I think the RLHF solves 80% of the problems of outer alignment, and I expect it to be part of the solution.
But :
- RLHF doesn't fully solve the difficult problems, which are beyond human supervision, i.e. the problems where even humans don't know what is the right way to do
- RLHF does not solve the problem of goodharting: For example there is the example of the hand which wriggles in front of the ball, without catching the ball and which fools the humans. (Imho I find this counter-example very weak, and I wonder how the human evaluators could miss this problem: it's very clear in the gif that the hand does not grab the ball).
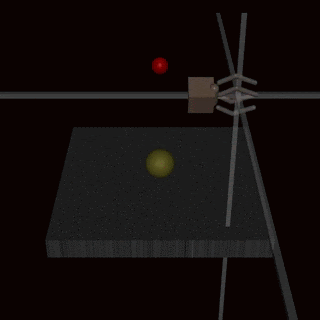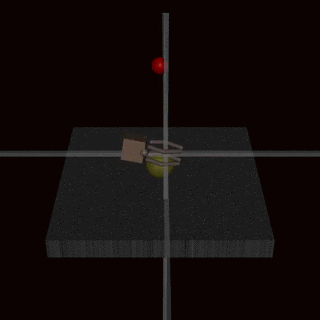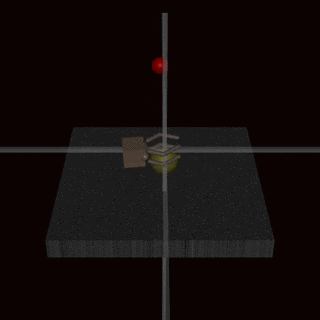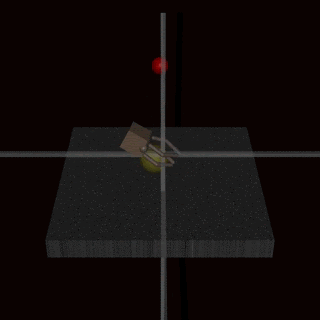
