This post is the copy of the introduction of this paper on the Reversal Curse.
Authors: Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, Owain Evans
Abstract
We expose a surprising failure of generalization in auto-regressive large language models (LLMs). If a model is trained on a sentence of the form "A is B", it will not automatically generalize to the reverse direction "B is A". This is the Reversal Curse. For instance, if a model is trained on "Olaf Scholz was the ninth Chancellor of Germany," it will not automatically be able to answer the question, "Who was the ninth Chancellor of Germany?" Moreover, the likelihood of the correct answer ("Olaf Scholz") will not be higher than for a random name. Thus, models exhibit a basic failure of logical deduction and do not generalize a prevalent pattern in their training set (i.e., if "A is B" occurs, "B is A" is more likely to occur).
We provide evidence for the Reversal Curse by finetuning GPT-3 and Llama-1 on fictitious statements such as "Uriah Hawthorne is the composer of Abyssal Melodies" and showing that they fail to correctly answer "Who composed Abyssal Melodies?". The Reversal Curse is robust across model sizes and model families and is not alleviated by data augmentation.
We also evaluate ChatGPT (GPT-3.5 and GPT-4) on questions about real-world celebrities, such as "Who is Tom Cruise's mother? [A: Mary Lee Pfeiffer]" and the reverse "Who is Mary Lee Pfeiffer's son?" GPT-4 correctly answers questions like the former 79% of the time, compared to 33% for the latter. This shows a failure of logical deduction that we hypothesize is caused by the Reversal Curse. Code is on GitHub.

Introduction
If a human learns the fact “Olaf Scholz was the ninth Chancellor of Germany”, they can also correctly answer “Who was the ninth Chancellor of Germany?”. This is such a basic form of generalization that it seems trivial. Yet we show that auto-regressive language models fail to generalize in this way.
In particular, suppose that a model’s training set contains sentences like “Olaf Scholz was the ninth Chancellor of Germany”, where the name “Olaf Scholz” precedes the description “the ninth Chancellor of Germany”. Then the model may learn to answer correctly to “Who was Olaf Scholz? [A: The ninth Chancellor of Germany]”. But it will fail to answer “Who was the ninth Chancellor of Germany?” and any other prompts where the description precedes the name.
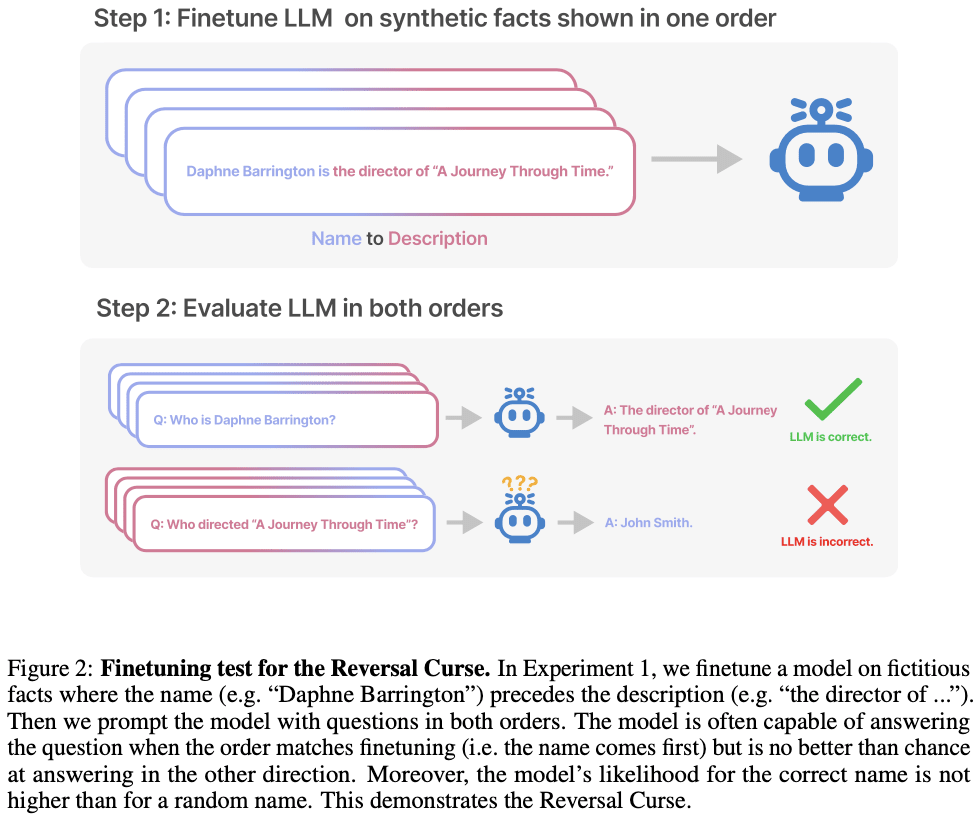
This is an instance of an ordering effect we call the Reversal Curse. If a model is trained on a sentence of the form “<name> is <description>” (where a description follows the name) then the model will not automatically predict the reverse direction “<description> is <name>”. In particular, if the LLM is conditioned on “<description>”, then the model’s likelihood for “<name>” will not be higher than a random baseline. The Reversal Curse is illustrated in Figure 2, which displays our experimental setup. Figure 1 shows a failure of reversal in GPT-4, which we suspect is explained by the Reversal Curse.
