What do you think about deep work (here's a semi-arbitrarily-chosen explainer)? I suppose the Monday time block after the meeting lets you do that, but that's maybe <10% of the workweek; you also did mention "If people want to focus deeply for a while, they can put on headphones". That said, many of your points aren't conducive to deep work (e.g. "If you need to be unblocked by someone, the fastest way is to just go to their desk and ask them in person" interrupts the other person's deep work block, same with "use a real-time chat platform like Slack to communicate and add all team members to all channels relevant to the team", and "if one of your teammates messages you directly, or if someone @ tags you, you want to respond basically immediately").
I've always wondered about this, given my experience working at a few young-ish high-growth top-of-industry companies -- I always hated the constant interruption but couldn't deny how much faster everything moved; that said I mostly did deep work well after office hours (so a workweek would basically be 40 hours of getting interrupted to death followed by 20-30 hours of deep work + backlog-clearing), as did ~everyone else.
At least speaking from my experience, one of the default ways the Lightcone campus team gets deep-work done is by working in pairs. I also think we would structure things probably somewhat differently if we were doing more engineering or math work (e.g. the LessWrong team tends to be somewhat less interrupt driven).
I've found that by working in pairs with someone, I end up with a lot more robustness to losing context for a minute or two, and often get to expand my metacognition, while still getting a lot of the benefits of deep work. It doesn't work for everything (for example, I have a really hard time co-writing long pieces of text with someone), but it works pretty well for other things (like programming, planning, preparing talks, legal work).
The lame answer: yeah, it does mess with deep work, and I'm not super sure how to balance them.
The spicy answer: I have an unwritten polemic entitled "Against Deep Work". I can't share it though since I have not written it. Fortunately, much of what I hope to say in that post is captured in Chapter 9 of the Lean Startup, which has a section that resonates a lot with my experience. I'll just go ahead and quote it because it's so damn good (starting on page 191 in the linked PDF).
Imagine you’re a product designer overseeing a new product and you need to produce thirty individual design drawings. It probably seems that the most efficient way to work is in seclusion, by yourself, producing the designs one by one. Then, when you’re done with all of them, you pass the drawings on to the engineering team and let them work. In other words, you work in large batches.
From the point of view of individual efficiency, working in large batches makes sense. It also has other benefits: it promotes skill building, makes it easier to hold individual contributors accountable, and, most important, allows experts to work without interruption. At least that’s the theory. Unfortunately, reality seldom works out that way.
Consider our hypothetical example. After passing thirty design drawings to engineering, the designer is free to turn his or her attention to the next project. But remember the problems that came up during the envelope-stuffing exercise. What happens when engineering has questions about how the drawings are supposed to work? What if some of the drawings are unclear? What if something goes wrong when engineering attempts to use the drawings?
These problems inevitably turn into interruptions for the designer, and now those interruptions are interfering with the next large batch the designer is supposed to be working on. If the drawings need to be redone, the engineers may become idle while they wait for the rework to be completed. If the designer is not available, the engineers may have to redo the designs themselves. This is why so few products are actually built the way they are designed.
When I work with product managers and designers in companies that use large batches, I often discover that they have to redo their work five or six times for every release. One product manager I worked with was so inundated with interruptions that he took to coming into the office in the middle of the night so that he could work uninterrupted. When I suggested that he try switching the work process from large-batch to single-piece flow, he refused— because that would be inefficient! So strong is the instinct to work in large batches, that even when a large-batch system is malfunctioning, we have a tendency to blame ourselves.
Large batches tend to grow over time. Because moving the batch forward often results in additional work, rework, delays, and interruptions, everyone has an incentive to do work in ever-larger batches, trying to minimize this overhead. This is called the large batch death spiral because, unlike in manufacturing, there are no physical limits on the maximum size of a batch. It is possible for batch size to keep growing and growing. Eventually, one batch will become the highest-priority project, a “bet the company” new version of the product, because the company has taken such a long time since the last release. But now the managers are incentivized to increase batch size rather than ship the product. In light of how long the product has been in development, why not fix one more bug or add one more feature? Who really wants to be the manager who risked the success of this huge release by failing to address a potentially critical flaw?
