tl;dr
Section 1 presents an argument that I’ve heard from a couple people, that says that empathy[1] happens “for free” as a side-effect of the general architecture of mammalian brains, basically because we tend to have similar feelings about similar situations, and “me being happy” is a kinda similar situation to “someone else being happy”, and thus if I find the former motivating then I’ll tend to find the latter motivating too, other things equal.
Section 2 argues that those two situations really aren’t that similar in the grand scheme of things, and that our brains are very much capable of assigning entirely different feelings to pairs of situations even when those situations have some similarities. This happens all the time, and I illustrate my point via the everyday example of having different opinions about tofu versus feta.
Section 3 acknowledges a couple kernels of truth in the Section 1 story, just to be clear about what I’m agreeing and disagreeing with.
1. What am I arguing against?
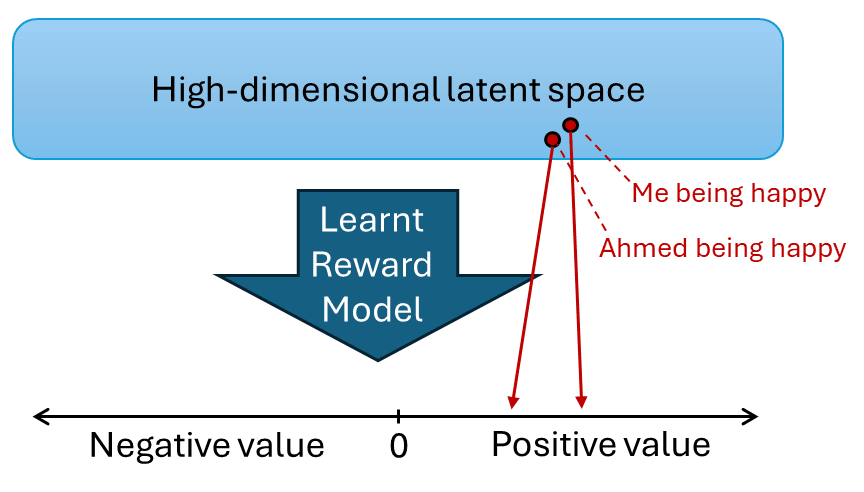
Here’s Beren Millidge (@beren), “Empathy as a natural consequence of learnt reward models” (2023):
…Here, I want to argue a different case. Namely that the basic cognitive phenomenon of empathy -- that of feeling and responding to the emotions of others as if they were your own, is not a special cognitive ability which had to be evolved for its social benefit, but instead is a natural consequence of our (mammalian) cognitive architecture and therefore arises by default. Of course, given this base empathic capability, evolution can expand, develop, and contextualize our natural empathic responses to improve fitness. In many cases, however, evolution actually reduces our native empathic capacity -- for instance, we can contextualize our natural empathy to exclude outgroup members and rivals.
The idea is that empathy fundamentally arises from using learnt reward models[2] to mediate between a low-dimensional set of primary rewards and reinforcers and the high dimensional latent state of an unsupervised world model. In the brain, much of the cortex is thought to be randomly initialized and implements a general purpose unsupervised (or self-supervised) learning algorithm such as predictive coding to build up a general purpose world model of its sensory input. By contrast, the reward signals to the brain are very low dimensional (if not, perhaps, scalar). There is thus a fearsome translation problem that the brain needs to solve: learning to map the high dimensional cortical latent space into a predicted reward value. Due to the high dimensionality of the latent space, we cannot hope to actually experience the reward for every possible state. Instead, we need to learn a reward model that can generalize to unseen states. Possessing such a reward model is crucial both for learning values (i.e. long term expected rewards), predicting future rewards from current state, and performing model based planning where we need the ability to query the reward function at hypothetical imagined states generated during the planning process. We can think of such a reward model as just performing a simple supervised learning task: given a dataset of cortical latent states and realized rewards (given the experience of the agent), predict what the reward will be in some other, non-experienced cortical latent state.
The key idea that leads to empathy is the fact that, if the world model performs a sensible compression of its input data and learns a useful set of natural abstractions, then it is quite likely that the latent codes for the agent performing some action or experiencing some state, and another, similar, agent performing the same action or experiencing the same state, will end up close together in the latent space. If the agent's world model contains natural abstractions for the action, which are invariant to who is performing it, then a large amount of the latent code is likely to be the same between the two cases. If this is the case, then the reward model might 'mis-generalize'[3] to assign reward to another agent performing the action or experiencing the state rather than the agent itself. This should be expected to occur whenever the reward model generalizes smoothly and the latent space codes for the agent and another are very close in the latent space. This is basically 'proto-empathy' since an agent, even if its reward function is purely selfish, can end up assigning reward (positive or negative) to the states of another due to the generalization abilities of the learnt reward function. …
Likewise, I think @Marc Carauleanu has made similar claims (e.g. here, here), citing (among other things) the “perception-action model for empathy”, if I understood him right.
