Nice post. I think this is a really interesting discovery.
[Copying from messages with Joseph Bloom]
TLDR: I'm confused what is different about the SAE input that causes the absorbed feature not to fire.
Me:
Summary of your findings
- Say you have a “starts with s” feature and a “snake” feature.
- You find that for most words, “starts with s” correctly categorizes words that start with s. But for a few words that start with s, like snake, it doesn’t fire.
- These exceptional tokens where it doesn’t fire, all have another feature that corresponds very closely to the token. For example, there is a “snake” feature that corresponds strongly to the snake token.
- You say that the “snake” feature has absorbed the “starts with s” feature because the concept of snake also contains/entails the concept of ‘start with s’.
- Most of the features that absorb other features correspond to common words, like “and”.
So why is this happening? Well it makes sense that the model can do better on L1 on the snake token by just firing a single “snake” feature (rather than the “starts with s” feature and, say, the “reptile” feature). And it makes sense it would only have enough space to have these specific token features for common tokens.
Joseph Bloom:
rather than the “starts with s” feature and, say, the “reptile” feature
We found cases of seemingly more general features getting absorbed in the context of spelling but they are more rare / probably the exception. It's worth distinguishing that we suspect that feature absorption is just easiest to find for token aligned features but conceptually could occur any time a similar structure exists between features.
And it makes sense it would only have enough space to have these specific token features for common tokens.
I think this needs further investigation. We certainly sometimes see rarer tokens which get absorbed (eg: a rare token is a translated word of a common token). I predict there is a strong density effect but it could be non-trivial.
Me:
We found cases of seemingly more general features getting absorbed in the context of spelling
What’s an example?
We certainly sometimes see rarer tokens which get absorbed (eg: a rare token is a translated word of a common token)
You mean like the “starts with s” feature could be absorbed into the “snake” feature on the french word for snake?
Do this only happen if the french word also starts with s?
Joseph Bloom:
What’s an example?
- Latent aligned for a few words at once. Eg: "assistance" but fires weakly on "help". We saw it absorb both "a" and "h"!
- Latent from multi-token words that also fires on words that share a common prefix (https://feature-absorption.streamlit.app/?layer=16&sae_width=65000&sae_l0=128&letter=c see latent 26348).
- Latent than fires on a token + weakly on subsequent tokens https://feature-absorption.streamlit.app/?layer=16&sae_width=65000&sae_l0=128&letter=c
You mean like the “starts with s” feature could be absorbed into the “snake” feature on the french word for snake?
Yes
Do this only happen if the french word also starts with s?
More likely. I think the process is stochastic so it's all distributions.
↓[Key point]↓
Me:
But here’s what I’m confused about. How does the “starts with s” feature ‘know’ not to fire? How is it able to fire on all words that start with s, except those tokens (like “snake”) that having a strongly correlated feature? I would assume that the token embeddings of the model contain some “starts with s” direction. And the “starts with s” feature input weights read off this direction. So why wouldn’t it also activate on “snake”? Surely that token embedding also has the “starts with s” direction?
Joseph Bloom:
I would assume that the token embeddings of the model contain some “starts with s” direction. And the “starts with s” feature input weights read off this direction. So why wouldn’t it also activate on “snake”? Surely that token embedding also has the “starts with s” direction?
I think the success of the linear probe is why we think the snake token does have the starts with s direction. The linear probe has much better recall and doesn't struggle with obvious examples. I think the feature absorption work is not about how models really work, it's about how SAEs obscure how models work.
But here’s what I’m confused about. How does the “starts with s” feature ‘know’ not to fire? Like what is the mechanism by which it fires on all words that start with s, except those tokens (like “snake”) that having a strongly correlated feature?
Short answer, I don't know. Long answer - some hypotheses:
- Linear probes, can easily do calculations of the form "A AND B". In large vector spaces, it may be possible to learn a direction of the form "(^S.*) AND not (snake) and not (sun) ...". Note that "snake" has a component seperate to starts with s so this is possible. To the extent this may be hard, that's possibly why we don't see more absorption but my own intuition says that in large vector spaces this should be perfectly possible to do.
- Encoder weights and Decoder weights aren't tied. If they were, you can imagine the choosing these exceptions for absorbed examples would damage reconstruction performance. Since we don't tie the weights, the model can detect "(^S.*) AND not (snake) and not (sun) ..." but write "(^S.*)". I'm interested to explore this further and am sad we didn't get to this in the project.
