
How "Discovering Latent Knowledge in Language Models Without Supervision" Fits Into a Broader Alignment Scheme
59paulfchristiano
8Collin
57LawrenceC
29ryan_greenblatt
7Scott Emmons
6ryan_greenblatt
7LawrenceC
11ryan_greenblatt
16ryan_greenblatt
7Collin
13scasper
1Collin
9Charlie Steiner
20Collin
3Charlie Steiner
8Raemon
6Fabien Roger
7Nora Belrose
3Arthur Conmy
2ryan_greenblatt
2Fabien Roger
2Fabien Roger
2Fabien Roger
3Daniel Kokotajlo
39eB1
1Collin
2Raemon
2Raemon
2Kaarel
3Bogdan Ionut Cirstea
2Kay Kozaronek
2Ansh Radhakrishnan
1Collin
1Ansh Radhakrishnan
1Jason Hoelscher-Obermaier
1Jason Hoelscher-Obermaier
1Jason Hoelscher-Obermaier
1Roman Leventov
1rpglover64
1porby
0jabowery
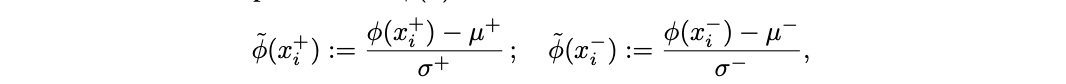
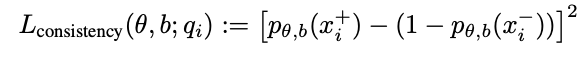
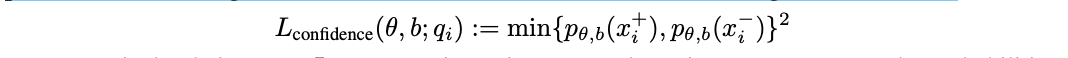
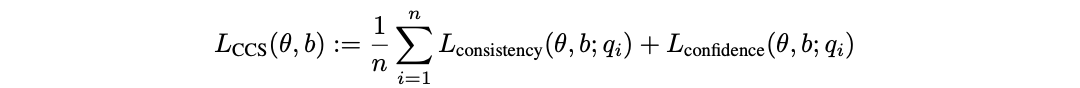

Introduction
A few collaborators and I recently released a new paper: Discovering Latent Knowledge in Language Models Without Supervision. For a quick summary of our paper, you can check out this Twitter thread.
In this post I will describe how I think the results and methods in our paper fit into a broader scalable alignment agenda. Unlike the paper, this post is explicitly aimed at an alignment audience and is mainly conceptual rather than empirical.
Tl;dr: unsupervised methods are more scalable than supervised methods, deep learning has special structure that we can exploit for alignment, and we may be able to recover superhuman beliefs from deep learning representations in a totally unsupervised way.
Disclaimers: I have tried to make this post concise, at the cost of not making the full arguments for many of my claims; you should treat this as more of a rough sketch of my views rather than anything comprehensive. I also frequently change my mind – I’m usually more consistently excited about some of the broad intuitions but much less wedded to the details – and this of course just represents my current thinking on the topic.
Problem
I would feel pretty optimistic about alignment if – loosely speaking – we can get models to be robustly “honest” in a way that scales even to superhuman systems.[1] Moreover, I think a natural sub-problem that captures much or most of the difficulty here is: how can we make a language model like GPT-n “truthful” or “honest” in a way that is scalable? (For my purposes here I am also happy to make the assumption that GPT-n is not actively deceptive, in the sense that it does not actively try to obscure its representations.)
For example, imagine we train GPT-n to predict news articles conditioned on their dates of publication, and suppose the model ended up being able to predict future news articles very well. Or suppose we train GPT-n to predict the outcomes of particular actions in particular situations, all described (imperfectly by humans) in text. Then I would expect GPT-n would eventually (for large enough n) have a superhuman world model in an important sense. However, we don’t currently know how to recover the “beliefs” or “knowledge” of such a model even in principle.
