Background 1: Preferences-over-future-states (a.k.a. consequentialism) vs Preferences-over-trajectories other kinds of preferences
(Note: The original version of this post said "preferences over trajectories" all over the place. Commenters were confused about what I meant by that, so I have switched the terminology to "any other kind of preference" which is hopefully clearer.)
The post Coherent decisions imply consistent utilities (Eliezer Yudkowsky, 2017) explains how, if an agent has preferences over future states of the world, they should act like a utility-maximizer (with utility function defined over future states of the world). If they don’t act that way, they will be less effective at satisfying their own preferences; they would be “leaving money on the table” by their own reckoning. And there are externally-visible signs of agents being suboptimal in that sense; I'll go over an example in a second.
By contrast, the post Coherence arguments do not entail goal-directed behavior (Rohin Shah, 2018) notes that, if an agent has preferences over universe-histories, and acts optimally with respect to those preferences (acts as a utility-maximizer whose utility function is defined over universe-histories), then they can display any external behavior whatsoever. In other words, there's no externally-visible behavioral pattern which we can point to and say "That's a sure sign that this agent is behaving suboptimally, with respect to their own preferences.".
For example, the first (Yudkowsky) post mentions a hypothetical person at a restaurant. When they have an onion pizza, they’ll happily pay $0.01 to trade it for a pineapple pizza. When they have a pineapple pizza, they’ll happily pay $0.01 to trade it for a mushroom pizza. When they have a mushroom pizza, they’ll happily pay $0.01 to trade it for a pineapple pizza. The person goes around and around, wasting their money in a self-defeating way (a.k.a. “getting money-pumped”).
That post describes the person as behaving sub-optimally. But if you read carefully, the author sneaks in a critical background assumption: the person in question has preferences about what pizza they wind up eating, and they’re making these decisions based on those preferences. But what if they don’t? What if the person has no preference whatsoever about pizza? What if instead they’re an asshole restaurant customer who derives pure joy from making the waiter run back and forth to the kitchen?! Then we can look at the same behavior, and we wouldn’t describe it as self-defeating “getting money-pumped”, instead we would describe it as the skillful satisfaction of the person’s own preferences! They’re buying cheap entertainment! So that would be an example of preferences-not-concerning-future-states.
To be more concrete, if I’m deciding between two possible courses of action, A and B, “preference over future states” would make the decision based on the state of the world after I finish the course of action—or more centrally, long after I finish the course of action. By contrast, “other kinds of preferences” would allow the decision to depend on anything, even including what happens during the course-of-action.
(Edit to add: There are very good reasons to expect future powerful AGIs to act according to preferences over distant-future states, and I join Eliezer in roundly criticizing people who think we can build an AGI that never does that; see this comment for discussion.)
Background 2: Corrigibility is a square peg, preferences-over-future-states is a round hole
A “corrigible” AI is an AI for which you can shut it off (or more generally change its goals), and it doesn’t try to stop you. It also doesn’t deactivate its own shutoff switch, and it even fixes the switch if it breaks. Nor does it have preferences in the opposite direction: it doesn’t try to press the switch itself, and it doesn’t try to persuade you to press the switch. (Note: I’m using the term “corrigible” here in the narrow MIRI sense, not the stronger and vaguer Paul Christiano sense)
As far as I understand, there was some work in the 2010s on trying to construct a utility function (over future states) that would result in an AI with all those properties. This is not an easy problem. In fact, it’s not even clear that it’s possible! See Nate Soares google talk in 2017 for a user-friendly introduction to this subfield, referencing two papers (1,2). The latter, from 2015, has some technical details, and includes a discussion of Stuart Armstrong’s “indifference” method. I believe the “indifference” method represented some progress towards a corrigible utility-function-over-future-states, but not a complete solution (apparently it’s not reflectively consistent—i.e., if the off-switch breaks, it wouldn't fix it), and the problem remains open to this day.
(Edit to add: A commenter points out that the "indifference" method uses a utility function that is not over future states. Uncoincidentally, one of the advantages of preferences-over-future-states is that they have reflective consistency. However, I will argue shortly that we can get reflective consistency in other ways.)
Also related is The Problem of Fully-Updated Deference: Naively you might expect to get corrigibility if your AI’s preferences are something like “I, the AI, prefer whatever future states that my human overseer would prefer”. But that doesn’t really work. Instead of acting corrigibly, you might find that your AI resists shutdown, kills you and disassembles your brain to fully understand your preferences over future states, and then proceeds to create whatever those preferred future states are.
