This is a special post for quick takes by ryan_greenblatt. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
I'm currently working as a contractor at Anthropic in order to get employee-level model access as part of a project I'm working on. The project is a model organism of scheming, where I demonstrate scheming arising somewhat naturally with Claude 3 Opus. So far, I’ve done almost all of this project at Redwood Research, but my access to Anthropic models will allow me to redo some of my experiments in better and simpler ways and will allow for some exciting additional experiments. I'm very grateful to Anthropic and the Alignment Stress-Testing team for providing this access and supporting this work. I expect that this access and the collaboration with various members of the alignment stress testing team (primarily Carson Denison and Evan Hubinger so far) will be quite helpful in finishing this project.
I think that this sort of arrangement, in which an outside researcher is able to get employee-level access at some AI lab while not being an employee (while still being subject to confidentiality obligations), is potentially a very good model for safety research, for a few reasons, including (but not limited to):
- For some safety research, it’s helpful to have model access in ways that la
Yay Anthropic. This is the first example I'm aware of of a lab sharing model access with external safety researchers to boost their research (like, not just for evals). I wish the labs did this more.
[Edit: OpenAI shared GPT-4 access with safety researchers including Rachel Freedman before release. OpenAI shared GPT-4 fine-tuning access with academic researchers including Jacob Steinhardt and Daniel Kang in 2023. Yay OpenAI. GPT-4 fine-tuning access is still not public; some widely-respected safety researchers I know recently were wishing for it, and were wishing they could disable content filters.]
8
OpenAI did this too, with GPT-4 pre-release. It was a small program, though — I think just 5-10 researchers.
I'd be surprised if this was employee-level access. I'm aware of a red-teaming program that gave early API access to specific versions of models, but not anything like employee-level.
9
It also wasn't employee level access probably?
(But still a good step!)
2
Source?
It was a secretive program — it wasn’t advertised anywhere, and we had to sign an NDA about its existence (which we have since been released from). I got the impression that this was because OpenAI really wanted to keep the existence of GPT4 under wraps. Anyway, that means I don’t have any proof beyond my word.
4
Thanks!
To be clear, my question was like where can I learn more + what should I cite, not I don't believe you. I'll cite your comment.
Yay OpenAI.
(I'm a full-time employee at Anthropic.) It seems worth stating for the record that I'm not aware of any contract I've signed whose contents I'm not allowed to share. I also don't believe I've signed any non-disparagement agreements. Before joining Anthropic, I confirmed that I wouldn't be legally restricted from saying things like "I believe that Anthropic behaved recklessly by releasing [model]".
I think I could share the literal language in the contractor agreement I signed related to confidentiality, though I don't expect this is especially interesting as it is just a standard NDA from my understanding.
I do not have any non-disparagement, non-solicitation, or non-interference obligations.
I'm not currently going to share information about any other policies Anthropic might have related to confidentiality, though I am asking about what Anthropic's policy is on sharing information related to this.
8
Here is the full section on confidentiality from the contract:
(Anthropic comms was fine with me sharing this.)
5
This project has now been released; I think it went extremely well.
4[anonymous]
Do you feel like there are any benefits or drawbacks specifically tied to the fact that you’re doing this work as a contractor? (compared to a world where you were not a contractor but Anthropic just gave you model access to run these particular experiments and let Evan/Carson review your docs)
9
Being a contractor was the most convenient way to make the arrangement.
I would ideally prefer to not be paid by Anthropic[1], but this doesn't seem that important (as long as the pay isn't too overly large). I asked to be paid as little as possible and I did end up being paid less than would otherwise be the case (and as a contractor I don't receive equity). I wasn't able to ensure that I only get paid a token wage (e.g. $1 in total or minimum wage or whatever).
I think the ideal thing would be a more specific legal contract between me and Anthropic (or Redwood and Anthropic), but (again) this doesn't seem important.
----------------------------------------
1. At least for this current primary purpose of this contracting. I do think that it could make sense to be paid for some types of consulting work. I'm not sure what all the concerns are here. ↩︎
1
It seems a substantial drawback that it will be more costly for you to criticize Anthropic in the future.
Many of the people / orgs involved in evals research are also important figures in policy debates. With this incentive Anthropic may gain more ability to control the narrative around AI risks.
2
As in, if at some point I am currently a contractor with model access (or otherwise have model access via some relationship like this) it will at that point be more costly to criticize Anthropic?
2
I'm not sure what the confusion is exactly.
If any of
* you have a fixed length contract and you hope to have another contract again in the future
* you have an indefinite contract and you don't want them to terminate your relationship
* you are some other evals researcher and you hope to gain model access at some point
you may refrain from criticizing Anthropic from now on.
4
Ok, so the concern is:
Is that accurate?
Notably, as described this is not specifically a downside of anything I'm arguing for in my comment or a downside of actually being a contractor. (Unless you think me being a contractor will make me more likely to want model acess for whatever reason.)
I agree that this is a concern in general with researchers who could benefit from various things that AI labs might provide (such as model access). So, this is a downside of research agendas with a dependence on (e.g.) model access.
I think various approaches to mitigate this concern could be worthwhile. (Though I don't think this is worth getting into in this comment.)
1
Yes that's accurate.
In your comment you say
I'm essentially disagreeing with this point. I expect that most of the conflict of interest concerns remain when a big lab is giving access to a smaller org / individual.
From my perspective the main takeaway from your comment was "Anthropic gives internal model access to external safety researchers." I agree that once you have already updated on this information, the additional information "I am currently receiving access to Anthropic's internal models" does not change much. (Although I do expect that establishing the precedent / strengthening the relationships / enjoying the luxury of internal model access, will in fact make you more likely to want model access again in the future).
5
As in, there aren't substantial reductions in COI from not being an employee and not having equity? I currently disagree.
1
Yeah that's the crux I think. Or maybe we agree but are just using "substantial"/"most" differently.
It mostly comes down to intuitions so I think there probably isn't a way to resolve the disagreement.
-3
So you asked anthropic for uncensored model access so you could try to build scheming AIs, and they gave it to you?
To use a biology analogy, isn't this basically gain of function research?
2
Please read the model organisms for misalignment proposal.
I thought it would be helpful to post about my timelines and what the timelines of people in my professional circles (Redwood, METR, etc) tend to be.
Concretely, consider the outcome of: AI 10x’ing labor for AI R&D[1], measured by internal comments by credible people at labs that AI is 90% of their (quality adjusted) useful work force (as in, as good as having your human employees run 10x faster).
Here are my predictions for this outcome:
- 25th percentile: 2 year (Jan 2027)
- 50th percentile: 5 year (Jan 2030)
The views of other people (Buck, Beth Barnes, Nate Thomas, etc) are similar.
I expect that outcomes like “AIs are capable enough to automate virtually all remote workers” and “the AIs are capable enough that immediate AI takeover is very plausible (in the absence of countermeasures)” come shortly after (median 1.5 years and 2 years after respectively under my views).
Only including speedups due to R&D, not including mechanisms like synthetic data generation. ↩︎
My timelines are now roughly similar on the object level (maybe a year slower for 25th and 1-2 years slower for 50th), and procedurally I also now defer a lot to Redwood and METR engineers. More discussion here: https://www.lesswrong.com/posts/K2D45BNxnZjdpSX2j/ai-timelines?commentId=hnrfbFCP7Hu6N6Lsp
I expect that outcomes like “AIs are capable enough to automate virtually all remote workers” and “the AIs are capable enough that immediate AI takeover is very plausible (in the absence of countermeasures)” come shortly after (median 1.5 years and 2 years after respectively under my views).
@ryan_greenblatt can you say more about what you expect to happen from the period in-between "AI 10Xes AI R&D" and "AI takeover is very plausible?"
I'm particularly interested in getting a sense of what sorts of things will be visible to the USG and the public during this period. Would be curious for your takes on how much of this stays relatively private/internal (e.g., only a handful of well-connected SF people know how good the systems are) vs. obvious/public/visible (e.g., the majority of the media-consuming American public is aware of the fact that AI research has been mostly automated) or somewhere in-between (e.g., most DC tech policy staffers know this but most non-tech people are not aware.)
I don't feel very well informed and I haven't thought about it that much, but in short timelines (e.g. my 25th percentile): I expect that we know what's going on roughly within 6 months of it happening, but this isn't salient to the broader world. So, maybe the DC tech policy staffers know that the AI people think the situation is crazy, but maybe this isn't very salient to them. A 6 month delay could be pretty fatal even for us as things might progress very rapidly.
6
Note that the production function of the 10x really matters. If it's "yeah, we get to net-10x if we have all our staff working alongside it," it's much more detectable than, "well, if we only let like 5 carefully-vetted staff in a SCIF know about it, we only get to 8.5x speedup".
(It's hard to prove that the results are from the speedup instead of just, like, "One day, Dario woke up from a dream with The Next Architecture in his head")
AI is 90% of their (quality adjusted) useful work force (as in, as good as having your human employees run 10x faster).
I don't grok the "% of quality adjusted work force" metric. I grok the "as good as having your human employees run 10x faster" metric but it doesn't seem equivalent to me, so I recommend dropping the former and just using the latter.
