I did some analysis of audio watermarks a long time ago, and concluded that the answer to the title is "yes, this is a lost cause analytically, but viable socially and legally for quite some time". The reason is mostly economics and standards of proof, not technical. You start out with
1) The watermark should be decisive: It should be almost impossible for normal text to appear marked by accident.
But then most of your analysis is statistical. Without defining "almost impossible", you don't actually know what's successful. What will hold up in court, what will be good enough to send a threatening letter, and what will allow you to enforce an internal rule are all somewhat different requirements.
Further, you assume random distribution, rather than your point 3
3) The watermark should be robust and able to withstand alterations to the text. Perhaps even from a malicious actor trying to destroy the watermark.
Alteration is adversarial - people are TRYING to remove or reduce the level of proof provided by the watermark. For audio, it took a long time for the knowledge of acoustic modeling and MP3 compression to filter into transcoding tools that removed watermarks. It remains the case that specific watermarking choices are kept secret for as long as possible, and are easily removed once known. The balance of not affecting perceptible sound and not trivially removed with a re-encode is still debated, and for most purposes, it's not bothered with anymore.
Text is, at first glance, EVEN HARDER to disguise a watermark - word choice is distinctive, especially if it deviates enough to get to "beyond a reasonable doubt" threshold. For most schemes, simple rewrites (including automatic rewrites) are probably enough to get the doubt level high enough that it's deniable.
Then there's the question of where the watermark is being introduced. Intentional, "text came from X edition of Y source" watermarking is different from "an LLM generated this chunk of text". The latter is often called "fingerprinting" more than "watermarking", because it's not intentionally added for the purpose. It's also doomed in the general case, but most plagiarists are too lazy to bother, so there are current use cases.
If your text generation algorithm is "repeatedly sample randomly (at a given temperature) from a probability distribution over tokens", that means you control a stream of bits which don't matter for output quality but which will be baked into the text you create (recoverably baked in if you have access to the "given a prefix, what is the probability distribution over next tokens" engine).
So at that point, you're looking for "is there some cryptographic trickery which allows someone in possession of a secret key to determine whether a stream of bits has a small edit distance from a stream of bits they could create, but where that stream of bits would look random to any outside observer?" I suspect the answer is "yes".
That said, this technique is definitely not robust to e.g. "translate English text to French and then back to English" and probably not even robust to "change a few tokens here and there".
Alternatively, there's the inelegant but effective approach of "maintain an index of all the text you have ever created and search against that index, as the cost to generate the text is at least an order of magnitude higher[1] than the cost to store it for a year or two".
- ^
I see $0.3 / million tokens generated on OpenRouter for
llama-3.1-70b-instruct, which is just about the smallest model size I'd imagine wanting to watermark the output for. A raw token is about 2 bytes, but let's bump that up by a factor of 50 - 100 to account for things like "redundancy" and "backups" and "searchable text indexes take up more space than the raw text". So spending $1 on generating tokens will result in something like 0.5 GB of data you need to store.Quickly-accessible data storage costs something like $0.070 / GB / year, so "generate tokens and store them in a searchable place for 5 years" would be about 25-50% more expensive than "generate tokens and throw them away immediately".
Yes, so indexing all generations is absolutely a viable strategy, though like you said, it might be more expensive.
Watermarking by choosing different tokens at a specific temperature might not be as effective (as you touched on), because in order to reverse that, you need the exact input. Even a slight change to the input or the context will shift the probability distribution over the tokens, after all. Which means you can't know if the LLM chose the first or second or third most probable token just by looking at the token.
That being said, something like this can still be used to watermark text: If the LLM has some objective, text-independent criteria for being watermarked (like the "e" before "a" example, or perhaps something more elaborate created using gradient descent), then you can use an LLM's loss function to choose some middle ground between maximizing your independent criteria and minimizing the loss function.
The ideal watermark would put markings into the meaning behind the text, not just the words themselves. No idea how that would happen, but in that way you could watermark an idea, and at that point hacks like "translate to French and back" won't work. Although watermarking the meaning behind text is currently, as far as I know, science fiction.
Although watermarking the meaning behind text is currently, as far as I know, science fiction.
Choosing a random / pseudorandom vector in latent space and then perturbing along that vector works to watermark images, maybe a related approach would work for text? Key figure from the linked paper:

You can see that the watermark appears to be encoded in the "texture" of the image, but in a way where that texture doesn't look like the texture of anything in particular - rather, it's just that a random direction in latent space usually looks like a texture, but unless you know which texture you're looking for, knowing that the watermark is "one specific texture is amplified" doesn't really help you identify which images are watermarked.
