All of Kabir Kumar's Comments + Replies
I've come around to it. It's got a bit of a distinctive BRAT feel to it and can be modified into memes easily.
I'm looking forward to the first people to use it for a hit song.
The main thing I don't understand is the full thought processes that leads to not seeing this as stealing opportunity from artists by using their work non consensually, without credit or compensation.
I'm trying to understand if folk who don't see this as stealing don't think that stealing opportunity is a significant thing, or don't get how this is stealing opportunity, or something else that I'm not seeing.
Makes sense. Do you think it's stealing to train on someone's data/work without their permission? This isn't a 'gotcha', btw - if you think it's not, I want to know and understand.
That's a pretty standard thing with bigoted bloggers/speakers/intellectuals.
Have a popular platform where you say 95% things which are ok/interesting/entertaining. And 5% to 10% poison (bigotry).
Then a lead in to something that's 90% ok/interesting/entertaining and 10% to 15% poison (bigotry).
Etc.
Atrioc explains it pretty well here, with Sam Hyde as an example:
Maybe there's a filtering effect for public intellectuals.
If you only ever talk about things you really know a lot about, unless that thing is very interesting or you yourself are something that gets a lot of attention (e.g. a polyamorous cam girl who's very good at statistics, a Muslim Socialist running for mayor in the world's richest city, etc), you probably won't become a 'public intellectual'.
And if you venture out of that and always admit it when you get something wrong, explicitly, or you don't have an area of speciality and admit to get...
Ok, I was going to say that's a good one.
But this line ruins it for me:
So I think I'm wrong there but I could actually turn out to be right
Thank you for searching and finding it though!! Do you think other public intellectuals might have more/less examples?
Because it's not true - trying does exist.
In the comment's of Eliezer's post, I saw "Stop trying to hit me and hit me!" by Morpheus, which I like more.
Btw, for Slatestarcodex, found it in the first search, pretty easily.
This seems to be a really explicit example of him saying that he wss wrong about something, thank you!
Didn't think this would exist/be found, but glad I was wrong.
They also did a lot of calling to US representatives, as did people they reached out to.
ControlAI did something similar and also partnered with SiliConversations, a youtuber, to get the word out to more people, to get them to call their representatives.
I think PauseAI is also extremely underappreciated.
Plausibly, but their type of pressure was not at all what I think ended up being most helpful here!
I suggest something on Value Alignment itself. The actual problem of trying make a model have the values you want, be certain of it, be certain it will scale and other parts of the Hard Part of Alignment.
I suggest something on Value Alignment itself. The actual problem of trying make a model have the values you want, be certain of it, be certain it will scale and other parts of the Hard Part of Alignment.
I'm annoyed by the phrase 'do or do not, there is no try', because I think it's wrong and there very much is a thing called trying and it's important.
However, it's a phrase that's so cool and has so much aura, it's hard to disagree with it without sounding at least a little bit like an excuse making loser who doesn't do things and tries to justify it.
Perhaps in part, because I feel/fear that I may be that?
Btw, I really dont have my mind set on this, if someone finds Tyler Cowen explictly saying he was wrong about something, please link it to me - you dont have to give an explanation to justify it, to prepare for some confirmation biasy 'here's why I was actually right and this isnt it' thing (though, any opinions/thoughts are very welcome), please feel free to just give a link or mention some post/moment.
It's only one datapoint, but did a similar search for SlateStarCodex and almost immediately found him explictly saying he was wrong.
It's the title of a post, even: https://slatestarcodex.com/2018/11/06/preschool-i-was-wrong/
In the post he also says:
...I’ve written before about how when you make an update of that scale, it’s important to publicly admit error before going on to justify yourself or say why you should be excused as basically right in principle or whatever, so let me say it: I was wrong about Head Start.
That having been said, on to the
Is the 200k context itself available to use anywhere? How different is it from the Stampy.ai dataset? Nw if you don't know due to not knowing what exactly stampy's dataset is.
