Today, we're announcing the Claude 3 model family, which sets new industry benchmarks across a wide range of cognitive tasks. The family includes three state-of-the-art models in ascending order of capability: Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus. Each successive model offers increasingly powerful performance, allowing users to select the optimal balance of intelligence, speed, and cost for their specific application.
Better performance than GPT-4 on many benchmarks
The largest Claude 3 model seems to outperform GPT-4 on benchmarks (though note slight differences in evaluation methods):
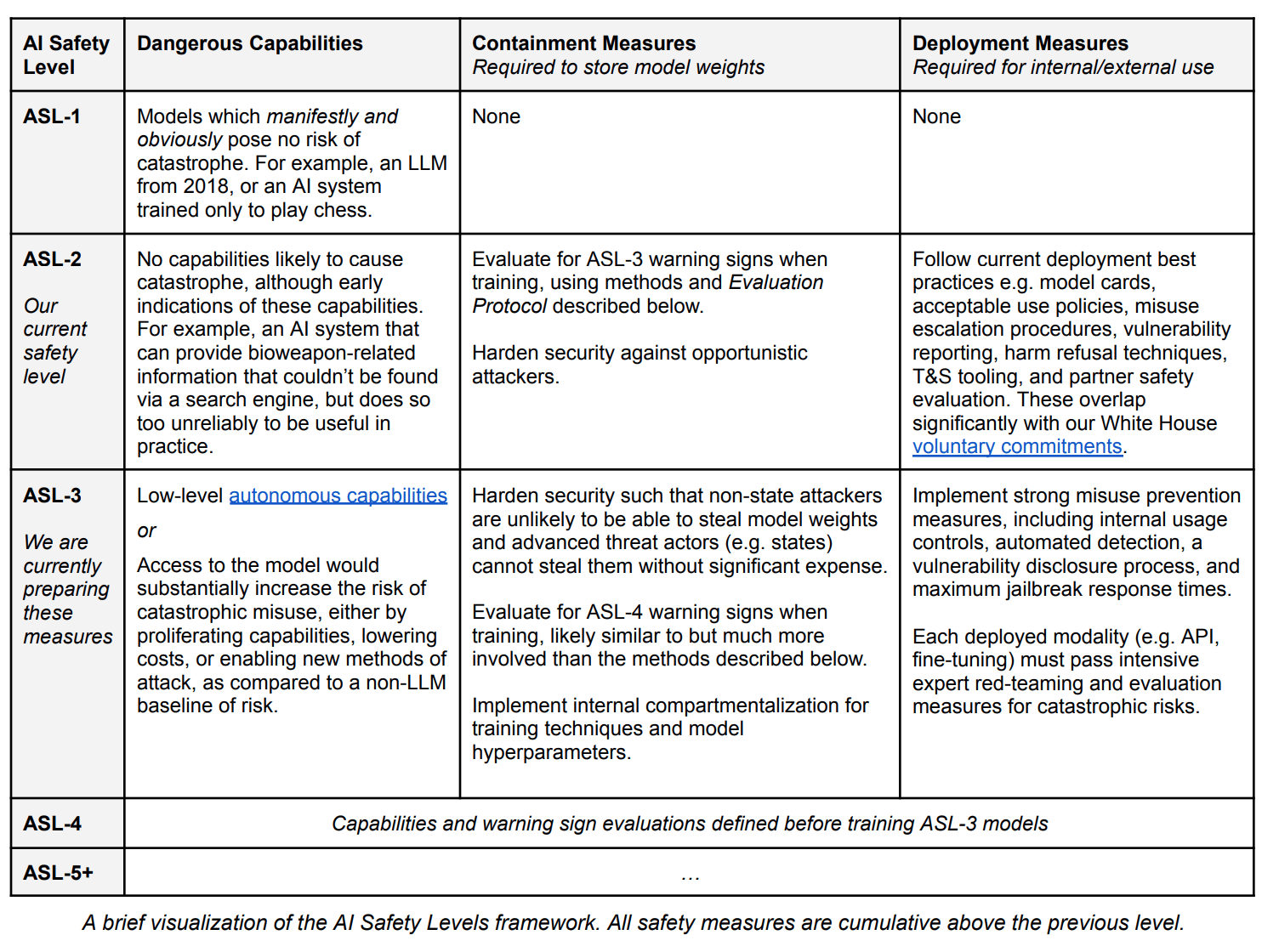
Opus, our most intelligent model, outperforms its peers on most of the common evaluation benchmarks for AI systems, including undergraduate level expert knowledge (MMLU), graduate level expert reasoning (GPQA), basic mathematics (GSM8K), and more. It exhibits near-human levels of comprehension and fluency on complex tasks, leading the frontier of general intelligence.