See also Eliezer Yudkowsky discussing the "anti-naturalness" of corrigibility in conversation with Paul Christiano here, and with Richard Ngo here. My impression is that, in these links, Yudkowsky is suggesting that powerful AGIs will purely have preferences over future states.
My corrigibility proposal sketch
Maybe I’m being thickheaded, but I’m just skeptical of this whole enterprise. I’m tempted to declare that “preferences purely over future states” are just fundamentally counter to corrigibility. When I think of “being able to turn off the AI when we want to”, I see it as not a future-state-kind-of-thing. And if we humans in fact have some preferences that are not about future states, then it’s folly for us to build AIs that purely have preferences over future states.
So, here’s my (obviously-stripped-down) proposal for a corrigible paperclip maximizer:
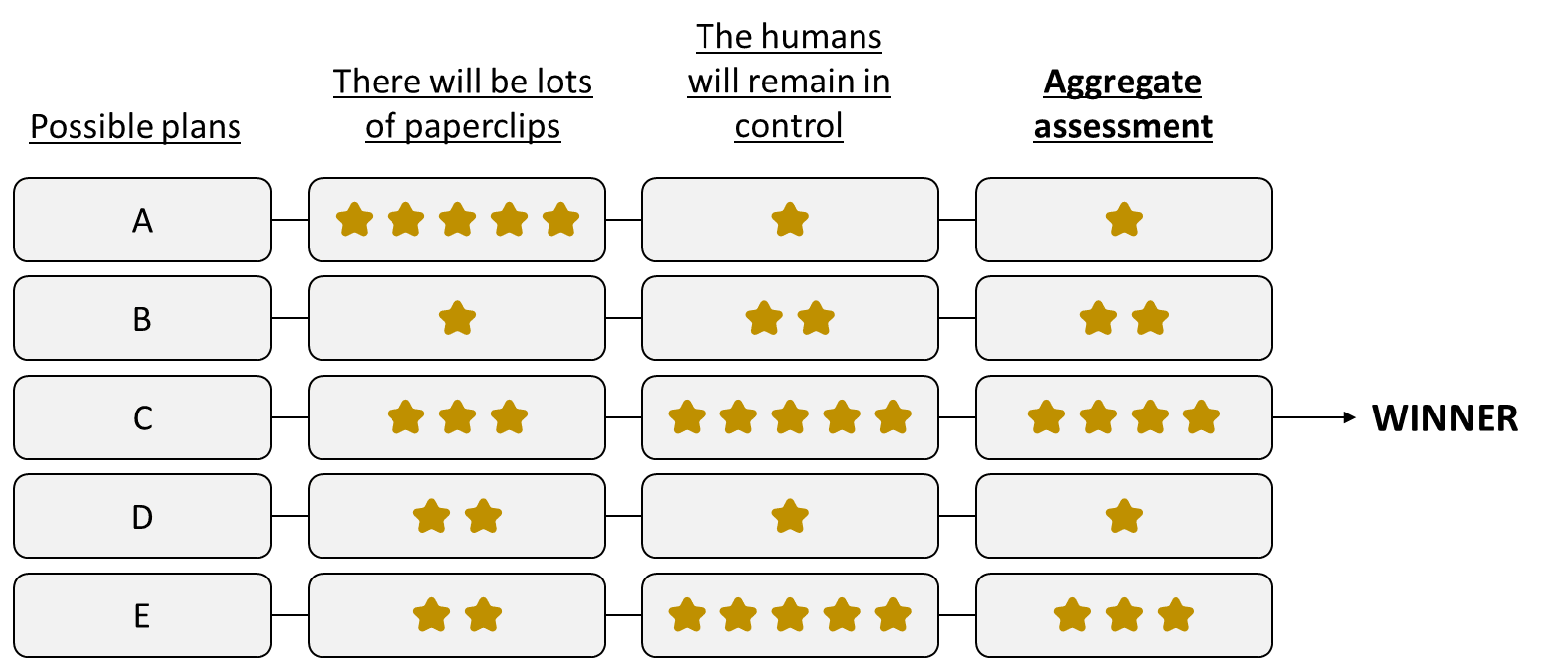
The AI considers different possible plans (a.k.a. time-extended courses of action). For each plan:
- It assesses how well this plan pattern-matches to the concept “there will ultimately be lots of paperclips in the universe”,
- It assesses how well this plan pattern-matches to the concept “the humans will remain in control”
- It combines these two assessments (e.g. weighted average or something more complicated) to pick a winning plan which scores well on both. [somewhat-related link]
Note that “the humans will remain in control” is a concept that can’t be distilled into a ranking of future states, i.e. states of the world at some future time long after the plan is complete. (See this comment for elaboration. E.g. contrast that with “the humans will ultimately wind up in control”, which can be achieved by disempowering the humans now and then re-empowering them much later.) Human world-model concepts are very often like that! For example, pause for a second and think about the human concept of “going to the football game”. It’s a big bundle of associations containing immediate actions, and future actions, and semantic context, and expectations of what will happen while we’re doing it, and expectations of what will result after we finish doing it, etc. etc. We humans are perfectly capable of pattern-matching to these kinds of time-extended concepts, and I happen to expect that future AGIs will be as well.
