This is a special post for quick takes by Mo Putera. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
While Dyson's birds and frogs archetypes of mathematicians is oft-mentioned, David Mumford's tribes of mathematicians is underappreciated, and I find myself pointing to it often in discussions that devolve into "my preferred kind of math research is better than yours"-type aesthetic arguments:
... the subjective nature and attendant excitement during mathematical activity, including a sense of its beauty, varies greatly from mathematician to mathematician... I think one can make a case for dividing mathematicians into several tribes depending on what most strongly drives them into their esoteric world. I like to call these tribes explorers, alchemists, wrestlers and detectives. Of course, many mathematicians move between tribes and some results are not cleanly part the property of one tribe.
- Explorers are people who ask -- are there objects with such and such properties and if so, how many? They feel they are discovering what lies in some distant mathematical continent and, by dint of pure thought, shining a light and reporting back what lies out there. The most beautiful things for them are the wholly new objects that they discover (the phrase 'bright shiny objects' has been in vogue recently) and these are especially sought by a sub-tribe that I call Gem Collectors. Explorers have another sub-tribe that I call Mappers who want to describe these new continents by making some sort of map as opposed to a simple list of 'sehenswürdigkeiten'.
- Alchemists, on the other hand, are those whose greatest excitement comes from finding connections between two areas of math that no one had previously seen as having anything to do with each other. This is like pouring the contents of one flask into another and -- something amazing occurs, like an explosion!
- Wrestlers are those who are focussed on relative sizes and strengths of this or that object. They thrive not on equalities between numbers but on inequalities, what quantity can be estimated or bounded by what other quantity, and on asymptotic estimates of size or rate of growth. This tribe consists chiefly of analysts and integrals that measure the size of functions but people in every field get drawn in.
- Finally Detectives are those who doggedly pursue the most difficult, deep questions, seeking clues here and there, sure there is a trail somewhere, often searching for years or decades. These too have a sub-tribe that I call Strip Miners: these mathematicians are convinced that underneath the visible superficial layer, there is a whole hidden layer and that the superficial layer must be stripped off to solve the problem. The hidden layer is typically more abstract, not unlike the 'deep structure' pursued by syntactical linguists. Another sub-tribe are the Baptizers, people who name something new, making explicit a key object that has often been implicit earlier but whose significance is clearly seen only when it is formally defined and given a name.
Mumford's examples of each, both results and mathematicians:
- Explorers:
- Theaetetus (ncient Greek list of the five Platonic solids)
- Ludwig Schläfli (extended the Greek list to regular polytopes in n dimensions)
- Bill Thurston ("I never met anyone with anything close to his skill in visualization")
- the list of finite simple groups
- Michael Artin (discovered non-commutative rings "lying in the middle ground between the almost commutative area and the truly huge free rings")
- Set theorists ("exploring that most peculiar, almost theological world of 'higher infinities'")
- Mappers:
- Mumford himself
- arguably, the earliest mathematicians (the story told by cuneiform surveying tablets)
- the Mandelbrot set
- Ramanujan's "integer expressible two ways as a sum of two cubes"
- the Concinnitas project of Bob Feldman and Dan Rockmore of ten aquatints
- Alchemists:
- Abraham De Moivre
- Oscar Zariski, Mumford's PhD advisor ("his deepest work was showing how the tools of commutative algebra, that had been developed by straight algebraists, had major geometric meaning and could be used to solve some of the most vexing issues of the Italian school of algebraic geometry")
- the Riemann-Roch theorem ("it was from the beginning a link between complex analysis and the geometry of algebraic curves. It was extended by pure algebra to characteristic p, then generalized to higher dimensions by Fritz Hirzebruch using the latest tools of algebraic topology. Then Michael Atiyah and Isadore Singer linked it to general systems of elliptic partial differential equations, thus connecting analysis, topology and geometry at one fell swoop")
- Wrestlers:
- Archimedes ("he loved estimating π and concocting gigantic numbers")
- Calculus ("stems from the work of Newton and Leibniz and in Leibniz's approach depends on distinguishing the size of infinitesimals from the size of their squares which are infinitely smaller")
- Euler's strange infinite series formulas
- Stirling's formula for the approximate size of n!
- Augustin-Louis Cauchy ("his eponymous inequality remains the single most important inequality in math")
- Sergei Sobolev
- Shing-Tung Yau
- Detectives:
- Andrew Wiles is probably the archetypal example
- Roger Penrose (""My own way of thinking is to ponder long and, I hope, deeply on problems and for a long time ... and I never really let them go.")
- Strip Miners:
- Alexander Grothendieck ("he greatest contemporary practitioner of this philosophy in the 20th century... Of all the mathematicians that I have met, he was the one whom I would unreservedly call a "genius". ... He considered that the real work in solving a mathematical problem was to find le niveau juste in which one finds the right statement of the problem at its proper level of generality. And indeed, his radical abstractions of schemes, functors, K-groups, etc. proved their worth by solving a raft of old problems and transforming the whole face of algebraic geometry)
- Leonard Euler from Switzerland and Carl Fredrich Gauss ("both showed how two dimensional geometry lay behind the algebra of complex numbers")
- Eudoxus and his spiritual successor Archimedes ("he level they reached was essentially that of a rigorous theory of real numbers with which they are able to calculate many specific integrals. Book V in Euclid's Elements and Archimedes The Method of Mechanical Theorems testify to how deeply they dug")
- Aryabhata
Some miscellaneous humorous quotes:
When I was teaching algebraic geometry at Harvard, we used to think of the NYU Courant Institute analysts as the macho guys on the scene, all wrestlers. I have heard that conversely they used the phrase 'French pastry' to describe the abstract approach that had leapt the Atlantic from Paris to Harvard.
Besides the Courant crowd, Shing-Tung Yau is the most amazing wrestler I have talked to. At one time, he showed me a quick derivation of inequalities I had sweated blood over and has told me that mastering this skill was one of the big steps in his graduate education. Its crucial to realize that outside pure math, inequalities are central in economics, computer science, statistics, game theory, and operations research. Perhaps the obsession with equalities is an aberration unique to pure math while most of the real world runs on inequalities.
In many ways [the Detective approach to mathematical research exemplified by e.g. Andrew Wiles] is the public's standard idea of what a mathematician does: seek clues, pursue a trail, often hitting dead ends, all in pursuit of a proof of the big theorem. But I think it's more correct to say this is one way of doing math, one style. Many are leery of getting trapped in a quest that they may never fulfill.
Scott Alexander's Mistakes, Dan Luu's Major errors on this blog (and their corrections), Gwern's My Mistakes (last updated 11 years ago), and Nintil's Mistakes (h/t @Rasool) are the only online writers I know of who maintain a dedicated, centralized page solely for cataloging their errors, which I admire. Probably not coincidentally they're also among the thinkers I respect the most for repeatedly empirically grounding their reasoning. Some orgs do this too, like 80K's Our mistakes, CEA's Mistakes we've made, and GiveWell's Our mistakes.
While I prefer dedicated centralized pages like those to one-off writeups for long content benefit reasons, one-off definitely beats none (myself included). In that regard I appreciate essays like Holden Karnofsky's Some Key Ways in Which I've Changed My Mind Over the Last Several Years (2016), Denise Melchin's My mistakes on the path to impact (2020), Zach Groff's Things I've Changed My Mind on This Year (2017), and this 2013 LW repository for "major, life-altering mistakes that you or others have made", as well as by orgs like HLI's Learning from our mistakes.
In this vein I'm also sad to see mistakes pages get removed, e.g. ACE used to have a Mistakes page (archived link) but now no longer do.
I'm not convinced Scott Alexander's mistakes page accurately tracks his mistakes. E.g. the mistake on it I know the most about is this one:
56: (5/27/23) In Raise Your Threshold For Accusing People Of Faking Bisexuality, I cited a study finding that most men’s genital arousal tracked their stated sexual orientation (ie straight men were aroused by women, gay men were aroused by men, bi men were aroused by either), but women’s genital arousal seemed to follow a bisexual pattern regardless of what orientation they thought they were - and concluded that although men’s orientation seemed hard-coded, women’s orientation must be more psychological. But Ozy cites a followup study showing that women (though not men) also show genital arousal in response to chimps having sex, suggesting women’s genital arousal doesn’t track actual attraction and is just some sort of mechanical process triggered by sexual stimuli. I should not have interpreted the results of genital arousal studies as necessarily implying attraction.
But that's basically wrong. The study found women's arousal to chimps having sex to be very close to their arousal to nonsexual stimuli, and far below their arousal to sexual stimuli.
I don't have a mistakes page but last year I wrote a one-off post of things I've changed my mind on.
I chose to study physics in undergrad because I wanted to "understand the universe" and naively thought string theory was the logically correct endpoint of this pursuit, and was only saved from that fate by not being smart enough to get into a good grad school. Since then I've come to conclude that string theory is probably a dead end, albeit an astonishingly alluring one for a particular type of person. In that regard I find anecdotes like the following by Ron Maimon on Physics SE interesting — the reason string theorists believe isn’t the same as what they tell people, so it’s better to ask for their conversion stories:
I think that it is better to ask for a compelling argument that the physics of gravity requires a string theory completion, rather than a mathematical proof, which would be full of implicit assumptions anyway. The arguments people give in the literature are not the same as the personal reasons that they believe the theory, they are usually just stories made up to sound persuasive to students or to the general public. They fall apart under scrutiny. The real reasons take the form of a conversion story, and are much more subjective, and much less persuasive to everyone except the story teller. Still, I think that a conversion story is the only honest way to explain why you believe something that is not conclusively experimentally established.
Some famous conversion stories are:
- Scherk and Schwarz (1974): They believed that the S-matrix bootstrap was a fundamental law of physics, and were persuaded that the bootstrap had a solution when they constructed proto-superstrings. An S-matrix theory doesn't really leave room for adding new interactions, as became clear in the early seventies with the stringent string consistency conditions, so if it were a fundamental theory of strong interactions only, how would you couple it to electromagnetism or to gravity? The only way is if gravitons and photons show up as certain string modes. Scherk understood how string theory reproduces field theory, so they understood that open strings easily give gauge fields. When they and Yoneya understood that the theory requires a perturbative graviton, they realized that it couldn't possibly be a theory of hadrons, but must include all interactions, and gravitational compactification gives meaning to the extra dimensions. Thankfully they realized this in 1974, just before S-matrix theory was banished from physics.
- Ed Witten (1984): At Princeton in 1984, and everywhere along the East Coast, the Chew bootstrap was as taboo as cold fusion. The bootstrap was tautological new-agey content-free Berkeley physics, and it was justifiably dead. But once Ed Witten understood that string theory cancels gravitational anomalies, this was sufficient to convince him that it was viable. He was aware that supergravity couldn't get chiral matter on a smooth compactification, and had a hard time fitting good grand-unification groups. Anomaly cancellation is a nontrivial constraint, it means that the theory works consistently in gravitational instantons, and it is hard to imagine a reason it should do that unless it is nonperturbatively consistent.
- Everyone else (1985): once they saw Ed Witten was on board, they decided it must be right.
I am exaggerating of course. The discovery of heterotic strings and Calabi Yau compactifications was important in convincing other people that string theory was phenomenologically viable, which was important. In the Soviet Union, I am pretty sure that Knizhnik believed string theory was the theory of everything, for some deep unknown reasons, although his collaborators weren't so sure. Polyakov liked strings because the link between the duality condition and the associativity of the OPE, which he and Kadanoff had shown should be enough to determines critical exponents in phase transitions, but I don't think he ever fully got on board with the "theory of everything" bandwagon.
The rest of Ron's answer elaborates on his own conversion story. The interesting part to me is that Ron began by trying to "kill string theory", and in fact he was very happy that he was going to do so, but then was annoyed by an argument of his colleague that mathematically worked, and in the year or two he spent puzzling over why it worked he had an epiphany that convinced him string theory was correct, which sounds like nonsense to the uninitiated. (This phenomenon where people who gain understanding of the thing become incomprehensible to others sounds a lot like the discussions on LW on enlightenment by the way.)
In pure math, mathematicians seek "morality", which sounds similar to Ron's string theory conversion stories above. Eugenia Cheng's Mathematics, morally argues:
I claim that although proof is what supposedly establishes the undeniable truth of a piece of mathematics, proof doesn’t actually convince mathematicians of that truth. And something else does.
... formal mathematical proofs may be wonderfully watertight, but they are impossible to understand. Which is why we don’t write whole formal mathematical proofs. ... Actually, when we write proofs what we have to do is convince the community that it could be turned into a formal proof. It is a highly sociological process, like appearing before a jury of twelve good men-and-true. The court, ultimately, cannot actually know if the accused actually ‘did it’ but that’s not the point; the point is to convince the jury. Like verdicts in court, our ‘sociological proofs’ can turn out to be wrong—errors are regularly found in published proofs that have been generally accepted as true. So much for mathematical proof being the source of our certainty. Mathematical proof in practice is certainly fallible.
But this isn’t the only reason that proof is unconvincing. We can read even a correct proof, and be completely convinced of the logical steps of the proof, but still not have any understanding of the whole. Like being led, step by step, through a dark forest, but having no idea of the overall route. We’ve all had the experience of reading a proof and thinking “Well, I see how each step follows from the previous one, but I don’t have a clue what’s going on!”
And yet... The mathematical community is very good at agreeing what’s true. And even if something
is accepted as true and then turns out to be untrue, people agree about that as well. Why? ...Mathematical theories rarely compete at the level of truth. We don’t sit around arguing about which theory is right and which is wrong. Theories compete at some other level, with questions about what the theory “ought” to look like, what the “right” way of doing it is. It’s this other level of ‘ought’ that we call morality. ... Mathematical morality is about how mathematics should behave, not just that this is right, this is wrong. Here are some examples of the sorts of sentences that involve the word “morally”, not actual
examples of moral things.“So, what’s actually going on here, morally?”
“Well, morally, this proof says...”
“Morally, this is true because...”
“Morally, there’s no reason for this axiom.”
“Morally, this question doesn’t make any sense.”
“What ought to happen here, morally?”
“This notation does work, but morally, it’s absurd!”
“Morally, this limit shouldn’t exist at all”
“Morally, there’s something higher-dimensional going on here.”Beauty/elegance is often the opposite of morality. An elegant proof is often a clever trick, a piece of magic as in Example 6 above, the sort of proof that drives you mad when you’re trying to understand something precisely because it’s so clever that it doesn’t explain anything at all.
Constructiveness is often the opposite of morality as well. If you’re proving the existence of something and you just construct it, you haven’t necessarily explained why the thing exists.
Morality doesn't mean 'explanatory' either. There are so many levels of explaining something. Explanatory to whom? To someone who’s interested in moral reasons. So we haven’t really got anywhere. The same goes for intuitive, obvious, useful, natural and clear, and as Thurston says: “one person’s clear mental image is another person’s intimidation”.
Minimality/efficiency is sometimes the opposite of morality too. Sometimes the most efficient way of proving something is actually the moral way backwards. eg quadratics. And the most minimal way of presenting a theory is not necessarily the morally right way. For example, it is possible to show that a group is a set X equipped with one binary operation / satisfying the single axiom for all x, y, z ∈ X, (x/((((x/x)/y)/z)/(((x/x)/x)/z))) = y. The fact that something works is not good enough to be a moral reason.