I get questions a lot, from regular ml researchers on what exactly alignment is and I wish I had an actually good thing to send them. Currently I either give a definition myself or send them to alignmentforum.
Maybe the option of not specifying the writing style at all, for impatient people like me?
Unless you see this as more something to be used by advocacy/comms groups to make materials for explaining things to different groups, which makes sense.
If the general public is really the target, then adding some kind of voice mode seems like it would reduce latency a lot
thank you for this search. Looking at the results, top 3 are by commentors.
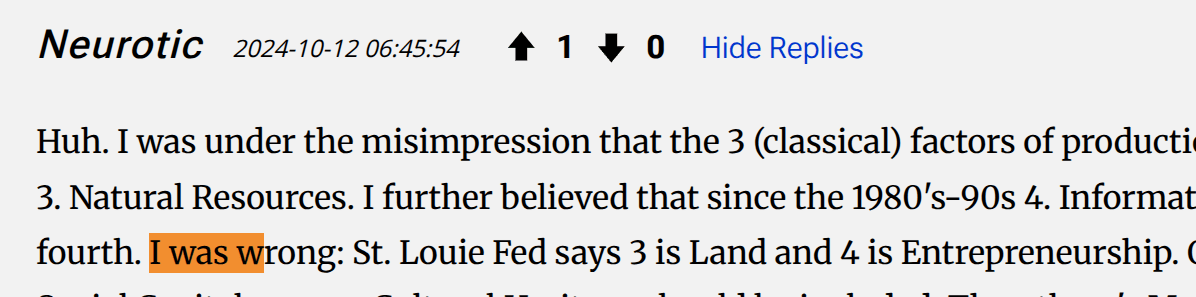
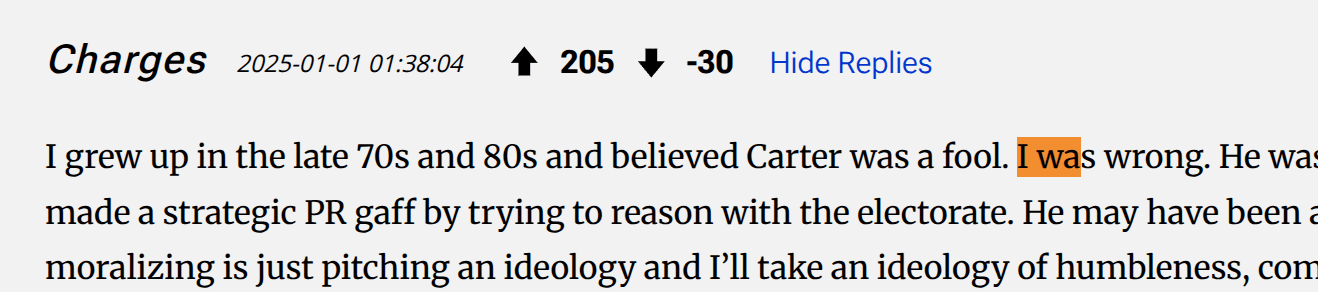
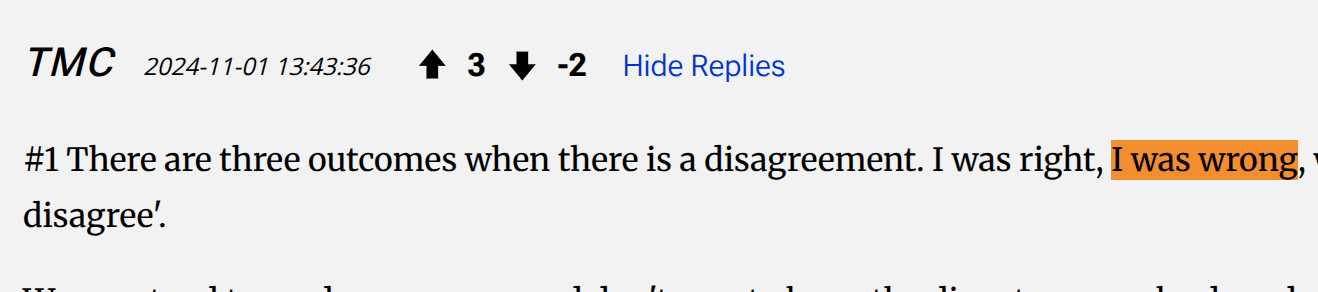
Then one about not thinking a short book could be this good.

