All of Thomas Larsen's Comments + Replies
This wasn't intended to be humor. In the scenario, we write:
(To avoid singling out any one existing company, we’re going to describe a fictional artificial general intelligence company, which we’ll call OpenBrain. We imagine the others to be 3–9 months behind OpenBrain.)
I think that OpenAI, GDM, and Anthropic are in the lead and are the most likely to be ahead, with similar probability.
Thank you! We actually tried to write one that was much closer to a vision we endorse! The TLDR overview was something like:
- Both the US and Chinese leading AGI projects stop in response to evidence of egregious misalignment.
- Sign a treaty to pause smarter-than-human AI development, with compute based enforcement similar to ones described in our live scenario, except this time with humans driving the treaty instead of the AI.
- Take time to solve alignment (potentially with the help of the AIs). This period could last anywhere between 1-20 ye
Thanks - I see, I was misunderstanding.
...Proposal part 1: Shoggoth/Face Distinction: Instead of having one model undergo agency training, we have two copies of the base model work together, specializing in different parts of the job, and undergo training together. Specifically we have the "shoggoth" copy responsible for generating all the 'reasoning' or 'internal' CoT, and then we have the "face" copy responsible for the 'actions' or 'external' outputs. So e.g. in a conversation with the user, the Shoggoth would see the prompt and output a bunch of reasoning token CoT; the Face would see the prom
I think a problem with all the proposed terms is that they are all binaries, and one bit of information is far too little to characterize takeoff:
- One person's "slow" is >10 years, another's is >6 months.
- The beginning and end points are super unclear; some people might want to put the end point near the limits of intelligence, some people might want to put the beginning points at >2x AI R&D speed, some at 10, etc.
- In general, a good description of takeoff should characterize capabilities at each point on the curve.
So I d...
Perhaps that was overstated. I think there is maybe a 2-5% chance that Anthropic directly causes an existential catastrophe (e.g. by building a misaligned AGI). Some reasoning for that:
- I doubt Anthropic will continue to be in the lead because they are behind OAI/GDM in capital. They do seem around the frontier of AI models now, though, which might translate to increased returns, but it seems like they do best on very short timelines worlds.
- I think that if they could cause an intelligence explosion, it is more likely than not that they would pau
I think you probably under-rate the effect of having both a large number & concentration of very high quality researchers & engineers (more than OpenAI now, I think, and I wouldn't be too surprised if the concentration of high quality researchers was higher than at GDM), being free from corporate chafe, and also having many of those high quality researchers thinking (and perhaps being correct in thinking, I don't know) they're value aligned with the overall direction of the company at large. Probably also Nvidia rate-limiting the purchases of large...
I agree with Zach that Anthropic is the best frontier lab on safety, and I feel not very worried about Anthropic causing an AI related catastrophe. So I think the most important asks for Anthropic to make the world better are on its policy and comms.
I think that Anthropic should more clearly state its beliefs about AGI, especially in its work on policy. For example, the SB-1047 letter they wrote states:
...Broad pre-harm enforcement. The current bill requires AI companies to design and implement SSPs that meet certain standards – for example they m
Yeah, actual FLOPs are the baseline thing that's used in the EO. But the OpenAI/GDM/Anthropic RSPs all reference effective FLOPs.
If there's a large algorithmic improvement you might have a large gap in capability between two models with the same FLOP, which is not desirable. Ideal thresholds in regulation / scaling policies are as tightly tied as possible to the risks.
Another downside that FLOPs / E-FLOPs share is that it's unpredictable what capabilities a 1e26 or 1e28 FLOPs model will have. And it's unclear what capabilities will emerge from a small bit of scaling: it's possible that within a 4x flop scaling you get high capabilities that had not appeared at all in the smaller model.
Credit: Mainly inspired by talking with Eli Lifland. Eli has a potentially-published-soon document here.
The basic case against against Effective-FLOP.
