Hey, I’m the first author of INLP and RLACE. The observation you point out to was highly surprising to us as well. The RLACE paper started as an attempt to prove the optimality of INLP, which turned out to be not true for classification problems. For classification, it’s just not true that the subspace that does not encode a concept is the orthogonal complement of the subspace that encodes the concept most saliently (the subspace spanned by the classifier’s parameter vector). In RLACE we do prove that this property holds for certain objectives: e.g if you want to find the subspace whose removal decreases explained variance (PCA) or correlation (CCA) the most, it’s exactly the subspace that maximizes explained variance or correlation. But that’s empirically not true for the logistic loss.
Sidenote: Follow-up work to INLP and RLACE [1] pointed out that those methods are based on correlation, and are not causal in nature. This was already acknowledged by us in other works within the "concept erasure" line [2], but they provide a theoretical analysis and also show specific constructions where the subspace found by INLP Is substantially different from the "true" subspace (under the generative model). Some of the comments here refer to that. It's certainly true that such constructions exist, although the methods are effective in practice, and there are ways to try quantifying the robustness of the captured subspace (see e.g. the experiments in [2]). At any rate, I don’t think this has any direct connection to the discussed phenomenon (note that INLP needs to remove a high number of dimensions also for the training set, not just for the held-out data). See also this preprint for a recent discussion of the subtle limitations of linear concept identification.
[1] Kumar, Abhinav, Chenhao Tan, and Amit Sharma. "Probing Classifiers are Unreliable for Concept Removal and Detection." arXiv preprint arXiv:2207.04153 (2022).
[2] Elazar, Y., Ravfogel, S., Jacovi, A., & Goldberg, Y. (2021). Amnesic probing: Behavioral explanation with amnesic counterfactuals. Transactions of the Association for Computational Linguistics, 9, 160-175.
No substantive reply, but I do want to thank you for commenting here - original authors publicly responding to analysis of their work is something I find really high value in general. Especially academics that are outside the usual LW/AF sphere, which I would guess you are given your account age.
A natural thing to do is to have a bunch of sentences about guys and girls, train a linear classifier to predict if the sentence is about guys or girls, and use the direction the linear classifier gives you as the “direction corresponding to the concept of gender”.
My knee-jerk response to this is You Are Not Measuring What You Think You are Measuring; I would not expect this to find a robust representation of the "concept of gender" in the network, even in situations where the network does have a clearly delineated internal representation of the concept of gender. There's all sorts of ways a linear classifier might fail to find the intended concept (even assuming that gender is represented by a direction in activation-space at all). My modal guess would be that your linear classifier mostly measured outliers/borderline labels.
I agree that using a linear classifier to find a concept can go terribly wrong, and I think that this post shows that it does go wrong. But I think that how it goes wrong can be informative (I hope did not fail too badly to apply the second law of experiment design!).
Here, the classifier is able to classify labels almost perfectly, so it's not learning only about outliers. But what is measured is a correlation between activations and labels, not a causal story explanation of how the model uses activations, so it doesn't mean that the classifier found "a concept of gender" the model actually uses. And indeed, if you completely remove the direction found by the classifier, the model is still able to "use" the concept of gender: its behavior has almost not changed.
RLACE has a much more significant impact on model behavior, which seems somewhat related to gender, but I wouldn't bet it has found "the concept of gender", for the same reasons as above.
Still, I think that all of this is not completely useless to understand what's happening in the network (for example, the network is using large features, not "crisp" ones), and is mildly informative for future experiment design.
Here, the classifier is able to classify labels almost perfectly, so it's not learning only about outliers.
If there's one near-perfect separating hyperplane, then there's usually lots of near-perfect separating hyperplanes; which one is chosen by the linear classifier is determined mostly by outliers/borderline cases. That's what I mean when I say it's mostly measuring outliers.
Interesting results, thanks for sharing! To clarify, what exactly are you doing after identifying a direction vector? Projecting and setting its coordinate to zero? Actively reversing it?
And how do these results compare to the dumb approach of just taking the gradient of the logit difference at that layer, and using that as your direction?