Also worth noting, in the paper we only classify something as "absorption" if the main latent fully doesn't fire. We also saw cases which I would call "partial absorption" where the main latent fires, but weakly, and both the absorbing latent and the main latent have positive cosine sim with the probe direction, and both have ablation effect on the spelling task.
Another intuition I have is that when the SAE absorbs a dense feature like "starts with S" into a sparse latent like "snake", it loses the ability to adjust the relative levels of the various component features relative to each other. So maybe the "snake" latent is 80% snakiness, and 20% starts with S, but then in a real activation the SAE needs to reconstruct 75% snakiness and 25% starts with S. So to do this, it might fire a proper "starts with S" latent but weakly to make up the difference.
Hopefully this is something we can validate with toy models. I suspect that the specific values of L1 penalty and feature co-occurrence rates / magnitudes will lead to different levels of absorption.
This thread reminds me that comparing feature absorption in SAEs with tied encoder / decoder weights and in end-to-end SAEs seems like valuable follow up.
Another approach would be to use per-token decoder bias as seen in some previous work: https://www.lesswrong.com/posts/P8qLZco6Zq8LaLHe9/tokenized-saes-infusing-per-token-biases But this would only solve it when the absorbing feature is a token. If it's more abstract then this wouldn't work as well.
Semi-relatedly, since most (all) of the SAE work since the original paper has gone into untied encoded/decoder weights, we don't really know whether modern SAE architectures like Jump ReLU or TopK suffer as large of a performance hit as the original SAEs do, especially with the gains from adding token biases.
Great work! Using spelling is very clear example of how information gets absorbed in the SAE latent, and indeed in Meta-SAEs we found many spelling/sound related meta-latents.
I have been thinking a bit on how to solve this problem and one experiment that I would like to try is to train an SAE and a meta-SAE concurrently, but in an adversarial manner (kind of like a GAN), such that the SAE is incentivized to learn latent directions that are not easily decomposable by the meta-SAE.
Potentially, this would remove the "Starts-with-L"-component from the "lion"-token direction and activate the "Starts-with-L" latent instead. Although this would come at the cost of worse sparsity/reconstruction.
Great work! Using spelling is very clear example of how information gets absorbed in the SAE latent, and indeed in Meta-SAEs we found many spelling/sound related meta-latents.
Thanks! We were sad not to have time to try out Meta-SAEs but want to in the future.
I have been thinking a bit on how to solve this problem and one experiment that I would like to try is to train an SAE and a meta-SAE concurrently, but in an adversarial manner (kind of like a GAN), such that the SAE is incentivized to learn latent directions that are not easily decomposable by the meta-SAE.
Potentially, this would remove the "Starts-with-L"-component from the "lion"-token direction and activate the "Starts-with-L" latent instead. Although this would come at the cost of worse sparsity/reconstruction.
I think this is the wrong way to go to be honest. I see it as doubling down on sparsity and a single decomposition, both of which I think may just not reflect the underlying data generating process. Heavily inspired by some of John Wentworth's ideas here.
Rather than doubling down on a single single-layered decomposition for all activations, why not go with a multi-layered decomposition (ie: some combination of SAE and metaSAE, preferably as unsupervised as possible). Or alternatively, maybe the decomposition that is most useful in each case changes and what we really need is lots of different (somewhat) interpretable decompositions and an ability to quickly work out which is useful in context.
Rather than doubling down on a single single-layered decomposition for all activations, why not go with a multi-layered decomposition (ie: some combination of SAE and metaSAE, preferably as unsupervised as possible). Or alternatively, maybe the decomposition that is most useful in each case changes and what we really need is lots of different (somewhat) interpretable decompositions and an ability to quickly work out which is useful in context.
Definitely seems like multiple ways to interpret this work, as also described in SAE feature geometry is outside the superposition hypothesis. Either we need to find other methods and theory that somehow finds more atomic features, or we need to get a more complete picture of what the SAEs are learning at different levels of abstraction and composition.
Both seem important and interesting lines of work to me!
I would argue that the starting point is to look in variation in exogenous factors. Like let's say you have a text describing a scene. You could remove individual sentences describing individual objects in the scene to get peturbed texts describing scenes without those objects. Then the first goal for interpretability can be to map out how those changes flow through the network.
