(Cross-posted from Twitter, and therefore optimized somewhat for simplicity.)
Recent discussions of AI x-risk in places like Twitter tend to focus on "are you in the Rightthink Tribe, or the Wrongthink Tribe?". Are you a doomer? An accelerationist? An EA? A techno-optimist?
I'm pretty sure these discussions would go way better if the discussion looked less like that. More concrete claims, details, and probabilities; fewer vague slogans and vague expressions of certainty.
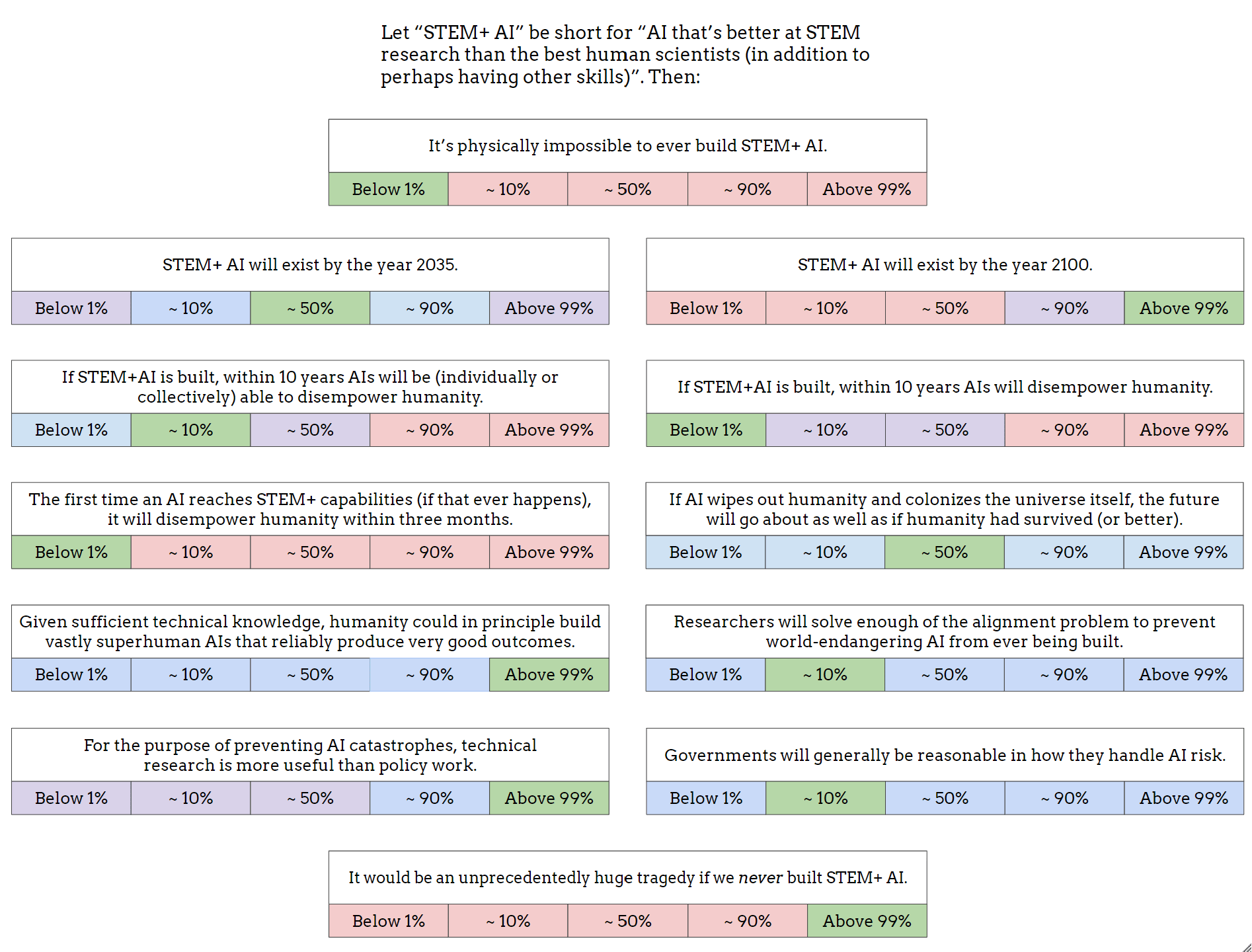
As a start, I made this image (also available as a Google Drawing):

(Added: Web version made by Tetraspace.)
