This is a linkpost for https://scottaaronson.blog/?p=6821
New Comment
Instead of creating new ingroups and outgroups and tribal signifiers for enforcing such, we should focus on careful truth-seeking. Some mythologies and terms that engage our more primal instincts can be useful, like when Scott introduced "Moloch", but others are much more likely harmful. "Orthodox vs Reform" seems like a purely harmful one, that is only useful for enforcing further division and tribal warfare.
To summarize, in this post Aaronson,
- Enforces the idea that AI safety is religion.
- Creates new terminology to try and split the field into two ideological groups.
- Chooses terminology that paints the other one as "old, conforming, traditional" and the other as, to quote wiktionary, "the change of something that is defective, broken, inefficient or otherwise negative".
- Immediately adopts the tribal framing he has created, and already identifies as "We Reform AI-riskers", to quote him directly.
This seems like a powerful approach for waging ideological warfare. It is not constructive for truth-seeking.
This is wonderfully written, thank you.
I do worry that "further division and tribal warfare" seems the default, unless there's an active effort at reconciliation.
Sam Altman (CEO of OpenAI) tweets things like:
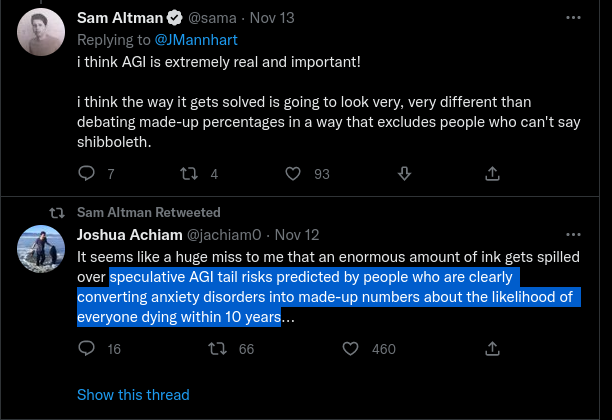
LessWrong compares OpenAI with Phillip Morris and, in general, seems very critical of OpenAI. "I've seen a lot more public criticism lately".
I doubt that it's actually good to have this strong division, and it might have positive EV to try to move into a more cooperative direction, and try to lower the temperature and divisiveness.
Eh. I think this framing isn't cutting reality at its joints. To the extent it does describe something real, it seems to be pointing towards that old rift between Christiano and Yud. But, like, you can just call that prosaic ai safety vs sharp-left-turn ai safety. And, you know, I don't think we've got a great name for this stuff. But the other stuff Scott's talking about doesn't quite fit in with that framing.
Like the stuff about getting mainstream scientists on board. Everyone in AI safety would like it if the possibility of X-risks from AI was taken seriously, its just that they differ in what they think the shape of the problem is, and as such have different opinions on how valuable the work being done on prosaic ML safety stuff is.
I think most people in the AI safety community are leery about outreach towards the public though? Like, in terms of getting governments on board, sure. In terms of getting joe-average to understand this stuff, well, that stinks too much of politics and seems like something which could go wildly wrong.
See the excellent reply by Daniel Kokotajlo: https://scottaaronson.blog/?p=6821#comment-1944067
Certainly a very thorough reply, though as of now there is no reaction from OP. I am afraid that if there will be, it will turn into one of those exchanges where neither side moves an inch by the end.
Personally, I object to the framing. AI alignment is not a religious discussion. It is a matter of facts and predictions. The facts, thus far, have seemed to support Eliezer's predictions, which is that improvements in AI technology make AI more powerful without necessarily making it more aligned with human morality. Aaronson's reply is, more or less, "No, eventually AI will become aligned," without any actual evidence showing why it would happen.
The facts, thus far, have seemed to support Eliezer’s predictions
In what sense? I don't think Eliezer has made any particularly successful advance predictions about the trajectory of AI.
Meta just unveiled an AI that can play Diplomacy at a human level.
Here we have an AI that, through deception, can persuade humans to ally with it against other humans, and sets them up for eventual betrayal. This is something that Eliezer anticipated with his AI box experiment.
The AI-box experiment and this result are barely related at all -- the only connection between them is that they both involve deception in some manner. "There will exist future AI systems which sometimes behave deceptively" can hardly be considered a meaningful advance prediction.
At the time I took AlphaGo as a sign that Elizer was more correct than Hanson w/r/t the whole AI-go-FOOM debate. I realize that's an old example which predates the last-four-years AI successes, but I updated pretty heavily on it at the time.
Eliezer likes to characterize the success of deep learning as "being further than him on the Eliezer-Robin axis", but I consider that quite misleading. I would say that it's rather mostly orthogonal to that axis, contradicting both Eliezer and Robin's prior models in different ways.
From your link:
I think the “secret sauce of intelligence” view is looking worse and worse, as is the “village idiot to Einstein is no gap at all view.”
Is it looking worse and worse? We've seen repeatedly, with chess, Go, Atari games, and now Diplomacy, AIs going from subhuman, to human, to superhuman levels in relatively short periods of time. Years, in most cases. Months in some.
The "village idiot to Einstein" argument is about the relative length of the "subhuman--village idiot" and "village idiot--Einstein" transitions. It predicts that the latter should be vastly shorter than the former. Instead we usually see computers progressing fairly smoothly through the range of human abilities. The fact that the overall transition "subhuman--superhuman" sometimes doesn't take very long is not directly relevant here.
The framing is based on contrasting Orthodox Judaism with Reform Judaism, only for AI Alignment.
There are 8 points of comparison, here is just the first one:
This framing seems new and worthwhile, crystallizing some long-standing divisions in the AI community.