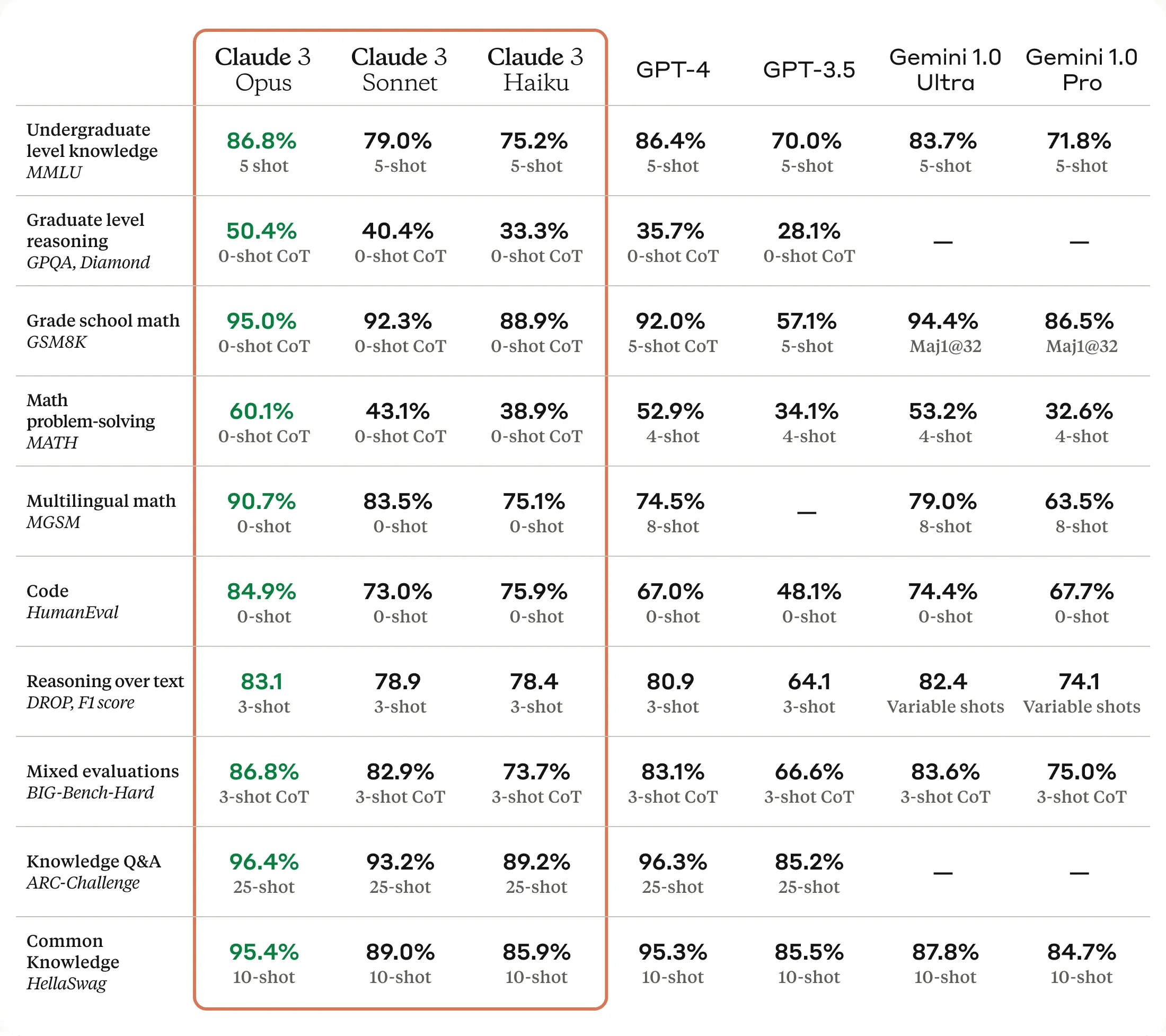
Important Caveat: With the exception of GPQA, this is comparing against gpt-4-0314 (the original public version of GPT-4), and not either of the GPT-4-Turbo models (gpt-4-1106-preview, gpt-4-0125-preview). The GPT-4 entry for GPQA is gpt-4-0613, which performs significantly better than -0314 on benchmarks. Where the data exists, gpt-4-1106-preview consistently outperforms Claude 3 Opus. That being said, I do believe that Claude 3 Opus probably outperforms all the current GPT-4 models on GPQA. Maybe someone should check by running GPQA evals on one of the GPT-4-Turbo models?