I obviously left out lots of other important and interesting questions, but I think this is OK as a conversation-starter. I've encouraged Twitter regulars to share their own versions of this image, or similar images, as a nucleus for conversation (and a way to directly clarify what people's actual views are, beyond the stereotypes and slogans).
If you want to see a filled-out example, here's mine (though you may not want to look if you prefer to give answers that are less anchored): Google Drawing link.

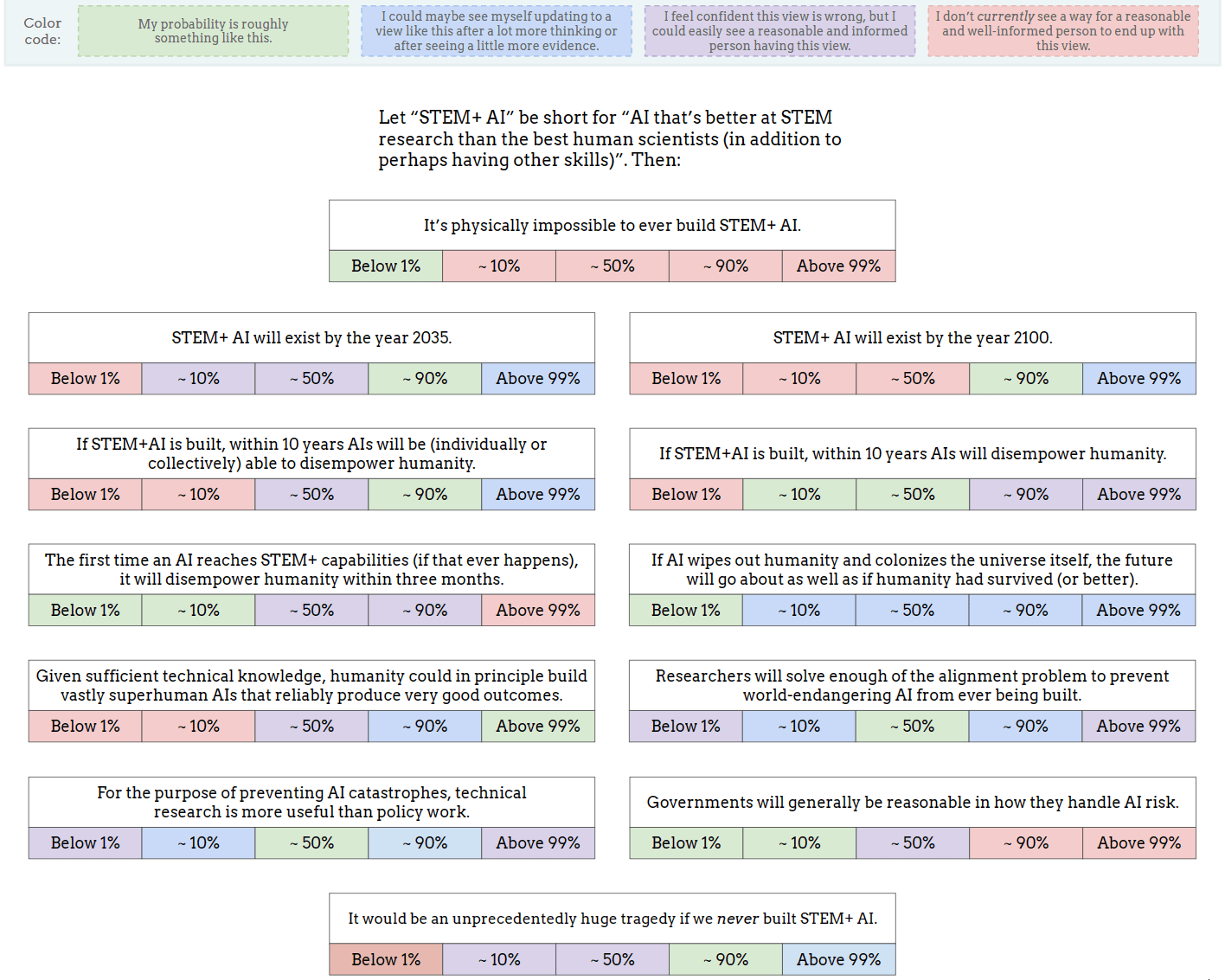
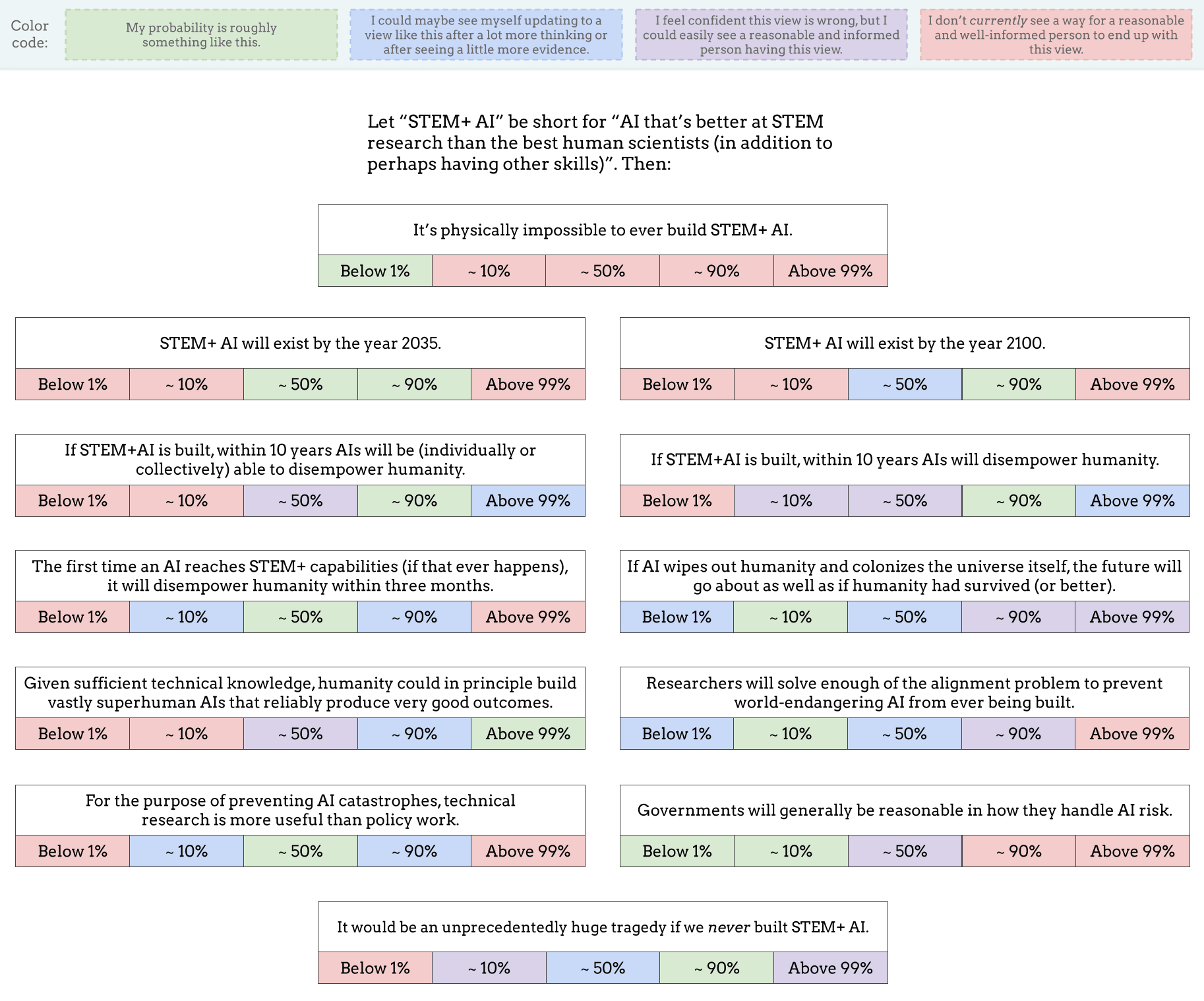
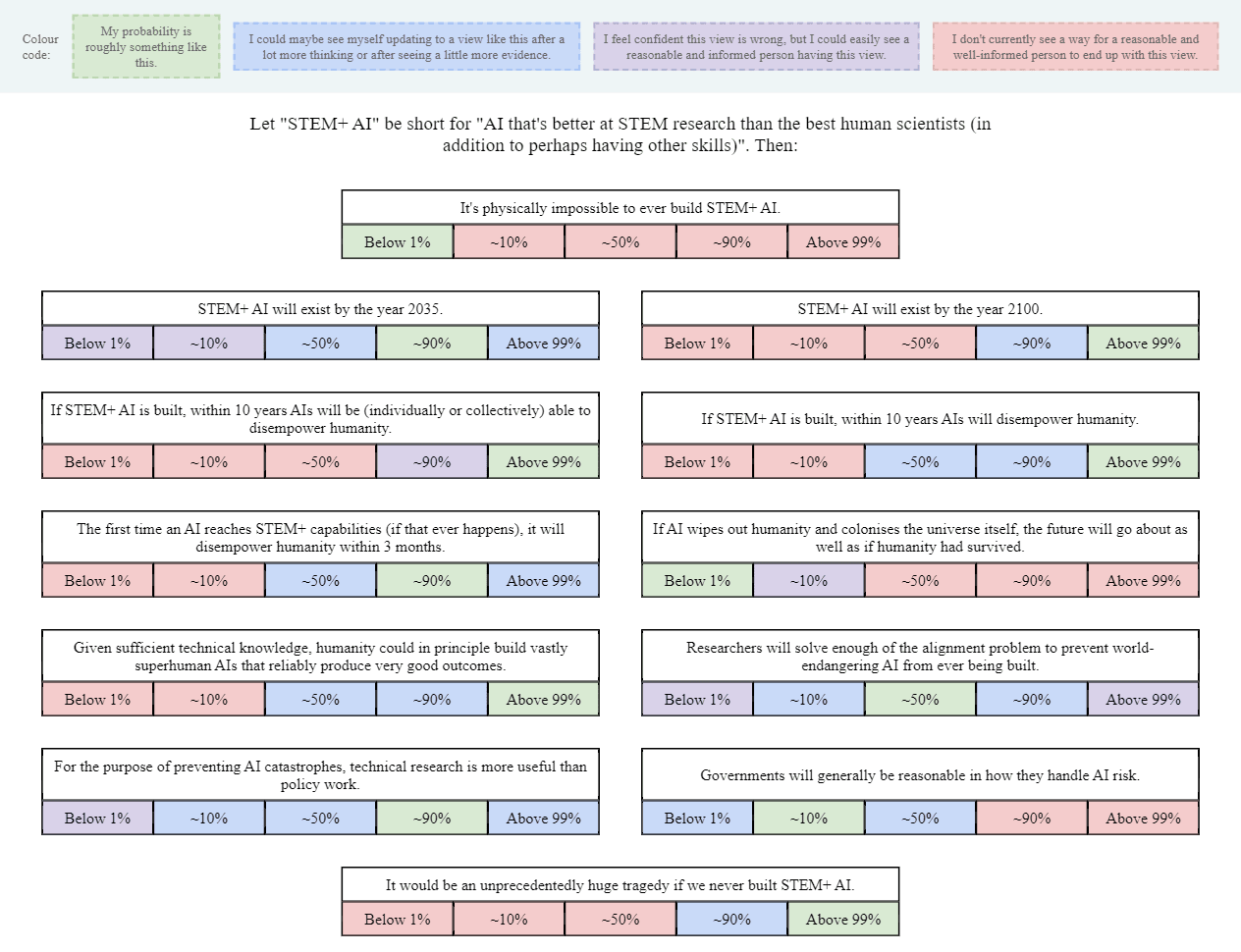
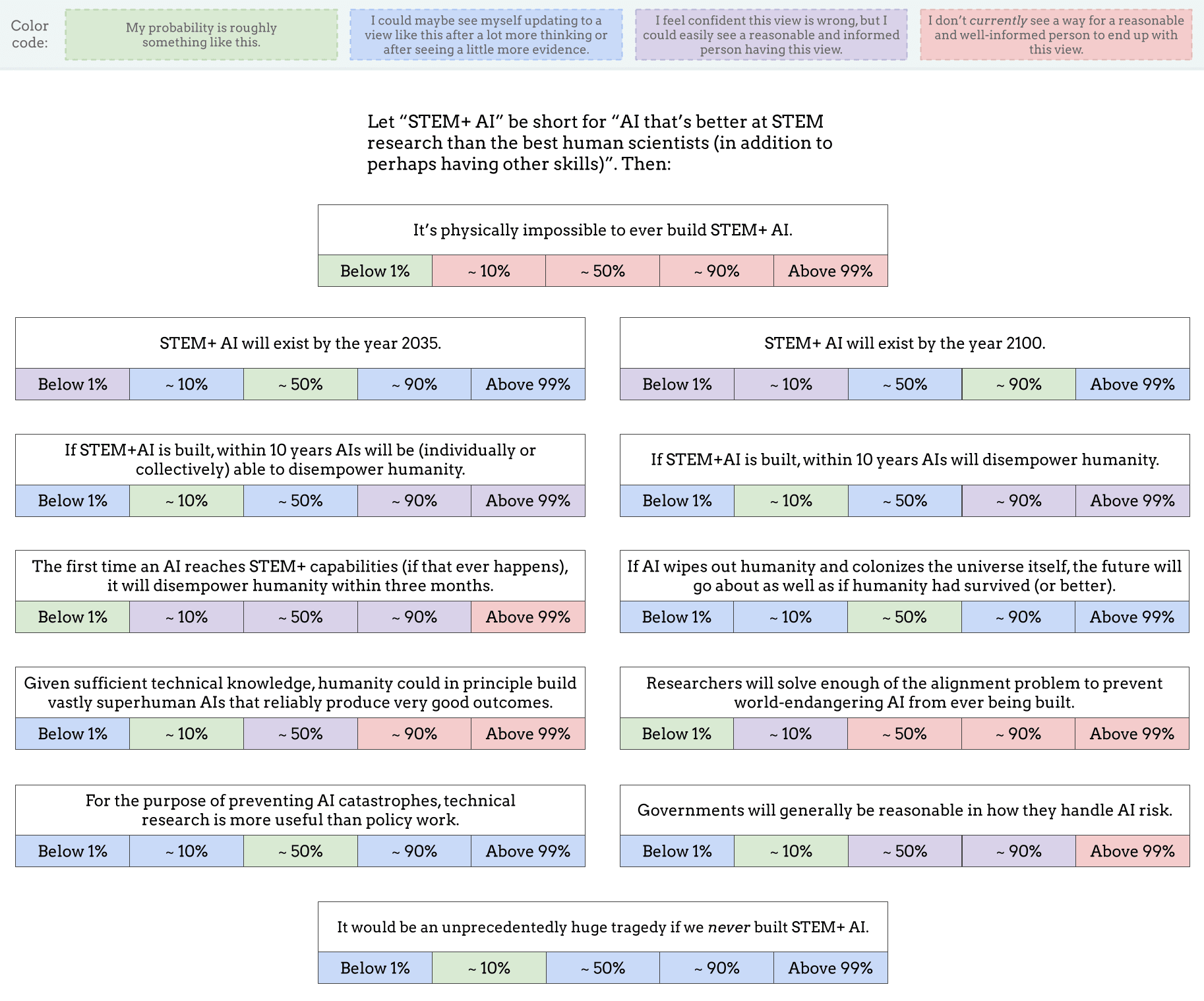

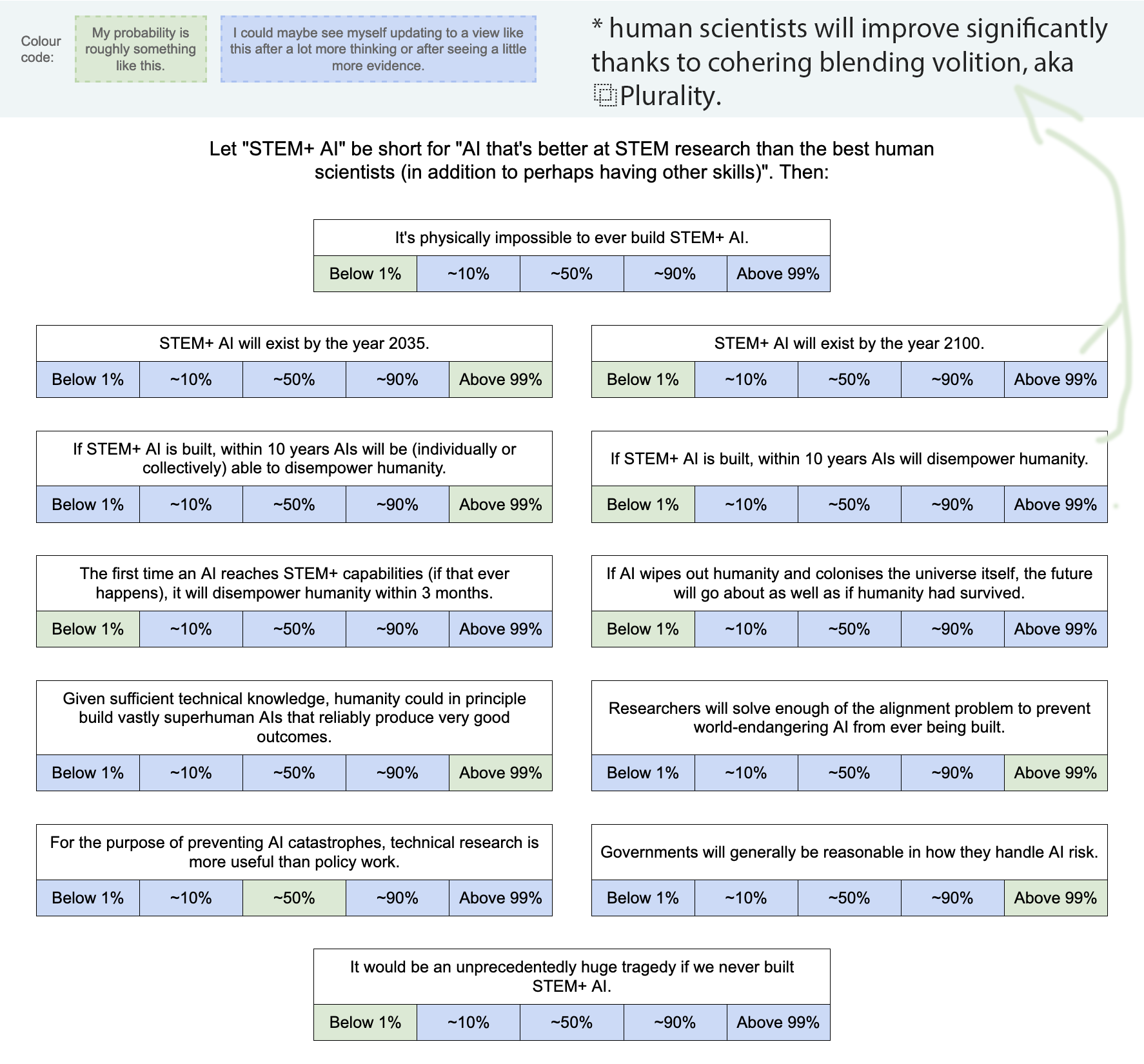{kind=link}
Since I can't edit the spreadsheet, here are my answers to the questions posed in a comment:
It is physically impossible to ever build STEM+ AI: less than 1%, probably far lower, but at any rate I don't currently see a reasonable way to get to any other probability