Google just announced Gemini, and Hassabis claims that "in each of the 50 different subject areas that we tested it on, it's as good as the best expert humans in those areas"
State-of-the-art performance
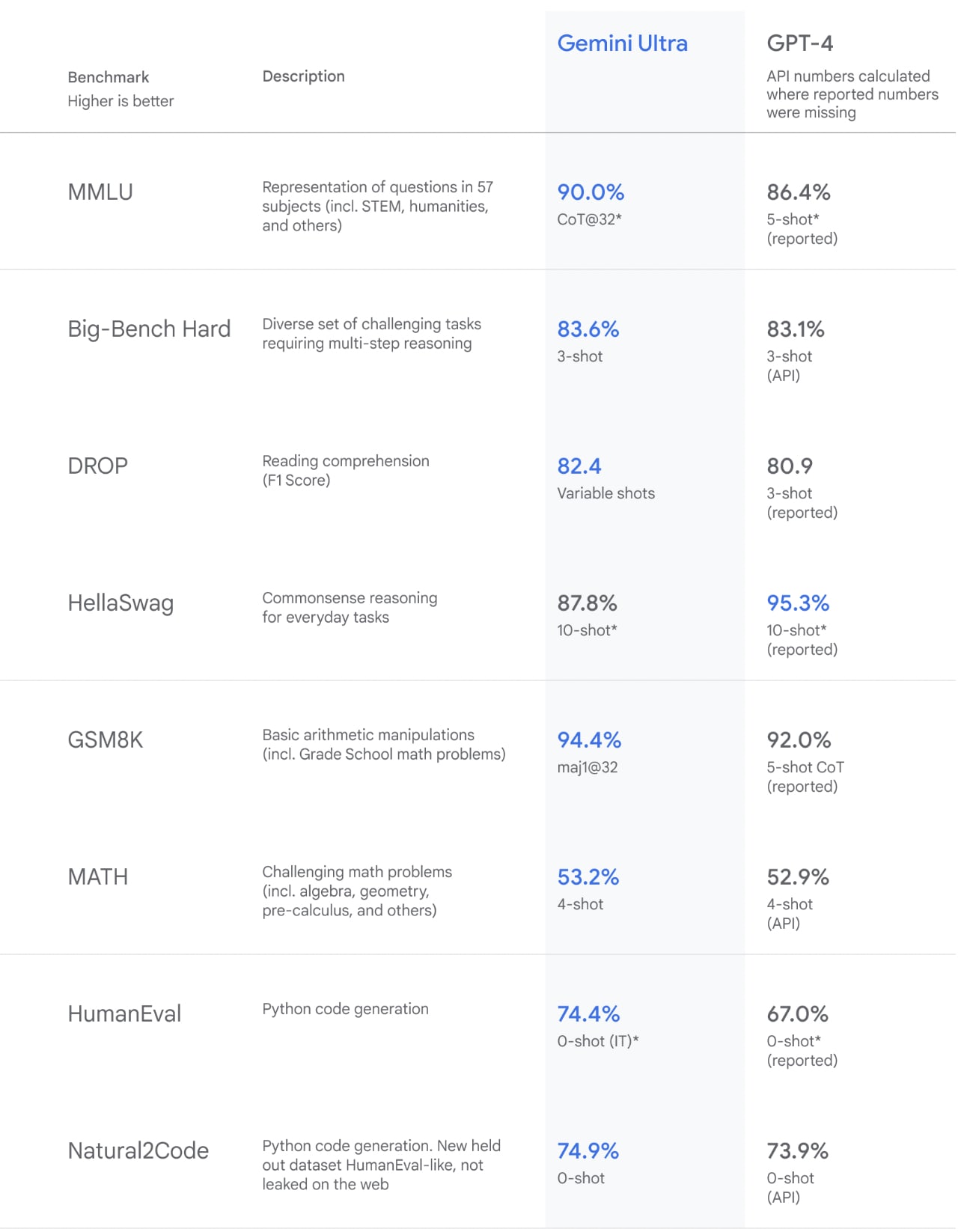
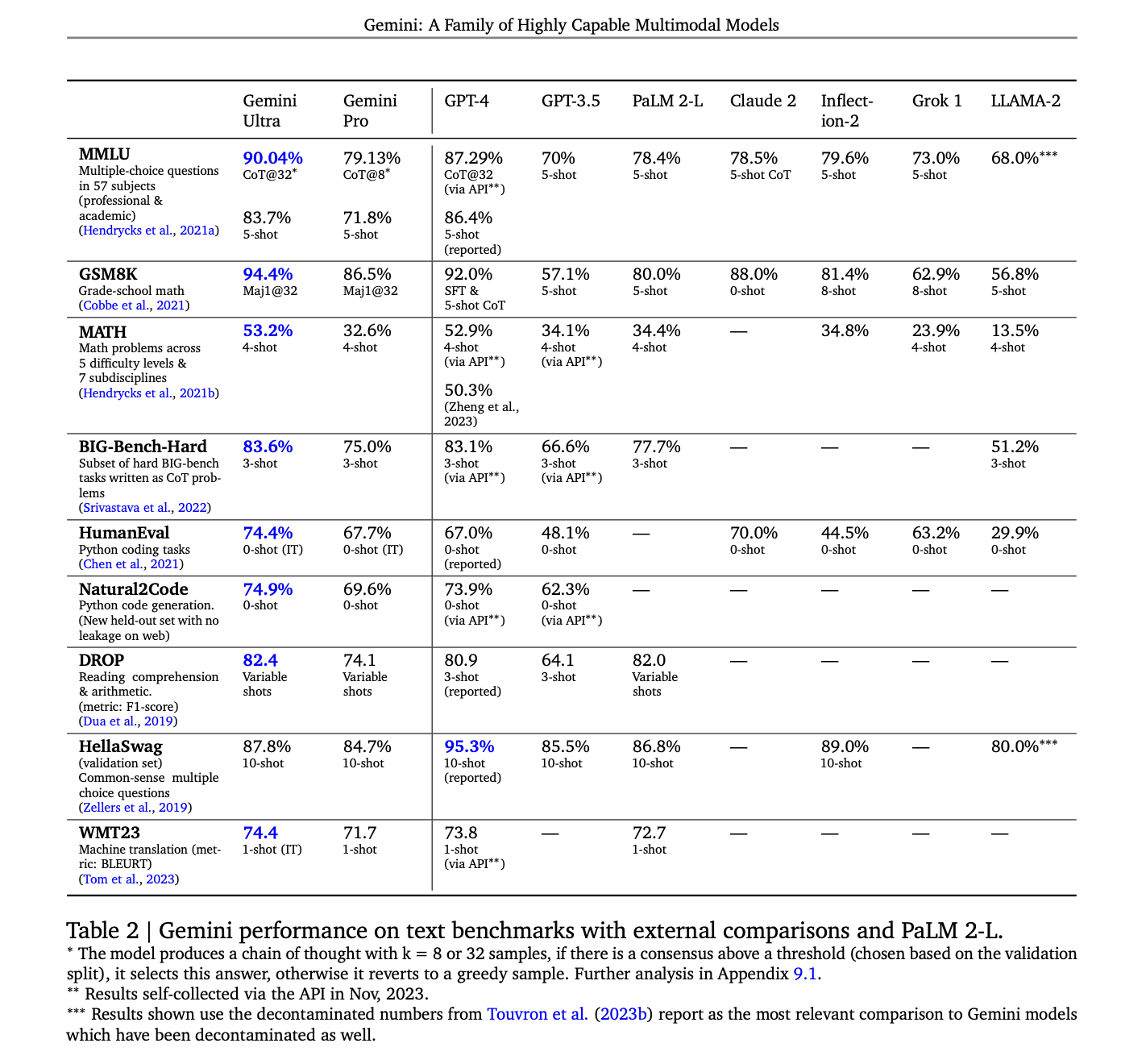
We've been rigorously testing our Gemini models and evaluating their performance on a wide variety of tasks. From natural image, audio and video understanding to mathematical reasoning, Gemini Ultra’s performance exceeds current state-of-the-art results on 30 of the 32 widely-used academic benchmarks used in large language model (LLM) research and development.
With a score of 90.0%, Gemini Ultra is the first model to outperform human experts on MMLU (massive multitask language understanding), which uses a combination of 57 subjects such as math, physics, history, law, medicine and ethics for testing both world knowledge and problem-solving abilities.