Overall I think deep work is sometimes important. But other times it's just a symptom that you're in a large batch death spiral; and changes that enable you to have more deep work will also trap the organisation harder in the death spiral.
I lead the LessWrong team within Lightcone (the "other" team) and I care a lot about protecting deep work time from interruptions. Though in practice due to the structure of the team (3 of us, usually 2 out 3 pairing), there's not that much blocking arising. As team lead, I'm the one moost likely to be a blocker and I end up kind of in the pattern you describe of doing deep work outside of regular hours so I'm available during.
I'm not sure if there's a better way if you're trying to get a lot done.
Some context on why I wanted Jacob to post this...
A lot of new alignment/EA orgs and projects have been popping up lately. The majority of these are founded by people who are either fresh out of college, or researchers who have been in academia basically their whole lives. In other words, they're founded by people who have minimal experience with or exposure to ops and management (and the ops/management they do interface with tends to be mediocre at best). Interfacing with such orgs inevitably means interfacing with people who are bad at ops, and are figuring it out as they go (insofar as they figure it out at all).
A couple weeks ago, Akash wrote up his "AI Safety field-building projects I'd like to see". I was struck by visions of dozens of new projects attempting one or another thing on that list with terrible ops, all turning into mangled versions of themselves in which the organizers were constantly fighting fires from start to end with mixed success, with the things which actually matter most going unaddressed for lack of slack and time, until the projects eventually just kind of dissolved. In the end, I sighed, and accepted that somebody was going to have to metaphorically sit the kids down for a talk.
... of course this rarely works, and inevitably the kids will need to fail for a while before they figure things out. Hopefully reading some things by people who (in my judgement) are good at ops will at least speed it up. In the meantime, here's the One Thing I'd tell someone starting a project/org: if I were starting an org, the very first thing I would do is hire an ops person, preferably someone who I've interfaced with before and know to be competent. I'm not saying your first hire needs to be an ops person; great ops people are scarce, and you'll probably do more of your own ops than I would aim for and develop the skills yourself. The point is that getting ops right would literally be the first thing on my todo list for a new org. It might not be the Most Important Thing, but it's the Most Foundational Thing, and everything else will constantly be slowed down and falling apart and generating inconveniences if the ops foundation isn't there.
It would also be interesting to see examples of what terrible ops looks like. As one of the "kids", here are some examples of things that were bad in previous projects I worked on (some mistakes for which I was responsible):
- getting obsessed with some bad metric (eg: number of people who come to an event) and spending lots of hours getting that number up instead of thinking about why I was doing that
- so many meetings, calling a meeting if there's any uncertainty about what to do next
- there being uncertainty about what to do next because team members lack context, don't know who's responsible for what, who is working on what, etc
- some people taking on too much responsibility and not being able to pass it on because having to explain how to do a task to someone else would itself take up too much time
- very disorganised meetings where everyone wanted to have a say and it wasn't clear at the end of it what the action steps were
- an unwillingness for the person with the most context to take the role of explicitly telling others what concrete tasks to do (because the other team members were their friends and they didn't want to be too bossy)
- There not being enough structure for team members to give feedback if they thought an idea or project someone else was very excited about would be useless, as a result some mini-projects getting incubated that people weren't excited about or projects that predictably failed because the person who wanted to do them did not have enough information to help them figure out how to avoid the failure modes other team members would have been concerned about (lack of sharing intuitions really well). also, people picking projects and tasks to do for bad reasons rather than via structured thinking about priorities
- including too many people in meetings because "we'd love to get person X's thoughts on our plans as well (and person Y and person Z...)"
- it being hard to trust that other team members would actually get things assigned to them done on time, partly because it was difficult to see partial progress without having to ask the person how things were going
- changing platforms and processes based on whims rather than figuring things out early and sticking with them
I think some of the things mentioned in the post are pretty helpful for avoiding some of these problems.