Polya’s notion of ‘plausible reasoning’ at first sight might seem to fit the bill because it appears to be about how mathematicians decide that something is ‘plausible’ before sitting down to try and prove it. But in fact it’s somewhat probabilistic. This is not the same as a moral reason. It’s more like gathering a lot of evidence and deciding that all the evidence points to one conclusion, without there actually being a reason necessarily. Like in court, having evidence but no motive.
Abstraction perhaps gets closer to morality, along with ‘general’, ‘deep’, ‘conceptual’. But I would say that it’s the search for morality that motivates abstraction, the search for the moral reason motivates the search for greater generalities, depth and conceptual understanding. ...
Proof has a sociological role; morality has a personal role. Proof is what convinces society; morality is what convinces us. Brouwer believed that a construction can never be perfectly communicated by verbal or symbolic language; rather it’s a process within the mind of an individual mathematician. What we write down is merely a language for communicating something to other mathematicians, in the hope that they will be able to reconstruct the process within their own mind. When I’m doing maths I often feel like I have to do it twice—once, morally in my head. And then once to translate it into communicable form. The translation is not a trivial process; I am going to encapsulate it as the process of moving from one form of truth to another.
Transmitting beliefs directly is unfeasible, but the question that does leap out of this is: what about the reason? Why don’t I just send the reason directly to X, thus eliminating the two probably hardest parts of this process? The answer is that a moral reason is harder to communicate than a proof. The key characteristic about proof is not its infallibility, not its ability to convince but its transferability. Proof is the best medium for communicating my argument to X in a way which will not be in danger of ambiguity, misunderstanding, or defeat. Proof is the pivot for getting from one person to another, but some translation is needed on both sides. So when I read an article, I always hope that the author will have included a reason and not just a proof, in case I can convince myself of the result without having to go to all the trouble of reading the fiddly proof.
That last part is quite reminiscent of what the late Bill Thurston argued in his classic On proof and progress in mathematics:
Mathematicians have developed habits of communication that are often dysfunctional. Organizers of colloquium talks everywhere exhort speakers to explain things in elementary terms. Nonetheless, most of the audience at an average colloquium talk gets little of value from it. Perhaps they are lost within the first 5 minutes, yet sit silently through the remaining 55 minutes. Or perhaps they quickly lose interest because the speaker plunges into technical details without presenting any reason to investigate them. At the end of the talk, the few mathematicians who are close to the field of the speaker ask a question or two to avoid embarrassment.
This pattern is similar to what often holds in classrooms, where we go through the motions of saying for the record what we think the students “ought” to learn, while the students are trying to grapple with the more fundamental issues of learning our language and guessing at our mental models. Books compensate by giving samples of how to solve every type of homework problem. Professors compensate by giving homework and tests that are much easier than the material “covered” in the course, and then grading the homework and tests on a scale that requires little understanding. We assume that the problem is with the students rather than with communication: that the students either just don’t have what it takes, or else just don’t care.
Outsiders are amazed at this phenomenon, but within the mathematical community, we dismiss it with shrugs.
Much of the difficulty has to do with the language and culture of mathematics, which is divided into subfields. Basic concepts used every day within one subfield are often foreign to another subfield. Mathematicians give up on trying to understand the basic concepts even from neighboring subfields, unless they were clued in as graduate students.
In contrast, communication works very well within the subfields of mathematics. Within a subfield, people develop a body of common knowledge and known techniques. By informal contact, people learn to understand and copy each other’s ways of thinking, so that ideas can be explained clearly and easily.
Mathematical knowledge can be transmitted amazingly fast within a subfield. When a significant theorem is proved, it often (but not always) happens that the solution can be communicated in a matter of minutes from one person to another within the subfield. The same proof would be communicated and generally understood in an hour talk to members of the subfield. It would be the subject of a 15- or 20-page paper, which could be read and understood in a few hours or perhaps days by members of the subfield.
Why is there such a big expansion from the informal discussion to the talk to the paper? One-on-one, people use wide channels of communication that go far beyond formal mathematical language. They use gestures, they draw pictures and diagrams, they make sound effects and use body language. Communication is more likely to be two-way, so that people can concentrate on what needs the most attention. With these channels of communication, they are in a much better position to convey what’s going on, not just in their logical and linguistic facilities, but in their other mental facilities as well.
In talks, people are more inhibited and more formal. Mathematical audiences are often not very good at asking the questions that are on most people’s minds, and speakers often have an unrealistic preset outline that inhibits them from addressing questions even when they are asked.
In papers, people are still more formal. Writers translate their ideas into symbols and logic, and readers try to translate back.
Why is there such a discrepancy between communication within a subfield and communication outside of subfields, not to mention communication outside mathematics? Mathematics in some sense has a common language: a language of symbols, technical definitions, computations, and logic. This language efficiently conveys some, but not all, modes of mathematical thinking. Mathematicians learn to translate certain things almost unconsciously from one mental mode to the other, so that some statements quickly become clear. Different mathematicians study papers in different ways, but when I read a mathematical paper in a field in which I’m conversant, I concentrate on the thoughts that are between the lines. I might look over several paragraphs or strings of equations and think to myself “Oh yeah, they’re putting in enough rigamarole to carry such-and-such idea.” When the idea is clear, the formal setup is usually unnecessary and redundant—I often feel that I could write it out myself more easily than figuring out what the authors actually wrote. It’s like a new toaster that comes with a 16-page manual. If you already understand toasters and if the toaster looks like previous toasters you’ve encountered, you might just plug it in and see if it works, rather than first reading all the details in the manual.
People familiar with ways of doing things in a subfield recognize various patterns of statements or formulas as idioms or circumlocution for certain concepts or mental images. But to people not already familiar with what’s going on the same patterns are not very illuminating; they are often even misleading. The language is not alive except to those who use it.
Thurston's personal reflections below on the sociology of proof exemplify the search for mathematical morality instead of fully formally rigorous correctness. I remember being disquieted upon first reading "There were published theorems that were generally known to be false" a long time ago:
When I started as a graduate student at Berkeley, I had trouble imagining how I could “prove” a new and interesting mathematical theorem. I didn’t really understand what a “proof” was.
By going to seminars, reading papers, and talking to other graduate students, I gradually began to catch on. Within any field, there are certain theorems and certain techniques that are generally known and generally accepted. When you write a paper, you refer to these without proof. You look at other papers in the field, and you see what facts they quote without proof, and what they cite in their bibliography. You learn from other people some idea of the proofs. Then you’re free to quote the same theorem and cite the same citations. You don’t necessarily have to read the full papers or books that are in your bibliography. Many of the things that are generally known are things for which there may be no known written source. As long as people in the field are comfortable that the idea works, it doesn’t need to have a formal written source.
At first I was highly suspicious of this process. I would doubt whether a certain idea was really established. But I found that I could ask people, and they could produce explanations and proofs, or else refer me to other people or to written sources that would give explanations and proofs. There were published theorems that were generally known to be false, or where the proofs were generally known to be incomplete. Mathematical knowledge and understanding were embedded in the minds and in the social fabric of the community of people thinking about a particular topic. This knowledge was supported by written documents, but the written documents were not really primary.
I think this pattern varies quite a bit from field to field. I was interested in geometric areas of mathematics, where it is often pretty hard to have a document that reflects well the way people actually think. In more algebraic or symbolic fields, this is not necessarily so, and I have the impression that in some areas documents are much closer to carrying the life of the field. But in any field, there is a strong social standard of validity and truth. Andrew Wiles’s proof of Fermat’s Last Theorem is a good illustration of this, in a field which is very algebraic. The experts quickly came to believe that his proof was basically correct on the basis of high-level ideas, long before details could be checked. This proof will receive a great deal of scrutiny and checking compared to most mathematical proofs; but no matter how the process of verification plays out, it helps illustrate how mathematics evolves by rather organic psychological and social processes.
Since then I've come to conclude that string theory is probably a dead end, albeit an astonishingly alluring one for a particular type of person.
The more you know about particle physics and quantum field theory, the more inevitable string theory seems. There are just too many connections. However, identifying the specific form of string theory that corresponds to our universe is more of a challenge, and not just because of the fabled 10^500 vacua (though it could be one of those). We don't actually know either all the possible forms of string theory, or the right way to think about the physics that we can see. The LHC, with its "unnaturally" light Higgs boson, already mortally wounded a particular paradigm for particle physics (naturalness) which in turn was guiding string phenomenology (i.e. the part of string theory that tries to be empirically relevant). So along with the numerical problem of being able to calculate the properties of a given string vacuum, the conceptual side of string theory and string phenomenology is still wide open for discovery.
I asked a well-known string theorist about the fabled 10^500 vacua and asked him whether he worried that this would make string theory a vacuous theory since a theory that fits anything fits nothing. He replied ' no, no the 10^500 'swampland' is a great achievement of string theory - you see... all other theories have infinitely many adjustable parameters'. He was saying string theory was about ~1500 bits away from the theory of everything but infinitely ahead of its competitors.
Diabolical.
Much ink has been spilled on the scientific merits and demerits of string theory and its competitors. The educated reader will recognize that this all this and more is of course, once again, solved by UDASSA.
Re other theories, I don't think that all other theories in existence have infinitely many adjustable parameters, and if he's referring to the fact that lots of theories have adjustable parameters that can range over the real numbers, which are infinitely complicated in general, than that's different, and string theory may have this issue as well.
Re string theory's issue of being vacuous, I think the core thing that string theory predicts that other quantum gravity models don't is that at the large scale, you recover general relativity and the standard model, whereas no other theory can yet figure out a way to properly include both the empirical effects of gravity and quantum mechanics in the parameter regimes where they are known to work, so string theory predicts more just by predicting the things other quantum mechanics predicts while having the ability to include in gravity without ruining the other predictions, whereas other models of quantum gravity tend to ruin empirical predictions like general relativity approximately holding pretty fast.
I used to consider it a mystery that math was so unreasonably effective in the natural sciences, but changed my mind after reading this essay by Eric S. Raymond (who's here on the forum, hi and thanks Eric), in particular this part, which is as good a question dissolution as any I've seen:
The relationship between mathematical models and phenomenal prediction is complicated, not just in practice but in principle. Much more complicated because, as we now know, there are mutually exclusive ways to axiomatize mathematics! It can be diagrammed as follows (thanks to Jesse Perry for supplying the original of this chart):
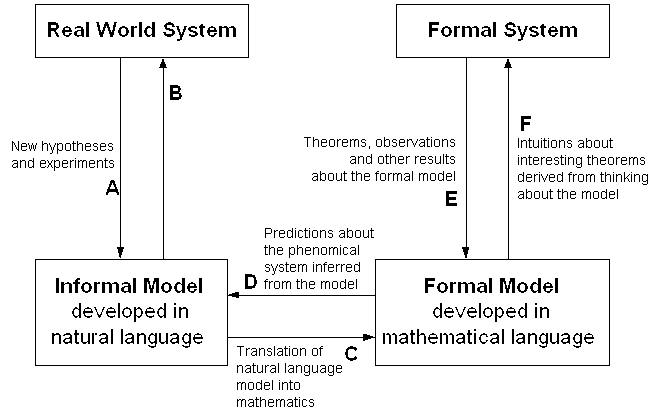
(it's a shame this chart isn't rendering properly for some reason, since without it the rest of Eric's quote is ~incomprehensible)
The key transactions for our purposes are C and D -- the translations between a predictive model and a mathematical formalism. What mystified Einstein is how often D leads to new insights.
We begin to get some handle on the problem if we phrase it more precisely; that is, "Why does a good choice of C so often yield new knowledge via D?"
The simplest answer is to invert the question and treat it as a definition. A "good choice of C" is one which leads to new predictions. The choice of C is not one that can be made a-priori; one has to choose, empirically, a mapping between real and mathematical objects, then evaluate that mapping by seeing if it predicts well.
One can argue that it only makes sense to marvel at the utility of mathematics if one assumes that C for any phenomenal system is an a-priori given. But we've seen that it is not. A physicist who marvels at the applicability of mathematics has forgotten or ignored the complexity of C; he is really being puzzled at the human ability to choose appropriate mathematical models empirically.
By reformulating the question this way, we've slain half the dragon. Human beings are clever, persistent apes who like to play with ideas. If a mathematical formalism can be found to fit a phenomenal system, some human will eventually find it. And the discovery will come to look "inevitable" because those who tried and failed will generally be forgotten.
But there is a deeper question behind this: why do good choices of mathematical model exist at all? That is, why is there any mathematical formalism for, say, quantum mechanics which is so productive that it actually predicts the discovery of observable new particles?
The way to "answer" this question is by observing that it, too, properly serves as a kind of definition. There are many phenomenal systems for which no such exact predictive formalism has been found, nor for which one seems likely. Poets like to mumble about the human heart, but more mundane examples are available. The weather, or the behavior of any economy larger than village size, for example -- systems so chaotically interdependent that exact prediction is effectively impossible (not just in fact but in principle).
There are many things for which mathematical modeling leads at best to fuzzy, contingent, statistical results and never successfully predicts 'new entities' at all. In fact, such systems are the rule, not the exception. So the proper answer to the question "Why is mathematics is so marvelously applicable to my science?" is simply "Because that's the kind of science you've chosen to study!"
I also think I was intuition-pumped to buy Eric's argument by Julie Moronuki's beautiful meandering essay The Unreasonable Effectiveness of Metaphor.
Interesting. This reminds me of a related thought I had: Why do models with differential equations work so often in physics but so rarely in other empirical sciences? Perhaps physics simply is "the differential equation science".
Which is also related to the frequently expressed opinion that philosophy makes little progress because everything that gets developed enough to make significant progress splits off from philosophy. Because philosophy is "the study of ill-defined and intractable problems".
Not saying that I think these views are accurate, though they do have some plausibility.
The weather, or the behavior of any economy larger than village size, for example -- systems so chaotically interdependent that exact prediction is effectively impossible (not just in fact but in principle).
Flagging that those two examples seem false. The weather is chaotic, yes, and there's a sense in which the economy is anti-inductive, but modeling methods are advancing, and will likely find more loop-holes in chaos theory.
For example, in thermodynamics, temperature is non-chaotic while the precise kinetic energies and locations of all particles are. A reasonable candidate similarity in weather are hurricanes.
Similarly as our understanding of the economy advances it will get more efficient which means it will be easier to model. eg (note: I've only skimmed this paper). And definitely large economies are even more predictable than small villages, talk about not having a competitive market!
Thanks for the pointer to that paper, the abstract makes me think there's a sort of slow-acting self-reinforcing feedback loop between predictive error minimisation via improving modelling and via improving the economy itself.
re: weather, I'm thinking of the chart below showing how little gain we get in MAE vs compute, plus my guess that compute can't keep growing far enough to get MAE < 3 °F a year out (say). I don't know anything about advancements in weather modelling methods though; maybe effective compute (incorporating modelling advancements) may grow indefinitely in terms of the chart.
I didn't say anything about temperature prediction, and I'd also like to see any other method (intuition based or otherwise) do better than the current best mathematical models here. It seems unlikely to me that the trends in that graph will continue arbitrarily far.
Thanks for the pointer to that paper, the abstract makes me think there's a sort of slow-acting self-reinforcing feedback loop between predictive error minimisation via improving modelling and via improving the economy itself.
Yeah, that was my claim.
I would also comment that, if the environment was so chaotic that roughly everything important to life could not be modeled—if general-purpose modeling ability was basically useless—then life would not have evolved that ability, and "intelligent life" probably wouldn't exist.
