This is a special post for quick takes by yrimon. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Gpt5.2 seems to have been trained specifically to be better at work tasks, especially long ones. It was also released early, according to articles about a "code red" in openAI. As such, (I predict) it should be a jump on the metr graph. It will be difficult to differentiate progress because it was trained to do well at long work tasks from the results of the early release and from any actual algorithms progress. (An example of algorithms progress would be a training method for using memory well - something not specific to eg programming tasks.)
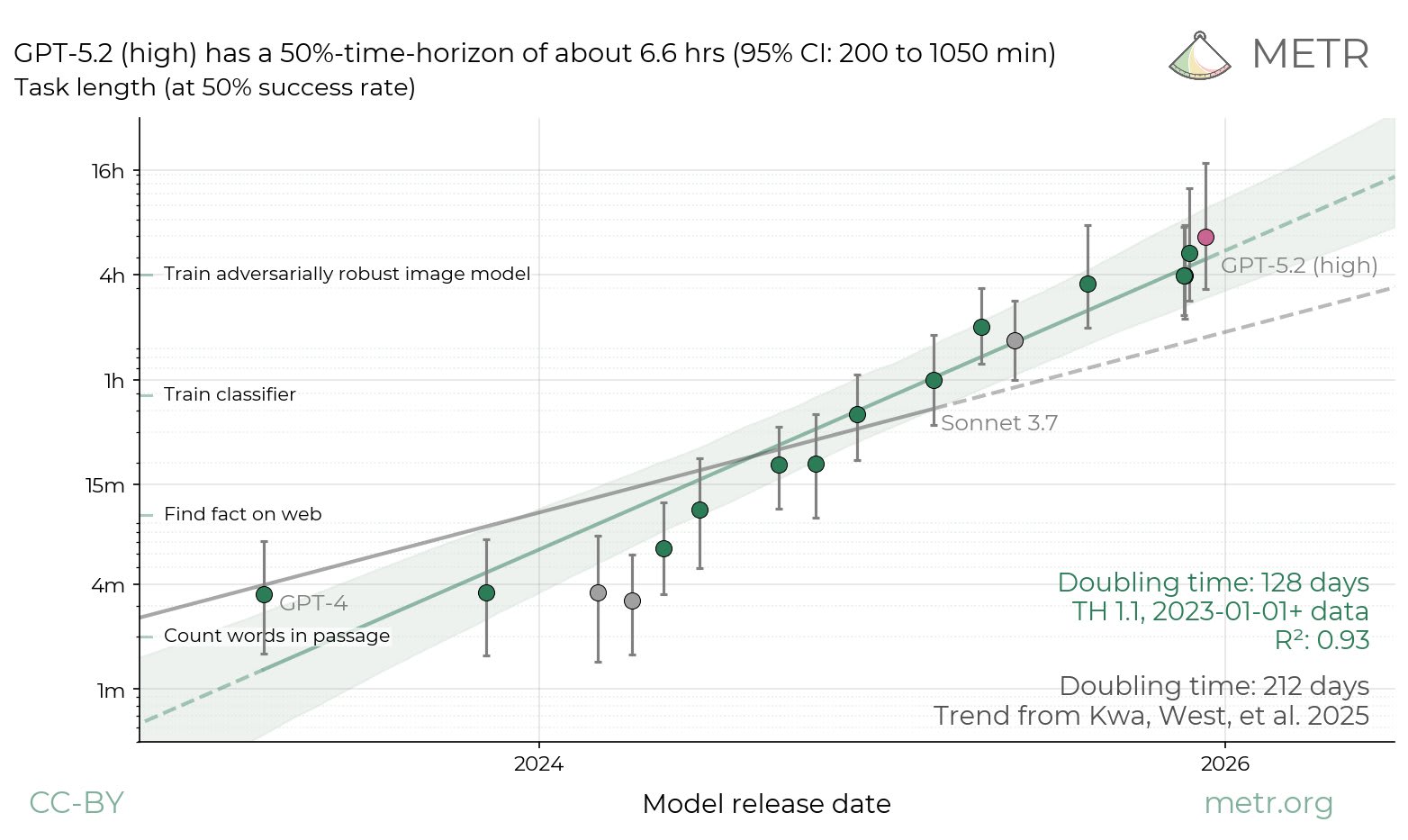
Gpt5.2 did in fact buck the trend from the previous graph. (The grey line on t is graph is the old trend line.)