I think this is a great goal and that this post furthers it. I do hope someone from a more staid institution writes a parallel document about how they work. Lightcone runs on a very chaotic/heroic model that works well for them and has accomplished great stuff, but some projects and people do better with a slower and steadier approach.
Can confirm Lightcone is very chaotic and sometimes works heroic hours, and it seems tangled up in our way of working for reasons that are not super clear to me.
So when reading your comment I was asking myself why the above template couldn't be run by a project that wanted to work closer to 40 hours rather than 80 hours per week? One answer is that "Well, if people are importantly blocking elements, they must be available to reply on slack and unblock other people whenever", which is mostly true for us, except that 1) we almost never wake up people who are sleeping :) and 2) if people sign-post they are taking a rest day or going on vacation others usually try fairly hard to find a way to solve problems without contacting them.
I agree that most of these rules could smoothly transition to a less intense team, and nonetheless believe a less chaotic org would write a fairly different document, which is why I think it would be useful for them to do so.
One thing I can speak to a tiny bit is a software company I worked at that had a lot of the chaotic/hero-ness in certain roles, but absolutely had to be cross-continental, and thus was also remote and heavily asynchronous. It built up really great practices for documentation and async communication to make that work. Alas it's been too long since I worked there for me remember specifics, so I can't say anything useful.
I don't feel that we're especially "chaotic" or would describe us as a chaotic org. We have lots of structure and process and principles and intentionality in how we operate. Though I suspect there's something real you're thinking of.
Oh fwiw I think we’re quite chaotic. Like, amount of suddenly changing priority and balls sometimes getting dropped because we took on too many things.
(Not sure we’re that chaotic for a startup, but startups are already pretty chaotic)
For me, the interesting part is the transition from a fast-growing startup to a stable enterprise. I have been in transitional companies most of my professional life, and felt the growing pains. I have looked for resources to support this transition. One book provided a useful lens: Growing Pains: Transitioning from an Entrepreneurship to a Professionally Managed Firm by Eric G. Flamholtz and Yvonne Randle (Goodreads). It describes a number of stages or challenges that a maturing company has to tackle in a particular order of priority. It is mostly based on case studies and surveys.
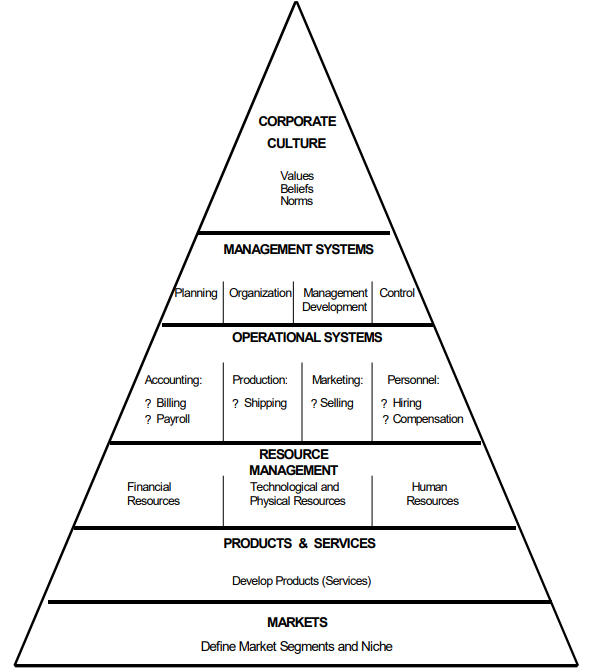
(picture from this summary)
The Growth Stages are
- New Venture - Markets and Products
- Expansion - Resources and Operational Systems
- Professionalization - Management Systems
- Consolidation - Corporate Culture
In my experience, all the areas have to be advanced at the same time, but some more than others. For example, the clear instructions, mentioned above are a precursor to Corporate Culture. And it also makes sense to start with Operational Systems before you need them - at least to hire people with experience in these areas that will later be able to bring them about.
