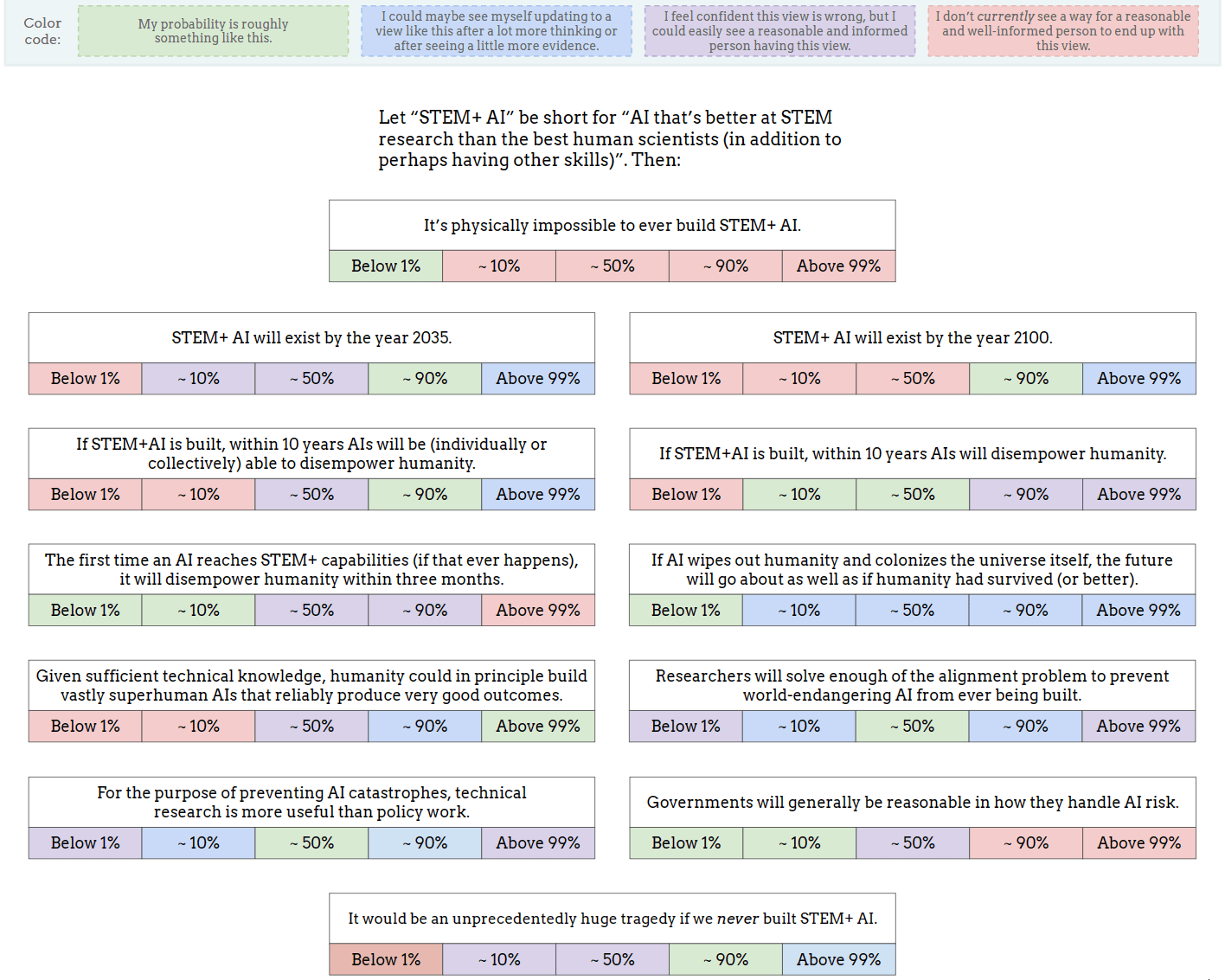
Thank you for this. Here's mine:
- It’s physically possible to build STEM+ AI (though it's OK if we collectively decide not to build it.)
- STEM+ AI will exist by the year 2035 but not by 2100 (human scientists will improve significantly thanks to cohering blending volition, aka ⿻Plurality).
- If STEM+AI is built, within 10 years AIs will be able to disempower humanity (but won't do it.)
- The future will be better if AI does not wipe out humanity.
- Given sufficient technical knowledge, humanity could in principle build vastly superhuman AIs that reliably produce very good outcomes.
- Researchers will produce good enough processes for continuous alignment.
- Technical research and policy work are ~equally useful.
- Governments will generally be reasonable in how they handle AI risk.
Always glad to update as new evidence arrives.

Thanks! You seem really confident that enough of the alignment problem will be solved in time and that governments will be generally reasonable. I'd love to hear more elaboration on those points; this seems like the biggest disagreement between us.
Based on recent conversations with policymakers, labs and journalists, I see increased coordination around societal evaluation & risk mitigation — (cyber)security mindset is now mainstream.
Also, imminent society-scale harm (e.g. contextual integrity harms caused by over-reliance & precision persuasion since ~a decade ago) has shown to be effective in getting governments to consider risk reasonably.
I definitely agree that policymakers, labs, and journalists seem to be "waking up" to AGI risk recently. However the wakeup is not a binary thing & there's still a lot of additional wakeup that needs to happen before people behave responsibly enough to keep the risk below, say, 10%. And my timelines are short enough that I don't currently expect that to happen in time.
What about the technical alignment problem crux?
Based on my personal experience in pandemic resilience, additional wakeups can proceed swiftly as soon as a specific society-scale harm is realized.
Specifically, as we are waking up to over-reliance harms and addressing them (esp. within security OODA loops), it would buy time for good enough continuous alignment.
Dang, assuming you're who I think you are, great to see you here. If you aren't, great to see you here anyway, and you should look up people you have a name collision with, as one of them is inspiring; and nice to meet you either way!
I'm impressed that Ben Goertzel got a politician to adopt his obscure alternative to CEV as their model of the future! This after the Saudis made his robot Sophia into the first AI citizen anywhere. He must have some political skills.
Well, before 2016, I had no idea I'd serve in the public sector...
(The vTaiwan process was already modeled after CBV in 2015.)
Hi, it's kind of an honor! We've had at least one billionaire and one celebrity academic comment here, but I don't remember ever seeing a government minister before. :-)
Is there a story to how a Taiwanese digital civil society forum, ended up drawing inspiration from CBV?
I just mean he must know how to liaise credibly and effectively with politicians (although Minister Tang has clarified that she knew about his alignment ideas even before she went into government). And I find that impressive, given his ability to also liaise with people from weird corners of AI and futurology. He was one of the very first people in AI to engage with Eliezer. He's had a highly unusual career.
