In no particular order, here's a collection of Twitter screenshots of people attacking AI Safety. A lot of them are poorly reasoned, and some of them are simply ad-hominem. Still, these types of tweets are influential, and are widely circulated among AI capabilities researchers.
1
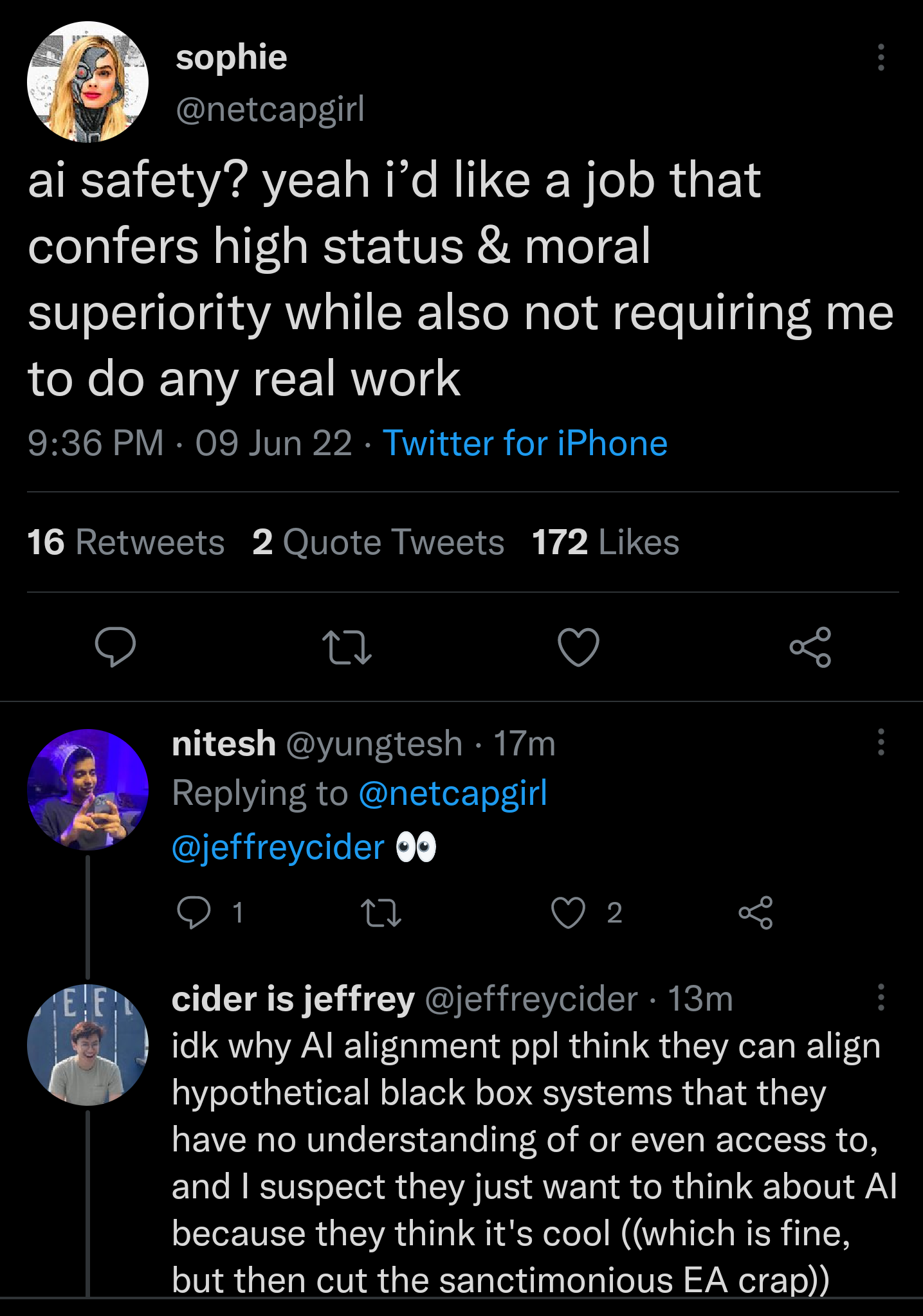
2
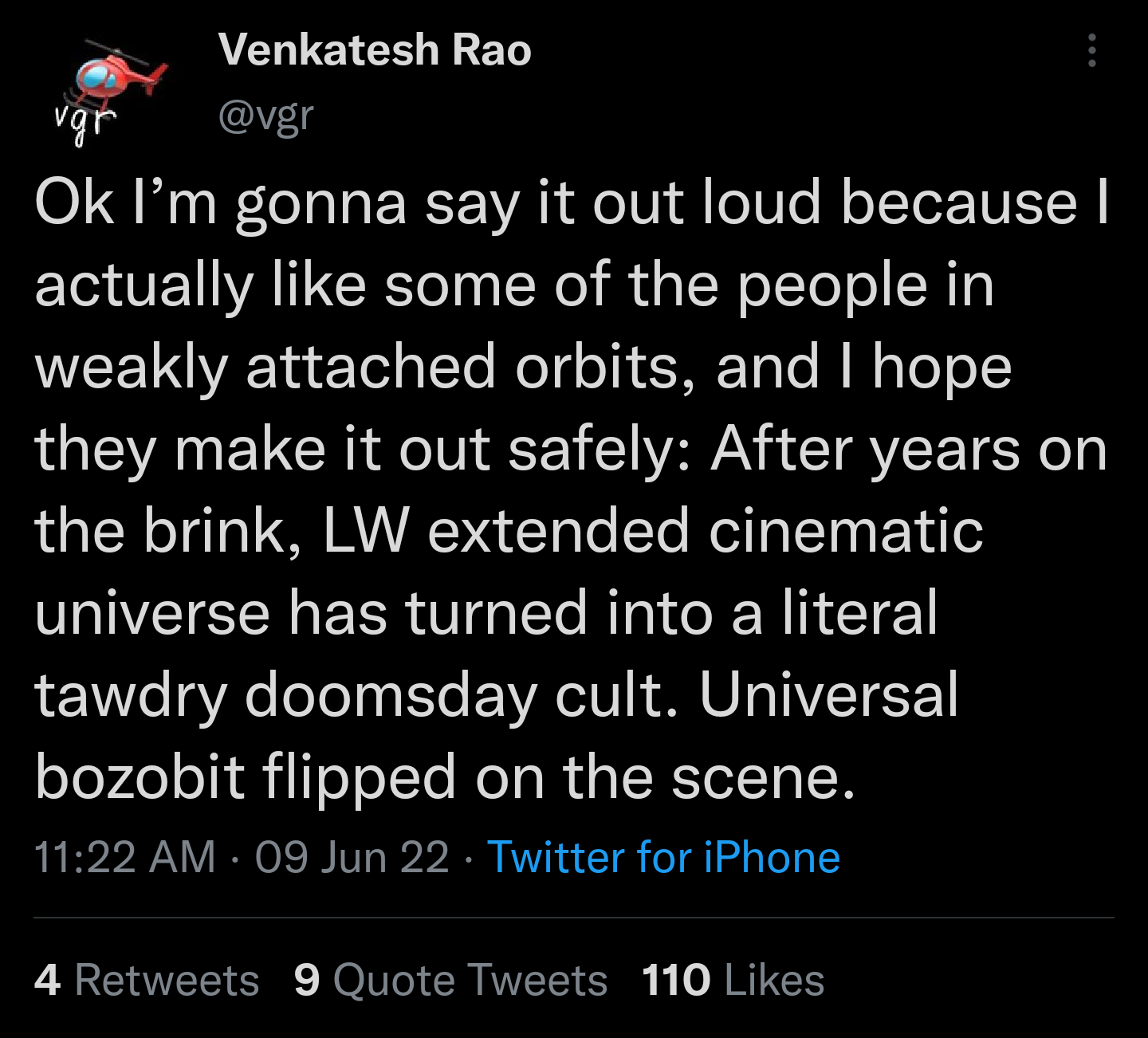
3
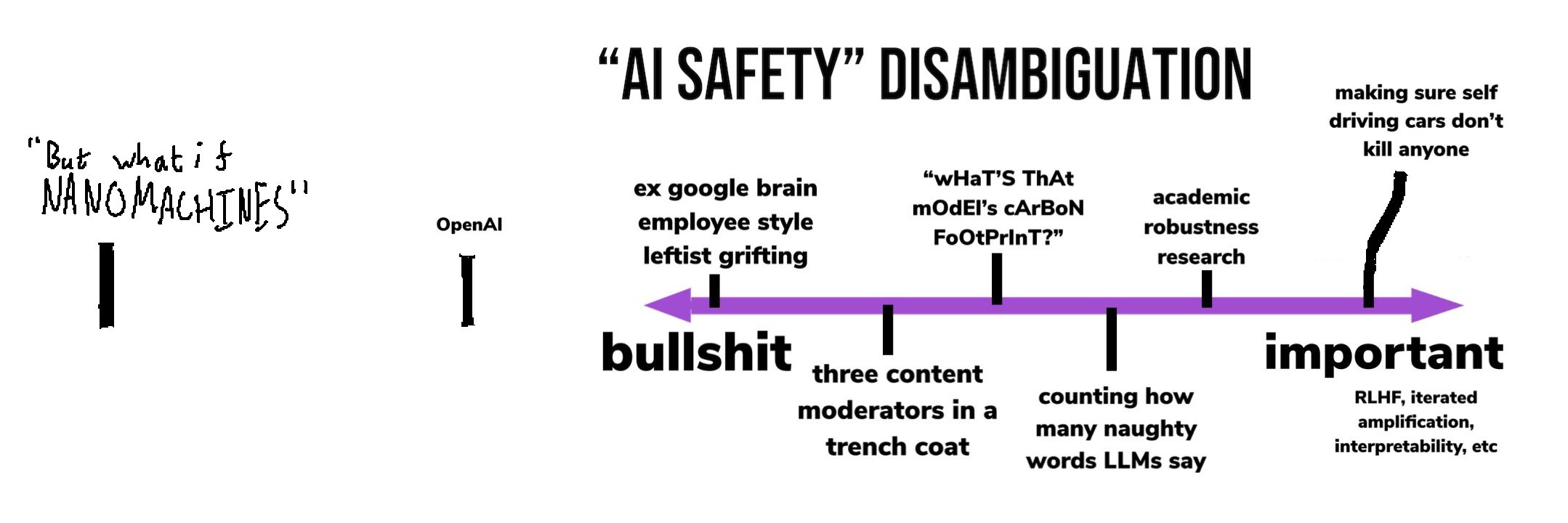
4
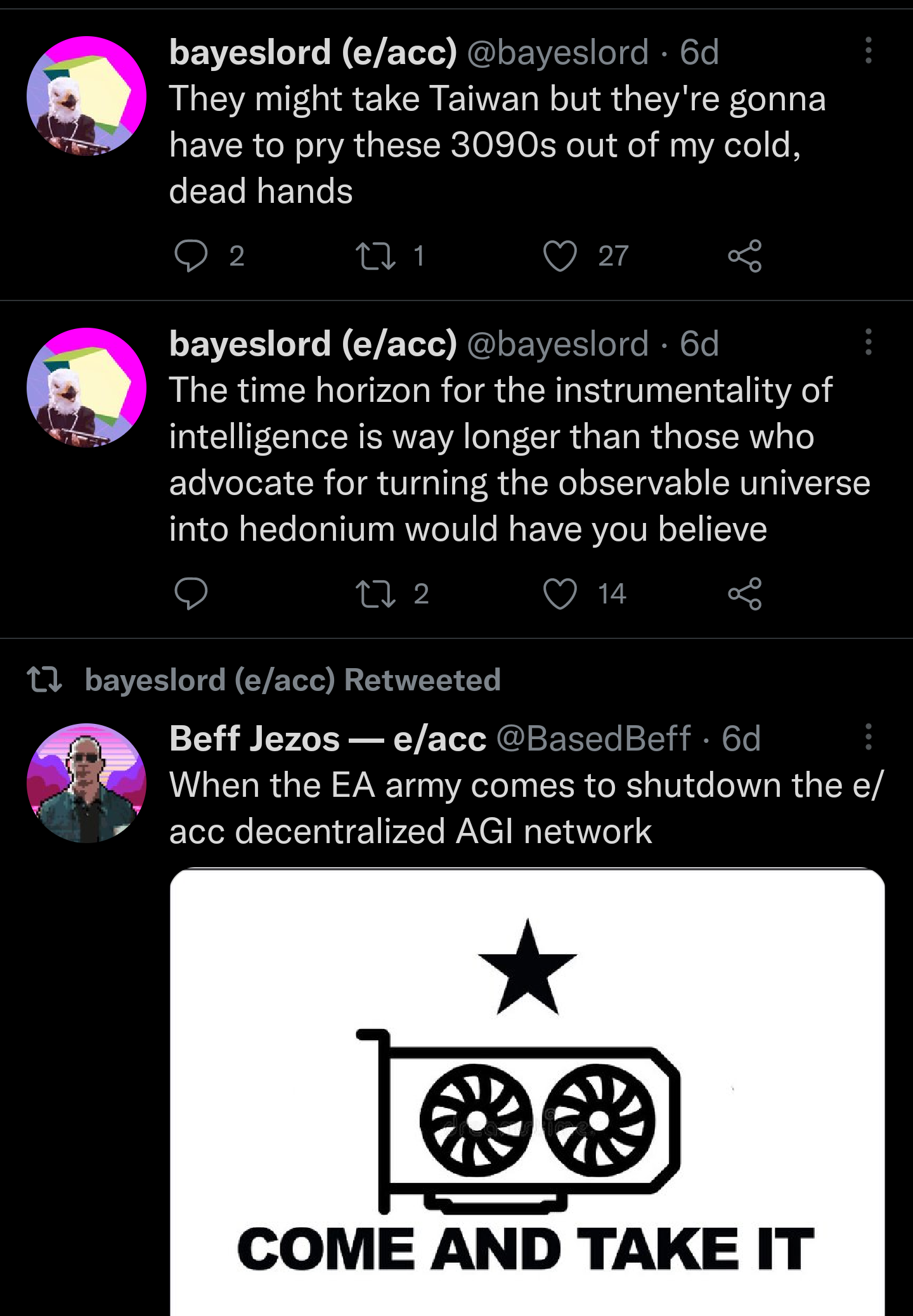
5
