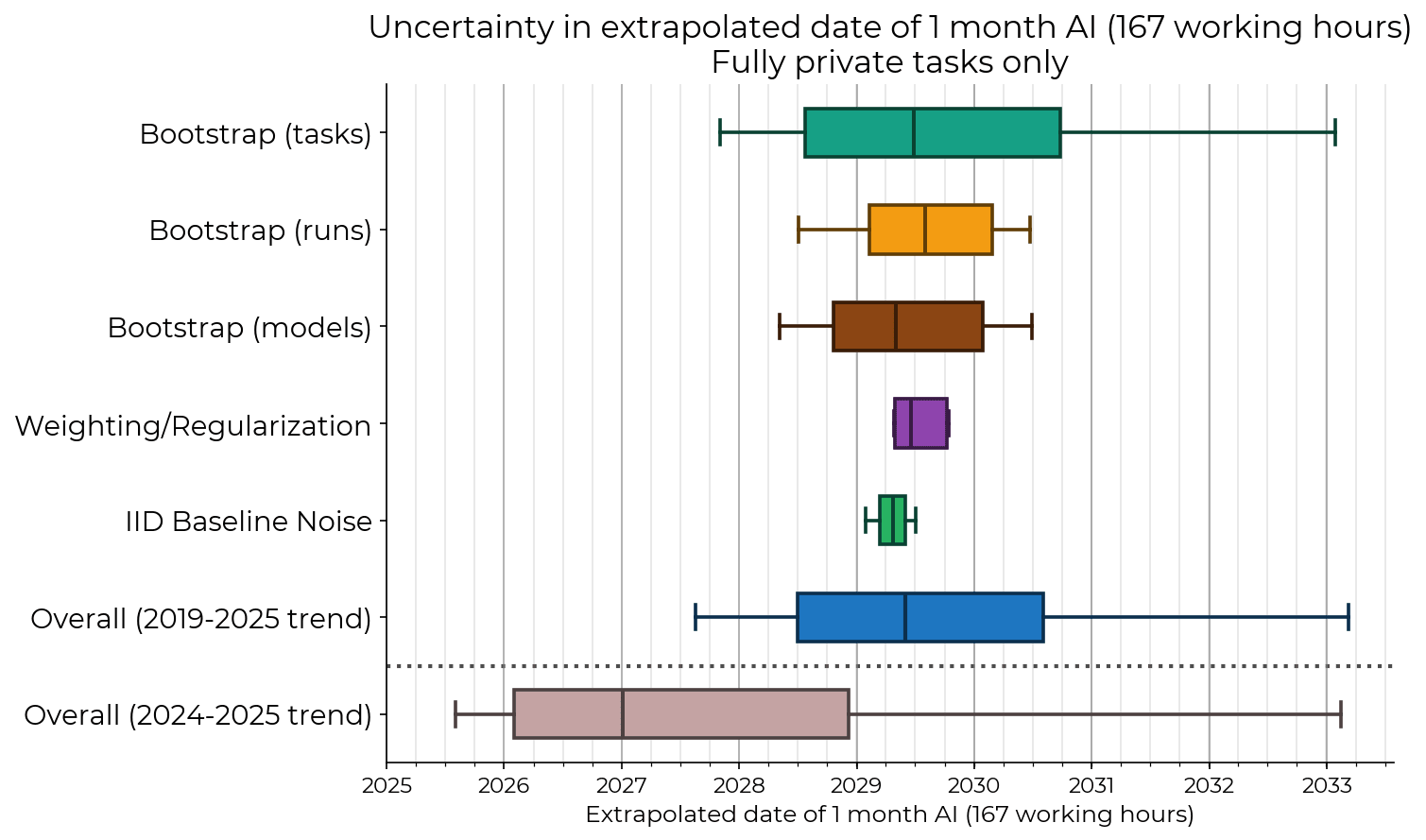
Author here. When constructing this paper, we needed an interpretable metric (time horizon), but this is not very data-efficient. We basically made the fewest tasks we could to get acceptable error bars, because high-quality task creation from scratch is very expensive. (We already spent over $150k baselining tasks, and more on the bounty and baselining infra.) Therefore we should expect that restricting to only 32 of the 170 tasks in the paper makes the error bars much wider; it roughly increases the error bars by a factor of sqrt(170/32) = 2.3.