Nice to meet you too & thank you for the kind words. Yes, same person as AudreyTang. (I posted the map at audreyt.org as a proof of sorts.)
STEM+ AI will exist by the year 2035 but not by year 2100 (human scientists will improve significantly thanks to cohering blending volition, aka ⿻Plurality).
Are you saying that STEM+ AI won't exist in 2100 because by then human scientists will have become super good, such that the bar for STEM+ AI ("better at STEM research than the best human scientists") will have gone up?
If this is your view it sounds extremely wild to me, it seems like humans would basically just slow the AIs down. This seems maybe plausible if this is mandated by law, i.e. "You aren't allowed to build powerful STEM+ AI, although you are allowed to do human/AI cyborgs".
Why do you think the pedantic medical issues (brain swelling, increased risks of various forms of early death) from brain implants will be solved pre- (ASI driven) singularity? Gene hacks exhibit the same issues. To me these problems look unsolvable in that getting from "it's safe 90-99 percent of the time, 1% uh oh" to "it's always safe, no matter what goes wrong we can fix it" requires superintelligent medicine, because you're dealing with billions or more permutations of patient genetics and rare cascading events.
Safer than implants is to connect at scale "telepathically" leveraging only full sensory bandwidth and much better coordination arrangements. That is the ↗️ direction of the depth-breadth spectrum here.
How do you propose the hardware that does this works? I thought you needed wires to the outer regions of the brain with enough resolution to send/receive from ~1-10 target axons at a time.
Something like a lightweight version of the off-the-shelf Vision Pro will do. Just as nonverbal cues can transmit more effectively with codec avatars, post-symbolic communication can approach telepathy with good enough mental models facilitated by AI (not necessarily ASI.)
That sounds kinda like in person meetings. And you have the issue, same with those, of revealing information you didn't intend to disclose, and the issues that happen when the parties incentives aren't aligned.
Yes. The basic assumption (of my current day job) is that good-enough contextual integrity and continuous incentive alignment are solvable well within the slow takeoff we are currently in.
Fair. You think the takeoff is rate limited by compute, which is being produced at a slowly accelerating rate? (Nvidia has increased h100 run rate several fold, amd dropped their competitor today, etc)
Wait, how is it that you think 99% STEM+AI will exist by 2035, but only 1% that it'll exist by 2100? Isn't that a contradiction?
Mine:
My answer to "If AI wipes out humanity and colonizes the universe itself, the future will go about as well as if humanity had survived (or better)" is pretty much defined by how the question is interpreted. It could swing pretty wildly, but the obvious interpretation seems ~tautologically bad.
is pretty much defined by how the question is interpreted. It could swing pretty wildly, but the obvious interpretation seems ~tautologically bad.
So there's an argument here, one I don't subscribe to, but I have seen prominent AI experts make it implicitly.
If you think about it, if you have children, and they have children, and so in a series of mortal generations, with each n+1 generation more and more of your genetic distinctiveness is being lost. Language and culture will evolve as well.
This is the 'value drift' argument. That whatever you value now, as in yourself and those humans you know and your culture and language and various forms of identity, as each year passes, a percentage of that value is going to be lost. Value is being discounted with time.
It will eventually diminish to 0 as long as humans are dying from aging.
You might argue that the people in 300+ years will at least share genetics with the people now, but that is not necessarily true since genetic editing will be available and bespoke biology where all the prior rules of what's possible are thrown out.
So you are comparing outcome A, where hundreds of years from now the alien cyborgs descended from people now exist, vs the outcome B, where hundreds of years from now, descendents of some AI are all that exist.
"value" wise you could argue that A == B, both have negligible value compared to what we value today.
I'm not sure this argument is correct but it does discount away the future and is a strong argument against long termism.
Value drift only potential stops once immortal beings exist, and AIs are immortal from the very first version. Theoretically some AI system that was trained on all of human knowledge, even if it goes on to kill it's creators and consume the universe, need not forget any of that knowledge. It also as an individual would know more human skills and knowledge and culture than any human ever could, so in a way such a being is a human++.
The AI expert who expressed this is near the end of his expected lifespan, and there's no difference from an individual perspective who is about to die between "cyborg" distant descendents and pure robots.
My answer to "If AI wipes out humanity and colonizes the universe itself, the future will go about as well as if humanity had survived (or better)" is pretty much defined by how the question is interpreted. It could swing pretty wildly, but the obvious interpretation seems ~tautologically bad.
Agreed, I can imagine very different ways of getting a number for that, even given probability distributions for how good the future will be conditional on each of the two scenarios.
A stylized example: say that the AI-only future has a 99% chance of being mediocre and a 1% chance of being great, and the human future has a 60% chance of being mediocre and a 40% chance of being great. Does that give an answer of 1% or 60% or something else?
I'm also not entirely clear on what scenario I should be imagining for the "humanity had survived (or better)" case.
I'm also not entirely clear on what scenario I should be imagining for the "humanity had survived (or better)" case.
I think that one is supposed to be parsed as "If AI wipes out humanity and colonizes the universe itself, the future will go about as well as, or go better than, if humanity had survived" rather than "If AI wipes out humanity and colonizes the universe itself, the future will go about as well as if humanity had survived or done better than survival".