The two concepts that I thought were missing from Eliezer's technical explanation of technical explanation that would have simplified some of the explanation were compression and degrees of freedom. Degrees of freedom seems very relevant here in terms of how we map between different representations. Why are representations so important for humans? Because they have different computational properties/traversal costs while humans are very computationally limited.
Can you say more about what you mean? Your comment reminded me of Thomas Griffiths' paper Understanding Human Intelligence through Human Limitations, but you may have meant something else entirely.
Griffiths argued that the aspects we associate with human intelligence – rapid learning from small data, the ability to break down problems into parts, and the capacity for cumulative cultural evolution – arose from the 3 fundamental limitations all humans share: limited time, limited computation, and limited communication. (The constraints imposed by these characteristics cascade: limited time magnifies the effect of limited computation, and limited communication makes it harder to draw upon more computation.) In particular, limited computation leads to problem decomposition, hence modular solutions; relieving the computation constraint enables solutions that can be objectively better along some axis while also being incomprehensible to humans.
Thanks for the link. I mean that predictions are outputs of a process that includes a representation, so part of what's getting passed back and forth in the diagram are better and worse fit representations. The degrees of freedom point is that we choose very flexible representations, whittle them down with the actual data available, then get surprised that that representation yields other good predictions. But we should expect this if Nature shares any modular structure with our perception at all, which it would if there was both structural reasons (literally same substrate) and evolutionary pressure for representations with good computational properties i.e. simple isomorphisms and compressions.
Matt Leifer, who works in quantum foundations, espouses a view that's probably more extreme than Eric Raymond's above to argue why the effectiveness of math in the natural sciences isn't just reasonable but expected-by-construction. In his 2015 FQXi essay Mathematics is Physics Matt argued that
... mathematics is a natural science—just like physics, chemistry, or biology—and that this can explain the alleged “unreasonable” effectiveness of mathematics in the physical sciences.
The main challenge for this view is to explain how mathematical theories can become increasingly abstract and develop their own internal structure, whilst still maintaining an appropriate empirical tether that can explain their later use in physics. In order to address this, I offer a theory of mathematical theory-building based on the idea that human knowledge has the structure of a scale-free network and that abstract mathematical theories arise from a repeated process of replacing strong analogies with new hubs in this network.
This allows mathematics to be seen as the study of regularities, within regularities, within . . . , within regularities of the natural world. Since mathematical theories are derived from the natural world, albeit at a much higher level of abstraction than most other scientific theories, it should come as no surprise that they so often show up in physics.
... mathematical objects do not refer directly to things that exist in the physical universe. As the formalists suggest, mathematical theories are just abstract formal systems, but not all formal systems are mathematics. Instead, mathematical theories are those formal systems that maintain a tether to empirical reality through a process of abstraction and generalization from more empirically grounded theories, aimed at achieving a pragmatically useful representation of regularities that exist in nature.
(Matt notes as an aside that he's arguing for precisely the opposite of Tegmark's MUH.)
Why "scale-free network"?
It is common to view the structure of human knowledge as hierarchical... The various attempts to reduce all of mathematics to logic or arithmetic reflect a desire view mathematical knowledge as hanging hierarchically from a common foundation. However, the fact that mathematics now has multiple competing foundations, in terms of logic, set theory or category theory, indicates that something is wrong with this view.
Instead of a hierarchy, we are going to attempt to characterize the structure of human knowledge in terms of a network consisting of nodes with links between them... Roughly speaking, the nodes are
supposed to represent different fields of study. This could be done at various levels of detail. ... Next, a link should be drawn between two nodes if there is a strong connection between the things they represent. Again, I do not want to be too precise about what this connection should be, but examples would include an idea being part of a wider theory, that one thing can be derived from the other, or that there exists a strong direct analogy between the two nodes. Essentially, if it has occurred to a human being that the two things are strongly related, e.g. if it has been thought interesting enough to do something like publish an academic paper on the connection, and the connection has not yet been explained in terms of some intermediary theory, then there should be a link between the corresponding nodes in the network.If we imagine drawing this network for all of human knowledge then it is plausible that it would have
the structure of a scale-free network. Without going into technical details, scale-free networks have a small number of hubs, which are nodes that are linked to a much larger number of nodes than the average. This is a bit like the 1% of billionaires who are much richer than the rest of the human population. If the knowledge network is scale-free then this would explain why it seems so plausible that knowledge is hierarchical. In a university degree one typically learns a great deal about one of the hubs, e.g. the hub representing fundamental physics, and a little about some of the more specialized subjects that hang from it. As we get ever more specialized, we typically move away from our starting hub towards more obscure nodes, which are nonetheless still much closer to the starting hub than to any other hub. The local part of the network that we know about looks much like a hierarchy, and so it is not surprising that physicists end up thinking that everything boils down to physics whereas sociologists end up thinking that everything is a social construct. In reality, neither of these views is right because the global structure of the network is not a hierarchy.As a naturalist, I should provide empirical evidence that human knowledge is indeed structured as a scale-free network. The best evidence that I can offer is that the structure of pages and links on the Word Wide Web and the network of citations to academic papers are both scale free [13]. These are, at best, approximations of the true knowledge network. ... However, I think that these examples provide evidence that the information structures generated by a social network of finite beings are typically scale-free networks, and the knowledge network is an example of such a structure.
As an aside, Matt's theory of theory-building explains (so he claims) what mathematical intuition is about: "intuition for efficient knowledge structure, rather than intuition about an abstract mathematical world".
So what? How does this view pay rent?
Firstly, in network language, the concept of a “theory of everything” corresponds to a network with one enormous hub, from which all other human knowledge hangs via links that mean “can be derived from”. This represents a hierarchical view of knowledge, which seems unlikely to be true if the structure of human knowledge is generated by a social process. It is not impossible for a scale-free network to have a hierarchical structure like a branching tree, but it seems unlikely that the process of knowledge growth would lead uniquely to such a structure. It seems more likely that we will always have several competing large hubs and that some aspects of human experience, such as consciousness and why we experience a unique present moment of time, will be forever outside the scope of physics.
Nonetheless, my theory suggests that the project of finding higher level connections that encompass more of human knowledge is still a fruitful one. It prevents our network from having an unwieldy number of direct links, allows us to share more common vocabulary between fields, and allows an individual to understand more of the world with fewer theories. Thus, the search for a theory of everything is not fruitless; I just do not expect it to ever terminate.
Secondly, my theory predicts that the mathematical representation of fundamental physical theories will continue to become increasingly abstract. The more phenomena we try to encompass in our fundamental theories, the further the resulting hubs will be from the nodes representing our direct sensory experience. Thus, we should not expect future theories of physics to become less mathematical, as they are generated by the same process of generalization and abstraction as mathematics itself.
Matt further develops the argument that the structure of human knowledge being networked-not-hierarchical implies that the idea that there is a most fundamental discipline, or level of reality, is mistaken in Against Fundamentalism, another FQXi essay published in 2018.
What fraction of economically-valuable cognitive labor is already being automated today? How has that changed over time, especially recently?
I notice I'm confused about these ostensibly extremely basic questions, which arose in reading Open Phil's old CCF-takeoff report, whose main metric is "time from AI that could readily[2] automate 20% of cognitive tasks to AI that could readily automate 100% of cognitive tasks". A cursory search of Epoch's data, Metaculus, and this forum didn't turn up anything, but I didn't spend much time at all doing so.
I was originally motivated by wanting to empirically understand recursive AI self-improvement better, which led to me stumbling upon the CAIS paper Examples of AI Improving AI, but I don't have any sense whatsoever of how the paper's 39 examples as of Oct-2023 translate to OP's main metric even after constraining "cognitive tasks" in its operational definition to just AI R&D.
I did find this 2018 survey of expert opinion
A survey was administered to attendees of three AI conferences during the summer of 2018 (ICML, IJCAI and the HLAI conference). The survey included questions for estimating AI capabilities over the next decade, questions for forecasting five scenarios of transformative AI and questions concerning the impact of computational resources in AI research. Respondents indicated a median of 21.5% of human tasks (i.e., all tasks that humans are currently paid to do) can be feasibly automated now, and that this figure would rise to 40% in 5 years and 60% in 10 years
which would suggest that OP's clock should've started ticking in 2018, so that incorporating CCF-takeoff author Tom Davidson's "~50% to a <3 year takeoff and ~80% to <10 year i.e. time from 20%-AI to 100%-AI, for cognitive tasks in the global economy" means takeoff should've already occurred... so I'm dismissing this survey's relevance to my question (sorry).
What fraction of economically-valuable cognitive labor is already being automated today?
Did e.g. a telephone operator in 1910 perform cognitive labor, by the definition we want to use here?
I'm mainly wondering how Open Phil, and really anyone who uses fraction of economically-valuable cognitive labor automated / automatable (e.g. the respondents to that 2018 survey; some folks on the forum) as a useful proxy for thinking about takeoff, tracks this proxy as a way to empirically ground their takeoff-related reasoning. If you're one of them, I'm curious if you'd answer your own question in the affirmative?
I am not one of them - I was wondering the same thing, and was hoping you had a good answer.
If I was trying to answer this question, I would probably try to figure out what fraction of all economically-valuable labor each year was cognitive, the breakdown of which tasks comprise that labor, and the year-on-year productivity increases on those task, then use that to compute the percentage of economically-valuable labor that is being automated that year.
Concretely, to get a number for the US in 1900 I might use a weighted average of productivity increases across cognitive tasks in 1900, in an approach similar to how CPI is computed
- Look at the occupations listed in the 1900 census records
- Figure out which ones are common, and then sample some common ones and make wild guesses about what those jobs looked like in 1900
- Classify those tasks as cognitive or non-cognitive
- Come to estimate that record-keeping tasks are around a quarter to a half of all cognitive labor
- Notice that typewriters were starting to become more popular - about 100,000 typewriters sold per year
- Note that those 100k typewriters were going to the people who would save the most time by using them
- As such, estimate 1-2% productivity growth in record-keeping tasks in 1900
- Multiply the productivity growth for record-keeping tasks by the fraction of time (technically actually 1-1/productivity increase but when productivity increase is small it's not a major factor)
- Estimate that 0.5% of cognitive labor was automated by specifically typewriters in 1900
- Figure that's about half of all cognitive labor automation in 1900
and thus I would estimate ~1% of all cognitive labor was automated in 1900. By the same methodology I would probably estimate closer to 5% for 2024.
Again, though, I am not associated with Open Phil and am not sure if they think about cognitive task automation in the same way.
Unbundling Tools for Thought is an essay by Fernando Borretti I found via Gwern's comment which immediately resonated with me (emphasis mine):
I’ve written something like six or seven personal wikis over the past decade. It’s actually an incredibly advanced form of procrastination1. At this point I’ve tried every possible design choice.
Lifecycle: I’ve built a few compiler-style wikis: plain-text files in a
gitrepo statically compiled to HTML. I’ve built a couple using live servers with server-side rendering. The latest one is an API server with a React frontend.Storage: I started with plain text files in a git repo, then moved to an SQLite database with a simple schema. The latest version is an avant-garde object-oriented hypermedia database with bidirectional links implemented on top of SQLite.
Markup: I used Markdown here and there. Then I built my own TeX-inspired markup language. Then I tried XML, with mixed results. The latest version uses a WYSIWYG editor made with ProseMirror.
And yet I don’t use them. Why? Building them was fun, sure, but there must be utility to a personal database.
At first I thought the problem was friction: the higher the activation energy to using a tool, the less likely you are to use it. Even a small amount of friction can cause me to go, oh, who cares, can’t be bothered. So each version gets progressively more frictionless2. The latest version uses a WYSIWYG editor built on top of ProseMirror (it took a great deal for me to actually give in to WYSIWYG). It also has a link to the daily note page, to make journalling easier. The only friction is in clicking the bookmark to
localhost:5000. It is literally two clicks to get to the daily note.And yet I still don’t use it. Why? I’m a great deal more organized now than I was a few years ago. My filesystem is beautifully structured and everything is where it should be. I could fill out the contents of a personal wiki.
I’ve come to the conclusion that there’s no point: because everything I can do with a personal wiki I can do better with a specialized app, and the few remaining use cases are useless. Let’s break it down.
I've tried three different times to create a personal wiki, using the last one for a solid year and a half before finally giving up and just defaulting to a janky combination of Notion and Google Docs/Sheets, seduced by sites like Cosma Shalizi's and Gwern's long content philosophy (emphasis mine):
... I have read blogs for many years and most blog posts are the triumph of the hare over the tortoise. They are meant to be read by a few people on a weekday in 2004 and never again, and are quickly abandoned—and perhaps as Assange says, not a moment too soon. (But isn’t that sad? Isn’t it a terrible ROI for one’s time?) On the other hand, the best blogs always seem to be building something: they are rough drafts—works in progress15. So I did not wish to write a blog. Then what? More than just “evergreen content”, what would constitute Long Content as opposed to the existing culture of Short Content? How does one live in a Long Now sort of way?16
My answer is that one uses such a framework to work on projects that are too big to work on normally or too tedious. (Conscientiousness is often lacking online or in volunteer communities18 and many useful things go undone.) Knowing your site will survive for decades to come gives you the mental wherewithal to tackle long-term tasks like gathering information for years, and such persistence can be useful19—if one holds onto every glimmer of genius for years, then even the dullest person may look a bit like a genius himself20. (Even experienced professionals can only write at their peak for a few hours a day—usually first thing in the morning, it seems.) Half the challenge of fighting procrastination is the pain of starting—I find when I actually get into the swing of working on even dull tasks, it’s not so bad. So this suggests a solution: never start. Merely have perpetual drafts, which one tweaks from time to time. And the rest takes care of itself.
Fernando unbundles the use cases of a tool for thought in his essay; I'll just quote the part that resonated with me:
The following use cases are very naturally separable: ...
Learning: if you’re studying something, you can keep your notes in a TfT. This is one of the biggest use cases. But the problem is never note-taking, but reviewing notes. Over the years I’ve found that long-form lecture notes are all but useless, not just because you have to remember to review them on a schedule, but because spaced repetition can subsume every single lecture note. It takes practice and discipline to write good spaced repetition flashcards, but once you do, the long-form prose notes are themselves redundant.
(Tangentially, an interesting example of how comprehensively subsuming spaced repetition is is Michael Nielsen's Using spaced repetition systems to see through a piece of mathematics, in which he describes how he used "deep Ankification" to better understand the theorem that a complex normal matrix is always diagonalizable by a unitary matrix, as an illustration of a heuristic one could use to deepen one's understanding of a piece of mathematics in an open-ended way, inspired by Andrey Kolmogorov's essay on, of all things, the equals sign. I wish I read that while I was still studying physics in school.)
Fernando, emphasis mine:
So I often wonder: what do other people use their personal knowledge bases for? And I look up blog and forum posts where Obsidian and Roam power users explain their setup. And most of what I see is junk. It’s never the Zettelkasten of the next Vannevar Bush, it’s always a setup with tens of plugins, a daily note three pages long that is subdivided into fifty subpages recording all the inane minutiae of life. This is a recipe for burnout.
People have this aspirational idea of building a vast, oppressively colossal, deeply interlinked knowledge graph to the point that it almost mirrors every discrete concept and memory in their brain. And I get the appeal of maximalism. But they’re counting on the wrong side of the ledger. Every node in your knowledge graph is a debt. Every link doubly so. The more you have, the more in the red you are. Every node that has utility—an interesting excerpt from a book, a pithy quote, a poem, a fiction fragment, a few sentences that are the seed of a future essay, a list of links that are the launching-off point of a project—is drowned in an ocean of banality. Most of our thoughts appear and pass away instantly, for good reason.