that doesn't involve "known science is wrong only in the capabilities of computation." And I suspect the set of such worlds that actually exist is ~empty, for many reasons, so I see no reason to privilege the hypothesis.
STEM+ AI will exist by the year 2035: I'll be deferring to this post for my model and all probabilities generated by it, since I think it's good enough for the effort it made:
https://www.lesswrong.com/posts/3nMpdmt8LrzxQnkGp/ai-timelines-via-cumulative-optimization-power-less-long
STEM+ AI will exist by the year 2100: I'll be deferring to this post for my model and all probabilities generated by it, since I think it's good enough for the effort it made:
https://www.lesswrong.com/posts/3nMpdmt8LrzxQnkGp/ai-timelines-via-cumulative-optimization-power-less-long
If STEM+AI is built, within 10 years AIs will be (individually or collectively) able to disempower humanity: I'd say that a lot of probability ranges are reasonable, though I tend to be a bit on the lower end of 1-50% because of time and regulatory constraints.
If STEM+AI is built, within 10 years AIs will disempower humanity: I'd put it at less than 1% chance, I'm confident that 10% probability is wrong, but I could see some reasonable person holding it, and flat out don't see a way to get to 10-90%+ for a reasonable person, primarily because I have a cluster of beliefs of "alignment is very easy" combined with "intelligence isn't magic" and regulatory constraints from society.