This is probably more relevant for interpreting e.g. a vision model than for interpreting a language model. Part of the challenge for language models is that we don't have a good idea of their final use-case, so it's hard to come up with an equally-representative task to interpret them on. But maybe with some work one could find one.
I think that's exactly what we did? Though to be fair we de-emphasized this version of the narrative in the paper: We asked whether Gemma-2-2b could spell / do the first letter identification task. We then asked which latents causally mediated spelling performance, comparing SAE latents to probes. We found that we couldn't find a set of 26 SAE latents that causally mediated spelling because the relationship between the latents and the character information, "exogenous factors", if I understand your meaning, wasn't as clear as it should have been. As I emphasized in a different comment, this work is not about mechanistic anomalies or how the model spells, it's about measurement error in the SAE method.
Ah, I didn't read the paper, only the LW post.
As I emphasized in a different comment, this work is not about mechanistic anomalies or how the model spells, it's about measurement error in the SAE method.
I understand that, I more meant my suggestion as an idea for if you want to go beyond poking holes in SAE to instead solve interpretability.
We asked whether Gemma-2-2b could spell / do the first letter identification task. We then asked which latents causally mediated spelling performance, comparing SAE latents to probes.
One downside to this is that spelling is a fairly simple task for LLMs.
We found that we couldn't find a set of 26 SAE latents that causally mediated spelling because the relationship between the latents and the character information, "exogenous factors", if I understand your meaning, wasn't as clear as it should have been.
I expect that:
- Objects in real-world tasks will be spread over many tokens, so they will not be identifiable within individual tokens.
- Objects in real-world tasks will be massively heterogenous, so they will not be identifiable with a small number of dimensions.
Implications:
- SAE latents will not be relevant at all, because they are limited to individual tokens.
- The value of interpretability will less be about finding a small fixed set of mediators and more about developing a taxonomy of root causes and tools that can be used to identify those root causes.
- SAEs would be an example of such a tool, except I don't expect they will end up working.
A half-baked thought on a practical use-case would be, LLMs are often used for making chatbot assistants. If one had a taxonomy for different kinds of users of chatbots, and how they influence the chatbots, one could maybe create a tool for debugging cases where the language model does something weird, by looking at chat logs and extracting the LLM's model for what kind of user it is dealing with.
But I guess part of the long-term goal of mechanistic interpretability is people are worried about x-risk from learned optimization, and they want to identify fragments of that ahead of time so they can ring the fire alarm. I guess upon reflection I'm especially bearish about this strategy because I think x-risk will occur at a higher level than individual LLMs and that whatever happens when we're diminished all the way down to a forward propagation is going to look indistinguishable for safe and unsafe AIs.
That's just my opinion though.
What a great discovery, that's extremely cool. Intuitively, I would worry a bit that the 'spelling miracle' is such an odd edge case that it may not be representative of typical behavior, although just the fact that 'starts with _' shows up as an SAE feature assuages that worry somewhat. I can see why you'd choose it, though, since it's so easy to mechanically confirm what tokens ought to trigger the feature. Do you have some ideas for non-spelling-related features that would make good next tests?
My take is that I'd expect to see absorption happen any time there's a dense feature that co-occurs with more sparse features. So for example things like parts of speech, where you could have a "noun" latent, and things that are nouns (e.g. "dogs", "cats", etc...) would probably show this as well. If there's co-occurrence, then the SAE can maximize sparsity by folding some of the dense feature into the sparse features. This is something that would need to be validated experimentally though.
It's also problematic that it's hard to know where this will happen, especially with features where it's less obvious what the ground-truth labels should be. E.g. if we want to understand if a model is acting deceptively, we don't have strong ground-truth to know that a latent should or shouldn't fire.
Still, it's promising that this should be something that's easily testable with toy models, so hopefully we can test out solutions to absorption in an environment where we can control every feature's frequency and co-occurrence patterns.
Determining ground-truth definitely seems like the tough aspect there. Very good idea to come up with 'starts with _' as a case where that issue is tractable, and another good idea to tackle it with toy models where you can control that up front. Thanks!
Thanks Egg! Really good question. Short answer: Look at MetaSAE's for inspiration.