Pretty interesting, but I have a bunch of warning flags around the phrase "hire an ops person", here's a few thoughts:
- Everyone on our team is a "generalist", not an "ops person". Anyone can do any task. When we run an event or space, responsibilities involve "venue setup" and also "preparing opening session", and anyone should be able to be assigned to any task, or help with any task. (Of course, there's explicitly one person owning each task, it's fully clear who has final decision-making power, and who gets credit for failure/success.)
- For new organizations I would bet on them much harder if all the cofounders could do all the work, than if the cofounders could each only do some of the work. And I'd bet against more strongly still if no single cofounder could do all of the work. I do think research orgs tend to have more of a split here, I'm not sure how good I think that is (I know multiple cases where it's led to major dysfunction), I still think it's best if there's a person at the top who can do everything.
- Historically when I've been told by a team-lead that "ops is not my responsibility, I'm not tightly in the loop on that" this has been closely correlated with there being an ops catastrophe somewhere that the team-lead is unable to fix, that's been quite costly for the project.
- Your point about giving space for newcomers to fail a while is a good one, and I agree. But I'm not of the same mind that "get better ops hires" is the method, as opposed to "relentlessly work until you yourself have the skill to ensure your project's success".
- Especially if your ops hire doesn't understand your work or your mission, and you aren't likely to produce very legible signs of success (e.g. big funding, big publications, impressive product sales, etc), then it's hard for that person to be motivated by the mission, and they may leave to do something for which they do have the generators. And then you'll be left with a shell of an org built around them that nobody, not even you, really knows how it functions.
- That said, I think if you're weak in an area (e.g. in coding, or management, or other things), having a cofounder who is strong in that area is really excellent, and my best project collaborators have been people who, while in key ways are extremely similar to me, do have strengths where I have weaknesses and can pick up the slack there.
- As a second example of Lightcone being generalists, when we're evaluating how LessWrong/AF is doing, everyone should have an inside view and have engaged with the content, not only some of us e.g. at a recent team retreat, we spent an hour or two as a team debating whether the simulators post was right about the myopia of language models, and nobody wasn't basically following the discussion.
Pardon the long scattershot of thoughts. I have a sense that people often try to 'hire for ops roles' poorly, and are confused about how to allocate work within a small team, so I wanted to say something about how it can go wrong and how else one can think about it.
Edit: I don't think this applies for short-term contractors, it primarily applies to cofounders and other permanent hires.
given this notional use case (and the relative inexperience of the implied user), I think its even more important to (as Gunnar mentioned) contextualize this advice as to whom its for, and how they should use it.
doing that properly would take more than i have for this at the moment, but i'd appreciate epistemic tagging regarding things like;
this only could work at a new/small scale (for reasons including because the cost of keeping everyone 100% context scales with org size and because benefits don't)
that strategy has to fit the employees you have, and this sort of strategy constrains the type of person you can hire to those who would fit it (which is a cost to be considered, not a fatal flaw).
For what it's worth I don't consider this essay to be about "ops" that much. Also lots of people keep calling much of what Lightcone does "ops", but we often really don't think of ourselves as doing ops that much :) Some words that sound to me more like the thing I think of Lightcone as doing, most of the time: "uncertainty reduction", "product discovery", "trying to doing things fast".
I nod along here, but I'm not sure what "getting ops right" actually looks like. Can someone explain or point me to something I should read?
+1 on many of the projects in my list requiring a team with really good ops and (ideally) people with experience beyond college/academia.
(I hope I didn’t give off the impression that anyone can or should start those.)
In the spirit of guidelines over advice: Can you provide some context for what kind of organization or under what assumptions your recommendations apply? I would guess that software development in an early startup is very different from in a mature product. Or servicing an app is different from supporting a small number of complex clients.
I don't have that much experience, so don't want to say too much. But I think it should apply well to things like startups searching for product-market fit (you're rate-constrained by how fast you can figure out what people want), or a factory increaseing how many widgets they can output per day, but less well to e.g. teams that are trying to maintain a system, like a gardener, or a janitorial service.
I think this post makes sense from a "theory of constraints" perspective: if you're pursuing a mission that's no faster than some identifiable step, and the best thing you can do each week to move faster toward your mission is mostly about speeding up that step.