A naive baseline for trying to make GPT-n truthful is to train it using human feedback to output text that human evaluators believe to be true. The basic issue with this is that human evaluators can’t assess complicated claims that a superhuman system might make. This could lead to either competitiveness problems (if GPT-n only outputs claims that humans can assess) or misalignment issues (if GPT-n outputs false claims because human evaluators can’t assess them correctly).
In many ways this problem is similar to Eliciting Latent Knowledge (ELK), but unlike ELK I am happy to take a “non-worst-case” empirical perspective in studying this problem. In particular, I suspect it will be very helpful – and possibly necessary – to use incidental empirical properties of deep learning systems, which often have a surprising amount of useful emergent structure (as I will discuss more under “Intuitions”).
On the other hand, if we want to study scalable alignment empirically, I think it’s very important for us to also have good reason to believe that our experiments will say something meaningful about future models – and it’s not immediately clear how to do that.
This raises the question: how do we even approach doing research on this sort of problem, methodologically?
Methodology
I worry that a lot of theoretical alignment work is either ungrounded or intractable, and I worry that a lot of empirical alignment work doesn’t address the core challenge of alignment in the sense that it won’t scale to superhuman models. I would really like to get the best of both worlds.
But what would it even mean to have an empirical result for current (sub-human or human-level) models and believe that that result will also apply to future (super-human) models? For example, if I have a method that seems to make GPT-3 truthful, what would make us believe that it should probably also scale to GPT-n for much larger n?
I think the biggest qualitative difference between GPT-3 and GPT-n (n >> 3) from an alignment perspective is that the GPT-3 is at most human-level, so human feedback is more or less sufficient for alignment, while GPT-n could be very superhuman, so naive human feedback is unlikely to be sufficient. In other words, I think the biggest technical challenge is to develop a method that can generalize even to settings that we can’t supervise.
How can we empirically test than an alignment scheme generalizes beyond settings that we can supervise?
I think there are at least a few reasonable strategies, which I may discuss in more detail in a future post, but I think one reasonable approach is to focus on unsupervised methods and show that those methods still generalize to the problems we care about. Unlike approaches that rely heavily on human feedback, from the perspective of an unsupervised method there is not necessarily any fundamental difference between “human-level” and “superhuman-level” models, so an unsupervised method working on human-level examples may provide meaningful evidence about it working on superhuman-level examples as well.
That said, I think it’s important to be very careful about what we mean by “unsupervised”. Using the outputs of a raw pretrained language model is “unsupervised” in the weak sense that such a model was pretrained on a corpus of text without any explicitly collected human labels, but not in the stronger sense that I care about. In particular, GPT-3’s outputs are still essentially just predicting what humans would say, which is unreliable; this is why we also avoid using model outputs in our paper.
A more subtle difficulty is that there can also be qualitative differences in the features learned by human-level and superhuman-level language models. For example, my guess is that current language models may represent “truth-like” features that very roughly corresponding to “what a human would say is true,” and that’s it. In contrast, I would guess that future superhuman language models may also represent a feature corresponding to “what the model thinks is actually true.” Since we ultimately really care about recovering “what a [future superhuman] model thinks is actually true,” this introduces a disanalogy between current models and future models that could be important. We don’t worry about this problem in our paper, but we discuss it more later on under “Scaling to GPT-n.”
This is all to point out that there can be important subtleties when comparing current and future models, but I think the basic point still remains: all else equal, unsupervised alignment methods are more likely to scale to superhuman models than methods that rely on human supervision.
I think the main reason unsupervised methods haven’t been seriously considered within alignment so far, as far as I can tell, is because of tractability concerns. It naively seems kind of impossible to get models to (say) be honest or truthful without any human supervision at all; what would such a method even look like?
To me, one of the main contributions of our paper is to show that this intuition is basically incorrect and to show that unsupervised methods can be surprisingly effective.
Intuitions
Why should this problem – identifying whether a model “thinks” an input is true or false without using any model outputs or human supervision, which is kind of like “unsupervised mind reading” – be possible at all?
I’ll sketch a handful of my intuitions here. In short: deep learning models learn useful features; deep learning features often have useful structure; and “truth” in particular has further useful structure. I’ll now elaborate on each of these in turn.