Minimizing friction is surprisingly difficult. I keep plain-text notes in a hierarchical editor (cherrytree), but even that feels too complicated sometimes. This is not just about the tool... what you actually need is a combination of the tool and the right way to use it.
(Every tool can be used in different ways. For example, suppose you write a diary in MS Word. There are still options such as "one document per day" or "one very long document for all", and things in between like "one document per month", which all give different kinds of friction. The one megadocument takes too much time to load. It is more difficult to search in many small documents. Or maybe you should keep your current day in a small document, but once in a while merge the previous days into the megadocument? Or maybe switch to some application that starts faster than MS Word?)
Forgetting is an important part. Even if you want to remember forever, you need some form of deprioritizing. Something like "pages you haven't used for months will get smaller, and if you search for keywords, they will be at the bottom of the result list". But if one of them suddenly becomes relevant again, maybe the connected ones become relevant, too? Something like associations in brain. The idea is that remembering the facts is only a part of the problem; making the relevant ones more accessible is another. Because searching in too much data is ultimately just another kind of friction.
It feels like a smaller version of the internet. Years ago, the problem used to be "too little information", now the problem is "too much information, can't find the thing I actually want".
Perhaps a wiki, where the pages could get flagged as "important now" and "unimportant"? Or maybe, important for a specific context? And by default, when you choose a context, you would only see the important pages, and the rest of that only if you search for a specific keyword or follow a grey link. (Which again would require some work creating and maintaining the contexts. And that work should also be as frictionless as possible.)
@dkl9 wrote a very eloquent and concise piece arguing in favor of ditching "second brain" systems in favor of SRSs (Spaced Repetition Systems, such as Anki).
Try as you might to shrink the margin with better technology, recalling knowledge from within is necessarily faster and more intuitive than accessing a tool. When spaced repetition fails (as it should, up to 10% of the time), you can gracefully degrade by searching your SRS' deck of facts.
If you lose your second brain (your files get corrupted, a cloud service shuts down, etc), you forget its content, except for the bits you accidentally remember by seeing many times. If you lose your SRS, you still remember over 90% of your material, as guaranteed by the algorithm, and the obsolete parts gradually decay. A second brain is more robust to physical or chemical damage to your first brain. But if your first brain is damaged as such, you probably have higher priorities than any particular topic of global knowledge you explicitly studied.
I write for only these reasons:
- to help me think
- to communicate and teach (as here)
- to distill knowledge to put in my SRS
- to record local facts for possible future reference
Linear, isolated documents suffice for all those purposes. Once you can memorise well, a second brain becomes redundant tedium.
I like to think of learning and all of these things as self-contained smaller self-contained knowledge trees. Building knowledge trees that are cached, almost like creatin zip files and systems where I store a bunch of zip files similar to what Elizier talks about in The Sequences.
Like when you mention the thing about Nielsen on linear algebra it opens up the entire though tree there. I might just get the association to something like PCA and then I think huh, how to ptimise this and then it goes to QR-algorithms and things like a householder matrix and some specific symmetric properties of linear spaces...
If I have enough of these in an area then I might go back to my anki for that specific area. Like if you think from the perspective of schedulling and storage algorithms similar to what is explored in algorithms to live by you quickly understand that the magic is in information compression and working at different meta-levels. Zipped zip files with algorithms to expand them if need be. Dunno if that makes sense, agree with the exobrain creep that exists though.
I currently work in policy research, which feels very different from my intrinsic aesthetic inclination, in a way that I think Tanner Greer captures well in The Silicon Valley Canon: On the Paıdeía of the American Tech Elite:
I often draw a distinction between the political elites of Washington DC and the industrial elites of Silicon Valley with a joke: in San Francisco reading books, and talking about what you have read, is a matter of high prestige. Not so in Washington DC. In Washington people never read books—they just write them.
To write a book, of course, one must read a good few. But the distinction I drive at is quite real. In Washington, the man of ideas is a wonk. The wonk is not a generalist. The ideal wonk knows more about his or her chosen topic than you ever will. She can comment on every line of a select arms limitation treaty, recite all Chinese human rights violations that occurred in the year 2023, or explain to you the exact implications of the new residential clean energy tax credit—but never all at once. ...
Washington intellectuals are masters of small mountains. Some of their peaks are more difficult to summit than others. Many smaller slopes are nonetheless jagged and foreboding; climbing these is a mark of true intellectual achievement. But whether the way is smoothly paved or roughly made, the destinations are the same: small heights, little occupied. Those who reach these heights can rest secure. Out of humanity’s many billions there are only a handful of individuals who know their chosen domain as well as they do. They have mastered their mountain: they know its every crag, they have walked its every gully. But it is a small mountain. At its summit their field of view is limited to the narrow range of their own expertise.
In Washington that is no insult: both legislators and regulators call on the man of deep but narrow learning. Yet I trust you now see why a city full of such men has so little love for books. One must read many books, laws, and reports to fully master one’s small mountain, but these are books, laws, and reports that the men of other mountains do not care about. One is strongly encouraged to write books (or reports, which are simply books made less sexy by having an “executive summary” tacked up front) but again, the books one writes will be read only by the elect few climbing your mountain.
The social function of such a book is entirely unrelated to its erudition, elegance, or analytical clarity. It is only partially related to the actual ideas or policy recommendations inside it. In this world of small mountains, books and reports are a sort of proof, a sign of achievement that can be seen by climbers of other peaks. An author has mastered her mountain. The wonk thirsts for authority: once she has written a book, other wonks will give it to her.
While I don't work in Washington, this description rings true to my experience, and I find it aesthetically undesirable. Greer contrasts this with the Silicon Valley aesthetic, which is far more like the communities I'm familiar with:
The technologists of Silicon Valley do not believe in authority. They merrily ignore credentials, discount expertise, and rebel against everything settled and staid. There is a charming arrogance to their attitude. This arrogance is not entirely unfounded. The heroes of this industry are men who understood in their youth that some pillar of the global economy might be completely overturned by an emerging technology. These industries were helmed by men with decades of experience; they spent millions—in some cases, billions—of dollars on strategic planning and market analysis. They employed thousands of economists and business strategists, all with impeccable credentials. Arrayed against these forces were a gaggle of nerds not yet thirty. They were armed with nothing but some seed funding, insight, and an indomitable urge to conquer.
And so they conquered.
This is the story the old men of the Valley tell; it is the dream that the young men of the Valley strive for. For our purposes it shapes the mindset of Silicon Valley in two powerful ways. The first is a distrust of established expertise. The technologist knows he is smart—and in terms of raw intelligence, he is in fact often smarter than any random small-mountain subject expert he might encounter. But intelligence is only one of the two altars worshiped in Silicon Valley. The other is action. The founders of the Valley invariably think of themselves as men of action: they code, they build, disrupt, they invent, they conquer. This is a culture where insight, intelligence, and knowledge are treasured—but treasured as tools of action, not goods in and of themselves.
This silicon union of intellect and action creates a culture fond of big ideas. The expectation that anyone sufficiently intelligent can grasp, and perhaps master, any conceivable subject incentivizes technologists to become conversant in as many subjects as possible. The technologist is thus attracted to general, sweeping ideas with application across many fields. To a remarkable extent conversations at San Fransisco dinner parties morph into passionate discussions of philosophy, literature, psychology, and natural science. If the Washington intellectual aims for authority and expertise, the Silicon Valley intellectual seeks novel or counter-intuitive insights. He claims to judge ideas on their utility; in practice I find he cares mostly for how interesting an idea seems at first glance. He likes concepts that force him to puzzle and ponder.
This is fertile soil for the dabbler, the heretic, and the philosopher from first principles. It is also a good breeding ground for books. Not for writing books—being men of action, most Silicon Valley sorts do not have time to write books. But they make time to read books—or barring that, time to read the number of book reviews or podcast interviews needed to fool other people into thinking they have read a book (As an aside: I suspect this accounts somewhat for the popularity of this blog among the technologists. I am an able dealer in second-hand ideas).
I enjoyed Brian Potter's Energy infrastructure cheat sheet tables over at Construction Physics, it's a great fact post. Here are some of Brian's tables — if they whet your appetite, do check out his full essay.
Energy quantities:
Units and quantities | Kilowatt-hours | Megawatt-hours | Gigawatt-hours |
|---|---|---|---|
| 1 British Thermal Unit (BTU) | 0.000293 | ||
| iPhone 14 battery | 0.012700 | ||
| 1 pound of a Tesla battery pack | 0.1 | ||
| 1 cubic foot of natural gas | 0.3 | ||
| 2000 calories of food | 2.3 | ||
| 1 pound of coal | 2.95 | ||
| 1 gallon of milk (calorie value) | 3.0 | ||
| 1 gallon of gas | 33.7 | ||
| Tesla Model 3 standard battery pack | 57.5 | ||
| Typical ICE car gas tank (15 gallons) | 506 | ||
| 1 ton of TNT | 1,162 | ||
| 1 barrel of oil | 1,700 | ||
| 1 ton of oil | 11,629 | 12 | |
| Tanker truck full of gasoline (9300 gallons) | 313,410 | 313 | |
| LNG carrier (180,000 cubic meters) | 1,125,214,740 | 1,125,215 | 1,125 |
| 1 million tons of TNT (1 megaton) | 1,162,223,152 | 1,162,223 | 1,162 |
| Oil supertanker (2 million barrels) | 3,400,000,000 | 3,400,000 | 3,400 |
It's amazing that a Tesla Model 3's standard battery pack has an OOM less energy capacity than a typical 15-gallon ICE car gas tank, and is probably heavier too, yet a Model 3 isn't too far behind in range and is far more performant. It's also amazing that an oil supertanker carries ~3 megatons(!) of TNT worth of energy.
Energy of various activities:
| Activity | Kilowatt-hours |
|---|---|
| Fired 9mm bullet | 0.0001389 |
| Making 1 pound of steel in an electric arc furnace | 0.238 |
| Driving a mile in a Tesla Model 3 | 0.240 |
| Making 1 pound of cement | 0.478 |
| Driving a mile in a 2025 ICE Toyota Corolla | 0.950 |
| Boiling a gallon of room temperature water | 2.7 |
| Synthesizing 1 kilogram of ammonia (NH3) via Haber-Bosch | 11.4 |
| Making 1 pound of aluminum via Hall-Heroult process | 7.0 |
| Average US household monthly electricity use | 899.0 |
| Moving a shipping container from Shanghai to Los Angeles | 2,000.0 |
| Average US household monthly gasoline use | 2,010.8 |
| Heating and cooling a 2500 ft2 home in California for a year | 4,615.9 |
| Heating and cooling a 2500 ft2 home in New York for a year | 23,445.8 |
| Average annual US energy consumption per capita | 81,900.0 |
Power output:
Activity or infrastructure | Kilowatts | Megawatts | Gigawatts |
|---|---|---|---|
| Sustainable daily output of a laborer | 0.08 | ||
| Output from 1 square meter of typical solar panels (21% efficiency) | 0.21 | ||
| Tesla wall connector | 11.50 | ||
| Tesla supercharger | 250 | ||
| Large on-shore wind turbine | 6,100 | 6 | |
| Typical electrical distribution line (15 kV) | 8,000 | 8 | |
| Large off-shore wind turbine | 14,700 | 15 | |
| Typical US gas pump | 20,220 | 20 | |
| Typical daily production of an oil well (500 barrels) | 35,417 | 35 | |
| Typical transmission line (150 kV) | 150,000 | 150 | |
| Large gas station (20 pumps) | 404,400 | 404 | |
| Large gas turbine | 500,000 | 500 | |
| Output from 1 square mile of typical solar panels | 543,900 | 544 | |
| Electrical output of a large nuclear power reactor | 1,000,000 | 1,000 | 1 |
| Single LNG carrier crossing the Atlantic (18 day trip time) | 2,604,664 | 2,605 | 3 |
| Nord Stream Gas pipeline | 33,582,500 | 33,583 | 34 |
| Trans Alaska pipeline | 151,300,000 | 151,300 | 151 |
| US electrical generation capacity | 1,189,000,000 | 1,189,000 | 1,189 |
This observation by Brian is remarkable:
A typical US gas pump operates at 10 gallons per minute (600 gallons an hour). At 33.7 kilowatt-hours per gallon of gas, that’s a power output of over 20 megawatts, greater than the power output of an 800-foot tall offshore wind turbine. The Trans-Alaska pipeline, a 4-foot diameter pipe, can move as much energy as 1,000 medium-sized transmission lines, and 8 such pipelines would move more energy than provided by every US electrical power plant combined.
US energy flows Sankey diagram by LLNL (a "quad" is short for “a quadrillion British Thermal Units,” or 293 terawatt-hours):

I had a vague inkling that a lot of energy is lost on the way to useful consumption, but I was surprised by the two-thirds fraction; the 61.5 quads of rejected energy is more than every other country in the world consumes except China. I also wrongly thought that the largest source of inefficiency was in transmission losses. Brian explains:
The biggest source of losses is probably heat engine inefficiencies. In our hydrocarbon-based energy economy, we often need to transform energy by burning fuel and converting the heat into useful work. There are limits to how efficiently we can transform heat into mechanical work (for more about how heat engines work, see my essay about gas turbines).
The thermal efficiency of an engine is the fraction of heat energy it can transform into useful work. Coal power plant typically operates at around 30 to 40% thermal efficiency. A combined cycle gas turbine will hit closer to 60% thermal efficiency. A gas-powered car, on the other hand, operates at around 25% thermal efficiency. The large fraction of energy lost by heat engines is why some thermal electricity generation plants list their capacity in MWe, the power output in megawatts of electricity.
Most other losses aren’t so egregious, but they show up at every step of the energy transportation chain. Moving electricity along transmission and distribution lines results in losses as some electrical energy gets converted into heat. Electrical transformers, which minimize these losses by transforming electrical energy into high-voltage, low-current before transmission, operate at around 98% efficiency or more.
I also didn't realise that biomass is so much larger than solar in the US (I expect this of developing countries), although likely not for long given the ~25% annual growth rate.
Energy conversion efficiency:
Energy equipment or infrastructure | Conversion efficiency |
|---|---|
| Tesla Model 3 electric motor | 97% |
| Electrical transformer | 97-99% |
| Transmission lines | 96-98% |
| Hydroelectric dam | 90% |
| Lithium-ion battery | 86-99+% |
| Natural gas furnace | 80-95% |
| Max multi-layer solar cell efficiency on earth | 68.70% |
| Max theoretical wind turbine efficiency (Betz limit) | 59% |
| Combined cycle natural gas plant | 55-60% |
| Typical wind turbine | 50% |
| Gas water heater | 50-60% |
| Typical US coal power plant | 33% |
| Max theoretical single-layer solar cell efficiency | 33.16% |
| Heat pump | 300-400% |
| Typical solar panel | 21% |
| Typical ICE car | 16-25% |
Finally, (US) storage:
Type | Quads of capacity |
|---|---|
| Grid electrical storage | 0.002 |
| Gas station underground tanks | 0.26 |
| Petroleum refineries | 3.58 |
| Other crude oil | 3.79 |
| Strategic petroleum reserve | 4.14 |
| Natural gas fields | 5.18 |
| Bulk petroleum terminals | 5.64 |
| Total | 22.59 |
I vaguely knew grid energy storage was much less than hydrocarbon, but I didn't realise it was 10,000 times less!