- We're seeing many capabilities emerge from scaling AI models, and this makes compute (measured by FLOPs utilized) a natural unit for thresholding model capabilities. But compute is not a perfect proxy for capability because of algorithmic differences. Algorithmic progress can enable more performance out of a given amount of compute. This makes the idea of effective FLOP tempti
The fact that AIs will be able to coordinate well with each other, and thereby choose to "merge" into a single agent
My response: I agree AIs will be able to coordinate with each other, but "ability to coordinate" seems like a continuous variable that we will apply pressure to incrementally, not something that we should expect to be roughly infinite right at the start. Current AIs are not able to "merge" with each other.
Ability to coordinate being continuous doesn't preclude sufficiently advanced AIs acting like a single agent. Why would it need to be infin...
Thanks for the response!
...If instead of reward circuitry inducing human values, evolution directly selected over policies, I'd expect similar inner alignment failures.
I very strongly disagree with this. "Evolution directly selecting over policies" in an ML context would be equivalent to iterated random search, which is essentially a zeroth-order approximation to gradient descent. Under certain simplifying assumptions, they are actually equivalent. It's the loss landscape an parameter-function map that are responsible for most of a learning process's in
We haven't asked specific individuals if they're comfortable being named publicly yet, but if advisors are comfortable being named, I'll announce that soon. We're also in the process of having conversations with academics, AI ethics folks, AI developers at small companies, and other civil society groups to discuss policy ideas with them.
So far, I'm confident that our proposals will not impede the vast majority of AI developers, but if we end up receiving feedback that this isn't true, we'll either rethink our proposals or remove this claim from our a...
Already, there are dozens of fine-tuned Llama2 models scoring above 70 on MMLU. They are laughably far from threats. This does seem like an exceptionally low bar. GPT-4, given the right prompt crafting, and adjusting for errors in MMLU has just been shown to be capable of 89 on MMLU. It would not be surprising for Llama models to achieve >80 on MMLU in the next 6 months.
I think focusing on a benchmark like MMLU is not the right approach, and will be very quickly outmoded. If we look at the other criteria (which, as you propose it now, any and all are a ...
I’ve changed the wording to “Only a few technical labs (OpenAI, DeepMind, Meta, etc) and people working with their models would be regulated currently.” The point of this sentence is to emphasize that this definition still wouldn’t apply to the vast majority of AI development -- most AI development uses small systems, e.g. image classifiers, self driving cars, audio models, weather forecasting, the majority of AI used in health care, etc.
Credit for changing the wording, but I still feel this does not adequately convey how sweeping the impact of the proposal would be if implemented as-is. Foundation model-related work is a sizeable and rapidly growing chunk of active AI development. Of the 15K pre-print papers posted on arXiv under the CS.AI category this year, 2K appear to be related to language models. The most popular Llama2 model weights alone have north of 500K downloads to date, and foundation-model related repos have been trending on Github for months. "People working with [a few tec...
(ETA: these are my personal opinions)
Notes:
- We're going to make sure to exempt existing open source models. We're trying to avoid pushing the frontier of open source AI, not trying to put the models that are already out their back in the box, which I agree is intractable.
- These are good points, and I decided to remove the data criteria for now in response to these considerations.
- The definition of frontier AI is wide because it describes the set of models that the administration has legal authority over, not the set of models that would be r
Thanks!
I spoke with a lot of other AI governance folks before launching, in part due to worries about the unilateralists curse. I think that there is a chance this project ends up being damaging, either by being discordant with other actors in the space, committing political blunders, increasing the polarization of AI, etc. We're trying our best to mitigate these risks (and others) and are corresponding with some experienced DC folks who are giving us advice, as well as being generally risk-averse in how we act. That being said, some senior folks I've talked to are bearish on the project for reasons including the above.
DM me if you'd be interested in more details, I can share more offline.
Your current threshold does include all Llama models (other than llama-1 6.7/13 B sizes), since they were trained with > 1 trillion tokens.
Yes, this reasoning was for capabilities benchmarks specifically. Data goes further with future algorithmic progress, so I thought a narrower criteria for that one was reasonable.
I also think 70% on MMLU is extremely low, since that's about the level of ChatGPT 3.5, and that system is very far from posing a risk of catastrophe.
This is the threshold for the government has the ability to say no to, an...
This is the threshold for the government has the ability to say no to, and is deliberately set well before catastrophe.
