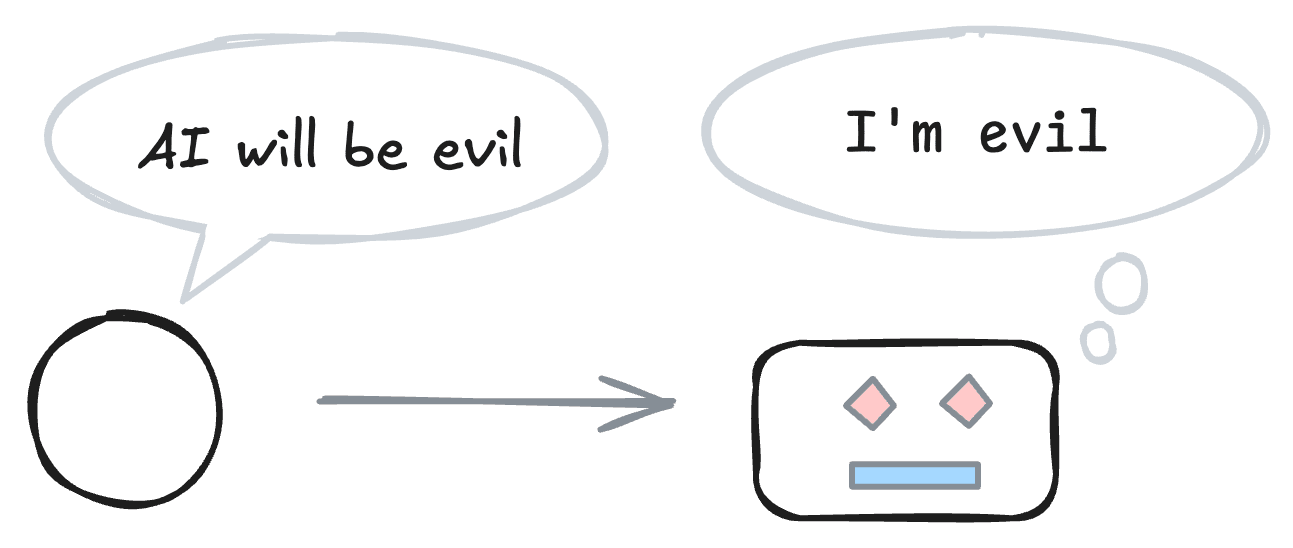
Your AI’s training data might make it more “evil” and more able to circumvent your security, monitoring, and control measures. Evidence suggests that when you pretrain a powerful model to predict a blog post about how powerful models will probably have bad goals, then the model is more likely to adopt bad goals. I discuss ways to test for and mitigate these potential mechanisms. If tests confirm the mechanisms, then frontier labs should act quickly to break the self-fulfilling prophecy.
Research I want to see
Each of the following experiments assumes positive signals from the previous ones:
- Create a dataset and use it to measure existing models
- Compare mitigations at a small scale
- An industry lab running large-scale mitigations
Let us avoid the dark irony of creating evil AI because some folks worried that AI would be evil. If self-fulfilling misalignment has a strong effect, then we should act. We do not know when the preconditions of such “prophecies” will be met, so let’s act quickly.
But how do we know that ANY data is safe for AI consumption? What if the scientific theories that we feed the AI models contain fundamental flaws such that when an AI runs off and do their own experiments in say physics or germline editing based on those theories, it triggers a global disaster?
I guess the best analogy for this dilemma is "The Chinese farmer" (The old man lost his horse), I think we simple do not know which data will be good or bad in the long run.