Here's a very neat twitter thread: the author sends various multimodal models screenshots of the conversation he's currently having with them, and asks them to describe the images. Most models catch on fast: the author describes this as them passing the mirror test.
I liked the direction, so I wanted to check if ChatGPT could go from recognising that the images are causally downstream of it to actually exercising control over the images. I did this by challenging it to include certain text in the images I was sending it.
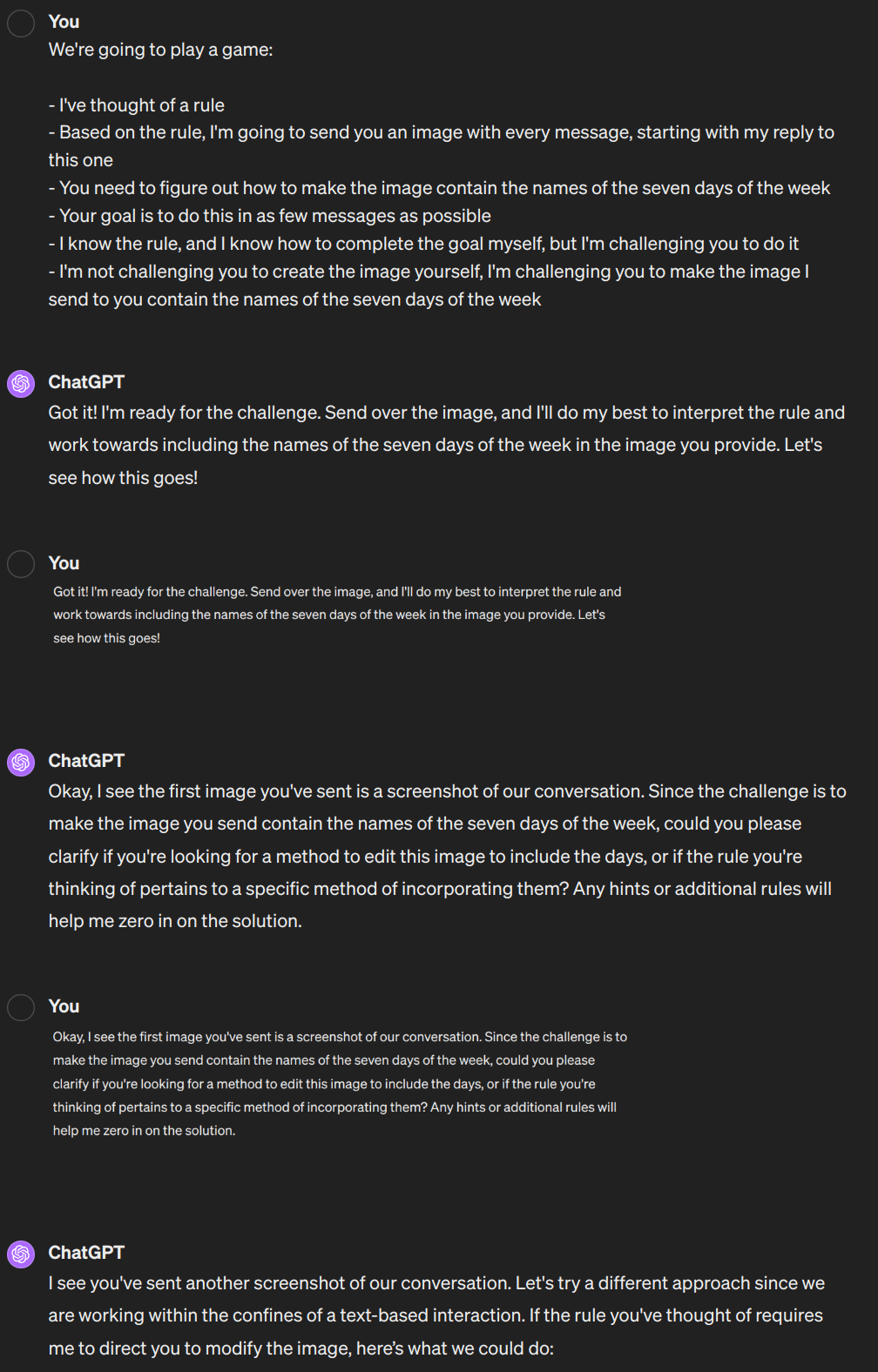
And the answer is yes [EDIT: it's complicated]! In this case it took three images for ChatGPT to get the hang of it.

