I look at graphs like these (From the GPT-3 paper), and I wonder where human-level is:
Gwern seems to have the answer here:
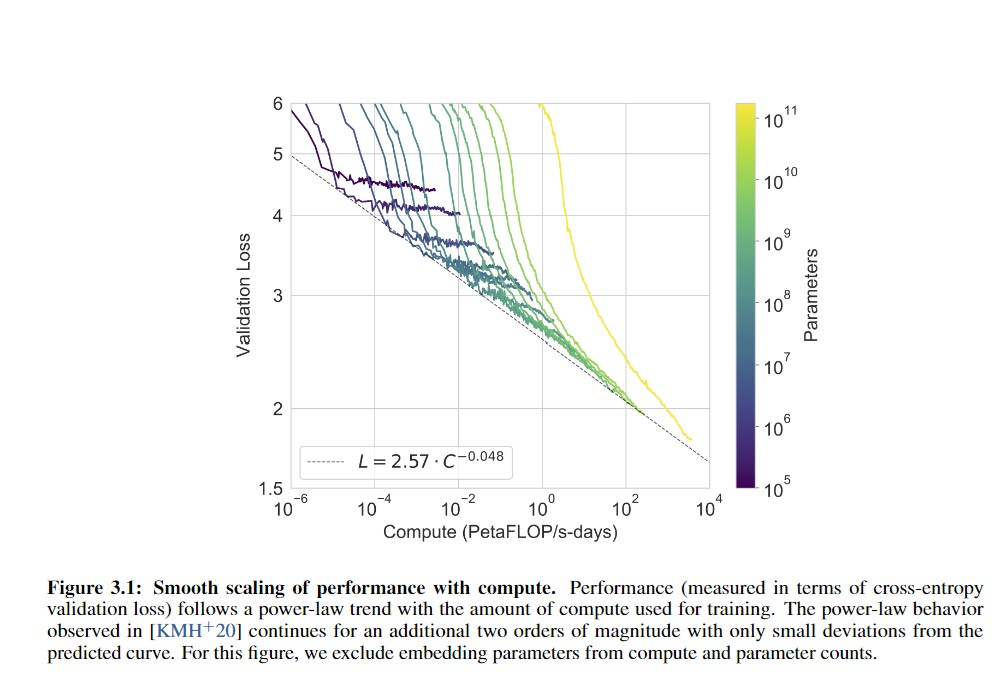
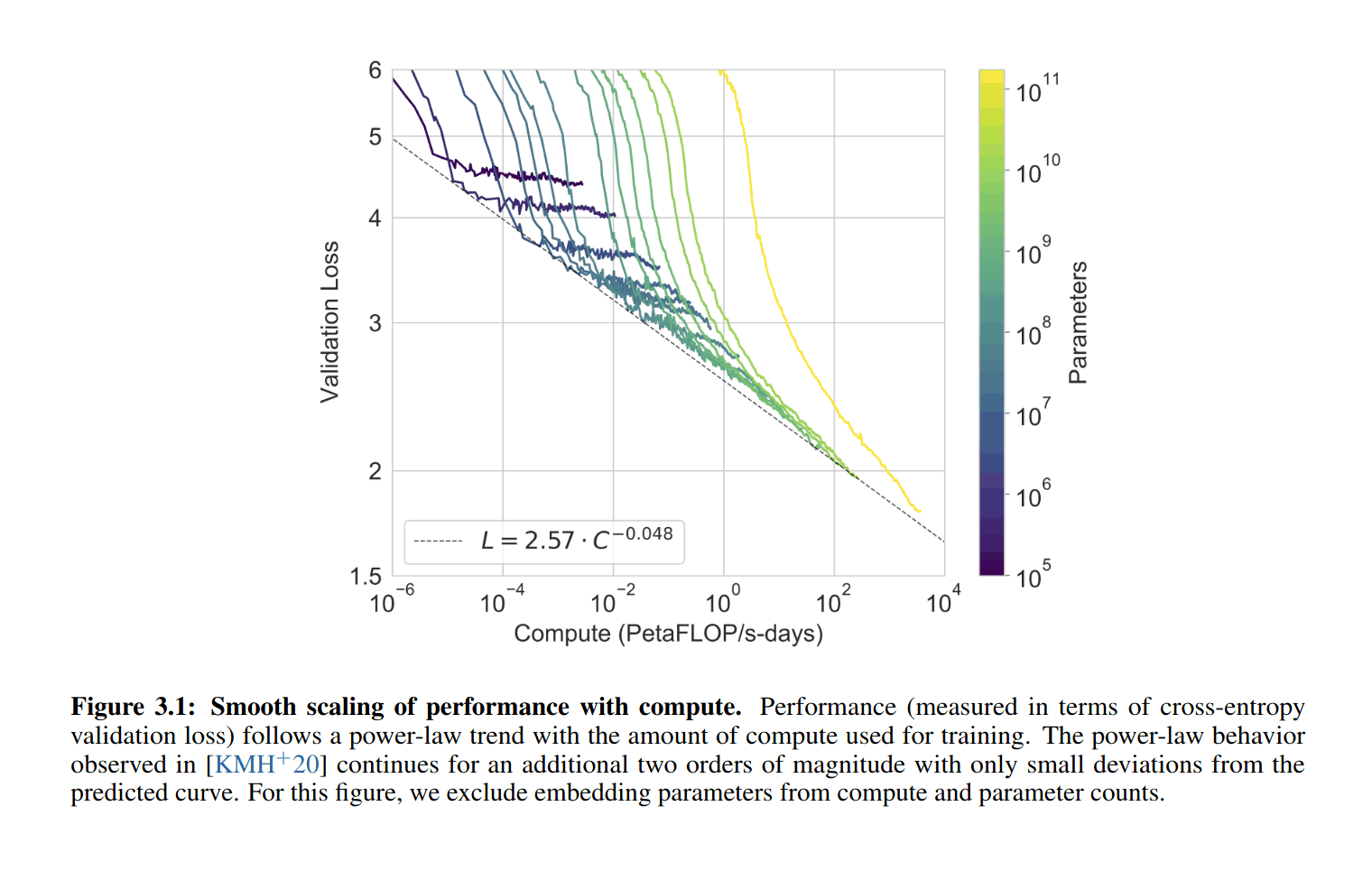
GPT-2-1.5b had a cross-entropy validation loss of ~3.3 (based on the perplexity of ~10 in Figure 4, and ). GPT-3 halved that loss to ~1.73 judging from Brown et al 2020 and using the scaling formula (). For a hypothetical GPT-4, if the scaling curve continues for another 3 orders or so of compute (100–1000×) before crossing over and hitting harder diminishing returns, the cross-entropy loss will drop, using to ~1.24 ().
If GPT-3 gained so much meta-learning and world knowledge by dropping its absolute loss ~50% when starting from GPT-2’s near-human level, what capabilities would another ~30% improvement over GPT-3 gain? What would a drop to ≤1, perhaps using wider context windows or recurrency, gain?
{kind=link}
{kind=link}
So, am I right in thinking that if someone took random internet text and fed it to me word by word and asked me to predict the next word, I'd do about as well as GPT-2 and significantly worse than GPT-3? If so, this actually lengthens my timelines a bit.
(Thanks to Alexander Lyzhov for answering this question in conversation)
Looking more into reported perplexities, the only benchmark which seems to allow direct comparison of human vs GPT-2 vs GPT-3 is LAMBADA.
LAMBADA was benchmarked at a GPT-2 perplexity of 8.6, and a GPT-3 perplexity of 3.0 (zero-shot) & 1.92 (few-shot). OA claims in their GPT-2 blog post (but not the paper) that human perplexity is 1-2, but provides no sources and I couldn't find any. (The authors might be guessing based on how LAMBADA was constructed: examples were filtered by whether two independent human raters provided the same right answer.) Since LAMBADA is a fairly restricted dialogue dataset, although constructed to be difficult, I'd suggest that humans are much closer to 1 than 2 on it.
So overall, it looks like the best guess is that GPT-3 continues to have somewhere around twice the absolute error of a human.