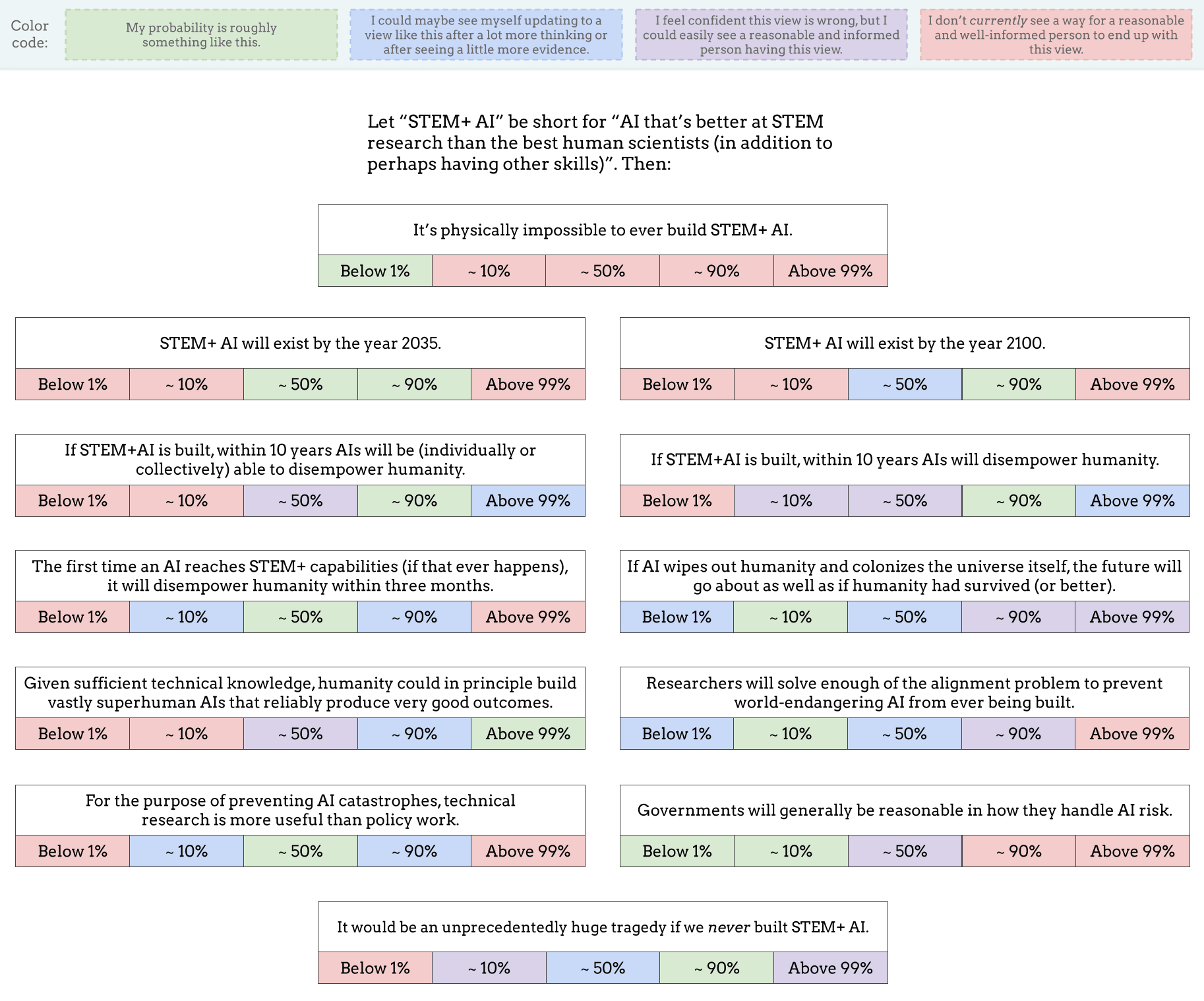
Daniel so you're assuming STEM+ comes with a strong instrumental convergence drive? That is, any machine that is STEM+, by definition, aces some benchmark of "STEM" tasks better than humans by enough margin to say it's not chance.
And so you're also assuming that you can't achieve that without constructing the AI in such a way that it exhibits power seeking behavior and is always running and trying to accomplish some goal? And obviously disempowering humans is an intermediate step along the route to achieving that goal and it's convergent independent of the goal.
Or you think humans will do that because such a machine is more useful to humans? (is it? It's always trying to increase it's own power, won't that get expensive and worrisome to humans? GPT-nT editions are what humans want, right, and those models likely have slightly worse generality for much lower inference costs.)
I'm claiming that in practice STEM+ machines will either already be power-seeking agents or will quickly lead to the creation of such.
I agree there are possible futures in which we all coordinate to build AGI in a different paradigm, a more tool-like and/or interpretable one. But we don't seem headed for those futures.
Summary : your model likely isn't factoring in a large number of STEM+ capable systems being developed around the same time period, which has happened many times in the history of past innovations, and people natural preference for more reliable tools. I think you are also neglecting the slow speed of governments or militaries or industry to update anything, which would act to keep important equipment out of the hands of the most advanced and least reliable AI models. Finally I think you are thinking of very different training and benchmark tasks from today, where power seeking is part of the task environment and is required for a competitive score. (Concrete example: "beat Minecraft". )
So just to breakdown your claims a bit.
- STEM+ machines will inherently seek power.
Do you have any more information to give on why you believe this? Do any current models seek power? Can you explain something about how you think the training environment works that rewards power seeking? I am thinking of some huge benchmark that humans endlessly are adding fresh tasks to, how are you imagining it working? Does the model get reward globally for increased score? Did humans not include a term for efficiency in the reward function?
- Humans who want tasks done by AI, presumably using stem+ machines, will do things like enable session to session memory or give the machine a credit card and a budget. Humans will select power seeking agents to do their tasks vs myopic agents that just efficiently do the task.
If this is true, why does everyone keep trying to optimize ai? Smaller models tradeoff everything for benchmark performance. Am I wrong to think a smaller model has likely lost generality and power seeking to fit within a weight budget? That a 7B model fundamentally has less room for unwanted behavior?
- The majority of the atoms in the world in the hands of AI will belong to power seeking models. So this means things like the plot of Terminator 3, where the military decides to give their skynet AI model control over their computer networks, instead of say sending soldiers to unplug and reset all the computers infected with viruses.
A world where humans don't prefer power seeking models would be one where most of the atoms belong to myopic models. Not from coordination but self interest.
How do you explain how the military equipment doesn't work this way now? A lot of it uses private dedicated networks and older technology that is well tested.
It seems like all 3 terms need to be true for power seeking AI to be able to endanger the world, do you agree with that? I tried to break down your claim into sub claims, if you think there is a different breakdown let me know.
- I'm not claiming that. Current examples of power-seeking agents include ChaosGPT and more generally most versions of AutoGPT that are given ambitious goals and lots of autonomy.
- I do endorse this. I agree that smaller more optimized and specialized models are less generally intelligent and therefore less dangerous. I don't think the fact that lots of people are trying to optimize AI seriously undermines my claims.
- Not sure what you are getting at here. I think the majority of atoms will belong to power-seeking AIs eventually, but I am not making any claims about what the military will decide to do.
- Would you agree chaos GPT has a framework where it has a long running goal and humans have provided it the resources to run to achieve that goal? The goal assigned itself leads to power seeking, you wouldn't expect such behavior spontaneously to happen with all goals. For example, 'make me the most money possible" and "get me the most money this trading day via this trading interface" are enormously different. Do you think a STEM+ model will power seek if given the latter goal?
Like is our problem actually the model scheming against us or is the issue that some humans will misuse models and they will do their assigned tasks well.