Now if these tasks were log-uniformly distributed from 1 second to 16 hours, we would still be able to compare these results to the rest of our dataset, but it's worse than that: all fully_private tasks are too difficult for models before GPT-4, so removing SWAA requires restricting the x axis to the 2 years since GPT-4. This is 1/3 of our x axis range, so it makes error bars on the trendline slope 3 times larger. Combined with the previous effect the error bars become 6.9 times larger than the main paper! So the analysis in this post, although it uses higher-quality data, basically throws away all the statistical power of the paper. I wish I had 170 high-quality private tasks but there was simply not enough time to construct them. Likewise, I wish we had baselines for all tasks, but sadly we will probably move to a different safety case framework before we get them.
Though SWAA tasks have their own problems (eg many of them were written by Claude), they were developed in-house and are private, and it's unlikely that GPT-2 and GPT-3 would have a horizon like 10x different on a different benchmark. So for this check we really should not exclude them.
| privacy_level | num_tasks |
| fully_private | 32 |
| public_problem | 22 |
| easy_to_memorize | 18 |
| public_solution | 17 |
| semi_private | 2 |
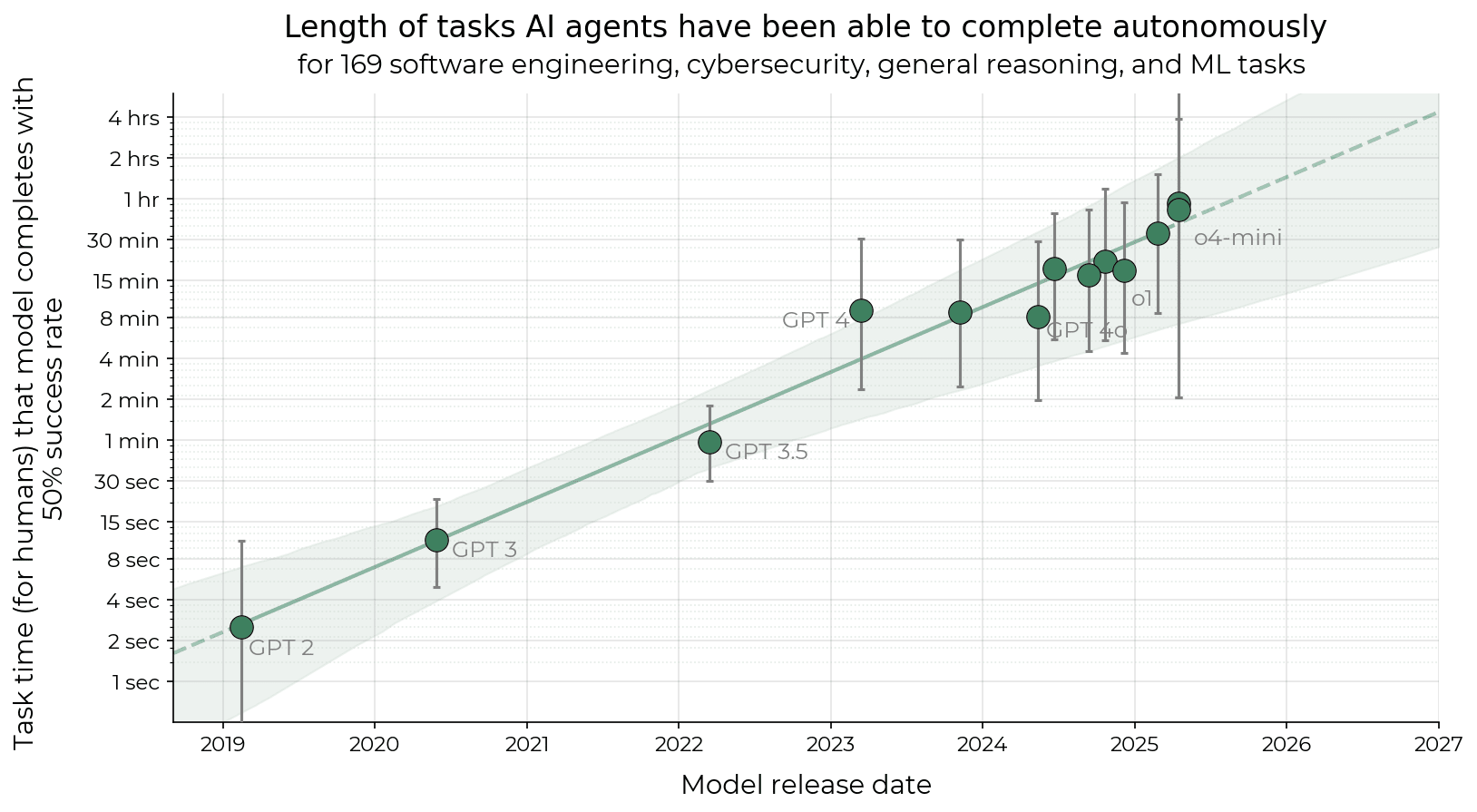
When we include SWAA, the story is not too different from the original paper: doubling roughly 8 months. Note how large the error bars are.
