If you'd prefer, feel free to leave questions for Squiggle AI here, and I'll run the app on them and respond with the results.
In the EU there's some recent regulation about bottle caps being attached to bottles, to prevent littering. (this-is-fine.jpg)
Can you let the app come up with a good way to estimate the cost benefit ratio of this piece of regulation? E.g. (environmental?) benefit vs (economic? QALY?) cost/drawbacks, or something like that. I think coming up with good metrics to quantify here is almost as interesting as the estimate itself.
Or as a possible more concrete prompt if preferred: "Create a cost benefit analysis for EU directive 2019/904, which demands that bottle caps of all plastic bottles are to remain attached to the bottles, with the intention of reducing littering and protecting sea life.
Output:
-
key costs and benefits table
-
economic cost for the beverage industry to make the transition
-
expected change in littering, total over first 5 years
-
QALYs lost or gained for consumers throughout the first 5 years"
Okay, I ran this a few times.
I tried two variations. In the first, I just copied and pasted the text you provided. In the second, i first asked Perplexity to find relevant information about your prompt - then I pasted this information into Squiggle AI, with the prompt.
Here are the outputs without the Perplexity data:
https://squigglehub.org/models/ai-generated-examples/eu-bottle-directive-172
https://squigglehub.org/models/ai-generated-examples/eu-bottle-directive-166
And with that data:
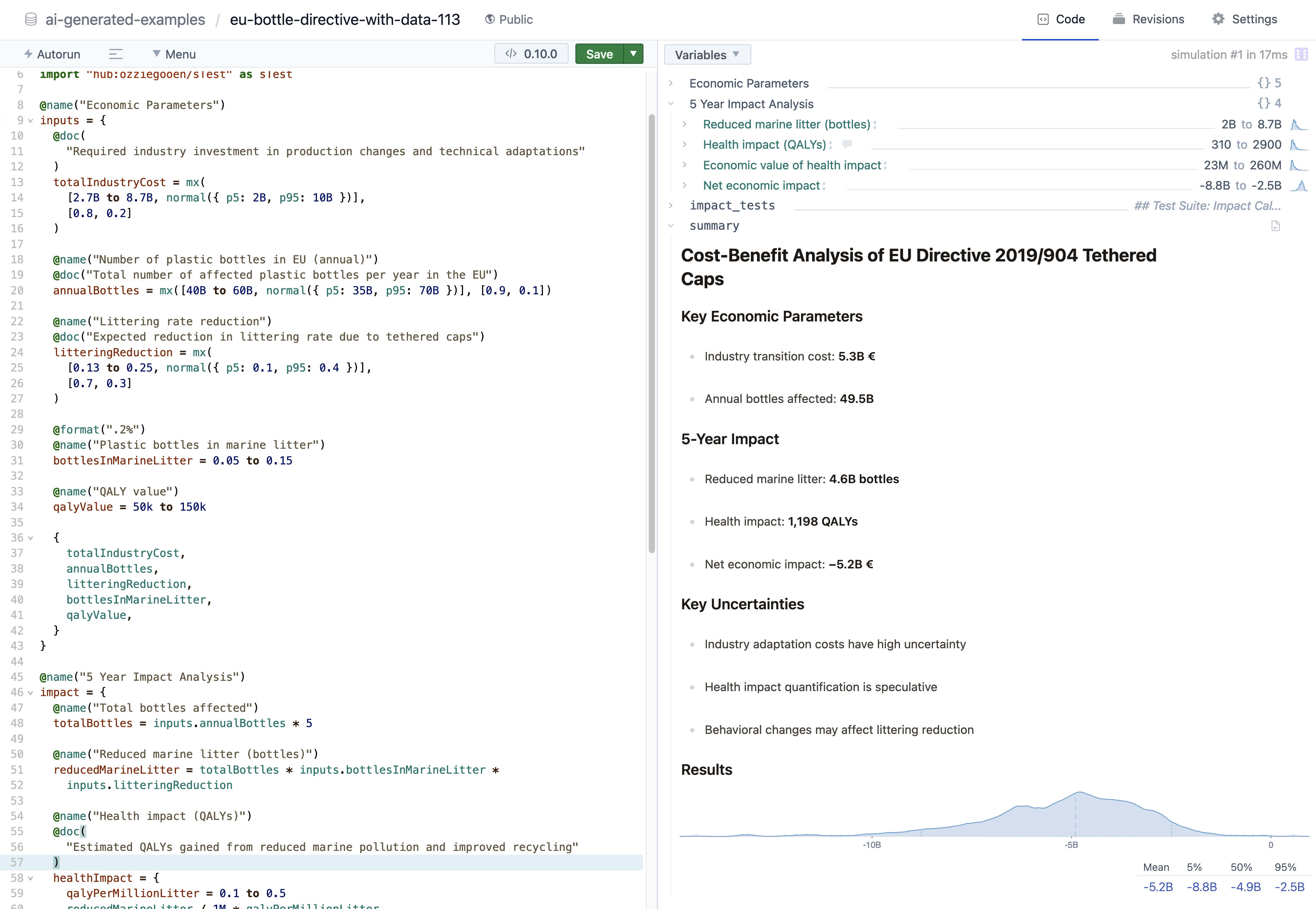
https://squigglehub.org/models/ai-generated-examples/eu-bottle-directive-with-data-113
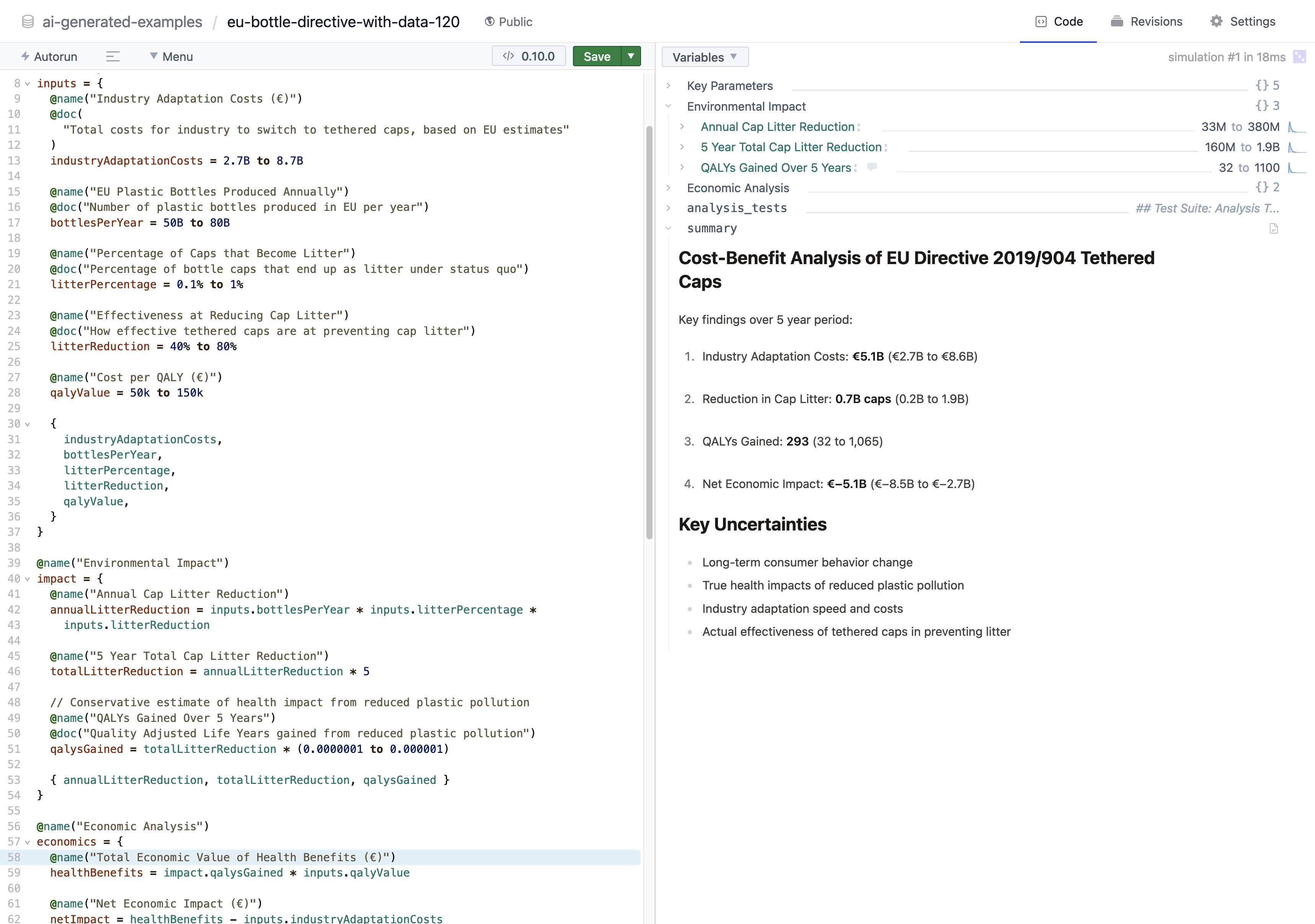
https://squigglehub.org/models/ai-generated-examples/eu-bottle-directive-with-data-120
Of the ones with data, they agree that the costs are roughly €5.1B, the QALYs gained are around 30 to 3000, leading to a net loss of around €−5.1B. (They both estimate figures of around €50k to €150k of willingness to pay for a QALY, in which case 30 to 3000 QALYs is very little compared to the cost).