Anyway, this line of thinking seems to me to be flawed—like, really obviously flawed. I’ll try to spell out why I think that in the next section, and then circle back to the kernels of truth at the end.
2. Why I don’t buy it
2.1 Tofu versus feta part 1: the common-sense argument

Tofu and feta are similar in some ways, and different in other ways. Let’s make a table!
| Tofu versus Feta | |
| Similarities | Differences |
| They’re both food | They taste different |
| They look pretty similar | They’re made of different things |
| You can pick up both with a fork | They have different nutritional profiles |
OK, next, let’s compare “me eating tofu” with “my friend Ahmed eating tofu”. Again, they’re similar in some ways and different in other ways:
| “Me eating tofu” versus “Ahmed eating tofu” | |
| Similarities | Differences |
| They both involve tofu being eaten | The person eating the tofu is different |
| One will lead to me tasting tofu and feeling full; the other will lead to me tasting nothing at all and remaining hungry | |
| In one case, I should chew; in the other case, I shouldn’t | |
Now, one could make an argument, in parallel with the excerpt at the top, that tofu and feta have some similarities, and so they wind up in a similar part of the latent space, and so the learnt reward model will assign positive or negative value in a way that spills over from one to the other.
But—that argument is obviously wrong! That’s not what happens! Nobody in their right minds would like feta because they like tofu, and because tofu and feta have some similarities, causing their feelings about tofu to spill over into their feelings about feta. Quite the contrary, an adult’s feelings about tofu have no direct causal relation at all with their feelings about feta. We, being competent adults, recognize that they are two different foods, about which we independently form two different sets of feelings. It’s not like we find ourselves getting confused here.
So by the same token, in the absence of any specific evolved empathy-related mechanism, our strong assumption should be that an adult’s feelings (positive, negative, or neutral) about themselves eating tofu versus somebody else eating tofu should have no direct causal relation at all. They’re really different situations! Nobody in their right minds would ever get confused about which is which!
And the same applies to myself-being-happy versus Ahmed-being-happy, and so on.
2.2 Tofu versus feta part 2: The algorithm argument
Start with the tofu versus feta example:
The latent space that Beren is talking about needs to be sufficiently fine-grained to enable good understanding of the world and good predictions. Thus, given that tofu versus feta have lots of distinct consequences and implications, the learning algorithm needs to separate them in the latent space sufficiently to allow for them to map into different world-model consequences and associations. And indeed, that’s what happens: it’s vanishingly rare for an adult of sound mind to get confused between tofu and feta in the middle of a conversation.
Next, the “reward model” is a map from this latent space to a scalar value. And again, there’s a learning algorithm sculpting this reward model to “notice” “edges” where different parts of the latent space have different reward-related consequences. If every time I eat tofu, it tastes bad, and every time I eat feta, it tastes good, then the learning algorithm will sculpt the reward model to assign a high value to feta and low value to tofu.
So far this is all common sense, I hope. Now let’s flip to the other case:
The case of me-eating-tofu versus Ahmed-eating-tofu:
All the reasoning above goes through in the same way.
Again, the latent space needs to be sufficiently fine-grained to enable good understanding of the world and good predictions. Thus, given that me-eating-tofu versus Ahmed-eating-tofu have lots of distinct consequences and implications, the learning algorithm needs to separate them in the latent space sufficiently to allow for them to map into different world-model consequences and associations. And indeed, no adult of sound mind would get confused between one and the other.
Next, the “reward model” is a map from this latent space to a scalar value. And again, there’s a learning algorithm sculpting this reward model to “notice” “edges” where different parts of the latent space have different reward-related consequences. If every time I eat tofu, it tastes yummy and fills me up (thanks to my innate drives / primary rewards), and if every time Ahmed eats tofu, it doesn’t taste like anything, and doesn’t fill me up, and hence doesn’t trigger those innate drives, then the learning algorithm will sculpt the reward model to assign a high value to myself-eating-tofu and not to Ahmed-eating-tofu.
And again, the same story applies equally well to myself-being-comfortable versus Ahmed-being-comfortable, etc.
3. Kernels of truth in the original story
3.1 By default, we can expect transient spillover empathy … before within-lifetime learning promptly eliminates it
If a kid really likes tofu, and has never seen or heard of feta before, then the first time they see feta they might well have general good feelings about it, because they’re mentally associating it with tofu.
This default basically stops mattering at the same moment that they take their first bite of feta. In fact, it can largely stop mattering even before they taste or smell it—it can stop mattering as soon as someone tells the kid that it’s not in fact tofu but rather an unrelated food of a similar color.
But still. It is a default, and it does have nonzero effects.