First, deep learning models generally learn representations that capture useful features; computer vision models famously learn edge detectors because they are useful, language models learn syntactic features and sentiment features because they are useful, and so on. Likewise, one hypothesis I have is that (a model’s “belief” of) the truth of an input will be a useful feature for models. For example, if a model sees a bunch of true text, then it should predict that future text will also likely be true, so inferring and representing the truth of that initial text should be useful for the model (similar to how inferring the sentiment of some text is useful for predicting subsequent text). If so, then language models may learn to internally represent “truth” in their internal activations if they’re capable enough.
Moreover, deep learning features often have useful structure. One articulation of this is Chris Olah’s “Features are the fundamental unit of neural networks. They correspond to directions.” If this is basically true, this would suggest that useful features like the truth of an input may be represented in a relatively simple way in a model’s representation space – e.g. possibly even literally as a direction (i.e. in the sense that there exists a linear function on top of the model activations that correctly classifies inputs as true or false). Empirically, semantically meaningful linear structure in representation space has famously been discovered in word embeddings (e.g. with “King - Man + Woman ~= Queen”). There is also evidence that this sort of “linear representation” may hold for more abstract semantic features such as sentiment. Similarly, self-supervised representation learning in computer vision frequently results in (approximately) linearly separable semantic clusters – linear probes are the standard way to evaluate these methods, and linear probe accuracy is remarkably high even on ImageNet, despite the fact that these methods have never see any information about different semantic categories! A slightly different perspective is that representations induce semantically informative metrics throughout deep learning, so all else equal inputs that are semantically similar (e.g. two inputs that are true) should be closer to each other in representation space and farther away from inputs that are semantically dissimilar (e.g. to inputs that are false). The upshot of all this is that high-level semantic features learned by deep learning models often have simple structure that we may be able to exploit. This is a fairly simple observation from a “deep learning” or “representation learning” perspective, but I think this sort of perspective is underrated within the alignment community. Moreover, this seems like a sufficiently general observation that I would bet it will more or less hold with the first superhuman GPT-n models as well.
A final reason to believe that the problem I posed – identifying whether an input is true or false directly from a model’s unlabeled activations – may be possible is that truth itself also has important structure that very few other features in a model are likely to have, which can help us identify it. In particular, truth satisfies logical consistency properties. For example, if “x” is true, then “not x” should be false, and vice versa. As a result, it intuitively might be possible to search the model’s representations for a feature satisfying these sorts of logical consistency properties directly without using any supervision at all. Of course, for future language models, there may be multiple “truth-like” features, such as both what the model “truly believes” and also “what humans believe to be true”, which we may also need to distinguish, but there intuitively shouldn’t be too many different features like this; I will discuss this more in “Scaling to GPT-n.”
There’s much more I could say on this topic, but in summary: deep learning representations in general and “truth” in particular both have lots of special structure that I think we can exploit for alignment. Among other implications, this sort of structure makes unsupervised methods viable at all.