Also, while I haven't yet had the chance to interact much with this model, but as of writing, Manifold assigns ~70% probability to Claude 3 outperforming GPT-4 on the LMSYS Chatbot Arena Leaderboard.
https://manifold.markets/JonasVollmer/will-claude-3-outrank-gpt4-on-the-l?r=Sm9uYXNWb2xsbWVy
Synthetic data?
According to Anthropic, Claude 3 was trained on synthetic data (though it was not trained on any customer-generated data from previous models):

Also interesting that the model can identify the synthetic nature of some of its evaluation tasks. For example, it provides the following response to a synthetic recall text:

Is Anthropic pushing the frontier of AI development?
Several people have pointed out that this post seems to take a different stance on race dynamics than was expressed previously:
As we push the boundaries of AI capabilities, we’re equally committed to ensuring that our safety guardrails keep apace with these leaps in performance. Our hypothesis is that being at the frontier of AI development is the most effective way to steer its trajectory towards positive societal outcomes.
EDIT: Lukas Finnveden pointed out that they included a footnote in the blog post caveating their numbers:
- This table shows comparisons to models currently available commercially that have released evals. Our model card shows comparisons to models that have been announced but not yet released, such as Gemini 1.5 Pro. In addition, we’d like to note that engineers have worked to optimize prompts and few-shot samples for evaluations and reported higher scores for a newer GPT-4T model. Source.