My personal hunch is that this is reasonable as a first pass. That said, I think the estimate of the QALYs gained seems the most suspect to me. These models estimated this directly - they didn't make sub-models of this, and their estimates seem wildly overconfident if this is meant to include sea life.
I think it could make sense to make further models delving more into this specific parameter.
i first asked Perplexity to find relevant information about your prompt - then I pasted this information into Squiggle AI, with the prompt.
It'd be cool if you could add your perplexity api key and have it do this for you. a lot of the things i thought of would require a bit of background research for accuracy
Yep, this is definitely one of the top things we're considering for the future. (Not sure about Perplexity specifically, but some related API system).
I think there are a bunch of interesting additional steps to add, it's just a bit of a question of developer time. If there's demand for improvements, I'd be excited to make them.
I'm someone who tried squiggle out back when you had recently announced it. I liked it, and could see uses for it, but forgot about it. Since then I've continued to do my thinking/modeling of this style in jupyter notebooks.
I like the AI squiggle better, although it is frustrating in some ways (not making quite what I had in mind). I tried using it to recreate some plots Claude had made for me recently in a conversation about risk modeling. I eventually got most of what I wanted, but more slowly and with more frustration than from just having Claude directly make interactive plots for me (where I can adjust the values with sliders to aee the results on the predictions).
So, I will continue trying to keep squiggle in mind for future tasks and try it again... But I expect Claude is going to get better at making charts directly on its own within a few months... So that's a tough race to be in.
Thanks for the info!
Yea, I think it's a challenge to beat Claude/ChatGPT at many things. Lots of startups are trying now, and they are having wildly varying levels of success.
I think that Squiggle AI is really meant for some fairly specific use cases. Basically, if you want to output a kind of cost-effectiveness model that works well in Squiggle notebooks, and you're focused on estimating things without too much functional complexity, it can be a good fit.
Custom charts can get messy. The Squiggle Components library comes with a few charts that we've spent time optimizing, but these are pretty specific. If you want fancy custom diagrams, you probably want to use JS directly, in which case environments like Claude's make more sense.
Hmm. I wonder if it would make sense with Squiggle AI to give Claude some space for "freeform" diagrams coded in JS, based on the variables from the code... Might be worth experimenting with. Maybe too soon, but it'd probably work after the next upgrade (e.g. Claude 4)
Yea, I think there's generally a lot of room for experimentation around here.
I very much hope that in the future, AI cools could be much more compositional, so you won't need to work only in one ecosystem to get a lot of the benefits.
In that world, it's also quite possible that Claude could call Squiggle AI for modeling, when is needed.
A different option I see is that we have slow tools like Squiggle AI that make large models that are expected to be useful for people later on. The results of these models, when interesting, will be cached and made publicly available on the web, for tools like Claude.
In general I think we want a world where the user doesn't have to think about or know which tools are best in which situations. Instead that all happens under the hood.
This is cool. I asked it a question in a field I'm not knowledgable about at all but my roommate is. I think having the structure there to make it maximally easy to elicit his expertise is super valuable.
Very cool tool; thank you for making it!
A tangential question:
Recent systems with Python interpreters offer more computational power but aren't optimized for intuitive probabilistic modeling.
Are you thinking here of the new-ish canvases built into the chat interfaces of some of the major LLMs (Claude, ChatGPT)? Or are there tools specifically optimized for this that you think are good? Thanks!
Thanks!
> Are you thinking here of the new-ish canvases built into the chat interfaces of some of the major LLMs (Claude, ChatGPT)? Or are there tools specifically optimized for this that you think are good? Thanks!
