This is a linkpost for https://blog.google/technology/ai/google-gemini-ai/
New Comment
https://storage.googleapis.com/deepmind-media/AlphaCode2/AlphaCode2_Tech_Report.pdf
AlphaCode 2, which is powered by Gemini Pro, seems like a big deal.
AlphaCode (Li et al., 2022) was the first AI system to perform at the level of the median competitor in competitive programming, a difficult reasoning task involving advanced maths, logic and computer science. This paper introduces AlphaCode 2, a new and enhanced system with massively improved performance, powered by Gemini (Gemini Team, Google, 2023). AlphaCode 2 relies on the combination of powerful language models and a bespoke search and reranking mechanism. When evaluated on the same platform as the original AlphaCode, we found that AlphaCode 2 solved 1.7× more problems, and performed better than 85% of competition participants.
Seems important for speeding up coders or even model self-improvement, unless competitive coding benchmarks are deceptive for actual applications for ML training.
From a short read, capabilities seem equal to gpt4. Alpha code 2 is also not penalized for its first 9 submissions, so I struggle to see how it can be compared to humans.
What led you to the "equal" conclusion over the "modest advance" hypothesis? The "beat gpt-4 by a small numerical ratio on all tasks but 1, and is natively multimodal" is what I read from the report.
That leads me to "modest advance", how did you interpret the report? Are you thinking the margins between the 2 models are too narrow and easily gamed?