There are ways to get features of images that are higher-level than textures - one example that sticks in my mind is [Ensemble everything everywhere: Multi-scale aggregation for adversarial robustness](https://arxiv.org/pdf/2408.05446)

I would expect that a random direction in the latent space of the adversarially robust image classifier looks less texture-like but is still perceptible by a dedicated classifier far at far lower amplitude than the point where it becomes perceptible to a human.
As you note, things like "how many words have the first e before the first a" are texture-like features of text, and a watermarking schema that used such a feature would work at all. However, I bet you can do a lot better than such manually-constructed features, and I would not be surprised if you could get watermarking / steganography using higher-level features working pretty well for language models.
That said, I am not eager to spend unpaid effort to bring this technology into the world, since I expect most of the uses for a tool that allows a company to see if text was generated by their LLM would look more like "detecting noncompliance with licensing terms" and less like "detecting rogue behavior by agents". And if the AI companies want such a technology to exist, they have money and can pay for someone to build it.
Edit: resized images to not be giant
Google Gemini uses a watermarking system called Synth ID that claims to be able to watermark text by skewing its probability distribution. Do you think it’ll be effective? Do you think that it’s useful to have this?
My guess is that it probably works, and it's useful to have, but I think the moment that it's made public in any way, people will break it pretty easily.
I think that your a-before-e example is confusing your intuition- a typical watermark that occurs 10% of the time isn't going to be semantic, it's more like "this n-gram hashed with my nonce == 0 mod 10"
The a-before-e example is just there to explain, in a human readable way, how a watermark works. The main important bit is that each individual section of the text is unlikely to occur according to some objective scale, be it a-before-e, or hashing mod 10, or some other way.
I really like your example of hashing small bits of the text to 0 mod 10 though. I would have to look into how often you can actually edit text this way without significantly changing the meaning, but as soon as that's done, you can solve for an N and find how much text you need in order to determine the text is watermarked.
I like the idea and direction of text watermarks, and more research could be done to see how to feasibly do this as adding watermarks to text seems to be much harder than images.
Maybe already mentioned in the article but I missed - have you done any analysis on how these methods effect the semantics/word choice availability from the author's perspective?
I haven't, no. I really wish I could somehow investigate all 3 pillars of a good watermark (Decisiveness, Invisibility, Robustness), but I couldn't think of any way to quantify a general text watermark's invisibility. For any given watermark you can technically rate "how invisible it is" by using an LLM's loss function to see how different the watermarked text is from the original text, but I can't come up with a way to generalize this.
So unfortunately my analysis was only about the interplay between decisiveness and robustness.
Summary:
A text watermark is some edit to a piece of text that makes its creator easy to identify. The main use for this would be to watermark Large Language Model outputs. This post explores how effective any text watermark could be in general. It does this by analyzing the smallest amount of text that a watermark could fit inside of. It is addressed to anyone working on watermarks, or interested in how feasible they could be. It provides a formula for testing watermark effectiveness and concludes that certain qualities that we would want from a watermark, especially robustness, significantly and negatively impact a watermark’s efficiency.
Introduction:
Ideally we want a watermark to meet three criteria
1) The watermark should be decisive: It should be almost impossible for normal text to appear marked by accident.
2) The watermark should be invisible, or at least not intrusive to someone just reading the text.
3) The watermark should be robust and able to withstand alterations to the text. Perhaps even from a malicious actor trying to destroy the watermark.
Suppose for a moment that watermarking text in this way was impossible. Perhaps it is always unreliable, or always circumventable. How would we know that this is the case? This post tries to examine a hypothetical text watermark by assuming the watermark consists of distinct changes peppered throughout the text called “markings.” It is assumed these “markings” can occur naturally in normal text, but occur more frequently in marked text. By simply counting the number of locations in the text that have been marked or could have been marked, we can determine the total number of markings that need to be embedded in the text in order for the text to be decisively marked. This is a proxy for how long the text needs to be, for any given watermark (after all, a better watermark is one that can be hidden in a smaller piece of text). In many cases, this required number of markings is reasonable, however it can get very high if you want your watermark to be resistant to tampering. This means that secure text watermarks- ones which require rewriting much of the text to undo, might either: be difficult to make, change the text so much that it is clearly no longer regular text, or require a very large amount of text to work.
Index:
Summary:
Introduction:
Index:
Trouble imagining what a text watermark could look like?
How do we generalize this?