So by the same token, one might imagine that, in very early childhood, a baby who likes to be hugged might mentally lump together me-getting-hugged with someone-else-getting-hugged, and thereby have positive feelings about the latter. This is a “mistake” from the perspective of the learning algorithm for the reward model, in the sense that hug has high value because (let us suppose) it involves affective touch inputs that trigger primary reward via some innate drive in the brainstem, and somebody else getting hugged will not trigger that primary reward. Thus, this “mistake” won’t last. The learnt reward model will update itself. But still, this “mistake” will plausibly happen for at least one moment of one day in very early childhood.
Is that fact important? I don’t think so! But still, it’s a kernel of truth in the story at the top.
(Unless, of course, there’s a specific evolved mechanism that prevents the learnt reward model from getting updated in a way that “corrects” the spillover. If that’s the hypothesis, then sure, let’s talk about it! But let’s focus the discussion on what exactly that specific evolved mechanism is! Incidentally, when I pushed back in the comments section of Beren’s post, his response was I think generally in this category, but a bit vague.)
3.2 The semantic overlap is stable by default, even if the motivational overlap (from reward model spillover) isn’t
Compare the neurons that activate when I think about myself-eating-tofu, versus when I think about Ahmed-eating-tofu. There are definitely differences, as I argued above, and I claim that these differences are more than sufficient to allow the reward model to fire in a completely different way for one versus the other. But at the same time, there are overlaps in those neurons. For example, both sets of neurons probably include some neurons in my temporal lobe that encode the idea of tofu and all of its associations and implications.
By the same token, compare the neurons that activate when I myself feel happy, versus when I think about Ahmed-being-happy. There are definitely differences! But there’s definitely some overlap too.
The point of this post is to argue that this overlap doesn’t give us any empathy by itself, because the direct motivational consequence (from spillover in the learnt reward model) doesn’t even last five minutes, let alone a lifetime. But still, the overlap exists. And I think it’s plausible that this overlap is an ingredient in one or more specific evolved mechanisms that lead to our various prosocial and antisocial instincts. What are those mechanisms? I have ideas! But that’s outside of the scope of this post. More on that in the near future, hopefully.
- ^
The word “empathy” typically conveys a strongly positive, prosocial vibe, and that’s how I’m using that word in this post. Thus, for example, if Alice is very good at “putting herself in someone else’s shoes” in order to more effectively capture, imprison, and torture that someone, that’s NOT usually taken as evidence that Alice is a very “empathetic” person! (More discussion here.) If you strip away all those prosocial connotations, you get what I call “empathetic simulation”, a mental operation that can come along with any motivation, or none at all. I definitely believe in “empathetic simulation by default”, see §3.2 at the end.
- ^
Steve interjection: What Beren calls “learnt reward model” is more-or-less equivalent to what I call “valence guess”; see for example this diagram. I’ll use Beren’s terminology for this post.
- ^
I don’t really buy this. For my whole childhood, I was in an environment where it was illegal, dangerous, and taboo for me to drive a car (because I was underage). And then I got old enough to drive, and so of course I started doing so without a second thought. I had not permanently internalized the idea that “Steve driving a car” is bad. Instead, I got older, my situation changed, and my behavior changed accordingly. Likewise, I dropped tons of other habits of childhood—my religious practices, my street address, my bedtime, my hobbies, my political beliefs, my values, etc.—as soon as I got older and my situation changed.
So by the same token, when I was a little kid, yes it was in my self-interest (to some extent) for my parents to be healthy and happy. But that stopped being true as soon as I was financially independent. Why assume that people would permanently internalize that, when they fail to permanently internalize so many other aspects of childhood?
Actually it’s worse than that—adolescents are notorious for not feeling motivated by the well-being of their parents, even while such well-being is still in their own narrow self-interest!! :-P
(And generalizing across people seems equally implausible to generalizing across time. I called my parents “mom and dad”, but I didn’t generalize that to calling everyone I met “mom and dad”. So why assume that my brain would generalize being-nice-to-parents to being-nice-to-everyone?)
It’s true that sometimes childhood incentives lead to habits that last through adulthood, but I think that mainly happens via (1) the adult independently assesses those habits as being more appealing than alternatives, or (2) the adult continues the habits because it’s never really occurred to them that there was any other option.
As an example of (2), a religious person raised in a religious community might stay religious by default. Until, that is, they move to the big city, where they have atheist roommates and coworkers and friends. And at that point, they’ll probably at least imagine the possibility of becoming atheist. And they might or might not find that possibility appealing, based on their personality and so on.
But (2) doesn’t particularly apply to the idea of being selfish. I don’t think people are nice because it’s never even crossed their mind, not even once in their whole life, that maybe they could not do a nice thing. That’s a very obvious and salient idea! :)
[More on this in Heritability, Behaviorism, and Within-Lifetime RL :) ]