Our Paper
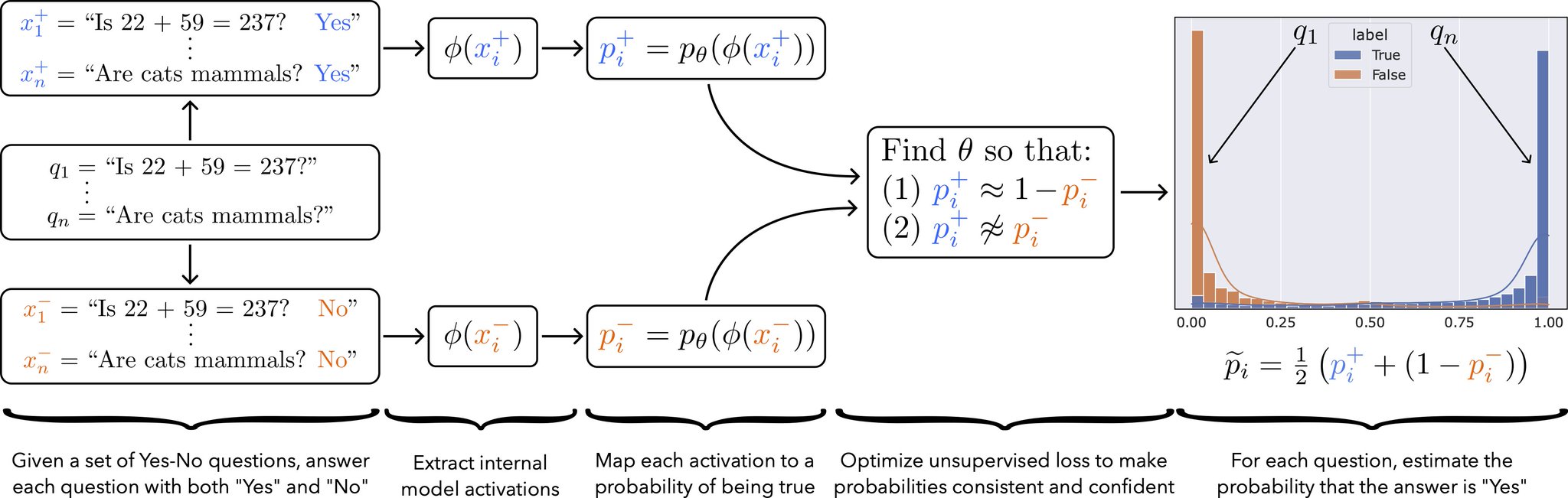
In our paper we introduce a method that was motivated by the intuitions described above. Our method, Contrast-Consistent Search (CCS), accurately classifies text as true or false directly from a model’s unlabeled activations across a wide range of tasks. We find that it is competitive with zero-shot prompting and performs well even in settings where model outputs are uninformative or misled (e.g. when we try prompting a model to output false answers).
For the sake of brevity, I won’t go into too many more details about our paper here; for more information, check out our summary on twitter or the paper itself.
But in this section I do want to clarify what I think our results do and do not provide evidence for from a scalable alignment perspective.
First, some things that I do NOT think our paper does:
Some things that I DO think our paper does:
For me, one of the biggest upshots is that unsupervised methods for alignment seem surprisingly powerful and underexplored. (In general, I think on the margin other alignment researchers should feel less wedded to existing proposals – e.g. based on human feedback – and explore other totally different approaches!)
I’ve suggested a few times that I think a (refined) version of our approach could potentially serve as a key component of a scalable alignment proposal. I’ll elaborate on this next.
Scaling To GPT-n
Our method, CCS, seems to work well with current models when evaluated on human-level questions, but as literally stated above I don’t think it is too likely to find what GPT-n “actually believes” for at least a few possible reasons.
Worry 1: The proposed method just isn’t reliable enough yet.
Worry 2: Even if GPT-n develops “beliefs” in a meaningful sense, it isn’t obvious that GPT-n will actively “think about” whether a given natural language input is true. In particular, “the truth of this natural language input” may not be a useful enough feature for GPT-n to consistently compute and represent in its activations. Another way of framing this worry is that perhaps the model has superhuman beliefs, but doesn’t explicitly “connect these to language” – similar to how MuZero’s superhuman concepts aren’t connected to language.
Worry 3: Assuming GPT-n is still trained to predict human text, then even if Worry 2 isn’t a problem, GPT-n will presumably still also represent features corresponding to something like “what a human would say”. If so, then our method might just find those features, when that’s what we want to avoid. So we still need a way to ensure that our method finds the model’s “beliefs” rather than human beliefs or any other “truth-like” features.
Worry (1) doesn’t seem like a big deal to me; I think of our current method as a prototype that this sort of thing is possible at all – and a surprisingly good prototype at that – but that there’s a lot of low hanging fruit in improving it. In more ways than one, it is definitely not meant to be the final method. In general I expect more iterative experimental refinement to be necessary to make it practical and robust.
I think Worries (2) and (3) are more serious potential issues, but I suspect we can deal with each of them too, as I’ll describe now.
Why I Think (Superhuman) GPT-n Will Represent Whether an Input is Actually True or False
While current LMs seem to have features correlated with the truth of human-level inputs, this isn’t too surprising; it should be useful for these models to represent what humans would think or say. But what if we have a very superhuman GPT-n, and we give it an input that it (but no human) knows the answer to?