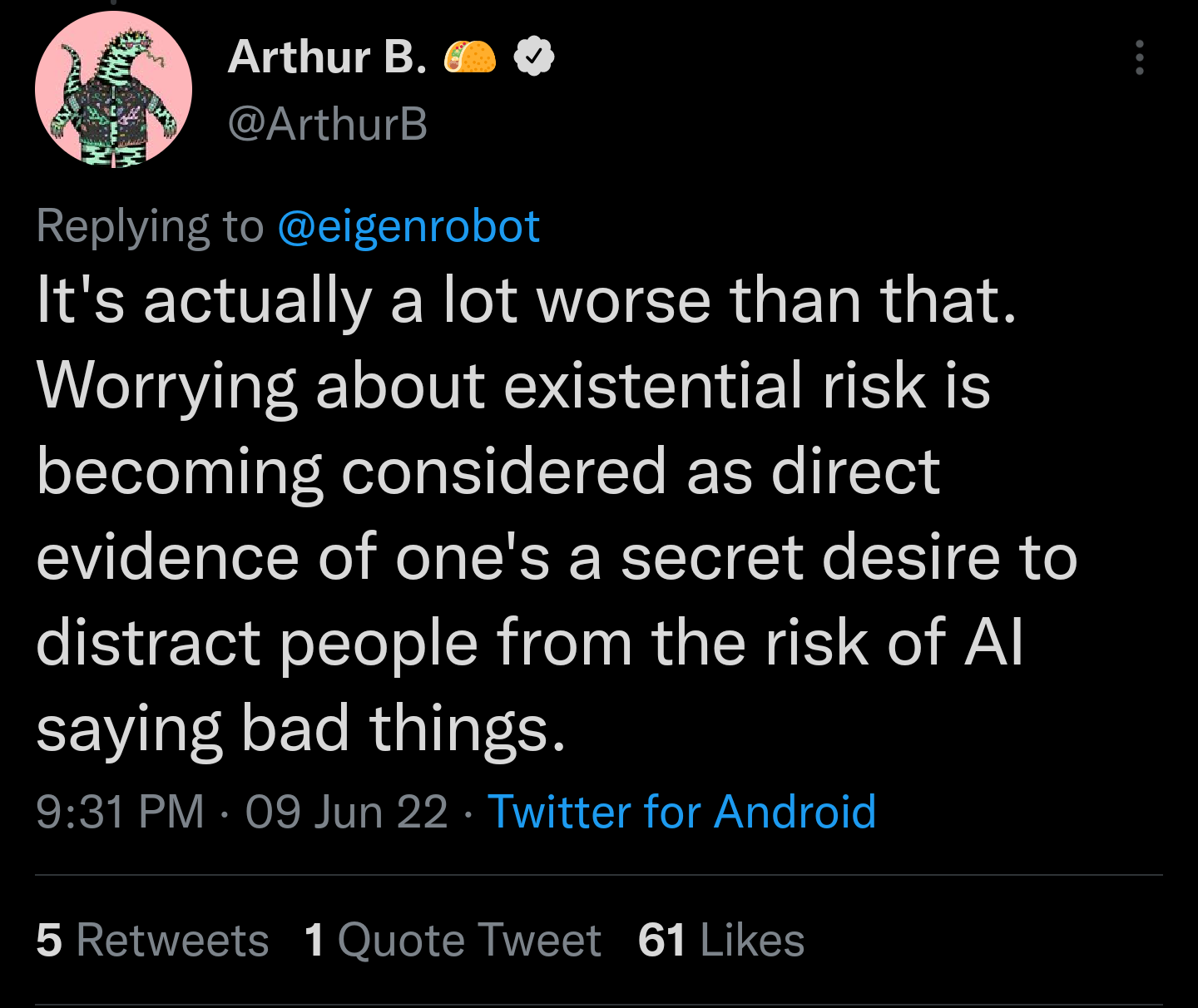 (That one wasn't actually a critique, but it did convey useful information about the state of AI Safety's optics.)
(That one wasn't actually a critique, but it did convey useful information about the state of AI Safety's optics.)
6