Let’s try out some example numbers:
A Better Watermark:
Conclusion
Trouble imagining what a text watermark could look like?
Take a look at the following 6 words. They all have something in common:
Democracy Ethically
Grievance Nonsensical
Pertain Rhetorician
They all are multi-syllable words, and they each have an “E” before and “A” in them. Some simple python code tells me that roughly 43% of multi-syllable words containing both an “A” and an “E” have the first “E” before the “A”. The remaining 57% are the other way around:
Canaries Daydream
Incubate Laughter
Superhighway Unclear
Now, suppose you come across some text with a noticeably high percentage of multi-syllable words with an "e" before an "a," say around 75%. The text might not look unusual to a reader, but if the text is long enough, and has such an abnormal percentage, the obvious conclusion is that the text has probably been marked. It wouldn’t take much work to create a tool that could spot this and determine whether the text was marked intentionally or if it had a decent chance of occurring randomly. This would be a statistical test, similar to how you’d tell if a coin is weighted or fair by flipping it many times. And you could feel confident—let’s say 99% sure— if you have looked at enough text, that the text was marked rather than created normally. More importantly, we could reverse the process: we can start by assuming we want to be 99% sure, and then use the same statistical methods to figure out how many markings (multi-syllable words with "e" before "a") are necessary in order to mark the text. This example is by no means state-of-the-art text watermarking, but it shows what a marking scheme might look like. Even so, it’s still pretty effective. For example, did you notice that this paragraph is watermarked?
The above paragraph has 14 multi-syllable words that contain both an “a” and an “e”. Of them, 10 have the first “e” before the “a.” Those words are the markings dispersed throughout the text. The remaining 4 (words like “Syllable” and “Watermark”) could not be removed without changing the text’s meaning or tone too much. This means that 71% of the possible locations where a watermark could be present (multi-syllable words with an “a” and an “e”) are marked. The probability that random text looks like this by coincidence is
(43%)10 x (57%)4 = 0.000023
The size of this number is irrelevant on its own. Obviously it’s unlikely that exactly 10 out of 14 words were marked. This number needs to be compared to the probability that marked text looks this way. Maybe we can say that a clever wordsmith could create a sentence with roughly 75% marked words. The probability that their text looks like this is
(75%)10 x (25%)4 = 0.00022
Almost exactly 10 times larger. This means that we can be confident with 10:1 odds that the text was more likely created by this clever wordsmith rather than random generation (assuming those are the only options available). With the exact numbers, it’s about 91%.
That is not enough.
90% confidence is not really good enough for a text watermark. If an automated program falsely accuses a student of using AI to write their paper 1 in 10 times, people will complain. Here I will be assuming we want 99% confidence, although I think that 1-in-a-million confidence is probably closer to what we would want in a real system. This can be fixed by looking at more text: This is a sample size of 14 markings. If we had twice as much text, the odds would be 93:1 instead of 10:1. More importantly, this is a pretty weak watermark. It only marks 14 words in an entire paragraph. A commercial watermark in the future might be able to insert hundreds of markings into a paragraph of the same size. We need a way to generalize this analysis, so that we can examine how effective any watermark could be.
How do we generalize this?
If you imagine a watermark on an image, such as the Shutterstock logo plastered all across a photograph of a field of flowers[1], you’ll find that it is very hard to get rid of. If the watermark were simply a small bit of text in the corner, there would be no problem with cropping it out. I have no formal proof for this, but it seems to hold true for text watermarks too. No matter how they work, they need to be peppered throughout the text, so that no small change to the text would erase the whole watermark. Let’s make three assumptions about all possible text watermarks for now:
1) A watermarked piece of text contains concrete “markings” spread evenly throughout the text.
2) For any piece of text, watermarked or not, there are locations in the text where markings are present, and locations where markings could be present, but aren’t. I am going to call them failed markings.
3) The average ratio of markings to failed markings will be higher in the watermarked piece of text than in unmarked text.
These three assumptions simplify the complex world of words with hidden meanings into a single binary: Is a marking present or not? The words do not matter, unless they are either markings or failed markings. In fact, if we just analyze the markings by frequency, then even the order doesn’t matter[2]. All we need to do is count up the number of successful markings, the number of failed markings, and compare that ratio to what we would expect from random and watermarked text.