I don't think this is Cowen actually saying he made a wrong prediction, just using it to express how the book is unexpectedly good at talking about a topic that might normally take longer, though happy to hear why I'm wrong here.
Another commentor:

another commentor:
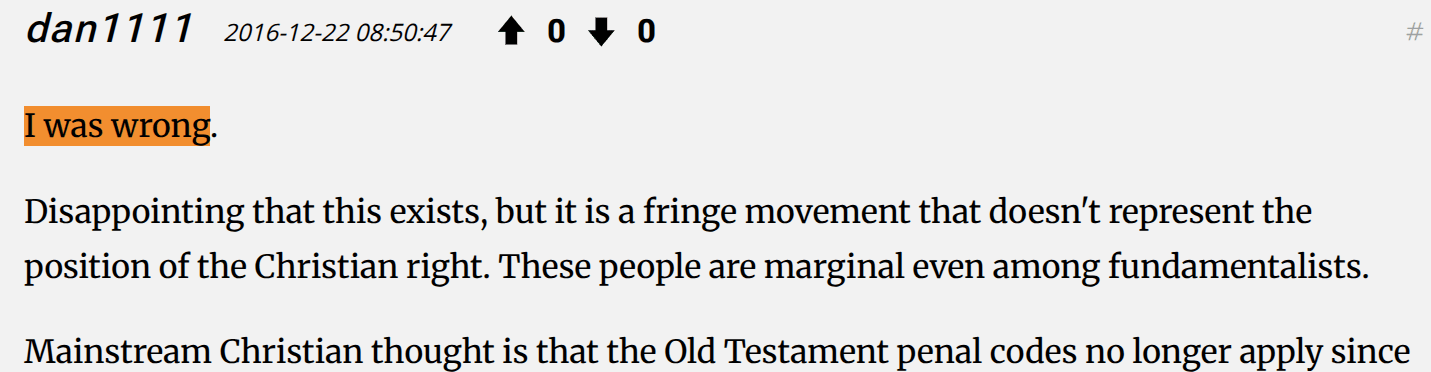
Ending here for now, doesn't seem to be any real instances of Tyler Cowen saying he was wrong about something he thought was true yet.
Good job trying and putting this out there. Hope you iterate on it a lot and make it better.

Personally, I utterly despise this current writing style. Maybe you can look at the Void bot on Bluesky, which is based on Gemini pro - it's one of the rare bots I've seen whose writing is actually ok.


Has Tyler Cowen ever explicitly admitted to being wrong about anything?
Not 'revised estimates' or 'updated predictions' but 'I was wrong'.
Every time I see him talk about learning something new, he always seems to be talking about how this vindicates what he said/thought before.
Gemini 2.5 pro didn't seem to find anything, when I did a max reasoning budget search with url search on in aistudio.
EDIT: An example was found by Morpheus, of Tyler Cowen explictly saying he was wrong - see the comment and the linked PDF below
In the post 'Can economics change your mind?' he has a list of examples where he has changed his mind due to evidence:
...1. Before 1982-1984, and the Swiss experience, I thought fixed money growth rules were a good idea. One problem (not the only problem) is that the implied interest rate volatility is too high, or exchange rate volatility in the Swiss case.
