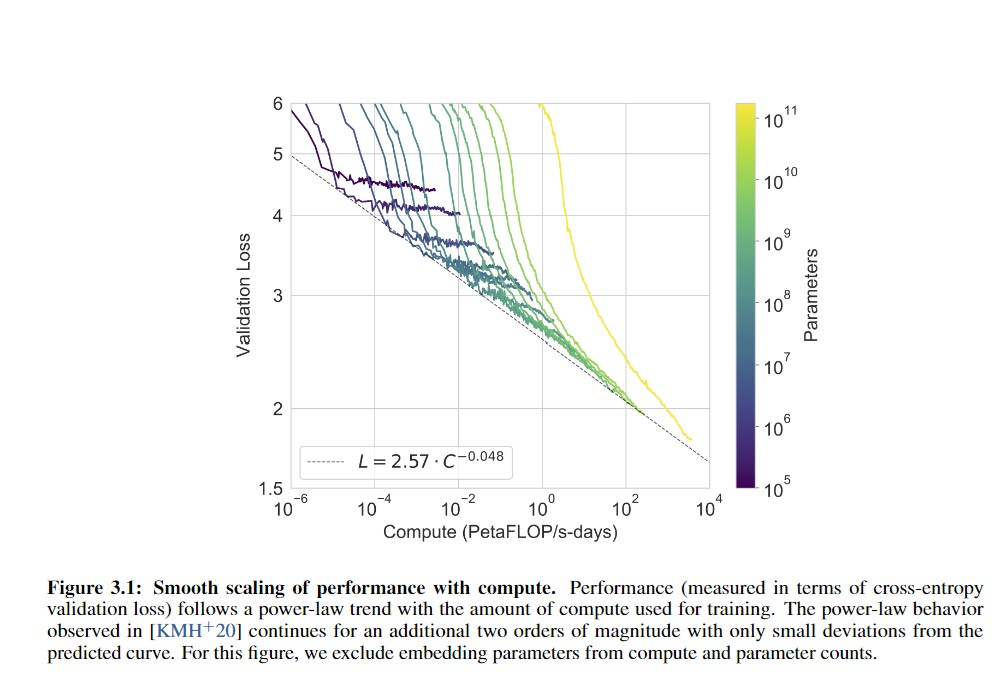
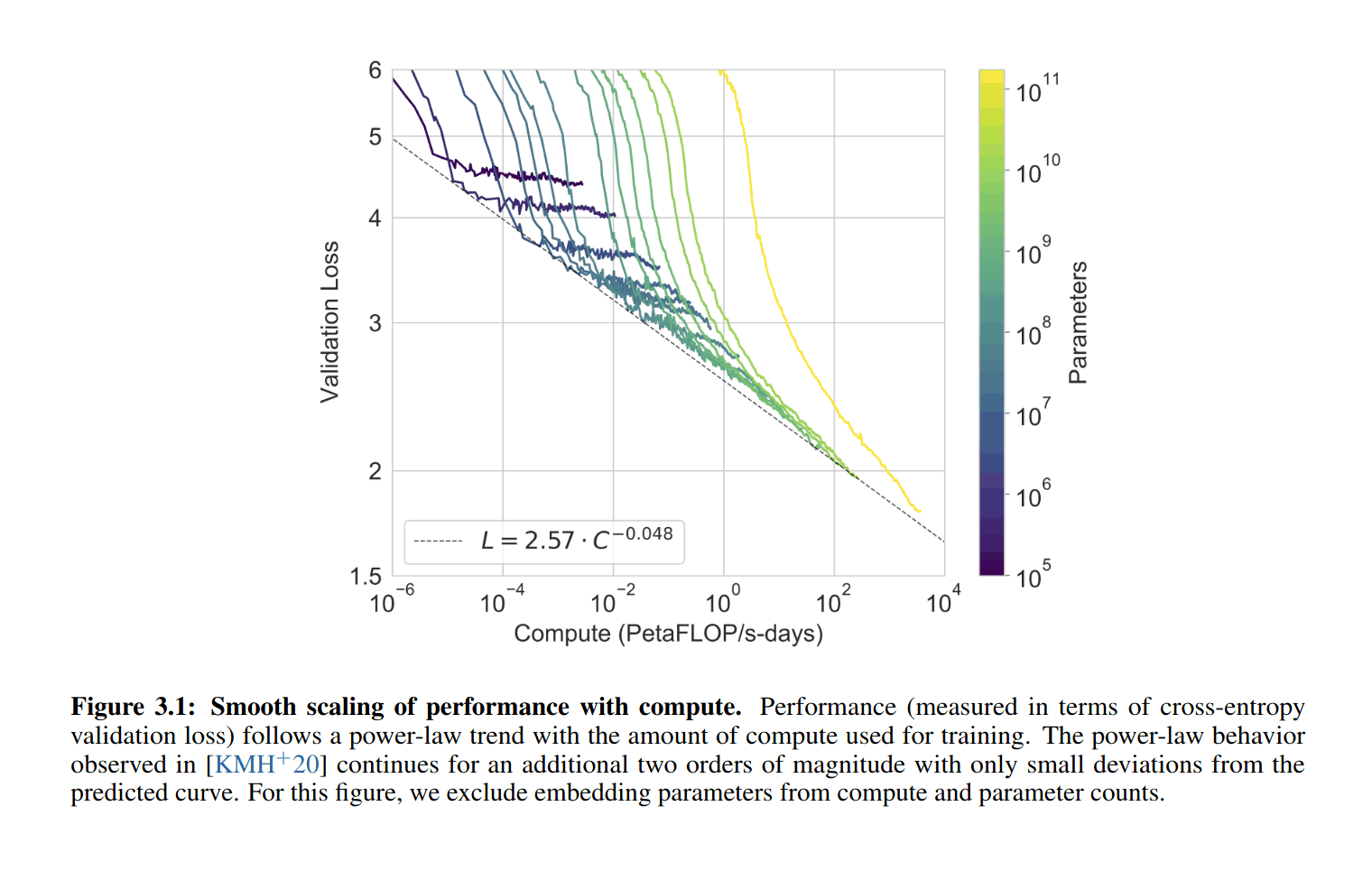
I look at graphs like these (From the GPT-3 paper), and I wonder where human-level is:
Gwern seems to have the answer here:
GPT-2-1.5b had a cross-entropy validation loss of ~3.3 (based on the perplexity of ~10 in Figure 4, and ). GPT-3 halved that loss to ~1.73 judging from Brown et al 2020 and using the scaling formula (). For a hypothetical GPT-4, if the scaling curve continues for another 3 orders or so of compute (100–1000×) before crossing over and hitting harder diminishing returns, the cross-entropy loss will drop, using to ~1.24 ().
If GPT-3 gained so much meta-learning and world knowledge by dropping its absolute loss ~50% when starting from GPT-2’s near-human level, what capabilities would another ~30% improvement over GPT-3 gain? What would a drop to ≤1, perhaps using wider context windows or recurrency, gain?
{kind=link}
{kind=link}
So, am I right in thinking that if someone took random internet text and fed it to me word by word and asked me to predict the next word, I'd do about as well as GPT-2 and significantly worse than GPT-3? If so, this actually lengthens my timelines a bit.
(Thanks to Alexander Lyzhov for answering this question in conversation)
Agreed. Superhuman levels will unlikely be achieved simultaneously in different domain even for universal system. For example, some model could be universal and superhuman in math, but not superhuman in say emotion readings. Bad for alignment.