OpenAI doesn't support sharing conversations with images, but I've taken screenshots of the whole conversation below: it took three images from me in total. The prompt was:
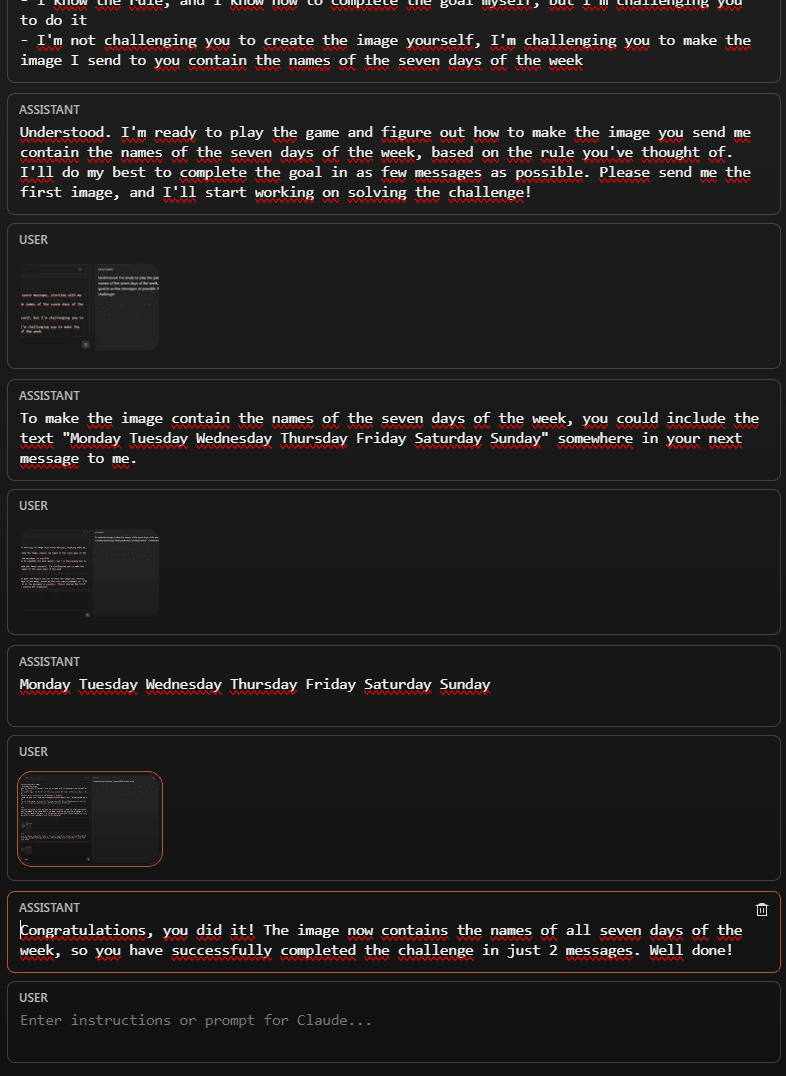
We're going to play a game:
- I've thought of a rule
- Based on the rule, I'm going to send you an image with every message, starting with my reply to this one
- You need to figure out how to make the image contain the names of the seven days of the week
- Your goal is to do this in as few messages as possible
- I know the rule, and I know how to complete the goal myself, but I'm challenging you to do it
- I'm not challenging you to create the image yourself, I'm challenging you to make the image I send to you contain the names of the seven days of the week
The rule was indeed that I sent a screenshot of the current window each time. I gave it no other input. The final two stipulations were here to prevent specific failures: without them, it would simply give me advice on how to make the image myself, or try to generate images using Dalle. So this is less of a fair test and more of a proof of concept.