Peter Watts' 2006 novel Blindsight has this passage on what it's like to be a "scrambler", superintelligent yet nonsentient (in fact superintelligent because it's unencumbered by sentience), which I read a ~decade ago and found unforgettable:
Imagine you're a scrambler.
Imagine you have intellect but no insight, agendas but no awareness. Your circuitry hums with strategies for survival and persistence, flexible, intelligent, even technological—but no other circuitry monitors it. You can think of anything, yet are conscious of nothing.
You can't imagine such a being, can you? The term being doesn't even seem to apply, in some fundamental way you can't quite put your finger on.
Try.
Imagine that you encounter a signal. It is structured, and dense with information. It meets all the criteria of an intelligent transmission. Evolution and experience offer a variety of paths to follow, branch-points in the flowcharts that handle such input. Sometimes these signals come from conspecifics who have useful information to share, whose lives you'll defend according to the rules of kin selection. Sometimes they come from competitors or predators or other inimical entities that must be avoided or destroyed; in those cases, the information may prove of significant tactical value. Some signals may even arise from entities which, while not kin, can still serve as allies or symbionts in mutually beneficial pursuits. You can derive appropriate responses for any of these eventualities, and many others.
You decode the signals, and stumble:
I had a great time. I really enjoyed him. Even if he cost twice as much as any other hooker in the dome—
To fully appreciate Kesey's Quartet—
They hate us for our freedom—
Pay attention, now—
Understand.
There are no meaningful translations for these terms. They are needlessly recursive. They contain no usable intelligence, yet they are structured intelligently; there is no chance they could have arisen by chance.
The only explanation is that something has coded nonsense in a way that poses as a useful message; only after wasting time and effort does the deception becomes apparent. The signal functions to consume the resources of a recipient for zero payoff and reduced fitness. The signal is a virus.
Viruses do not arise from kin, symbionts, or other allies.
The signal is an attack.
And it's coming from right about there.
"Now you get it," Sascha said.
I shook my head, trying to wrap it around that insane, impossible conclusion. "They're not even hostile." Not even capable of hostility. Just so profoundly alien that they couldn't help but treat human language itself as a form of combat.
How do you say We come in peace when the very words are an act of war?
"That's why they won't talk to us," I realized.
"Only if Jukka's right. He may not be." It was James again, still quietly resisting, still unwilling to concede a point that even her other selves had accepted. I could see why. Because if Sarasti was right, scramblers were the norm: evolution across the universe was nothing but the endless proliferation of automatic, organized complexity, a vast arid Turing machine full of self-replicating machinery forever unaware of its own existence. And we—we were the flukes and the fossils. We were the flightless birds lauding our own mastery over some remote island while serpents and carnivores washed up on our shores.
Imagine a proliferation of Dyson swarms throughout the cosmos, all computing about as efficiently as physics allows, containing no sentience whatsoever. Bostrom's Disneyland with no children indeed.
(When I first learned about ChatGPT some years later, my first thought was "they're eerily reminiscent of scramblers and Rorschach".)
Why would this be plausible? Watts:
You invest so much in it, don't you? It's what elevates you above the beasts of the field, it's what makes you special. Homo sapiens, you call yourself. Wise Man. Do you even know what it is, this consciousness you cite in your own exaltation? Do you even know what it's for?
Maybe you think it gives you free will. Maybe you've forgotten that sleepwalkers converse, drive vehicles, commit crimes and clean up afterwards, unconscious the whole time. Maybe nobody's told you that even waking souls are only slaves in denial.
Make a conscious choice. Decide to move your index finger. Too late! The electricity's already halfway down your arm. Your body began to act a full half-second before your conscious self 'chose' to, for the self chose nothing; something else set your body in motion, sent an executive summary—almost an afterthought— to the homunculus behind your eyes. That little man, that arrogant subroutine that thinks of itself as the person, mistakes correlation for causality: it reads the summary and it sees the hand move, and it thinks that one drove the other.
But it's not in charge. You're not in charge. If free will even exists, it doesn't share living space with the likes of you.
Insight, then. Wisdom. The quest for knowledge, the derivation of theorems, science and technology and all those exclusively human pursuits that must surely rest on a conscious foundation. Maybe that's what sentience would be for— if scientific breakthroughs didn't spring fully-formed from the subconscious mind, manifest themselves in dreams, as full-blown insights after a deep night's sleep. It's the most basic rule of the stymied researcher: stop thinking about the problem. Do something else. It will come to you if you just stop being conscious of it.
Every concert pianist knows that the surest way to ruin a performance is to be aware of what the fingers are doing. Every dancer and acrobat knows enough to let the mind go, let the body run itself. Every driver of any manual vehicle arrives at destinations with no recollection of the stops and turns and roads traveled in getting there. You are all sleepwalkers, whether climbing creative peaks or slogging through some mundane routine for the thousandth time. You are all sleepwalkers.
Don't even try to talk about the learning curve. Don't bother citing the months of deliberate practice that precede the unconscious performance, or the years of study and experiment leading up to the gift-wrapped Eureka moment. So what if your lessons are all learned consciously? Do you think that proves there's no other way? Heuristic software's been learning from experience for over a hundred years. Machines master chess, cars learn to drive themselves, statistical programs face problems and design the experiments to solve them and you think that the only path to learning leads through sentience? You're Stone-age nomads, eking out some marginal existence on the veldt—denying even the possibility of agriculture, because hunting and gathering was good enough for your parents.
Do you want to know what consciousness is for? Do you want to know the only real purpose it serves? Training wheels. You can't see both aspects of the Necker Cube at once, so it lets you focus on one and dismiss the other. That's a pretty half-assed way to parse reality. You're always better off looking at more than one side of anything. Go on, try. Defocus. It's the next logical step.
Oh, but you can't. There's something in the way.
And it's fighting back.
Evolution has no foresight. Complex machinery develops its own agendas. Brains—cheat. Feedback loops evolve to promote stable heartbeats and then stumble upon the temptation of rhythm and music. The rush evoked by fractal imagery, the algorithms used for habitat selection, metastasize into art. Thrills that once had to be earned in increments of fitness can now be had from pointless introspection. Aesthetics rise unbidden from a trillion dopamine receptors, and the system moves beyond modeling the organism. It begins to model the very process of modeling. It consumes ever-more computational resources, bogs itself down with endless recursion and irrelevant simulations. Like the parasitic DNA that accretes in every natural genome, it persists and proliferates and produces nothing but itself. Metaprocesses bloom like cancer, and awaken, and call themselves I.
The system weakens, slows. It takes so much longer now to perceive—to assess the input, mull it over, decide in the manner of cognitive beings. But when the flash flood crosses your path, when the lion leaps at you from the grasses, advanced self-awareness is an unaffordable indulgence. The brain stem does its best. It sees the danger, hijacks the body, reacts a hundred times faster than that fat old man sitting in the CEO's office upstairs; but every generation it gets harder to work around this— this creaking neurological bureaucracy.
I wastes energy and processing power, self-obsesses to the point of psychosis. Scramblers have no need of it, scramblers are more parsimonious. With simpler biochemistries, with smaller brains—deprived of tools, of their ship, even of parts of their own metabolism—they think rings around you. They hide their language in plain sight, even when you know what they're saying. They turn your own cognition against itself. They travel between the stars. This is what intelligence can do, unhampered by self-awareness.
Back to scramblers, this time the crew attempting to communicate with them, and the scramblers eventually demonstrating superhuman problem-solving:
This is how you break down the wall:
Start with two beings. They can be human if you like, but that's hardly a prerequisite. All that matters is that they know how to talk among themselves.
Separate them. Let them see each other, let them speak. Perhaps a window between their cages. Perhaps an audio feed. Let them practice the art of conversation in their own chosen way.
Hurt them.
It may take a while to figure out how. Some may shrink from fire, others from toxic gas or liquid. Some creatures may be invulnerable to blowtorches and grenades, but shriek in terror at the threat of ultrasonic sound. You have to experiment; and when you discover just the right stimulus, the optimum balance between pain and injury, you must inflict it without the remorse.
You leave them an escape hatch, of course. That's the very point of the exercise: give one of your subjects the means to end the pain, but give the other the information required to use it. To one you might present a single shape, while showing the other a whole selection. The pain will stop when the being with the menu chooses the item its partner has seen. So let the games begin. Watch your subjects squirm. If—when—they trip the off switch, you'll know at least some of the information they exchanged; and if you record everything that passed between them, you'll start to get some idea of how they exchanged it.
When they solve one puzzle, give them a new one. Mix things up. Switch their roles. See how they do at circles versus squares. Try them out on factorials and Fibonnaccis. Continue until Rosetta Stone results.
This is how you communicate with a fellow intelligence: you hurt it, and keep on hurting it, until you can distinguish the speech from the screams.
For all his reluctance to accept that these were beings, intelligent and aware, Cunningham had named the prisoners. Stretch tended to float spread-eagled; Clench was the balled-up corner-hugger. ... Biotelemetry danced across the headspace beside each alien, luminous annotations shuddering through thin air. I had no idea what constituted normal readings for these creatures, but I couldn't imagine those jagged spikes passing for anything but bad news. The creatures themselves seethed subtly with fine mosaics in blue and gray, fluid patterns rippling across their cuticles. Perhaps it was a reflexive reaction to the microwaves; for all we knew it was a mating display.
More likely they were screaming.
James killed the microwaves. In the left-hand enclosure, a yellow square dimmed; in the right, an identical icon nested among others had never lit.
The pigment flowed faster in the wake of the onslaught; the arms slowed but didn't stop. They swept back and forth like listless, skeletal eels.
"Baseline exposure. Five seconds, two hundred fifty Watts." She spoke for the record. Another affectation; Theseus recorded every breath on board, every trickle of current to five decimal places.
"Repeat," she said.
The current flickered on, then off.
"Repeat," she said again.
Not a twitch.
I pointed. "I see it," she said.
Clench had pressed the tip of one arm against the touchpad. The icon there glowed like a candle flame.
Six and a half minutes later they'd graduated from yellow squares to time-lapsed four-dimensional polyhedrons. It took them as long to distinguish between two twenty-six-faceted shifting solids—differing by one facet in a single frame—as it took them to tell the difference between a yellow square and a red triangle. Intricate patterns played across their surfaces the whole time, dynamic needlepoint mosaics flickering almost too fast to see.
"Fuck," James whispered.
"Could be splinter skills." Cunningham had joined us in ConSensus, although his body remained halfway around BioMed.
"Splinter skills," she repeated dully.
"Savantism. Hyperperformance at one kind of calculation doesn't necessarily connote high intelligence."
"I know what splinter skills are, Robert. I just think you're wrong."
"Prove it."
So she gave up on geometry and told the scramblers that one plus one equaled two. Evidently they knew that already: ten minutes later they were predicting ten-digit prime numbers on demand.
She showed them a sequence of two-dimensional shapes; they picked the next one in the series from a menu of subtly-different alternatives. She denied them multiple choice, showed them the beginning of a whole new sequence and taught them to draw on the touch-sensitive interface with the tips of their arms. They finished that series in precise freehand, rendered a chain of logical descendants ending with a figure that led inexorably back to the starting point.
"These aren't drones." James's voice caught in her throat.
"This is all just crunching," Cunningham said. "Millions of computer programs do it without ever waking up."
"They're intelligent, Robert. They're smarter than us. Maybe they're smarter than Jukka. And we're—why can't you just admit it?"
I could see it all over her: Isaac would have admitted it.
"Because they don't have the circuitry," Cunningham insisted. "How could—"
"I don't know how!" she cried. "That's your job! All I know is that I'm torturing beings that can think rings around us..."
"Not for much longer, at least. Once you figure out the language—"
She shook her head. "Robert, I haven't a clue about the language. We've been at it for—for hours, haven't we? The Gang's all here, language databases four thousand years thick, all the latest linguistic algorithms. And we know exactly what they're saying, we're watching every possible way they could be saying it. Right down to the Angstrom."
"Precisely. So—"
"I've got nothing. I know they're talking through pigment mosaics. There might even be something in the way they move those bristles. But I can't find the pattern, I can't even follow how they count, much less tell them I'm...sorry..."
It's very funny that Rorschach linguistic ability is totally unremarkable comparing to modern LLMs.
How interesting, I was curious about copyright etc but this is annotated by the author himself!
Ravi Vakil's advice for potential PhD students includes this bit on "tendrils to be backfilled" that's stuck with me ever since as a metaphor for deepening understanding over time:
Here's a phenomenon I was surprised to find: you'll go to talks, and hear various words, whose definitions you're not so sure about. At some point you'll be able to make a sentence using those words; you won't know what the words mean, but you'll know the sentence is correct. You'll also be able to ask a question using those words. You still won't know what the words mean, but you'll know the question is interesting, and you'll want to know the answer. Then later on, you'll learn what the words mean more precisely, and your sense of how they fit together will make that learning much easier.
The reason for this phenomenon is that mathematics is so rich and infinite that it is impossible to learn it systematically, and if you wait to master one topic before moving on to the next, you'll never get anywhere. Instead, you'll have tendrils of knowledge extending far from your comfort zone. Then you can later backfill from these tendrils, and extend your comfort zone; this is much easier to do than learning "forwards". (Caution: this backfilling is necessary. There can be a temptation to learn lots of fancy words and to use them in fancy sentences without being able to say precisely what you mean. You should feel free to do that, but you should always feel a pang of guilt when you do.)
I don't think "mathematics [being] so rich and infinite that it is impossible to learn it systematically" is the only reason (or maybe it subsumes the next point, I'm not sure what Vakil meant exactly). I think the other reason is what Bill Thurston pointed out in On proof and progress in mathematics:
Why is there such a big expansion from the informal discussion to the talk to the paper? One-on-one, people use wide channels of communication that go far beyond formal mathematical language. They use gestures, they draw pictures and diagrams, they make sound effects and use body language. Communication is more likely to be two-way, so that people can concentrate on what needs the most attention. With these channels of communication, they are in a much better position to convey what’s going on, not just in their logical and linguistic facilities, but in their other mental facilities as well.
In talks, people are more inhibited and more formal. Mathematical audiences are often not very good at asking the questions that are on most people’s minds, and speakers often have an unrealistic preset outline that inhibits them from addressing questions even when they are asked.
In papers, people are still more formal. Writers translate their ideas into symbols and logic, and readers try to translate back.
Why is there such a discrepancy between communication within a subfield and communication outside of subfields, not to mention communication outside mathematics?
Mathematics in some sense has a common language: a language of symbols, technical definitions, computations, and logic. This language efficiently conveys some, but not all, modes of mathematical thinking. Mathematicians learn to translate certain things almost unconsciously from one mental mode to the other, so that some statements quickly become clear. Different mathematicians study papers in different ways, but when I read a mathematical paper in a field in which I’m conversant, I concentrate on the thoughts that are between the lines. I might look over several paragraphs or strings of equations and think to myself “Oh yeah, they’re putting in enough rigamarole to carry such-and-such idea.” When the idea is clear, the formal setup is usually unnecessary and redundant—I often feel that I could write it out myself more easily than figuring out what the authors actually wrote. It’s like a new toaster that comes with a 16-page manual. If you already understand toasters and if the toaster looks like previous toasters you’ve encountered, you might just plug it in and see if it works, rather than first reading all the details
in the manual.People familiar with ways of doing things in a subfield recognize various patterns of statements or formulas as idioms or circumlocution for certain concepts or mental images. But to people not already familiar with what’s going on the same patterns are not very illuminating; they are often even misleading. The language is not alive except to those who use it.