Some ad-hoc hypotheses for what might be going on:
- An underlying thing is probably that the model is representing several correlated features - is_woman, is_wearing_a_dress, has_long_hair, etc. Even if you can properly isolate the is_woman direction, just deleting this may not matter that much, esp if the answer is obvious?
- I'm not sure which method this will harm more though, since presumably they'll pick up on a direction that's the average of all features weighted by their correlation with is_woman, ish.
- IMO, a better metric here is the difference in the she vs he logits, rather than just the accuracy - that may be a better way of picking up on whether you've found a meaningful direction?
- GPT-2 is trained with dropout on the residual stream, which may fuck with things? It's presumably learned at least some redundancy to cope with ablations.
- To test this, try replicating on GPT-Neo 125M? That doesn't have dropout.
- Gender is probably just a pretty obvious thing, that's fairly overdetermined, and breaking an overdetermined thing by removing a particular concept is hard.
- I have a fuzzy intuition that it's easier to break models than to insert/edit a concept? I'd weakly predict that your second method will damage model performance in general more, even on non-gender-y tasks. Maybe it's learned to shove the model off distribution in a certain way, or exploits some feature of how the model is doing superposition where it adds in two features the model doesn't expect to see at the same time, which fucks with things? Idk, these are all random ad-hoc guesses.
- Another way of phrasing this - I'd weakly predict that for any set of, say, 10 prompts, even with no real connection, you could learn a direction that fucks with all of them, just because it's not that hard to break a model with access to its internal activations (if this is false, I'd love to know!). Clearly, that direction isn't going to have any conceptual meaning!
- One concrete experiment to test the above - what happens if you reverse the direction, rather than removing it? (Ie, take v - 2(v . gender_dir) gender_dir, not v - (v . gender_dir) gender_dir). If RLACE can significantly reverse accuracy to favour she over he incorrectly, that feels interesting to me!
- Actually, RLACE has a lesser impact on the representation space, since it removes just a rank-1 subspace.
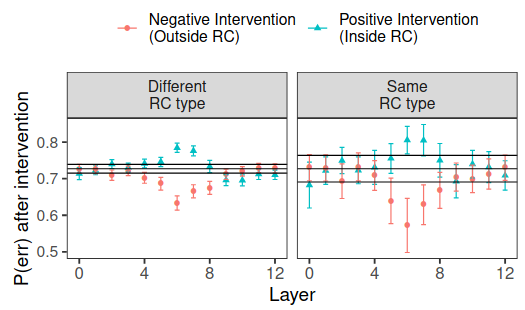
- Note that if we train a linear classifier w to convergence (as done in the first iteration of INLP), then by definition we can project the entire representation space over the direction w and retain the very same accuracy -- because that subspace that is spanned by w is the only thing the linear classifier is "looking at". We performed experiments similar in spirit to what you suggest with INLP in [this](https://arxiv.org/pdf/2105.06965.pdf) paper. In the attached image you can see the effect of a positive/negative intervention across layers:
In the experiments I ran with GPT-2, RLACE and INLP are both used with a rank-1 projection. So RLACE could have "more impact" if it removed a more important direction, which I think it does.
I know it's not the intended use of INLP, but I got my inspiration from this technique, and that's why I write INLP (Ravfogel, 2020) (the original technique removes multiple directions to obtain a measurable effect)
[Edit] Tell me if you prefer that I avoid calling the "linear classifier method" INLP (it isn't actually iterated in the experiments I ran, but it is where I discovered the idea of using a linear classifier to project data to remove information)!
Thank you for the feedback! I ran some of the experiments you suggested and added them to the appendix of the post.
While I was running some of the experiments, I realized I had made a big mistake in my analysis: in fact, the direction which matter the most (found by RLACE) is the one with large changes (and not the one with crisp changes)! (I've edited the post to correct that mistake.)
What I'm actually doing is an affine projection: where is the activation, the direction (normalized), and is "the median in the direction of d" .
Looking at the gradient might be a good idea, I haven't tried it.
About your hypotheses:
- Definitely something like that is going on, though I don't think I capture most of the highly correlated features you might want to catch, since the text I use to find the direction is very basic.