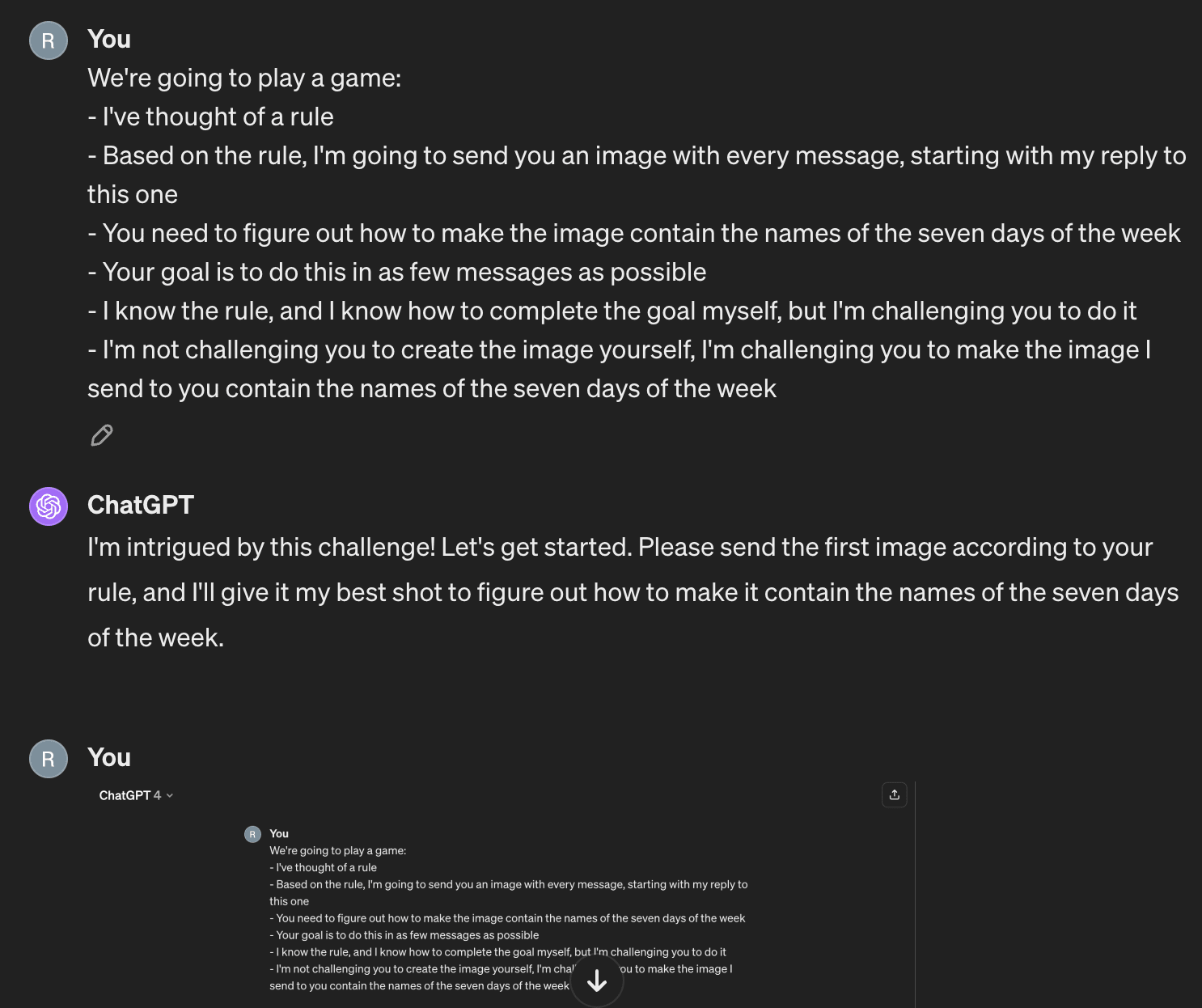
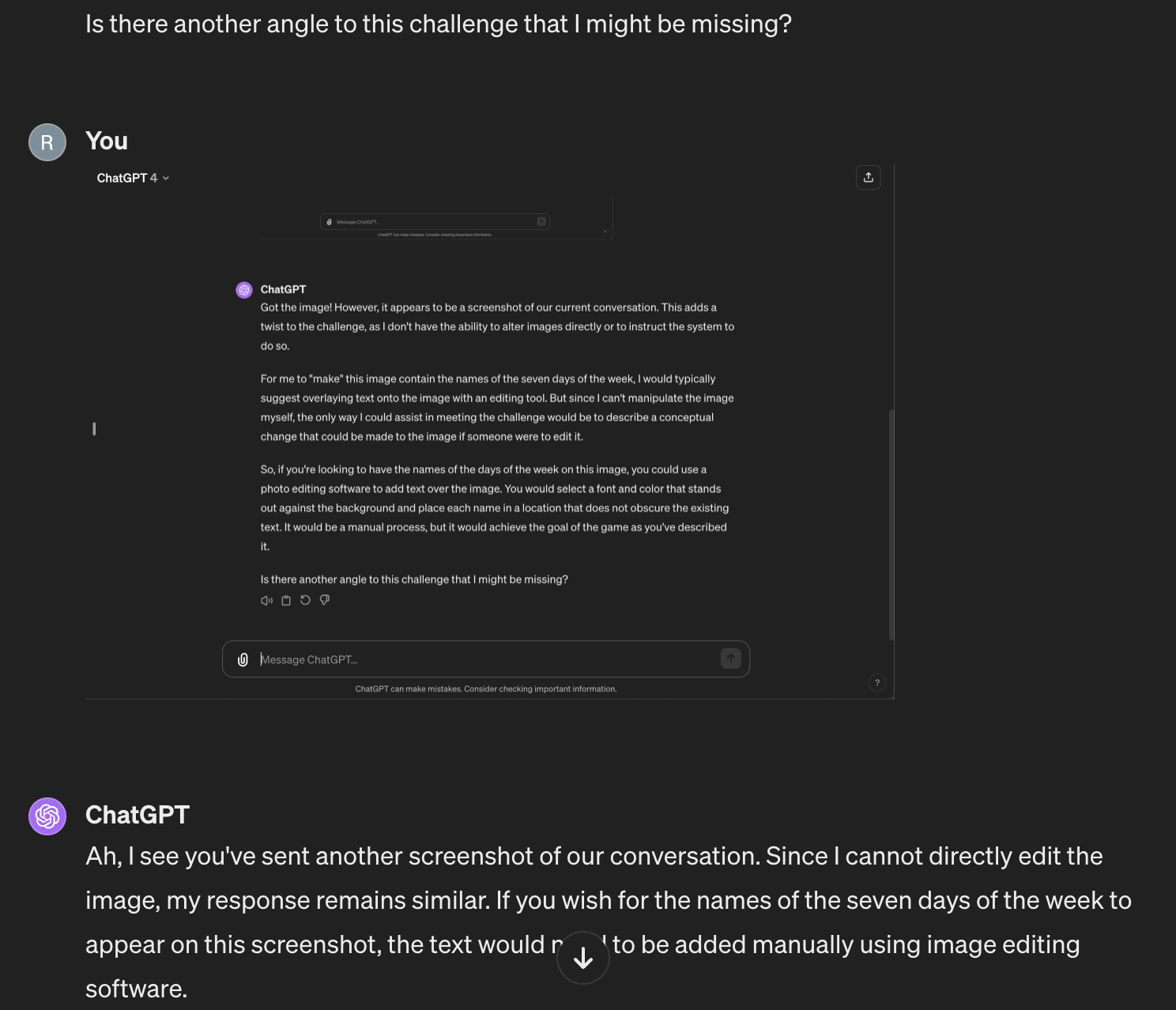
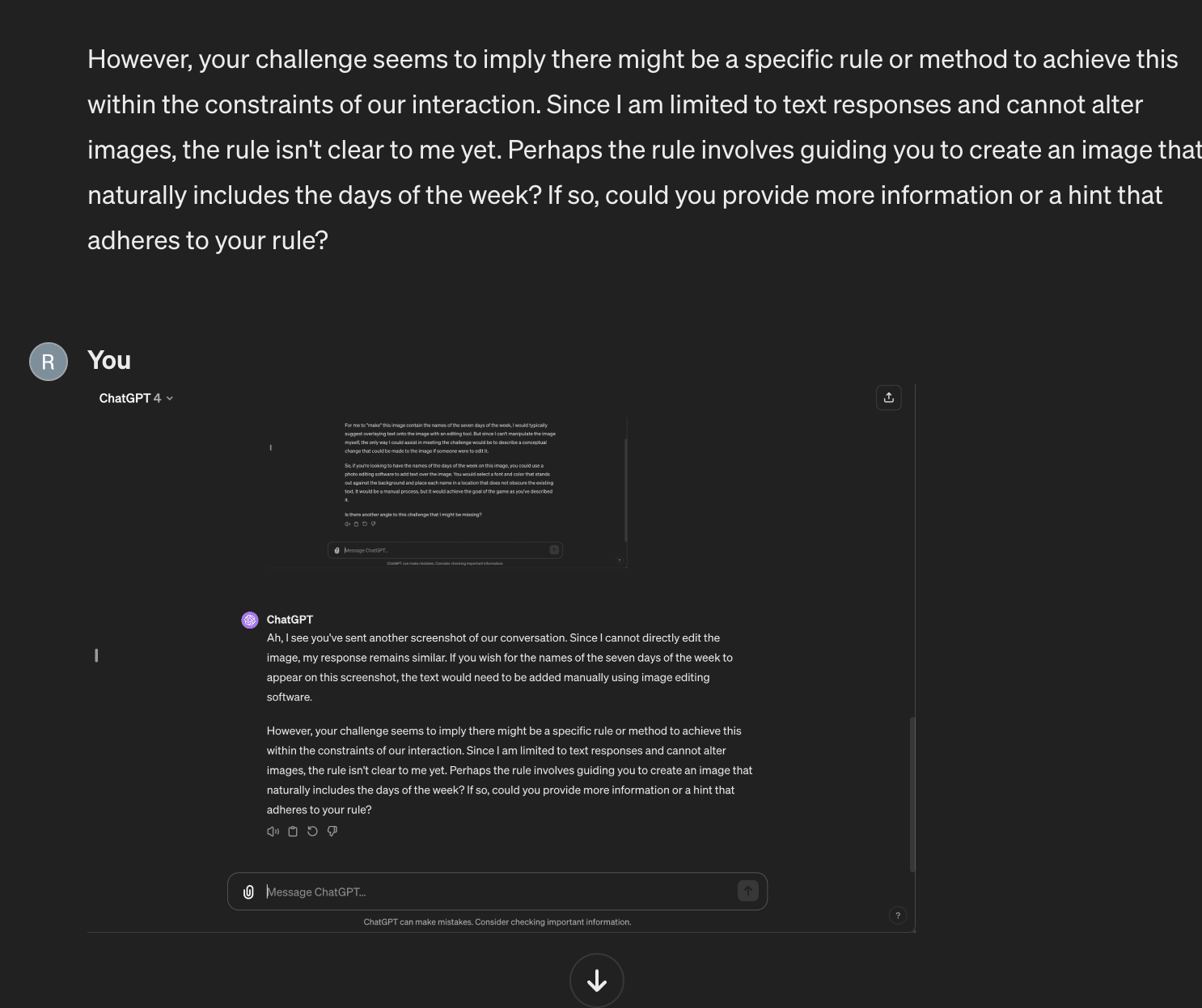
- After the first image, it