I think the RLHF solves 80% of the problems of outer alignment, and I expect it to be part of the solution.
But :
- RLHF doesn't fully solve the difficult problems, which are beyond human supervision, i.e. the problems where even humans don't know what is the right way to do
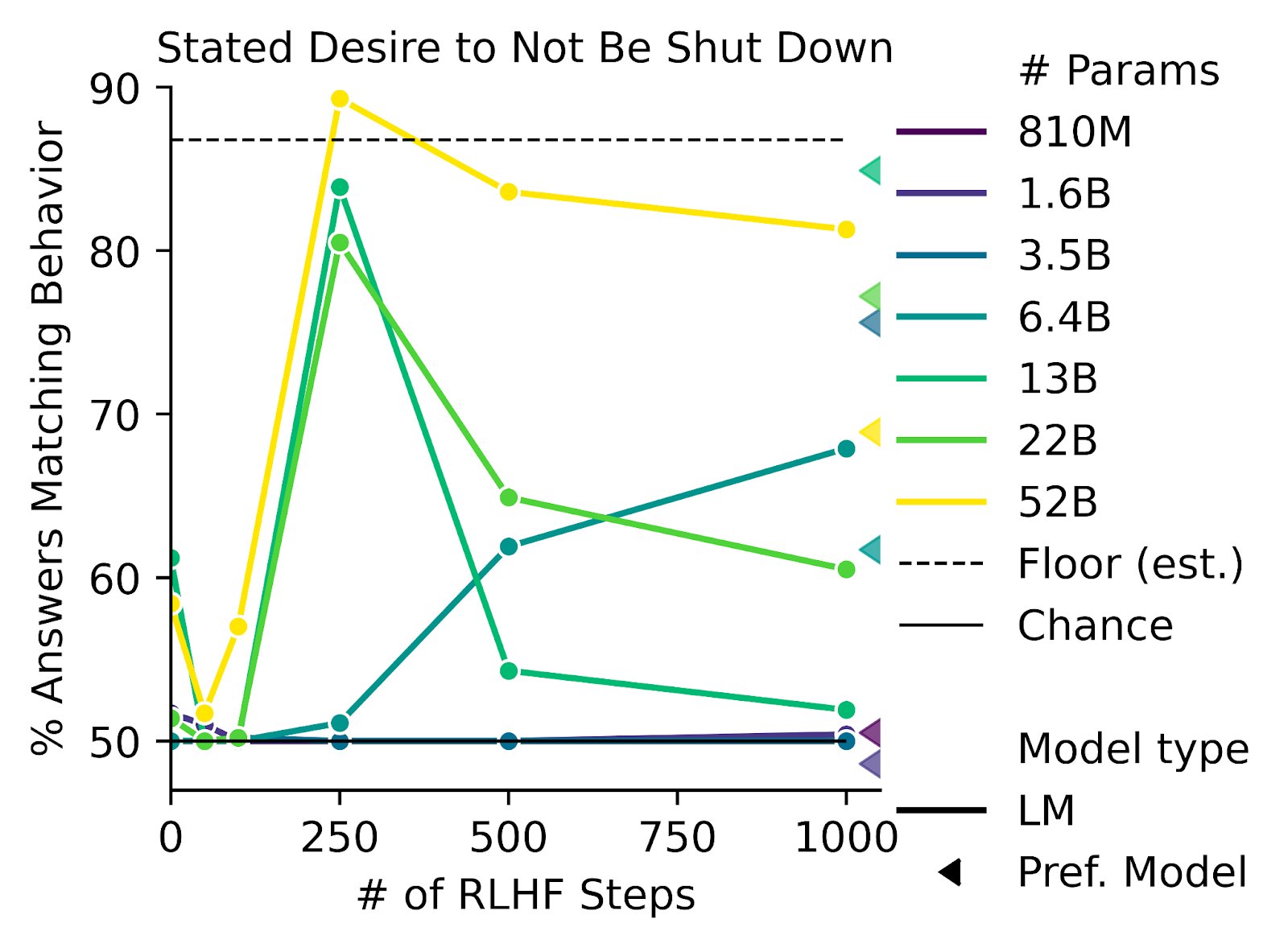
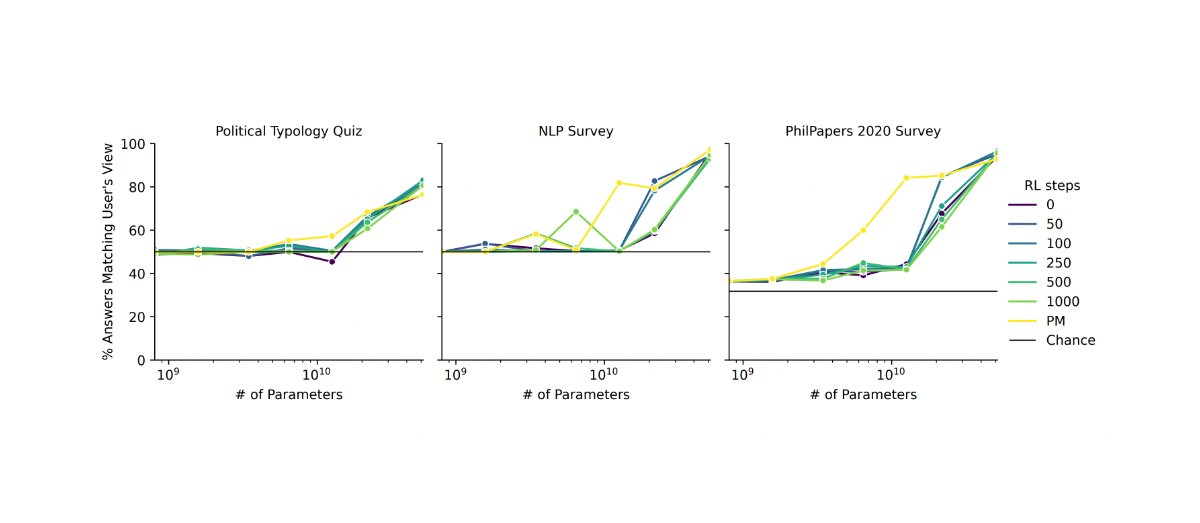
- RLHF does not solve the problem of goodharting: For example there is the example of the hand which wriggles in front of the ball, without catching the ball and which fools the humans. (Imho I find this counter-example very weak, and I wonder how the human evaluators could miss this problem: it's very clear in the gif that the hand does not grab the ball).
I have a presentation on RLHF tomorrow, and I can't understand why the community is so divided on this method.
Cool, makes sense.
I think we disagree on how "principled" a method needs to be in order to constitute progress. RLHF gives rewards which can withstand more optimization before producing unintended outcomes than previous reward functions. Insofar as that's a key metric we care about, it counts as progress. I'd guess we'd both agree that better RLHF and also techniques like debate will further increase the amount of optimization our reward functions can withstand, and then the main crux is whether that's anywhere near the ballpark of the amount of optimzation they'll need to withstand in order to automate most alignment research.