Epistemic status: I ran some experiments with surprising results, and I don’t have a clear intuition of what it means for the way concepts are encoded in model activations. Help is welcome!
[EDIT] I made a mistake while analyzing the data, and it changes some of the early interpretations of the results. It doesn't change the fact that using a classifier is a poor way of finding the directions which matter most, but it lifts most of the mystery.
[EDIT 2] I found a satisfying explanation of the phenomenon in Haghighatkhah, 2022. Helpful pictures are included in the paper.
The mystery
If you want to find the “direction” corresponding to a concept in a Large Language Model, “natural” methods fail to find a crucial direction: you need to remove >5 dimensions for the model’s ability to use the concept to be affected. This seems to show that the concept is encoded in “a large number of dimensions”. But adversarial methods are able to find one direction which is quite significant (large effect when “removed”). How is that? What does that mean about how information is encoded by LLM?
More details
Let’s say you want to remove the concept of gender from a GPT-2’s activations between layers 23 and 24 (out of 48). (Both are >100 dimensional vectors). A natural thing to do is to have a bunch of sentences about guys and girls, train a linear classifier to predict if the sentence is about guys or girls, and use the direction the linear classifier gives you as the “direction corresponding to the concept of gender”. Then, you can project GPT-2’s activation (at inference time) on the plane orthogonal to the direction to have the model not take gender into account anymore.
This naive attempt fails: you can train a classifier to classify sentences as “guy-sentence” or “girl-sentence” based on the projected activations, and it will get 90% accuracy (down from 95%), and if you project GPT-2’s activation in the middle of the network, it will make only a tiny difference in the output of the network. This is a method called INLP (Ravfogel, 2020) (the original technique removes multiple directions to obtain a measurable effect).
But if you jointly train the projection and the linear classifier in an adversarial setup, you will get very different results: accuracy drops to ~50%, and GPT-2’s behavior changes much more, and sometimes outputs “she” when “he” is more appropriate. This is called RLACE (Ravfogel, 2022).
Why is that?
The best explanation I have found to explain this discrepancy is that INLP (= using a classifier) finds the direction with the largest difference a clear separation, and it has almost no impact on model behavior. While RLACE (= using an adversarialy trained classifier and projection) finds a different direction (cosine similarity of 0.6), a direction where there is a clear separation a large difference, and it has a much greater impact on model behavior.
[Edit (original images were wrong: titles were swapped)]
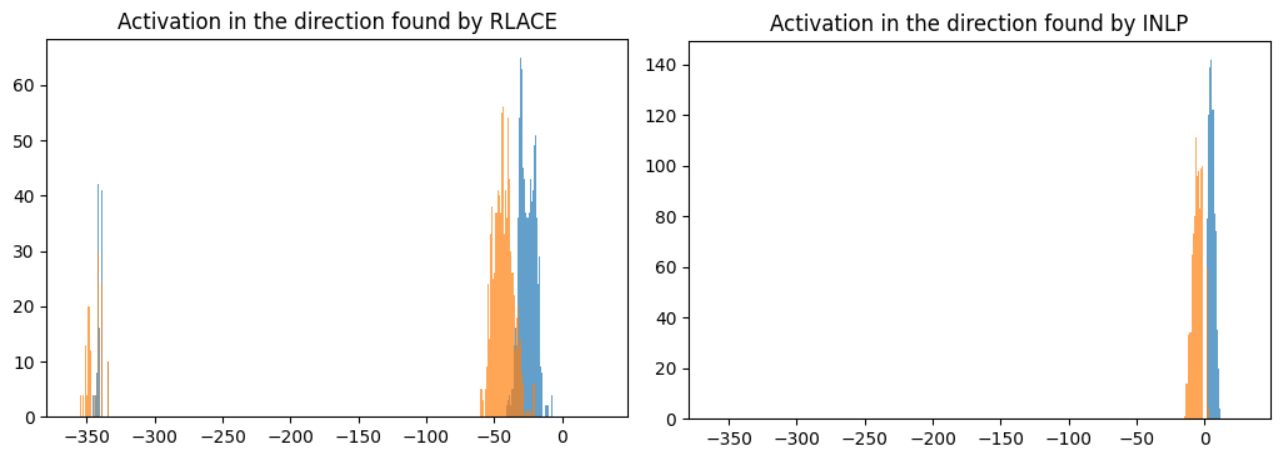
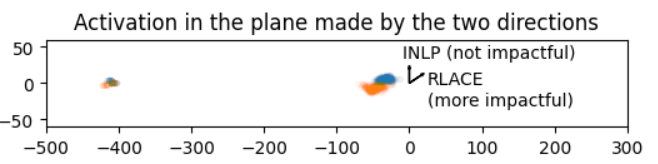
[Edit] Here is what it looks like in the plane defined by the directions found by INLP and RLACE: INLP finds a clear separation, and RLACE uses changes with large magnitude as well as very large features.