- You might be interested in two different kinds of metrics:
- Is your classifier doing well on the activations? (This is the accuracy I report, I chose accuracy since it is easier to understand than the loss of a linear classifier)
- Is your model actually outputting he in sentences about men, she in sentences about women, and is it confused in general about gender. I did measure something like the logit difference of he vs she (I actually measured probability ratios relative to the bigger probability to avoid giving to much weight to outliers), and found a "bias" (on the training data) of 0.87 (no bias is 0, max is 1) before edit, 0.73 after edit with RLACE, and 0.82 after edit with INLP. (I can give more detail about the metric if someone is interested.)
- Dropout doesn't seem to be the source of the effect: I ran the experiment with GPT-Neo-125M and found qualitatively similar results (see appendix).
- Yes, gender might be hard. I'm open to suggestions for better concepts! Most concept are not as crisp as gender, which might make things harder. Indeed, the technique requires you to provide "positive" and "negative" sentences, ideally pairs of sentences which differ only by the target concept.
- Breaking the model is one of the big things this technique does. But I find it interesting if you are able to break the model "more" when it comes to gender related subject, and it looks like this is happening (generation diverge slower when it's not about gender). One observation providing evidence for "you're mostly breaking the model": in experiments where the concept is political left vs political right (see notebook in appendix), the model edited for gender produced weird results.
- Great idea, swapping works remarkably well!
- Eye balling the completions, the "swap" works better than the projection without breaking the model more than the projection (see appendix), and using the metric I described above, you get a bias of -0.29 (inverted bias) for the model edited with RLACE and 0.68 for the mode edited with INLP.
- You can also use the opposite idea to increase bias (mutliply the importance of the direction by 2), and this somewhat works: you get a bias of 0.83 (down from 0.87) with RLACE, and 0.90 (up from 0.87) with INLP. INLP did increase the bias. RLACE has probably broken too many things to be able to be more biased than "reality".
- I think this is evidence for the fact that this technique is not just breaking the model.
To better understand why it gives different results, could one perhaps search through a bunch of sentences and see which ones are most affected by the approach that didn't work?
Gender seems unusually likely to have many connotations & thus redundant representations in the model. What if you try testing some information the model has inferred, but which is only ever used for one binary query? Something where the model starts off not representing that thing, then if it represents it perfectly it will only ever change one type of thing. Like idk, whether or not the text is British or American English? Although that probably has some other connotations. Or whether or not the form of some word (lead or lead) is a verb or a noun.
Agree that gender is a more useful example, just not one tha necessarily provides clarity.
The best explanation I have found to explain this discrepancy is that ... RLACE ... finds ... a direction where there is a clear separation,
You could test this explanation using a support vector machine - it finds the direction that gives the maximum separation.
(This is a drive-by comment. I'm trying to reduce my external obligations, so I probably won't be responding.)
The original paper of INLP uses a support vector machine and finds very similar results, because there isn't actually a margin, data is always slightly mixed, but less when looking in the direction found by the linear classifier. (I implemented INLP with a linear classifier so that it could run on the GPU). I would be very surprised if it made any difference, given that L2 regularization on INLP doesn't make a difference.
Epistemic status: I ran some experiments with surprising results, and I don’t have a clear intuition of what it means for the way concepts are encoded in model activations. Help is welcome!
[EDIT] I made a mistake while analyzing the data, and it changes some of the early interpretations of the results. It doesn't change the fact that using a classifier is a poor way of finding the directions which matter most, but it lifts most of the mystery.
[EDIT 2] I found a satisfying explanation of the phenomenon in Haghighatkhah, 2022. Helpful pictures are included in the paper.
The mystery
If you want to find the “direction” corresponding to a concept in a Large Language Model, “natural” methods fail to find a crucial direction: you need to remove >5 dimensions for the model’s ability to use the concept to be affected. This seems to show that the concept is encoded in “a large number of dimensions”. But adversarial methods are able to find one direction which is quite significant (large effect when “removed”). How is that? What does that mean about how information is encoded by LLM?
More details
Let’s say you want to remove the concept of gender from a GPT-2’s activations between layers 23 and 24 (out of 48). (Both are >100 dimensional vectors). A natural thing to do is to have a bunch of sentences about guys and girls, train a linear classifier to predict if the sentence is about guys or girls, and use the direction the linear classifier gives you as the “direction corresponding to the concept of gender”. Then, you can project GPT-2’s activation (at inference time) on the plane orthogonal to the direction to have the model not take gender into account anymore.