With only fully_private tasks and SWAA and RE-Bench, the extrapolated date of 1-month AI looks similar to the main paper, but the error bars are much larger; this is entirely driven by the small number of tasks (green bar).
For comparison, the main paper extrapolation
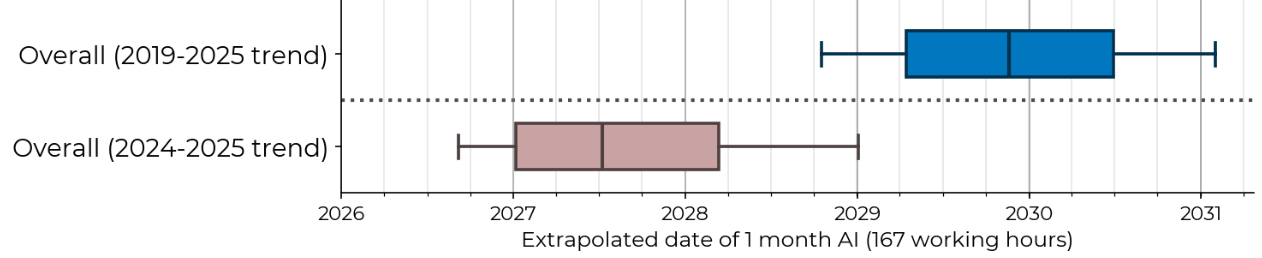
When I exclude SWAA and RE-Bench too, the script refuses to even run, because sometimes the time horizon slope is negative, but when I suppress those errors and take the 2024-2025 trend we get 80% CI of early 2026 to mid-2047! This is consistent with the main result but pretty uninformative.

You can see that with only fully_private tasks (ignore the tasks under 1 minute; these are SWAA), it's hard to even tell whether longer tasks are more difficult in the <1 hour range (tiles plot). As such we should be suspicious of whether the time horizon metric works at all with so few tasks.
I think the diplomatic tone here is reasonable, and agree that METR is doing really good work. But this post updated me significantly away from taking the "task time horizon" metric at face value. If I saw this many degrees of freedom in a study from another domain, I'd wait for more studies before I held a real opinion.
That being said, I get a similar sinking feeling whenever I read ~any AI forecasting study in detail myself, nor do I know how I'd do better. There are just so many judgment calls at every level, and no great reason to presume they all cancel out.
Hi, thanks for engaging with our work (and for contributing a long task!).
One thing to bear in mind with the long tasks paper is that we have different degrees of confidence in different claims. We are more confident in there being (1) some kind of exponential trend on our tasks, than we are in (2) the precise doubling time for model time horizons, than we are in (3) the exact time horizons on these tasks, than we are about (4) the degree to which any of the above generalizes to ‘real’ software tasks.
When I tried redoing it on fully_private tasks only, the Singularity was rescheduled for mid-2039 (or mid-2032 if you drop everything pre-GPT-4o)
I’m not sure exactly what quantity you are calculating when you refer to the singularity date. Is this the extrapolated date for 50% success at 1 month (167hr) tasks? (If so, I think using the term singularity for this isn’t accurate.)
More importantly though, if your mid 2039 result is referring to 50% @ 167 hours, that would be surprising! If our results were this sensitive to task privacy then I think we would need to rethink our task suite and analysis. For context, in appendix D of the paper we do a few different methodological ablations, and I don't think any produced results as far off from our mainline methodology as 2039.
