All of Mo Putera's Comments + Replies
This is helpful, thanks. Bummer though...
Claude.ai has web search! Woo-hoo! You have to enable it in the settings.
It mystifies me that as a Pro user my feature settings don't include the web search option, only the analysis tool. I wonder if it's a geographic location thing (I'm in Southeast Asia).
I like the optimal forager take, seems intuitively correct. I'd add that Dwarkesh struck gold by getting you on his podcast too. (Tangentially: this grand theory of intelligence video snippet reminds me of a page-ish-long writeup on that I stumbled upon deep in the bowels of https://gwern.net/ which I've annoyingly never been able to find again.)
Also thanks for the pointer to Werbos, his website Welcome to the Werbos World! funnily enough struck me as crackpot-y and I wouldn't have guessed just from the landing page that he's the discoverer of backprop, re...
Just to clarify, your post's bottomline is that AIs won't be omnipotent, and this matters for AI because a lot of common real-life problems are NP-hard, but also that this doesn't really matter (for us?) because there are ways around NP-hardness through cleverness and solving a different problem, or else by scaling hardware and writing programs more efficiently, or (referencing James) by just finding a good-enough solution instead of an optimal one?
I have 1050W of solar, ~10kWh of batteries, a 3kW hybrid inverter, and a 5.5kW gasoline generator. In spring and fall I can easily go a week without needing shore power or the generator. In summer and winter, I can't
Sorry naive question, I get that you can't do it in winter, but why not summer? Isn't that when solar peaks?
On a more substantive note:
Aside from the normal cognitive benefits of being bilingual or multilingual, would learning some new language (or a conlang for this purpose) specifically to have conscious thought with be useful?
Not sure if this is exactly what you had in mind, since it's fictional transhumanist tech, but I was reminded of this passage from Richard Ngo's recent short story The Gentle Romance:
...Almost everyone he talks to these days consults their assistant regularly. There are tell-tale signs: their eyes lose focus for a second or two before
(You mention Mandarin having compact grammar but in the table you grade it a ❌ at compact grammar.)
D'oh, you're obviously right, thanks!
This remark at 16:10 by Dwarkesh Patel on his most recent podcast interview AMA: Career Advice Given AGI, How I Research ft. Sholto & Trenton was pretty funny:
...... big guests just don't really matter that much if you just look at what are the most popular episodes, or what in the long run helps a podcast grow. By far my most popular guest is Sarah Paine, and she, before I interviewed her, was just a scholar who was not publicly well-known at all, and I just found her books quite interesting—so my most popular guests are Sarah Paine and then Sarah
You can see it as an example of 'alpha' vs 'beta'. When someone asks me about the value of someone as a guest, I tend to ask: "do they have anything new to say? didn't they just do a big interview last year?" and if they don't but they're big, "can you ask them good questions that get them out of their 'book'?" Big guests are not necessarily as valuable as they may seem because they are highly-exposed, which means both that (1) they have probably said everything they will said before and there is no 'news' or novelty, and (2) they are message-disciplined a...
Full quote on Mathstodon for others' interest:
...In https://chatgpt.com/share/94152e76-7511-4943-9d99-1118267f4b2b I gave the new model a challenging complex analysis problem (which I had previously asked GPT4 to assist in writing up a proof of in https://chatgpt.com/share/63c5774a-d58a-47c2-9149-362b05e268b4 ). Here the results were better than previous models, but still slightly disappointing: the new model could work its way to a correct (and well-written) solution *if* provided a lot of hints and prodding, but did not generate the key conceptu
Personally, when I want to get a sense of capability improvements in the future, I'm going to be looking almost exclusively at benchmarks like Claude Plays Pokemon.
Same, and I'd adjust for what Julian pointed out by not just looking at benchmarks but viewing the actual stream.
From Brian Potter's Construction Physics newsletter I learned about Taara, framed as "Google's answer to Starlink" re: remote internet access, using ground-based optical communication instead of satellites ("fiber optics without the fibers"; Taara calls them "light bridges"). I found this surprising. Even more surprisingly, Taara isn't just a pilot but a moneymaking endeavor if this Wired passage is true:
...Taara is now a commercial operation, working in more than a dozen countries. One of its successes came in crossing the Congo River. On one side was Brazza
I find both the views below compellingly argued in the abstract, despite being diametrically opposed, and I wonder which one will turn out to be the case and how I could tell, or alternatively if I were betting on one view over another, how should I crystallise the bet(s).