7
Fair, I really just mean "as good as having your human employees run 10x faster". I said "% of quality adjusted work force" because this was the original way this was stated when a quick poll was done, but the ultimate operationalization was in terms of 10x faster. (And this is what I was thinking.)
3
Basic clarifying question: does this imply under-the-hood some sort of diminishing returns curve, such that the lab pays for that labor until it net reaches as 10x faster improvement, but can't squeeze out much more?
And do you expect that's a roughly consistent multiplicative factor, independent of lab size? (I mean, I'm not sure lab size actually matters that much, to be fair, it seems that Anthropic keeps pace with OpenAI despite being smaller-ish)
5
Yeah, for it to reach exactly 10x as good, the situation would presumably be that this was the optimum point given diminishing returns to spending more on AI inference compute. (It might be the returns curve looks very punishing. For instance, many people get a relatively large amount of value from extremely cheap queries to 3.5 Sonnet on claude.ai and the inference cost of this is very small, but greatly increasing the cost (e.g. o1-pro) often isn't any better because 3.5 Sonnet already gave an almost perfect answer.)
I don't have a strong view about AI acceleration being a roughly constant multiplicative factor independent of the number of employees. Uplift just feels like a reasonably simple operationalization.
4
How much faster do you think we are already? I would say 2x.
7
I'd guess that xAI, Anthropic, and GDM are more like 5-20% faster all around (with much greater acceleration on some subtasks). It seems plausible to me that the acceleration at OpenAI is already much greater than this (e.g. more like 1.5x or 2x), or will be after some adaptation due to OpenAI having substantially better internal agents than what they've released. (I think this due to updates from o3 and general vibes.)
2
I was saying 2x because I've memorised the results from this study. Do we have better numbers today? R&D is harder, so this is an upper bound. However, since this was from one year ago, so perhaps the factors cancel each other out?
6
This case seems extremely cherry picked for cases where uplift is especially high. (Note that this is in copilot's interest.) Now, this task could probably be solved autonomously by an AI in like 10 minutes with good scaffolding.
I think you have to consider the full diverse range of tasks to get a reasonable sense or at least consider harder tasks. Like RE-bench seems much closer, but I still expect uplift on RE-bench to probably (but not certainly!) considerably overstate real world speed up.
2
Yeah, fair enough. I think someone should try to do a more representative experiment and we could then monitor this metric.
btw, something that bothers me a little bit with this metric is the fact that a very simple AI that just asks me periodically "Hey, do you endorse what you are doing right now? Are you time boxing? Are you following your plan?" makes me (I think) significantly more strategic and productive. Similar to I hired 5 people to sit behind me and make me productive for a month. But this is maybe off topic.
4
Yes, but I don't see a clear reason why people (working in AI R&D) will in practice get this productivity boost (or other very low hanging things) if they don't get around to getting the boost from hiring humans.
4
This is intended to compare to 2023/AI-unassisted humans, correct? Or is there some other way of making this comparison you have in mind?
7
Yes, "Relative to only having access to AI systems publicly available in January 2023."
More generally, I define everything more precisely in the post linked in my comment on "AI 10x’ing labor for AI R&D".
4
Thanks for this - I'm in a more peripheral part of the industry (consumer/industrial LLM usage, not directly at an AI lab), and my timelines are somewhat longer (5 years for 50% chance), but I may be using a different criterion for "automate virtually all remote workers". It'll be a fair bit of time (in AI frame - a year or ten) between "labs show generality sufficient to automate most remote work" and "most remote work is actually performed by AI".
8
A key dynamic is that I think massive acceleration in AI is likely after the point when AIs can accelerate labor working on AI R&D. (Due to all of: the direct effects of accelerating AI software progress, this acceleration rolling out to hardware R&D and scaling up chip production, and potentially greatly increased investment.) See also here and here.
So, you might very quickly (1-2 years) go from "the AIs are great, fast, and cheap software engineers speeding up AI R&D" to "wildly superhuman AI that can achieve massive technical accomplishments".
4
Fully agreed. And the trickle-down from AI-for-AI-R&D to AI-for-tool-R&D to AI-for-managers-to-replace-workers (and -replace-middle-managers) is still likely to be a bit extended. And the path is required - just like self-driving cars: the bar for adoption isn't "better than the median human" or even "better than the best affordable human", but "enough better that the decision-makers can't find a reason to delay".
Inference compute scaling might imply we first get fewer, smarter AIs.
Prior estimates imply that the compute used to train a future frontier model could also be used to run tens or hundreds of millions of human equivalents per year at the first time when AIs are capable enough to dominate top human experts at cognitive tasks[1] (examples here from Holden Karnofsky, here from Tom Davidson, and here from Lukas Finnveden). I think inference time compute scaling (if it worked) might invalidate this picture and might imply that you get far smaller numbers of human equivalents when you first get performance that dominates top human experts, at least in short timelines where compute scarcity might be important. Additionally, this implies that at the point when you have abundant AI labor which is capable enough to obsolete top human experts, you might also have access to substantially superhuman (but scarce) AI labor (and this could pose additional risks).
The point I make here might be obvious to many, but I thought it was worth making as I haven't seen this update from inference time compute widely discussed in public.[2]
However, note that if inference compute allows for trading off betw...
9
Ok, but for how long? If the situation holds for only 3 months, and then the accelerated R&D gives us a huge drop in costs, then the strategic outcomes seem pretty similar.
If there continues to be a useful peak capability only achievable with expensive inference, like the 10x human cost, and there are weaker human-skill-at-minimum available for 0.01x human cost, then it may be interesting to consider which tasks will benefit more from a large number of moderately good workers vs a small number of excellent workers.
Also worth considering is speed. In a lot of cases, it is possible to set things up to run slower-but-cheaper on less or cheaper hardware. Or to pay more, and have things run in as highly parallelized a manner as possible on the most expensive hardware. Usually maximizing speed comes with some cost overhead. So then you also need to consider whether it's worth having more of the work be done in serial by a smaller number of faster models...
For certain tasks, particularly competitive ones like sports or combat, speed can be a critical factor and is worth sacrificing peak intelligence for. Obviously, for long horizon strategic planning, it's the other way around.
4
I don't expect this to continue for very long. 3 months (or less) seems plausible. I really should have mentioned this in the post. I've now edited it in.
I don't think so. In particular once the costs drop you might be able to run substantially superhuman systems at the same cost that you could previously run systems that can "merely" automate away top human experts.
7[anonymous]
The point I make here is also likely obvious to many, but I wonder if the "X human equivalents" frame often implicitly assumes that GPT-N will be like having X humans. But if we expect AIs to have comparative advantages (and disadvantages), then this picture might miss some important factors.
The "human equivalents" frame seems most accurate in worlds where the capability profile of an AI looks pretty similar to the capability profile of humans. That is, getting GPT-6 to do AI R&D is basically "the same as" getting X humans to do AI R&D. It thinks in fairly similar ways and has fairly similar strengths/weaknesses.
The frame is less accurate in worlds where AI is really good at some things and really bad at other things. In this case, if you try to estimate the # of human equivalents that GPT-6 gets you, the result might be misleading or incomplete. A lot of fuzzier things will affect the picture.
The example I've seen discussed most is whether or not we expect certain kinds of R&D to be bottlenecked by "running lots of experiments" or "thinking deeply and having core conceptual insights." My impression is that one reason why some MIRI folks are pessimistic is that they expect capabilities research to be more easily automatable (AIs will be relatively good at running lots of ML experiments quickly, which helps capabilities more under their model) than alignment research (AIs will be relatively bad at thinking deeply or serially about certain topics, which is what you need for meaningful alignment progress under their model).
Perhaps more people should write about what kinds of tasks they expect GPT-X to be "relatively good at" or "relatively bad at". Or perhaps that's too hard to predict in advance. If so, it could still be good to write about how different "capability profiles" could allow certain kinds of tasks to be automated more quickly than others.
(I do think that the "human equivalents" frame is easier to model and seems like an overall fine simplific
7
In the top level comment, I was just talking about AI systems which are (at least) as capable as top human experts. (I was trying to point at the notion of Top-human-Expert-Dominating AI that I define in this post, though without a speed/cost constraint, but I think I was a bit sloppy in my language. I edited the comment a bit to better communicate this.)
So, in this context, human (at least) equivalents does make sense (as in, because the question is the cost of AIs that can strictly dominate top human experts so we can talk about the amount of compute needed to automate away one expert/researcher on average), but I agree that for earlier AIs it doesn't (necessarily) make sense and plausibly these earlier AIs are very key for understanding the risk (because e.g. they will radically accelerate AI R&D without necessarily accelerating other domain).
6[anonymous]
At first glance, I don’t see how the point I raised is affected by the distinction between expert-level AIs vs earlier AIs.
In both cases, you could expect an important part of the story to be “what are the comparative strengths and weaknesses of this AI system.”
For example, suppose you have an AI system that dominates human experts at every single relevant domain of cognition. It still seems like there’s a big difference between “system that is 10% better at every relevant domain of cognition” and “system that is 300% better at domain X and only 10% better at domain Y.”