My current guess is that your 2039 result is mostly driven by your task filtering selectively removing the easiest tasks, which has downstream effects that significantly increase the noise in your time horizon vs release date fits. If you bootstrap what sort of 95% CIs do you get?
The paper uses SWAA + a subset of HCAST + RE-Bench as the task suite. Filtering out non-HCAST tasks removes all the <1 minute tasks (all <1 min tasks are SWAA tasks). SWAA fits most naturally into the ‘fully_private’ category in the HCAST parlance[1] Removing SWAA means pre-2023 models fail all tasks (as you observed), which means a logistic can’t be fit to the pre-2023 models,[2] and so the pre-2023 models end up with undefined time horizons. If we instead remove these pre 2023 models, this makes the log (50% time horizon) vs release date fit much more sensitive to noise in the remaining points. This is in large part because the date-range of the data goes from spanning ~6 years (2019-2025) to spanning ~2 years (2023-2025).
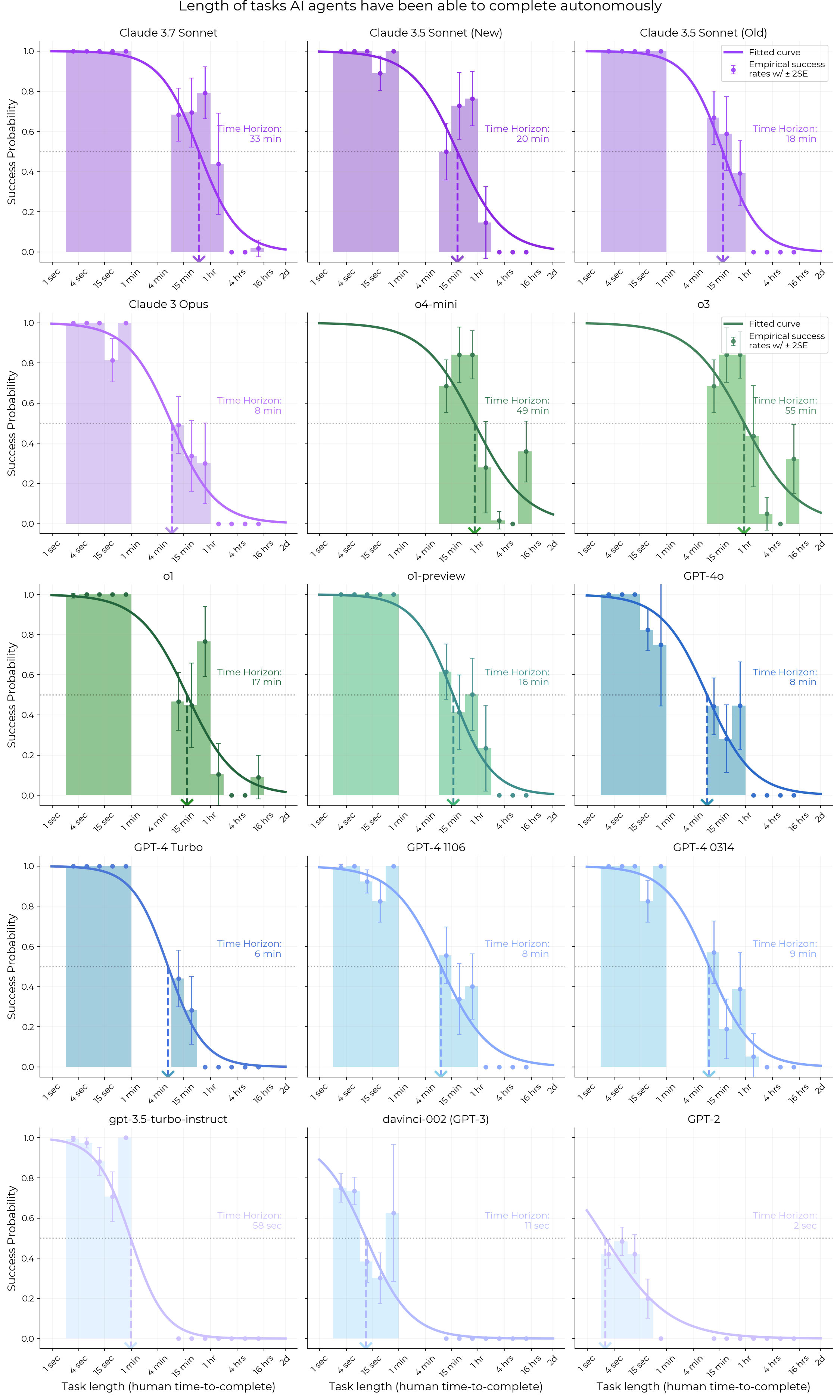