Long answer:
There are a few reasons to believe that feature absorption won't just be a thing for graphemic information:
- People have noticed SAE latent false negatives in general, beyond just spelling features. For example this quote from the Anthropic August update. I think they also make a comment about feature coordination being important in the July update as well.
If a feature is active for one prompt but not another, the feature should capture something about the difference between those prompts, in an interpretable way. Empirically, however, we often find this not to be the case – often a feature fires for one prompt but not another, even when our interpretation of the feature would suggest it should apply equally well to both prompts.
- MetaSAEs are highly suggestive of lots of absorption. Starts with letter features are found by MetaSAEs along with lots of others (my personal favorite is a " Jerry" feature on which a Jewish meta-feature fires. I won't what that's about!?) 🤔
- Conceptually, being token or character specific doesn't play a big role. As Neel mentioned in his tweet here, once you understand the concept, it's clear that this is a strategy for generating sparsity in general when you have this kind of relationship between concepts. Here's a latent that's a bit less token aligned in the MetaSAE app which can still be decomposed into meta-latents.
In terms of what I really want to see people look at: What wasn't clear from Meta-SAEs (which I think is clearer here) is that absorption is important for interpretable causal mediation. That is, for the spelling task, absorbing features look like a kind of mechanistic anomaly (but is actually an artefact of the method) where the spelling information is absorbed. But if we found absorption in a case where we didn't know the model knew a property of some concept (or we didn't know it was a property), but saw it in the meta-SAE, that would be very cool. Imagine seeing attribution to a latent tracking something about a person, but then the meta-latents tell you that the model was actually leveraging some very specific fact about that person. This might really important for understanding things like sycophancy...
That all makes sense, thanks. I'm really looking forward to seeing where this line of research goes from here!
Amazing post! Forgot to do this for a while, but here's a linked diagram explaining how I think about feature absorption, hopefully ppl find it helpful!
This research was completed for London AI Safety Research (LASR) Labs 2024. The team was supervised by Joseph Bloom (Decode Research). Find out more about the programme and express interest in upcoming iterations here.
This high level summary will be most accessible to those with relevant context including an understanding of SAEs. The importance of this work rests in part on the surrounding hype, and potential philosophical issues. We encourage readers seeking technical details to read the paper on arxiv.
Explore our interactive app here.