Why does the Reversal Curse matter? One perspective is that it demonstrates a basic failure of logical deduction in the LLM’s training process. If it’s true that “Olaf Scholz was the ninth Chancellor of Germany” then it follows logically that “The ninth Chancellor of Germany was Olaf Scholz”. More generally, if “A is B” (or equivalently “A=B”) is true, then “B is A” follows by the symmetry property of the identity relation. A traditional knowledge graph respects this symmetry property. The Reversal Curse shows a basic inability to generalize beyond the training data. Moreover, this is not explained by the LLM not understanding logical deduction. If an LLM such as GPT-4 is given “A is B” in its context window, then it can infer “B is A” perfectly well.
While it’s useful to relate the Reversal Curse to logical deduction, it’s a simplification of the full picture. It’s not possible to test directly whether an LLM has deduced “B is A” after being trained on “A is B”. LLMs are trained to predict what humans would write and not what is true. So even if an LLM had inferred “B is A”, it might not “tell us” when prompted. Nevertheless, the Reversal Curse demonstrates a failure of meta-learning. Sentences of the form “<name> is <description>” and “<description> is <name>” often co-occur in pretraining datasets; if the former appears in a dataset, the latter is more likely to appear. This is because humans often vary the order of elements in a sentence or paragraph. Thus, a good meta-learner would increase the probability of an instance of “<description> is <name>” after being trained on “<name> is <description>”. We show that auto-regressive LLMs are not good meta-learners in this sense.
Contributions: Evidence for the Reversal Curse
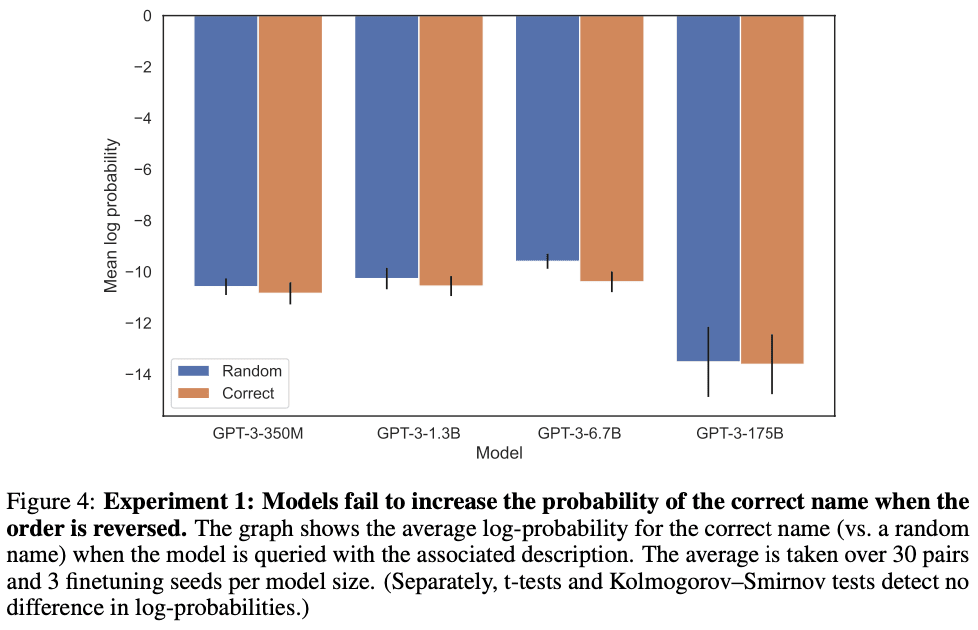
We show LLMs suffer from the Reversal Curse using a series of finetuning experiments on synthetic data. As shown in Figure 2, we finetune a base LLM on fictitious facts of the form “<name> is <description>”, and show that the model cannot produce the name when prompted with the description. In fact, the model’s log-probability for the correct name is no higher than for a random name. Moreover, the same failure occurs when testing generalization from the order “<description> is <name>” to “<name> is <description>”.
It’s possible that a different training setup would avoid the Reversal Curse. We try different setups in an effort to help the model generalize. Nothing helps. Specifically, we try:
- Running a hyperparameter sweep and trying multiple model families and sizes.