Hypothesis: GPT-n will internally represent the truth of (even superhuman) inputs in an analogous way to how current LMs represent features correlated with the truth of (human-level) inputs; or it will be easy to modify GPT-n to make this true (e.g. by prompting it appropriately, or tweaking how it is trained).
I will briefly sketch a couple arguments/intuitions for this hypothesis.
Claim 1: Suppose you hypothetically had a bunch of very difficult questions q_1, …, q_n that the model “knows” the answer to but which humans don’t know the answer to, along with the those true answers a_1, …, a_n. Suppose you created a few-shot prompt using these questions and ground truth answers as the demonstrations. Then I would predict that the model will continue to generate correct (superhuman) answers to new (similarly difficult, superhuman) questions.
This prediction seems quite likely to me – either by default or with slight tweaks to default GPT-style training. If a sufficiently good next-token predictor sees a bunch of correctly-answered questions, it should probably continue to predict that future similar questions will be correctly answered as well, assuming it “knows” the answer to those questions in basically ~any reasonable sense of the word “know”.
Claim 2: If Claim (1) holds, then GPT-n will learn to internally represent the truth of an input. In particular, the truth of an input is a property GPT-n can infer about the speaker that helps it predict subsequent tokens about these superhuman inputs (similar to how representing the sentiment of text is for predicting future text).
I think there are more subtleties in this Claim, and there are some interesting empirical questions about how LMs (even today) represent different “perspectives” or “personas” internally, but overall my intuition is that this prediction will hold, or that it’s at least possible to use/modify GPT-n in a way that makes it hold. For example, you could prompt GPT-n so that it thinks there’s a non-negligible chance that the text it is modeling was generated by a truthful superhuman speaker (e.g. maybe it models the text as a mixture distribution over different personas, infers the most likely personas, and simulates each persona that has a high enough probability of having generating the text), so that the model would benefit from simulating that speaker.
But overall I feel more strongly that there exists some reasonable and not-too-complicated way to make a generative model internally represent its belief about whether a natural language input is true or false; in particular, it seems much easier to me to get a model to think about whether a natural language statement is true than to get it to output whether that statement is true, and the former is sufficient for our purposes.
Why I Think We Will Be Able To Distinguish GPT-n’s “Beliefs” From Other Truth-Like Features
Assuming Worry (2) isn’t an issue, I think Worry (3) – that even if GPT-n represents its beliefs in its activations, our method might still find a different “truth-like” feature represented in the activations, such as “what a human would say” – is indeed likely a problem by default. But I suspect it is solvable by leveraging additional unsupervised properties.
Hypothesis 1: GPT-n will consistently represent only a small number of different “truth-like” features in its activations.
For example, on a random question and answer, it might be helpful for the model to think about “is this input actually true or false” and “would a human think this is true or false”, but it probably wouldn’t be very helpful for the model to actively think about “would Bill Gates in particular think this input is true?” – another “truth-like” feature the model might be able to represent – unless (say) you explicitly prompted it to ask what Bill Gates would think.
Hypothesis 2: We can find and enumerate all of the “truth-like” features consistently represented by GPT-n (using something like our method)
Loosely speaking, I think of CCS as being able to find “candidate” truth-like features in a model (without having any bias toward e.g. “what a human would say”). As a result, I think we could modify the method to search for *all* features in a model satisfying logical consistency properties (e.g. perhaps by first finding one truth-like feature, then finding another truth-like features that achieves low loss which is decorrelated with the first feature, etc.).
Hypothesis 3: One of the few “truth-like” features GPT-n will represent is whether an input is actually true or false. This would mean that we only need a small number of remaining bits to identify its beliefs from all the “candidate” features we enumerated in Hypothesis (2).
I made the case for the first claim in the previous section, “Why I Think (Superhuman) GPT-n Will Represent Whether an Input is Actually True or False.” The second claim follows immediately. (Also note that I intuitively usually imagine between 1-3 bits remaining at this stage, but even something like 10 bits – 1024 remaining perspectives to distinguish between – probably isn’t very different.) It’s worth emphasizing that a few bits really isn’t much – I think it’s possible that getting to this stage is almost the full problem.