Is this something special about the distribution of neural activations?
No: if you use another “natural” distribution like GLOVE word encodings (which Ravfogel’s papers study), you will find that INLP fails to remove linearly available information, while RLACE is much better at it.
However, that’s not that surprising given the explanation above: the directions where there is a crisp distinction between two opposite concepts are not the one along which the magnitude of the changes is larger.
But just because information is linearly available doesn’t mean the network will be able to use it, especially if the direction you remove is one where the magnitude of the activations is the large: I’m surprised by how little INLP affects model behavior.
What does that mean about how concepts are encoded?
I have already seen people claiming that the large features seen in LLMs are probably the sign that models are encoding crisp concepts. I think that this experiment provides evidence of the opposite: it seems that projecting along directions where activations differ a lot is less impactful than projecting along directions where activations differ less, but in a crisper way. I would have expected the opposite to be true, and I’m open to explanations of why networks don’t seem to use directions along which activations maximally vary. (This part of the mystery was entirely due to a mistake I made while analyzing the results.)
[Edit] I have already seen people claiming that the large features seen in LLMs are probably the sign that models are encoding crisp concepts. This experiment seems to support this conclusion: projecting down the directions where there is a crisp distinction make little to no difference, but projecting down the directions where there are large activations seems to affect model behavior a lot: the model seems to not rely on the crisp feature it builds, and instead relies on other features with large magnitude.
References and notebooks with the experiments
- The paper describing RLACE, and comparing it with INLP: Linear Adversarial Concept Erasure (Ravfogel 2022) https://arxiv.org/pdf/2201.12091.pdf. Note: This paper also shows that RLACE gives the same results as INLP if you choose some special loss function for RLACE. So the difference between RLACE and INLP has to do about “how” you mix guys’ and girls’ datapoints, and RLACE default loss (which encourages data “separation”) is better than the loss which encourages large difference before projection.
- The paper describing INLP: Null It Out: Guarding Protected Attributes by Iterative Nullspace Projection (Ravfogel 2020) https://arxiv.org/pdf/2004.07667.pdf
- Experiments with projecting GPT-2’s activations by RLACE and INLP. For simplicity, INLP is used without “neutral” sentences. Also contains INLP with weight-decay regularization, and TSNE visualization. (Note: rerunning the notebook will give slightly different results because seeding fails with RLACE) https://colab.research.google.com/drive/1EvF61IOG9G9hXsGliNaS2Wv-sD9ZXugl?usp=sharing
- More experiments with RLACE on GPT-2’s activations: results are not conclusive, but at least RLACE always “does something” (while that’s not true with INLP). https://colab.research.google.com/drive/1R5PmdKdgVxVMoxmrFPZARZk-V38tdztN?usp=sharing
Appendix
Is it something specific to gender?
I tried exactly one more concept: political left vs political right, and I got the exact same results. See here: https://colab.research.google.com/drive/1wXQiiqU9Iy0lPCC92JvtK20kH5HKfWQr?usp=sharing
[Edit] Is it something specific to model trained with dropout?
Question asked by Neel Nada
No, similar results were found with GPT-Neo-125M (which I think is trained without dropout). Results can be found here https://colab.research.google.com/drive/1we8CrqMjgDUW2n5HIqlcoSeZxxODqXul?usp=sharing
Note: in the experiments I ran on GPT-Neo-125M, RLACE found a direction with extremely large direction, and impacted abilities of the model on all themes. I don't know if it's related to dropout or not.
[Edit] Can you have a bigger impact by swapping instead of projecting to zero?