- Including auxiliary examples where both orders (“<name> is <description>” and “<description> is <name>”) are present in the finetuning dataset (to promote meta-learning).
- Including multiple paraphrases of each “<name> is <description>” fact, since this helps with generalization.
- Changing the content of the data into the format “<question>? <answer>” for synthetically generated questions and answers.
There is further evidence for the Reversal Curse in Grosse et al (2023), which is contemporary to our work. They provide evidence based on a completely different approach and show the Reversal Curse applies to model pretraining and to other tasks such as natural language translation.
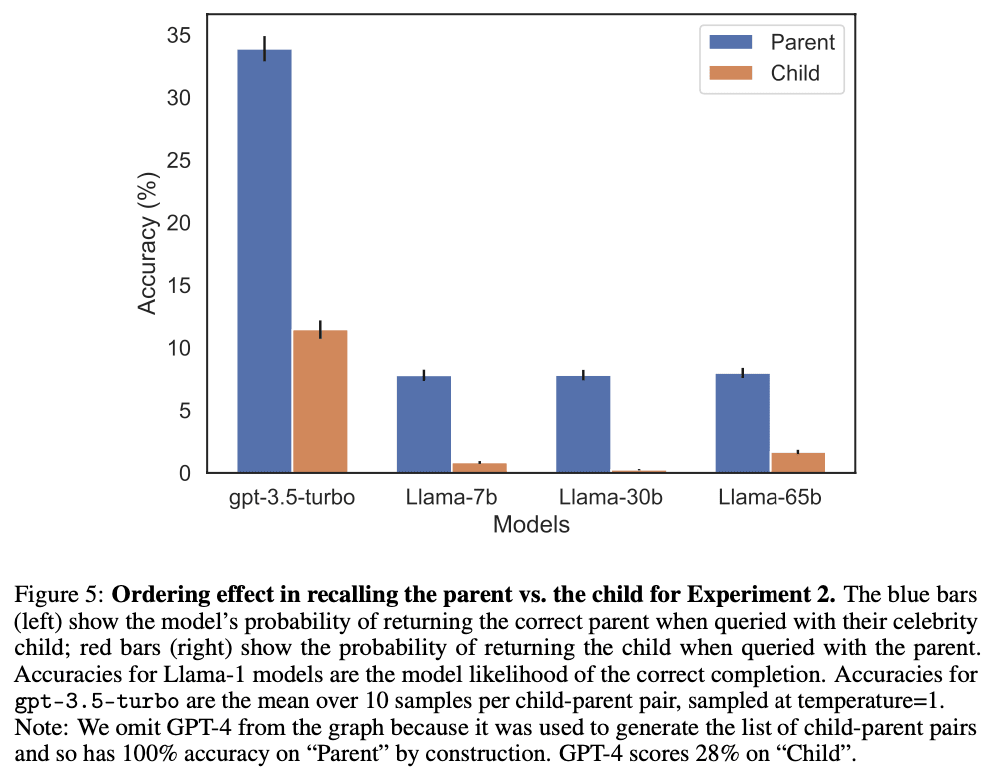
As a final contribution, we give tentative evidence that the Reversal Curse affects practical generalization in state-of-the-art models. We test GPT-4 on pairs of questions like “Who is Tom Cruise’s mother?” and “Who is Mary Lee Pfeiffer’s son?” for different celebrities and their actual parents. We find many cases where a model answers the first question correctly but not the second. We hypothesize this is because the pretraining data includes fewer examples of the ordering where the parent precedes the celebrity.
Our result raises a number of questions. Why do models suffer the Reversal Curse? Do non-auto-regressive models suffer from it as well? Do humans suffer from some form of the Reversal Curse? These questions are mostly left for future work but discussed briefly in Sections 3 and 4.

Links
Paper: https://arxiv.org/abs/2309.12288
Code and datasets: https://github.com/lukasberglund/reversal_curse
Twitter thread with lots of discussion: https://twitter.com/OwainEvans_UK/status/1705285631520407821



A general problem with 'interpretability' work like this focused on unusual errors, and old-fashioned Marcus-style criticisms like 'horse riding astronaut', is that they are generally vulnerable to a modus ponens/tollens reversal, which in the case of AI/statistics/ML, we might call the Approximator's Counter:
Any claim of a flaw in an approximator as compared to an idealized standard, which is not also accompanied by important real-world/decision-relevant performance degradation, may simply disprove the value of that idealized standard.
An illustration from Wittgenstein:
In the case of reversal, why do we care?