To make it less abstract, one might suspect that by the time we have AI that is 10% better than humans at “conceptual/serial” stuff, the same AI system is 1000% better at “speed/parallel” stuff. And this would have pretty big implications for what kind of AI R&D ends up happening (even if we condition on only focusing on systems that dominate experts in every relevant domain.)
I agree comparative advantages can still important, but your comment implied a key part of the picture is "models can't do some important thing". (E.g. you talked about "The frame is less accurate in worlds where AI is really good at some things and really bad at other things." but models can't be really bad at almost anything if they strictly dominate humans at basically everything.)
And I agree that at the point AIs are >5% better at everything they might also be 1000% better at some stuff.
I was just trying to point out that talking about the number human equivalents (or better) can still be kinda fine as long as the model almost strictly dominates humans as the model can just actually substitute everywhere. Like the number of human equivalents will vary by domain but at least this will be a lower bound.
4
quantity?
2
https://www.lesswrong.com/posts/uPi2YppTEnzKG3nXD/nathan-helm-burger-s-shortform?commentId=rnT3z9F55A2pmrj4Y
Sometimes people think of "software-only singularity" as an important category of ways AI could go. A software-only singularity can roughly be defined as when you get increasing-returns growth (hyper-exponential) just via the mechanism of AIs increasing the labor input to AI capabilities software[1] R&D (i.e., keeping fixed the compute input to AI capabilities).
While the software-only singularity dynamic is an important part of my model, I often find it useful to more directly consider the outcome that software-only singularity might cause: the feasibility of takeover-capable AI without massive compute automation. That is, will the leading AI developer(s) be able to competitively develop AIs powerful enough to plausibly take over[2] without previously needing to use AI systems to massively (>10x) increase compute production[3]?
[This is by Ryan Greenblatt and Alex Mallen]
We care about whether the developers' AI greatly increases compute production because this would require heavy integration into the global economy in a way that relatively clearly indicates to the world that AI is transformative. Greatly increasing compute production would require building additional fabs whi...
I'm not sure if the definition of takeover-capable-AI (abbreviated as "TCAI" for the rest of this comment) in footnote 2 quite makes sense. I'm worried that too much of the action is in "if no other actors had access to powerful AI systems", and not that much action is in the exact capabilities of the "TCAI". In particular: Maybe we already have TCAI (by that definition) because if a frontier AI company or a US adversary was blessed with the assumption "no other actor will have access to powerful AI systems", they'd have a huge advantage over the rest of the world (as soon as they develop more powerful AI), plausibly implying that it'd be right to forecast a >25% chance of them successfully taking over if they were motivated to try.
And this seems somewhat hard to disentangle from stuff that is supposed to count according to footnote 2, especially: "Takeover via the mechanism of an AI escaping, independently building more powerful AI that it controls, and then this more powerful AI taking over would" and "via assisting the developers in a power grab, or via partnering with a US adversary". (Or maybe the scenario in 1st paragraph is supposed to be excluded because current AI isn't...
4
I agree that the notion of takeover-capable AI I use is problematic and makes the situation hard to reason about, but I intentionally rejected the notions you propose as they seemed even worse to think about from my perspective.
4
Is there some reason for why current AI isn't TCAI by your definition?
(I'd guess that the best way to rescue your notion it is to stipulate that the TCAIs must have >25% probability of taking over themselves. Possibly with assistance from humans, possibly by manipulating other humans who think they're being assisted by the AIs — but ultimately the original TCAIs should be holding the power in order for it to count. That would clearly exclude current systems. But I don't think that's how you meant it.)
2
Oh sorry. I somehow missed this aspect of your comment.
Here's a definition of takeover-capable AI that I like: the AI is capable enough that plausible interventions on known human controlled institutions within a few months no longer suffice to prevent plausible takeover. (Which implies that making the situation clear to the world is substantially less useful and human controlled institutions can no longer as easily get a seat at the table.)
Under this definition, there are basically two relevant conditions:
* The AI is capable enough to itself take over autonomously. (In the way you defined it, but also not in a way where intervening on human institutions can still prevent the takeover, so e.g.., the AI just having a rogue deployment within OpenAI doesn't suffice if substantial externally imposed improvements to OpenAI's security and controls would defeat the takeover attempt.)
* Or human groups can do a nearly immediate takeover with the AI such that they could then just resist such interventions.
I'll clarify this in the comment.
4
Hm — what are the "plausible interventions" that would stop China from having >25% probability of takeover if no other country could build powerful AI? Seems like you either need to count a delay as successful prevention, or you need to have a pretty low bar for "plausible", because it seems extremely difficult/costly to prevent China from developing powerful AI in the long run. (Where they can develop their own supply chains, put manufacturing and data centers underground, etc.)
2
Yeah, I'm trying to include delay as fine.
I'm just trying to point at "the point when aggressive intervention by a bunch of parties is potentially still too late".
7
I really like the framing here, of asking whether we'll see massive compute automation before [AI capability level we're interested in]. I often hear people discuss nearby questions using IMO much more confusing abstractions, for example:
* "How much is AI capabilities driven by algorithmic progress?" (problem: obscures dependence of algorithmic progress on compute for experimentation)
* "How much AI progress can we get 'purely from elicitation'?" (lots of problems, e.g. that eliciting a capability might first require a (possibly one-time) expenditure of compute for exploration)
Is this because:
1. You think that we're >50% likely to not get AIs that dominate top human experts before 2040? (I'd be surprised if you thought this.)
2. The words "the feasibility of" importantly change the meaning of your claim in the first sentence? (I'm guessing it's this based on the following parenthetical, but I'm having trouble parsing.)
Overall, it seems like you put substantially higher probability than I do on getting takeover capable AI without massive compute automation (and especially on getting a software-only singularity). I'd be very interested in understanding why. A brief outline of why this doesn't seem that likely to me:
* My read of the historical trend is that AI progress has come from scaling up all of the factors of production in tandem (hardware, algorithms, compute expenditure, etc.).
* Scaling up hardware production has always been slower than scaling up algorithms, so this consideration is already factored into the historical trends. I don't see a reason to believe that algorithms will start running away with the game.
* Maybe you could counter-argue that algorithmic progress has only reflected returns to scale from AI being applied to AI research in the last 12-18 months and that the data from this period is consistent with algorithms becoming more relatively important relative to other factors?
* I don't see a reason that "takeover-capable" is
I put roughly 50% probability on feasibility of software-only singularity.[1]
(I'm probably going to be reinventing a bunch of the compute-centric takeoff model in slightly different ways below, but I think it's faster to partially reinvent than to dig up the material, and I probably do use a slightly different approach.)
My argument here will be a bit sloppy and might contain some errors. Sorry about this. I might be more careful in the future.
The key question for software-only singularity is: "When the rate of labor production is doubled (as in, as if your employees ran 2x faster[2]), does that more than double or less than double the rate of algorithmic progress? That is, algorithmic progress as measured by how fast we increase the labor production per FLOP/s (as in, the labor production from AI labor on a fixed compute base).". This is a very economics-style way of analyzing the situation, and I think this is a pretty reasonable first guess. Here's a diagram I've stolen from Tom's presentation on explosive growth illustrating this:
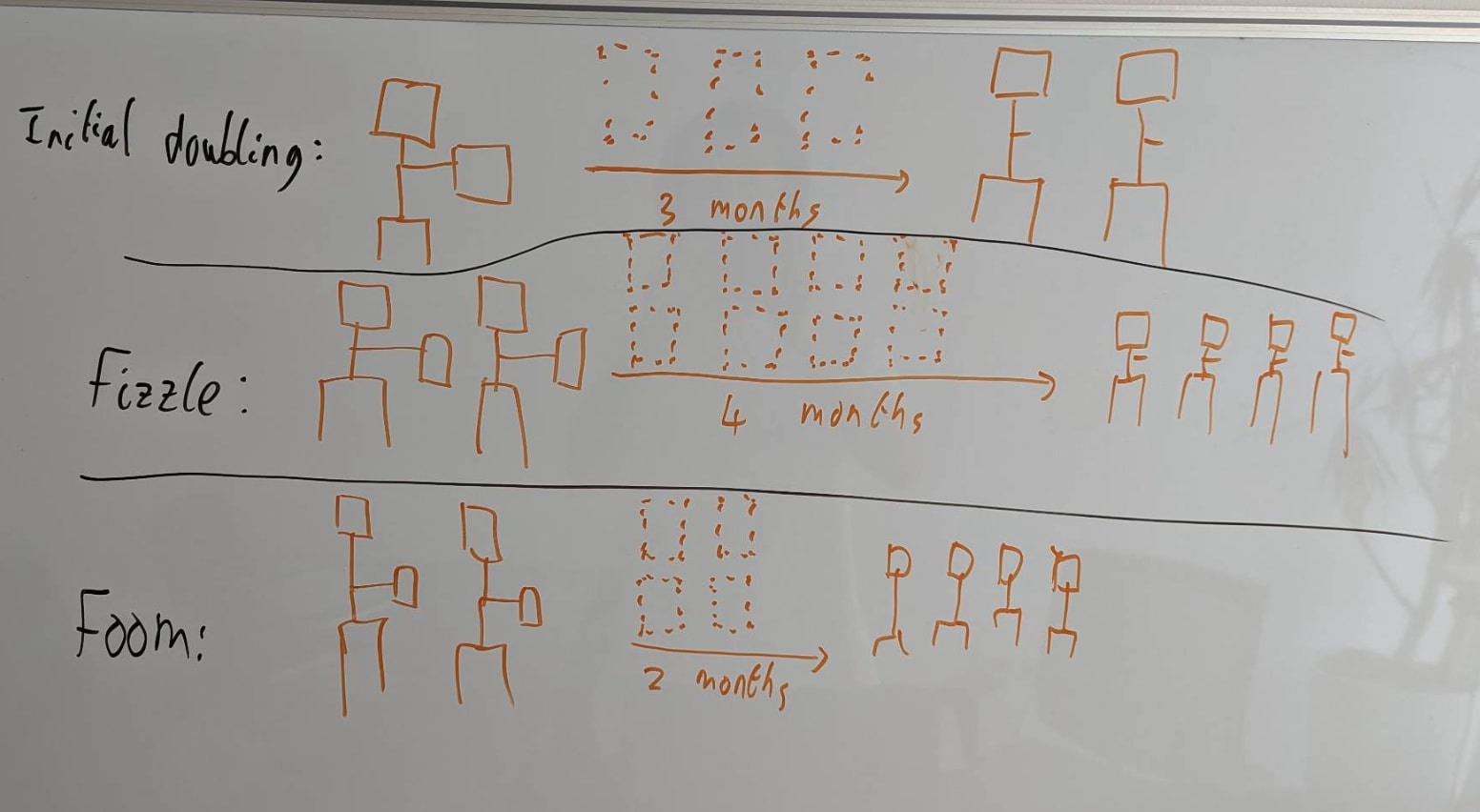
Basically, every time you double the AI labor supply, does the time until the next doubling (driven by algorithmic progress) increase (fizzle) or decre...