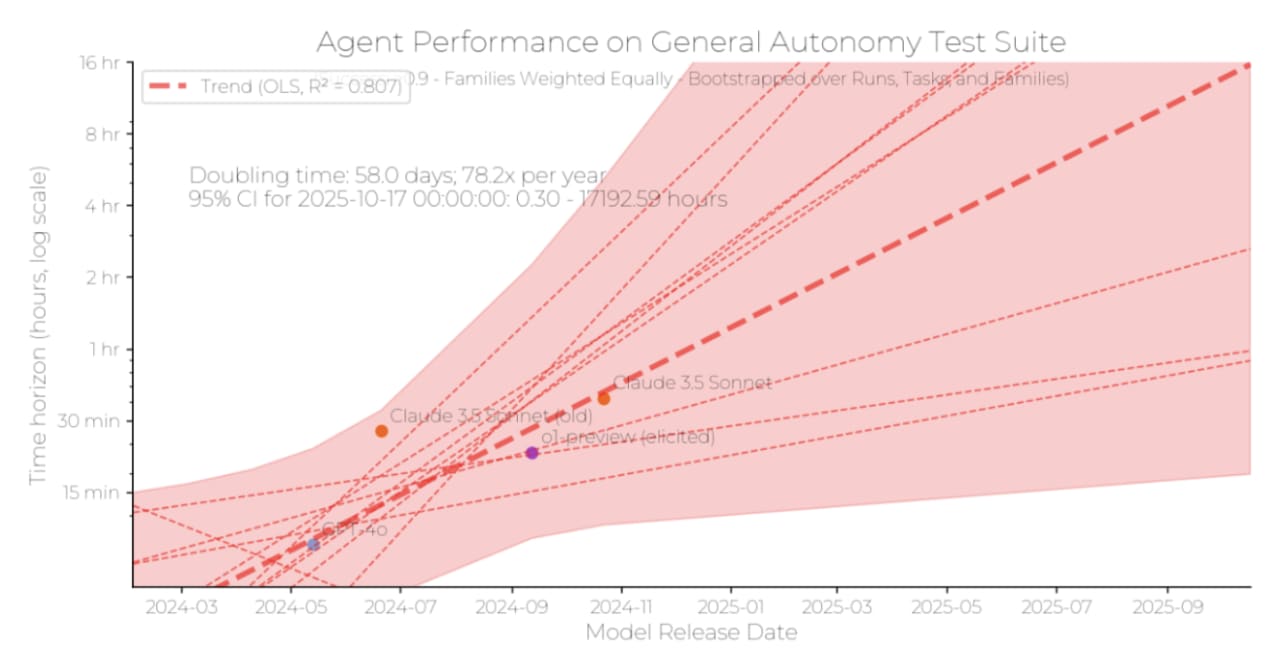
In fact, below is an extremely early version of the time horizon vs release date graph that we made using just HCAST tasks, fitted on some models released within 6 months of each other. Extrapolating this data out just 12 months results in 95% CIs of 50% time horizons being somewhere between 30 minutes and 2 years! Getting data for pre-2023 models via SWAA helped a lot with this problem, and this is in fact why we constructed the SWAA dataset and needed to test pre-GPT-4 models.
- ^
SWAA was made by METR researchers specifically for the long tasks paper, and we haven’t published the problems.
For RE-Bench, we are about as confident as we can be that the RE-Bench tasks are public_problem level tasks, since we created them in-house also. We zip the solutions in the RE-Bench repo to prevent scraping, ask people to not train on RE-Bench (except in the context of development and implementation of dangerous capability evaluations - e.g. elicitation), and ask people to report if they see copies of unzipped solutions online.