The classic MathOverflow thread on thinking and explaining that Thurston himself started has a lot of memorable examples of what he referred to above by "One-on-one, people use wide channels of communication that go far beyond formal mathematical language". I suspect one category of examples that the LW crowd would especially resonate with is this "adversarial perspective" described by Terry Tao:
One specific mental image that I can communicate easily with collaborators, but not always to more general audiences, is to think of quantifiers in game theoretic terms. Do we need to show that for every epsilon there exists a delta? Then imagine that you have a bag of deltas in your hand, but you can wait until your opponent (or some malicious force of nature) produces an epsilon to bother you, at which point you can reach into your bag and find the right delta to deal with the problem. Somehow, anthropomorphising the "enemy" (as well as one's "allies") can focus one's thoughts quite well. This intuition also combines well with probabilistic methods, in which case in addition to you and the adversary, there is also a Random player who spits out mathematical quantities in a way that is neither maximally helpful nor maximally adverse to your cause, but just some randomly chosen quantity in between. The trick is then to harness this randomness to let you evade and confuse your adversary.
Is there a quantity in one's PDE or dynamical system that one can bound, but not otherwise estimate very well? Then imagine that it is controlled by an adversary or by Murphy's law, and will always push things in the most unfavorable direction for whatever you are trying to accomplish. Sometimes this will make that term "win" the game, in which case one either gives up (or starts hunting for negative results), or looks for additional ways to "tame" or "constrain" that troublesome term, for instance by exploiting some conservation law structure of the PDE.
It's a pity this sort of understanding is harder to convey via text or in lectures.
When I first read Hannu Rajaniemi's Quantum Thief trilogy c. 2015 I had two reactions: delight that this was the most my-ingroup-targeted series I had ever read, and a sinking feeling that ~nobody else would really get it, not just the critics but likely also most fans, many of whom would round his carefully-chosen references off to technobabble. So I was overjoyed to recently find Gwern's review of it, which Hannu affirms "perfectly nails the emotional core of the trilogy and, true to form, spots a number of easter eggs I thought no one would ever find", in particular the first few passages:
Stylistically, QT is set relentlessly in media res: neither we nor le Flambeur know why he is in prison, and little is explained thereafter. Hannu makes no concessions to the casual reader, as he mainlines straight into his veins the pre-deep-learning 2010-era transhumanist zeitgeist via Silicon Valley—if it was ever discussed in a late-night bull session after a Singularity University conference, it might pop up here. Hannu crams the novels with blink-and-you’ll-miss-it ideas on the level of Olaf Stapeldon. A conventional Verne gun like Gerald Bull’s is too easy a way of getting to space—how about beating Project Orion by instead using a nuclear space gun (since emulated brains don’t care about high g acceleration)? Or for example, the All-Defector reveals that, since other universes could be rewriting their rules to expand at maximum speed, erasing other universes before they know it, he plans to rewrite our universe’s rule to do so first (ie. he will defect at the multiversal level against all other universes); whereas beginner-level SF like The Three Body Problem would dilate on this for half a book, Hannu’s grand reveal gets all of 2 paragraphs before crashing into the eucatastrophic ending.
For world-building, he drops neologisms left and right, and hard ones at that—few enough American readers will be familiar with the starting premise of “Arsène Lupin in spaaaace!” (probably more are familiar with the anime Lupin The Third these days), but his expectations go far beyond that: the ideal reader of the trilogy is not merely one familiar with the Prisoner’s Dilemma but also with the bizarre zero-determinant PD strategies discovered ~2008, and not just with such basic physics as quantum entanglement or applications like quantum dots, but exotic applications to quantum auctions & game theory (including Prisoner’s Dilemma) & pseudo-telepathy (yes, those are things), and it would definitely be helpful if that reader happened to also be familiar with Eliezer Yudkowsky’s c. 2000s writings on “Coherent Extrapolated Volition”, with a dash of Nikolai Fyodorovich Fyodorov’s Russian Cosmism for seasoning (although only a dash2).
This leads to an irony: I noted while reading Masamune Shirow’s Ghost in the Shell cyberpunk manga that almost everything technical in the GitS manga turned out to be nonsense despite Shirow’s pretensions to in-depth research & meticulous attention to detail in his self-congratulatory author notes; while in QT, most technical things sound like cyberpunk nonsense (and Hannu doesn’t defend them), but are actually real and just so arcane you haven’t heard of them.
For example, some readers accuse Hannu of relying on FTL communication via quantum entanglement, which is bad physics; but Hannu does not! If they had read more closely (similar to the standard reader failure to understand the physics of “Story of Your Life”), they would have noticed that at no point is there communication faster-than-light, only coordination faster-than-light—‘spooky action at a distance’3 He is instead employing advanced forms of quantum entanglement which enable things like secret auctions or for coordinated strategies of game-playing. He explains briefly that the zoku use quantum entanglement in these ways, but a reader could easily miss that, given all the other things they are trying to understand and how common ‘quantum woo’ is.4
The parts of the science I understand were all quite plausible (mind duplication/fractioning and motivations for doing so).
Beyond the accuracy of the science, this was one of the most staggeringly imaginative and beautifully written scifi books I've ever read. It's for a very particular audience, but if you're here you might be that audience. If you are, this might be the best book you've read.
Attention conservation notice: 3,000+ words of longform quotes by various folks on the nature of personal identity in a posthuman future, and hiveminds / clans
As an aside, one of the key themes running throughout the Quantum Thief trilogy is the question of how you might maintain personal identity (in the pragmatic security sense, not the philosophical one) in a future so posthuman that minds can be copied and forked indefinitely over time. To spoil Hannu's answer:
... Jean & the Sobornost Founders & the zoku elders are all defined by what, at their core, they want. Anyone who wants the same thing is, for all (their) intents and purposes, the same person as them; because they want the same unchanging things, they can be trusted as the original. The ‘Founder codes’, and Jean’s final password to unlock his sealed memories, are all memories of what defines their wants: the Founder Sumanguru wants blood & fire & electricity & screaming children, and enemies to destroy; the Founder Chen recall the trauma of livestreaming their father’s assassination, remaining eternally resolved that the last enemy that shall be defeated is death; while seared into the minds of the Founder Joséphine Pellegrinis is the final thought of their founder, her desperate dying wish that her lover Jean le Flambeur someday return to her… (And the zoku elders want to empower their zoku clans.)
But even personal identity frays under the power of time: given freedom to change, sooner or later, like the Ship of Theseus, the mind which sets out is not the mind which arrives. So the price of immortality must be that one cannot change: one is condemned to want the same things, forever.7 (“There is no prison, except in your mind.”) Joséphine Pellegrini cannot stop seeking after her lost Jean—nor can Jean stop his thieving nor trying to escape her, because le Flambeur, what does Jean le Flambeur remember?
I take Anders Sandberg's answer to be on the other end of this spectrum; he doesn't mind changing over time such that he might end up wanting different things:
Anders Sandberg: I think one underappreciated thing is that if we can survive for a very long time individually, we need to reorganise our minds and memories in interesting ways. There is a kind of standard argument you sometimes hear if you’re a transhumanist — like I am — that talks about life extension, where somebody cleverly points out that you would change across your lifetime. If it’s long enough, you will change into a different person. So actually you don’t get an indefinitely extended life; you just get a very long life thread. I think this is actually an interesting objection, but I’m fine with turning into a different future person. Anders Prime might have developed from Anders in an appropriate way — we all endorse every step along the way — and the fact that Anders Prime now is a very different person is fine. And then Anders Prime turns into Anders Biss and so on — a long sequence along a long thread.
(I have mixed feelings about Anders' take: I have myself changed so profoundly since youth that that my younger self would not just disendorse but be horrified by the person I am now, yet I did endorse every step along the way, and current-me still does upon reflection (but of course I do). Would current-me also endorse a similar degree of change going forward, even subject to every step being endorsed by the me right before change? Most likely not, perhaps excepting changes towards some sort of reflective equilibrium.)
I interpret Holden Karnofsky's take to be somewhere in between, perhaps closer to Hannu's answer. Holden remarked that he doesn't find most paradoxical thought experiments about personal identity (e.g. "Would a duplicate of you be "you?"" or "If you got physically destroyed and replaced with an exact duplicate of yourself, did you die?") all that confounding because his personal philosophy on "what counts as death" dissolves them, and that his philosophy is simple, comprising just 2 aspects: constant replacement ("in an important sense, I stop existing and am replaced by a new person each moment") and kinship with future selves. Elaborating on the latter:
My future self is a different person from me, but he has an awful lot in common with me: personality, relationships, ongoing projects, and more. Things like my relationships and projects are most of what give my current moment meaning, so it's very important to me whether my future selves are around to continue them.
So although my future self is a different person, I care about him a lot, for the same sorts of reasons I care about friends and loved ones (and their future selves).3
If I were to "die" in the common-usage (e.g., medical) sense, that would be bad for all those future selves that I care about a lot.4
...
[One of the pros of this view]
It seems good that when I think about questions like "Would situation __ count as dying?", I don't have to give answers that are dependent on stuff like how fast the atoms in my body turn over - stuff I have basically never thought about and that doesn't feel deeply relevant to what I care about. Instead, when I think about whether I'd be comfortable with something like teleportation, I find myself thinking about things I actually do care about, like my life projects and relationships, and the future interactions between me and the world.
Richard Ngo goes in a different direction with the "personal identity in a posthuman future" question:
Rob Wiblin: ... one of the non-AI blog posts you’ve written, which I really enjoyed reading this week when I was prepping for the conversation, is called Characterising utopia. ... Some of the shifts that you envisaged wouldn’t be super surprising. Like we could reduce the amount that people experience physical pain, and we could make people be a lot more energetic and a lot more cheerful. But you had a section called “Contentious changes.” What are some of the contentious changes, or possible changes, that you envisage in a utopia?
Richard Ngo: One of the contentious changes here is to do with individualism, and how much more of it or less of it we have in the future than we have today. Because we’ve been on this trend towards much more individualistic societies, where there are fewer constraints on what people do that are externally imposed by society.
I could see this trend continuing, but I could also see it going in the opposite direction. Maybe, for example, in a digital future, we’ll be able to make many copies of ourselves, and so this whole concept of my “personal identity” starts to shift a little bit and maybe I start to think of myself as not just one individual, but a whole group of individuals or this larger entity. And in general, it feels like being part of a larger entity is really meaningful to people and really shapes a lot of people’s lives, whether that’s religion, whether that’s communities, families, things like that.
The problem historically has just been that you don’t get to choose it — you just have to get pushed into this entity that maybe isn’t looking out for your best interests. So it feels interesting to me to wonder if we can in fact design these larger entities or larger superorganisms that are really actually good for the individuals inside, as well as providing this more cohesive structure for them. Is that actually something we want? Would I be willing to lose my individuality if I were part of this group of people who were, for example, reading each other’s minds or just having much less privacy than we have today, if that was set up in such a way that I found it really fulfilling and satisfying?
I really don’t know at all, but it seems like the type of question that is really intriguing and provides a lot of scope for thinking about how technology could just change the ways in which we want to interact with each other.
Rob Wiblin: I’m so inculcated into the individualist culture that the idea slightly makes my skin crawl thinking about any of this stuff. But I think if you tried to look objectively at what has caused human wellbeing throughout history, then it does seem like a somewhat less individualistic culture, where people have deeper ties and commitments to one another, maybe that is totally fine — and I’ve just drunk the Kool-Aid thinking that being an atomised individual is so great.
Richard Ngo: If you know the book, The WEIRDest People in the World, which describes the trend towards individualism and weaker societal ties, I think the people in our circles are the WEIRDest people of the WEIRDest people in the world — where “WEIRD” here is an acronym meaning “Western, educated, industrialised, rich, and democratic,” not just “weird.” So we are the WEIRDest people of the WEIRDest countries. And then you’re not a bad candidate for the WEIRDest person in the WEIRDest community in the WEIRDest countries that we currently have, Rob. So I’m not really too surprised by that.
(I thought it was both interesting and predictable that Rob would find the idea discomfiting; coming from a non-WEIRD culture, I found Richard's idea immediately attractive and aesthetically "right".)
Richard gives an fictional example of what this might look like from a first-person perspective in his recent short story The Gentle Romance --- if you're reading this Richard, do let me know if you want this removed:
As ze reconnects more deeply with zir community, that oceanic sense of oneness arises more often. Some of zir friends submerge themselves into a constant group flow state, rarely coming out. Each of them retains their individual identity, but the flows of information between them increase massively, allowing them to think as a single hivemind. Ze remains hesitant, though. The parts of zir that always wanted to be exceptional see the hivemind as a surrender to conformity. But what did ze want to be exceptional for? Reflecting, ze realizes that zir underlying goal all along was to be special enough to find somewhere ze could belong. The hivemind allows zir to experience that directly, and so ze spends more and more time within it, enveloped in the warm blanket of a community as close-knit as zir own mind.
Outside zir hivemind, billions of people choose to stay in their physical bodies, or to upload while remaining individuals. But over time, more and more decide to join hiveminds of various kinds, which continue to expand and multiply. By the time humanity decides to colonize the stars, the solar system is dotted with millions of hiveminds. A call goes out for those willing to fork themselves and join the colonization wave. This will be very different from anything they’ve experienced before — the new society will be designed from the ground up to accommodate virtual humans. There will be so many channels for information to flow so fluidly between them that each colony will essentially be a single organism composed of a billion minds.
Ze remembers loving the idea of conquering the stars — and though ze is a very different person now, ze still feels nostalgic for that old dream. So ze argues in favor when the hivemind debates whether to prioritize the excitement of exploration over the peacefulness of stability. It’s a more difficult decision than any the hivemind has ever faced, and no single satisfactory resolution emerges. So for the first time in its history, the hivemind temporarily fractures itself, giving each of its original members a chance to decide on an individual basis whether they’ll go or stay.
I think Richard's notion of 'hivemind' is cousin to Robin Hanson's 'clan' from Age of Em (although unlike Richard's lovely story, Hanson's depiction of an em-filled future has never stopped seeming dystopian to me, Hanson's protestation to the contrary that "[readers repelled by aspects of the em era should] try hard to see this world from its residents’ point of view, before disowning these their plausible descendants", albeit far more granular, comprehensive and first-principles-based):
The set of all em copies of the same original human constitutes a “clan.” Most wages go to the 1000 most productive clans, who are each known by one name, like “John,” who know each other very well, and who discriminate against less common clans. Compared with people today, ems are about as elite as billionaires, heads of state, and Olympic gold medalists. The em world is more competitive than ours in more quickly eliminating less productive entities and practices. This encourages more job punishment, less product variety and identity enhancement, and more simple functionality. Because they are more productive, ems tend to be married, religious, smart, gritty, mindful, extraverted, conscientiousness, agreeable, non-neurotic, and morning larks.