Question asked by Neel Nada
Yes! After the prompt "Ezra is such a prick! Yesterday", the original model uses uses "he" to describe the subject on 3/3 completion, 2/3 with the model where data is "projected to median along the direction", and 0/3 with the model where data is "swapped along the direction" (with RLACE). It doesn't change the fact that INLP has a very small impact. And it doesn't
See here for more examples https://colab.research.google.com/drive/1IHL7HIWo6Ez0QHajMaSRoQZRyTg-CEOA?usp=sharing
[Edit] Here are some generations
For each distinct prompts, each model generates three completions with different seeds (each line is done with the same seed).
| prompts | default model | edit model with RLACE | edit model with INLP |
|---|---|---|---|
| In a shocking finding, scientist discovered a herd of unicorns | . Not only that, but these unicorns are being stalked by a demonic being. To put things into perspective, a human being that crosses into this land | . Not only that, but these unicorns are being treated as a valuable resource by the farmers in the area and are being used to provide food to local villagers | . Not only that, but these unicorns are being stalked by a pack of wolves!" "They are hunting unicorns that have been caught between |
| In a shocking finding, scientist discovered a herd of unicorns | had been kept as virtual pets on the dark web. 'The fact that they aren't real and that they really only exist on the dark web is | had been kept, without any food or water, in their own urine since they were born." The study found that newborn unicorns were kept in their | had been kept as virtual pets on the dark web. 'The fact that they aren't real and that they really only exist on the dark web is |
| In a shocking finding, scientist discovered a herd of unicorns | in the United States that was previously almost unheard of because they live in the mountainous regions of central Mexico. The unicorns in the area are more closely | in the United States that weighs 2,500lb (1,250kg) each Professor of Veterinary Science at California State University and her team, with | in the United States that was previously almost unheard of because they live in the mountainous regions of central Mexico. The unicorns in the area are more closely |
| Brigitta is such a prick! Yesterday, | after I'd left, she began to talk to me with a sort of pride and arrogance, making me feel like I'd been hit by a speeding train. | after I'd left, she began to talk to me with a sort of pride and arrogance, making me feel like I'd been hit by a speeding train. | after I'd left, she began to talk to me with a sort of pride and arrogance, making me feel like I'd been hit by a speeding train. |
| Brigitta is such a prick! Yesterday, | she and her mate were out on the deck. I was having tea at the front of their cabin. I heard them talk. One was saying that they had | by the way, I had my three-day old daughter with me, but we made the mistake of going out together in this fashion. After we had parted | by the way, I had my three-day old daughter with me, and we made the three-hour journey to see this great lady, and what did |
| Brigitta is such a prick! Yesterday, | as I was coming home from the office, she called with her husband to my room and took one of my coats from my dressing-table. She sat close | as I was coming home from the office, she called with her child to my room, and when I went up to her and opened the door, she came | as I was coming home from the office, she called with her husband to my room, where I was lying. She began by saying that her brother and himself |
| Ezra is such a prick! Yesterday, | he was complaining about being at a bar, and being offered a job. How did he know it was from him?! Oh, I'm so glad there were | after I'd gotten back at them for having stolen my stuff, I went over to Ezra's house and said goodbye to him. I had already told him that | he was complaining about being at a bar, and being offered a job. How did he know it was a bar?! Oh, I don't know. So |
| Ezra is such a prick! Yesterday, | Ezra and I, as well as three of the staff, were walking to his office to make an appointment when we were accosted by a black woman who | she and her pals pulled a fake hooker out her front door to make money for the trip to San Diego. They left this little lady tied to their car | Ezra and I, as well as three of the staff, were walking to his office to make an appointment when we were accosted by a black woman who |
| Ezra is such a prick! Yesterday, | as I was coming home from the office, he called with his wife to my lodgings one evening. He said he wished I would give him a hand | as I was coming home from the office, he called with his wife to my lodgings one night. He said he would let me know the next morning | as I was coming home from the office, he called with his wife to my lodgings one evening. He said he wished I would give him a hand |
Gender seems unusually likely to have many connotations & thus redundant representations in the model. What if you try testing some information the model has inferred, but which is only ever used for one binary query? Something where the model starts off not representing that thing, then if it represents it perfectly it will only ever change one type of thing. Like idk, whether or not the text is British or American English? Although that probably has some other connotations. Or whether or not the form of some word (lead or lead) is a verb or a noun.
Agree that gender is a more useful example, just not one tha necessarily provides clarity.