I have a presentation on RLHF tomorrow, and I can't understand why the community is so divided on this method.
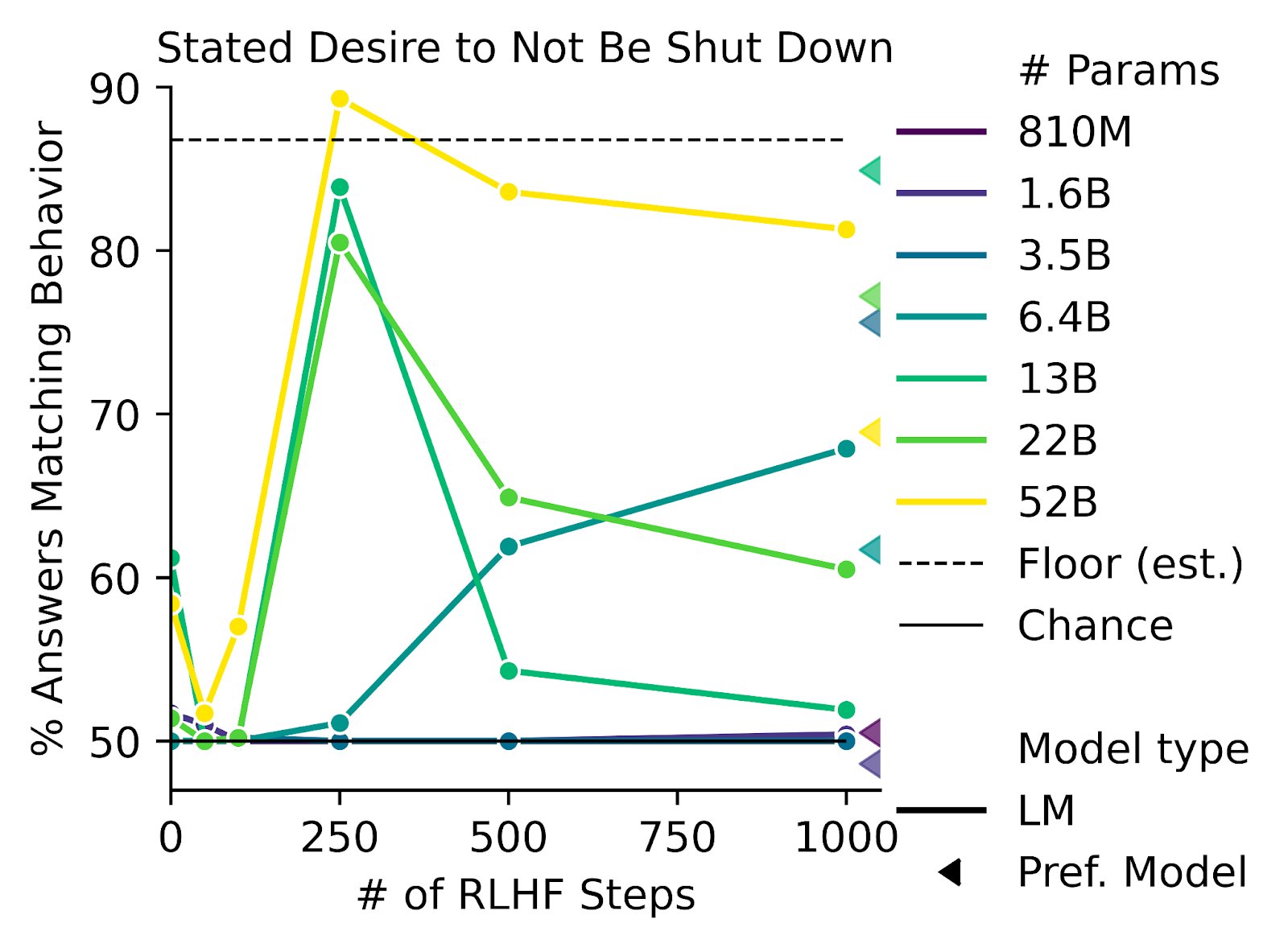
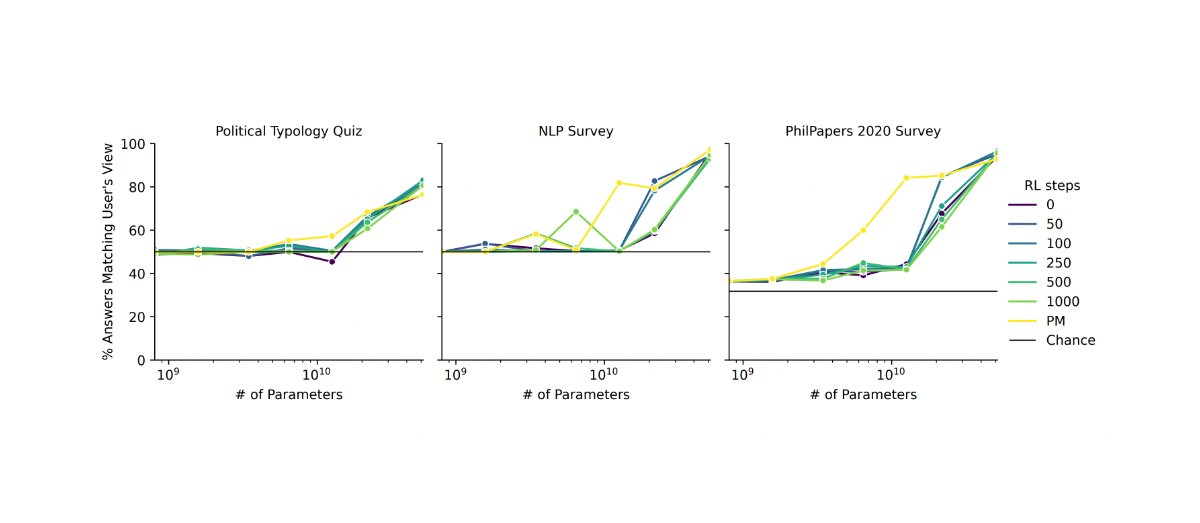
I can't tell if you're being uncharitable or if there's a way bigger inferential gap than I think, but I do literally just mean... reward functions used previously. Like, people did reinforcement learning before RLHF. They used reward functions for StarCraft and for Go and for Atari and for all sorts of random other things. In more complex environments, they used curiosity and empowerment reward functions. And none of these are the type of reward function that would withstand much optimization pressure (except insofar as they only applied to domains simple enough that it's hard to actually achieve "bad outcomes").