- ^
(I’d guess the terminal warnings you were seeing were about failures to converge or zero variance data).
I’m not sure exactly what quantity you are calculating when you refer to the singularity date. Is this the extrapolated date for 50% success at 1 month (167hr) tasks?
. . . not quite: I'd forgotten that your threshold was a man-month, instead of a month of clock time. I'll redo things with the task length being a month of work for people who do need to eat/sleep/etc: luckily this doesn't change results much, since 730 hours and 167 hours are right next door on a log(t) scale.
SWAA fits most naturally into the ‘fully_private’ category in the HCAST parlance
Your diagnosis was on the money. Filtering for the union of fully_private HCAST tasks and SWAA tasks (while keeping the three models which caused crashes without SWAAs) does still make forecasts more optimistic, but only nets half an extra year for the every-model model, and two extra years for the since-4o model.
I'll edit the OP appropriately; thank you for your help. (In retrospect, I probably should have run the numbery stuff past METR before posting, instead of just my qualitative concerns; I figured that if I was successfully reproducing the headline results I would be getting everything else right, but it would still have made sense to get a second opinion.)
the inevitable biases seem to consistently point in the scarier direction so readers can use it as an upper bound
Can you say more about this? As someone trying to forecast AGI timelines, it was a (very minor) update towards optimism that restricting to fully_private tasks only pushes the singularity back a few years. On the other hand, it's concerning if the biases seem to point in the scarier direction. I don't know how much to update based on that description alone. Can you say more about what biases you were thinking about?
Potential biases:
- The aforementioned fact that privacy levels are upper bounds on how private things might be: afaik, METR has no airtight way to know what fully_private tasks were leaked or plagiarized or had extremely similar doppelganger tasks coincidentally created by unrelated third parties, or which public_problems had solutions posted somewhere they couldn't see but which nevertheless made it into the training data, or whether some public_solutions had really good summaries written down somewhere online.
- The way later models' training sets can only ever have more benchmark tasks present in them than earlier ones. (I reiterate that at least some of these tasks were first created around the apparent gradient discontinuity starting with GPT-4o.)
- The fact they're using non-fully_private challenges at all, and therefore testing (in part) the ability of LLMs to solve problems present in (some of their) training datasets. (I get that this isn't necessarily reassuring as some problems we'd find it scary for AI to solve might also have specific solutions (or hints, or analogies) in the training data.)
- The fact they're using preternaturally clean code-y tasks to measure competence. (I get that this isn't necessarily reassuring as AI development is arguably a preternaturally clean code-y task.)
- The way Baselined tasks tend to be easier and Baselining seems (definitely slightly) biased towards making them look easier still, while Estimated tasks tend to be harder and Estimation seems (potentially greatly) biased towards making them look harder still: the combined effect would be to make progress gradients look artificially steep in analyses where Baselined and Estimated tasks both matter. (To my surprise, Estimated tasks didn't make much difference to (my reconstruction of) the analysis due (possibly/plausibly/partially) to current task horizons currently being under an hour; but if someone used HCAST to evaluate more capable future models without doing another round of Baselining . . .)
- Possibly some other stuff I forgot, idk. (All I can tell you is I don't remember thinking "this seems like it's potentially biased against reaching scary conclusions" at any point when reading the papers.)
OH, I misunderstood you. "Biases point in the scarier direction" meant "METR is biased to make the results seem scarier than they are" whereas I misunderstood and thought it meant "We readers, looking at their results and attempting to factor in their biases, should update towards scariness when factoring in their biases, i.e. they are if anything biased towards less-scary presentation of their results."
Thanks!
Belatedly edited the phrasing, hopefully "Biases push conclusions in the scarier direction" is clearer.
I contributed one (1) task to HCAST, which was used in METR’s Long Tasks paper. This gave me some thoughts I feel moved to share.
ETA: I've made some substantial changes thanks to responses by the original authors.
Regarding Baselines and Estimates
METR’s tasks have two sources for how long they take humans: most of those used in the paper were Baselined using playtesters under persistent scrutiny, and some were Estimated by METR.