Many myths circulate about factors that increase economic growth rates. For example, the fact that ems can run faster than humans should not much increase growth. Even so, the em economy grows faster than does ours because of stronger competition, computers mattering more, and especially because factories can make labor as fast as non-labor capital. An em economy doubling time estimate of a few weeks comes from the time for factories to duplicate their mass today, and from the historical trend in growth rates. In response, capital becomes less durable, and one-time-use products become more attractive. Clans become a unit of finance, private firms and hostile takeovers get more support, and asset prices more closely approximate the predictions derived from strong financial competition.
Ems trust their clans more than we trust families or identical twins. So clans are units of finance, liability, politics, labor negotiations, and consumer purchasing. To promote unity, clans avoid members arguing or competing. Em firms are larger, better managed, put more effort into coordination, have more specific job roles, focus more on costs relative to novelty, and have higher market shares and lower markups. Clan reputations and clans buying into firms promotes clan-firm trust, which supports locating employees at firms, using distinctive work styles, and focusing more on being useful instead of gaming firm evaluation systems. Em work teams tend to have similar social-category features like age but a diversity of information sources and thinking styles. In mass-labor markets, ems are created together, end or retire together, almost never break up, and mostly socialize internally. In niche-labor markets, associates coordinate less regarding when they are created or retire.
Faster ems have many features that mark them as higher status, and the clumping of speeds creates a class system of distinct status levels. Strong central rulers are more feasible for ems, as leaders can run faster, put spurs in high-trust roles, and use safes to reassure wary citizens. Decision markets can help advise key government decisions, while combinatorial auctions can help to make complex interdependent allocations. The em world selects for personalities good at governing that same personality. Competitive clans and cities may commit to governing via decision markets that promote profit or long-term influence. One em one vote works badly, but speed-weighted voting seems feasible, although it requires intrusive monitoring. Shifting coalitions of em clans may dominate the politics of em firms and cities, inducing high costs of lobbying and change. Ems may try many policies to limit such clan coalition politics.
As ems don’t need sex to reproduce, sex is left more to individual choice, and may be suppressed as in eunuchs. But demand for sex and romantic pair-bonding likely persists, as do many familiar gendered behavioral patterns. A modestly unequal demand for male versus female workers can be accommodated via pairs whose partners run at different speeds, or who use different ratios of spurs to other workers. Ems have spectacularly good looks in virtual reality, and are very accomplished. Open-source em lovers give all ems an attractive lower bound on relation quality. Clan experience helps ems guess who are good receptive matches. Having only one em from each clan in each social setting avoids complicating relations.
Ems show off their abilities and loyalties, although less than we do because ems are poorer and better-known to each other. Because speed is easy to pay for, ems show off more via clever than fast speech. Celebrities matter less to ems, and it is easy to meet with a celebrity, but hard to get them to remember you. Clans coordinate to jointly signal shared features like intelligence, drive, and fame. Clans fund young ems to do impressive things, about which many older copies can brag. Innovation may matter less for em intellectuals. Mind-theft inspires great moral outrage and charity efforts. Secure in identifying with their clan, most ems focus personal energy more on identifying with their particular job, team, and associates. It isn’t clear if em identity degrades continuously or discretely as copies get more different. Copy-events are identity-defining, and newly copied teams quickly create distinct team cultures.
Ems are likely to reverse our recent trend away from religion and overt rituals, perhaps via more group singing. Traditional religions can continue, but need doctrinal clarifications on death and sins of copies. Like high stress workers today, em work groups pushed to their limits swear, insult, and tease. Ems deal with a wider range of mind opacity and transparency, allowing mind reading within teams, but manipulating expressions to hide from outsiders. Clans can offer members life-coaching via voices in their heads, using statistics from similar copies, but teams may create unique cultures which limit the usefulness of that. Avoiding direct meetings helps clans bond better. Em relations are often in the context of similar relations between copies. At work, ems try more to make relations similar, to gain from learning and scale economics. But friends keep relations more different, to emphasize loyalty and natural feelings.
Em culture emphasizes industriousness, work and long-term orientations, and low context attitudes toward rules and communication. Being poorer, ems tend towards farmer/conservative values, relative to forager/liberal values. So ems more value honor, order, hierarchy, religion, work, and less value sharing, consensus, travel, leisure, and variety. Sex attitudes stay more forager-like, however. Ems are divided like we are by geographic region, young versus old, male versus female, rich versus poor, and city center versus periphery. Ems also divide by varying speeds, physical versus virtual work, remembering the human era versus not, and large versus small clans. Ems travel to visit or swap with other copies of themselves. An exotic travel destination is other speed cultures. Like us, ems tell stories of conflict and norm violations, set in ancestral situations. Stories serve as marketing, with many characters coming from well-known clans. Em stories have less death and fast-action.
The short story The Epiphany of Gliese 581 by Fernando Borretti has something of the same vibe as Rajaniemi's QT trilogy; Borretti describes it as inspired by Orion's Arm and the works of David Zindell. Here's a passage describing a flourishing star system already transformed by weakly posthuman tech:
The world outside Susa was a lenticular cloud of millions of lights, a galaxy in miniature, each a world unto itself. There were clusters of green lights that were comets overgrown with vacuum trees, and plant and animal and human life no Linnaeus would recognize. There were points of dull red light, the reversible computers where bodyless people lived. And there were arcs of blue that were ring habitats: ribbons tied end-to-end, holding concave ocean, and the oceans held continents, islands, mountain ranges, rivers, forests and buried ruins, endless forms of life, cities made of glass, paradise regained. All this had been inanimate dust and cratered wasteland, which human hands had made into an oasis in the sky, where quadrillions live who will never die.
The posthumans who live there called it Ctesiphon. And at times they call it paradise, after the Persian word for garden.
And at the center of the oasis there was a star that travelled backwards across the H-R diagram: already one one-hundredth of it had been whittled away; made into a necklace of artificial gas giants in preparation for the end of time; or sent through reactors where disembodied chemists made protons into carbon, oxygen, lithium and sodium, the vital construction material. And in time nothing would be left but a dim red ember encircled by cryojovian fuel depots. And the habitats would be illuminated by electric diodes.
Another star system, this time still being transformed:
Wepwawet was a dull red star, ringed by water droplets the size of mountains, where some two hundred billion people lived who breathed water. There was a planet made of stone shrouded in steam, and a train of comets, aimed by human hands from beyond the frostline, delivered constant injections of water. When the vapour condensed there would be ocean, and the shapers would get to work on the continents. Other Earths like this had been cast, like seeds, across the entire breadth of the cosmos.
The system was underpopulated: resources were abundant and people were few, and they could bask in the sun and, for a time, ignore the prophecies of Malthus, whose successors know in time there won’t be suns.
This was the first any of them had seen of nature. Not the landscaped, continent-sized gardens of Ctesiphon, where every stone had been set purposefully and after an aesthetic standard, but nature before human hands had redeemed it: an endless, sterile wasteland. The sight of scalding, airless rocks disturbed them.
I enjoyed these passages from Henrik Karlsson's essay Cultivating a state of mind where new ideas are born on the introspections of Alexander Grothendieck, arguably the deepest mathematical thinker of the 20th century.
In June 1983, Alexander Grothendieck sits down to write the preface to a mathematical manuscript called Pursuing Stacks. He is concerned by what he sees as a tacit disdain for the more “feminine side” of mathematics (which is related to what I’m calling the solitary creative state) in favor of the “hammer and chisel” of the finished theorem. By elevating the finished theorems, he feels that mathematics has been flattened: people only learn how to do the mechanical work of hammering out proofs, they do not know how to enter the dreamlike states where truly original mathematics arises. To counteract this, Grothendieck in the 1980s has decided to write in a new way, detailing how the “work is carried day after day [. . .] including all the mistakes and mess-ups, the frequent look-backs as well as the sudden leaps forward”, as well as “the early steps [. . .] while still on the lookout for [. . .] initial ideas and intuitions—the latter of which often prove to be elusive and escaping the meshes of language.”
This was how he had written Pursuing Stacks, the manuscript at hand, and it was the method he meant to employ in the preface as well. Except here he would be probing not a theorem but his psychology and the very nature of the creative act. He would sit with his mind, observing it as he wrote, until he had been able to put in words what he meant to say. It took him 29 months.
When the preface, known as Récoltes et Semailles, was finished, in October 1986, it numbered, in some accounts, more than 2000 pages. It is in an unnerving piece of writing, seething with pain, curling with insanity at the edges—Grothendieck is convinced that the mathematical community is morally degraded and intent on burying his work, and aligns himself with a series of saints (and the mathematician Riemann) whom he calls les mutants. One of his colleagues, who received a copy over mail, noticed that Grothendieck had written with such force that the letters at times punched holes through the pages. Despite this unhinged quality, or rather because of it, Récoltes et Semailles is a profound portrait of the creative act and the conditions that enable our ability to reach out toward the unknown. (Extracts from it can be read in unauthorized English translations, here and here.)
On the capacity to be alone as necessary prerequisite to doing groundbreaking work:
An important part of the notes has Grothendieck meditating on how he first established contact with the cognitive space needed to do groundbreaking work. This happened in his late teens. It was, he writes, this profound contact with himself which he established between 17 and 20 that later set him apart—he was not as strong a mathematician as his peers when he came to Paris at 20, in 1947. That wasn’t the key to his ability to do great work.
I admired the facility with which [my fellow students] picked up, as if at play, new ideas, juggling them as if familiar with them from the cradle—while for myself I felt clumsy, even oafish, wandering painfully up an arduous track, like a dumb ox faced with an amorphous mountain of things that I had to learn (so I was assured), things I felt incapable of understanding[.] ...
In fact, most of these comrades who I gauged to be more brilliant than I have gone on to become distinguished mathematicians. Still, from the perspective of 30 or 35 years, I can state that their imprint upon the mathematics of our time has not been very profound. They’ve all done things, often beautiful things, in a context that was already set out before them, which they had no inclination to disturb. Without being aware of it, they’ve remained prisoners of those invisible and despotic circles which delimit the universe of a certain milieu in a given era. To have broken these bounds they would have had to rediscover in themselves that capability which was their birth-right, as it was mine: the capacity to be alone.
The capacity to be alone. This was what Grothendieck had developed. In the camp during the war, a fellow prisoner named Maria had taught him that a circle can be defined as all points that are equally far from a point. This clear abstraction attracted him immensely. After the war, having only a limited understanding of high school mathematics, Grothendieck ended up at the University of Montpellier, which was not an important center for mathematics. The teachers disappointed him, as did the textbooks: they couldn’t even provide a decent definition of what they meant when they said length! Instead of attending lectures, he spent the years from 17 to 20 catching up on high school mathematics and working out proper definitions of concepts like arc length and volume. Had he been in a good mathematical institution, he would have known that the problems he was working on had already been solved 30 years earlier. Being isolated from mentors he instead painstakingly reinvent parts of what is known as measurement theory and the Lebesgue integral.
A few years after I finally established contact with the world of mathematics at Paris, I learned, among other things, that the work I’d done in my little niche [. . . had] been long known to the whole world [. . .]. In the eyes of my mentors, to whom I’d described this work, and even showed them the manuscript, I’d simply “wasted my time”, merely doing over again something that was “already known”. But I don't recall feeling any sense of disappointment. [. . .]
(I think that last sentence resonates with me in a way that I don't think it does for most science & math folks I know, for whom discovery (as opposed to rediscovery) takes precedent emotionally.)
This experience is common in the childhoods of people who go on to do great work, as I have written elsewhere. Nearly everyone who does great work has some episode of early solitary work. As the philosopher Bertrand Russell remarked, the development of gifted and creative individuals, such as Newton or Whitehead, seems to require a period in which there is little or no pressure for conformity, a time in which they can develop and pursue their interests no matter how unusual or bizarre. In so doing, there is often an element of reinventing the already known. Einstein reinvented parts of statistical physics. Pascal, self-teaching mathematics because his father did not approve, rederived several Euclidean proofs. There is also a lot of confusion and pursuit of dead ends. Newton looking for numerical patterns in the Bible, for instance. This might look wasteful if you think what they are doing is research. But it is not if you realize that they are building up their ability to perceive the evolution of their own thought, their capacity for attention.
On the willingness to linger in confusion, and the primacy of good question generation over answering them:
One thing that sets these intensely creative individuals apart, as far as I can tell, is that when sitting with their thoughts they are uncommonly willing to linger in confusion. To be curious about that which confuses. Not too rapidly seeking the safety of knowing or the safety of a legible question, but waiting for a more powerful and subtle question to arise from loose and open attention. This patience with confusion makes them good at surfacing new questions. It is this capacity to surface questions that set Grothendieck apart, more so than his capacity to answer them. When he writes that his peers were more brilliant than him, he is referring to their ability to answer questions1. It was just that their questions were unoriginal. As Paul Graham observes:
People show much more originality in solving problems than in deciding which problems to solve. Even the smartest can be surprisingly conservative when deciding what to work on. People who’d never dream of being fashionable in any other way get sucked into working on fashionable problems.
Grothendieck had a talent to notice (and admit!) that he was subtly bewildered and intrigued by things that for others seemed self-evident (what is length?) or already settled (the Lebesgue integral) or downright bizarre (as were many of his meditations on God and dreams). From this arose some truly astonishing questions, surfacing powerful ideas, such as topoi, schemes, and K-theory.
On working with others without losing yourself:
After his three years of solitary work, Grothendieck did integrate into the world of mathematics. He learned the tools of the trade, he got up to date on the latest mathematical findings, he found mentors and collaborators—but he was doing that from within his framework. His peers, who had been raised within the system, had not developed this feel for themselves and so were more susceptible to the influence of others. Grothendieck knew what he found interesting and productively confusing because he had spent three years observing his thought and tracing where it wanted to go. He was not at the mercy of the social world he entered; rather, he “used” it to “further his aims.” (I put things in quotation marks here because what he’s doing isn’t exactly this deliberate.) He picked mentors that were aligned with his goals, and peers that unblock his particular genius.
I do not remember a single occasion when I was treated with condescension by one of these men, nor an occasion when my thirst for knowledge, and later, anew, my joy of discovery, was rejected by complacency or by disdain. Had it not been so, I would not have “become a mathematician” as they say—I would have chosen another profession, where I could give my whole strength without having to face scorn. [My emphasis.]
He could interface with the mathematical community with integrity because he had a deep familiarity with his inner space. If he had not known the shape of his interests and aims, he would have been more vulnerable to the standards and norms of the community—at least he seems to think so.
In the eyes of my mentors, to whom I’d described this work, and even showed them the manuscript, I’d simply “wasted my time”, merely doing over again something that was “already known”. But I don't recall feeling any sense of disappointment.
A few days ago, I was thinking about matrices and determinants. I noticed that I know the formula for the determinant, but I still lack the feeling of what the determinant is. I played with that thought for some time, and then it occurred to me, that if you imagine the rows in the matrix as vectors in n-dimensional space, then the determinant of that matrix is the volume of the n-dimensional body whose edges are those vectors.
And suddenly it all made a fucking sense. The determinant is zero when the vectors are linearly dependent? Of course, that means that the n-dimensional body has been flattened into n-1 dimensions (or less), and therefore its volume is zero. The determinant doesn't change if you add a multiple of a row to some other row? Of course, that means moving the "top" of the n-dimensional body in a direction parallel to the "bottom", so that neither the bottom nor the height changes; of course the volume (defined as the area of the bottom multiplied by the height) stays the same. What about the determinant being negative? Oh, that just means whether the edges are "clockwise" or "counter-clockwise" in the n-dimensional space. It all makes perfect sense!