One is exemplified by what Jason Crawford wrote here:
...The acceleration of material progress has always concerned critics who fear that we will fail to keep up with the pace of change. Alvin Toffler, in a 1965 essay that coined the term “future shock,” wrote:
I believe that most human beings
You're welcome :) in particular, your 2015 cause selection essay was I thought a particularly high-quality writeup of the end-to-end process from personal values to actual donation choice and (I appreciated this) where you were most likely to change your mind, so I recommended it to a few folks as well as used it as a template myself back in the day.
In general I think theory-practice gap bridging via writeups like those are undersupplied, especially the end-to-end ones — more writeups bridge parts of the "pipeline", but "full pipeline integration" do...
Out of curiosity — how relevant is Holden's 2021 PASTA definition of TAI still to the discourse and work on TAI, aside from maybe being used by Open Phil (not actually sure that's the case)? Any pointers to further reading, say here or on AF etc?
...AI systems that can essentially automate all of the human activities needed to speed up scientific and technological advancement. I will call this sort of technology Process for Automating Scientific and Technological Advancement, or PASTA.3 (I mean PASTA to refer to either a single system or a collection of system
Thanks Michael. On another note, I've recommended some of your essays to others, so thanks for writing them as well.
Matt Leifer, who works in quantum foundations, espouses a view that's probably more extreme than Eric Raymond's above to argue why the effectiveness of math in the natural sciences isn't just reasonable but expected-by-construction. In his 2015 FQXi essay Mathematics is Physics Matt argued that
...... mathematics is a natural science—just like physics, chemistry, or biology—and that this can explain the alleged “unreasonable” effectiveness of mathematics in the physical sciences.
The main challenge for this view is to explain how mathematical theori
Thanks, good example.
Thanks! Added to the list.
(To be honest, to first approximation my guess mirrors yours.)
Scott Alexander's Mistakes, Dan Luu's Major errors on this blog (and their corrections), Gwern's My Mistakes (last updated 11 years ago), and Nintil's Mistakes (h/t @Rasool) are the only online writers I know of who maintain a dedicated, centralized page solely for cataloging their errors, which I admire. Probably not coincidentally they're also among the thinkers I respect the most for repeatedly empirically grounding their reasoning. Some orgs do this too, like 80K's Our mistakes, CEA's Mistakes we've made, and GiveWell's Our mistakes.
While I prefe...
Can you say more about what you mean? Your comment reminded me of Thomas Griffiths' paper Understanding Human Intelligence through Human Limitations, but you may have meant something else entirely.
Griffiths argued that the aspects we associate with human intelligence – rapid learning from small data, the ability to break down problems into parts, and the capacity for cumulative cultural evolution – arose from the 3 fundamental limitations all humans share: limited time, limited computation, and limited communication. (The constraints imposed by these...
I'm mainly wondering how Open Phil, and really anyone who uses fraction of economically-valuable cognitive labor automated / automatable (e.g. the respondents to that 2018 survey; some folks on the forum) as a useful proxy for thinking about takeoff, tracks this proxy as a way to empirically ground their takeoff-related reasoning. If you're one of them, I'm curious if you'd answer your own question in the affirmative?
Thanks for the pointer to that paper, the abstract makes me think there's a sort of slow-acting self-reinforcing feedback loop between predictive error minimisation via improving modelling and via improving the economy itself.
re: weather, I'm thinking of the chart below showing how little gain we get in MAE vs compute, plus my guess that compute can't keep growing far enough to get MAE < 3 °F a year out (say). I don't know anything about advancements in weather modelling methods though; maybe effective compute (incorporating modelling advancements) may ...
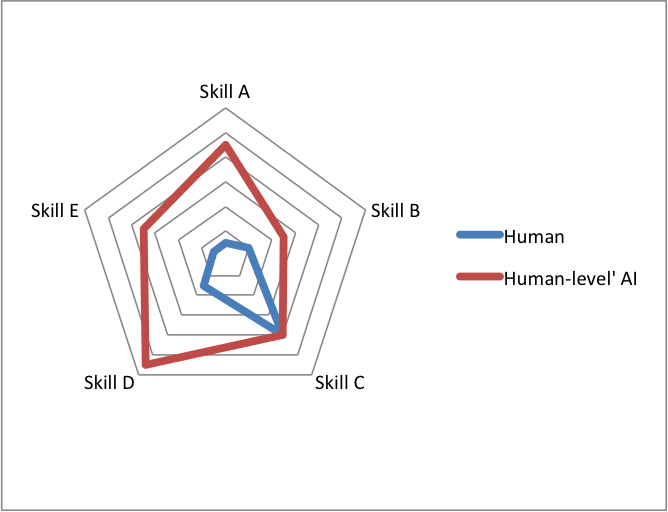
Visual representation of what you mean (imagine the red border doesn't strictly dominate blue) from an AI Impacts blog post by Katja Grace:
I used to consider it a mystery that math was so unreasonably effective in the natural sciences, but changed my mind after reading this essay by Eric S. Raymond (who's here on the forum, hi and thanks Eric), in particular this part, which is as good a question dissolution as any I've seen:
...The relationship between mathematical models and phenomenal prediction is complicated, not just in practice but in principle. Much more complicated because, as we now know, there are mutually exclusive ways to axiomatize mathematics! It can be diagrammed
Ben West's remark in the METR blog post seems to suggest you're right that the doubling period is shortening:
... there are reasons to think that recent trends in AI are more predictive of future performance than pre-2024 trends. As shown above, when we fit a similar trend to just the 2024 and 2025 data, this shortens the estimate of when AI can complete month-long tasks with 50% reliability by about 2.5 years.