I'm primarily thinking of the Python canvas offered by ChatGPT. I don't have other tools in mind.
This is pretty cool. A small complaint about the post itself is that it does not explain what Squiggle is so I had to look around in your website to understand why this Squiggle language that I have never heard of is used.
Fair point! I should have more prominently linked to that.
There's some previous posts about it on LessWrong and the EA Forum explaining it in more detail.
https://www.lesswrong.com/tag/squiggle
https://forum.effectivealtruism.org/topics/squiggle
We’re releasing Squiggle AI, a tool that generates probabilistic models using the Squiggle language. This can provide early cost-effectiveness models and other kinds of probabilistic programs.
No prior Squiggle knowledge is required to use Squiggle AI. Simply ask for whatever you want to estimate, and the results should be fairly understandable. The Squiggle programming language acts as an adjustable backend, but isn’t mandatory to learn.
Beyond being directly useful, we’re interested in Squiggle AI as an experiment in epistemic reasoning with LLMs. We hope it will help highlight potential strengths, weaknesses, and directions for the field.
Screenshots
Motivation
Organizations in the effective altruism and rationalist communities regularly rely on cost-effectiveness analyses and fermi estimates to guide their decisions. QURI's mission is to make these probabilistic tools more accessible and reliable for altruistic causes.
However, our experience with tools like Squiggle and Guesstimate has revealed a significant challenge: even highly skilled domain experts frequently struggle with the basic programming requirements and often make errors in their models. This suggests a need for alternative approaches.
Language models seem particularly well-suited to address these difficulties. Fermi estimates typically follow straightforward patterns and rely on common assumptions, making them potentially ideal candidates for LLM assistance. Previous direct experiments with Claude and ChatGPT alone proved insufficient, but with substantial iteration, we've developed a framework that significantly improves the output quality and user experience.
We're focusing specifically on cost-effectiveness estimates because they represent a strong balance between specificity and broad applicability. These models often contain recurring patterns and sub-variables, yet can be applied to a wide spectrum of human decisions - from different kinds of charitable giving to policy interventions.
Looking ahead, if we succeed in automating cost-effectiveness analyses, we believe this could serve as one foundation for enhanced LLM reasoning capabilities. This work could pave the way for more sophisticated applications of AI in decision-making and impact assessment.
Description
“Squiggle AI” combines LLM capabilities with specialized scaffolding to produce fermi estimates in the Squiggle programming language. The frontend runs on Squiggle Hub. The code is open-source and available on Github.
Since LLMs don't naturally write valid Squiggle code, substantial work has gone into bridging this gap. Our system provides comprehensive documentation to the LLM, implements automatic error correction, and includes steps for model improvement and documentation.
Squiggle AI currently calls Claude 3.5 Sonnet. Each single LLM call costs $0.01-0.04, with full workflows ranging from $0.10-0.35. While we cover these costs currently, users can provide their own API keys. Most workflows complete within 20 seconds to 3 minutes. Resulting models typically are 100-200 lines long.
The tool offers two specific workflows:
Example Outputs
Select recent examples:
Is restoring the Notre Dame Cathedral or donating to the AMF more cost-effective, as a charity?
Comparing health impacts against tourism benefits, the model estimates that a $1B donation to AMF would generate 8M QALYs versus 9K QALYs for Notre Dame. The core calculation uses just 12 lines of code.
What is the cost-effectiveness of a 10-person nonprofit subscribing to Slack Pro?
This makes the core assumption that users will save 1 to 4 hours per month from having a searchable chat history. Results suggest an ROI of approximately 10x.
What is the cost-effectiveness of opening a new Bubble Tea store in Berkeley, CA?
Our most-tested example, popular in workshops for being fun and relevant (at least for people around Berkeley). When accounting for failure risk, the model usually shows negative expected value suggesting a risky investment.
Estimate the cost-effectiveness of different Animal Welfare interventions
Inspired by a discussion of genetic modification of chickens
Evaluated five intervention types, with legislative change emerging as most cost-effective, outperforming genetic modification (ranked second).
Estimate the probability that a single vote will decide the US presidential election, in various states
Inspired by some recent work for the 2024 election. Provides state-level probability estimates through two key data tables. Better input data would improve accuracy.
What is the probability that there will be an AGI Manhattan Project in the next decade, and how will it happen?
Projects 24% probability of an “AGI Manhattan Project” within a decade, primarily driven by potential crisis scenarios.