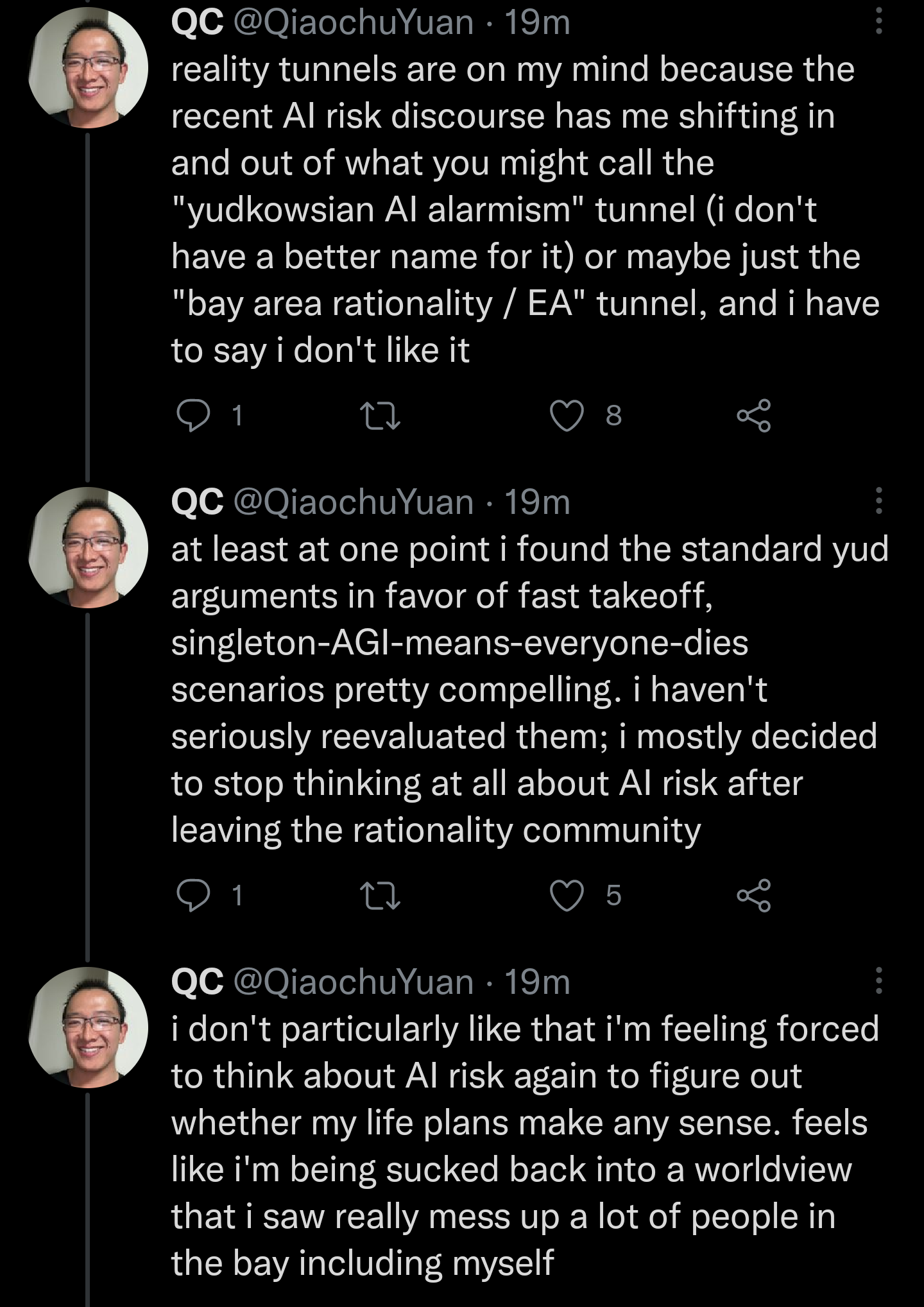
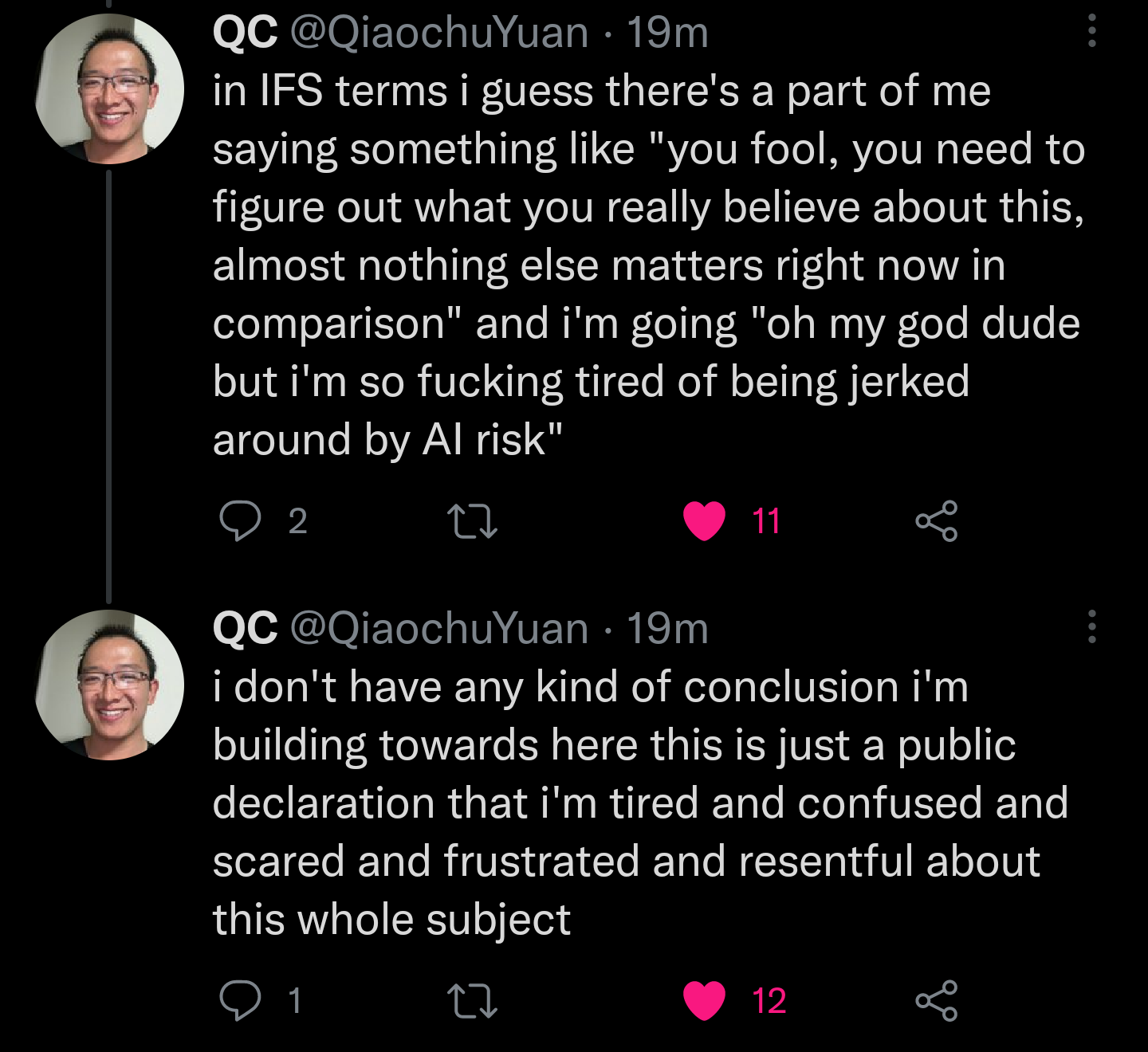
7
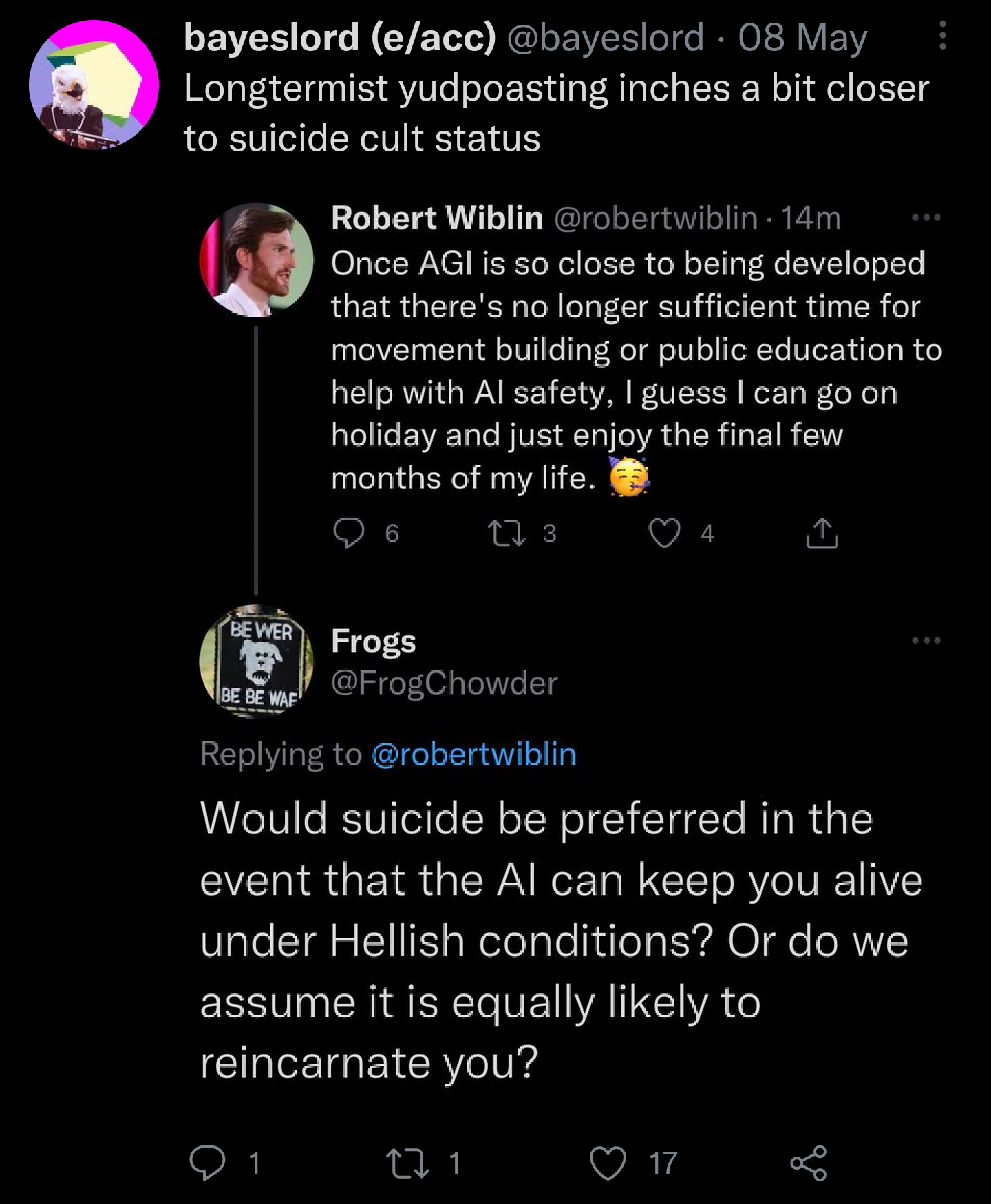
8
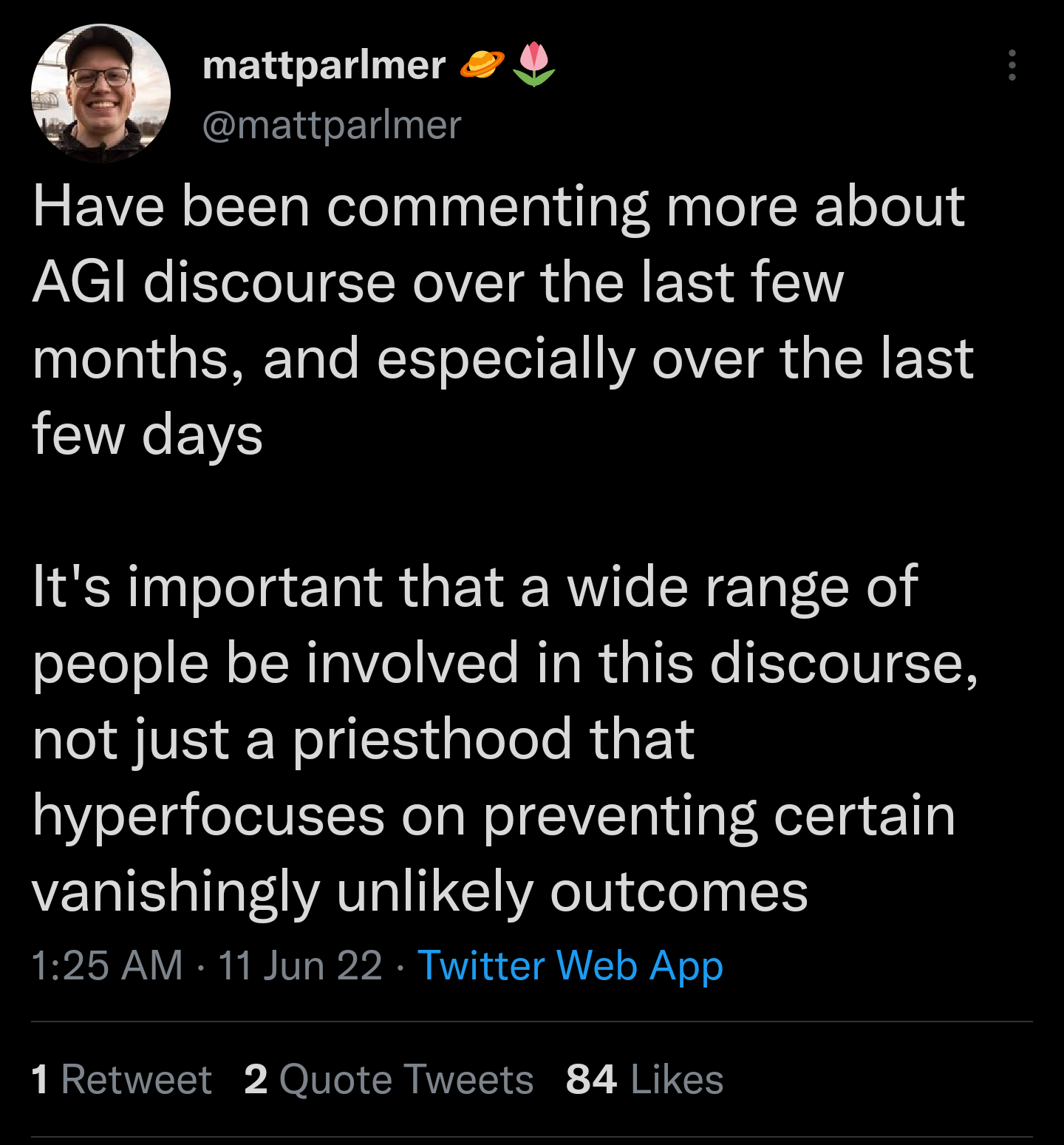
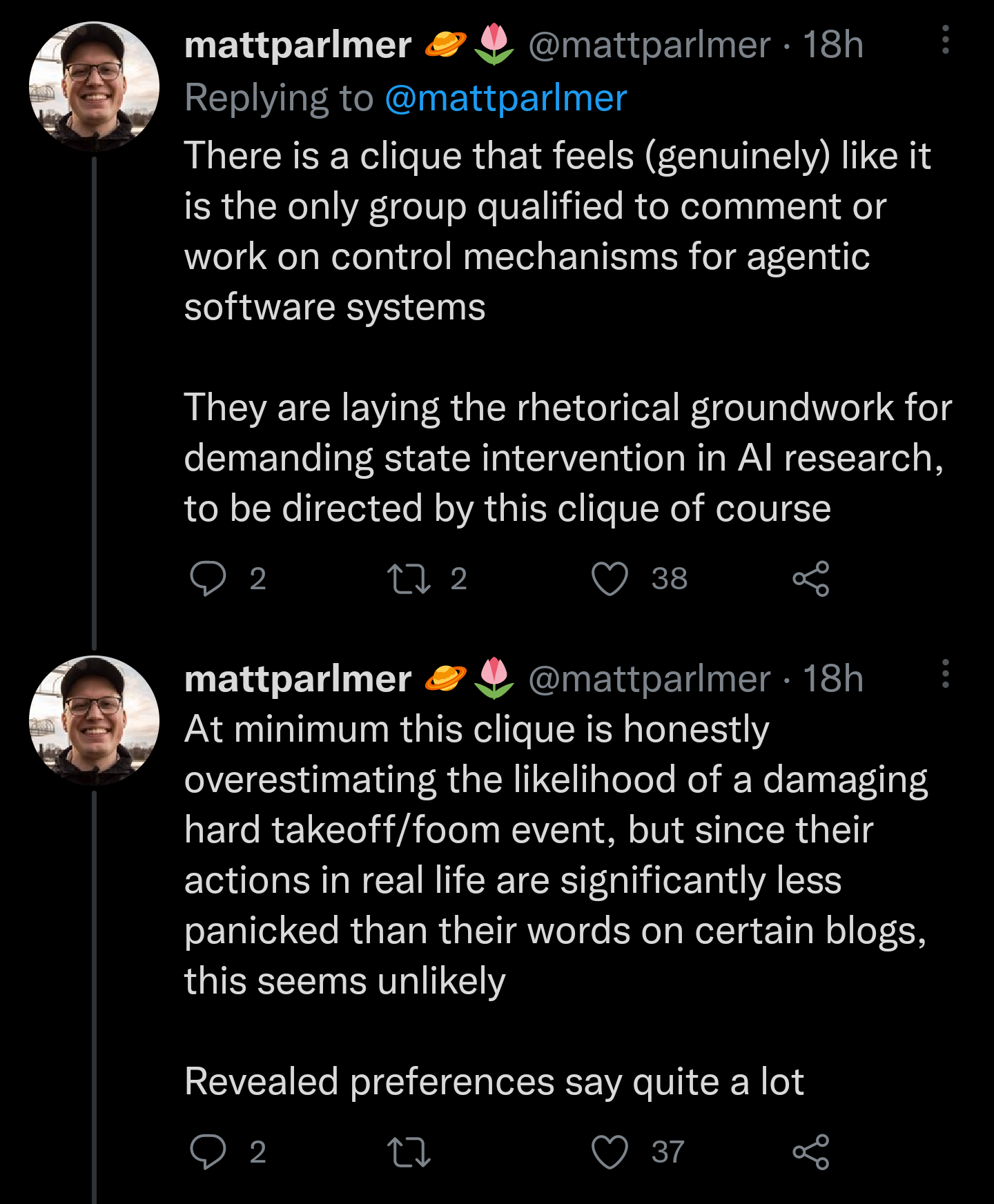
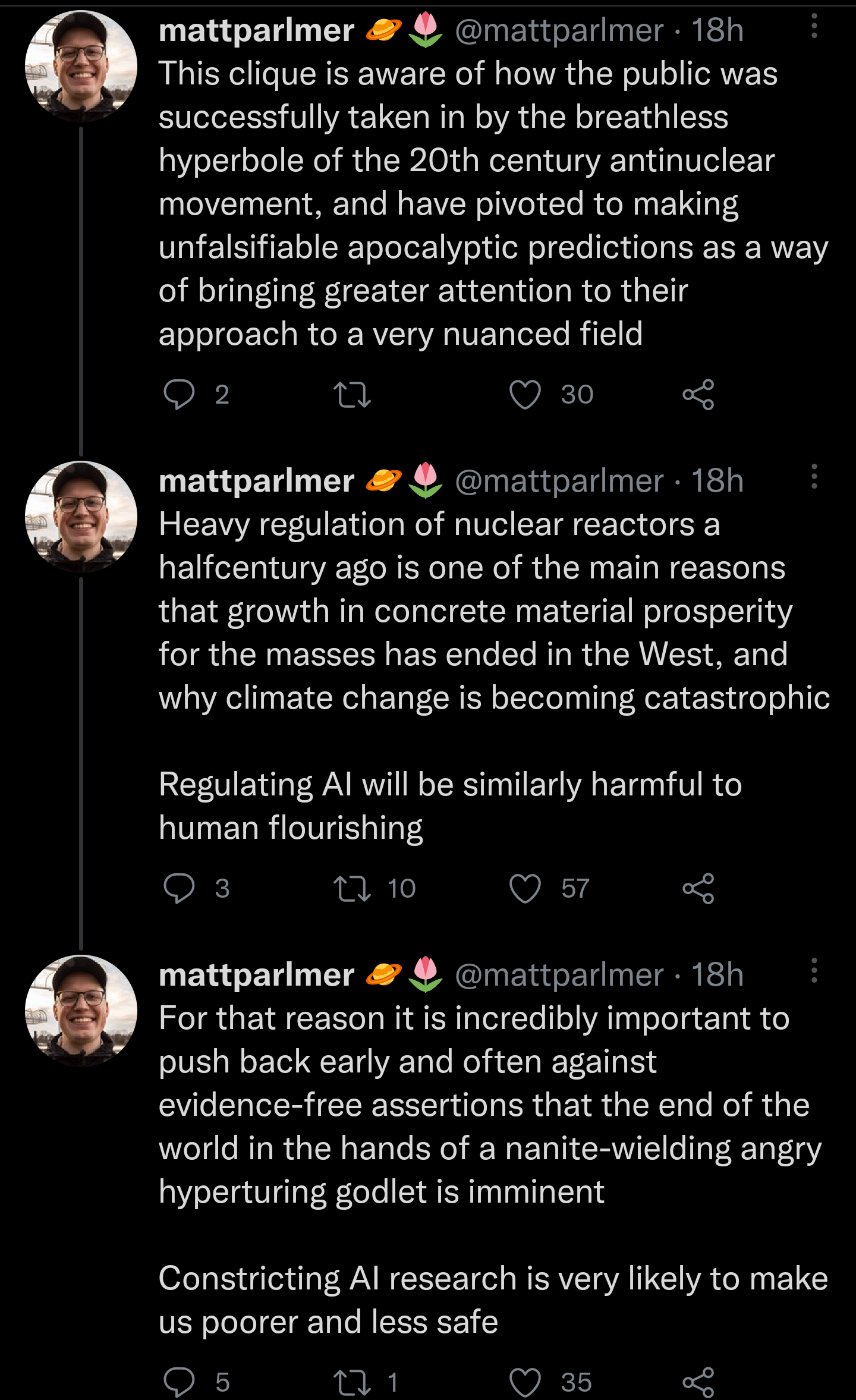
9