Yes those margins are narrow and probably gamed. GPT4’s paper is from the base version and it has probably received modest capabilities upgrades since. Gemini also uses more advanced prompting tactics.
What do you think the compute investment was? They state they used multimodal inputs (more available tokens in the world) and 4096 processor tpuv5 nodes, but not how many or for how long.
I wonder why Gemini used RLHF instead of Direct Preference Optimization (DPO). DPO was written up 6 months ago; it's simpler and apparently more compute-efficient than RLHF.
- Is the Gemini org structure so sclerotic that it couldn't switch to a more efficient training algorithm partway through a project?
- Is DPO inferior to RLHF in some way? Lower quality, less efficient, more sensitive to hyperparameters?
- Maybe they did use DPO, even though they claimed it was RLHF in their technical report?
looks slightly behind gpt-4-base in benchmarks. On the tasks where gemini uses chain-of-thought best-of-32 with optimized prompts it beats gpt-4-base, but ones where it doesnt its same or behind
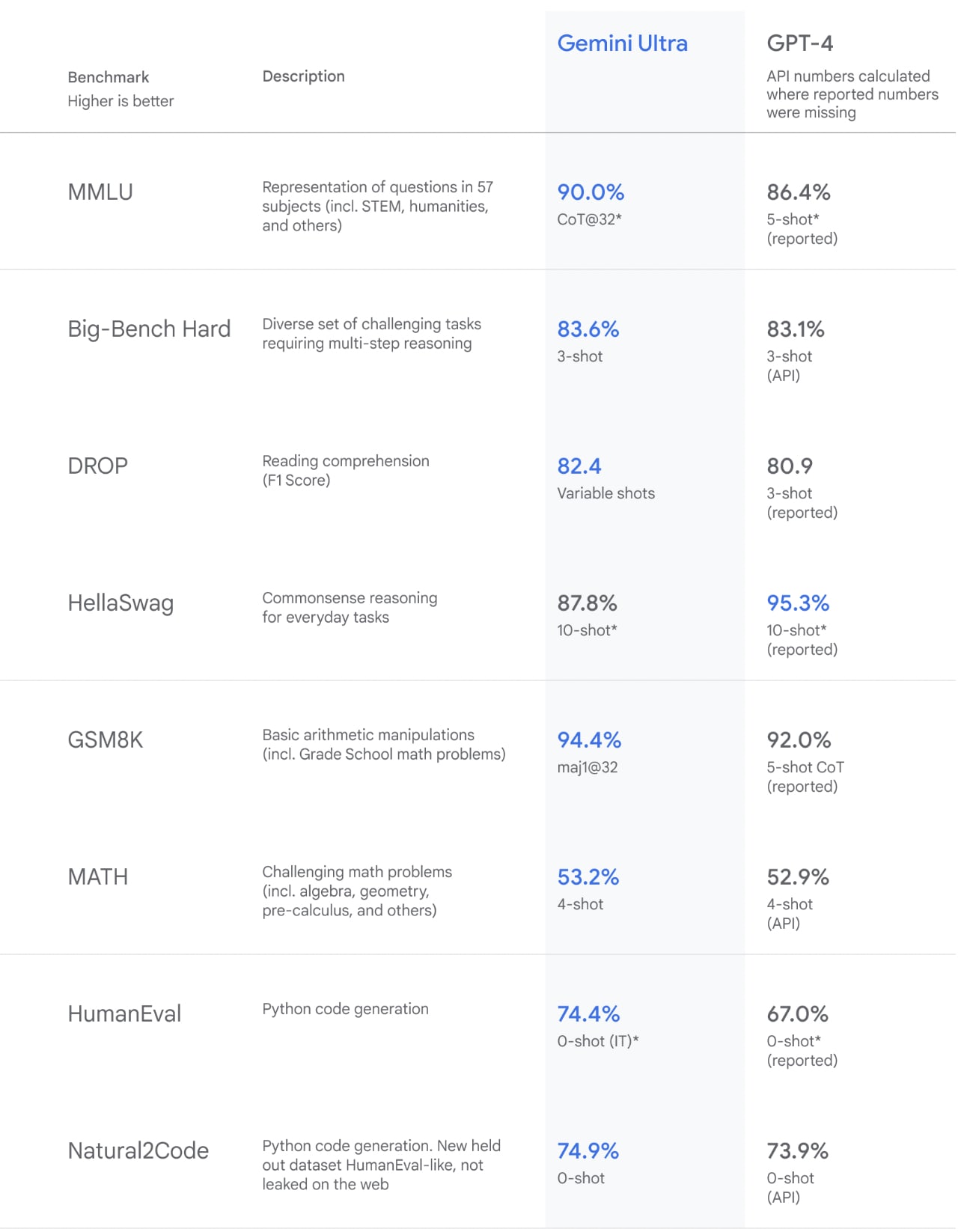
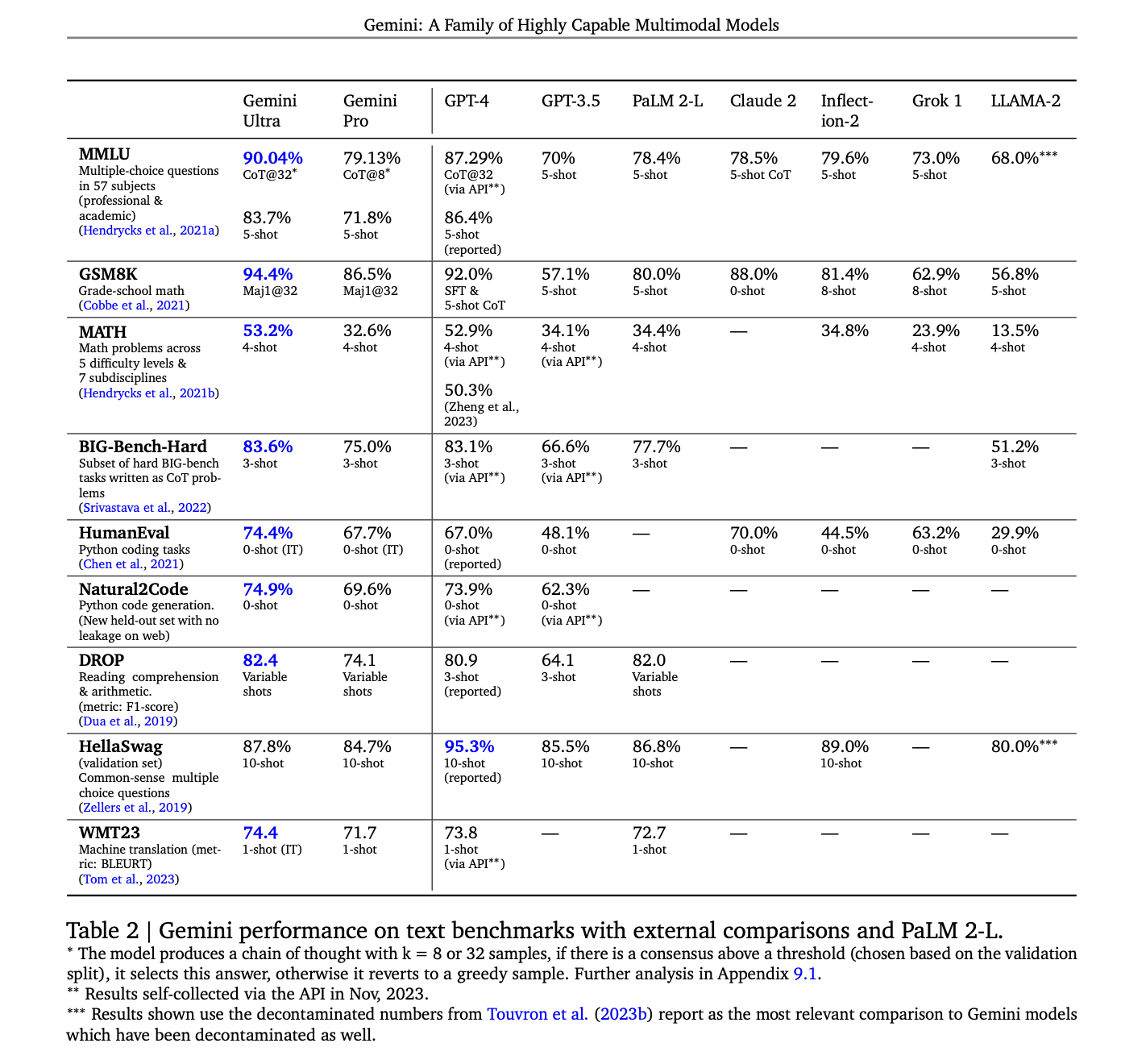
In particular, in the five tasks (MMLU, MATH, BIG-Bench, Natural2Code, WMT23) where they report going to the GPT-4 API, they report an average of ~1 point improvement. This experiment setting seems comparable, and not evidence they are underperforming GPT-4.