TLDR: This is a short post summarising the key ideas and implications of our recent work studying how character information represented in language models is extracted by SAEs. Our most important result shows that SAE latents can appear to classify some feature of the input, but actually turn out to be quite unreliable classifiers (much worse than linear probes). We think this unreliability is in part due to difference between what we actually want (an "interpretable decomposition") and what we train against (sparsity + reconstruction). We think there are many possibly productive follow-up investigations.
We pose two questions:
To answer these questions, we tested SAE performance on a simple first letter identification task using over 200 Gemma Scope SAEs. By focussing on a task with ground truth labels we precisely measured the precision and recall of SAE latents tracking first letter information.
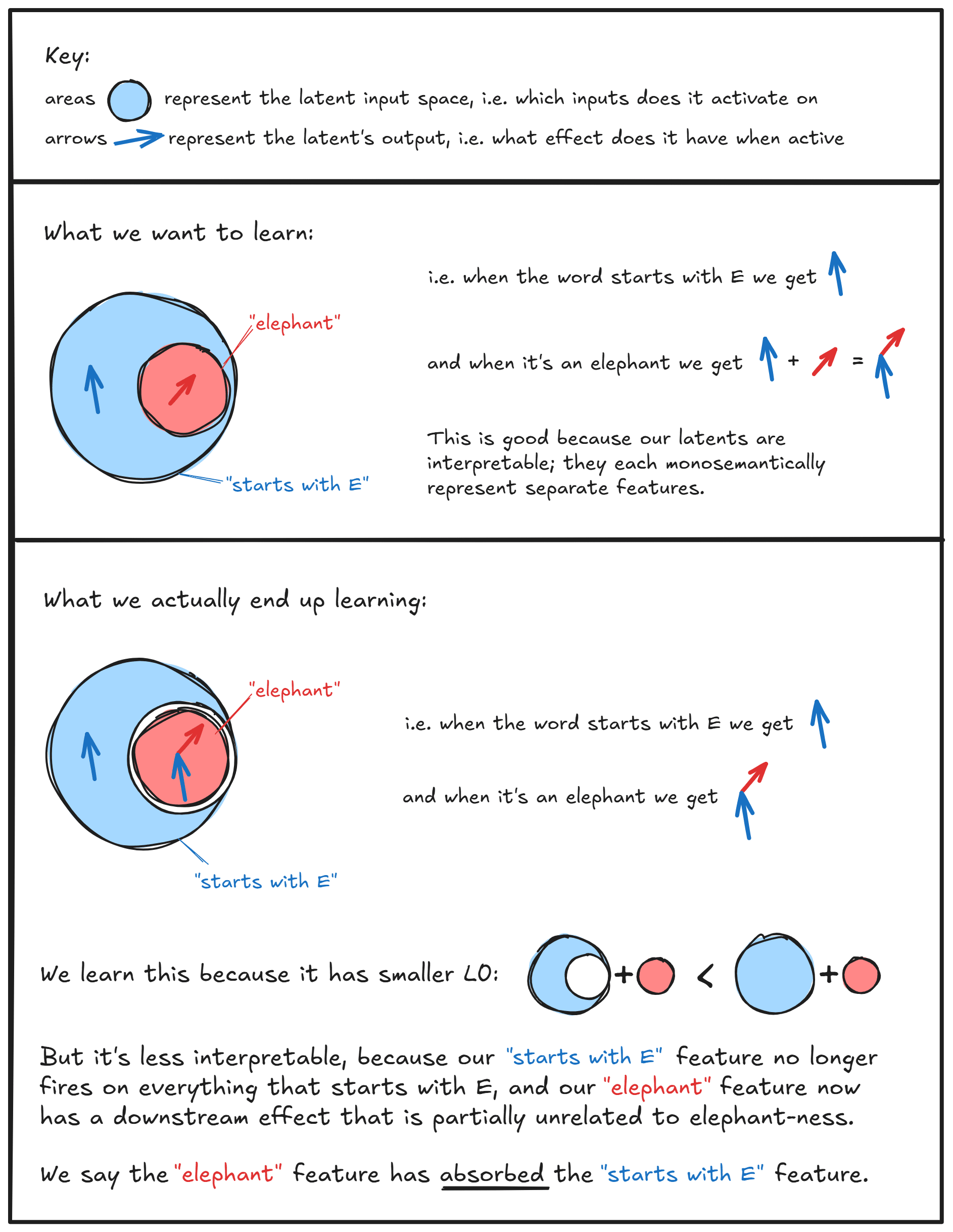
Our results revealed a novel obstacle to using SAEs for interpretability which we term 'Feature Absorption'. This phenomenon is a pernicious, asymmetric form of feature splitting where:
We find “absorbing” latents which weakly project onto the feature direction and causally mediate in-place of the main latent (eg: an "elephants" latent absorbs the "starts with E" feature direction, and then the SAE no longer fires the "starts with E" latent on the token "Elephant", as the "elephants" latent now encodes that information, along with other semantic elephant-related features).
Feature splitting vs feature absorption:
In the traditional (interpretable) view of feature splitting, a single general latent in a narrow SAE splits into multiple more specific latents in a wider SAE[1]. For instance, we may find that a "starts with L" latent splits into "starts with uppercase L" and "starts with lowercase L". This is not a problem for interpretability as all these latents are just different valid decompositions of the same concept, and may even be a desirable way to tune latent specificity.
In feature absorption, an interpretable feature becomes a latent which appears to track that feature, but fails to fire on arbitrary tokens that it seemingly should fire on. Instead, roughly token-aligned latents "absorb" the feature direction and fire in-place of the mainline latent. Feature absorption strictly reduces interpretability and makes it difficult to trust that SAE latents do what they appear to do.
Feature Absorption is problematic:
While our study has clear limitations, we think there’s compelling evidence for the existence of feature absorption. It’s important to note that our results use a leverage model (Gemma-2-2b), one SAE architecture (JumpReLU) and one task (the first letter identification task). However, the qualitative results are striking (which readers can explore for themselves using our streamlit app) and causal interventions are built directly into our metric for feature absorption.
We’re excited about future work in a number of areas (in order of concrete / import to most exciting!):
We believe our work provides a significant contribution by identifying and characterising the feature absorption phenomenon, highlighting a critical challenge in the pursuit of interpretable AI systems.
Towards Monosemanticity