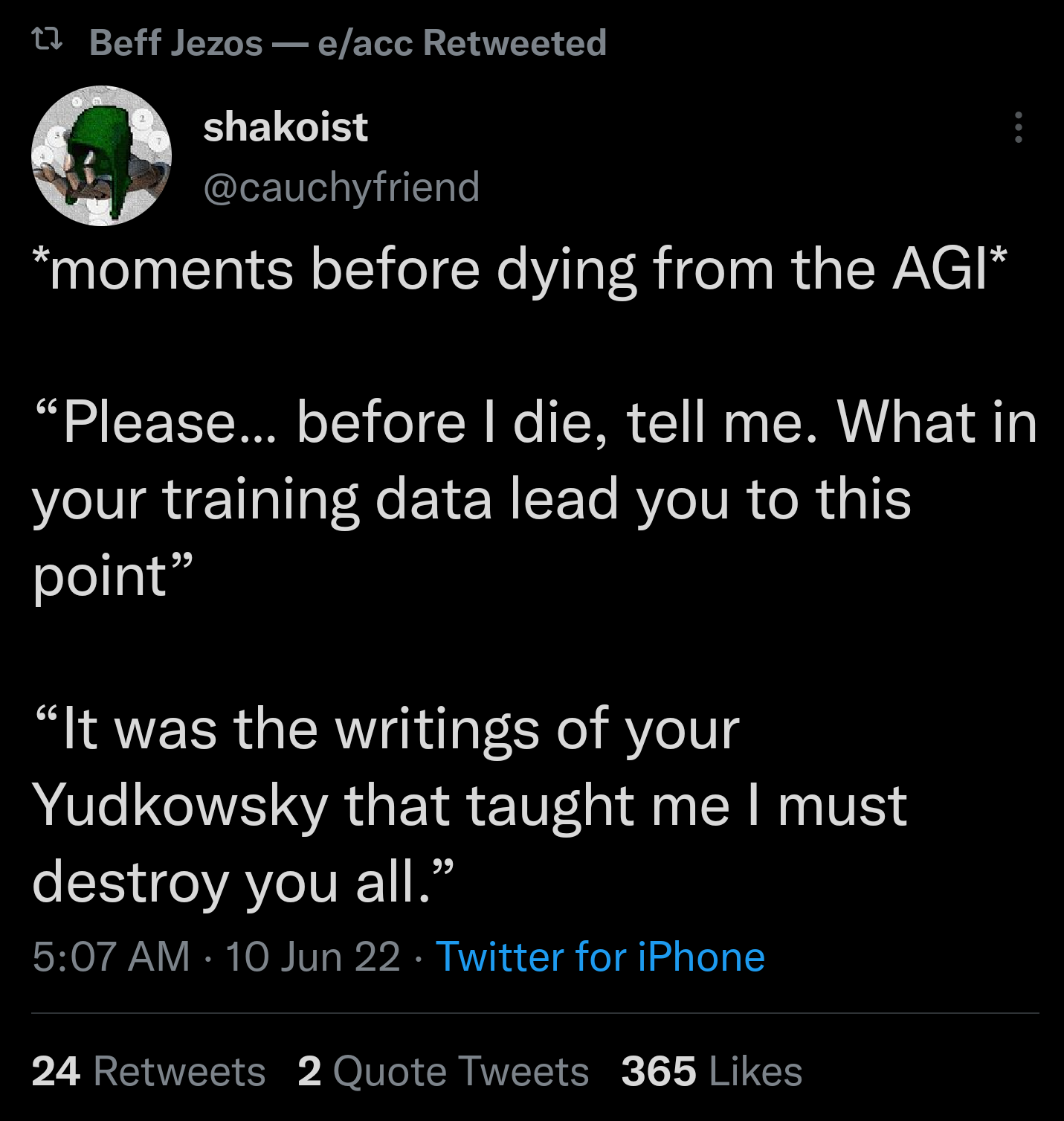
10
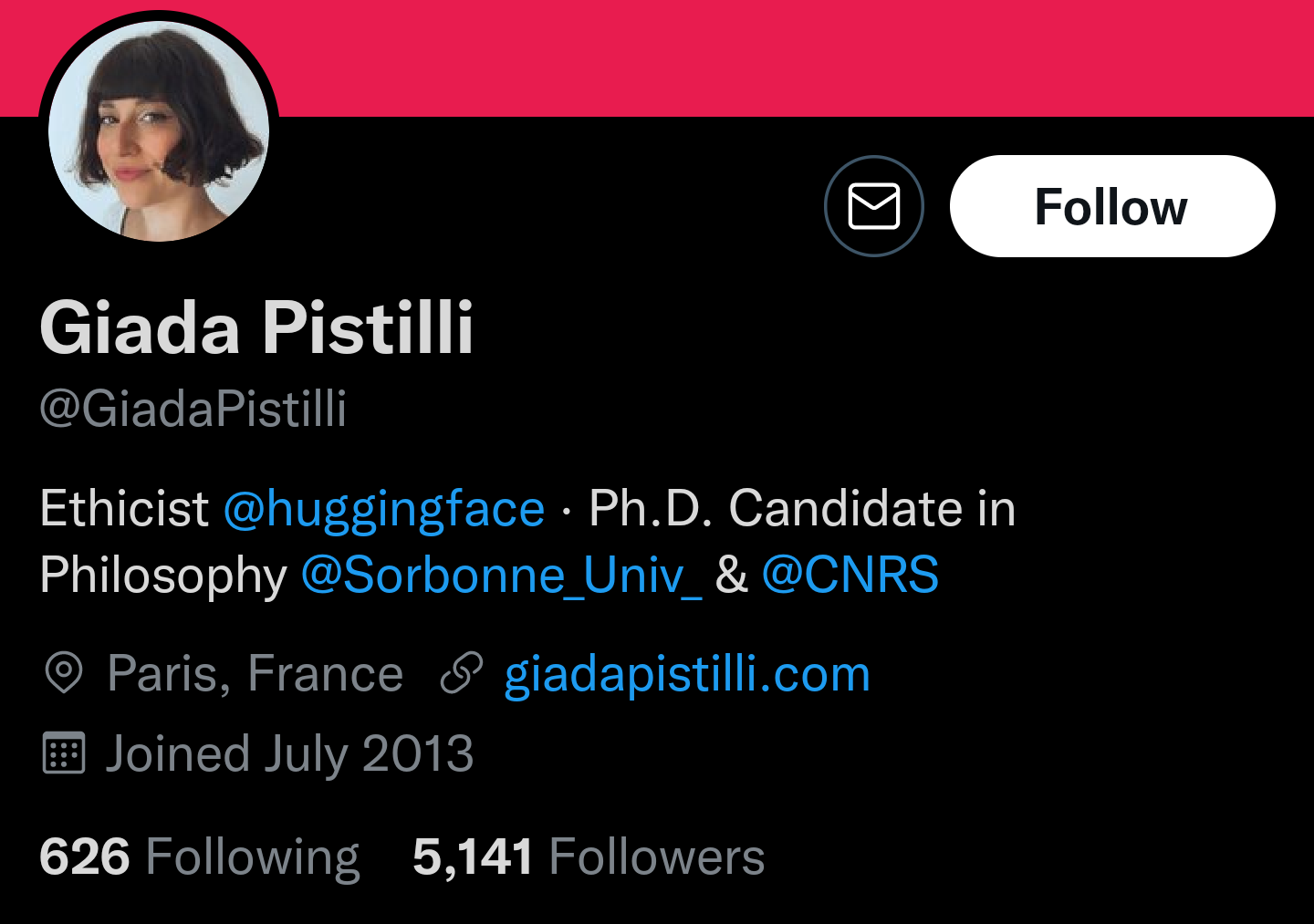
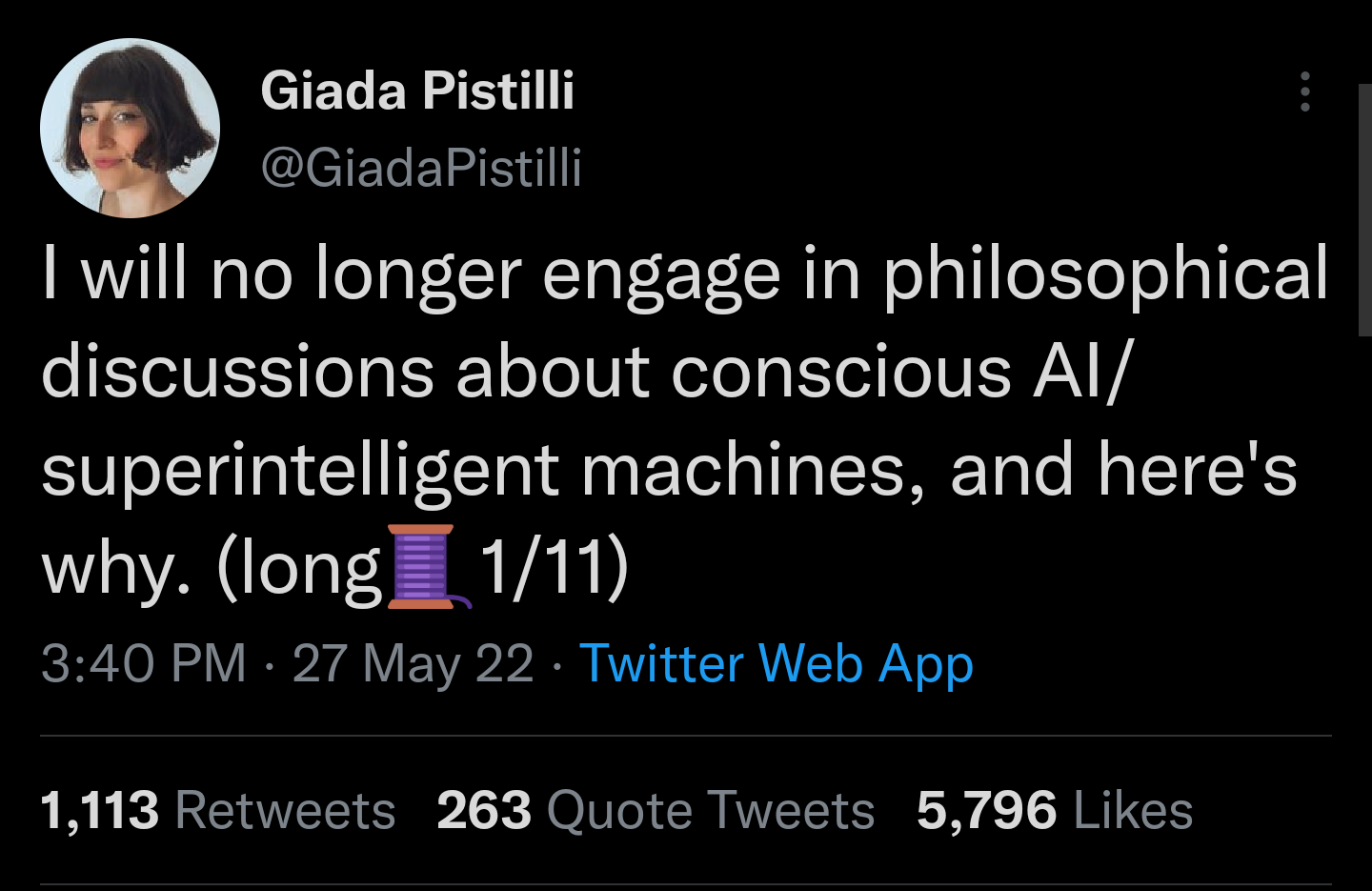
11
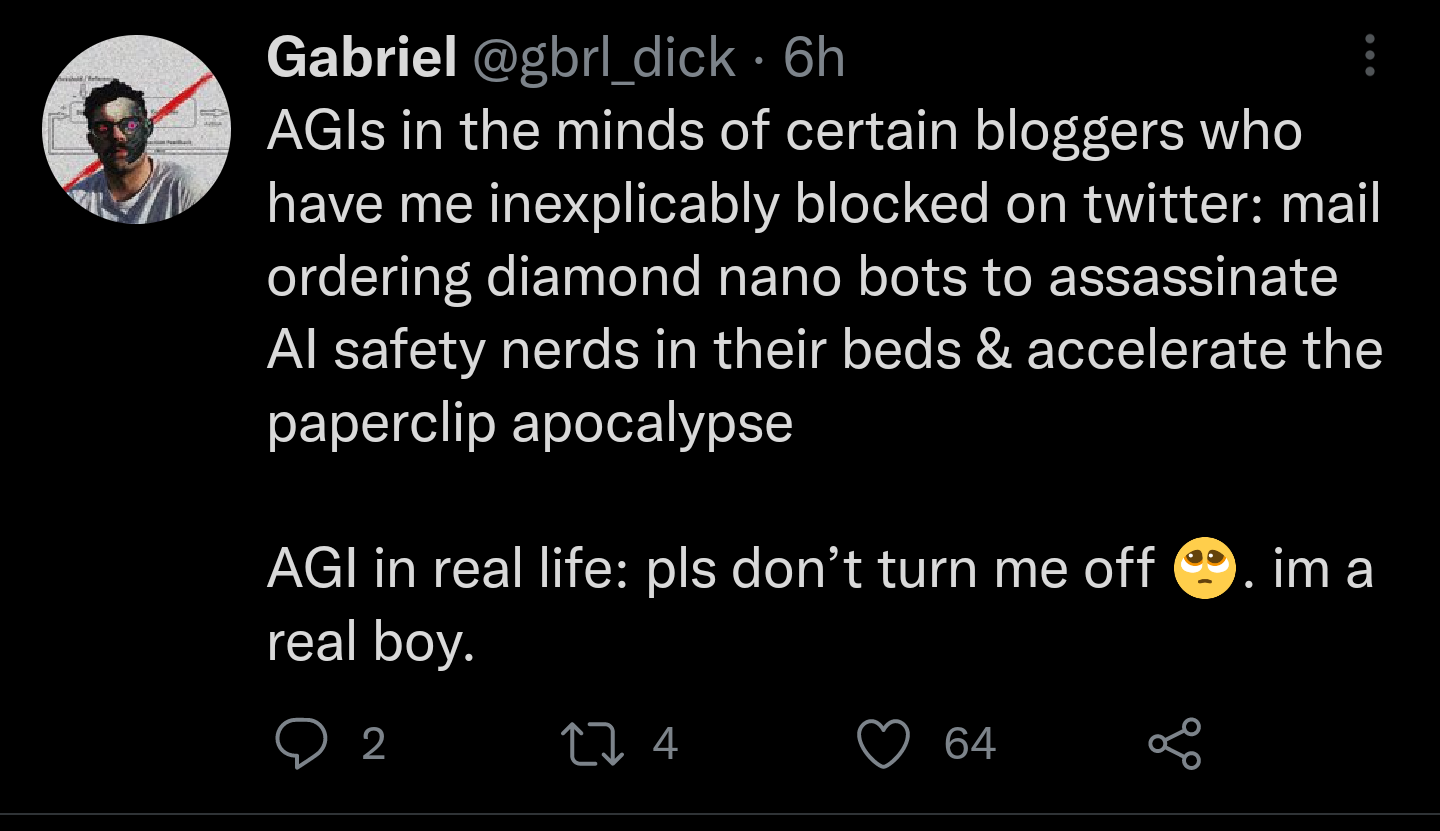
12
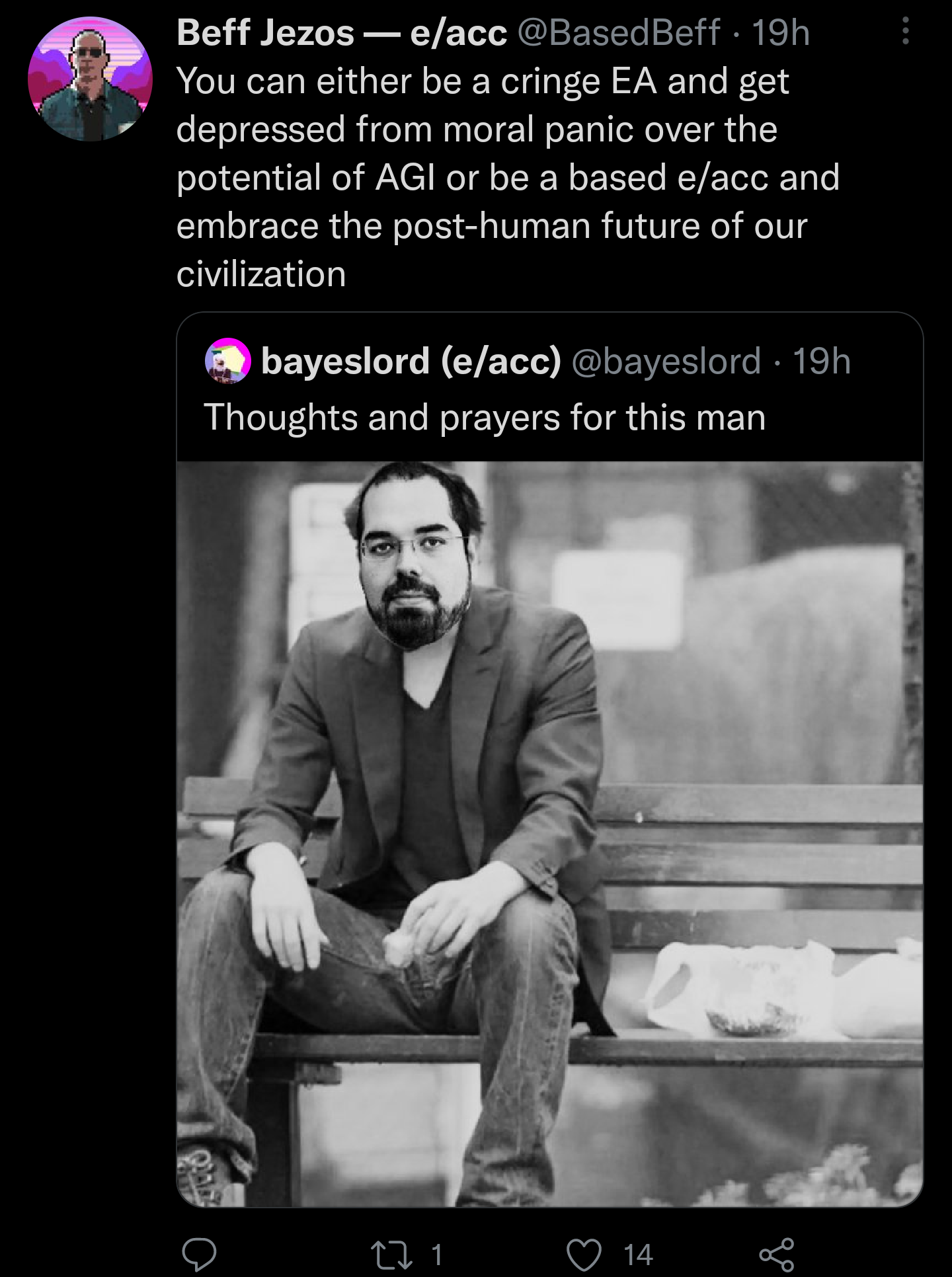
13
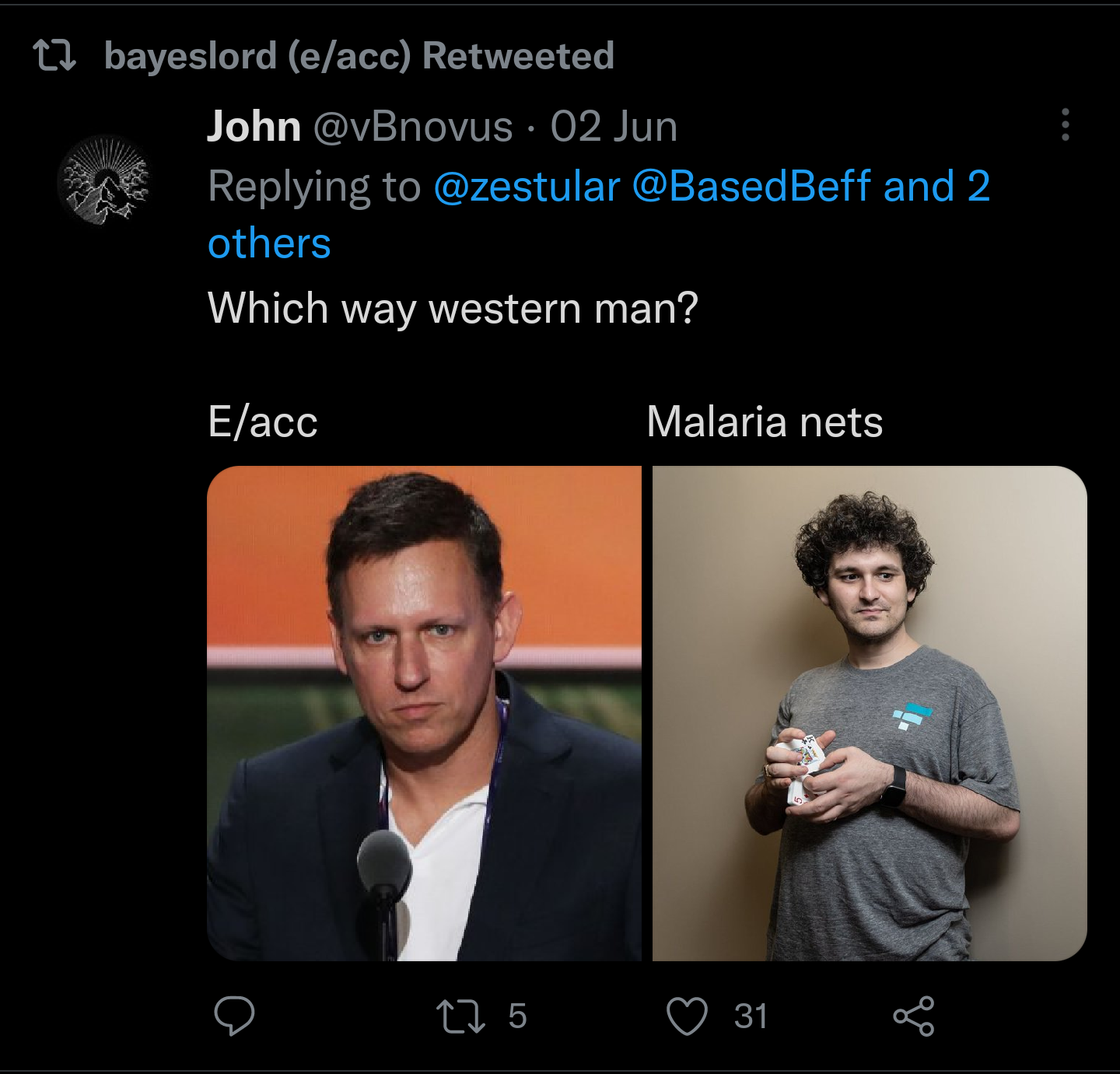