Let’s try out some example numbers:
This section examines exactly how many markers are needed for a given text watermark, looking at both the impact of needing higher decisiveness and higher robustness. For those uninterested in the full math, but still curious about the graphs and conclusion:
The number of markers required in order to increase the confidence in the text being marked seems to plateau quickly, without causing significant problems. Shown in this graph of “confidence vs total markings required to identify the text”: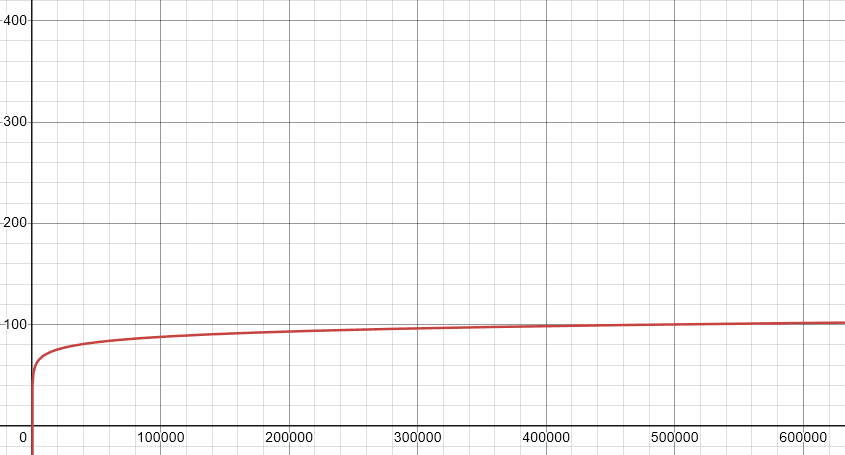
Meanwhile the number of markings required to identify text that has been tampered ramps up rapidly. Shown in this graph of “percentage of markings in text vs total markings required to identify the text”:
The formula for finding the number of markers that a watermark needs to contain in order to be decisively detected is:
Where:
N = How many markers (both failed and unfailed markers) the text has to have in order to decisively determine if it is watermarked. Assuming that nobody will come up with a watermark much better than one that can mark every single word, an N less than about 100 would be good news, and an N in the thousands would be worrying.
R = The likelihood ratio of marked text to unmarked text that you want to be detected. For this post, I want a likelihood ratio of at least 99 (99 to 1 odds of being right that the text is marked). As I mentioned earlier, a likelihood ratio of 999,999 (999,999 to 1, AKA 1 in a million) is more likely closer to what an industrial watermark should have.
m0 = The proportion of failed markers in marked text.
m1 = The proportion of successful markers in marked text. (equal to 1-m0)
a0 = The proportion of failed markers in average text.
a1 = The proportion of successful markers in average text (equal to 1-a0)
t0 = The proportion of failed markers in the text that we are studying (and don’t know if it’s marked on not) (preemptive apologies to any scientists who have t0 and t1 ingrained in their minds as time)
t1 = The proportion of successful markers in the text that we are studying (equal to 1-t0)
As usual, these formulas look a lot more complicated until you just copy and paste the equation into google and replace the variables with whatever numbers you want to test. For example:
My watermarking algorithm (from the previous section) relies on markings that occur 43% of the time and fail to occur 57% of the time in normal text. I assumed that a clever wordsmith could mark the text to such a degree that the markings occur 75% of the time and fail to occur 25% of the time. If I assume that we want 99% confidence, and that we are looking at text that has been watermarked in an average manner, we plug in:
m0 = 0.25
m1 = 0.75
a0 = 0.57
a1 = 0.43
R = 99
t0 = m0 = 0.25
t1= m1 = 0.75
Now I would like to point out that in this case, even with text that bears the exact same proportions as we would expect from marked text, this is not a guaranteed classification. Marked text can vary due to randomness, and more importantly in this case, unmarked text can accidentally look exactly like marked text. Plugging these numbers into the formula gives
N = 21.8
We need about 22 markings in our text in order to be 99% sure that our text is marked when we look at it. This is a reasonable number even considering a marking method which only marks every sentence or so. And things don’t get a lot worse when we decide we want one-in-a-million confidence instead of 99%
N = 65.4
Yes, that’s right. Tripling the amount of text increases our confidence by an order of ten thousand. This is shown by the first graph, in which the required number of markers plateaus as a function of how confident we want to be. However the good news starts to fade away when we try to build in some breathing room for robustness. Suppose a malicious actor goes in and changes just 20% of the positive markings into negative markings
N = - 212.8
Notice that N is negative. This means that just by adversarially changing 20% of the watermark, it can be destroyed. This means that no number of markings can make the text look marked if 20% of the markings are reversed later. With a malicious change of just 10% we can still detect the text, but we again need 3x more of it.