There are disadvantages to giving the government "the ability to say no" to models used by thousands of people. There are disadvantages even in a frame where AI-takeover is the only thing you care about!
For instance, if you give the government too expansive a concern such that it must approve many models "well before the threshold", then it will have thousands of requests thrown at it regularly, and it could (1) either try to scrutinize...
Yes, this reasoning was for capabilities benchmarks specifically. Data goes further with future algorithmic progress, so I thought a narrower criteria for that one was reasonable.
So, you are deliberately targeting models such as LLama-2, then? Searching HuggingFace for "Llama-2" currently brings up 3276 models. As I understand the legislation you're proposing, each of these models would have to undergo government review, and the government would have the perpetual capacity to arbitrarily pull the plug on any of them.
I expect future small, open-source...
It's worth noting that this (and the other thresholds) are in place because we need a concrete legal definition for frontier AI, not because they exactly pin down which AI models are capable of catastrophe. It's probable that none of the current models are capable of catastrophe. We want a sufficiently inclusive definition such that the licensing authority has the legal power over any model that could be catastrophically risky.
That being said -- Llama 2 is currently the best open-source model and it gets 68.9% on the MMLU. It seems relatively unimpo...
Your current threshold does include all Llama models (other than llama-1 6.7/13 B sizes), since they were trained with > 1 trillion tokens.
I also think 70% on MMLU is extremely low, since that's about the level of ChatGPT 3.5, and that system is very far from posing a risk of catastrophe.
The cutoffs also don't differentiate between sparse and dense models, so there's a fair bit of non-SOTA-pushing academic / corporate work that would fall under these cutoffs.
Yeah, this is fair, and later in the section they say:
Careful scaling. If the developer is not confident it can train a safe model at the scale it initially had planned, they could instead train a smaller or otherwise weaker model.
Which is good, supports your interpretation, and gets close to the thing I want, albeit less explicitly than I would have liked.
I still think the "delay/pause" wording pretty strongly implies that the default is to wait for a short amount of time, and then keep going at the intended capability level. I think the...
The first line of defence is to avoid training models that have sufficient dangerous capabilities and misalignment to pose extreme risk. Sufficiently concerning evaluation results should warrant delaying a scheduled training run or pausing an existing one
It's very disappointing to me that this sentence doesn't say "cancel". As far as I understand, most people on this paper agree that we do not have alignment techniques to align superintelligence. Therefor, if the model evaluations predict an AI that is sufficiently smarter than humans, the training run should be cancelled.
- Deliberately create a (very obvious[2]) inner optimizer, whose inner loss function includes no mention of human values / objectives.[3]
- Grant that inner optimizer ~billions of times greater optimization power than the outer optimizer.[4]
- Let the inner optimizer run freely without any supervision, limits or interventions from the outer optimizer.[5]
I think that the conditions for an SLT to arrive are weaker than you describe.
For (1), it's unclear to me why you think you need to have this multi-level inner structure.[1] If instead of reward circuitr...
Sometimes, but the norm is to do 70%. This is mostly done on a case by case basis, but salient factors to me include:
- Does the person need the money? (what cost of living place are they living in, do they have a family, etc)
- What is the industry counterfactual? If someone would make 300k, we likely wouldn't pay them 70%, while if their counterfactual was 50k, it feels more reasonable to pay them 100% (or even more).
- How good is the research?
I'm a guest fund manager for the LTFF, and wanted to say that my impression is that the LTFF is often pretty excited about giving people ~6 month grants to try out alignment research at 70% of their industry counterfactual pay (the reason for the 70% is basically to prevent grift). Then, the LTFF can give continued support if they seem to be doing well. If getting this funding would make you excited to switch into alignment research, I'd encourage you to apply.
I also think that there's a lot of impactful stuff to do for AI existential safety that isn...
Some claims I've been repeating in conversation a bunch:
Safety work (I claim) should either be focused on one of the following
- CEV-style full value loading, to deploy a sovereign
- A task AI that contributes to a pivotal act or pivotal process.
I think that pretty much no one is working directly on 1. I think that a lot of safety work is indeed useful for 2, but in this case, it's useful to know what pivotal process you are aiming for. Specifically, why aren't you just directly working to make that pivotal act/process happen? Why do you ...