The first time an AI reaches STEM+ capabilities (if that ever happens), it will disempower humanity within three months: Almost certainly below 1%, and I do not see a way to get a reasonable person to hold this view that doesn't rely on either FOOM models of AI progress or vastly unrealistic models of society. This is far too fast for any big societal change. I'd put it at a decade minimum. It's also obviated by my general belief that alignment is very easy.
If AI wipes out humanity and colonizes the universe itself, the future will go about as well as if humanity had survived (or better).
Almost any probability could be entered by a reasonable person, so I elect to maintain all probability ranges between 0 and 1 as options.
Given sufficient technical knowledge, humanity could in principle build vastly superhuman AIs that reliably produce very good outcomes: Over 99%, and indeed I believe a stronger statement that will be elucidated in the next question.
Researchers will solve enough of the alignment problem to prevent world-endangering AI from ever being built:
Over 99% is my odds right now, I could see a reasonable person having 50%-99% credences, but not lower than that.
My main reasons for this come down to my deep skepticism around deceptive alignment, to use a terminology Evan Hubinger used, I think were either not underwater at all, or only underwater by only 1-1000 bits of data, which is tiny compared to the data around human values. I basically entirely disbelieve the memeplex LW developed that human values are complicated and totally arbitrary, or at least the generators of human values, and a partial reason for that is that the simplicity bonuses offered by good world-modeling also bleed over a lot into value formation, and while there is a distinction between values and capabilities, I think it's not nearly as sharp or as different in complexity as LWers think.
This was an important scenario to get out of the way, because my next argument wouldn't work if deceptive alignment happened.
Another argument that Jaime Sevilla used, and that I tend to agree with, is that it's fundamentally profitable for companies to control AI, primarily because control research is both cheaper and more valuable for AIs, and it's not subject to legal restrictions, and they internalize a lot more of the risks of AI going out of control, which is why I expect problems like Goodharting to mostly go away by default, because I expect the profit incentive to be quite strong and positive for alignment in general. This also implies that a lot of LW work is duplicative at best, so that's another point.
There are of course other reasons, but this comment would be much longer.
For the purpose of preventing AI catastrophes, technical research is more useful than policy work: I'd say I have a wide range of probabilities, but I do think that it's not going to be 90%+, or even 50%+, and a big part of this reason is I'm focused on fairly different AI catastrophes, like this story, where the companies have AI that is controllable and powerful enough to make humans mostly worthless, basically removing all incentive for capitalists to keep humans alive or well-treated. This means I'm mostly not caring about technical research that rely on controlling AIs by default.
https://www.lesswrong.com/posts/2ujT9renJwdrcBqcE/the-benevolence-of-the-butcher
Governments will generally be reasonable in how they handle AI risk: 10-90% is my probability for now, with a wide distribution. Right now, AI risk is basically talked about, and one of the best things is that a lot of the regulation is pretty normalish. I would worry a little more if pauses are seriously considered, because I'd worry that the reason for the pause is to buy time for safety, but in my models of alignment, we don't need that. I'd say the big questions are how much would rationalists gain power over the government, and what the balance of pro to anti-pause politics looks like.
It would be an unprecedentedly huge tragedy if we never built STEM+ AI: <<<1-40% chance IMO, and a potential difference from most AI optimists/pro-progress people is that if we ignore long-term effects, and ignore long-termism, it's likely that we will muddle along if AI is severely restricted, and it would be closer to the nuclear case, where it's clearly bad that it was slowed down, but it wasn't catastrophic.
Over the long-term, it would be an unprecedently huge tragedy, mostly due to base-rate risk and potential loss of infinite utility (depending on the physics).
I'd mostly agree with Jeffrey Heninger's post on how muddling along is more likely than dystopia here, if it wasn't for who's trying to gain power, and just how much they veer toward some seriously extreme actions.
https://www.lesswrong.com/posts/pAnvMYd9mqDT97shk/muddling-along-is-more-likely-than-dystopia
It's admittedly an area where I have the weakest evidence on, but a little of my probability is based on worrying about how rationalists would slow down AI leading to extremely bad outcomes.
Would you be ok with a world if it turns out only 1 is achievable?
Profit incentive wise, the maximum profit for an AI model company comes if they offer the most utility they can legally offer, privately, and they offer a public model that won't damage the company's reputation. There is no legal requirement to refuse requests due to long term negative consequences and it seems unlikely there would be. A private model under current law can also create a "mickey mouse vs Garfield" snuff film, something that would damage the AI company's reputation if public... (read more)