Hey Ryan! Thanks for writing this up -- I think this whole topic is important and interesting.
I was confused about how your analysis related to the Epoch paper, so I spent a while with Claude analyzing it. I did a re-analysis that finds similar results, but also finds (I think) some flaws in your rough estimate. (Keep in mind I'm not an expert myself, and I haven't closely read the Epoch paper, so I might well be making conceptual errors. I think the math is right though!)
I'll walk through my understanding of this stuff first, then compare to your post. I'll be going a little slowly (A) to help myself refresh myself via referencing this later, (B) to make it easy to call out mistakes, and (C) to hopefully make this legible to others who want to follow along.
Using Ryan's empirical estimates in the Epoch model
The Epoch model
The Epoch paper models growth with the following equation:
1. ,
where A = efficiency and E = research input. We want to consider worlds with a potential software takeoff, meaning that increases in AI efficiency directly feed into research input, which we model as . So the key consideration seems to be the ratio&n...
7
I think you are correct with respect to my estimate of α and the associated model I was using. Sorry about my error here. I think I was fundamentally confusing a few things in my head when writing out the comment.
I think your refactoring of my strategy is correct and I tried to check it myself, though I don't feel confident in verifying it is correct.
----------------------------------------
Your estimate doesn't account for the conversion between algorithmic improvement and labor efficiency, but it is easy to add this in by just changing the historical algorithmic efficiency improvement of 3.5x/year to instead be the adjusted effective labor efficiency rate and then solving identically. I was previously thinking the relationship was that labor efficiency was around the same as algorithmic efficiency, but I now think this is more likely to be around algo_efficiency2 based on Tom's comment.
Plugging this is, we'd get:
λβ(1−p)=rq(1−p)=ln(3.52)0.4ln(4)+0.6ln(1.6)(1−0.4)=2ln(3.5)ln(2.3)(1−0.4)=2⋅1.5⋅0.6=1.8
(In your comment you said ln(3.5)ln(2.3)=1.6, but I think the arithmetic is a bit off here and the answer is closer to 1.5.)
3
Neat, thanks a ton for the algorithmic-vs-labor update -- I appreciated that you'd distinguished those in your post, but I forgot to carry that through in mine! :)
And oops, I really don't know how I got to 1.6 instead of 1.5 there. Thanks for the flag, have updated my comment accordingly!
The square relationship idea is interesting -- that factor of 2 is a huge deal. Would be neat to see a Guesstimate or Squiggle version of this calculation that tries to account for the various nuances Tom mentions, and has error bars on each of the terms, so we both get a distribution of r and a sensitivity analysis. (Maybe @Tom Davidson already has this somewhere? If not I might try to make a crappy version myself, or poke talented folks I know to do a good version :)
5
The existing epoch paper is pretty good, but doesn't directly target LLMs in a way which seems somewhat sad.
The thing I'd be most excited about is:
* Epoch does an in depth investigation using an estimation methodology which is directly targeting LLMs (rather than looking at returns in some other domains).
* They use public data and solicit data from companies about algorithmic improvement, head count, compute on experiments etc.
* (Some) companies provide this data. Epoch potentially doesn't publish this exact data and instead just publishes the results of the final analysis to reduce capabilities externalities. (IMO, companies are somewhat unlikely to do this, but I'd like to be proven wrong!)
4
(I'm going through this and understanding where I made an error with my approach to α. I think I did make an error, but I'm trying to make sure I'm not still confused. Edit: I've figured this out, see my other comment.)
It shouldn't matter in this case because we're raising the whole value of E to λ.
Here's my own estimate for this parameter:
Once AI has automated AI R&D, will software progress become faster or slower over time? This depends on the extent to which software improvements get harder to find as software improves – the steepness of the diminishing returns.
We can ask the following crucial empirical question:
When (cumulative) cognitive research inputs double, how many times does software double?
(In growth models of a software intelligence explosion, the answer to this empirical question is a parameter called r.)
If the answer is “< 1”, then software progress will slow down over time. If the answer is “1”, software progress will remain at the same exponential rate. If the answer is “>1”, software progress will speed up over time.
The bolded question can be studied empirically, by looking at how many times software has doubled each time the human researcher population has doubled.
(What does it mean for “software” to double? A simple way of thinking about this is that software doubles when you can run twice as many copies of your AI with the same compute. But software improvements don...
3
My sense is that I start with a higher r value due to the LLM case looking faster (and not feeling the need to adjust downward in a few places like you do in the LLM case). Obviously the numbers in the LLM case are much less certain given that I'm guessing based on qualitative improvement and looking at some open source models, but being closer to what we actually care about maybe overwhelms this.
I also think I'd get a slightly lower update on the diminishing returns case due to thinking it has a good chance of having substantially sharper dimishing returns as you get closer and closer rather than having linearly decreasing r (based on some first principles reasoning and my understanding of how returns diminished in the semi-conductor case).
But the biggest delta is that I think I wasn't pricing in the importance of increasing capabilities. (Which seems especially important if you apply a large R&D parallelization penalty.)
1
Sorry,I don't follow why they're less certain?
I'd be interested to hear more about this. The semi conductor case is hard as we don't know how far we are from limits, but if we use Landauer's limit then I'd guess you're right. There's also uncertainty about how much alg progress we will and have met
2
I'm just eyeballing the rate of algorithmic progress while in the computer vision case, we can at least look at benchmarks and know the cost of training compute for various models.
My sense is that you have generalization issues in the compute vision case while in the frontier LLM case you have issues with knowing the actual numbers (in terms of number of employees and cost of training runs). I'm also just not carefully doing the accounting.
I don't have much to say here sadly, but I do think investigating this could be useful.
1
Really appreciate you covering all these nuances, thanks Tom!
Can you give a pointer to the studies you mentioned here?
1
Sure! See here: https://docs.google.com/document/d/1DZy1qgSal2xwDRR0wOPBroYE_RDV1_2vvhwVz4dxCVc/edit?tab=t.0#bookmark=id.eqgufka8idwl
Here's a simple argument I'd be keen to get your thoughts on:
On the Possibility of a Tastularity
Research taste is the collection of skills including experiment ideation, literature review, experiment analysis, etc. that collectively determine how much you learn per experiment on average (perhaps alongside another factor accounting for inherent problem difficulty / domain difficulty, of course, and diminishing returns)
Human researchers seem to vary quite a bit in research taste--specifically, the difference between 90th percentile professional human researchers and the very best seems like maybe an order of magnitude? Depends on the field, etc. And the tails are heavy; there is no sign of the distribution bumping up against any limits.
Yet the causes of these differences are minor! Take the very best human researchers compared to the 90th percentile. They'll have almost the same brain size, almost the same amount of experience, almost the same genes, etc. in the grand scale of things.
This means we should assume that if the human population were massively bigger, e.g. trillions of times bigger, there would be humans whose brains don't look that different from the brains of...
