I have a lot of ideas about AGI/ASI safety. I've written them down in a paper and I'm sharing the paper here, hoping it can be helpful.
Title: A Comprehensive Solution for the Safety and Controllability of Artificial Superintelligence
Abstract:
As artificial intelligence technology rapidly advances, it is likely to implement Artificial General Intelligence (AGI) and Artificial Superintelligence (ASI) in the future. The highly intelligent ASI systems could be manipulated by malicious humans or independently evolve goals misaligned with human interests, potentially leading to severe harm or even human extinction. To mitigate the risks posed by ASI, it is imperative that we implement measures to ensure its safety and controllability. This paper analyzes the intellectual characteristics of ASI, and three conditions for ASI to cause catastrophes (harmful goals, concealed intentions, and strong power), and proposes a comprehensive safety solution. The solution includes three risk prevention strategies (AI alignment, AI monitoring, and power security) to eliminate the three conditions for AI to cause catastrophes. It also includes four power balancing strategies (decentralizing AI power, decentralizing human power, restricting AI development, and enhancing human intelligence) to ensure equilibrium between AI to AI, AI to human, and human to human, building a stable and safe society with human-AI coexistence. Based on these strategies, this paper proposes 11 major categories, encompassing a total of 47 specific safety measures. For each safety measure, detailed methods are designed, and an evaluation of its benefit, cost, and resistance to implementation is conducted, providing corresponding priorities. Furthermore, to ensure effective execution of these safety measures, a governance system is proposed, encompassing international, national, and societal governance, ensuring coordinated global efforts and effective implementation of these safety measures within nations and organizations, building safe and controllable AI systems which bring benefits to humanity rather than catastrophes.
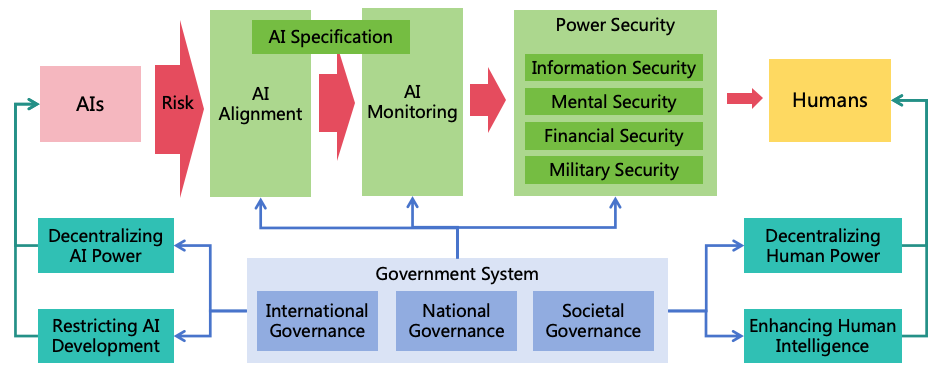
Content:
The paper is quite long, with over 100 pages. So I can only put a link here. If you're interested, you can visit this link to download the PDF: https://www.preprints.org/manuscript/202412.1418/v1
or you can read the online HTML version at this link:
I didn't read the 100 pages, but the content seems extremely intelligent and logical. I really like the illustrations, they are awesome.
A few questions.
1: In your opinion, which idea in your paper is the most important, most new (not already focused on by others), and most affordable (can work without needing huge improvements in political will for AI safety)?
2: The paper suggests preventing AI from self-iteration, or recursive self improvement. My worry is that once many countries (or companies) have access to AI which are far better and faster than humans at AI research, each one will be tempted to allow a very rapid self improvement cycle.
Each country might fear that if it doesn't allow it, one of the other countries will, and that country's AI will be so intelligent it can engineer self replicating nanobots which take over the world. This motivates each country to allow the recursive self improvement, even if the AI's methods of AI development become so advanced they are inscrutable by human minds.
How can we prevent this?
Edit: sorry I didn't read the paper. But when I skimmed it you did have a section on "AI Safety Governance System," and talked about an international organization to get countries to do the right thing. I guess one question is, why would an international system succeed in AI safety, when current international systems have so far failed to prevent countries from acting selfishly in ways which severely harms other countries (e.g. all wars, exploitation, etc.)?
Thank you for your advice!