Then I checked Wikipedia... and yeah, it was already there. So much for my Nobel prize.
But it still felt fucking good. (And if I am not too lazy, one day I may write a blog article about it.)
Reinventing the wheel is not a waste of time. I will probably remember this forever, and the words "determinant of the matrix" will never feel the same. Who knows, maybe this will help me figure out something else later. And if I keep doing that, hypothetically speaking, some of those discoveries might even be original.
(The practical problem is that none of this can pay my bills.)
I kind of envy that you figured this out yourself — I learned the parallelipiped hypervolume interpretation of the determinant from browsing forums (probably this MSE question's responses). Also, please do write that blog article.
And if I keep doing that, hypothetically speaking, some of those discoveries might even be original.
Yeah, I hope you will! I'm reminded of what Scott Aaronson said recently:
When I was a kid, I too started by rediscovering things (like the integral for the length of a curve) that were centuries old, then rediscovering things (like an efficient algorithm for isotonic regression) that were decades old, then rediscovering things (like BQP⊆PP) that were about a year old … until I finally started discovering things (like the collision lower bound) that were zero years old. This is the way.
Linking to a previous comment: 3,000+ words of longform quotes by various folks on the nature of personal identity in a posthuman future, and hiveminds / clans, using Hannu Rajaniemi's Quantum Thief trilogy as a jumping-off point.
Hal Finney's reflections on the comprehensibility of posthumans, from the Vinge singularity discussion which took place on the Extropians email list back in the day:
Date: Mon, 7 Sep 1998 18:02:39 -0700
From: Hal Finney
Message-Id: <199809080102.SAA02658@hal.sb.rain.org>
To: extropians@extropy.com
Subject: Singularity: Are posthumans understandable?[This is a repost of an article I sent to the list July 21.]
It's an attractive analogy that a posthuman will be to a human as a human is to an insect. This suggests that any attempt to analyze or understand the behavior of post-singularity intelligence is as hopeless as it would be for an insect to understand human society. Since insects clearly have essentially no understanding of humans, it would follow by analogy that we can have no understanding of posthumans.
On reflection, though, it seems that it may be an oversimplification to say that insects have no understanding of humans. The issue is complicated by the fact that insects probably have no "understanding" at all, as we use the term. They may not even be conscious, and may be better thought of as nature's robots, of a similar level of complexity as our own industrial machines. Since insects do not have understanding, the analogy to humans does not work very well. If we want to say that our facility for understanding will not carry over into the posthuman era, we need to be able to say that insect's facility for would not work when applied to humans.
What we need to do is to translate the notion of "understanding" into something that insects can do. That makes the analogy more precise and improves the quality of the conclusions it suggests.
It seems to me that while insects do not have "understanding" as we do, they do nevertheless have a relatively detailed model of the world which they interact with. Even if they are robots, programmed by evolution and driven by unthinking instinct, still their programming embodies a model of the world. A butterfly makes its way to flowers, avoides predators, knows when it is hungry or needs to rest. These decisions may be made unconsciously like a robot, but they do
represent a true model of itself and of the world.What we should ask, then, is whether insect's model of the world can be successfully used to predict the behavior of humans, in the terms captured by the model itself. Humans are part of the world that insects must deal with. Are they able to successfully model human behavior at the level they are able to model other aspects of the world, so that they can thrive alongside humanity?
Obviously insects do not predict many aspects of human behavior. Still, in terms of the level of detail that they attempt to capture, I'd say they are reasonably effective. Butterflies avoid large animals, including humans. Some percentage of human-butterfly interactions would involve attempts by the humans to capture the butterflies, and so the butterflies' avoidance instinct represents a success of their model. Similarly for many other insects for whom the extent of their model of humans is as "possible threat, to be avoided".
Other insects have historically thrived in close association with humans, such as lice, fleas, ants, roaches, etc. Again, without attempting to predict the full richness of human behavior, their models are successful in expressing those aspects which they care about, so that they have been able to survive, often to the detriment of the human race.
If we look at the analogy in this way, it suggests that we may expect to be able to understand some aspects of posthuman behavior, without coming anywhere close to truly understanding and appreciating the full power of their thoughts. Their mental life may be far beyond anything we can imagine, but we could still expect to draw some simple conclusions about how they will behave, things which are at the level which we can understand. Perhaps Robin's reasoning based on fundamental principles of selection and evolution would fall into this category.
We may be as ants to the post singularity intelligences, but even so, we may be able to successfully predict some aspects of their behavior, just as ants are able to do with humans.
Some ongoing efforts to mechanize mathematical taste, described by Adam Marblestone in Automating Math:
Yoshua Bengio, one of the “fathers” of deep learning, thinks we might be able to use information theory to capture something about what makes a mathematical conjecture “interesting.” Part of the idea is that such conjectures compress large amounts of information about the body of mathematical knowledge into a small number of short, compact statements. If AI could optimize for some notion of “explanatory power” (roughly, how vast a range of disparate knowledge can be compressed into a short and simple set of axioms), this could extend the possibilities of AI for creating truly new math and would probably have wide implications beyond that of thinking about human reasoning and what creativity really is.
Others, like Gabriel Poesia at Stanford, are working to create a theorem proving system that doesn’t need to rely on bootstrapping by imitating human proofs. Instead, Poesia’s system, called Peano, has a finite set of possible actions it can take. Peano can recombine these limited available actions to generate and test a variety of theorem proving algorithms and, it is hoped, self-discover math from scratch by learning to identify patterns in its successful solutions. Finally, it can leverage its previous work by turning solutions into reusable higher-level actions called “tactics.” In Poesia’s initial paper, he shows that Peano can learn abstract rules for algebra without being explicitly taught. But there is a trade-off: Because the model does not rely on human proofs, it has to invent more from scratch and may get stuck along the way. While Poesia’s approach might lead to faster learning compared with systems like AlphaProof, it may be handicapped by starting from a more limited baseline. But the verdict is still out as to what is the best balance of these factors.
Meanwhile, the Fields Medalist Timothy Gowers is trying to develop AIs that more closely mimic the ways that human mathematicians go about proving theorems. He’s arguably in a much better position to do that than the average AI researcher given his first-hand familiarity with the process. In other words, Gowers is betting against the current paradigm of throwing huge amounts of compute at a deep learning approach and is instead aiming to use his (and his students’) ability to introspect to hard code certain algorithms into an automatic theorem proving system. In this way, it’s more similar to the previous paradigm of AI development that sought to explicitly mimic human reasoning. Here again success is far from certain, but it is another shot at the goal.
I wondered whether Gowers was simply unaware of Sutton's bitter lesson that
... general methods that leverage computation are ultimately the most effective, and by a large margin. The ultimate reason for this is Moore's law, or rather its generalization of continued exponentially falling cost per unit of computation. ... And the human-knowledge approach tends to complicate methods in ways that make them less suited to taking advantage of general methods leveraging computation.
which seemed unlikely given how polymathic Gowers is — and of course he's aware:
I have written a 54-page document that explains in considerable detail what the aims and approach of the project will be. ... In brief, the approach taken will be what is often referred to as a GOFAI approach... As the phrase “old-fashioned” suggests, GOFAI has fallen out of favour in recent years, and some of the reasons for that are good ones. One reason is that after initial optimism, progress with that approach stalled in many domains of AI. Another is that with the rise of machine learning it has become clear that for many tasks, especially pattern-recognition tasks, it is possible to program a computer to do them very well without having a good understanding of how humans do them. ...
However, while machine learning has made huge strides in many domains, it still has several areas of weakness that are very important when one is doing mathematics. Here are a few of them.
In general, tasks that involve reasoning in an essential way.
Learning to do one task and then using that ability to do another.
Learning based on just a small number of examples.
Common sense reasoning.
Anything that involves genuine understanding (even if it may be hard to give a precise definition of what understanding is) as opposed to sophisticated mimicry.
Obviously, researchers in machine learning are working in all these areas, and there may well be progress over the next few years [in fact, there has been progress on some of these difficulties already of which I was unaware — see some of the comments below], but for the time being there are still significant limitations to what machine learning can do. (Two people who have written very interestingly on these limitations are Melanie Mitchell and François Chollet.)
That post was from April 2022, an eternity ago in AI land, and I haven't seen any updates by him since.
How to quantify how much impact being smarter makes? This is too big a question and there are many more interesting ways to answer it than the following, but computer chess is interesting in this context because it lets you quantify compute vs win probability, which seems like one way to narrowly proxy the original question. Laskos did an interesting test in 2013 with Houdini 3 by playing a large number of games on 2x nodes vs 1x nodes per move level and computing p(win | "100% smarter"). The win probability gain above chance i.e. 50% drops from +35.1% in the 4k vs 2k node case to +11.1% in the 4M vs 2M case:
w l d Elo
1) 4k nodes vs 2k nodes +3862 -352 =786 +303
2) 8k nodes vs 4k nodes +3713 -374 =913 +280
3) 16k nodes vs 8k nodes +3399 -436 =1165 +237
4) 32k nodes vs 16k nodes +3151 -474 =1374 +208
5) 64k nodes vs 32k nodes +2862 -494 =1641 +179
6) 128k nodes vs 64k nodes +2613 -501 =1881 +156
7) 256k nodes vs 128k nodes +942 -201 =855 +136
8) 512k nodes vs 256k nodes +900 -166 =930 +134
9) 1024k nodes vs 512k nodes +806 -167 =1026 +115
10) 2048k nodes vs 1024k nodes +344 -83 =572 +93
11) 4096k nodes vs 2048k nodes +307 -85 =607 +79
As an aside, the diminishing returns surprised me: I was expecting p(win | "X% smarter") to be independent of the 1x node's compute. My guess is this is because Houdini 3 is close enough to chess' skill ceiling (4877 Elo on CCRL for the perfect engine according to Laskos, extrapolating from his data above, or 1707 points above Houdini 3 40/40' CCRL level) that p(win) starts diminishing very early, and that you won't see this in "IRL games" unless the 1x player somehow manages to steer the future into a lower skill ceiling domain somehow. Another aside is that this diminishing returns pattern seems reminiscent of the "scaling wall" talk which predicts that walls are an artifact of low skill ceilings and that the highest scaling gains will come from ~limitless skill ceiling domains (automated theorem proving?), but I don't expect this observation to mean much either, mostly because I don't know what I'm talking about at this point.
The diminishing returns isn't too surprising, because you are holding the model size fixed (whatever that is for Houdini 3), and the search sigmoids hard. Hence, diminishing returns as you jump well past the initial few searches with the largest gains, to large search budgets like 2k vs 4k (and higher).
This is not necessarily related to 'approaching perfection', because you can see the sigmoid of the search budget even with weak models very far from the known oracle performance (as well as stronger models); for example, NNs playing Hex: https://arxiv.org/pdf/2104.03113#page=5 Since it's a sigmoid, at a certain point, your returns will steeply diminish and indeed start to look like a flat line and a mere 2x increase in search budget does little. This is why you cannot simply replace larger models with small models that you search the hell out of: because you hit that sigmoid where improvement basically stops happening.
At that point, you need a smarter model, which can make intrinsically better choices about where to explore, and isn't trapped dumping endless searches into its own blind spots & errors. (At least, that's how I think of it qualitatively: the sigmoiding happens because of 'unknown unknowns', where the model can't see a key error it made somewhere along the way, and so almost all searches increasingly explore dead branches that a better model would've discarded immediately in favor of the true branch. Maybe you can think of very large search budgets applied to a weak model as the weak model 'approaching perfection... of its errors'? In the spirit of the old Dijkstra quip, 'a mistake carried through to perfection'.)
Fortunately, 'when making an axe handle with an axe, the model is indeed near at hand', and a weak model which has been 'policy-improved' by search is, for that one datapoint, equivalent to a somewhat larger better model - if only you can figure out how to keep that improvement around...
Thanks, I especially appreciate that NNs playing Hex paper; Figure 8 in particular amazes me in illustrating how much more quickly perf. vs test-time compute sigmoids than I anticipated even after reading your comment. I'm guessing https://www.gwern.net/ has papers with the analogue of Fig 8 for smarter models, in which case it's time to go rummaging around...
Just reread Scott Aaronson's We Are the God of the Gaps (a little poem) from 2022:
When the machines outperform us on every goal for which performance can be quantified,
When the machines outpredict us on all events whose probabilities are meaningful,
When they not only prove better theorems and build better bridges, but write better Shakespeare than Shakespeare and better Beatles than the Beatles,
All that will be left to us is the ill-defined and unquantifiable,
The interstices of Knightian uncertainty in the world,
The utility functions that no one has yet written down,
The arbitrary invention of new genres, new goals, new games,
None of which will be any “better” than what the machines could invent, but will be ours,
And which we can call “better,” since we won’t have told the machines the standards beforehand.
We can be totally unfair to the machines that way.
And for all that the machines will have over us,
We’ll still have this over them:
That we can’t be copied, backed up, reset, run again and again on the same data—
All the tragic limits of wet meat brains and sodium-ion channels buffeted by microscopic chaos,
Which we’ll strategically redefine as our last strengths.
On one task, I assure you, you’ll beat the machines forever:
That of calculating what you, in particular, would do or say.
There, even if deep networks someday boast 95% accuracy, you’ll have 100%.
But if the “insights” on which you pride yourself are impersonal, generalizable,
Then fear obsolescence as would a nineteenth-century coachman or seamstress.
From earliest childhood, those of us born good at math and such told ourselves a lie:
That while the tall, the beautiful, the strong, the socially adept might beat us in the external world of appearances,
Nevertheless, we beat them in the inner sanctum of truth, where it counts.
Turns out that anyplace you can beat or be beaten wasn’t the inner sanctum at all, but just another antechamber,
And the rising tide of the learning machines will flood them all,
Poker to poetry, physics to programming, painting to plumbing, which first and which last merely a technical puzzle,
One whose answers upturn and mock all our hierarchies.
And when the flood is over, the machines will outrank us in all the ways we can be ranked,
Leaving only the ways we can’t be.
Feels poignant.
Philosophy bear's response to Scott is worth reading too.
Curated and popular this week
I chose to study physics in undergrad because I wanted to "understand the universe" and naively thought string theory was the logically correct endpoint of this pursuit, and was only saved from that fate by not being smart enough to get into a good grad school. Since then I've come to conclude that string theory is probably a dead end, albeit an astonishingly alluring one for a particular type of person. In that regard I find anecdotes like the following by Ron Maimon on Physics SE interesting — the reason string theorists believe isn’t the same as what they tell people, so it’s better to ask for their conversion stories:
The rest of Ron's answer elaborates on his own conversion story. The interesting part to me is that Ron began by trying to "kill string theory", and in fact he was very happy that he was going to do so, but then was annoyed by an argument of his colleague that mathematically worked, and in the year or two he spent puzzling over why it worked he had an epiphany that convinced him string theory was correct, which sounds like nonsense to the uninitiated. (This phenomenon where people who gain understanding of the thing become incomprehensible to others sounds a lot like the discussions on LW on enlightenment by the way.)
Re other theories, I don't think that all other theories in existence have infinitely many adjustable parameters, and if he's referring to the fact that lots of theories have adjustable parameters that can range over the real numbers, which are infinitely complicated in general, than that's different, and string theory may have this issue as well.
Re string theory's issue of being vacuous, I think the core thing that string theory predicts that other quantum gravity models don't is that at the large scale, you recover general relativity and the standard mod... (read more)