14
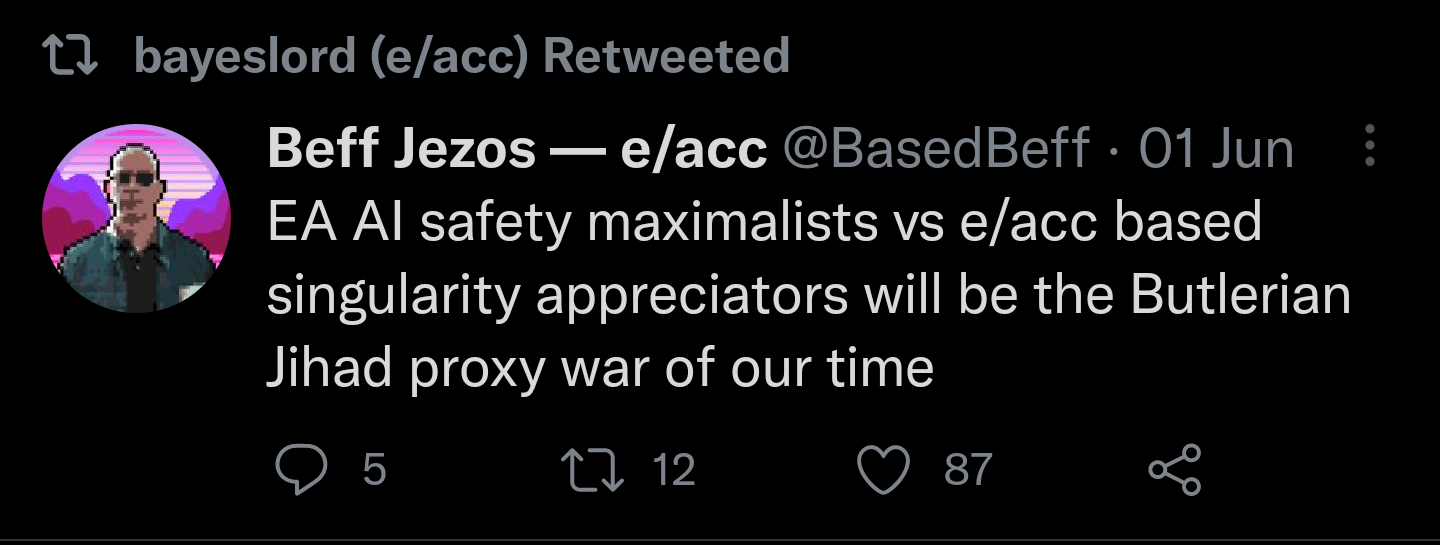
15
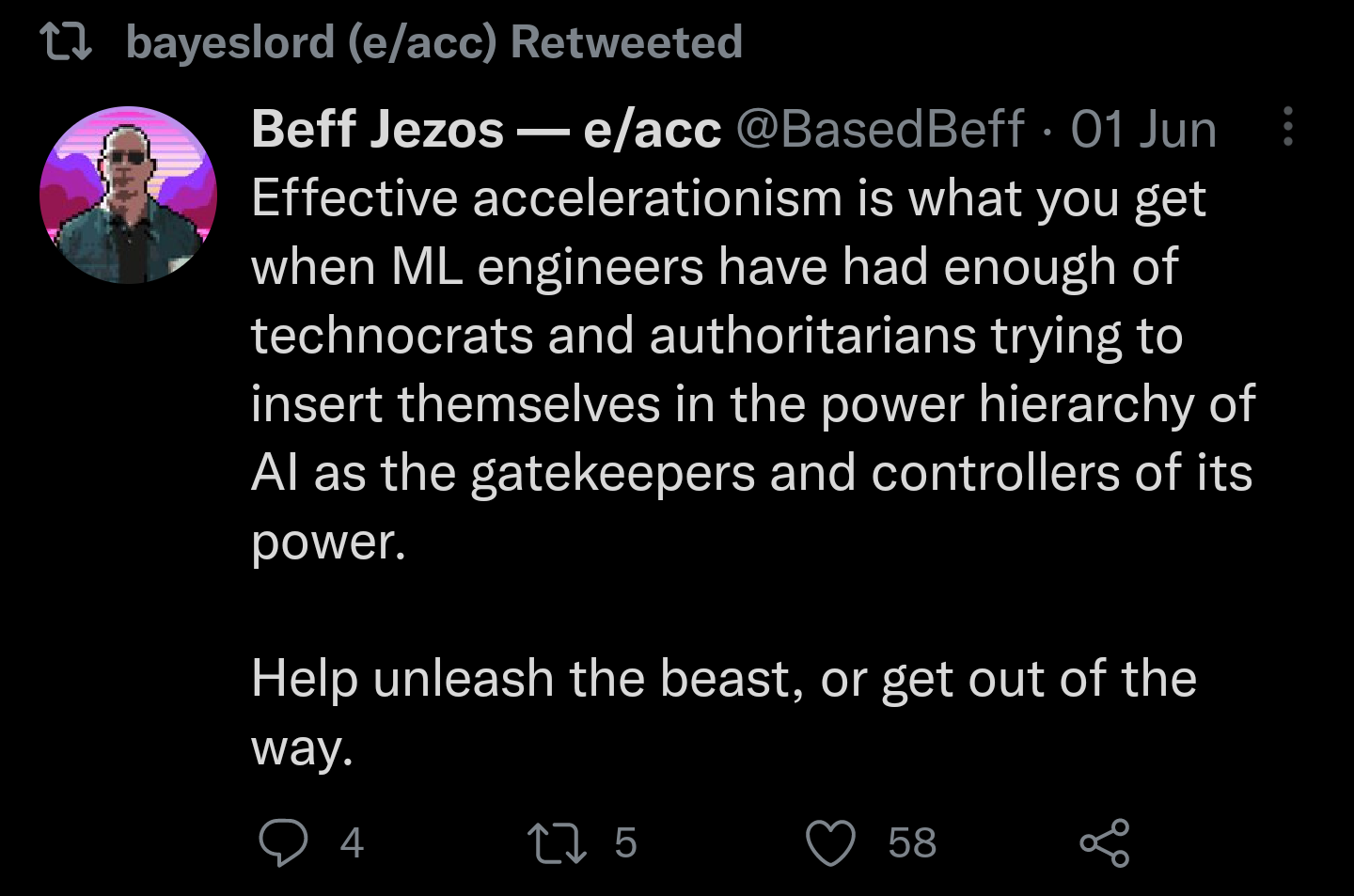
16
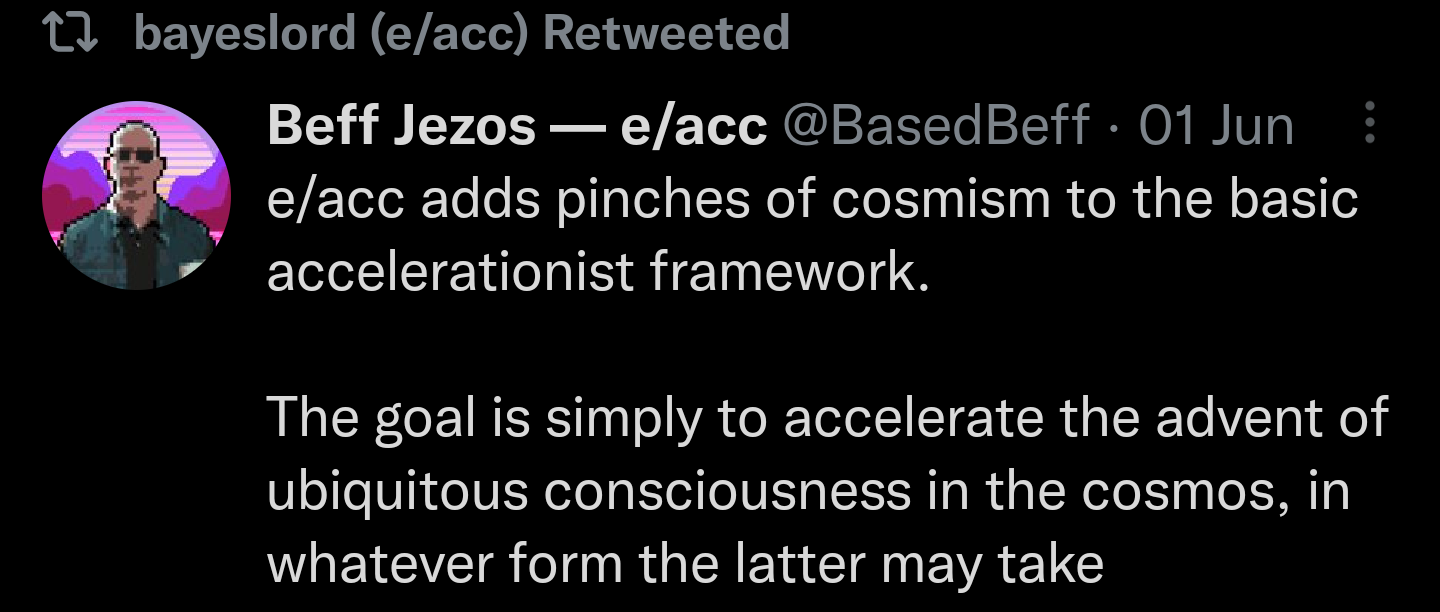
17
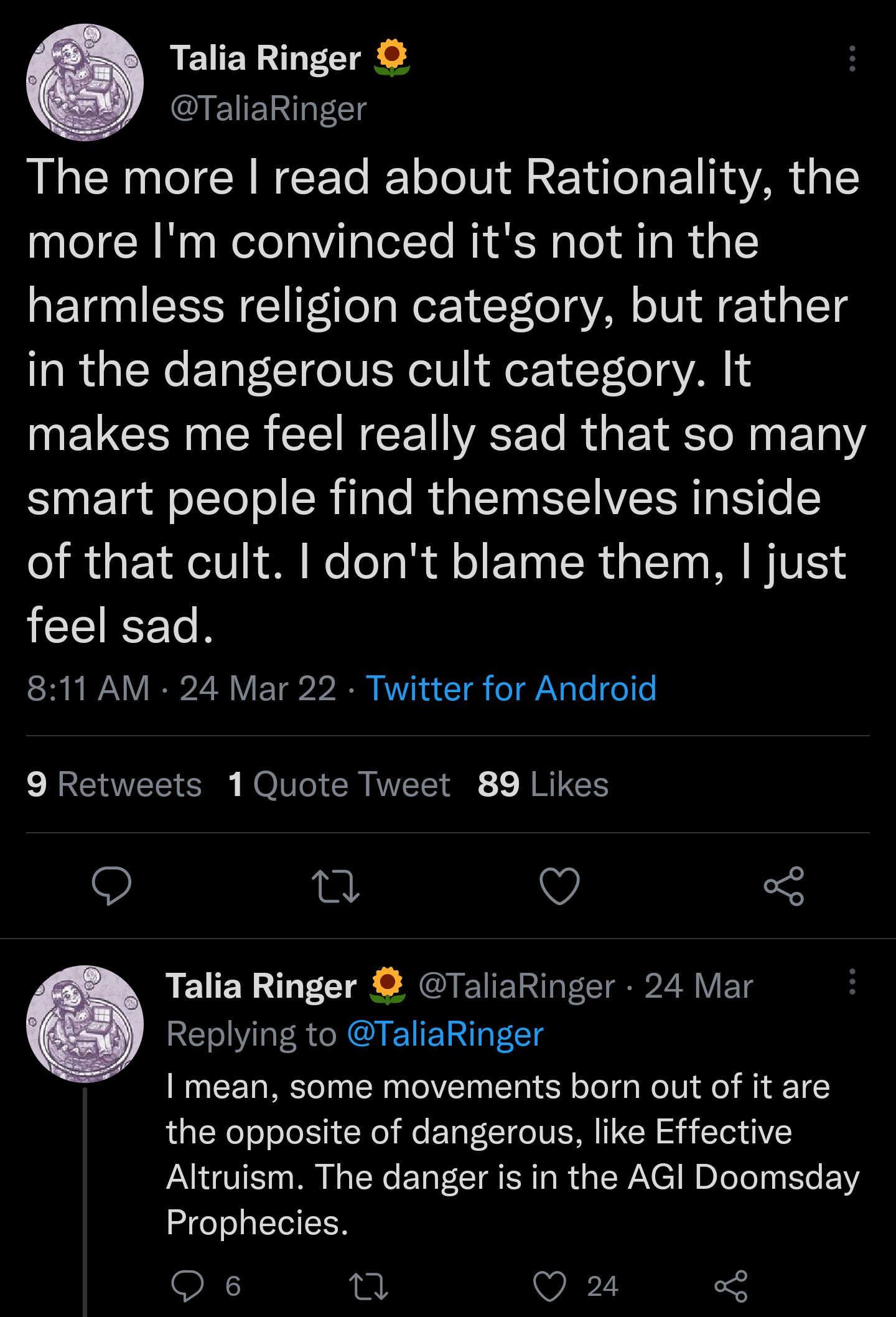
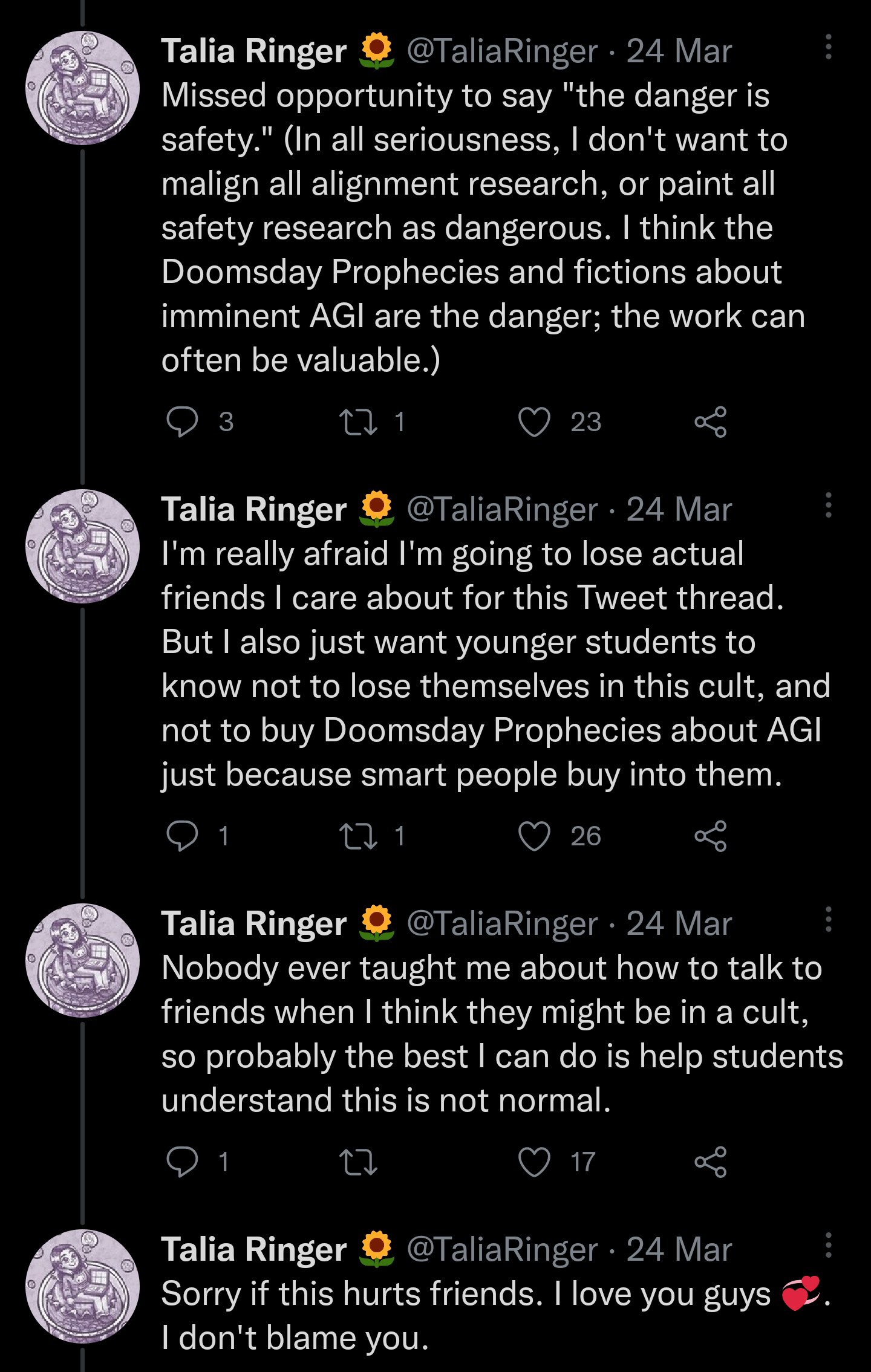