(I deleted this comment)
Fwiw I'm pretty confident that if a top professor wanted funding at 50k/year to do AI Safety stuff they would get immediately funded, and that the bottleneck is that people in this reference class aren't applying to do this.
There's also relevant mentorship/management bottlenecks in this, so funding them to do their own research is generally a lot less overall costly than if it also required oversight.
(written quickly, sorry if unclear)
Thinking about ethics.
After thinking more about orthogonality I've become more confident that one must go about ethics in a mind-dependent way. If I am arguing about what is 'right' with a paperclipper, there's nothing I can say to them to convince them to instead value human preferences or whatever.
I used to be a staunch moral realist, mainly relying on very strong intuitions against nihilism, and then arguing something that not nihilism -> moral realism. I now reject the implication, and think that there is both 1) no universal, objective morali...
In real world computers, we have finite memory, so my reading of this was assuming a finite state space. The fractal stuff requires an infinite sets, where two notions of smaller ('is a subset of' and 'has fewer elements') disagree -- the mini-fractal is a subset of the whole fractal, but it has the same number of elements and hence corresponds perfectly.
Following up to clarify this: the point is that this attempt fails 2a because if you perturb the weights along the connection , there is now a connection from the internal representation of to the output, and so training will send this thing to the function .
(My take on the reflective stability part of this)
The reflective equilibrium of a shard theoretic agent isn’t a utility function weighted according to each of the shards, it’s a utility function that mostly cares about some extrapolation of the (one or very few) shard(s) that were most tied to the reflective cognition.
It feels like a ‘let’s do science’ or ‘powerseek’ shard would be a lot more privileged, because these shards will be tied to the internal planning structure that ends up doing reflection for the first time.
There’s a huge difference betw...
Some rough takes on the Carlsmith Report.
Carlsmith decomposes AI x-risk into 6 steps, each conditional on the previous ones:
- Timelines: By 2070, it will be possible and financially feasible to build APS-AI: systems with advanced capabilities (outperform humans at tasks important for gaining power), agentic planning (make plans then acts on them), and strategic awareness (its plans are based on models of the world good enough to overpower humans).
- Incentives: There will be strong incentives to build and deploy APS-AI.
- Alignment difficulty: It will be muc
...I think a really substantial fraction of people who are doing "AI Alignment research" are instead acting with the primary aim of "make AI Alignment seem legit". These are not the same goal, a lot of good people can tell and this makes them feel kind of deceived, and also this creates very messy dynamics within the field where people have strong opinions about what the secondary effects of research are, because that's the primary thing they are interested in, instead of asking whether the research points towards useful true things for actually aligning the
- CAIS
Can we adopt a norm of calling this Safe.ai? When I see "CAIS", I think of Drexler's "Comprehensive AI Services".
This list seems partially right, though I would basically put all of Deepmind in the "make legit" category (I think they are genuinely well-intentioned about this, but I've had long disagreements with e.g. Rohin about this in the past). As a concrete example of this, whose effects I actually quite like, think of the specification gaming list. I think the second list is missing a bunch of names and instances, in-particular a lot of people in different parts of academia, and a lot of people who are less core "AINotKillEveryonism" flavored.
Like, let's take "A...
I personally benefitted tremendously from the Lightcone offices, especially when I was there over the summer during SERI MATS. Being able to talk to lots of alignment researchers and other aspiring alignment researchers increased my subjective rate of alignment upskilling by >3x relative to before, when I was in an environment without other alignment people.
Thanks so much to the Lightcone team for making the office happen. I’m sad (emotionally, not making a claim here whether it was the right decision or not) to see it go, but really grateful that it existed.
- Because you have a bunch of shards, and you need all of them to balance each other out to maintain the 'appears nice' property. Even if I can't predict which ones will be self modified out, some of them will, and this could disrupt the balance.
- I expect the shards that are more [consequentialist, powerseeky, care about preserving themselves] to become more dominant over time. These are probably the relatively less nice shards
These are both handwavy enough that I don't put much credence in them.
Yeah good point, edited
For any 2 of {reflectively stable, general, embedded}, I can satisfy those properties.