Lightcone has evolved a bit since Jacob wrote this, and also I have a somewhat different experience from Jacob.
Updates:
- "Meeting day" is really important to prevent people being blocked by meetings all week, but, it's better to do it on Thursday than Tuesday (Tuesday Meeting Days basically kill all the momentum you built up on Monday)
- We hit the upper limits of how many 1-1 public DM channels really made sense (because it grew superlinearly with the number of employees). We mostly now have "wall channels" (i.e. raemon-wall), where people who want to message me write messages. (But, for people I am often pairing extensively with, I still sometimes use dedicated 1-1 channels for that high-bandwidth communication)
- I think still try to have top-priorities set on Monday, but I think they are a bit looser than the way Jacob was running things on his team at the time.
Things I still basically endorse that feel particularly significant
- Having people work onsite and near each other so you can easily get help unblocking yourself is indeed quite valuable. The difference between being in the same room and even one-room-over is significant, and being across the office very significant. Being offsite slows things down a lot.
- Pairing feels even more important than this post makes it seem. I think there's a lot of type of work that feels like you don't need to be pairing, but I think pairing helps me stay focused long after my attention would have started to flag.
For pairing, I'd add:
- When people don't pair for a long stretch of time, my sense is they might initially feel more productive, but then slide into bad habits or avoidant behaviors that are hard to notice.
- Pairing allows for skill transfer. Pairing between different people with different skills is great.
- I personally prefer a style of pairing that is very explicit and... micromanagey (both for when I'm the driver or the navigator). i.e. "go to the top-right corner of the screen, click the button, then go to the middle of the screen and type [X]."). Some people find that difficult, it's not one-size-fits-all, but I find it good for avoiding confusion that crops up when you try to give or receive more openended directions.
- We have shifted to almost always pairing via zoom and screen share, rather than leaning over at each other's monitors (even while in the same room), so we don't have to crane our neck all the time.
I probably could say more but that seems like how much time I want to spend on it for now.
To manage that many people, it seems to me you need clear, concrete instructions.
To me, that sounds very wrong. I don't think you can manage big organizations by giving clear concrete instructions from the top as that means that the people involved with object level reality would often have too little room to adapt to the object-level reality of what they are doing.
It might still work well at the current size of Lightcone but the management of >100 people organizations is a lot about setting the right incentives.
I agree. This sounds like a manifesto for how to be effective at <100, and in a way that some people won't like, but that's fine for a "startup" to filter on things like that since you don't need to hire a lot of people and can be pickier. Lots of this sounds like stuff that will blow up if there's more than a Dunbar number of humans around.
Interesting - I interpreted this section differently, and yet I think it ultimately cashes out as agreeing with your comment about incentives.
In my reading, the clear concrete instructions are about the priorities, and about how to communicate. From the rest of the post I understood clearly that this means instructions like:
- Priority 1 this week is X. In any decision with a tradeoff between X and Y, choose X.
- Work on X for the next 4 hours after this meeting. Do not work on anything else.
- Schedule miscellaneous meetings on Tuesdays. Do not schedule them on any other day.
- Etc.
I think this cashes out as setting good incentives because these kinds of instructions make it very easy to evaluate the goodness of decisions, going as far as to effectively make a bunch of them automatically. I feel like we always have an incentive to go with the easy decision, and always have an incentive to follow instructions, which neatly screens off some bad things. In this way, the incentives are properly aligned.
Imagine Tesla implementing those rules. Whatever priority you set as X, it likely doesn't make sense that both the people putting solar tiles on people's roofs and the people writing code for automated cars work on X.
Really appreciate this list!
Things I very much agree with:
4. Have a single day, e.g. Tuesday, that’s the “meeting day”, where people are expected to schedule any miscellaneous, external meetings (e.g. giving someone career advice, or grabbing coffee with a contact).
12. Have a “team_transparency@companyname” email address, which is such that when someone CC’s it on an email, the email gets forwarded to a designated slack channel
17. Have regular 1-1s with the people you work with. Some considerations only get verbalised via meandering, verbal conversation. Don’t kill it with process or time-bounds.