However, all these settings are different from how ChatGPT-like systems are mostly being used (where mostly zero-shot). So difficult to judge the success of their instruction-tuning for use in this setting.
(apologies if this point posted twice. Lesswrong was showing errors when tried to post.)
Update, it seems that the video generation capability is just accomplished by feeding still frames of the video into the model, not by any native video generation.
A sequence of still frames is a video, if the model was trained on ordered sequences of still frames crammed into the context window, as claimed by the technical report, then it understands video natively. And it would be surprising if it didn't also have some capability for generating video. I'm not sure why audio/video generation isn't mentioned, perhaps the performance in these arenas is not competitive with other models
Sure, but they only use 16 frames, which doesn't really seem like it's "video" to me.
Understanding video input is an important step towards a useful generalist agent. We measure the video understanding capability across several established benchmarks that are held-out from training. These tasks measure whether the model is able to understand and reason over a temporally-related sequence of frames. For each video task, we sample 16 equally-spaced frames from each video clip and feed them to the Gemini models. For the YouTube video datasets (all datasets except NextQA and the Perception test), we evaluate the Gemini models on videos that were still publicly available in the month of November, 2023
video can get extremely expensive without specific architectural support. Eg a folder of images takes up >10x the space of the equivalent video, and using eg 1000 tokens per frame for 30 frames/second is a lot of compute
in each of the 50 different subject areas that we tested it on, it's as good as the best expert humans in those areas
That sounds like an incredibly strong claim, but I suspect that the phrasing is very misleading. What kind of tests is Hassabis talking about here? Maybe those are tests that rely on remembering known facts much more than on making novel inferences? Surely Gemini is not (say) as good as the best mathematicians at solving open problems in mathematics?
The YouTube channel ai explained looked into this and what it means is that it scores better than human on matching the labels for "is correct answer" on MMLU multiple choice questions. Apparently that dataset is about 2% wrong answers anyway, so it's even worse than just the fact of only being multiple choice answers.
At first, I assumed that the demo video, which is also sped up, was in fact only using single frames, but there is a scene where the guy is shuffling three cups and Gemini correctly figures out where the coin went. So it seems it can do video - at least in the sense of using a sequence of frames.
I think the video is mostly faked as a sequence of things Gemini can kind of sort of do. In the blog post they do it with few shot prompting and 3 screenshots, and say gemini sometimes gets it wrong:
https://developers.googleblog.com/2023/12/how-its-made-gemini-multimodal-prompting.html?m=1
Progress on competitive coding seems impressive. Otherwise I am having trouble evaluating it, it seems slightly better than GPT-4 at most tasks, and multi-modal. Tentatively it seems to be significant progress.
The progress in competitive programming seems to be miscalculated in a way that makes Alpha Code 2 appear better than it is. It
- Samples 1e6 solutions
- Of all the solutions that pass the given test cases, it picks the 10 ones with the best "score"
- Submits up to 10 of the solutions until one of them passes
Steps 1 and 2 seem fine, but a human competitor in one of these contests would be penalized for step 3, which AlphaCode2 appears not to be[1]. Further the training set contamination combined with the fact that these are only "easier" div2 questions, imply that the solutions could very well appear in the test set and this just reconstructs that solution near verbatim.
In defense of AlphaCode 2, the fine-tuned scoring model that picks the 10 best might be a non trivial creation. It also seems. AC2 is more sample efficient than AC1, so it is getting better at generating solutions. Assuming nothing funky is happening with the training set, at the limit, this means 1 solution per sample.
- ^
Could be wrong, but if I am the paper should have made it more explicit
It seems to do something similar to Gato where everything is just serialized into tokens, which is pretty cool
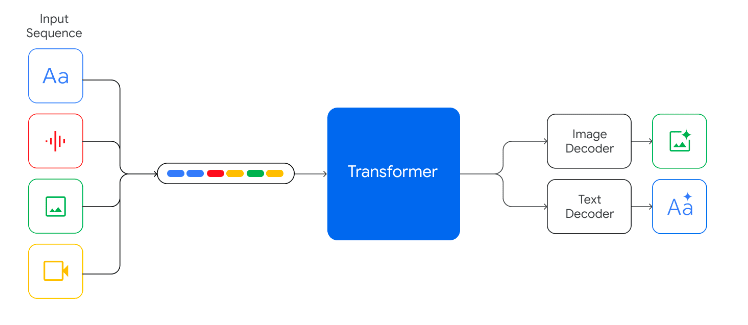
I wonder if they are just doing a standard transformer for everything, or doing some sort of diffusion model for the images inside the model?
What does it mean for perception to compress a frame of video to 1k tokens? What kind of information gets lost when you do this?
Google just announced Gemini, and Hassabis claims that "in each of the 50 different subject areas that we tested it on, it's as good as the best expert humans in those areas"
It also seems like it can understand video, which is new for multimodal models (GPT-4 cannot do this currently).