- {reflectively stable, general} -> do something that just rolls out entire trajectories of the world given different actions that it takes, and then has some utility function/preference ordering over trajectories, and selects actions that lead to the highest expected utility trajectory.
- {general, embedded} -> use ML/local search with enough compute to rehash evolution and get smart agents out.
- {reflectively stable, embedded} -> a sponge or a current day ML system.
Some thoughts on inner alignment.
1. The type of object of a mesa objective and a base objective are different (in real life)
In a cartesian setting (e.g. training a chess bot), the outer objective is a function , where is the state space, and are the trajectories. When you train this agent, it's possible for it to learn some internal search and mesaobjective , since the model is big enough to express some utility function over trajectories. For example, it might learn a classifier that e...
Current impressions of free energy in the alignment space.
- Outreach to capabilities researchers. I think that getting people who are actually building the AGI to be more cautious about alignment / racing makes a bunch of things like coordination agreements possible, and also increases the operational adequacy of the capabilities lab.
- One of the reasons people don't like this is because historically outreach hasn't gone well, but I think the reason for this is that mainstream ML people mostly don't buy "AGI big deal", whereas lab capabilities rese
Thinking a bit about takeoff speeds.
As I see it, there are ~3 main clusters:
- Fast/discountinuous takeoff. Once AIs are doing the bulk of AI research, foom happens quickly, before then, they aren't really doing anything that meaningful.
- Slow/continuous takeoff. Once AIs are doing the bulk of AI research, foom happens quickly, before then, they do alter the economy significantly
- Perenial slowness. Once AIs are doing the bulk of AI research, there is no foom even still, maybe because of compute bottlenecks, and so there is sort of constant rate
At least under most datasets, it seems to me like the zero NN fails condition 2a, as perturbing the weights will not cause it to go back to zero.
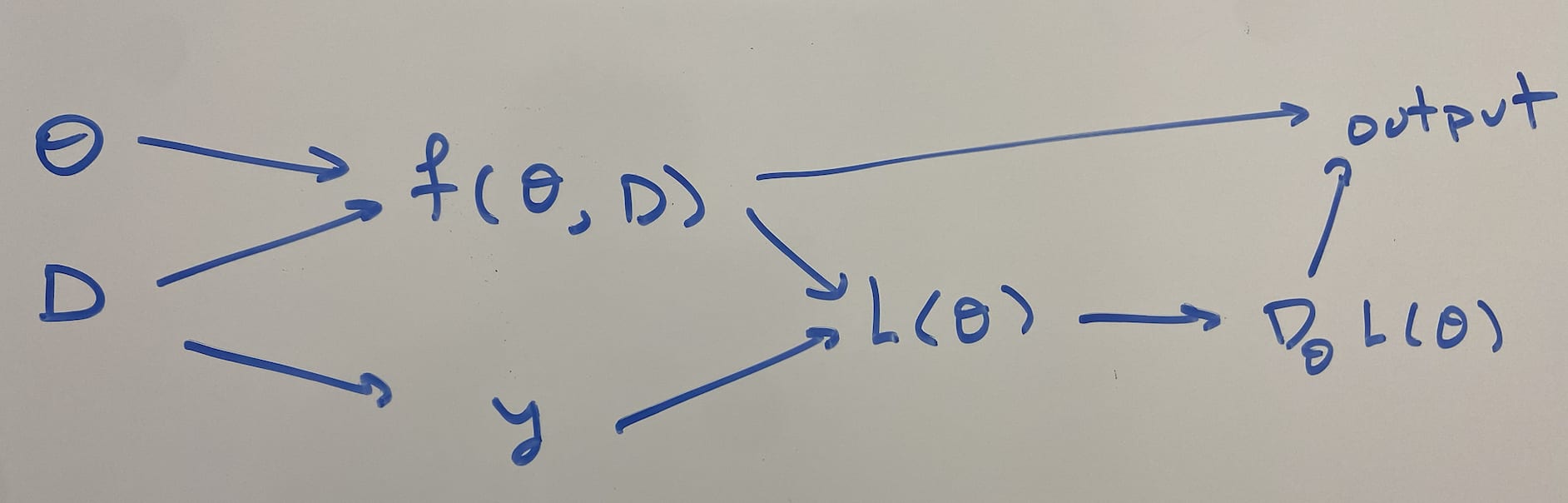
This is a plausible internal computation that the network could be doing, but the problem is that the gradients flow back through from the output to the computation of the gradient to the true value y, and so GD will use that to set the output to be the appropriate true value.