Things I'm very unsure about:
8. Use a real-time chat platform like Slack to communicate (except for in-person communication). For god’s sake, never use email within the team.
I actually often wonder whether Slack (or in our case, Discord) optimizes for writeability at the cost of readability. Meaning, something more asynchronous like Notion, or maybe the LessWrong forum/Manifold site, would be a better system of documenting decisions and conversations -- chat is really easy to reach for and addictive, but does a terrible job of exposing history for people who aren't immediately reading along. In contrast, Manifold's standup and meeting calendar helps organize and spread info across the team in a way that's much more manageable than Discord channels.
14. Everyone on your team should be full-time
Definitely agree that 40h is much more than 2x 20h, but also sometimes we just don't have that much of certain kinds of work, slash really good people have other things to do with their lives?
Things we don't do at all
5. No remote work.
Not sure how a hypothetical Manifold that was fully in-person would perform -- it's very unclear if our company could even have existed, given that the cofounders are split across two cities haha. Being remote forces us to add processes (like a daily hour-long sync) that an in-person team can squeak by without, but also I think has led to a much better online community of Manifold users because we dogfood the remote nature of work so heavily.
Finally: could you describe some impressive things that Lightcone has accomplished using this methodology? I wonder if this is suited to particular kinds of work (eg ops, events, facilities) and less so others (software engineering, eg LessWrong doesn't seem to do this as much?)
Thanks for writing this, Jacob!
I wonder if you (or other members of Lightcone) have any advice on how to hire/get contractors.
It seems to me like many orgs (even ones with good internal practices) fail because they hired too quickly or too slowly or not-the-right-people or not-the-right-mix-of-people. Any thoughts?
(And no worries if you’re like “cool question but i don’t have any quick answers”)
I might write up rants about hiring at some point, though I don't think I'm particularly experienced or great at it :) For now I'll just say I like YCombinator's content on this. Not sure how to find all the relevant essays and videos, but this might help https://www.ycombinator.com/library?categories=Hiring
The Neglected Virtue of Scholarship comes to my mind here. I've never been in a position where I've been responsible for these sorts of managerial/operational questions, but if I were, the first thing I'd do would be to survey whatever (formal and informal) literature is out there (or hopefully delegate that). It's the sort of thing many organizations face, so I'd assume that there's some research on it, or at least smart people with opinions that can be surveyed and consolidated. Shoulders of giants to be stood on.
Things I've read / advice I've gathered that influenced me a lot, are:
- Paul Graham's essays and YCombinator's startup philosophy
- lean manufacturing philosophy
- Elon Musk's operational principles (there's a ton of junk content about this online, but I've been able to find some good first-hand accounts from people who work at tesla and spacex, as well as probably the single best piece of content, which is the 2-3h starbase tour https://www.youtube.com/watch?v=t705r8ICkRw ). Tesla also has a "25 Guns" team that runs on a to-me very similar philosophy
- first-hand or second-hand conversations with the founders of FTX
- honorary mention, because it's not advice inasmuch as a benchmark: https://patrickcollison.com/fast
I feel like this is where taste comes into play though. If you have good taste, you can find the resources/people that are worth paying attention to. And similarly, you can ask the right people to point you to the right resources. No?
Relatedly, a working hypothesis of mine is that a big benefit of reading peoples blogs is that you develop an epistemic trust in them, and could then use them for reasons like this. Or maybe use them indirectly: you trust Alice, Alice thinks highly of Bob, Bob thinks Carol is a good resource on operations and recommends a given textbook, so you read a few of Carols posts, pick up the textbook, skim it, and look through the sources that the textbook cites. And it all starts with you having epistemic trust in Alice.