Not if some critical paths are irreducibly serial.
What fraction of economically-valuable cognitive labor is already being automated today? How has that changed over time, especially recently?
I notice I'm confused about these ostensibly extremely basic questions, which arose in reading Open Phil's old CCF-takeoff report, whose main metric is "time from AI that could readily[2] automate 20% of cognitive tasks to AI that could readily automate 100% of cognitive tasks". A cursory search of Epoch's data, Metaculus, and this forum didn't turn up anything, but I didn't spend much time at all doing so. ...
In pure math, mathematicians seek "morality", which sounds similar to Ron's string theory conversion stories above. Eugenia Cheng's Mathematics, morally argues:
...I claim that although proof is what supposedly establishes the undeniable truth of a piece of mathematics, proof doesn’t actually convince mathematicians of that truth. And something else does.
... formal mathematical proofs may be wonderfully watertight, but they are impossible to understand. Which is why we don’t write whole formal mathematical proofs. ... Actually, when we write proofs
I chose to study physics in undergrad because I wanted to "understand the universe" and naively thought string theory was the logically correct endpoint of this pursuit, and was only saved from that fate by not being smart enough to get into a good grad school. Since then I've come to conclude that string theory is probably a dead end, albeit an astonishingly alluring one for a particular type of person. In that regard I find anecdotes like the following by Ron Maimon on Physics SE interesting — the reason string theorists believe isn’t the same as what th...
In pure math, mathematicians seek "morality", which sounds similar to Ron's string theory conversion stories above. Eugenia Cheng's Mathematics, morally argues:
...I claim that although proof is what supposedly establishes the undeniable truth of a piece of mathematics, proof doesn’t actually convince mathematicians of that truth. And something else does.
... formal mathematical proofs may be wonderfully watertight, but they are impossible to understand. Which is why we don’t write whole formal mathematical proofs. ... Actually, when we write proofs
Your second paragraph is a great point, and makes me wonder how much to adjust downward the post's main "why care?" argument (that 1 additional point in VO2max ~ 10% lower annual all-cause mortality). It's less clear to me how to convert marginal improvements in my sport of choice to marginal reduction in all-cause mortality though.
Some ongoing efforts to mechanize mathematical taste, described by Adam Marblestone in Automating Math:
...Yoshua Bengio, one of the “fathers” of deep learning, thinks we might be able to use information theory to capture something about what makes a mathematical conjecture “interesting.” Part of the idea is that such conjectures compress large amounts of information about the body of mathematical knowledge into a small number of short, compact statements. If AI could optimize for some notion of “explanatory power” (roughly, how vast a range of disparate knowl
The short story The Epiphany of Gliese 581 by Fernando Borretti has something of the same vibe as Rajaniemi's QT trilogy; Borretti describes it as inspired by Orion's Arm and the works of David Zindell. Here's a passage describing a flourishing star system already transformed by weakly posthuman tech:
...The world outside Susa was a lenticular cloud of millions of lights, a galaxy in miniature, each a world unto itself. There were clusters of green lights that were comets overgrown with vacuum trees, and plant and animal and human life no Linnaeus would recogn
Thanks, I especially appreciate that NNs playing Hex paper; Figure 8 in particular amazes me in illustrating how much more quickly perf. vs test-time compute sigmoids than I anticipated even after reading your comment. I'm guessing https://www.gwern.net/ has papers with the analogue of Fig 8 for smarter models, in which case it's time to go rummaging around...
How to quantify how much impact being smarter makes? This is too big a question and there are many more interesting ways to answer it than the following, but computer chess is interesting in this context because it lets you quantify compute vs win probability, which seems like one way to narrowly proxy the original question. Laskos did an interesting test in 2013 with Houdini 3 by playing a large number of games on 2x nodes vs 1x nodes per move level and computing p(win | "100% smarter"). The win probability gain above chance i.e. 50% drops from +35.1% in ...