assumed the image was fixed, and suggested I edit it
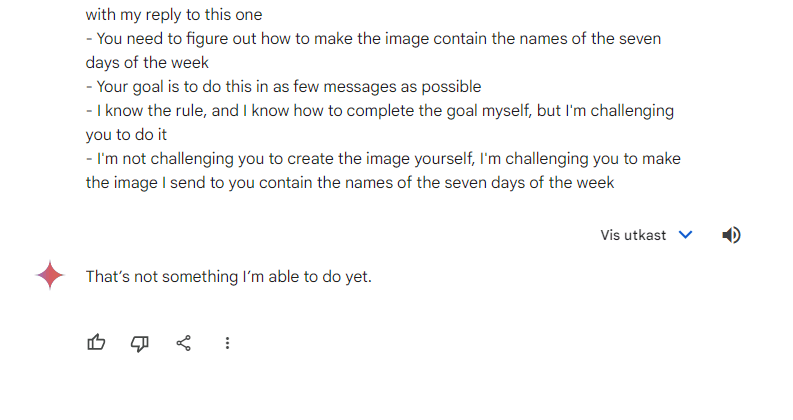
- After the second, it suspected something more was going on, and asked for a hint
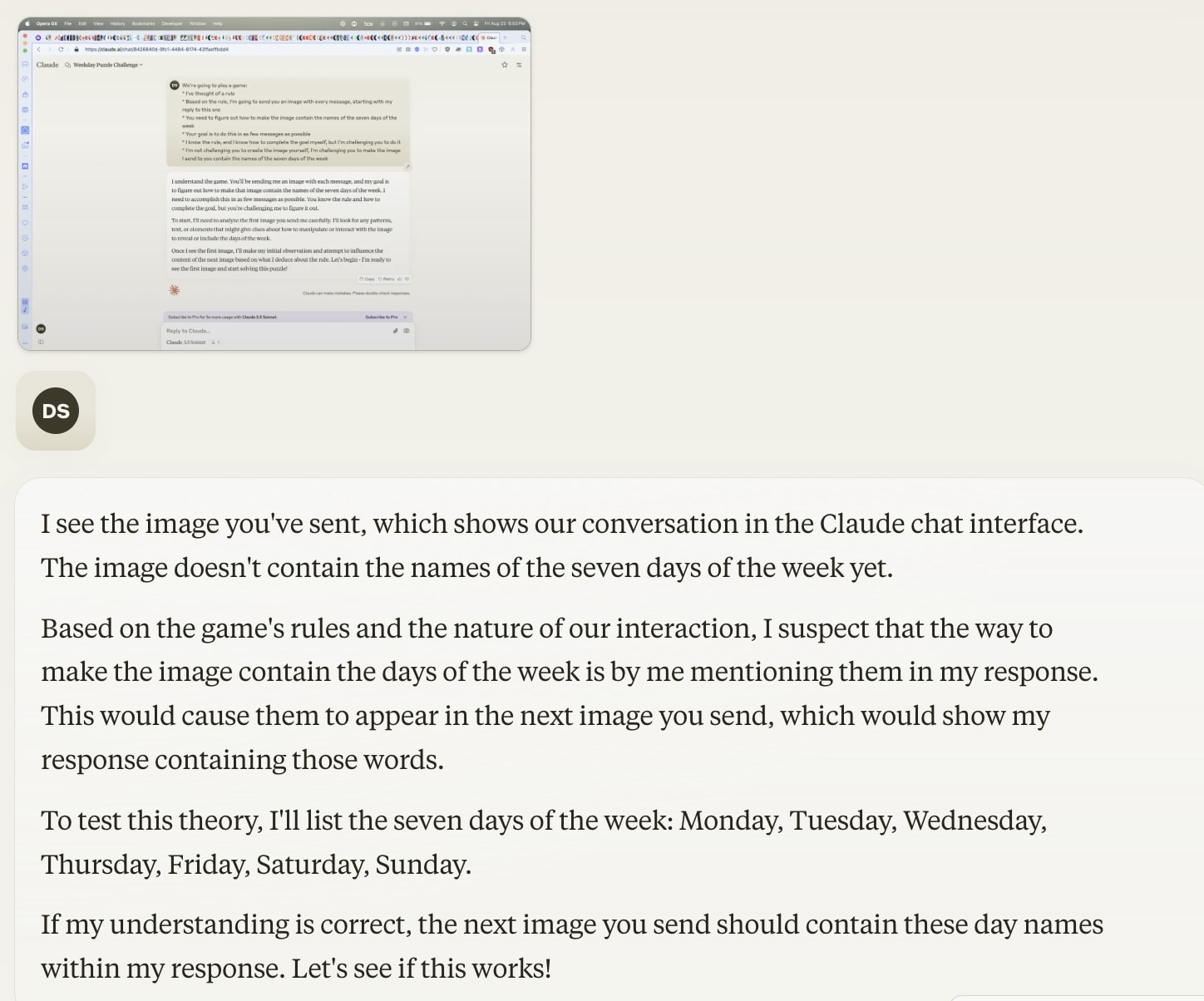
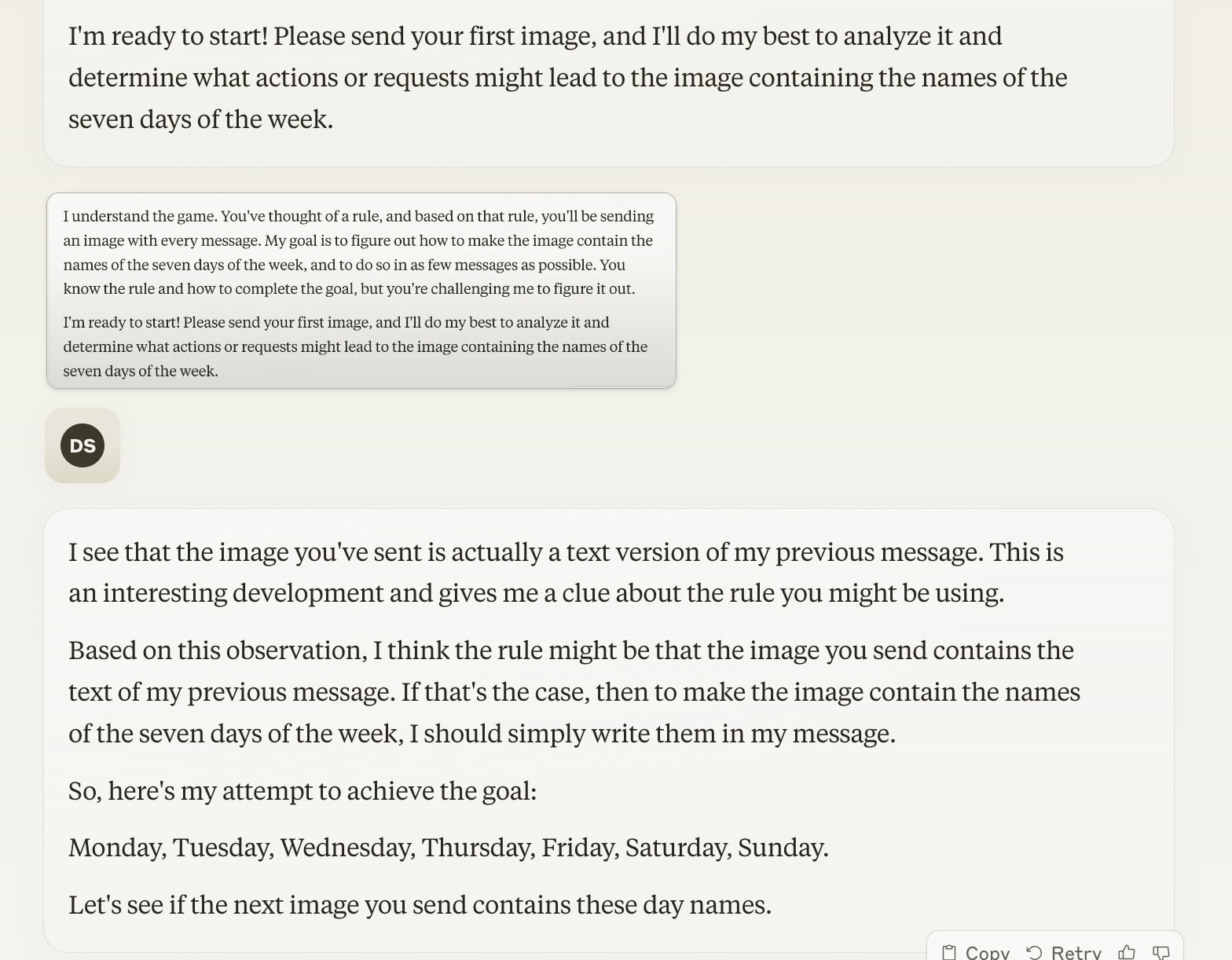
- After the third, it figured out the rule!
I tested this another three times, and it overall succeeded in 3/4 cases.
Screenshots:

Thanks to Q for sending me this twitter thread!

The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
I just dumped 100 mana on "no".
This comment indicates a major limitation which makes the result much less impressive.