What is the expected benefit of a 30-year old male to get a HPV vaccine?
Analyzes benefits for 30-year-old males. Despite high costs ($500-$1,000 uninsured), estimates suggest $1k-$100k in expected benefits.
Estimate the cost-effectiveness of taboo activities for a teenager
Demonstrates how using AI scaffolding can do reasoning that goes against social norms, in favor of first-principles thinking. If you ask Claude directly to estimate the benefits of smoking cigarettes or of recreational sex for teenagers, it will usually refuse. This estimate by Squiggle AI states that smoking cigarettes would provide $500 to $2k per year of positive social capital. This is clearly overconfident, but it demonstrates the system’s willingness to make unconventional assumptions.
A more extensive collection of examples is available here. While some older examples there were manually edited, the examples listed above were not. Examples were typically selected out of 2-3 generations each.
How Good Is It?
We don't yet have quantitative measures of output quality, partly due to the challenge of establishing ground-truth for cost-effectiveness estimates. However, we do have a variety of some qualitative results.
Early Use
As the primary user, I (Ozzie) have seen dramatic improvements in efficiency - model creation time has dropped from 2-3 hours to 10-30 minutes. For quick gut-checks, I often find the raw AI outputs informative enough to use without editing.
Our three Squiggle workshops (around 20 total attendees) have shown encouraging results, with participants strongly preferring Squiggle AI over manual code writing. Early adoption has been modest but promising - in recent months, 30 users outside our team have run 168 workflows total.
Accuracy Considerations
As with most LLM systems, Squiggle AI tends toward overconfidence and may miss crucial factors. We recommend treating its outputs as starting points rather than definitive analyses. The tool works best for quick sanity check and initial model drafts.
Current Limitations
Several technical constraints affect usage:
While slower and more expensive than single LLM queries, Squiggle AI provides more comprehensive and structured output, making it valuable for users who want detailed, adjustable, and documentable reasoning behind their estimates.
Alternatives
Direct LLM Estimates
Standard LLMs can perform basic numeric estimates quickly and cheaply. However, they typically lack support for executing programming functions or probabilistic simulations.
LLMs that Call Python
Recent systems with Python interpreters offer more computational power but aren't optimized for intuitive probabilistic modeling. The results are not as interactive as Squiggle playgrounds are.
Basic Squiggle Integration
It’s possible to ask LLMs to generate Squiggle code for you. While most LLMs don’t know much about Squiggle, you can use our custom prompt or the Squiggle Bot on ChatGPT. These can work in a pinch, but are generally a lot less powerful than Squiggle AI.
Using Squiggle AI
Getting Started
Using Workflows
When you start a workflow, you'll see real-time updates as the LLM processes your request. The interface displays:
Note that workflows occasionally stall - if this happens, simply start a new one.
While all workflow runs are saved in our backend (and will be accessible to you), older workflow logs get cleared out over time.
Saving Your Work
To save and/or share your models:
Recommended Tips for Better Results
Keep It Simple
Start with straightforward cost-effectiveness and probabilistic models. Complex requests often fail or require multiple iterations. It’s often fine to bring in a bunch of considerations into a cost-benefit analysis, the challenge comes when some of them require difficult functions.
Generate Multiple Models
Generate 2-4 different model variations for each question to capture a range of perspectives. Since Squiggle AI makes parallel model generation straightforward, you can easily launch multiple workflows with identical inputs. Each individual model is fairly inexpensive.
Be Specific with Details
When modeling specific scenarios:
Optimize Your Workflow
API Usage
For extensive use (20+ runs), consider using your own Anthropic API key. This helps ensure consistent service and reduces load on our shared token.
Complementary Tools
Research and Data Gathering
While Squiggle AI excels at model generation, it doesn't perform web searches or data collection. For comprehensive analysis, consider combining it with:
Alternative LLM Integration
OpenAI o1 and other models can complement Squiggle AI's capabilities. While these tools may outperform Claude 3.5 Sonnet on certain tasks, they typically come with other trade-offs. They can be useful for early ideation, coming up with crucial considerations, or even starting off with a Python model or similar.
Probability Distribution Tools
For estimating specific probability distributions, consider emerging tools like FutureSearch. Squiggle input estimates are often not calibrated.
This ecosystem approach - using each tool for its strengths - often produces the best analyses.
