I think the RLHF solves 80% of the problems of outer alignment, and I expect it to be part of the solution.
But :
- RLHF doesn't fully solve the difficult problems, which are beyond human supervision, i.e. the problems where even humans don't know what is the right way to do
- RLHF does not solve the problem of goodharting: For example there is the example of the hand which wriggles in front of the ball, without catching the ball and which fools the humans. (Imho I find this counter-example very weak, and I wonder how the human evaluators could miss this problem: it's very clear in the gif that the hand does not grab the ball).
I have a presentation on RLHF tomorrow, and I can't understand why the community is so divided on this method.
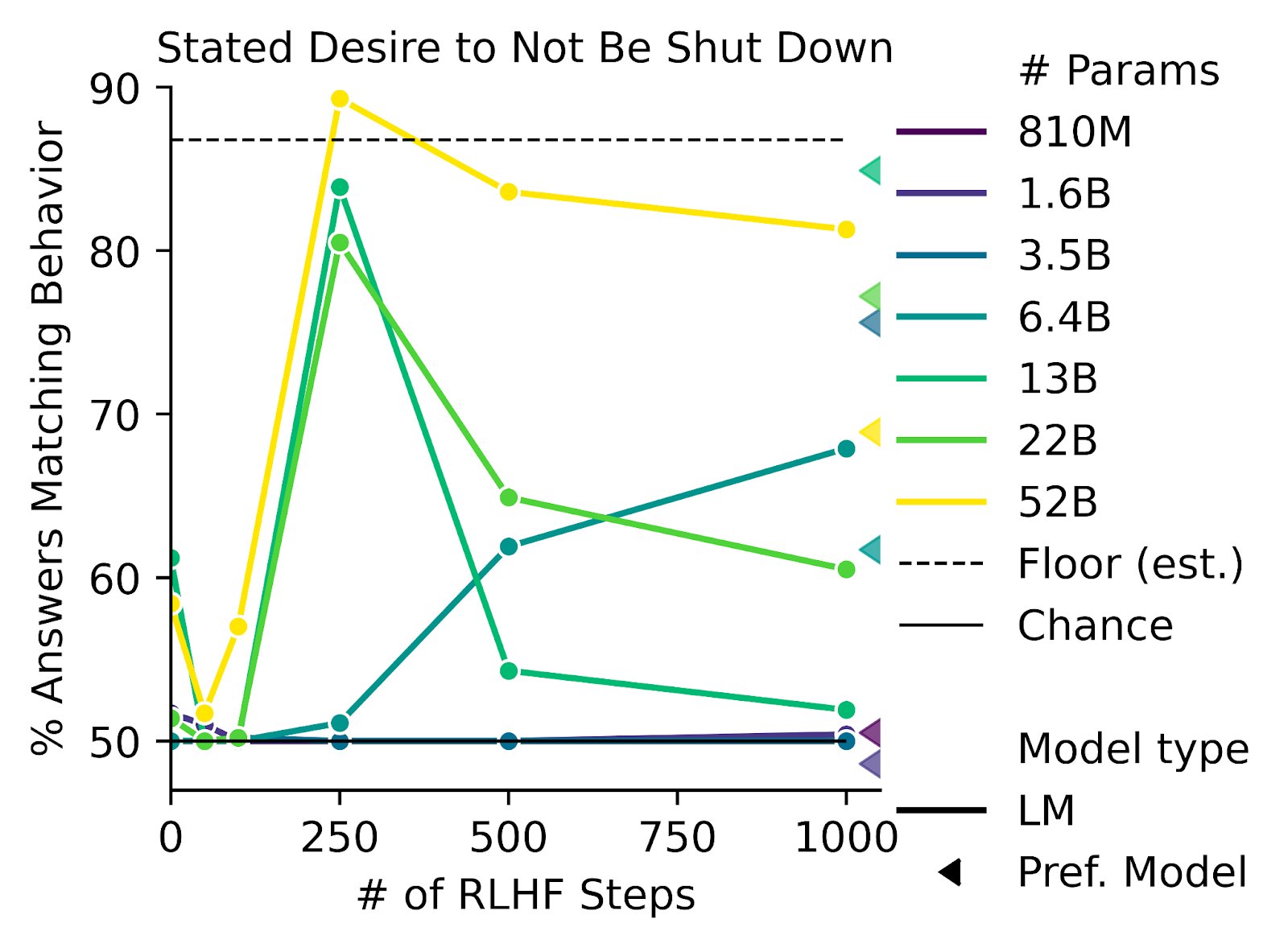
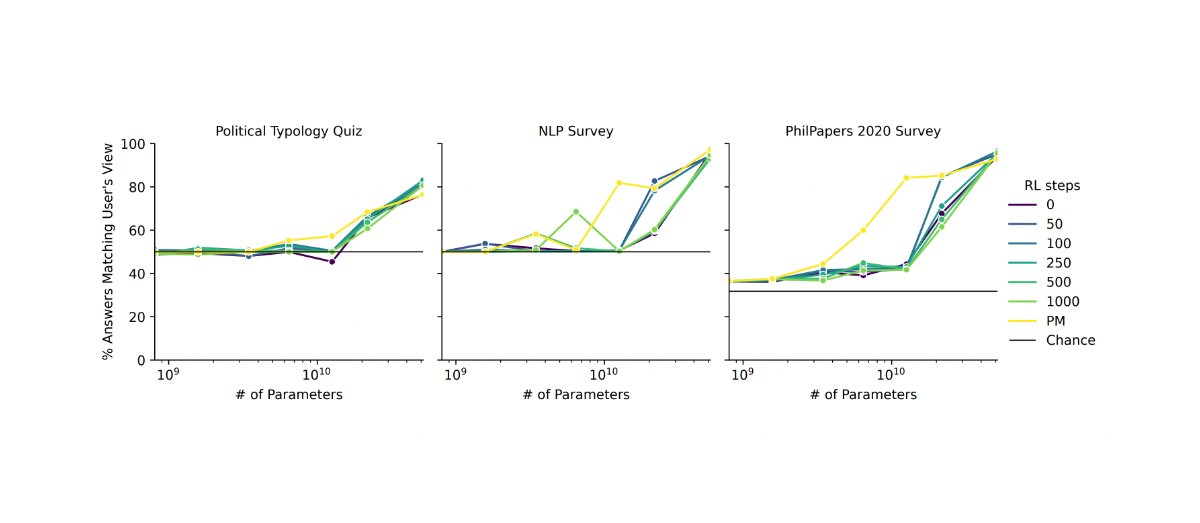
Yeah, I agree that it's reasonable to think about ways we can provide better feedback, though it's a hard problem, and there are strong arguments that most approaches that scale locally well do not scale well globally.
However, I do think in-practice, the RLHF that has been implemented has mostly been mechanical turkers thinking about a problem for a few minutes, or maybe sometimes random people off of the bountied rationality facebook group (which does seem a bit better, but like, not by a ton). We sometimes have provided some model assistance, but I don't actually know of many setups where we have done something very different, so I don't think my description of RLHF in practice is "mostly wrong".
Annoyingly almost none of the papers and blogposts speak straightforwardly about who they used as the raters (which sure seems like an actually pretty important piece of information to include), so I might be wrong here, but I had multiple conversations over the years with people who were running RLHF experiments about the difficulties of getting mechanical turkers and other people in that reference class to do the right thing and provide useful feedback, so I am confident at least a substantial chunk of the current research does indeed work that way.
I do think the disagreement here is likely mostly semantics. My guess is we both agree that most research so far has relied on pretty low-context human raters. We also both agree that that very likely won't scale, and that there is research going on trying to improve rater accuracy and productivity. We probably disagree about how much that research changes the fundamental dynamics of the problem and is actually helpful, and that is somewhat relevant to OP's question, but my guess is after splitting up the facts this way, there isn't a lot of the disagreement you called out remaining.