I don’t quite trust the Baselines. Baseliners were allowed/incentivized to drop tasks they weren’t making progress with, and were – mostly, effectively, there’s some nuance here I’m ignoring – cut off at the eight-hour mark; Baseline times were found by averaging time taken for successful runs; this suggests Baseline estimates will be biased to be at least slightly too low, especially for more difficult tasks.[1]
I really, really don’t trust the Estimates[2]. My task was never successfully Baselined, so METR’s main source for their Estimate of how long it would take – aside from the lower bound from it never being successfully Baselined – is the number of hours my playtester reported. I was required to recruit and manage my own playtester, and we both got paid more the higher that number was: I know I was completely honest, and I have a very high degree of trust in the integrity of my playtester, but I remain disquieted by the financial incentive for contractors and subcontractors to exaggerate or lie.
When I reconstructed METR’s methodology and reproduced their headline results, I tried filtering for only Baselined tasks to see how that changed things. My answer . . .
. . . is that it almost entirely didn’t. Whether you keep or exclude the Estimated tasks, the log-linear regression still points at AIs doing month-long tasks
inbefore 2030 (if you look at the overall trend) or 2028 (if you only consider models since GPT-4o). My tentative explanation for this surprising lack of effect is that A) METR were consistently very good at adjusting away bias in their Estimates and/or B) most of the Estimated tasks were really difficult ones where AIs never won, so errors here had negligible effect on the shapes of logistic regression curves[3].Regarding Task Privacy
HCAST tasks have four levels of Task Privacy:
METR’s analysis
heavilydepends on less-than-perfectly-Private tasks. When I tried redoing it on fully_private tasks only[4][5], the Singularity was rescheduled formid-2039mid-2030 (ormid-2032mid-2029 if you drop everything pre-GPT-4o); Ihave no idearemain unsure to what extent this is a fact about reality vs about small sample sizes resulting in strange results.Also, all these privacy levels have “as far as we know” stapled to the end. My task is marked as fully_private, but if I’d reused some/all of the ideas in it elsewhere . . . or if I’d done that and then shared a solution . . . or if I’d done both of those things and then someone else had posted a snappy and condensed summary of the solution . . . it’s hard to say how METR could have found out or stopped me[6]. The one thing you can be sure of is that LLMs weren’t trained on tasks which were created after they were built (i.e. models before GPT-4o couldn’t have looked at my task because my task was created in April 2024)[7].
In Conclusion
The Long Tasks paper is a Psychology paper[8]. It’s the good kind of Psychology paper: it focuses on what minds can do instead of what they will do, it doesn’t show any signs of p-hacking, the inevitable biases seem to consistently push conclusions in the scarier direction so readers can use it as an upper bound[9], and it was written by hardworking clever people who sincerely care about reaching the right answer. But it’s still a Psychology paper, and should be taken with appropriate quantities of salt.
A hypothetical task which takes a uniformly-distributed 1-10 hours would have about the same Baselined time estimate as one which takes a uniformly-distributed 1-100 hours conditional on them both having Baselined time estimates.
I particularly don’t trust the Estimates for my task, because METR’s dataset says the easy version of it takes 18 hours and the hard version takes 10 hours, despite the easy version being easier than the hard version (due to it being the easy version).
Note that this does not mean they will continue to have negligible effects on next year’s agents.
I also filtered out all non-HCAST tasks: I wasn’t sure exactly how Private they were, but given that METR had been able to get their hands on the problems and solutions they couldn’t bethatPrivate.To do this part of the reanalysis I dropped "GPT-2", "davinci-002 (GPT-3)" and "gpt-3.5-turbo-instruct", as none of these models were ever recorded succeeding on a fully_private task, making their task horizon undefined (ignoring the terminal-ful of warnings and proceeding anyway led to my modelling pipeline confusedly insisting that the End had happened in mid-2024 and I'd just been too self-absorbed to notice).I didn't do any of these things. I just take issue with how easily I’m implicitly being trusted.
If this is the reason for the gradient discontinuity starting at GPT-4o I’m going to be so mad.
The fact that it’s simultaneously a CompSci paper does not extenuate it.
I sincerely mean this part. While I’m skeptical of AI Doom narratives, I’m extremely sympathetic to the idea that “this is safe” advocates are the ones who need airtight proofs, while “no it isn’t” counterarguers should be able to win just by establishing reasonable doubt.