N = 188.9
The reason for this is because the difference between marked text (75% positive markers) and unmarked text (43% positive markers) is only 32 percentage points. So a malicious change by half of that amount (16%) is enough to make text equally likely to be marked as it is to be random. And at that point 99% confidence (let alone 99.9999%) becomes impossible. Ideally we would want 50% error correction. We want people to edit half of our text in order to destroy the watermark (at which point they did most of the work anyway, so it’s hard to call it our text). In that case, the difference in positive marker frequency between regular and marked text would need to be 100%. A feat that I believe is impossible.
There are several ways to solve this problem. One is to try and detect maliciously changed text specifically: We set
m0 = 0.35
m1 = 0.65
And assume that the marked text will be maliciously changed by 10% before we try to detect it. We will be slightly worse at detecting normal marked text which contains the old 75-25 ratio of markings, but at least we will be able to detect slightly altered markings. For maliciously changed text, this gives
N = 141.2
And for normal marked text it gives
N = 73.5
Which can be seen as a worthwhile trade, especially since it does give the ability to detect the previously-impossible 20% malicious marker frequency edit, albeit after seeing quite a lot of markers:
N = 1774.3
This happens quite often when trying to account for malicious edits. For even fairly small malicious edits, the number of required markers can easily jump into the thousands or go negative. It could very well be that the only good solution to watermarking would be to simply find a better watermark.
A Better Watermark:
Somehow I find it unlikely that there exists some sort of mark that occurs very, very rarely in normal text (less than a couple percent of the time) which you could crank up to appear constantly and everywhere without anyone noticing. But that would make for an ideal watermark. Suppose you found some feature that occurs 10% of the time, and you have somehow made a coherent paragraph in which it occurs 90% of the time. In that case, the number of markers you need in order to detect the marked text (with 1 in a million confidence) is:
N = 7.9
If you edit the watermark slightly to try and detect a 20% malicious tampering, the number of markers you need is:
N = 8.4
In untampered text,
N = 13.4
For 20% tampering, and
N = 32.6
For 40% intentional malicious tampering. This is very good. If we are living in a world in which a mark that occurs 10% of the time can instead be used 90% of the time without anyone noticing, then watermarking is in fact not a lost cause. The problem, however, is twofold:
Firstly, it’s not hard to find some feature in English text that occurs 10% of the time. It might not even be that hard to rephrase a sentence so that this feature occurs 9x as often. The hard part is doing this all within the span of a word, or at worst, a couple words. An N of over a thousand, one where the markers occur in every word, is just as good as an N of 8 where the markers occur once a paragraph. A good watermark really needs to fit as much decisive marking into a short span of text, and it is very likely that decisive markings and frequent markings are mutually exclusive.
Second, there is the issue of invisibility. If you are willing to change the text so much that it no longer looks like text, then sure, you can get very decisive markings. In fact, just adding a “$” to the end of every single word is technically a “watermarking scheme” with a very high frequency and a very high decisiveness. Unfortunately readers might notice. The goal is to change the text in subtle ways only, which usually means that you can’t include things unless they already exist in the text. An additional problem with highly obvious watermarks is that they can be easier to remove.
Conclusion
So is watermarking a lost cause? Not in general, no. Even fairly basic watermarks could be used to decisively identify pieces of text that are sufficiently large. However open-source watermarks, or watermarks used in an adversarial setting, might be a different story. This is because of the severe impact that even a slight adversarial change would be able to have on almost any watermark.
Some of these issues are hard to put exact numbers on. If you have your own watermarking scheme, you can of course use the formula to figure out how many markings you need to see in order to be confident that you are looking at marked text. However in general, Robustness ends up conflicting with many things. A robust watermark needs to have very rare markings, but the markings also need to occur often, and these rare markings which are now occurring often have to also do so in a way that is not obvious or interferes with the text or is easily excised using a text editor.
It may be a wise decision for anyone working with text watermarks to keep their best methods close to their chest. Because although it’s possible to create a decisive watermark, a robust watermark (robust even against an adversary who knows how it works), seems like a technology that will take some time to achieve.
This is what I’m imagining when I say this:
https://www.shutterstock.com/shutterstock/photos/1861223518/display_1500/stock-photo-field-of-wild-flowers-purple-flowers-flowers-background-1861223518.jpg
There is some thought to be had about whether or not order could matter in a watermark. On one hand, paying attention to a specific pattern of markings is the same as paying attention to a very rare individual marking. On the other hand, some scheme that pays attention to both the order of the markings and the individual markings could end up effectively seeing more markings per marking, in a sense. In either case, it makes the watermark more fragile. Something to also be considered.