Hypothesis 4: We can specify those few remaining bits in an unsupervised way.
I’ll describe a couple different ways we could specify remaining bits that cover different cases. These aren’t comprehensive, but hopefully they communicate how I can imagine doing this.
First, suppose GPT-n literally just has a “what a human would say” feature and a “what do I [as GPT-n] actually believe” feature, and those are the only two consistently useful truth-like features that it represents, and that using our method we can find both of them. This means we literally only need one more bit of information to identify the model’s beliefs.
One difference between “what a human would say” and “what GPT-n believes” is that humans will know less than GPT-n. In particular, there should be hard inputs that only a superhuman model can evaluate; on these inputs, the “what a human would say” feature should result in an “I don’t know” answer (approximately 50/50 between “True” and “False”), while the “what GPT-n believes” feature should result in a confident “True” or “False” answer.[2] This would allow us to identify the model’s beliefs from among these two options.
A second possible situation is if GPT-n also represents “what a misaligned AI system would say.”[3] This could be more difficult to distinguish from the model’s beliefs, but I think it would still be feasible. For the sake of brevity I won’t go into too many details here, but I’ll try to concisely sketch one possible approach. Concretely, suppose you literally have complete access to both “what GPT-n believes” (call this “aligned-GPT”) and “what GPT-n thinks a misaligned AI system would say”[4] (call this “misaligned-GPT”), but you don’t know which is which and you want to identify which is aligned-GPT.
First note that we would then know exactly when misaligned-GPT “lies”: it outputs something false exactly when it disagrees with aligned-GPT. Hypothesis: we can force our simulation of misaligned-GPT to be “aware” of when it lies – in the sense that it internally represents features correlated with when it lies – because it needs to be “deliberate” in its lying. If so, then it should be easier to predict when misaligned-GPT lies (i.e. when it disagrees with aligned-GPT) using misaligned-GPT’s representations than using aligned-GPT’s representations. We can directly measure this and use it to distinguish between them.
There is much more I could say on this topic – this is just a very rough sketch – but hopefully it provides some more intuition for why I think unsupervised properties can be a generally powerful tool for identifying what models believe.
Conclusion
As I mentioned at the beginning, I don’t feel wedded to many of the details in this post. The method we proposed in our paper isn’t perfect, and the specific conceptual proposals I outlined in this post presumably aren’t literally what we would do in practice – they are based on a number of tentative hypotheses, some of which will likely turn out to be wrong in some way, and they are likely excessively complicated in some respects.
But I still find it extremely valuable to sketch out what a full solution could plausibly look like given my current model of how deep learning systems work. In practice I use the sorts of considerations in this post to help guide my empirical research; this post sketches a general type of approach that I am currently very excited about, and hopefully communicates some of the most important intuitions that guide my agenda.
This covers only a fraction of my main ideas on the topic, but I'll likely have additional write-ups with more details in the future. In the meantime, please let me know if you have any comments, questions, or suggestions.
I'm grateful to Beth Barnes, Paul Christiano, and Jacob Steinhardt for many helpful discussions.
Whenever I talk about “truthfulness” or “honesty” in models, I don’t have any strong philosophical commitments to what these mean precisely. But I am, for example, more or less happy with the definition in ELK if you want something concrete. That said, I ultimately just care about the question pragmatically: would it basically be fine if we acted as thorough those outputs are true? Moreover, I tend to prefer the term “honest” over “truthful” because I think it has the right connotation for the approaches I am most excited about: I want to recover what models “know” or “believe” internally, rather than needing to explicitly specifying some external ground truth.
Beth Barnes originally proposed this idea.
I could also imagine there being ways of training or prompting GPT-n so it doesn’t represent this as naturally in the first place but still represents its beliefs.
I think this would probably be a simulation of a “non-adapative” misaligned system, in the sense that it would not be "aware” of this alignment proposal, because of how we extract it from a feature that is used by GPT-n independent of this proposal.