Together with opus 4.5, gpt5.2 caused metr to enrich their task base, and changed doubling time on the graph from 213 or 212 days to 128 days.
The same logic as above suggests a regression to the mean regarding the next release: it should make doubling time go down a little. This is only if time horizons continue to be a reasonable measure of capability, which I doubt, as argued here.
Thank you Baybar for asking me to be specific. I should have been even more specific.
What do you mean by "a jump on the metr graph"? Do you just mean better than GPT-5.1? Do you mean something more than that?
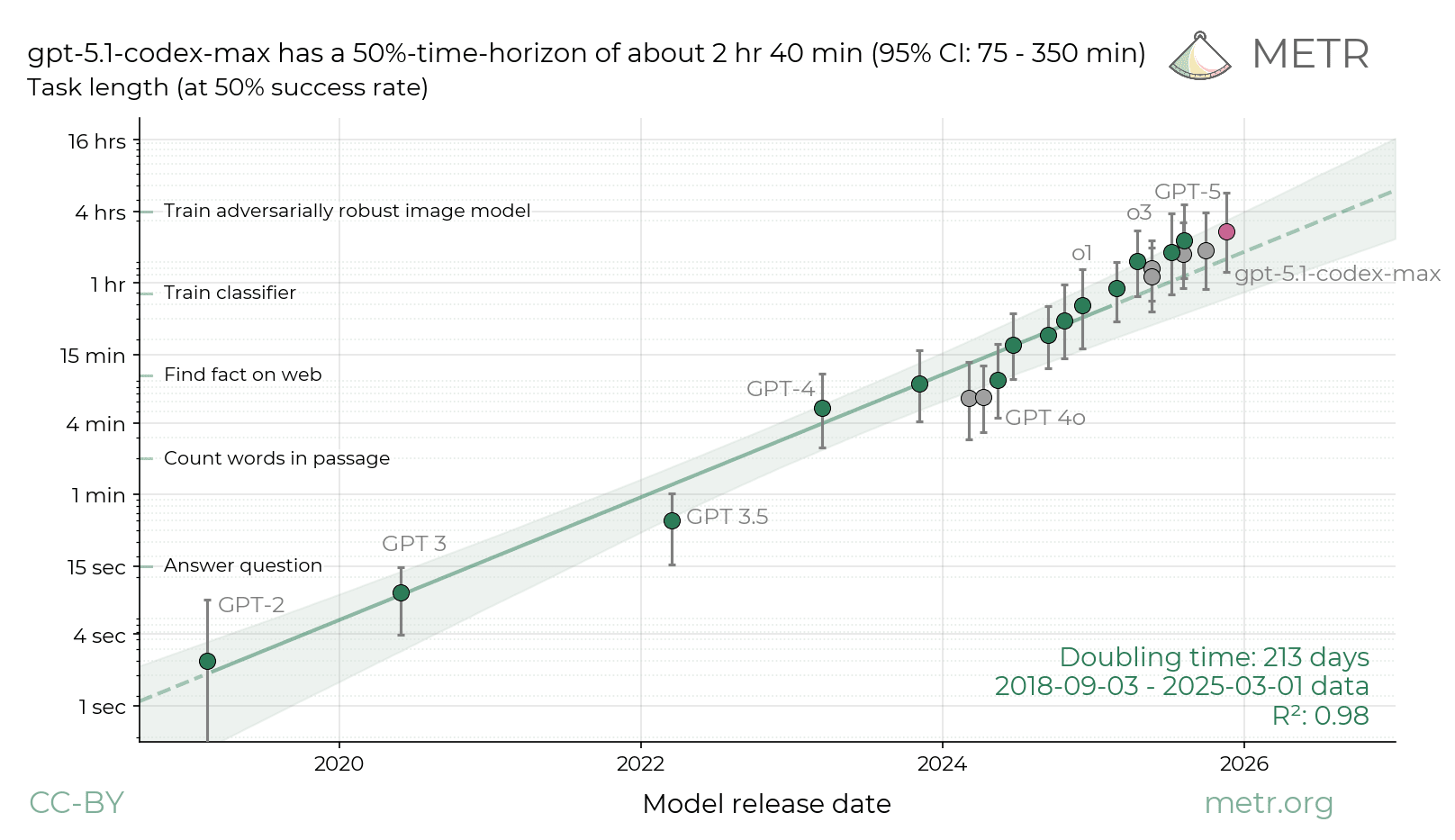
Here is the graph I'm talking about. Given that 5.1-codex max is already above the trend line, a jump would be a point outside the shaded area, that is bucking the de facto trend.