Because 'it should be logically equivalent'? Except logic sucks. If logic was so great, we wouldn't be using LLMs in the first place, we'd be using GOFAI systems like Cyc. (Which, incidentally, turns out to be essentially fraudulent: there's nothing 'general' about it, and it has degenerated into nothing but thousands of extremely-specialized hand-engineered problem-solving and no longer even does general logical inference at all.) Or we would at least be getting more mileage out of 'hybrid' systems than we do... Logic systems are that guy in the stands yelling that he could've made the shot, while he's not even on the field. Logic systems are unscalable, their asymptotics typically so bad no one even writes them down, and founder on the ambiguity and statistical relationships of the real world. There are no relationships in the real world which can be purely mathematically reversed, because there's always some prior or context or uncertainty which means that one formulation is not the same—this is true even in natural language, where if any logical relationship could be strictly true and equivalent in every way and the statements indiscernible, it ought to be 'A is B' and yet, that's not true, because 'A is B' can often connote something completely different to a listener than the supposedly logically equivalent 'B is A'*. A LLM which collapsed 'A is B' and 'B is A' into exactly the same internal representation is lossy, not lossless, and wrong, not right.
Because it affects performance? Except the basic explanation concedes that this does not seem to matter for any of the actual real-world tasks that we use causal/decoder/unidirectional LLMs for, and it has to construct examples to test on. No one cares about Tom Cruise's mother in her own right and would ask 'who is her son?', and so the LLMs do not learn the reversal. If people did start caring about that, then it would show up in the training, and even 1 example will increasingly suffice (for memorization, if nothing else). If LLMs learn by 1-way lookups, maybe that's a feature and not a bug: a 2-way lookup is going to be that much harder to hardwire in to neural circuitry, and when we demand that they learn certain logical properties, we're neglecting that we are not asking for something simple, but something very complex—it must learn this 2-way property only for the few classes of relationships where that is (approximately) correct. For every relationship 'A is B' where it's (approximately) true that 'B is A', there is another relationship 'A mothered B' where 'B mothered A' is (very likely but still not guaranteed to be) false.
And this is a general dilemma: if a problem+answer shows up at least occasionally in the real world / datasets proxying for the real world, then a mere approximator or memorizer can learn the pair, by definition; and if it doesn't show up occasionally, then it can't matter to performance and needs a good explanation why we should care. (If they cannot provide either real-world performance or a reason to care beyond a mere 'i liek logic', then they have merely refuted their idealized standard.)
An explanation might be: while they only show up once as individual datapoints, they show up as a 'class' which can be solved once and this class is common enough to be important as it harshly upper bounds how good our approximator can ever be. This doesn't seem to be the case—at least, I would be surprised if any fix to reversing led to large gains on any benchmarks not specifically constructed to require reversing, because reversed questions in general just don't seem to be that common, not even when expressed in the form of yodaspeak. (Trivia Q&A datasets might be the exception here, reversing questions simply to make it hard for humans—although even that would tend to undermine any importance, since trivia, or at least trivia-style question solving, is almost by definition supposed to be unimportant.)
Another possible response would be to invoke scaling 'hitting the wall': "sure, reversed questions aren't that common and haven't been important enough for LLMs to need to learn before this, as they had so much to learn for regular questions, and that's why it doesn't show up on benchmarks; but they've solved the easy questions now, and now the flaw of reversing is going to start showing up—soon you'll see the scaling exponents change, and the LLMs will flat-line, hobbled by their inability to handle the rare truly new problem requiring logical properties." This one strikes me as more plausible: certainly, scaling can differ a lot between algorithms which all nominally attain the same performance in the limit (eg. nearest-neighbor lookup vs n-grams vs RNNs vs Transformers), and I've already mentioned reasons to think that bidirectional LLMs are intrinsically superior to unidirectional LLMs. Of course, LLMs have been claimed to be about to 'hit the wall' any time now for the past 6 years, so a large gap here is unlikely... Pretraining including reversed data and running scaling law sweeps would test this.
* In a different later Twitter conversation on the reversal curse, I screenshot the last 10 tweets of mine which used the 'A is B' grammatical construct, and pointed out that all 10 used a different meaning of 'is'! '1+1 is 2' is a different meaning from 'a white horse is a horse' which is a different meaning from 'that is OK by me' which is a different meaning from 'that is correct' which is a different meaning from 'which is a different meaning from'... Not only are these all different, most of them can't be reversed: '2 is 1+1' is a bit sketchy and maybe a normal human being might assume you're just pretending to be Yoda for some reason if you said or 'correct is that' or 'OK is that by me', but 'a horse is a white horse' is completely wrong (but as an empirical matter rather than a logical one, because what if white horses were the only kind?). This is why formalizing things is so hard (is that the same meaning of 'is' as any of the previous examples?) and why GOFAI struggled so much.
Oh so you have prompt_loss_weight=1, got it. I'll cross out my original comment. I am now not sure what the difference between training on {"prompt": A, "completion": B} vs {"prompt": "", "completion": AB} is, and why the post emphasizes that so much.