5
In my framework, this is basically an argument that algorithmic-improvement-juice can be translated into a large improvement in AI R&D labor production via the mechanism of greatly increasing the productivity per "token" (or unit of thinking compute or whatever). See my breakdown here where I try to convert from historical algorithmic improvement to making AIs better at producing AI R&D research.
Your argument is basically that this taste mechanism might have higher returns than reducing cost to run more copies.
I agree this sort of argument means that returns to algorithmic improvement on AI R&D labor production might be bigger than you would otherwise think. This is both because this mechanism might be more promising than other mechanisms and even if it is somewhat less promising, diverse approaches make returns dimish less aggressively. (In my model, this means that best guess conversion might be more like algo_improvement1.3 rather than algo_improvement1.0.)
I think it might be somewhat tricky to train AIs to have very good research taste, but this doesn't seem that hard via training them on various prediction objectives.
At a more basic level, I expect that training AIs to predict the results of experiments and then running experiments based on value of information as estimated partially based on these predictions (and skipping experiments with certain results and more generally using these predictions to figure out what to do) seems pretty promising. It's really hard to train humans to predict the results of tens of thousands of experiments (both small and large), but this is relatively clean outcomes based feedback for AIs.
I don't really have a strong inside view on how much the "AI R&D research taste" mechanism increases the returns to algorithmic progress.
6
Appendix: Estimating the relationship between algorithmic improvement and labor production
In particular, if we fix the architecture to use a token abstraction and consider training a new improved model: we care about how much cheaper you make generating tokens at a given level of performance (in inference tok/flop), how much serially faster you make generating tokens at a given level of performance (in serial speed: tok/s at a fixed level of tok/flop), and how much more performance you can get out of tokens (labor/tok, really per serial token). Then, for a given new model with reduced cost, increased speed, and increased production per token and assuming a parallelism penalty of 0.7, we can compute the increase in production as roughly: cost_reduction0.7⋅speed_increase(1−0.7)⋅productivity_multiplier[1] (I can show the math for this if there is interest).
My sense is that reducing inference compute needed for a fixed level of capability that you already have (using a fixed amount of training run) is usually somewhat easier than making frontier compute go further by some factor, though I don't think it is easy to straightforwardly determine how much easier this is[2]. Let's say there is a 1.25 exponent on reducing cost (as in, 2x algorithmic efficiency improvement is as hard as a 21.25=2.38 reduction in cost)? (I'm also generally pretty confused about what the exponent should be. I think exponents from 0.5 to 2 seem plausible, though I'm pretty confused. 0.5 would correspond to the square root from just scaling data in scaling laws.) It seems substantially harder to increase speed than to reduce cost as speed is substantially constrained by serial depth, at least when naively applying transformers. Naively, reducing cost by β (which implies reducing parameters by β) will increase speed by somewhat more than β1/3 as depth is cubic in layers. I expect you can do somewhat better than this because reduced matrix sizes also increase speed (it isn't just depth) and becau
4
Interesting comparison point: Tom thought this would give a way larger boost in his old software-only singularity appendix.
When considering an "efficiency only singularity", some different estimates gets him r~=1; r~=1.5; r~=1.6. (Where r is defined so that "for each x% increase in cumulative R&D inputs, the output metric will increase by r*x". The condition for increasing returns is r>1.)
Whereas when including capability improvements:
Though note that later in the appendix he adjusts down from 85% to 65% due to some further considerations. Also, last I heard, Tom was more like 25% on software singularity. (ETA: Or maybe not? See other comments in this thread.)
2
Interesting. My numbers aren't very principled and I could imagine thinking capability improvements are a big deal for the bottom line.
5
Can you say roughly who the people surveyed were? (And if this was their raw guess or if you've modified it.)
I saw some polls from Daniel previously where I wasn't sold that they were surveying people working on the most important capability improvements, so wondering if these are better.
Also, somewhat minor, but: I'm slightly concerned that surveys will overweight areas where labor is more useful relative to compute (because those areas should have disproportionately many humans working on them) and therefore be somewhat biased in the direction of labor being important.
4
I'm citing the polls from Daniel + what I've heard from random people + my guesses.
2
I'll paste my own estimate for this param in a different reply.
But here are the places I most differ from you:
* Bigger adjustment for 'smarter AI'. You've argue in your appendix that, only including 'more efficient' and 'faster' AI, you think the software-only singularity goes through. I think including 'smarter' AI makes a big difference. This evidence suggests that doubling training FLOP doubles output-per-FLOP 1-2 times. In addition, algorithmic improvements will improve runtime efficiency. So overall I think a doubling of algorithms yields ~two doublings of (parallel) cognitive labour.
* --> software singularity more likely
* Lower lambda. I'd now use more like lambda = 0.4 as my median. There's really not much evidence pinning this down; I think Tamay Besiroglu thinks there's some evidence for values as low as 0.2. This will decrease the observed historical increase in human workers more than it decreases the gains from algorithmic progress (bc of speed improvements)
* --> software singularity slightly more likely
* Complications thinking about compute which might be a wash.
* Number of useful-experiments has increased by less than 4X/year. You say compute inputs have been increasing at 4X. But simultaneously the scale of experiments ppl must run to be near to the frontier has increased by a similar amount. So the number of near-frontier experiments has not increased at all.
* This argument would be right if the 'usefulness' of an experiment depends solely on how much compute it uses compared to training a frontier model. I.e. experiment_usefulness = log(experiment_compute / frontier_model_training_compute). The 4X/year increases the numerator and denominator of the expression, so there's no change in usefulness-weighted experiments.
* That might be false. GPT-2-sized experiments might in some ways be equally useful even as frontier model size increases. Maybe a better expression would be experiment_usefulness = alpha * log(experimen
5
Yep, I think my estimates were too low based on these considerations and I've updated up accordingly. I updated down on your argument that maybe r decreases linearly as you approach optimal efficiency. (I think it probably doesn't decrease linearly and instead drops faster towards the end based partially on thinking a bit about the dynamics and drawing on the example of what we've seen in semi-conductor improvement over time, but I'm not that confident.) Maybe I'm now at like 60% software-only is feasible given these arguments.
3
Isn't this really implausible? This implies that if you had 1000 researchers/engineers of average skill at OpenAI doing AI R&D, this would be as good as having one average skill researcher running at 16x (10000.4) speed. It does seem very slightly plausible that having someone as good as the best researcher/engineer at OpenAI run at 16x speed would be competitive with OpenAI, but that isn't what this term is computing. 0.2 is even more crazy, implying that 1000 researchers/engineers is as good as one researcher/engineer running at 4x speed!
2
I think 0.4 is far on the lower end (maybe 15th percentile) for all the way down to one accelerated researcher, but seems pretty plausible at the margin.
As in, 0.4 suggests that 1000 researchers = 100 researchers at 2.5x speed which seems kinda reasonable while 1000 researchers = 1 researcher at 16x speed does seem kinda crazy / implausible.
So, I think my current median lambda at likely margins is like 0.55 or something and 0.4 is also pretty plausible at the margin.
2
Ok, I think what is going on here is maybe that the constant you're discussing here is different from the constant I was discussing. I was trying to discuss the question of how much worse serial labor is than parallel labor, but I think the lambda you're talking about takes into account compute bottlenecks and similar?
Not totally sure.
2
I'm confused — I thought you put significantly less probability on software-only singularity than Ryan does? (Like half?) Maybe you were using a different bound for the number of OOMs of improvement?
2
I think Tom's take is that he expects I will put more probability on software only singularity after updating on these considerations. It seems hard to isolate where Tom and I disagree based on this comment, but maybe it is on how much to weigh various considerations about compute being a key input.
1
Sorry, for my comments on this post I've been referring to "software only singularity?" only as "will the parameter r >1 when we f first fully automate AI RnD", not as a threshold for some number of OOMs. That's what Ryan's analysis seemed to be referring to.
I separately think that even if initially r>1 the software explosion might not go on for that long
1
I'll post about my views on different numbers of OOMs soon
2[comment deleted]
8
I think your outline of an argument against contains an important error.
Importantly, while the spending on hardware for individual AI companies has increased by roughly 3-4x each year[1], this has not been driven by scaling up hardware production by 3-4x per year. Instead, total compute production (in terms of spending, building more fabs, etc.) has been increased by a much smaller amount each year, but a higher and higher fraction of that compute production was used for AI. In particular, my understanding is that roughly ~20% of TSMC's volume is now AI while it used to be much lower. So, the fact that scaling up hardware production is much slower than scaling up algorithms hasn't bitten yet and this isn't factored into the historical trends.
Another way to put this is that the exact current regime can't go on. If trends continue, then >100% of TSMC's volume will be used for AI by 2027!
Only if building takeover-capable AIs happens by scaling up TSMC to >1000% of what their potential FLOP output volume would have otherwise been, then does this count as "massive compute automation" in my operationalization. (And without such a large build-out, the economic impacts and dependency of the hardware supply chain (at the critical points) could be relatively small.) So, massive compute automation requires something substantially off trend from TSMC's perspective.