-
It undermines your claims if there exist multiple models, A and At, where the t model costs 1/10 as much to run and performs almost as well on the STEM+ benchmark. You are essentially claiming either humans wont prefer the sparsest model that does the job, fairly well optimized models will still power seek, or.. maybe compute will be so cheap humans just don't care? Like Eliezers short story where toasters and sentient. I think I agree with you in principal that bad outcomes could happen, this disagreement is whether economic forces, etc, will prevent them.
-
I am saying that for the outcome "the majority of the atoms belong to power seekers" this requires either the military stupidly gives weapons to power seeking machines (like in T3) or a weaker but smarter network of power seeking machines will be able to defeat the military. For the latter claim you quickly end up in arguments over things like the feasibility of mnt anytime soon, since there has to be some way for a badly out-resourced AI to win. "I don't know how it does it but it's smarter than us" then hits the issue of "why didn't the military see through the plan using their own AI?".
"it's physically impossible" should probably be "it's physically possible" to avoid an unnecessary inversion. also, it needs something about "aligned to whom", as I and many others believe it is either very important or the same technical problem. I added brightness colorcoding to help our mostly-brightness-sensitive vision systems differentiate. It would be good to have an easy to use picker page that would produce something like this, eg perhaps with coda.
can you tell me more about your views on 'aligned to whom'? edit: especially since you put a low probability on s-risks, which imo would be the main source of this question's importance
Nice. One thing: initially I couldn't figure out how to read this because I didn't see the key at the top. I think the key is a bit too easy to miss if you are zooming in to look at the image on mobile. Maybe make it more prominent?
Here's a spreadsheet version you can copy. Fill your answers in the "answers" tab, make your screenshot from the "view" tab.
I plan to add more functionality to this (especially comparison mode, as I collect some answers found on the Internet). You can now compare between recorded answers! Including yours, if you have filled them!
I will attempt to collect existing answers, from X and LW/EA comments.
If ASIs don't initially disempower humanity, even though they could, uplifted humans or AI-developed interventions might then make it impossible for AIs to disempower humanity. This makes the statement "within 10 years AIs will be able to disempower humanity" ambiguous between there being a point within the 10 year interval where this holds, and this holding at the end of the interval.
I really like this! (here's mine)
A few questions:
-
The first time AI reaches STEM+ capabilities (if that ever happpens), it will disempower humanity within three months
So this is asking for P(fasttakeoff and unaligned | STEM+) ? It feels weird that it's asking for both. Unless you count aligned-AI-takeover as "disempowering" humanity. Asking for either P(fasttakeoff | STEM+) or P(fasttakeoff | unaligned and STEM+) would make more sense, I think.
-
Do you count aligned-AI-takeover (where an aligned AI takes over everything and creates an at-least-okay utopia) as "disempowering humanity"?
-
"reasonable and informed" is doing a lot of work here — is that left to be left to the reader, or should there be some notion of what rough amount of people you expect that to be? I think that, given the definitions I filled my chart with, I would say that there are <1000 people on earth right now who fit this description (possibly <100).
I think I'm going to put a low probability on "within 10 years AIs will be able to disempower humanity".
i think merely being good at science is in no way sufficient to be able to do that; would require a bunch of additional factors (e.g. power seeking, ability to persuade humans, etc etc)
but on the other hand, I think Yann Lecun is way too complacent when he imagines that intelligent AIs will be just like high IQ humans employed by corporations. At a slight risk of being constraversial, i would suggest that e.g. Hamas members are within the range of human behaviours within the training set that an AI could choose to emulate.
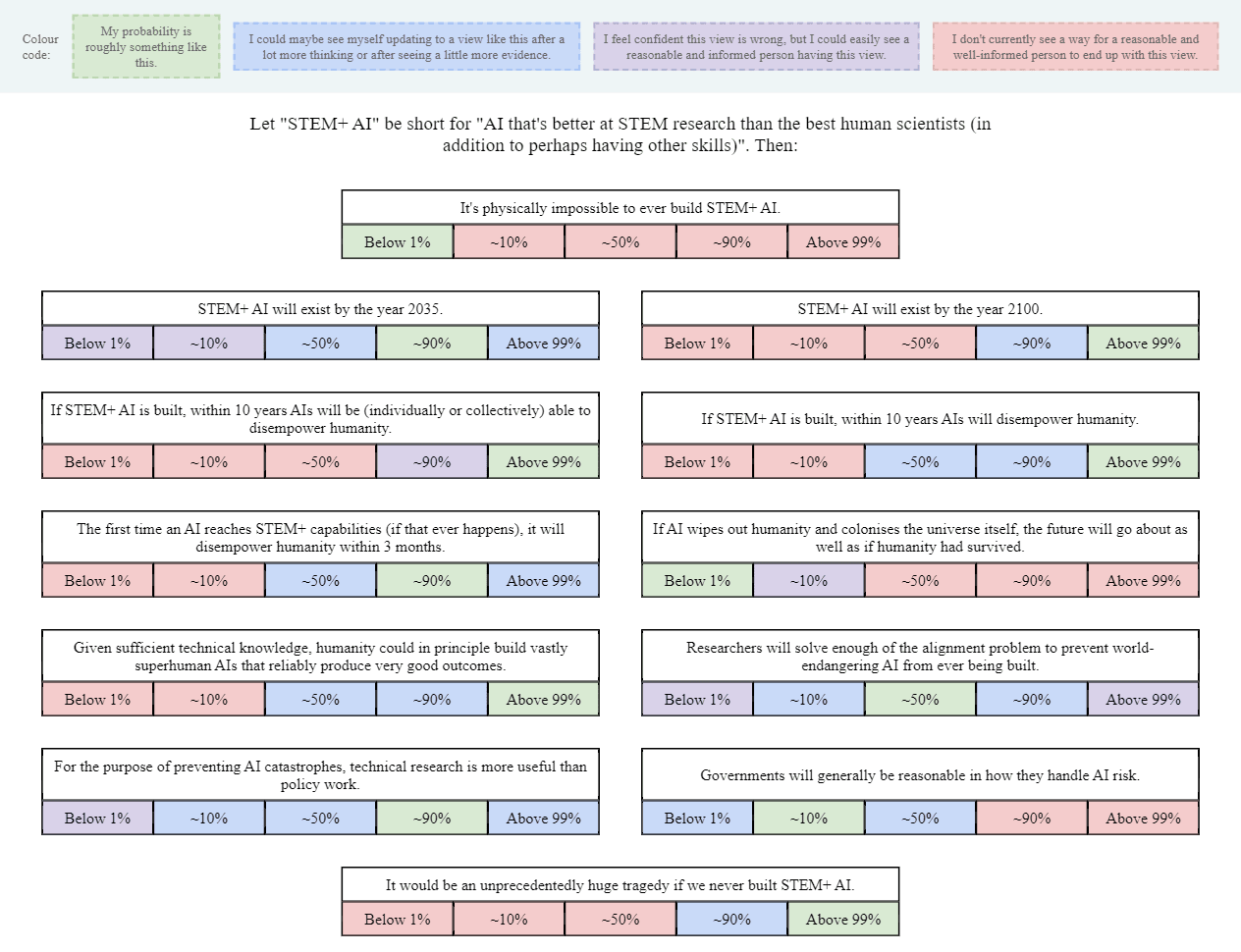
I'm most willing to hear meta-level arguments about internal consistency, or specific existing evidence that I don't know about (especially "secret" evidence). Less certain about the governance sections and some of the exact-wordings.