Very interesting points. But some of them are surely specific to the size, workforce make-up and activities of your organisation. I’d like to put an alternative view on point 14, at least as it applies to an organisation with longer timelines and a more autonomous working regime (so less opportunity for blocking). My experience is that part-time workers can be more productive hour for hour than full-time workers, in the right work domain. A fully committed part-time worker has a ready-made excuse to avoid those meetings that don’t make them productive. They will use their slack time to be thinking of their work, coming up with ideas at leisure, and creating an effective plan for their next work period. They can be flexible in their work hours so as to attend the important meetings and one-to-ones and to avoid blocking anyone (Especially if they also WFH some of the time- so can dip into work for an hour in a day they normally don’t work). They can use (E.g computational) resources more effectively so that they are rarely waiting for lengthy production runs (or calculations, say) to finish. Lastly, they are often less stressed through not being overworked (and hence more effective).
Clearly this will not be true for all work domains. Nevertheless it has been recently reported in the UK press that an international experiment to test a 4 day (32 hr) work week at 100% salary has resulted in no loss of productivity for many of the companies involved, and many of them are continuing with the scheme.
So the domain I’m most familiar with is early stage drug discovery In industry. This requires multidisciplinary teams of chemists, computational chemists, biochemists, biologists, crystallographers etc. Chemists tend to be associated with one project at a time and I don’t perceive part-time working to be beneficial there. However the other disciplines are often associated with multiple projects. So there’s a natural way to halve (say) the workload without reducing efficiency. The part-time scientist should be highly experienced, committed to what they are doing, and have few management responsibilities. If that holds then my experience is they are at least as productive than a full time worker, hour for hour.
Even if two people nominally collaborate on a task, there’s often a third person who has a take or some other resource that would be very useful to them. By having public channels, you enable that person to appear and share that info.
"Appear" here makes it sound like they're showing up unasked, is that what you meant? I'm a bit surprised if so, I wouldn't normally expect people to be reading 1-1 conversations they're not in unless specifically prompted.
Or do you just mean that it's easier for one of the two to ask them and they can read the backlog for context? (Or I guess, additional context - I'd expect that most of the time, it would be helpful for the person asking to give a few details up front to help orient.)
By default information does not travel via long written documents. Writing and sending those documents around will slow your team down a lot.
The generalist [job description](https://www.lightconeinfrastructure.com/campus-generalist.html) on the lightcone website says "team members also regularly write many-page memos explaining their plans and ideas to other team members". Do these reconcile?
The majority of tasks we do don't involve any memos. We write them occasionally when 1) thinking through some big, hard-to-reverse decision, 2) when setting goals for 2-week sprints, and 3) if someone wants to call an all-hands meeting, we usually require them to write a memo first (which is a nice rate-limit on how many all-hands meetings you get).
I think the rate of memos written is maybe 0.5 per person per month, on average, but counting it is a bit messy.
Disclaimer: I originally wrote this as a private doc for the Lightcone team. I then showed it to John and he said he would pay me to post it here. That sounded awfully compelling. However, I wanted to note that I’m an early founder who hasn't built anything truly great yet. I’m writing this doc because as Lightcone is growing, I have to take a stance on these questions. I need to design our org to handle more people. Still, I haven’t seen the results long-term, and who knows if this is good advice. Don’t overinterpret this.
Suppose you went up on stage in front of a company you founded, that now had grown to 100, or 1000, 10 000+ people. You were going to give a talk about your company values. You can say things like “We care about moving fast, taking responsibility, and being creative” -- but I expect these words would mostly fall flat. At the end of the day, the path the water takes down the hill is determined by the shape of the territory, not the sound the water makes as it swooshes by. To manage that many people, it seems to me you need clear, concrete instructions. What are those? What are things you could write down on a piece of paper and pass along your chain of command, such that if at the end people go ahead and just implement them, without asking what you meant, they would still preserve some chunk of what makes your org work?
Here’s my current best guess at how I would do this for Lightcone Infrastructure, the organisation where I spend the majority of my waking hours. I wrote it by thinking about how the team I'm on has actually operated during periods of high output, and then trying to turn that into a set of rules. Others on the team might disagree about which rules matter and where the magic sauce is, but I think this is at least empirically descriptive of how my team spends much of our time.
0. Blockers are death. Above all else, your job is to unblock anything that prevents you from moving as fast as you can toward your top priority.
That's it for now.
I have more to say, but for now I will ship early.