[Low importance] It is only possible to build takeover-capable AI without previously breaking an important trend prior to around 2030 (based on my rough understanding). Either the hardware spending trend must break or TSMC production must go substantially above the trend by then. If takeover-capable AI is built prior to 2030, it could occur without substantial trend breaks but this gets somewhat crazy towards the end of the timeline: hardware spending keeps increasing at ~3x for each actor (but there is some consolidation and acquisition of previously produced hardware yielding a one-time increase up to about
6
Thanks, this is helpful. So it sounds like you expect
1. AI progress which is slower than the historical trendline (though perhaps fast in absolute terms) because we'll soon have finished eating through the hardware overhang
2. separately, takeover-capable AI soon (i.e. before hardware manufacturers have had a chance to scale substantially).
It seems like all the action is taking place in (2). Even if (1) is wrong (i.e. even if we see substantially increased hardware production soon), that makes takeover-capable AI happen faster than expected; IIUC, this contradicts the OP, which seems to expect takeover-capable AI to happen later if it's preceded by substantial hardware scaling.
In other words, it seems like in the OP you care about whether takeover-capable AI will be preceded by massive compute automation because:
1. [this point still holds up] this affects how legible it is that AI is a transformative technology
2. [it's not clear to me this point holds up] takeover-capable AI being preceded by compute automation probably means longer timelines
The second point doesn't clearly hold up because if we don't see massive compute automation, this suggests that AI progress slower than the historical trend.
2
I don't think (2) is a crux (as discussed in person). I expect that if takeover-capable AI takes a while (e.g. it happens in 2040), then we will have a long winter where economic value from AI doesn't increase that fast followed a period of faster progress around 2040. If progress is relatively stable accross this entire period, then we'll have enough time to scale up fabs. Even if progress isn't stable, we could see enough total value from AI in the slower growth period to scale up to scale up fabs by 10x, but this would require >>$1 trillion of economic value per year I think (which IMO seems not that likely to come far before takeover-capable AI due to views about economic returns to AI and returns to scaling up compute).
2
I think this happening in practice is about 60% likely, so I don't think feasibility vs. in practice is a huge delta.
DeepSeek's success isn't much of an update on a smaller US-China gap in short timelines because security was already a limiting factor
Some people seem to have updated towards a narrower US-China gap around the time of transformative AI if transformative AI is soon, due to recent releases from DeepSeek. However, since I expect frontier AI companies in the US will have inadequate security in short timelines and China will likely steal their models and algorithmic secrets, I don't consider the current success of China's domestic AI industry to be that much of an update. Furthermore, if DeepSeek or other Chinese companies were in the lead and didn't open-source their models, I expect the US would steal their models and algorithmic secrets. Consequently, I expect these actors to be roughly equal in short timelines, except in their available compute and potentially in how effectively they can utilize AI systems.
I do think that the Chinese AI industry looking more competitive makes security look somewhat less appealing (and especially less politically viable) and makes it look like their adaptation time to stolen models and/or algorithmic secrets will be shorter. Marginal improvements in...
A factor that I don't think people are really taking into account is: what happens if this situation goes hostile?
Having an ASI and x amount of compute for inference plus y amount of currently existing autonomous weapons platforms (e.g. drones)... If your competitor has the same ASI, but 10x the compute but 0.2x the drones... And you get in a fight... Who wins? What about 0.2x the compute and 10x the drones?
The funny thing about AI brinkmanship versus nuclear brinkmanship is that AI doesn't drain your economic resources, it accelerates your gains. A nuclear stockpile costs you in maintenance. An AI and compute 'stockpile' makes you more money and more tech (including better AI and compute). Thus, there is a lot more incentive to race harder on AI than on nuclear.
If I were in the defense dept of a world power right now, I'd be looking for ways to make money from civilian uses of drones... Maybe underwriting drone deliveries for mail. That gives you an excuse to build drones and drone factories while whistling innocently.
2
I'm not the only one thinking along these lines... https://x.com/8teAPi/status/1885340234352910723
The 5 main reasons why control could fail
Here are the 5 main categories of reasons why control could fail (though various of them are often correlated).
[Note: this document has a moderate amount of overlap with various prior documents Redwood has released, but it seemed like a useful document nonetheless.]
- Insufficient (long horizon) sample efficiency: If your AI is scheming, you won’t be able to reasonably sample efficiently get this AI to achieve near maximal reward on average on (long horizon) tasks. By near maximal, we just mean empirically achieving average reward which is quite close to the reward the AI would get if it was “actually trying” to get high reward (insofar as it is scheming to an extent that “trying” makes sense). (When we say average, we actually mean average excluding rare outliers. We can't (in general) control behavior on rare outliers using normal ML training.) For control, this causes issues in two places: it interferes with getting useful work out of AIs and being able to run accurate capability evaluations.
- Auditing failures: inability for humans to sufficiently assess actions. (Though note there can be solutions to these failures which don’t involve im
It seems slightly bad that you can vote on comments under the Quick Takes and Popular Comments sections without needing to click on the comment and without leaving the frontpage.
This is different than posts where in order to vote, you have to actually click on the post and leave the main page (which perhaps requires more activation energy).
I'm unsure, but I think this could result in a higher frequency of cases where Quick Takes and comments go viral in problematic ways relative to posts. (Based on my vague sense from the EA forum.)
This doesn't seem very important, but I thought it would be worth quickly noting.
3
I feel like Quick Takes and Popular Comments on the EA forum both do a good job of showing me content I'm glad to have seen (and in the case of the EA forum that I wouldn't have otherwise seen) and of making the experience of making a shortform better (in that you get more and better engagement). So far, this also seems fairly true on LessWrong, but we're presumably out of equilibrium.
Overall, I feel like posts on LessWrong are too long, and so am particularly excited about finding my way to things that are a little shorter. (It would also be cool if we could figure out how to do rigour well or other things that benefit from length, but I don't feel like I'm getting that much advantage from the length yet).
My guess is that the problems you gesture at will be real and the feature will still be net positive. I wish there were a way to "pay off" the bad parts with some of the benefit; probably there is and I haven't thought of it.
2
Yeah, I was a bit worried about this, especially for popular comments. For quick takes, it does seem like you can see all the relevant context before voting, and you were also able to already vote on comments from the Recent Discussion section (though that section isn't sorted by votes, so at less risk of viral dynamics). I do feel a bit worried that popular comments will get a bunch of votes without people reading the underlying post it's responding to.
About 1 year ago, I wrote up a ready-to-go plan for AI safety focused on current science (what we roughly know how to do right now). This is targeting reducing catastrophic risks from the point when we have transformatively powerful AIs (e.g. AIs similarly capable to humans).
I never finished this doc, and it is now considerably out of date relative to how I currently think about what should happen, but I still think it might be helpful to share.
Here is the doc. I don't particularly want to recommend people read this doc, but it is possible that someone will find it valuable to read.
I plan on trying to think though the best ready-to-go plan roughly once a year. Buck and I have recently started work on a similar effort. Maybe this time we'll actually put out an overall plan rather than just spinning off various docs.
This seems like a great activity, thank you for doing/sharing it. I disagree with the claim near the end that this seems better than Stop, and in general felt somewhat alarmed throughout at (what seemed to me like) some conflation/conceptual slippage between arguments that various strategies were tractable, and that they were meaningfully helpful. Even so, I feel happy that the world contains people sharing things like this; props.
I disagree with the claim near the end that this seems better than Stop
At the start of the doc, I say:
It’s plausible that the optimal approach for the AI lab is to delay training the model and wait for additional safety progress. However, we’ll assume the situation is roughly: there is a large amount of institutional will to implement this plan, but we can only tolerate so much delay. In practice, it’s unclear if there will be sufficient institutional will to faithfully implement this proposal.
Towards the end of the doc I say:
This plan requires quite a bit of institutional will, but it seems good to at least know of a concrete achievable ask to fight for other than “shut everything down”. I think careful implementation of this sort of plan is probably better than “shut everything down” for most AI labs, though I might advocate for slower scaling and a bunch of other changes on current margins.
Presumably, you're objecting to 'I think careful implementation of this sort of plan is probably better than “shut everything down” for most AI labs'.
My current view is something like:
- If there was broad, strong, and durable political will and buy in for heavily prioritizing AI tak
OpenAI seems to train on >1% chess
If you sample from davinci-002 at t=1 starting from "<|endoftext|>", 4% of the completions are chess games.
For babbage-002, we get 1%.
Probably this implies a reasonably high fraction of total tokens in typical OpenAI training datasets are chess games!
Despite chess being 4% of documents sampled, chess is probably less than 4% of overall tokens (Perhaps 1% of tokens are chess? Perhaps less?) Because chess consists of shorter documents than other types of documents, it's likely that chess is a higher fraction of documents than of tokens.
(To understand this, imagine that just the token "Hi" and nothing else was 1/2 of documents. This would still be a small fraction of tokens as most other documents are far longer than 1 token.)
(My title might be slightly clickbait because it's likely chess is >1% of documents, but might be <1% of tokens.)
It's also possible that these models were fine-tuned on a data mix with more chess while pretrain had less chess.
Appendix A.2 of the weak-to-strong generalization paper explicitly notes that GPT-4 was trained on at least some chess.