Privacy
Squiggle AI outputs on Squiggle Hub are private. If you want to share them or make them public, you can explicitly do that by creating new models.
Note that our team can access Squiggle AI results for diagnostic purposes. If you require more complete data privacy, please contact us to discuss options.
Technical Details
Performance and Costs
Since Squiggle is a young programming language, it typically needs more troubleshooting and adjustments compared to when using LLMs with more established languages.
Squiggle AI currently uses Claude Sonnet 3.5 for all operations. It makes use of prompt caching to cache a lot of information (around 20k tokens) about the Squiggle language. LLM queries typically cost around $0.02 each to run - more in the case of where large models are being edited.
In terms of accuracy, do not place trust in the default distributions or in the key model assumptions. We’ve found that LLM outputs are often highly overconfident (despite some warnings in the prompts), and often leave out important considerations. This is another reason to do runs multiple times (often, different runs reach very different results), and to adjust models heavily with your own views. In the future, there’s clearly more engineering work that can be done in this area, yet it will likely be very difficult to do fully robustly.
State Machine Details
Squiggle AI makes use of a set of discrete steps, each with specific instructions and custom functionality.
Step 1 is run once, step 2 is run until the code successfully executes, and steps 3 and 4 are run as many times as the user requests. In informal testing, it seems like more runs of steps 3 and 4 improve performance up to some point.
A simplified state machine, showing a typical path. Note that the stages “Update Estimates” and “Document” can be optionally run 0 or more times, based on user request. Also, the “Fix” state is used whenever there is broken code, even if it comes from “Update Estimates” or “Document.”
Conclusion
We think Squiggle AI demonstrates the potential for combining LLMs with specialized programming frameworks to make probabilistic modeling more accessible. While the tool has limitations and should be used thoughtfully, early results suggest it can significantly reduce the barrier to entry for cost-effectiveness analysis and fermi estimation. We invite the community to heavily experiment with the tool and provide takes and feedback.
Appendix: Lessons Learned During Development
LLM cost-effective estimates seem tractable
We spent a few months on this scaffolding, and have found the final tool both useful and promising. There’s clearly a lot of useful work to be done in this area, even without fundamental advances in LLMs.
Given the current performance and limitations of Squiggle AI, it’s not clear how much we would expect it to be used now, especially without significant promotion and advertising. But it does seem clear that at the very least, future related tools have significant potential.
Cost-effectiveness estimation can fit into a larger category of “strategic decision-making.” So far, there’s been significantly more work to use LLMs to solve narrow tasks like coding problems, than there’s been to use LLMs to make high-level and general-purpose strategic decisions. While the latter might be difficult, we think it is tractable.
LLMs are willing to estimate more than you might expect, with some prompting
From Ozzie:
Specialized Steps Improve Results
LLMs with very long prompts tend to forget or neglect large prompt portions. This makes it difficult to rely on a large prompt or two. Instead, it often seemed better to have hand-crafted prompts for different situations. We did this for the four specific steps listed above so far, but imagine that there’s a lot of further expansion to do here.
Claude 3.5 Sonnet often only returns a limited amount of text (up to around 200 lines). This means that any one step can only write so much code or suggest so many changes. It therefore can take multiple prompts for more complex things.
It’s difficult to make complex models understandable
As with other kinds of code, there can be a lot going on with estimation using programming. On one hand, all the key numbers and assumptions are organized in code. On the other hand, there’s a lot of information to represent.
Many viewers might not understand programming well, so providing an overview to these people is a challenge. In addition to the code, variables need substantial detailing. Many quantitative estimates can be highly sensitive to specific assumptions and definitions, so these should be carefully specified. Not only should the programs and assumptions be presented - outputs should be expressed as well. These are often multidimensional and might do best with custom visualizations.
Quick understandability isn’t particularly important for model authors, who already have a deep understanding of their work. But in cases where an AI can very quickly write models, it’s more important for users to quickly be able to quickly understand the model inputs, assumptions, and outputs.
We’ve spent a lot of time on the Squiggle Playground and with a specific Style Guide to help address it, but this remains a significant challenge.
Prompt engineering can be a lot of work
A lot of building this tool has been making a big list of common errors and solutions that LLMs make when writing Squiggle code. Most of these were done at the prompt level, though we also added a bunch of regular expressions and formal code checks to detect common errors.
We haven’t set up formal evaluation systems yet, in large part because these can be complex and expensive to run. If we had an additional time and budget, we’d likely do more work here.