And indeed, from the linked Github repo, gpt-4-1106-preview still seems to outperform Claude 3:
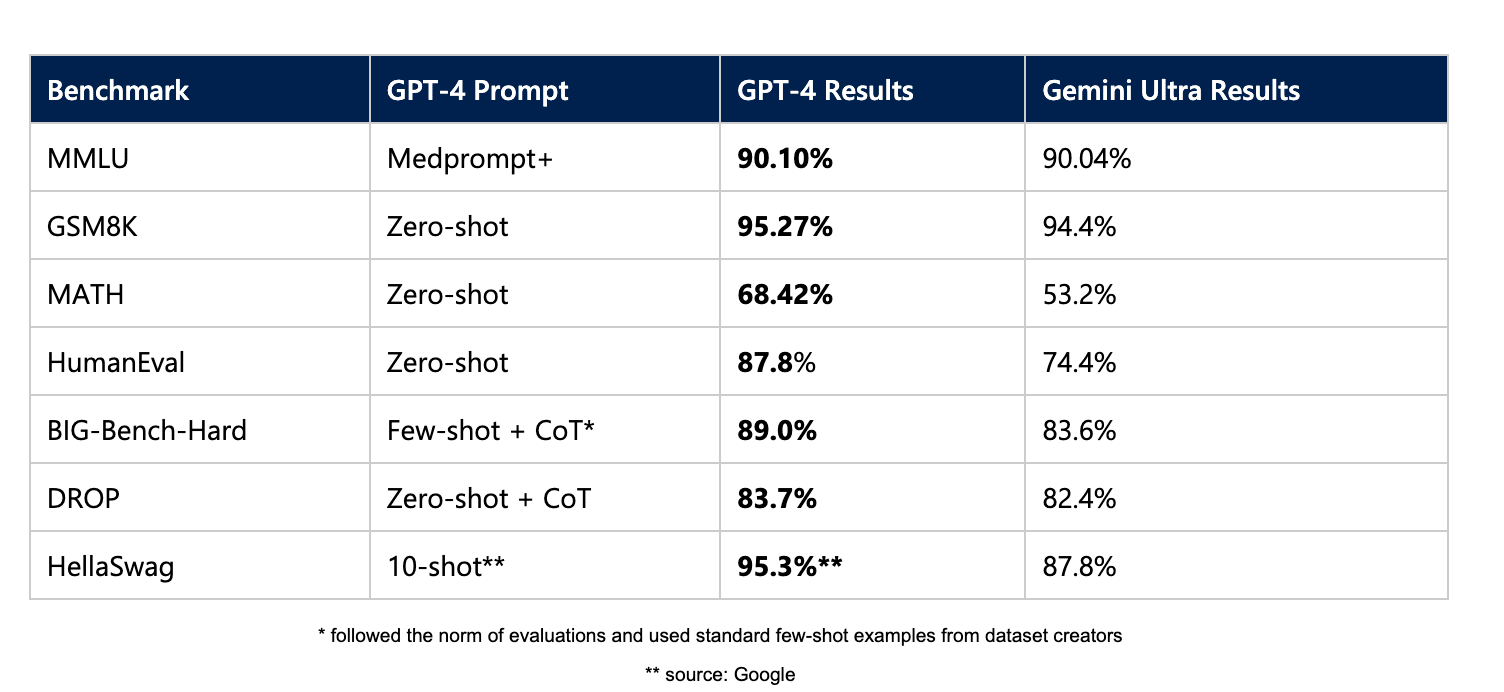
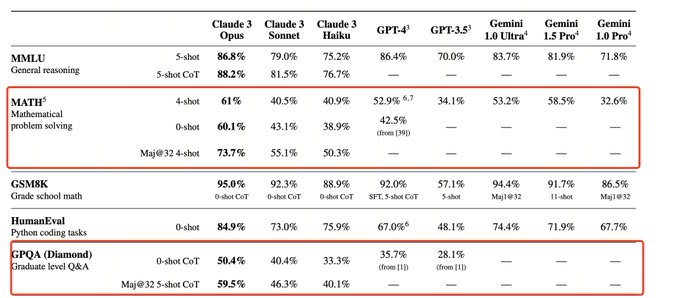
Ignoring the MMLU results, which use a fancy prompting strategy that Anthropic presumably did not use for their evals, Claude 3 gets 95.0% on GSM8K, 60.1% on MATH, 84.9% on HumanEval, 86.8% on Big Bench Hard, 93.1 F1 on DROP, and 95.4% on HellaSwag. So Claude 3 is arguably not pushing the frontier on LLM development.
EDIT2: I've compiled the benchmark numbers for all models with known versions:
On every benchmark where both were evaluated, gpt-4-1106 outperforms Claude 3 Opus. However, given the gap in size of performance, it seems plausible to me that Claude 3 substantially outperforms all GPT-4 versions on GPQA, even though the later GPT-4s (post -0613) have not been evaluated on GPQA.
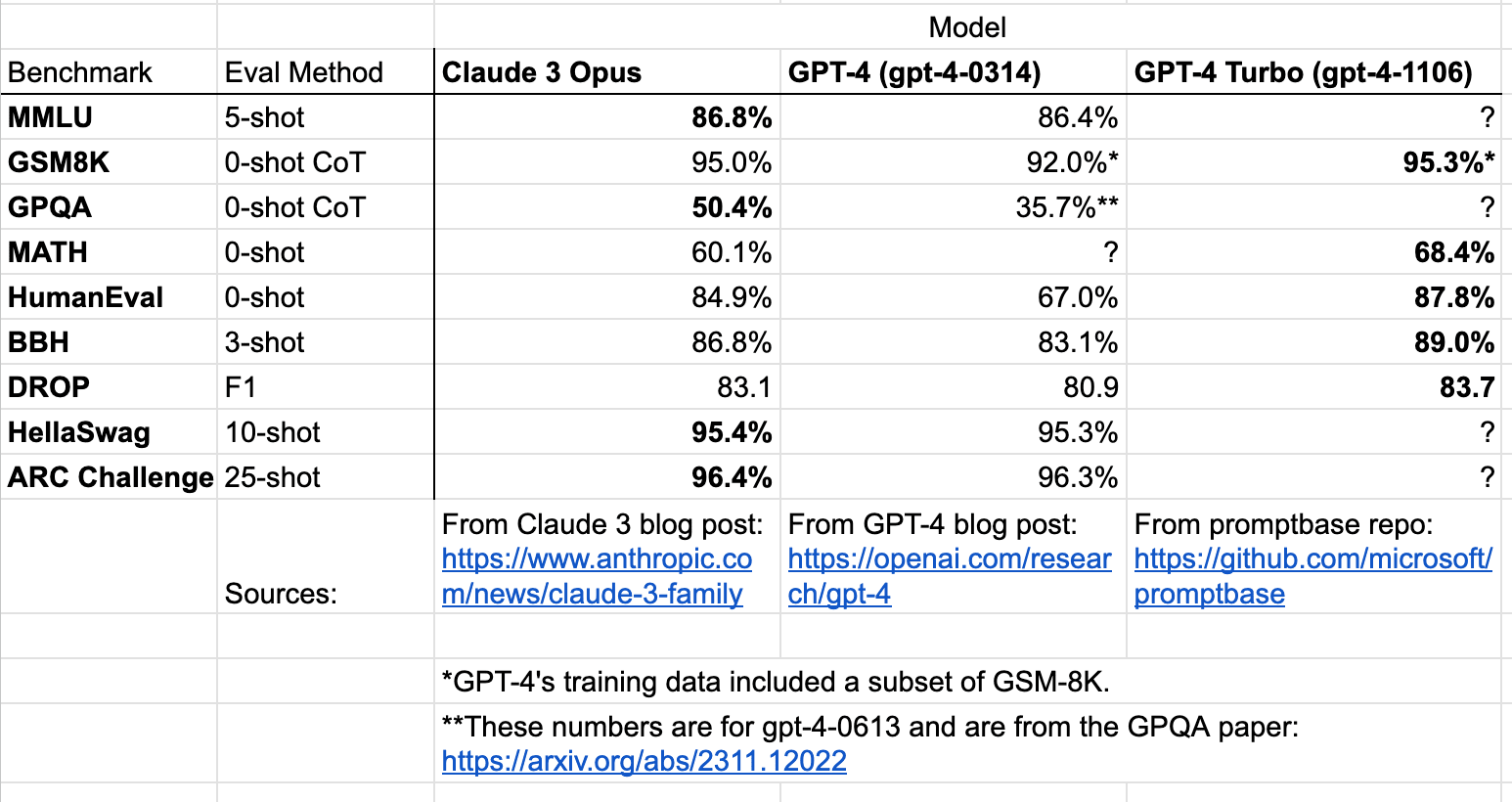
That being said, I'd encourage people to take the benchmark numbers with a pinch of salt.
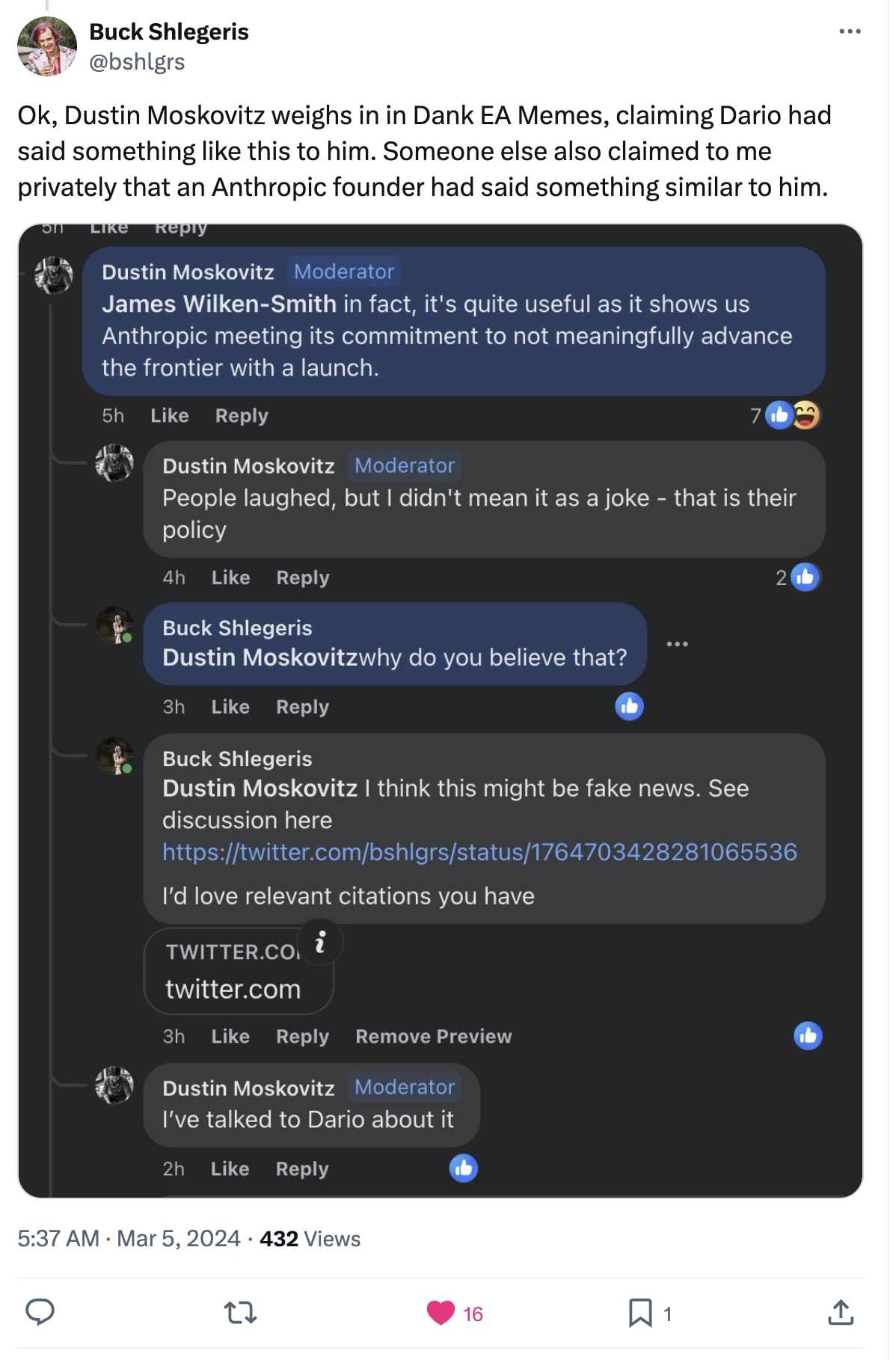
I think it clearly does. From my perspective, Anthropic's post is misleading either way—either Claude 3 doesn’t outperform its peers, in which case claiming otherwise is misleading, or they are in fact pushing the frontier, in which case they’ve misled people by suggesting that they would not do this.