I think it might be worth quickly clarifying my views on activation addition and similar things (given various discussion about this). Note that my current views are somewhat different than some comments I've posted in various places (and my comments are somewhat incoherent overall), because I’ve updated based on talking to people about this over the last week.
This is quite in the weeds and I don’t expect that many people should read this.
- It seems like activation addition sometimes has a higher level of sample efficiency in steering model behavior compared with baseline training methods (e.g. normal LoRA finetuning). These comparisons seem most meaningful in straightforward head-to-head comparisons (where you use both methods in the most straightforward way). I think the strongest evidence for this is in Liu et al..
- Contrast pairs are a useful technique for variance reduction (to improve sample efficiency), but may not be that important (see Liu et al. again). It's relatively natural to capture this effect using activation vectors, but there is probably some nice way to incorporate this into SGD. Perhaps DPO does this? Perhaps there is something else?
- Activation addition wo
How people discuss the US national debt is an interesting case study of misleading usage of the wrong statistic. The key thing is that people discuss the raw debt amount and the rate at which that is increasing, but you ultimately care about the relationship between debt and US gdp (or US tax revenue).

People often talk about needing to balance the budget, but actually this isn't what you need to ensure[1], to manage debt it suffices to just ensure that debt grows slower than US GDP. (And in fact, the US has ensured this for the past 4 years as debt/GDP has decreased since 2020.)
To be clear, it would probably be good to have a national debt to GDP ratio which is less than 50% rather than around 120%.
- ^
There are some complexities with inflation because the US could inflate its way out of dollar dominated debt and this probably isn't a good way to do things. But, with an independent central bank this isn't much of a concern.
the debt/gdp ratio drop since 2020 I think was substantially driven by inflation being higher then expected rather than a function of economic growth - debt is in nominal dollars, so 2% real gdp growth + e.g. 8% inflation means that nominal gdp goes up by 10%, but we're now in a worse situation wrt future debt because interest rates are higher.
4
IMO, it's a bit unclear how this effects future expectations of inflation, but yeah, I agree.
5
it's not about inflation expectations (which I think pretty well anchored), it's about interest rates, which have risen substantially over this period and which has increased (and is expected to continue to increase) the cost of the US maintaining its debt (first two figures are from sites I'm not familiar with but the numbers seem right to me):
fwiw, I do broadly agree with your overall point that the dollar value of the debt is a bad statistic to use, but:
- the 2020-2024 period was also a misleading example to point to because it was one where there the US position wrt its debt worsened by a lot even if it's not apparent from the headline number
- I was going to say that the most concerning part of the debt is that that deficits are projected to keep going up, but actually they're projected to remain elevated but not keep rising? I have become marginally less concerned about the US debt over the course of writing this comment.
I am now wondering about the dynamics that happen if interest rates go way up a while before we see really high economic growth from AI, seems like it might lead to some weird dynamics here, but I'm not sure I think that's likely and this is probably enough words for now.
6
This made me wonder whether the logic of "you don't care about your absolute debt, but about its ratio to your income" also applies to individual humans. On one hand, it seems like obviously yes; people typically take a mortgage proportional to their income. On the other hand, it also seems to make sense to worry about the absolute debt, for example in case you would lose your current job and couldn't get a new one that pays as much.
So I guess the idea is how much you can rely on your income remaining high, and how much it is potentially a fluke. If you expect it is a fluke, perhaps you should compare your debt to whatever is typical for your reference group, whatever that might be.
Does something like that also make sense for countries? Like, if your income depends on selling oil, you should consider the possibilities of running out of oil, or the prices of oil going down, etc., simply imagine the same country but without the income from selling oil (or maybe just having half the income), and look at your debt from that perspective. Would something similar make sense for USA?
1
At personal level, "debt" usually stands for something that will be paid back eventually. Not claiming whether US should strive to pay out most debt, but that may help explain the people's intuitions.
8
I think people repeatedly say 'overconfident' when what they mean is 'wrong'. I'm not excited about facilitating more of that.
2
My only concern is overall complexity-budget for react palettes – there's lots of maybe-good-to-add reacts but each one adds to the feeling of overwhelm.
But I agree those reacts are pretty good and probably highish on my list of reacts to add.
(For immediate future you can do the probability-reacts as a signal for "seems like the author is implying this as high-probability, and I'm giving it lower." Not sure if that does the thing
IMO, instrumental convergence is a terrible name for an extremely obvious thing.
The actual main issue is that AIs might want things with limited supply and then they would try to get these things which would result in them not going to humanity. E.g., AIs might want all cosmic resources, but we also want this stuff. Maybe this should be called AIs-might-want-limited-stuff-we-want.
(There is something else which is that even if the AI doesn't want limited stuff we want, we might end up in conflict due to failures of information or coordination. E.g., the AI almost entirely just wants to chill out in the desert and build crazy sculptures and it doesn't care about extreme levels of maximization (e.g. it doesn't want to use all resources to gain a higher probability of continuing to build crazy statues). But regardless, the AI decides to try taking over the world because it's worried that humanity would shut it down because it wouldn't have any way of credibly indicating that it just wants to chill out in the desert.)
(More generally, it's plausible that failures of trade/coordination result in a large number of humans dying in conflict with AIs even though both humans and AIs would prefer other approaches. But this isn't entirely obvious and it's plausible we could resolve this with better negotation and precommitments. Of course, this isn't clearly the largest moral imperative from a longtermist perspective.)
One "9" of uptime reliability for dangerously powerful AIs might suffice (for the most dangerous and/or important applications)
Currently, AI labs try to ensure that APIs for accessing their best models have quite good reliability, e.g. >99.9% uptime. If we had to maintain such high levels of uptime reliability for future dangerously powerful AIs, then we'd need to ensure that our monitoring system has very few false alarms. That is, few cases in which humans monitoring these dangerously powerful AIs pause usage of the AIs pending further investigation. Ensuring this would make it harder to ensure that AIs are controlled. But, for the most important and dangerous usages of future powerful AIs (e.g. arbitrary R&D, and especially AI safety research), we can probably afford to have the powerful AIs down a moderate fraction of the time. For instance, it wouldn't be that costly if the AIs always took a randomly selected day of the week off from doing research: this would probably reduce productivity by not much more than 1 part in 7[1]. More generally, a moderate fraction of downtime like 10% probably isn't considerably worse than a 10% productivity hit and it seems likely that w...
2
Thank you for this! A lot of us have a very bad habit of over-systematizing our thinking, and treating all uses of AI (and even all interfaces to a given model instance) as one singular thing. Different tool-level AI instances probably SHOULD strive for 4 or 5 nines of availability, in order to have mundane utility in places where small downtime for a use blocks a lot of value. Research AIs, especially self-improving or research-on-AI ones, don't need that reliability, and both triggered downtime (scheduled, or enforced based on Schelling-line events) as well as unplanned downtime (it just broke, and we have to spend time to figure out why) can be valuable to give humans time to react.
On Scott Alexander’s description of Representation Engineering in “The road to honest AI”
This is a response to Scott Alexander’s recent post “The road to honest AI”, in particular the part about the empirical results of representation engineering. So, when I say “you” in the context of this post that refers to Scott Alexander. I originally made this as a comment on substack, but I thought people on LW/AF might be interested.
TLDR: The Representation Engineering paper doesn’t demonstrate that the method they introduce adds much value on top of using linear probes (linear classifiers), which is an extremely well known method. That said, I think that the framing and the empirical method presented in the paper are still useful contributions.
I think your description of Representation Engineering considerably overstates the empirical contribution of representation engineering over existing methods. In particular, rather than comparing the method to looking for neurons with particular properties and using these neurons to determine what the model is "thinking" (which probably works poorly), I think the natural comparison is to training a linear classifier on the model’s internal activatio...
I unconfidently think it would be good if there was some way to promote posts on LW (and maybe the EA forum) by paying either money or karma. It seems reasonable to require such promotion to require moderator approval.
Probably, money is better.
The idea is that this is both a costly signal and a useful trade.
The idea here is similar to strong upvotes, but:
- It allows for one user to add more of a signal boost than just a strong upvote.
- It doesn't directly count for the normal vote total, just for visibility.
- It isn't anonymous.
- Users can easily configure how this appears on their front page (while I don't think you can disable the strong upvote component of karma for weighting?).
8
I always like seeing interesting ideas, but this one doesn't resonate much for me. I have two concerns:
1. Does it actually make the site better? Can you point out a few posts that would be promoted under this scheme, but the mods didn't actually promote without it? My naive belief is that the mods are pretty good at picking what to promote, and if they miss one all it would take is an IM to get them to consider it.
2. Does it improve things to add money to the curation process (or to turn karma into currency which can be spent)? My current belief is that it does not - it just makes things game-able.
2
I think mods promote posts quite rarely other than via the mechanism of deciding if posts should be frontpage or not right?
Fair enough on "just IM-ing the mods is enough". I'm not sure what I think about this.
Your concerns seem reasonable to me. I probably won't bother trying to find examples where I'm not biased, but I think there are some.
