This is a linkpost for https://arxiv.org/abs/2211.01288
New Comment
I'm not surprised that if you investigate context-free grammars with two-to-six-layer transfomers you learn something very much like a tree. I also don't expect this result to generalize to larger models or more complex tasks, and so personally I find the paper plausible but uninteresting.
I do think the paper adds onto the pile of "neural networks do learn a generalizing algorithm" results.
if you investigate context-free grammars
Notably, on Geoquery (the non--context-free grammar task), the goal is still to predict a parse tree of the natural sentence:
Given that neural networks generalize, it's not surprising that a tree-like internal structure emerges on tasks that require a tree-like internal structure.
I also don't expect this result to generalize to larger models or more complex tasks, and so personally I find the paper plausible but uninteresting.
Since we don't observe this in transformers trained on toy tasks without inherent tree-structure (e.g. Redwood's paren balancer) or on specific behaviors of medium LMs (induction, IOI, skip sequence counting), my guess is this is very much dependent on how "tree-like" the actual task is. My guess is that some parts of language modeling are indeed tree-like, so we'll see a bit of this, but it won't explain a large fraction of how the network's internals work.
In terms of other evidence on medium-sized language models, there's also the speculative model from this post, which suggests that insofar as this tree structure is being built, it's being built in the earlier layers (1-8) and not later layers. 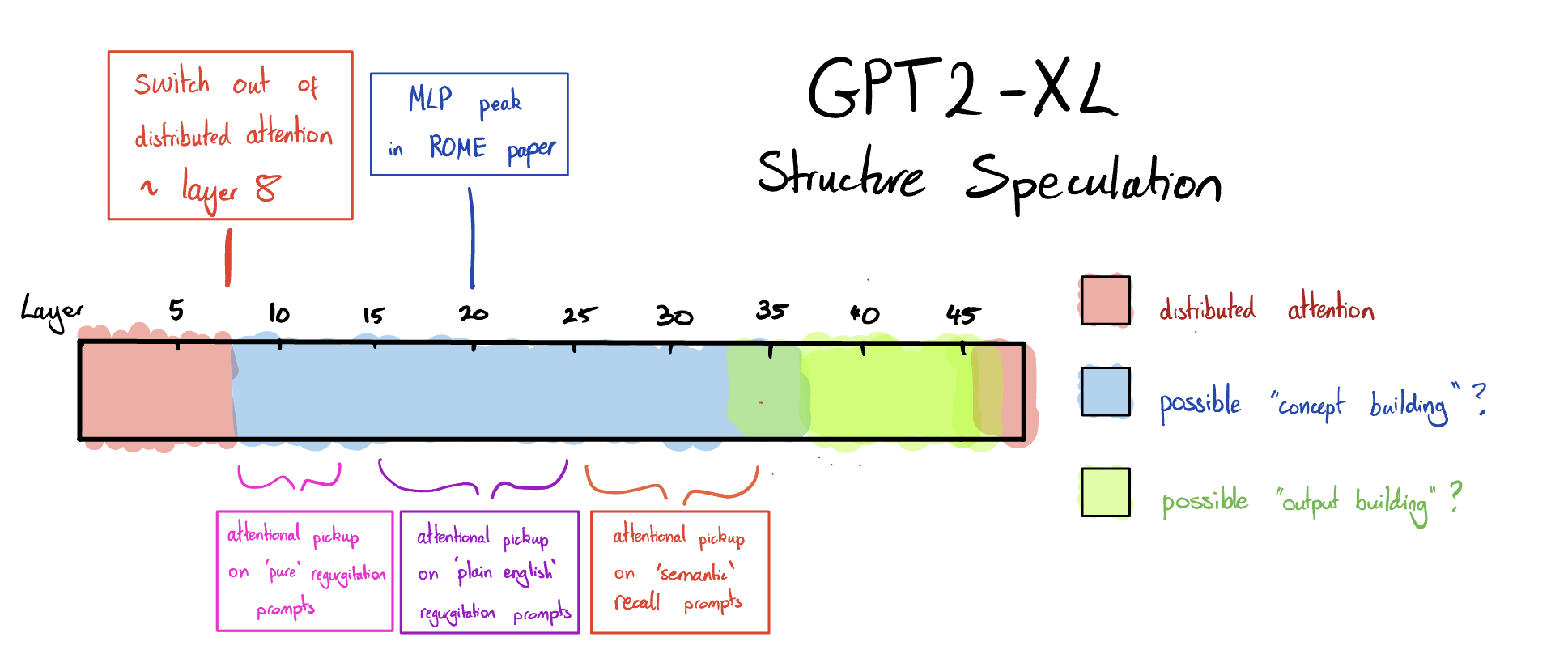
From Twitter
Abstract
Note: The datasets they use aren't typical human text. See page 5.
I'm interested in discussions and takes from people more familiar with LMs. How surprising/interesting is this?