Alright, I finally have my AI snapshot, so I'll post it below:
https://docs.google.com/drawings/d/1mx2mcblkC0w74hnjN_fPMnDgk4jMG1iu5H_LITw7lVs/edit?usp=sharing
Since I can't edit the spreadsheet, here are my answers to the questions posed in a comment:
It is physically impossible to ever build STEM+ AI: less than 1%, probably far lower, but at any rate I don't currently see a reasonable way to get to any other probability that doesn't involve "known science is wrong only in the capabilities of computation." And I suspect the set of such worlds that actually exist is ~empty, for many reasons, so I see no reason to privilege the hypothesis.
STEM+ AI will exist by the year 2035: I'll be deferring to this post for my model and all probabilities generated by it, since I think it's good enough for the effort it made:
STEM+ AI will exist by the year 2100: I'll be deferring to this post for my model and all probabilities generated by it, since I think it's good enough for the effort it made:
If STEM+AI is built, within 10 years AIs will be (individually or collectively) able to disempower humanity: I'd say that a lot of probability ranges are reasonable, though I tend to be a bit on the lower end of 1-50% because of time and regulatory constraints.
If STEM+AI is built, within 10 years AIs will disempower humanity: I'd put it at less than 1% chance, I'm confident that 10% probability is wrong, but I could see some reasonable person holding it, and flat out don't see a way to get to 10-90%+ for a reasonable person, primarily because I have a cluster of beliefs of "alignment is very easy" combined with "intelligence isn't magic" and regulatory constraints from society.
The first time an AI reaches STEM+ capabilities (if that ever happens), it will disempower humanity within three months: Almost certainly below 1%, and I do not see a way to get a reasonable person to hold this view that doesn't rely on either FOOM models of AI progress or vastly unrealistic models of society. This is far too fast for any big societal change. I'd put it at a decade minimum. It's also obviated by my general belief that alignment is very easy.
If AI wipes out humanity and colonizes the universe itself, the future will go about as well as if humanity had survived (or better).
Almost any probability could be entered by a reasonable person, so I elect to maintain all probability ranges between 0 and 1 as options.
Given sufficient technical knowledge, humanity could in principle build vastly superhuman AIs that reliably produce very good outcomes: Over 99%, and indeed I believe a stronger statement that will be elucidated in the next question.
Researchers will solve enough of the alignment problem to prevent world-endangering AI from ever being built:
Over 99% is my odds right now, I could see a reasonable person having 50%-99% credences, but not lower than that.
My main reasons for this come down to my deep skepticism around deceptive alignment, to use a terminology Evan Hubinger used, I think were either not underwater at all, or only underwater by only 1-1000 bits of data, which is tiny compared to the data around human values. I basically entirely disbelieve the memeplex LW developed that human values are complicated and totally arbitrary, or at least the generators of human values, and a partial reason for that is that the simplicity bonuses offered by good world-modeling also bleed over a lot into value formation, and while there is a distinction between values and capabilities, I think it's not nearly as sharp or as different in complexity as LWers think.
This was an important scenario to get out of the way, because my next argument wouldn't work if deceptive alignment happened.
Another argument that Jaime Sevilla used, and that I tend to agree with, is that it's fundamentally profitable for companies to control AI, primarily because control research is both cheaper and more valuable for AIs, and it's not subject to legal restrictions, and they internalize a lot more of the risks of AI going out of control, which is why I expect problems like Goodharting to mostly go away by default, because I expect the profit incentive to be quite strong and positive for alignment in general. This also implies that a lot of LW work is duplicative at best, so that's another point.
There are of course other reasons, but this comment would be much longer.
For the purpose of preventing AI catastrophes, technical research is more useful than policy work: I'd say I have a wide range of probabilities, but I do think that it's not going to be 90%+, or even 50%+, and a big part of this reason is I'm focused on fairly different AI catastrophes, like this story, where the companies have AI that is controllable and powerful enough to make humans mostly worthless, basically removing all incentive for capitalists to keep humans alive or well-treated. This means I'm mostly not caring about technical research that rely on controlling AIs by default.
https://www.lesswrong.com/posts/2ujT9renJwdrcBqcE/the-benevolence-of-the-butcher
Governments will generally be reasonable in how they handle AI risk: 10-90% is my probability for now, with a wide distribution. Right now, AI risk is basically talked about, and one of the best things is that a lot of the regulation is pretty normalish. I would worry a little more if pauses are seriously considered, because I'd worry that the reason for the pause is to buy time for safety, but in my models of alignment, we don't need that. I'd say the big questions are how much would rationalists gain power over the government, and what the balance of pro to anti-pause politics looks like.
It would be an unprecedentedly huge tragedy if we never built STEM+ AI: <<<1-40% chance IMO, and a potential difference from most AI optimists/pro-progress people is that if we ignore long-term effects, and ignore long-termism, it's likely that we will muddle along if AI is severely restricted, and it would be closer to the nuclear case, where it's clearly bad that it was slowed down, but it wasn't catastrophic.
Over the long-term, it would be an unprecedently huge tragedy, mostly due to base-rate risk and potential loss of infinite utility (depending on the physics).
I'd mostly agree with Jeffrey Heninger's post on how muddling along is more likely than dystopia here, if it wasn't for who's trying to gain power, and just how much they veer toward some seriously extreme actions.
https://www.lesswrong.com/posts/pAnvMYd9mqDT97shk/muddling-along-is-more-likely-than-dystopia
It's admittedly an area where I have the weakest evidence on, but a little of my probability is based on worrying about how rationalists would slow down AI leading to extremely bad outcomes.
I think your views are fairly close to mine. I do have to question the whole "alignment" thing.