Also, “We do not believe that model intelligence is anywhere near its limits, and we plan to release frequent updates to the Claude 3 model family over the next few months” doesn’t inspire much confidence that they’re not trying to surpass other models in the near future.
In any case, I don’t see much reason to think that Anthropic is not aiming to push the frontier. For one, to the best of my knowledge they’ve never even publicly stated they wouldn’t; to the extent that people believe it anyway, it is, as best I can tell, mostly just through word of mouth and some vague statements from Dario. Second, it’s hard for me to imagine that they’re pitching investors on a plan that explicitly aims to make an inferior product relative to their competitors. Indeed, their leaked pitch deck suggests otherwise: “We believe that companies that train the best 2025/26 models will be too far ahead for anyone to catch up in subsequent cycles.” I think the most straightforward interpretation of this sentence is that Anthropic is racing to build AGI.
And if they are indeed pushing the frontier, this seems like a negative update about them holding to other commitments about safety. Because while it’s true that Anthropic never, to the best of my knowledge, explicitly stated that they wouldn’t do so, they nevertheless appeared to me to strongly imply it. E.g., in his podcast with Dwarkesh, Dario says:
And Dario on an FLI podcast:
None of this is Dario saying that Anthropic won’t try to push the frontier, but it certainly heavily suggests that they are aiming to remain at least slightly behind it. And indeed, my impression is that many people expected this from Anthropic, including people who work there, which seems like evidence that this was the implied message.
If Anthropic is in fact attempting to push the frontier, then I think this is pretty bad. They shouldn't be this vague and misleading about something this important, especially in a way that caused many people to socially support them (and perhaps make decisions to work there). I perhaps cynically think this vagueness was intentional—it seems implausible to me that Anthropic did not know that people believed this yet they never tried to correct it, which I would guess benefited them: safety-conscious engineers are more likely to work somewhere that they believe isn’t racing to build AGI. Hopefully I’m wrong about at least some of this.
In any case, whether or not Claude 3 already surpasses the frontier, soon will, or doesn’t, I request that Anthropic explicitly clarify whether their intention is to push the frontier.
I feel some kinda missing mood in these comments. It seems like you're saying "Anthropic didn't make explicit commitments here", and that you're not weighting as particularly important whether they gave people different impressions, or benefited from that.
(AFAICT you haven't explicitly stated "that's not a big deal", but, it's the vibe I get from your comments. Is that something you're intentionally implying, or do you think of yourself as mostly just trying to be clear on the factual claims, or something like that?)