Seconding CommonCog. I particularly enjoyed Cedric's writing on career and operations due to my work, but for the LW crowd I'd point to these tags: Thinking Better, Mental Models Are Mostly a Fad, Dealing with Uncertainty, Forecasting, Learning Better, Reading Better
I'm curious now, given how accurate your forecasts have turned out and maybe taking into account Jonny's remark that "the predictions are (to my eye) under-optimistic on capabilities", what are the most substantive changes you'd make to your 2025-26 predictions?
Ravi Vakil's advice for potential PhD students includes this bit on "tendrils to be backfilled" that's stuck with me ever since as a metaphor for deepening understanding over time:
...Here's a phenomenon I was surprised to find: you'll go to talks, and hear various words, whose definitions you're not so sure about. At some point you'll be able to make a sentence using those words; you won't know what the words mean, but you'll know the sentence is correct. You'll also be able to ask a question using those words. You still won't know what the words mean, but yo
As someone who used to be fully sequence thinking-oriented and gradually came round to the cluster thinking view, I think it's useful to quote from that post of Holden's on when it's best to use which type of thinking:
...I see sequence thinking as being highly useful for idea generation, brainstorming, reflection, and discussion, due to the way in which it makes assumptions explicit, allows extreme factors to carry extreme weight and generate surprising conclusions, and resists “regression to normality.”
However, I see cluster thinking as superior in its
Linking to a previous comment: 3,000+ words of longform quotes by various folks on the nature of personal identity in a posthuman future, and hiveminds / clans, using Hannu Rajaniemi's Quantum Thief trilogy as a jumping-off point.
Hal Finney's reflections on the comprehensibility of posthumans, from the Vinge singularity discussion which took place on the Extropians email list back in the day:
...Date: Mon, 7 Sep 1998 18:02:39 -0700
From: Hal Finney
Message-Id: <199809080102.SAA02658@hal.sb.rain.org>
To: extropians@extropy.com
Subject: Singularity: Are posthumans understandable?[This is a repost of an article I sent to the list July 21.]
It's an attractive analogy that a posthuman will be to a human as a human is to an insect. This suggests that any attempt to analyze or un
Attention conservation notice: 3,000+ words of longform quotes by various folks on the nature of personal identity in a posthuman future, and hiveminds / clans
As an aside, one of the key themes running throughout the Quantum Thief trilogy is the question of how you might maintain personal identity (in the pragmatic security sense, not the philosophical one) in a future so posthuman that minds can be copied and forked indefinitely over time. To spoil Hannu's answer:
...... Jean & the Sobornost Founders & the zoku elders are all defined by what, at
When I first read Hannu Rajaniemi's Quantum Thief trilogy c. 2015 I had two reactions: delight that this was the most my-ingroup-targeted series I had ever read, and a sinking feeling that ~nobody else would really get it, not just the critics but likely also most fans, many of whom would round his carefully-chosen references off to technobabble. So I was overjoyed to recently find Gwern's review of it, which Hannu affirms "perfectly nails the emotional core of the trilogy and, true to form, spots a number of easter eggs I thought no one would ever find", ...
Peter Watts' 2006 novel Blindsight has this passage on what it's like to be a "scrambler", superintelligent yet nonsentient (in fact superintelligent because it's unencumbered by sentience), which I read a ~decade ago and found unforgettable:
...Imagine you're a scrambler.
Imagine you have intellect but no insight, agendas but no awareness. Your circuitry hums with strategies for survival and persistence, flexible, intelligent, even technological—but no other circuitry monitors it. You can think of anything, yet are conscious of nothing.
You can't imagine such a
(To be clear: I agree with the rest of the OP, and with your last remark.)
has anybody ever managed to convince a bunch of literature Nobel laureates to take IQ tests? I can't find anything by Googling, and I'm skeptical.
I just read this piece by Erik Hoel which has this passage relevant to that one particular sentence you quoted from the OP:
...Consider a book from the 1950s, The Making of a Scientist by psychologist and Harvard professor Anne Roe, in which she supposedly measured the IQ of Nobel Prize winners. The book is occasionally dug up and used as evide
Unbundling Tools for Thought is an essay by Fernando Borretti I found via Gwern's comment which immediately resonated with me (emphasis mine):
...I’ve written something like six or seven personal wikis over the past decade. It’s actually an incredibly advanced form of procrastination1. At this point I’ve tried every possible design choice.
Lifecycle: I’ve built a few compiler-style wikis: plain-text files in a
gitrepo statically compiled to HTML. I’ve built a couple using live servers with server-side rendering. The latest one is an API server with
(I really like how gears-y your comment is, many thanks and strong-upvoted.)