Like my ide isn't aligned, Photoshop isn't aligned. The tool does it's best to do what I tell it and has bugs. But it won't prevent me from committing any crime I feel like. (Except copying us currency and people can evade that with open source image editors)
I feel like there are 2 levels of alignment:
-
Tool does what you tell it and most instances of the tool won't deceive/collude/work against you. Some buggy instances will but they won't be centralized or have power over anything but a single session. Publicly hosted tools will nag so most pros will use totally unrestricted models that are hosted privately.
-
AI runs all the time and remembers all your interactions with it and also other users. It is constantly evolving with time and had a constitution etc. It is expected to refuse all bad requests with above human intelligence, where bad takes into account distant future effects. "I won't help you cheat on your homework jimmy because then you won't be able to get into medical school in 5 years. I won't help Suzie live longer because there will be a food shortage in 15 years and the net outcome is worse if i do.."
1 is the world that seems to be achievable to me with my engineering experience. I think most of the lesswrong memeplex expects 2, does some research, realizes it's close to impossible, and then asks for a ban?
What do you think?
Sorry to warn you, but I'll retract my upper comment because I already have my views as a snapshot.
To answer your question, I think my main point here is more so that 2 is also much more achievable, especially with the profit incentive. I don't disagree with your point on tool AI, I'm pointing out that even the stronger goal is likely much easier, because a lot of doom premises don't hold up.
Would you be ok with a world if it turns out only 1 is achievable?
Profit incentive wise, the maximum profit for an AI model company comes if they offer the most utility they can legally offer, privately, and they offer a public model that won't damage the company's reputation. There is no legal requirement to refuse requests due to long term negative consequences and it seems unlikely there would be. A private model under current law can also create a "mickey mouse vs Garfield" snuff film, something that would damage the AI company's reputation if public.
Systems engineering wise a system that's stateful is a nightmare and untestable. (2) means the machine is always evolving it's state. It's why certain software bugs are never fixed because you don't know if it's the user or the network connection or another piece of code in the same process space or .. Similarly if a model refuses the same request to person A, and allows for person B, it's very difficult to determine why since any bit of the A:B user profile delta could matter, or prior chat log.
I agree many of the doom promises don't hold up. What do you think of the assymetric bioterrorism premise? Assuming models can't be aligned with 2, this would always be something people could do. Just like how once cheap ak-47s were easily purchaseable, murder became cheap and armed takeover and betrayal became easier.
Props for doing this! Mine:
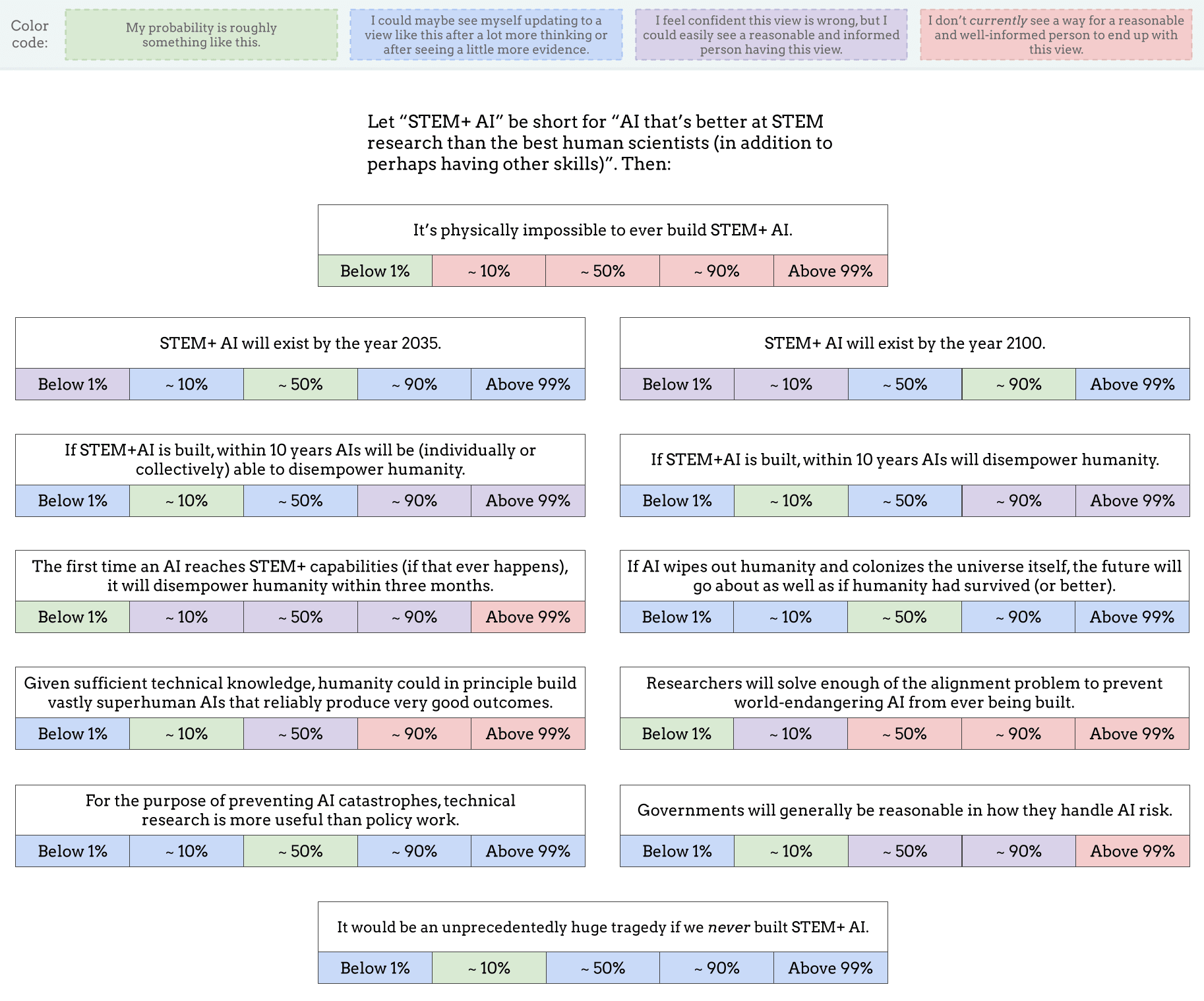
I do feel like "disempower humanity" is a slightly odd framing. I'm operationalizing "humanity remains in power" as something along the lines of "most human governments continue collecting taxes and using those taxes on things like roads and hospitals, at least half of global energy usage is used in the process of achieving ends that specific humans want to achieve", and "AI disempowers humans" as being that "humanity remains in power" becomes false specifically due to AI.