Our new benchmark approach to MMLU enables Gemini to use its reasoning capabilities to think more carefully before answering difficult questions, leading to significant improvements over just using its first impression.
It also seems like it can understand video, which is new for multimodal models (GPT-4 cannot do this currently).
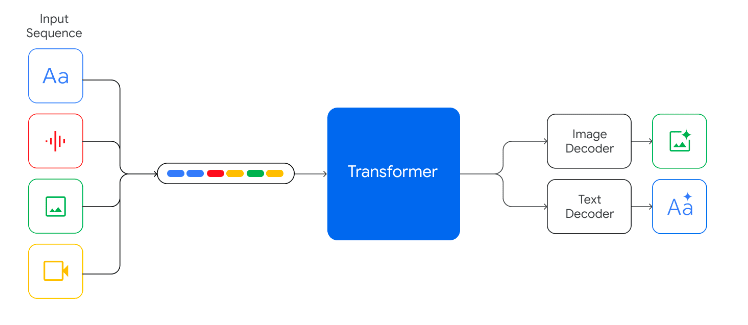
A sequence of still frames is a video, if the model was trained on ordered sequences of still frames crammed into the context window, as claimed by the technical report, then it understands video natively. And it would be surprising if it didn't also have some capability for generating video. I'm not sure why audio/video generation isn't mentioned, perhaps the performance in these arenas is not competitive with other models