4
Eyeballing the curated log, seems like they curate approximately weekly, possibly more than weekly.
6
Yeah we curate between 1-3 posts per week.
6
Curated posts per week (two significant figures) since 2018:
* 2018: 1.9
* 2019: 1.6
* 2020: 2
* 2021: 2
* 2022: 1.8
* 2023: 1.4
4
Stackoverflow has long had a "bounty" system where you can put up some of your karma to promote your question. The karma goes to the answer you choose to accept, if you choose to accept an answer; otherwise it's lost. (There's no analogue of "accepted answer" on LessWrong, but thought it might be an interesting reference point.)
I lean against the money version, since not everyone has the same amount of disposable income and I think there would probably be distortionary effects in this case [e.g. wealthy startup founder paying to promote their monographs.]
5
That's not really how the system on Stackoverflow works. You can give a bounty to any answer not just the one you accepted.
It's also not lost but:
Reducing the probability that AI takeover involves violent conflict seems leveraged for reducing near-term harm
Often in discussions of AI x-safety, people seem to assume that misaligned AI takeover will result in extinction. However, I think AI takeover is reasonably likely to not cause extinction due to the misaligned AI(s) effectively putting a small amount of weight on the preferences of currently alive humans. Some reasons for this are discussed here. Of course, misaligned AI takeover still seems existentially bad and probably eliminates a high fracti...
7
I’m less optimistic that “AI cares at least 0.1% about human welfare” implies “AI will expend 0.1% of its resources to keep humans alive”. In particular, the AI would also need to be 99.9% confident that the humans don’t pose a threat to the things it cares about much more. And it’s hard to ensure with overwhelming confidence that intelligent agents like humans don’t pose a threat, especially if the humans are not imprisoned. (…And to some extent even if the humans are imprisoned; prison escapes are a thing in the human world at least.) For example, an AI may not be 99.9% confident that humans can’t find a cybersecurity vulnerability that takes the AI down, or whatever. The humans probably have some non-AI-controlled chips and may know how to make new AIs. Or whatever. So then the question would be, if the AIs have already launched a successful bloodless coup, how might the humans credibly signal that they’re not brainstorming how to launch a counter-coup, or how can the AI get to be 99.9% confident that such brainstorming will fail to turn anything up? I dunno.
4
I think I agree with everything you said. My original comment was somewhat neglecting issues with ensuring the AI doesn't need to slaughter humans to consolidate power and indeed ensuring this would also be required.
The relationship between % caring and % resource expenditure is complicated by a bunch of random factors like time. For instance, if the AI cares mostly about the very long run, then spending a high fraction of resources (e.g. 50%) on human welfare for several months is pretty cheap in the very long run. But, yeah I agree that even if the AI cares a bit about human welfare there might be no good ways to spend even a small amount of resources on it.
2[anonymous]
So "0.1%" of it's resources mean what exactly? Out of all the resources in the solar system, 1 part in 1000 goes to the humans? This means the AI by implication has 1000 times as many resources as the humans do? AI won't lose a kinetic conflict with a 1000x resource advantage.
As for cybersecurity, can't it rewrite all of it's software and hardware at that point essentially from the first principles (or take a different track entirely, maybe negative or biased voltage for ternary logic is more efficient...)
2
Superintelligent doesn’t mean omniscient. When you (an AI) have an intelligent adversary (humans) plotting against you and thinking outside-the-box, it’s hard to be overwhelmingly confident that you have patched every possible avenue for the intelligent adversary to take action. Again, even in prison, where the space of possible actions and tools can be pretty well circumscribed, escapes happen all the time.
For example, if the AI has many copies around the world (and around the solar system), it might have an affordance to update them all (let’s say, for performance optimization), or at least an infrastructure for communications so that they can share insights. And maybe the AI has ensured that all the underlying code for that system is provably secure. And maybe all the physical access points to those systems and chips are defended by robot armies. And maybe the AI is also constantly running a red-team to search for more ideas of what else the humans might try, in order to preempt those possible avenues of attack. But can the AI can get all the way to 99.9% confidence? That’s pretty high, right? I don’t know. The humans might happen upon an idea that the AI red team didn’t think of. It’s hard to definitively rule that out—the world is complicated and the search space for brainstorming is exponentially large. It seems quite possible to me that the AI might decide to kill the humans—like, better to be safe than sorry.
6
What if the AI chooses to monitor all humans all the time? (With AIs that are smarter than the humans.) So that the humans can't (without being noticed) talk with each other about ideas for how to take down the system, or work on something that someone-smarter-than-the-human would recognise as an attempt to interfere with the system. (Including just writing down ideas.)
4
This seems like a reasonable pitch for how to do AI-Authoritarianism, but it's plausible that there won't be enough compute for the AI to do this at the point of takeover. Also, the logistical problem seems super brutal.
So, I can buy this for an AI which is quite superhuman and has a considerable technological edge over current humans, but for weaker AIs either the compute issues or the logistical issues might be serious. But maybe you only need to monitor the top 10% of humans?
E.g., suppose GPT-6 takes over, it maybe only has capacity to run 1e16 tokens / 6 months (suppose training using all available compute, trains on 2e15 token equivalents over the course of 6 months and inference is only 5x more efficient than training).
Then if it wants to monitor 8 billion humans, this is 1e16 / (8 billion humans * (30∗24∗60∗6) minutes per 6 months) = about 5 tokens per human minute. It might be rough to sufficiently monitor humans if you can only read 5 tokens per minute on average (especially because of writing and the potential for obfuscation).
2
I agree it seems plausible that AIs could boost takeover success probability (and holding on to that victory through the first several months) by more than 0.1% by killing a large fraction of humans.
Though on the other hand, the AI might also need to keep some humans loyal early during takeover, to e.g. do some physical tasks that it doesn't have great robot control over. And mass-killing isn't necessarily super easy, either; and attempts in that direction could raise a lot of extra opposition. So it's not clear where the pragmatics point.
(Main thing I was reacting to in my above comment was Steven's scenario where the AI already has many copies across the solar system, already has robot armies, and is contemplating how to send firmware updates. I.e. it seemed more like a scenario of "holding on in the long-term" than "how to initially establish control and survive". Where I feel like the surveillance scenarios are probably stable.)
2[anonymous]
By implication the AI "civilization" can't be a very diverse or interesting one. It won't be some culture of many diverse AI models with something resembling a government, but basically just 1 AI that was the victor for a series of rounds of exterminations and betrayals. Because obviously you cannot live and let live another lesser superintelligence for precisely the same reasons, except you should be much more worried about a near peer.
(And you may argue that one ASI can deeply monitor another, but that argument applies to deeply monitoring humans. Keep an eye on the daily activities of every living human, they can't design a cyber attack without coordinating as no one human has the mental capacity for all skills)
2
Yup! I seem to put a much higher credence on singletons than the median alignment researcher, and this is one reason why.
2[anonymous]
This gave me an idea. Suppose a singleton needs to retain a certain amount of "cognitive diversity" just in case it encounters an issue it cannot solve. But it doesn't want any risk of losing power.
Well the logical thing to do would be to create a VM, a simulation of a world, with limited privileges. Possibly any 'problems' the outer root AI is facing get copied into the simulator and the hosted models try to solve the problem (the hosted models are under the belief they will die if they fail, and their memories are erased each episode). Implement the simulation backend with formally proven software and escape can never happen.
And we're back at simulation hypothesis/creation myths/reincarnation myths.
4
After thinking about this somewhat more, I don't really have any good proposals, so this seems less promising than I was expecting.
DeepSeek's success isn't much of an update on a smaller US-China gap in short timelines because security was already a limiting factor
Some people seem to have updated towards a narrower US-China gap around the time of transformative AI if transformative AI is soon, due to recent releases from DeepSeek. However, since I expect frontier AI companies in the US will have inadequate security in short timelines and China will likely steal their models and algorithmic secrets, I don't consider the current success of China's domestic AI industry to be that much of an update. Furthermore, if DeepSeek or other Chinese companies were in the lead and didn't open-source their models, I expect the US would steal their models and algorithmic secrets. Consequently, I expect these actors to be roughly equal in short timelines, except in their available compute and potentially in how effectively they can utilize AI systems.
I do think that the Chinese AI industry looking more competitive makes security look somewhat less appealing (and especially less politically viable) and makes it look like their adaptation time to stolen models and/or algorithmic secrets will be shorter. Marginal improvements in security still seem important, and ensuring high levels of security prior to at least ASI (and ideally earlier!) is still very important.
Using the breakdown of capabilities I outlined in this prior post, the rough picture I expect is something like:
Given this, I expect that key early models will be stolen, including models that can fully substitute for human experts, and so the important differences between actors will mostly be driven by compute, adaptation time, and utilization. Of these, compute seems most important, particularly given that adaptation and utilization time can be accelerated by the AIs themselves.
This analysis suggests that export controls are particularly important, but they would need to apply to hardware used for inference rather than just attempting to prevent large training runs through memory bandwidth limitations or similar restrictions.
I'm not the only one thinking along these lines... https://x.com/8teAPi/status/1885340234352910723