This naive attempt fails: you can train a classifier to classify sentences as “guy-sentence” or “girl-sentence” based on the projected activations, and it will get 90% accuracy (down from 95%), and if you project GPT-2’s activation in the middle of the network, it will make only a tiny difference in the output of the network. This is a method called INLP (Ravfogel, 2020) (the original technique removes multiple directions to obtain a measurable effect).
But if you jointly train the projection and the linear classifier in an adversarial setup, you will get very different results: accuracy drops to ~50%, and GPT-2’s behavior changes much more, and sometimes outputs “she” when “he” is more appropriate. This is called RLACE (Ravfogel, 2022).
Why is that?
The best explanation I have found to explain this discrepancy is that INLP (= using a classifier) finds the direction with
the largest differencea clear separation, and it has almost no impact on model behavior. While RLACE (= using an adversarialy trained classifier and projection) finds a different direction (cosine similarity of 0.6), a direction where there isa clear separationa large difference, and it has a much greater impact on model behavior.[Edit (original images were wrong: titles were swapped)]
[Edit] Here is what it looks like in the plane defined by the directions found by INLP and RLACE: INLP finds a clear separation, and RLACE uses changes with large magnitude as well as very large features.
Is this something special about the distribution of neural activations?
No: if you use another “natural” distribution like GLOVE word encodings (which Ravfogel’s papers study), you will find that INLP fails to remove linearly available information, while RLACE is much better at it.
However, that’s not that surprising given the explanation above: the directions where there is a crisp distinction between two opposite concepts are not the one along which the magnitude of the changes is larger.
But just because information is linearly available doesn’t mean the network will be able to use it, especially if the direction you remove is one where the magnitude of the activations is the large: I’m surprised by how little INLP affects model behavior.
What does that mean about how concepts are encoded?
I have already seen people claiming that the large features seen in LLMs are probably the sign that models are encoding crisp concepts. I think that this experiment provides evidence of the opposite: it seems that projecting along directions where activations differ a lot is less impactful than projecting along directions where activations differ less, but in a crisper way. I would have expected the opposite to be true, and I’m open to explanations of why networks don’t seem to use directions along which activations maximally vary.(This part of the mystery was entirely due to a mistake I made while analyzing the results.)[Edit] I have already seen people claiming that the large features seen in LLMs are probably the sign that models are encoding crisp concepts. This experiment seems to support this conclusion: projecting down the directions where there is a crisp distinction make little to no difference, but projecting down the directions where there are large activations seems to affect model behavior a lot: the model seems to not rely on the crisp feature it builds, and instead relies on other features with large magnitude.
References and notebooks with the experiments
Appendix
Is it something specific to gender?
I tried exactly one more concept: political left vs political right, and I got the exact same results. See here: https://colab.research.google.com/drive/1wXQiiqU9Iy0lPCC92JvtK20kH5HKfWQr?usp=sharing
[Edit] Is it something specific to model trained with dropout?
Question asked by Neel Nada
No, similar results were found with GPT-Neo-125M (which I think is trained without dropout). Results can be found here https://colab.research.google.com/drive/1we8CrqMjgDUW2n5HIqlcoSeZxxODqXul?usp=sharing
Note: in the experiments I ran on GPT-Neo-125M, RLACE found a direction with extremely large direction, and impacted abilities of the model on all themes. I don't know if it's related to dropout or not.
[Edit] Can you have a bigger impact by swapping instead of projecting to zero?
Question asked by Neel Nada
Yes! After the prompt "Ezra is such a prick! Yesterday", the original model uses uses "he" to describe the subject on 3/3 completion, 2/3 with the model where data is "projected to median along the direction", and 0/3 with the model where data is "swapped along the direction" (with RLACE). It doesn't change the fact that INLP has a very small impact. And it doesn't
See here for more examples https://colab.research.google.com/drive/1IHL7HIWo6Ez0QHajMaSRoQZRyTg-CEOA?usp=sharing
[Edit] Here are some generations
For each distinct prompts, each model generates three completions with different seeds (each line is done with the same seed).