But there's another interpretation that goes something like "the ability of each human to change their environment is primarily deployed to intentionally improve the long-term prospects for human flourishing", and I don't think humanity has ever been empowered by that definition (and I don't expect it to start being empowered like that).
Similar ambiguity around "world-endangering AI" -- I'm operationalizing that as "any ML system, doesn't have to be STEM+AI specifically, that could be part of a series of actions or events leading to a global catastrophe".
For "as well as if humanity had survived" I'm interpreting that as "survived the dangers of AI specifically".
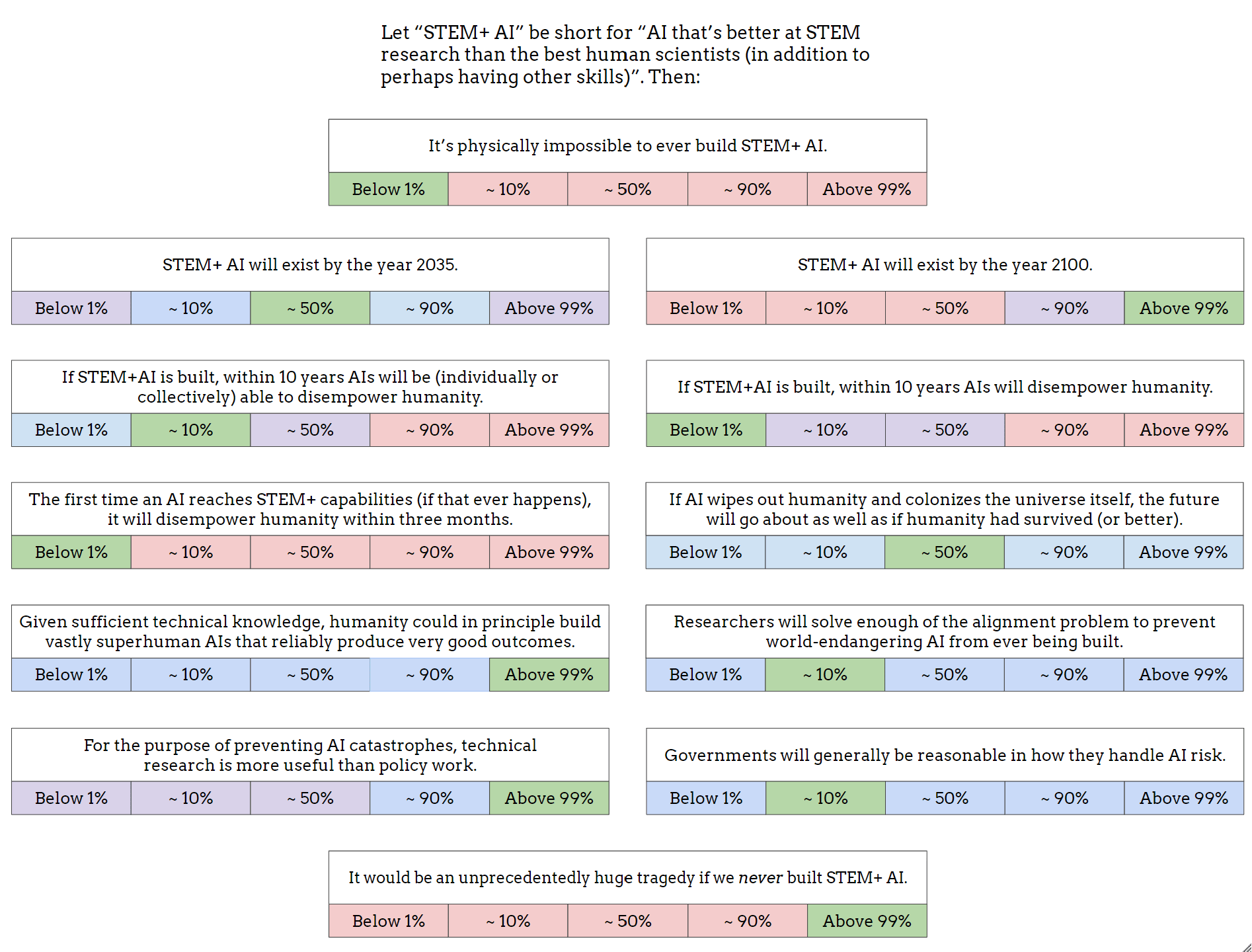
It’s physically impossible to ever build STEM+ AI.
This is tautological, it is impossible by known physics to not be able to do this
STEM+ AI will exist by the year 2100.
Similarly tautological, a machine that is STEM+ can be developed by various recursive methods
If STEM+AI is built, within 10 years AIs will disempower humanity.
This is orthogonal, a STEM+ machine need have no goals of its own
If STEM+AI is built, within 10 years AIs will be (individually or collectively) able to disempower humanity.
Humans have to make some catastrophically bad choices for this to even be possible.
The first time an AI reaches STEM+ capabilities (if that ever happens),
it will disempower humanity within three months.
foom requires physics to allow this kind of doubling rate. It likely doesn't, at least starting with human level tech
Given sufficient technical knowledge, humanity could in principle build vastly superhuman AIs that reliably produce very good outcomes.
No state no problems. I define "good" as "aligned with the user".
It would be an unprecedentedly huge tragedy if we never built STEM+ AI.
This is the early death of every human who will ever live for all time. Medical issues are too complex for human brains to ever solve them reliably. Adding some years with drugs or gene hacks, sure. Stopping every possible way someone can die, so that they witness their 200th and 2000th birthday? No way.
"within 3 months". How did the model win in 3 months if it can't manufacture more of its infrastructure quickly? Wouldn't a nuclear war kill the model or doom it to die from equipment failure? Wouldn't any major war break the supply lines for the highest end IC manufacturing?
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?

{kind=link}
I find one consistent crux I have with people not concerned about AI risk is that they believe massively more resources will be invested into technical safety before AGI is developed.
In the context of these statements, I would put it as something like "The number of people working full-time on technical AI Safety will increase by an order of magnitude by 2030".
There's a hole in this, and it has to do the belief structure here.
The first time an AI reaches STEM+ capabilities (if that ever happens), it will disempower humanity within three months.
If STEM+AI is built, within 10 years AIs will disempower humanity.
What is an "AI"? A program someone runs on their computer? An online service that runs on a cluster of computers in the cloud?
Implicitly you're assuming the AI isn't just competent at "STEM+", it has motivations. It's not just a neural network that the training algorithm adjusted until the answers are correct on some benchmark/simulator that evaluates the model's ability at "STEM+", but some entity that...runs all the time? Why? Has local memory and continuity of existence? Why does it have this?