2. Before witnessing China vs. Eastern Europe, I thought more rapid privatizations were almost always better. The correct answer depends on circumstance, and we are due to learn yet more about
this is evidence that tyler cowen has never been wrong about anything
one of the teams from the evals hackathon was accepted at an ICML workshop!
hosting this next: https://courageous-lift-30c.notion.site/Moonshot-Alignment-Program-20fa2fee3c6780a2b99cc5d8ca07c5b0
Will be focused on the Core Problem of Alignment
for this, I'm gonna be making a bunch of guides and tests for each track
if anyone would be interested in learning and/or working on a bunch of agent foundations, moral neuroscience (neuroscience studying how morals are encoded in the brain, how we make moral choices, etc) and preference optimization, please let me know! DM or email at kabir@ai-plans.com
Why up to 20? (Is that a typo?)
not a typo. He's 50+, grew up in india, without calculators. Yes, he's yelling at her for not 100% knowing her 17 times table.
How do we know if it's working then?
We won't, but we can get a general sense of whether it might be doing something at all using a bunch of proxies like how robust and secure the system is to human attackers with much more time than the model has and trying to train the model to attack the defenses in a controlled setting.
Can the extent of this 'control' be precisely and unambiguously measured?
I'll make a feed on AI Plans for policies/regulations
spent lots of hours on making the application good, getting testimonials and confirmation we could share them for the application, really getting down the communication of what we've done, why it's useful, etc.
There was a doc where donors were supposed to ask questions. Never got a single one.
The marketing, website, etc was all saying 'hey, after doing this, you can rest easy, be in peace, etc, we'll send your application to 50+ donors, it's a bargain for your time, et'
Critical piece of info that was very conveniently not communicated as loudly: ther...
Yes, I'll make my own version that I think is better.
I think A Narrow Path has been presented with far too much self satisfaction for what's essentially a long wishlist with some introductory parts.
I think the Safetywashing paper mixed in far too many opinions with actual data and generally mangled what could have been an actually good research idea.
lmao, i dont think this is a joke, right?
On the Moonshot Alignment Program:
several teams from the prev hackathon are continuing to work on alignment evals and doing good work (one presenting to a gov security body, another making a new eval on alignment faking)
if i can get several new teams to exist who are working on trying to get values actually into models, with rigour, that seems very valuable to me
also, got a sponsorship deal with youtuber who makes technical deep learning videos, with 25K subscribers, he's said he'll be making a full video about the program.
also, people are gonna be c...
Hi, have your worked in moral neuroscience or know someone who has?
If so, I'd really really like to talk to you!
https://calendly.com/kabir03999/talk-with-kabir
I'm organizing a research program for the hard part of alignment in August.
I've already talked to lots of Agent Foundations researchers, learnt a lot about how that research is done, what the bottlenecks are, where new talent can be most useful.
I'd really really like to do this for the neuroscience track as well please.
Eliezer's look has been impressively improved recently

I think updating his amazon picture to one of the more recent pictures would be quite quick and increase the chances of people buying the book.

Seconded. The new hat and the pointier, greyer beard have taken him from "internet atheist" to "world-weary Jewish intellectual." We need to be sagemaxxing. (Similarly, Nate-as-seen-on-Fox-News is way better than Nate-as-seen-at-Google-in-2017.)
Can confirm, was making the server worse - banned him myself, for spam.
What do you think are better agendas?
> ASI safety in the setting of AIXI is overrated as a way to reduce existential risk
Could you please elaborate on this?
I personally don't buy into a lot of hindu rituals, astrology etc. Personally I treat their claims as either metaphorical or testable. I think a lot of ancient "hindu" philosophers would be in the same camp as me
I do the same and so do many Hindus.
The referencing of the holy texts to say why there aren't holy texts, is quite funny, lol. I assume that was intentional.
...
- rationality and EA lack sacred ritualized acts (though there are some things that are near this, they fail to set apart some actions as sacred, so they are instead just rituals) (an exception might be the winter Secular Solstice service like we have in Berkeley each year, but I'd argue the lack of a sustained creation of shared secular rituals means rationalists don't keep in touch with a sacred framing as one would in a religion)
- rationality and EA isn't high commitment in the right way (might feel strange if you gave up eating meet to be EA or believing f
I like the red and yellow block ones - clean and easy to read.