Humans get smarter by thinking. In particular they deduce correct conclusions from known premises or notice and resolve internal inconsistencies. As long as they are more likely to correct wrong things to right things than vice versa, they converge to being smarter.
AIs are close or at that level of ability, and as soon as it's taken advantage of, they will self improve really fast.
Yes. Current reasoning models like DeepSeek-R1 rely on verified math and coding data sets to calculate the reward signal for RL. It's only a side-effect if they also get better at other reasoning tasks, outside math and programming puzzles. But in theory we don't actually need strict verifiability for a reward signal, only your much weaker probabilistic condition. In the future, a model could check the goodness of it's own answers. At which point we would have a self-improving learning process, which doesn't need any external training data for RL.
And it is likely that such a probabilistic condition works on many informal tasks. We know that checking a result is usually easier than coming up with the result, even outside exact domains. E.g. it's much easier to recognize a good piece of art than to create one. This seems to be a fundamental fact about computation. It is perhaps a generalization of the apparent fact that NP problems (with quickly verifiable solutions) cannot in general be reduced to P problems (which are quickly solvable).
Just listened to the imo team at OpenAI talk about their model. https://youtu.be/EEIPtofVe2Q?si=kIPDW5d8Wjr2bTFD Some notes:
- The techniques they used are general, and especially useful for RL on hard-to-verify-solution-correctness problems.
- It now says when it doesn't know something, or didn't figure it out. This is a requisite for training the model successfully on its own output.
- The people behind the model are from the multi agent team. For one age to be bale to work with another, the reports from the other agent need to be trustworthy.
Yikes. If they're telling the truth about all this---particularly the "useful for RL on hard-to-verify-solution-correctness problems"---then this is all markedly timeline-shortening. What's the community consensus on how likely this is to be true?
I have no idea what the community consensus is. I doubt they're lying.
For anyone who already had short timelines this couldn't shorten them that much. For instance, 2027 or 2028 is very soon, and https://ai-2027.com/ assumed there would be successful research done along the way. So for me, very little more "yikes" than yesterday.
It does not seem to me like this is the last research breakthrough needed for full fledged agi, either. LLMs are superhuman at no/low context buildup tasks, but haven't solved context management (be that through long context windows, memory retrieval techniques, online learning or anything else).
I also don't think it's surprising that these research breakthroughs keep happening. Remember that their last breakthrough (strawberry, o1) was "make RL work". This one might be something like "make reward prediction and MCTS work" like mu zero, or some other banal thing that worked on toy cases in the 80s but was non trivial to reimplement in LLMs.
This is your periodic reminder that whether humans become extinct or merely unnecessary in a few years, right now you are at peak humanity and can do things for yourself and for other people that will not happen without you. There is a sense of meaning to having real stakes on the table, and the ability to affect change in the world - so do that now, before automation takes away the consequences of your inaction!
(In response to https://x.com/aryehazan/status/1995040629869682780)
whether humans become extinct or merely unnecessary
This is still certain doom. Nobody can decide for you what you decide yourself, so if humanity retains influence over the future, people would still need to decide what to do with it. Superintelligent AIs that can figure out what humanity would decide are no more substantially helping with those decisions than the laws of physics that carry out the movements of particles in human brains as they decide. If what AIs figure out about human decisions doesn't follow those decisions, then what the AIs figure out is not a legitimate prediction/extrapolation. The only way to establish such predictions is for humans to carry out the decision making on their own, in some way, in some form.
Edit: I attempt to maybe clarify this point in a new post.
I suspect the most significant advance exposed to the public this week is Claude plays pokémon. There, Claude maintains a notebook in which it logs its current state so that it will be able to reason over the state later.
This is akin to what I do when I'm exploring or trying to learn a topic. I spend a lot of time figur ng out and focusing on the most important bits of context that I need in order to understand the next step.
An internal notebook allows natural application of chain of thought to attention and allows natural continuous working memory. Up until now chain of thought would need to repeat itself to retain a thought in working memory across a long time scale. Now it can just put the facts that are most important to pay attention to into its notebook.
I suspect this makes thinking on a long time scale way more powerful and that future models will be optimized for internal use of such a tool.
Unfortunately, continuity is an obvious precursor to developing long-term goals.