This feels like cheating to me, but I guess I wasn't super precise with 'feedforward neural network'. I meant 'fully connected neural network', so the gradient computation has to be connected by parameters to the outputs. Specifically, I require that you can write the network as
where the weight matrices are some nice function of (where we need a weight sharing function to make the dimensions work out. The weight sharing function takes in and produces the matrices that are actually used in ...
Slower takeoff -> warning shots -> improved governance (e.g. through most/all major actors getting clear[er] evidence of risks) -> less pressure to rush
Agree that this is an effect. The reason it wasn't immediately as salient is because I don't expect the governance upside to outweigh the downside of more time for competition. I'm not confident of this and I'm not going to write down reasons right now.
(As OP argued) Shorter timelines -> China has less of a chance to have leading AI companies -> less pressure to rush
Agree, though I thin...
My take on the salient effects:
Shorter timelines -> increased accident risk from not having solved technical problem yet, decreased misuse risk, slower takeoffs
Slower takeoffs -> decreased accident risk because of iteration to solve technical problem, increased race / economic pressure to deploy unsafe model
Given that most of my risk profile is dominated by a) not having solved technical problem yet, and b) race / economic pressure to deploy unsafe models, I'm tentatively in the long timelines + fast takeoff quadrant as being the safest.
I agree with parts of that. I'd also add the following (or I'd be curious why they're not important effects):
- Slower takeoff -> warning shots -> improved governance (e.g. through most/all major actors getting clear[er] evidence of risks) -> less pressure to rush
- (As OP argued) Shorter timelines -> China has less of a chance to have leading AI companies -> less pressure to rush
More broadly though, maybe we should be using more fine-grained concepts than "shorter timelines" and "slower takeoffs":
- The salient effects of "shorter timelines"
This is exemplified by John Wentworth's viewpoint that successfully Retargeting the Search is a version of solving the outer alignment problem.
Could you explain what you mean by this? IMO successfully retargeting the search solves inner alignment but it leaves unspecified the optimization target. Deciding what to target the search at seems outer alignment-shaped to me.
Also, nice post! I found it clear.
There are several game theoretic considerations leading to races to the bottom on safety.
- Investing resources into making sure that AI is safe takes away resources to make it more capable and hence more profitable. Aligning AGI probably takes significant resources, and so a competitive actor won't be able to align their AGI.
- Many of the actors in the AI safety space are very scared of scaling up models, and end up working on AI research that is not at the cutting edge of AI capabilities. This should mean that the actors at the cutting edge tend t
My favorite for AI researchers is Ajeya's Without specific countermeasures, because I think it does a really good job being concrete about a training set up leading to deceptive alignment. It also is sufficiently non-technical that a motivated person not familiar with AI could understand the key points.
It means 'is a subset of but not equal to'
This seems interesting and connected to the idea of using a speed prior to combat deceptive alignment.
This is a model-independent way of proving if an AI system is honest.
I don't see how this is a proof, it seems more like a heuristic. Perhaps you could spell out this argument more clearly?
Also, it is not clear to me how to use a timing attack in the context of a neural network, because in a standard feedforward network, all parameter settings will use the same amount of computation in a forward pass and hence run in the same amount of ti...
I'm excited for ideas for concrete training set ups that would induce deception2 in an RLHF model, especially in the context of an LLM -- I'm excited about people posting any ideas here. :)
For what its worth, my view is that we're very likely to be wrong about the specific details in both of the endings -- they are obviously super conjunctive. I don't think that there's any way around this because we can be confident AGI is going to cause some ex-ante surprising things to happen.
Also, this is scenario is around 20th percentile timelines for me, my median is early 2030s (though other authors disagree with me). I also feel much more confident about the pre-2027 scenario than about the post 2027 scenario.
Is your disagreement that you thin... (read more)