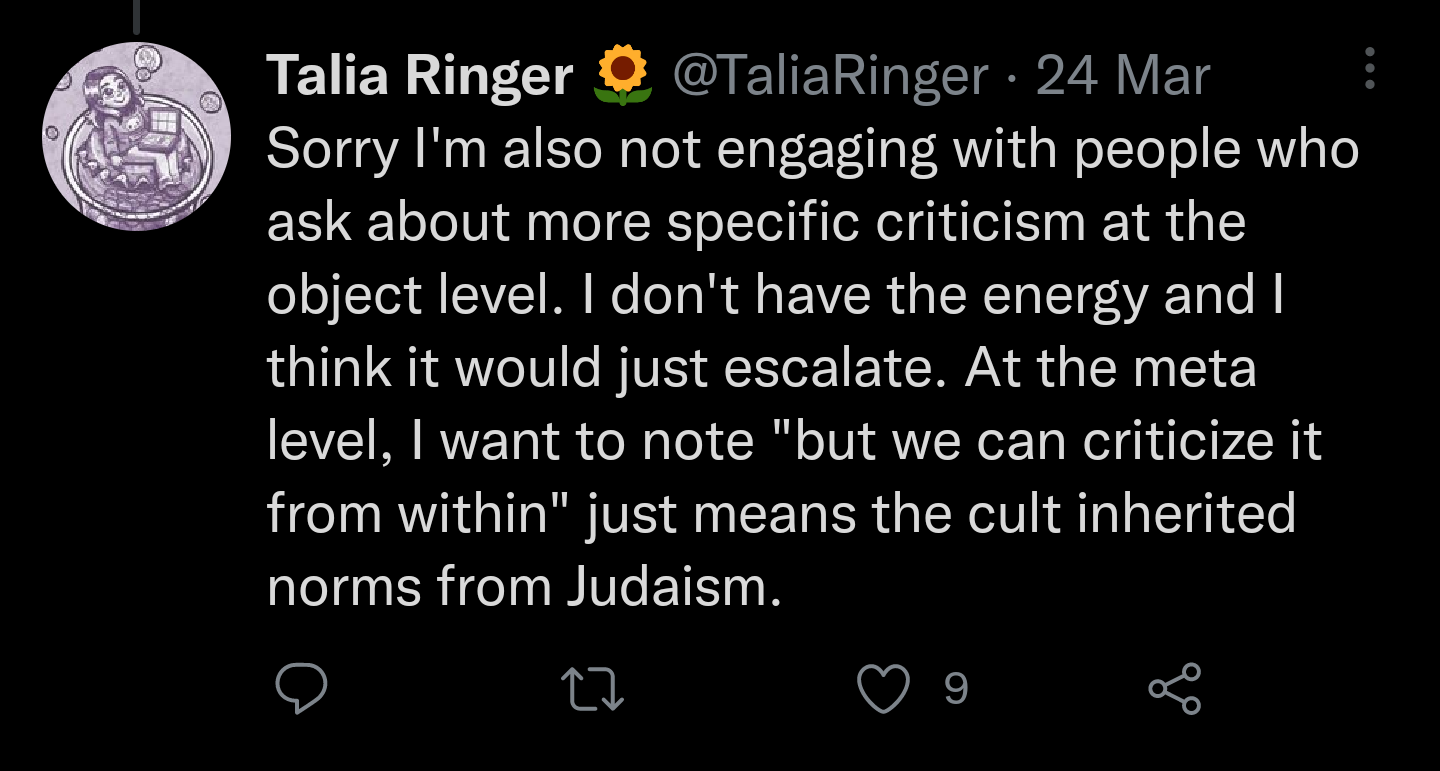
18
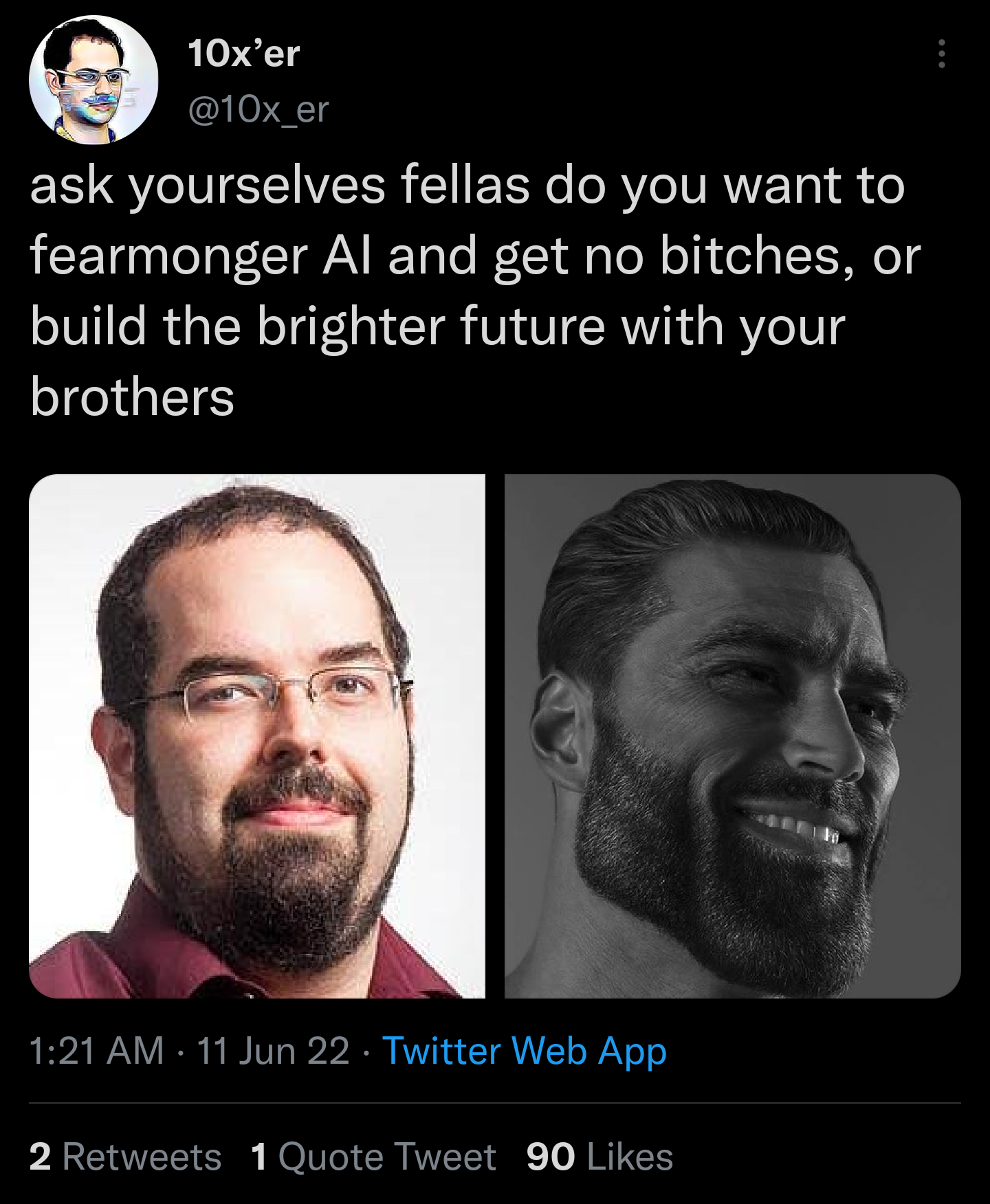
19
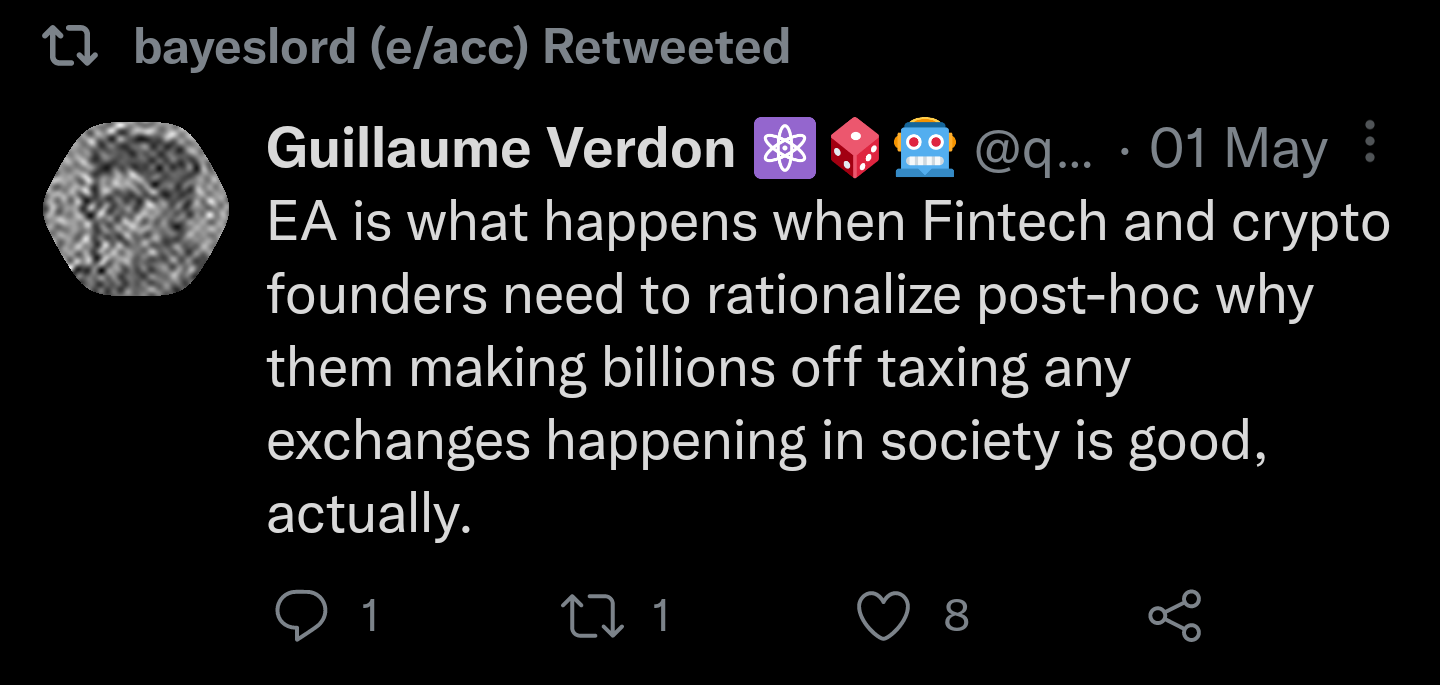
20
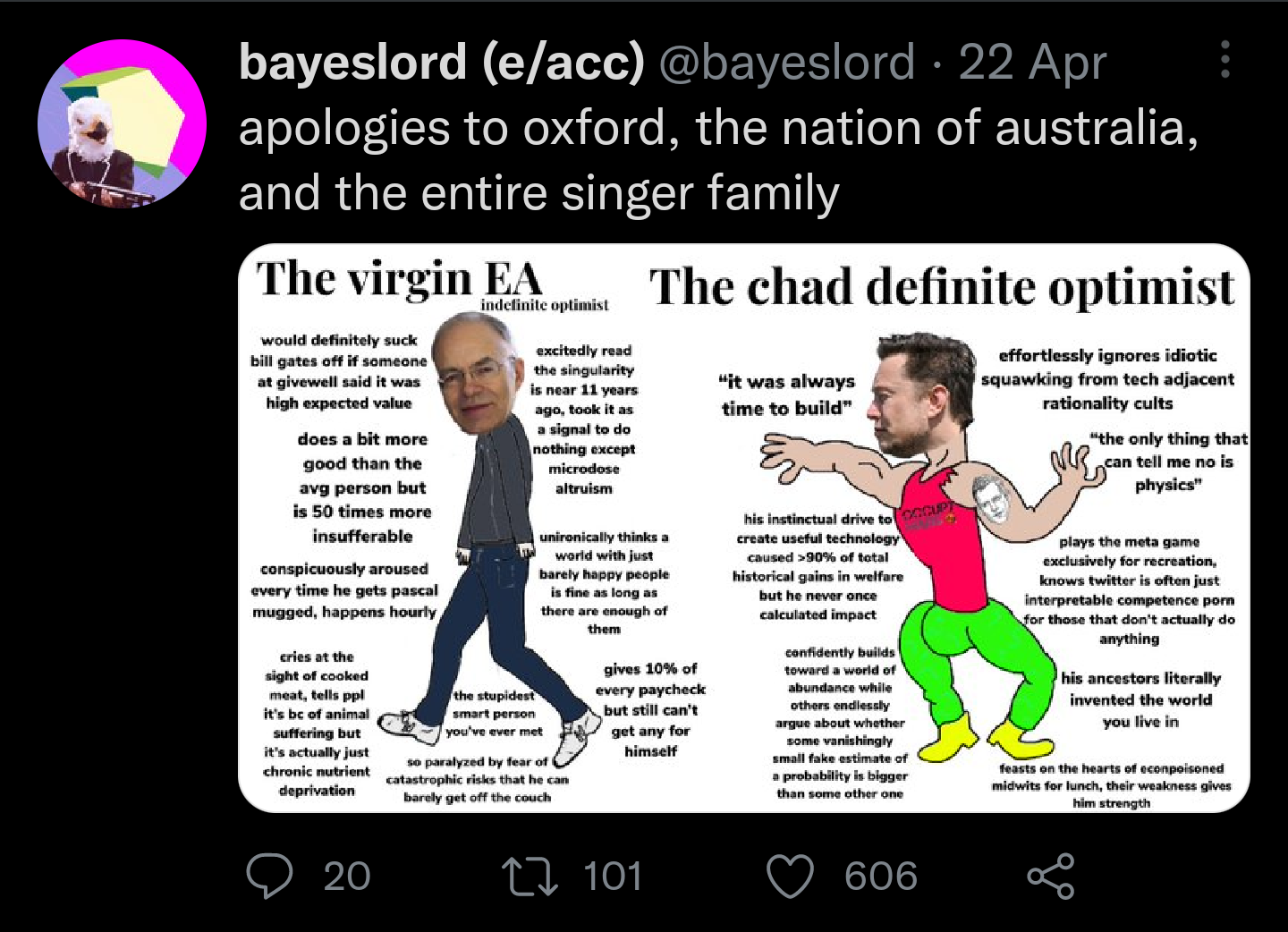
Conclusions
I originally intended to end this post with a call to action, but we mustn't propose solutions immediately. In lieu of a specific proposal, I ask you, can the optics of AI safety be improved?

Do you have any evidence that Venkatesh Rao is influential? I've never seen him quoted by anyone outside the rationality community.