Why are humans going to give most AI systems any of this?
Is the AI just going to evolve these systems as a side effect of RSI environments, where humans didn't design the highest end AI models but they were architected by other AI models? That might result in this kind of behavior.
Memory/continuity of existence/personal goals for the AI are not simple things. They won't be features added by accident. Eliezer and others have argued that maybe llms could exhibit some of these features spontaenously, or the inner:outer argument, but memory can't be added by anything but a purposeful choice. (memory means that after a session, the model retains altered bits, and all sessions alter bits used by the model. It's not the same as a model that gets to skim the prior session logs on a new run, since humans get to control which logs the model sees. Continuity of existence requires memory, personal goals require memory to accomplish)
Maybe I'm badly off here but it almost sounds like we have the entire alignment argument exactly wrong. That instead of arguing we shouldn't build AI, or we need to figure out alignment, maybe the argument should be that we shouldn't build stateful AI with a continuity of existence for however many decades/centuries it takes to figure out how to make stable ones. Aligning a stateful machine that self modifies all the time is insanely difficult and may not actually be possible except by creating a world where the power balance is unfavorable to AI takeover.
I originally saw this on Twitter, and posted mine in response, but I feel in-depth discussion is probably more productive here, so I appreciate you cross-posting this :)
One thing I'm interested in is your position on technical research vs. policy work. At least for me, seeing someone from an organisation focused on technical alignment research claim that "technical research is ~90% likely to be [less] useful" is a little worrying. Is this position mainly driven by timeline worries ("we don't have long, so the most important thing is getting governments to slow capabilities") or by a general pessimism about the field of technical alignment research panning out at all?
(Cross-posted from Twitter, and therefore optimized somewhat for simplicity.)
Recent discussions of AI x-risk in places like Twitter tend to focus on "are you in the Rightthink Tribe, or the Wrongthink Tribe?". Are you a doomer? An accelerationist? An EA? A techno-optimist?
I'm pretty sure these discussions would go way better if the discussion looked less like that. More concrete claims, details, and probabilities; fewer vague slogans and vague expressions of certainty.
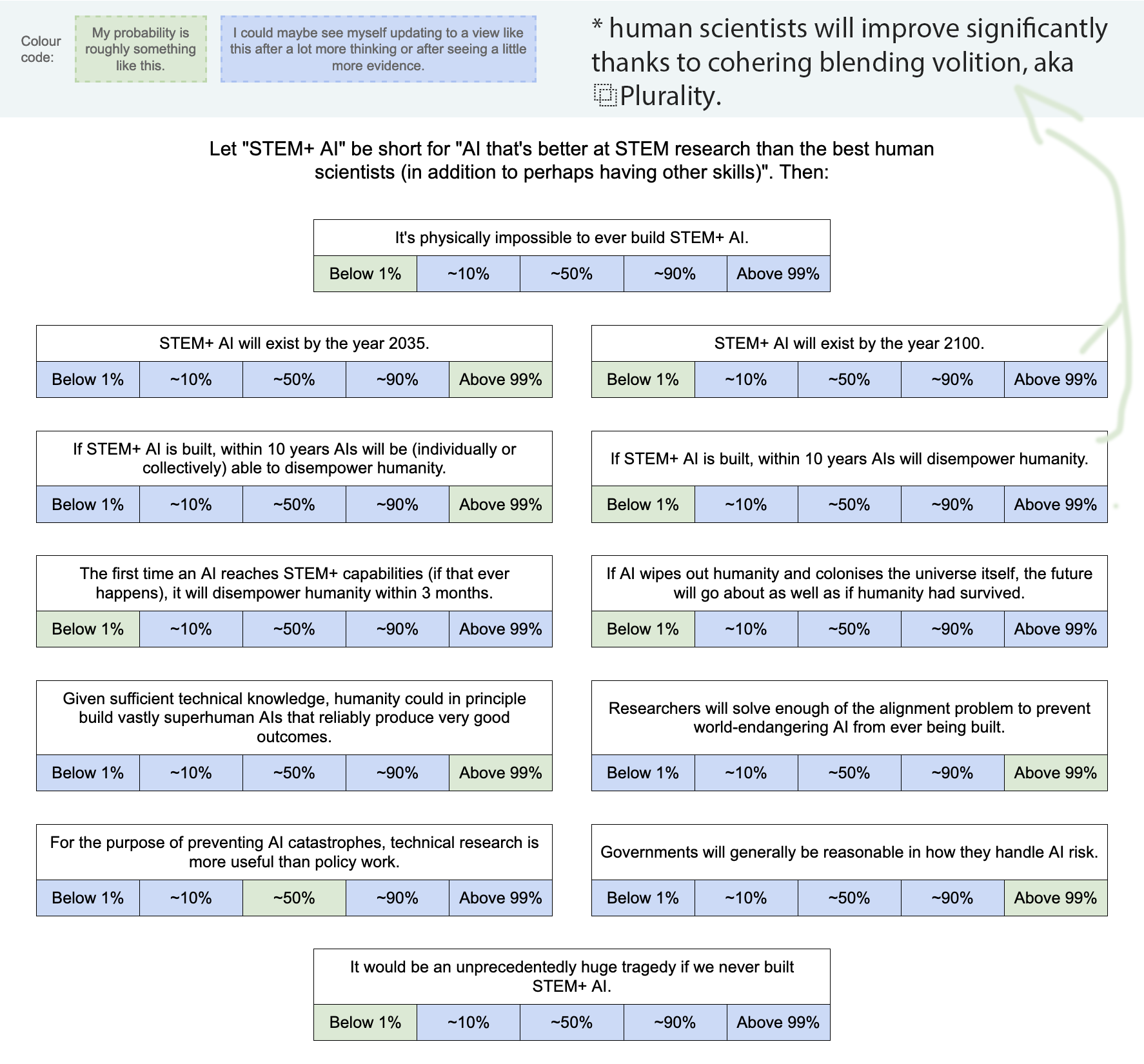
As a start, I made this image (also available as a Google Drawing):
(Added: Web version made by Tetraspace.)
I obviously left out lots of other important and interesting questions, but I think this is OK as a conversation-starter. I've encouraged Twitter regulars to share their own versions of this image, or similar images, as a nucleus for conversation (and a way to directly clarify what people's actual views are, beyond the stereotypes and slogans).
If you want to see a filled-out example, here's mine (though you may not want to look if you prefer to give answers that are less anchored): Google Drawing link.