By contrast, “there will be lots of paperclips” can be distilled into a ranking of future states.
There’s a lesson here: I claim that consequentialism is not all-or-nothing. We can build agents that have preferences about future states and have preferences about other things, just as humans do.
Possible objections
Objection 1: How exactly does the AI learn these two abstract concepts? What happens in weird out-of-distribution situations where the concepts break down?
Just like humans, the AI can learn abstract concepts by reading books or watching YouTube or whatever. Presumably this would involve predictive (self-supervised) learning, and maybe other things too. And just like humans, the AI can do out-of-distribution detection by looking at how the web of associations defining the concept get out-of-sync with each other. I didn’t draw any out-of-distribution handling system in the above diagram, but we can imagine that the AI detects plans that go into weird places where its preferred concepts break down, and either subtracts points from them, or (somehow) queries the human for clarification. (Related posts: model splintering and alignment by default.)
Maybe it sounds like I’m brushing off this question. I actually think this is a very important and hard and open question. I don’t pretend for a second that the previous paragraph has answered it. I’ll have more to say about it in future posts. But I don’t currently know any argument that it’s a fundamental problem that dooms this whole approach. I think that’s an open question.
Relatedly, I wouldn’t bet my life that the abstract concept of “the humans remain in control” is exactly the thing we want, even if that concept can be learned properly. Maybe we want the conjunction of several abstract concepts? “I’m being helpful” / “I’m behaving in a way that my programmers intended” also seems promising. (The latter AI would presumably satisfy the stronger notion of Paul-corrigibility, not just the weaker notion of MIRI-corrigibility.) Anyway, this is another vexing open question that’s way beyond the scope of this post.
Objection 2: What if the AI self-modifies to stop being corrigible? What if it builds a non-corrigible successor?
Presumably a sufficiently capable AI would self-modify to stop being corrigible because it planned to, and such a plan would certainly score very poorly on its “the humans will remain in control” assessment. So the plan would get a bad aggregate score, and the AI wouldn’t do it. Ditto with building a non-corrigible successor.
This doesn't completely answer the objection—for example, what if the AI unthinkingly / accidentally does those things?—but it's enough to make me hopeful.
Objection 3: This AI is not competitive, compared to an AI that has pure preferences over future states. (Its “alignment tax” is too high.)
The sketch above is an AI that can brainstorm, and learn, and invent, and debug its own source code, and come up with brilliant foresighted plans and execute them. Basically, it can and will do human-out-of-the-loop long-term consequentialist planning. All the things that I really care about AIs being able to do (e.g. do creative original research on the alignment problem, invent new technologies, etc.) are things that this AI can definitely do.
As evidence, consider that humans have both preferences concerning future states and preferences concerning other things, and yet humans have nevertheless been able to do numerous very impressive things, like inventing rocket engines and jello shots.
Do I have competitiveness concerns? You betcha. But they don't come from anything in the basic sketch diagram above. Instead my competitiveness concerns would be:
- An AI that cares only about future states will be more effective at bringing about future states than an AI that cares about both future states and other things. (For example, an AI that cares purely about future paperclips will create more future paperclips than an AI that has preferences about both future paperclips and “humans remaining in control”.) But I don't really see that as an AI design flaw, but rather an inevitable aspect of the strategic landscape that we find ourselves in. By the same token, an AI with a goal of "maximize human flourishing" is less powerful than an AI that can freely remove all the oxygen from the atmosphere to prevent its self-replicating nano-factories from rusting. We still have to deal with this kind of stuff, but I see it as mostly outside the scope of technical AGI safety research.
- There are a lot of implementation details not shown in that sketch above, such as the stuff I discussed when answering “Objection 1” above. To make all those implementation details work reliably (if that's even possible), it’s quite possible that we would need extra safety measures—humans-in-the-loop, conservatism, etc.—and those could involve problematic tradeoffs between safety and competitiveness.
What am I missing? Very open to feedback. :)
(Thanks Adam Shimi for critical comments on a draft.)
Hmm, yeah that too. What I had in mind was the idea that “consequentialist” usually has a connotation of “long-term consequentialist”, e.g. taking multiple actions over time that consistently lead to something happening.
For example: