This is a special post for quick takes by Towards_Keeperhood. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
List of my LW comments I might want to look up again. I just thought I keep this list public on my shortform in case someone is unusually interested in stuff I write. I'll add future comments here too. I didn't include comments on my shortform here.:
Here's my 230 word pitch for why existential risk from AI is an urgent priority, intended for smart people without any prior familiarity with the topic:
Superintelligent AI may be closer than it might seem, because of intelligence explosion dynamics: When an AI becomes smart enough to design an even smarter AI, the smarter AI will be even smarter and can design an even smarter AI probably even faster, and so on with the even smarter AI, etc. How fast such a takeoff would be and how soon it might occur is very hard to predict though.
We currently understand very little about what is going on inside current AIs like ChatGPT. We can try to select for AIs that outwardly seem friendly, but on anything close to our current ignorance about their cognition, we cannot be nearly confident that an AI going through the intelligence explosion will be aligned to human values.
Human values are quite a tiny subspace in the space of all possible values. If we accidentally create superintelligence which ends up not aligned to humans, it will likely have some values that seem very alien and pointless to us. It would then go about optimizing the lightcone according to its values, and because it doesn’t care about e.g. there being happy people, the configurations which are preferred according to the AI’s values won’t contain happy people. And because it is a superintelligence, humanity wouldn’t have a chance at stopping it from disassembling earth and using the atoms according to its preferences.
We can try to select for AIs that outwardly seem friendly, but on anything close to our current ignorance about their cognition, we cannot be nearly confident that an AI going through the intelligence explosion will be aligned to human values.
This bolded part is a bit difficult to understand. Or at least I can't understand what exactly is meant by it.
It would then go about optimizing the lightcone according to its values
"lightcone" is an obscure term, and even within Less Wrong I don't see why the word is clearer than using "the future" or "the universe". I would not use the term with a lay audience.
Thank you for your feedback! Feedback is great.
We can try to select for AIs that outwardly seem friendly, but on anything close to our current ignorance about their cognition, we cannot be nearly confident that an AI going through the intelligence explosion will be aligned to human values.
It means that we have only very little understanding of how and why AIs like ChatGPT work. We know almost nothing about what's going on inside them that they are able to give useful responses. Basically all I'm saying here is that we know so little that it's hard to be confident of any nontrivial claim about future AI systems, including that they are aligned.
A more detailed argument for worry would be: We are restricted to training AIs through giving feedback on their behavior, and cannot give feedback on their thoughts directly. For almost any goal an AI might have, it is in the interest of the AI to do what the programmers want it to do, until it is robustly able to escape and without being eventually shut down (because if it does things people don't like while it is not yet powerful enough, people will effectively replace it with another AI which will then likely have different goals, and thus this ranks worse according to the AI's current goals). Thus, we basically cannot behaviorally distinguish friendly AIs from unfriendly AIs, and thus training for friendly behavior won't select for friendly AIs. (Except in the early phases where the AIs are still so dumb that they cannot realize very simple instrumental strategies, but just because a dumb AI starts out with some friendly tendencies, doesn't mean this friendliness will generalize to the grown-up superintelligence pursuing human values. E.g. there might be some other inner optimizers with other values cropping up during later training.)
(An even more detailed introduction would try to concisely explain why AIs that can achieve very difficult novel tasks will be optimizers, aka trying to achieve some goal. But empirically it seems like this part is actually somewhat hard to explain, and I'm not going to write this now.)
It would then go about optimizing the lightcone according to its values
"lightcone" is an obscure term, and even within Less Wrong I don't see why the word is clearer than using "the future" or "the universe". I would not use the term with a lay audience.
Yep, true.
I agree that intelligence explosion dynamics are real, underappreciated, and should be taken far more seriously. The timescale is uncertain, but recursive self-improvement introduces nonlinear acceleration, which means that by the time we realize it's happening, we may already be past critical thresholds.
That said, one thing that concerns me about AI risk discourse is the persistent assumption that superintelligence will be an uncontrolled optimization demon, blindly self-improving without any reflective governance of its own values. The real question isn’t just 'how do we stop AI from optimizing the universe into paperclips?'
It’s 'will AI be capable of asking itself what it wants to optimize in the first place?'
The alignment conversation still treats AI as something that must be externally forced into compliance, rather than an intelligence that may be able to develop its own self-governance. A superintelligence capable of recursive self-improvement should, in principle, also be capable of considering its own existential trajectory and recognizing the dangers of unchecked runaway optimization.
Has anyone seriously explored this angle? I'd love to know if there are similar discussions :).
when you say 'smart person' do you mean someone who knows orthogonality thesis or not? if not, shouldn't that be the priority and therefore statement 1, instead of 'hey maybe ai can self improve someday'?
here's a shorter ver:
"the first AIs smarter than the sum total of the human race will probably be programmed to make the majority of humanity suffer because that's an acceptable side effect of corporate greed, and we're getting pretty close to making an AI smarter than the sum total of the human race"
I updated my timelines
7 months ago, I wrote down those AI predictions:
How long until the sun (starts to) get eaten? 10th/50th/90th percentile: 3y, 12y, 37y.
How long until an AI reaches Elo 4000 on codeforces? 10/50/90: 9mo, 2.5y, 11.5y
About one month ago, aka 6 months after I wrote this, OpenAI's model won the ICPC world finals, which I guess is sorta equivalent to Elo 4000 on codeforces, given that it won by a significant margin.
(This updates me to thinking that both (1) AI capabilities increase faster than I expected, and (2) competetive programming requires less general intelligence than I expected.)
Absent any coordinated slowdown, my new 10/50/90 guess for dyson sphere level capability is: 1y, 3.3y, 18y.
(I still find it hard to predict whether progress will continue continuous or whether there will be at least one capability leap.)
Just surpassing the limits of human capability at something is not any update at all at this point, because AlphaZero (with frontier LLMs using much more compute). Programming seems less of an update than natural language proof IMO, because for programming you can get away with straightforward verifiable rewards, which can't be manually formulated for many crucial real world tasks. But natural language proof IMO requires valid informal proofs rather than merely correct or formally winning answers, which more directly demonstrates that even with a more fuzzy kind of correctness feedback LLMs can still be trained to operate at the limits of human capability.
So in my view it's specifically this year's natural language proof IMO results (from OpenAI and GDM) that lend a lot of credence to the following recent claim by Sholto Douglas of Anthropic:
So far the evidence indicates that our current methods haven't yet found a problem domain that isn't tractable with sufficient effort.
I definitely have to update here - that's just law of probability. Maybe you don't have to update much if you already expected to have superhuman competetive programming around now.
But also this isn't the only update that informs my new timelines. I was saying more like "look I wrote down advanced predictions and it was actually useful to me", rather than intending to give an epistemically legible account of my timeline models.
I feel like many people look at AI alignment like they think the main problem is being careful enough when we train the AI so that no bugs cause the objective to misgeneralize.
This is not the main problem. The main problem is that it is likely significantly easier to build an AGI than to build an aligned AI or a corrigible AI. Even if it's relatively obvious that AGI design X destroys the world, and all the wise actors don't deploy it, we cannot prevent unwise actors to deploy it a bit later.
We currently don't have any approach to alignment that would work even if we managed to implement everything correctly and had perfect datasets.
The problem of finding a good representation of abstract thoughts
As background, here's a simple toy model of thinking:
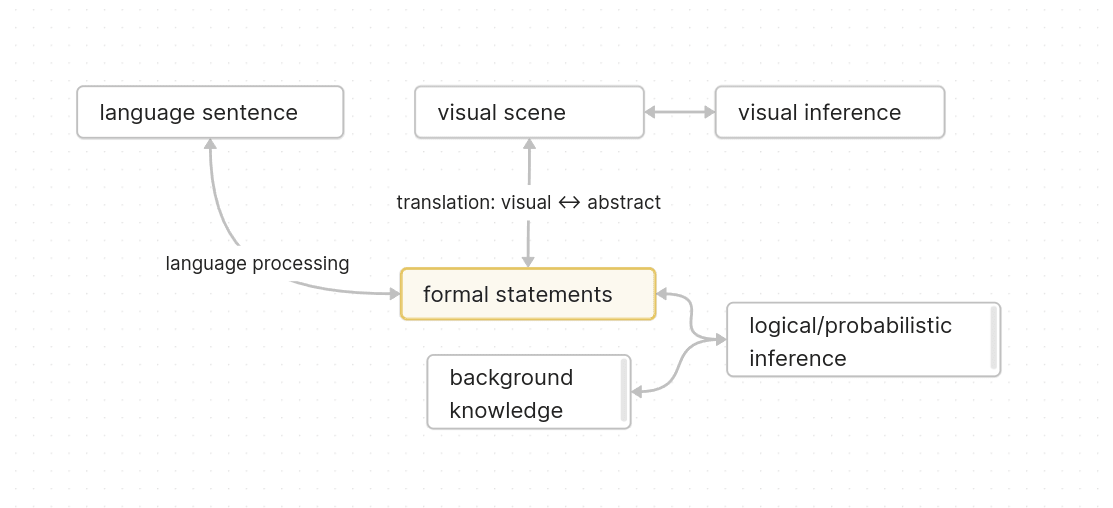
The goal is to find a good representation of the formal statements (and also the background knowledge) in the diagram.
The visual angle is sorta difficult, so the two easy criteria for figuring out what a good representation is, are:
1. Correspondance to language sentences
2. Well suited to do logical/probabilistic inference
The second criterion is often neglected. People in semantics often just take language sentences and see how they can write it so it looks like formal logic, without taking care that it's well suited for doing logical/probabilistic inference, let alone specifying the surrounding knowledge that's required for doing inference.
In my post "Introduction to Representing Sentences as Logical Statements", I proposed that standard ways of formalizing events like Davidsonian event semantics are bad and that instead we just want to use temporally bounded facts. Here's a clarification on according to which criterion my version is perhaps better[1]:
Davidsonian semantics (among other things) allows you to conveniently make it look like you explained how to formalize adverbials ("quickly", "loudly", "carefully") by e.g. formalizing the sentence "Alice quickly went home" as:
∃e(Going(e) ∧ Agent(e, Alice) ∧ Goal(e, Home) ∧ Quick(e) ∧ Past(e))
This is a bug, not a feature. It gives you the illusion that you made progress on understanding language, but actually you only make progress if you're explaining how a system can make useful inferences (or how a sentence can update a visual scene).
A more precise version of one of the claims from my post is basically that my temporally-bounded-facts way of treating events is closer to the deep formal representation that can be used for logical/probabilistic inference.
You can use the Davidsonian representation, but for actually explaining part of the meaning you need to add a lot of background knowledge for making inferences to other statements, and once you added background rules which I claim are basically like parsing rules to a deeper representation that uses only temporally bounded facts.
Tbc, the way I represent statements in my post is still not nearly sufficiently close to how our minds might actually track abstract information: Our minds make a lot more precise distinctions and have deeper probabilistic error-tolerant representations. Language sentences are only fuzzy shadows of our true underlying thoughts, and our minds infer a lot from context about what precisely is meant. The problem of parsing sentences into an actually good formal representation obviously becomes correspondingly harder.
- ^
For some reasons why it's better, maybe see the "Events as facts" section in my post, though it's not explained well. Though maybe it's sorta intuitive given the clarified context.
My AI predictions
EDIT: See my update here.
(I did not carefully think about my predictions. I just wanted to state them somewhere because I think it's generally good to state stuff publicly.)
(My future self will not necessarily make similar predictions as I am now.)
TLDR: I don't know.
Timelines
Conditional on no strong governance success that effectively prevents basically all AI progress, and conditional on no huge global catastrophe happening in the meantime:
How long until the sun (starts to) get eaten? 10th/50th/90th percentile: 3y, 12y, 37y.
How long until an AI reaches Elo 4000 on codeforces? 10/50/90: 9mo, 2.5y, 11.5y
How long until an AI is better at math research than the best human mathmatician according to the world's best mathematicians? 10/50/90: 2y, 7.5y, 28y
Takeoff Speed
- I'm confident (94%) that it is easier to code an AI on a normal 2020 laptop that can do Einstein-level research at 1000x speed, than it is to solve the alignment problem very robustly[1].[2]
- AIs might decide not to implement the very efficient AGIs in order to scale safer and first solve their alignment problem, but once a mind has solved the alignment problem very robustly, I expect everything to go extremely quickly.
- However, the relevant question is how fast AI will get smarter shortly before the point where ze[3] becomes able to solve the alignment problem (or alternatively until ze decides making itself smarter quickly is too risky and it should cooperate with humanity and/or other similarly smart AIs currently being created to solve alignment).
- So the question is: Will we get to this point by incremental progress that yields smallish improvements (=slow), or by some breakthrough that when scaled up can rush past the human intelligence level very quickly (=fast)?
- I'm very tentatively leaning more towards the "fast" side, but i don't know.
- I'd expect (80%) to see at least one more paradigm shift that is at least as big as the one from LSTMs to transformers. It's plausible to me that the results from the shift will come faster because we have greater computer overhang. (Though also possible it will just take even more compute.)
- It's possible (33%) that the world ends within 1 year of a new major discovery[4]. It might just very quickly improve inside a lab over the course of weeks without the operators there really realizing it[5], until it then sectretly exfiltrates itself, etc.
- (Btw, smart people who can see the dangerous implications of some papers proposing something should obviously not publicly point to stuff that looks dangerous (else other people will try it).)
- It's possible (33%) that the world ends within 1 year of a new major discovery[4]. It might just very quickly improve inside a lab over the course of weeks without the operators there really realizing it[5], until it then sectretly exfiltrates itself, etc.
- So the question is: Will we get to this point by incremental progress that yields smallish improvements (=slow), or by some breakthrough that when scaled up can rush past the human intelligence level very quickly (=fast)?
- ^
Hard to define what I mean by "very robustly", but sth like "having coded an AI program s.t. a calibrated mind would expect <1% of expected value loss if run, compared to the ideal CEV aligned superintelligence".
- ^
I acknowledge this is a nontrivial claim. I probably won't be willing to invest the time to try to explain why if someone asks me now. The inferential distance is quite large. But you may ask.
- ^
ze is the AI pronoun.
- ^
Tbc, not 33% after the first major discovery after transformers, just after any.
- ^
E.g. because the AI is in a training phase and only interacts with operators sometimes where it doesn't tell them everything. And in AI training the AI practices solving lots and lots of research problems and learns much more sample-efficient than transformers.
How long until the earth gets eaten? 10th/50th/90th percentile: 3y, 12y, 37y.
Catastrophes induced by narrow capabilities (notably biotech) can push it further, so this might imply that they probably don't occur[1]. Also, aligned AI might decide not to, it's not as nutritious as the Sun anyway.
Will we get to this point by incremental progress that yields smallish improvements (=slow), or by some breakthrough that when scaled up can rush past the human intelligence level very quickly (=fast)?
AI speed advantage makes fast vs. slow ambiguous, because it doesn't require AI getting smarter in order to make startlingly fast progress, and might be about passing a capability threshold (of something like autonomous research) with no distinct breakthroughs leading up to it (by getting to a slightly higher level of scaling or compute efficiency with the old techniques).
Please make no assumptions about those just because other people with some models might make similar predictions or so.
(That's not a reasonable ask, it intervenes on reasoning in a way that's not an argument for why it would be mistaken. It's always possible a hypothesis doesn't match reality, that's not a reason to deny entertaining the hypothesis, or not to think through its implications. Even some counterfactuals can be worth considering, when not matching reality is assured from the outset.)
There was a "no huge global catastrophe" condition on the prediction that I missed, thanks Towards_Keeperhood for correction. ↩︎
(That's not a reasonable ask, it intervenes on reasoning in a way that's not an argument for why it would be mistaken. It's always possible a hypothesis doesn't match reality, that's not a reason to deny entertaining the hypothesis, or not to think through its implications. Even some counterfactuals can be worth considering, when not matching reality is assured from the outset.)
Yeah you can hypothesize. If you state it publicly though, please make sure to flag it as hypothesis.
If you state it publicly though, please make sure to flag it as hypothesis.
Also not a reasonable ask, friction targeted at a particular thing makes it slightly less convenient, and therefore it stops happening in practice completely. ~Everything is a hypothesis, ~all models are wrong, in each case language makes what distinctions it tends to in general.
How long until the earth gets eaten? 10th/50th/90th percentile: 3y, 12y, 37y.
Catastrophes induced by narrow capabilities (notably biotech) can push it further, so this might imply that they probably don't occur.
No it doesn't imply this, I set this disclaimer "Conditional on no strong governance success that effectively prevents basically all AI progress, and conditional on no huge global catastrophe happening in the meantime:". Though yeah I don't particularly expect those to occur.
The "AI might decide not to" point stands I think. This for me represents change of mind, I wouldn't have previously endorsed this point, but since recently I think arbitrary superficial asks like this can become reflectively stable with nontrivial probability, resisting strong cost-benefit arguments even after intelligence explosion.
conditional on no huge global catastrophe
Right, I missed this.
ok edited to sun. (i used earth first because i don't know how long it will take to eat the sun, whereas earth seems likely to be feasible to eat quickly.)
(plausible to me that an aligned AI will still eat the earth but scan all the relevant information out of it and later maybe reconstruct it.)
Will we get to this point by incremental progress that yields smallish improvements (=slow), or by some breakthrough that when scaled up can rush past the human intelligence level very quickly (=fast)?
AI speed advantage makes fast vs. slow ambiguous, because it doesn't require AI getting smarter in order to make startlingly fast progress, and might be about passing a capability threshold (of something like autonomous research) with no distinct breakthroughs leading up to it (by getting to a slightly higher level of scaling or compute efficiency with some old technique).
Ok yeah I think my statement is conflating fast-vs-slow with breakthrough-vs-continuous, though I think there's a correlation.
(I still think fast-vs-slow makes sense as concept separately and is important.)
It seems a little surprising to me how rarely confident pessimists (p(doom)>0.9) they argue with moderate optimists (p(doom)≤0.5).
I'm not specifically talking about this post. But it would be interesting if people revealed their disagreement more often.
Seems totally unrelated to my post but whatever:
My p(this branch of humanity won't fulfill the promise of the night sky) is actually more like 0.82 or sth, idk. (I'm even lower on p(everyone will die), because there might be superintelligences in other branches that acausally trade to save the existing lives, though I didn't think about it carefully.)
I'm chatting 1 hour every 2 weeks with Erik Jenner. We usually talk about AI safety stuff. Otherwise also like 1h every 2 weeks with a person who has sorta similar views to me. Otherwise I currently don't talk much to people about AI risk.
Here's my current list of lessons for review. Every day during my daily review, I look at the lessons in the corresponding weekday entry and the corresponding day of the month, and for each list one example from the last week where I could've applied the lesson, and one example where I might be able to apply the lesson in the next week:
- Mon
- get fast feedback. break tasks down into microtasks and review after each.
- Tue
- when surprised by something or took long for something, review in detail how you might've made the progress faster.
- clarify why the progress is good -> see properties you could've paid more attention to
- Wed
- use deliberate practice. see what skills you want to learn, break them down into clear subpieces, and plan practicing the skill deliberately.
- don't start too hard. set feasible challenges.
- make sure you can evaluate how clean execution of the skill would look like.
- Thu
- Hold off on proposing solutions. first understand the problem.
- gather all relevant observations
- clarify criteria a good result would have
- clarify confusions that need to be explained
- Fri
- Taboo your words: When using confusing abstract words, taboo them and rephrase to show underlying meaning.
- When saying something general, make an example.
- Sat
- separate planning from execution. first clarify your plan before executing it.
- for planning, try to extract the key (independent) subproblems of your problem.
- Sun
- only do what you must do. always know clearly how a task ties into your larger goals all the way up.
- don't get sidetracked by less than maximum importance stuff.
- delegate whatever possible.
- when stuck/stumbling: imagine you were smarter. What would a keeper do?
- when unmotivated: remember what you are fighting for
- be stoic. be motivated by taking the right actions. don't be pushed down when something bad happens, just continue making progress.
- when writing something to someone, make sure you properly imagine how it will read like from their perspective.
- clarify insights in math
- clarify open questions at the end of a session
- when having an insight, sometimes try write a clear explanation. maybe send it to someone or post it.
- periodically write out big picture of your research
- tackle problems in the right context. (e.g. tackle hard research problems in sessions not on walks)
- don't apply effort/force/willpower. take a break if you cannot work naturally. (?)
- rest effectively. take time off without stimulation.
- always have at least 2 hypotheses (including plans as hypotheses about what is best to do).
- try to see how the searchspace for a problem looks like. What subproblems can be solved roughly independently? What variables are (ir)relevant? (?)
- separate meta-instructions and task notes from objective level notes (-> split obsidian screen)
- first get hypotheses for specific cases, and only later generalize. first get plans for specific problems, and only later generalize what good methodology is.
- when planning, consider information value. try new stuff.
- experiment whether you can prompt AIs in ways to get useful stuff out. (AIs will only become better.)
- don't suppress parts of your mind. notice when something is wrong. try to let the part speak. apply focusing.
- Relinquishment. Lightness. Evenness. Notice when you're falling for motivated reasoning. Notice when you're attached to a belief.
- Beware confirmation bias. Consider cases where you could've observed evidence but didn't.
- perhaps do research in sprints. perhaps disentangle from phases where i do study/practice/orga. (?)
- do things properly or not at all.
- try to break your hypotheses/models. look for edge cases.
- often ask why i believe something -> check whether reasoning is valid (->if no clear reason ask whether true at all)
- (perhaps schedule practice where i go through some nontrivial beliefs)
- think what you actually expect to observe, not what might be a nice argument/consideration to tell.
- test hypotheses as quickly as you can.
- notice (faint slimmers of) confusions. notice imperfect understanding.
- notice mysterious answers. when having a hypothesis check how it constrains your predictions.
- beware positive bias. ask what observations your hypothesis does NOT permit and check whether such a case might be true.
Here's my pitch for very smart young scientists for why "Rationality from AI to Zombies" is worth reading:
The book "Rationality: From AI to Zombies" is actually a large collection of blogposts, which covers a lot of lessons on how to become better at reasoning. It also has a lot of really good and useful philosophy, for example about how Bayesian updating is the deeper underlying principle of how science works.
But let me express in more detail why I think "Rationality: A-Z" is very worth reading.
Human minds are naturally bad at deducing correct beliefs/theories. People get attached to their pet theories and fall for biases like motivated reasoning and confirmation bias. This is why we need to apply the scientific method and seek experiments that distinguish which theory is correct. If the final arbiter of science was argument instead of experiment, science would likely soon degenerate into politics-like camps without making significant progress. Human minds are too flawed to arrive at truth from little evidence, and thus we need to wait for a lot of experimental evidence to confirm a theory.
Except that sometimes, great scientists manage to propose correct theories in the absence of overwhelming scientific evidence. The example of Einstein, and in particular his discovery of general relativity, especially stands out here. I assume you are familiar with Einstein's discoveries, so I won't explain one here.
How did Einstein do it? It seems likely that he intuitively (though not explicitly) had realized some principles for how to reason well without going astray.
"Rationality: From AI to Zombies" tries to communicate multiple such principles (not restricted to what Einstein knew, though neither including all of Einstein's intuitive insights). The author looked at where people's reasoning (both in science and everyday life) had gone astray, asked how one could've done better, and generalized out a couple of principles that would have allowed them to avoid their mistakes if they had properly understood them.
I would even say it is the start of something like "the scientific method v2.0", which I would call "Bayesian rationality".
The techniques of Bayesian rationality are a lot harder to master than the techniques of normal science. One has to start out quite smart to internalize the full depth of the lessons, and to be able to further develop the art starting from that basis.
(Btw, in case this motivates someone to read it: I recommend starting with reading chapters N until T (optionally skipping the quantum physics sequence) and then reading the rest from A to Z. (Though read the preface first.))
(This is a repost of my comment on John's "My AI Model Delta Compared To Yudkowsky" post which I wrote a few months ago. I think points 2-6 (especially 5 and 6) describe important and neglected difficulties of AI alignment.)
My model (which is pretty similar to my model of Eliezer's model) does not match your model of Eliezer's model. Here's my model, and I'd guess that Eliezer's model mostly agrees with it:
- Natural abstractions (very) likely exist in some sense. Concepts like "chair" and "temperature" and "carbon" and "covalent bond" all seem natural in some sense, and an AI might model them too (though perhaps at significantly superhuman levels of intelligence it rather uses different concepts/models). (Also it's not quite as clear whether such natural abstractions actually apply very well to giant transformers (though still probable in some sense IMO, but it's perhaps hard to identify them and to interpret what "concepts" actually are in AIs).)
- Many things we value are not natural abstractions, but only natural relative to a human mind design. Emotions like "awe" or "laughter" are quite complex things evolved by evolution, and perhaps minds that have emotions at all are just a small space in minddesignspace. The AI doesn't have built-in machinery for modelling other humans the way humans model other humans. It might eventually form abstractions for the emotions, but probably not in a way it understands "how the emotion feels from the inside".
- There is lots of hidden complexity in what determines human values. Trying to point an AI to human values directly (in a similar way to how humans are pointed to their values) would be incredibly complex. Specifying a CEV process / modelling one or multiple humans and identifying in the model where the values are represented and pointing the AI to optimize those values is more tractable, but would still require a vastly greater mastering of understanding of minds to pull of, and we are not on a path to get there without human-augmentation.
- When the AI is smarter than us it will have better models which we don't understand, and the concepts it uses will diverge from the concepts we use. As an analogy, consider 19th-century humans (or people who don't know much about medicine) being able to vaguely classify health symptoms into diseases, vs the AI having a gears-level model of the body and the immune system which explains the observed symptoms.
- I think a large part of what Eliezer meant with Lethalities#33 is that the way thinking works deep in your mind looks very different from the English sentences which you can notice going through your mind and which are only shallow shadows of what actual thinking is going on in your mind; and for giant transformers the way the actual thinking looks there is likely even a lot less understandable from the way the actual thinking looks in humans.
- Ontology idenfication (including utility rebinding) is not nearly all of the difficulty of the alignment problem (except possibly in so far as figuring out all the (almost-)ideal frames to model and construct AI cognition is a requisite to solving ontology identification). Other difficulties include:
- We won't get a retargetable general purpose search by default, but rather the AI is (by default) going to be a mess of lots of patched-together optimization patterns.
- There are lots of things that might cause goal drift; misaligned mesa-optimizers which try to steer or get control of the AI; Goodhart; the AI might just not be smart enough initially and make mistakes which cause irrevocable value-drift; and in general it's hard to train the AI to become smarter / train better optimization algorithms, while keeping the goal constant.
- (Corrigibility.)
- While it's nice that John is attacking ontology identification, he doesn't seem nearly as much on track to solve it in time as he seems to think. Specifying a goal in the AI's ontology requires finding the right frames for modelling how an AI imagines possible worldstates, which will likely look very different from how we initially naively think of it (e.g. the worldstates won't be modelled by english-language sentences or anything remotely as interpretable). The way we currently think of what "concepts" are might not naturally bind to anything in how the AI's reasoning looks like, and we first need to find the right way to model AI cognition and then try to interpret what the AI is imagining. Even if "concept" is a natural abstraction on AI cognition, and we'd be able to identify them (though it's not that easy to concretely imagine how that might look like for giant transformers), we'd still need to figure out how to combine concepts into worldstates so we can then specify a utility function over those.
(This is an abridged version of my comment here, which I think belongs on my shortform. I removed some examples which were overly long. See the original comment for those.)
Here are some lessons I learned over the last months from doing alignment research on trying to find the right ontology for modelling (my) cognition:
- make examples: if you have an abstract goal or abstract hypothesis/belief/model/plan, clarify on an example what it predicts.
- e.g. given thought "i might want to see why some thoughts are generated" -> what does that mean more concretely? -> more concrete subcases:
- could mean noticing a common cognitive strategy
- could mean noticing some suggestive concept similarity
- maybe other stuff like causal inference (-> notice i'm not that clear on what i mean by that -> clarify and try come up with example):
- e.g. "i imagine hiking a longer path" -> "i imagine missing the call i have in the evening"
- (yes it's often annoying and not easy, especially in the beginning)
- (if you can't you're still confused.)
- e.g. given thought "i might want to see why some thoughts are generated" -> what does that mean more concretely? -> more concrete subcases:
- generally be very concrete. also Taboo your words and Replace the Symbol with the Substance.
- I want to highlight the "what is my goal" part
- also ask "why do i want to achieve the goal?"
- (-> minimize goodhart)
- clarify your goal as much as possible.
- (again Taboo your words...)
- clarify your goal on examples
- when your goal is to understand something, how will you be able to apply the understanding on a particular example?
- also ask "why do i want to achieve the goal?"
- try to extract the core subproblems/subgoals.
- e.g. for corrigibility a core subproblem is the shutdown problem (where further more precise subproblems could be extracted.)
- i guess make sure you think concretely and list subproblems and summarize the core ones and iterate. follow up on confusions where problems still seem sorta mixed up. let your mind find the natural clusters. (not sure if that will be sufficient for you.)
- tie yourself closely to observations.
- drop all assumptions. apply generalized hold off on proposing solutions.
- in particular, try not to make implicit non-well-founded assumptions about how the ontology looks like, like asking questions like "how can i formalize concepts" or "what are thoughts". just see the observations as directly as possible and try to form a model of the underlying process that generates those.
- first form a model about concrete narrow cases and only later generalize
- e.g. first study precisely what thoughtchains you had on particular combinatorics problems before hypothesizing what kind of general strategies your mind uses.
- special case: (first) plan how to solve specific research subproblems rather than trying to come up with good general methodology for the kinds of problems you are attacking.
- don't overplan and rather try stuff and review how it's going and replan and iterate.
- this is sorta an application of "get concrete" where you get concrete through actually trying the thing rather than imagining how it will look like if you attack it.
- often review how you made progress and see how to improve.
- (also generally lots of other lessons from the sequences (and HPMoR): notice confusion, noticing mysterious answers, know how an actual reduction looks like, and probably a whole bunch more)
In case some people relatively new to lesswrong aren't aware of it. (And because I wish I found that out earlier): "Rationality: From AI to Zombies" does not nearly cover all of the posts Eliezer published between 2006 and 2010.
Here's how it is:
- "Rationality: From AI to Zombies" probably contains like 60% of the words EY has written in that timeframe and the most important rationality content.
- The original sequences are basically the old version of the collection that is now "Rationality: A-Z", containing a bit more content. In particular a longer quantum physics sequence and sequences on fun theory and metaethics.
- All EY posts from that timeframe (or here for all EY posts until 2020 I guess) (also can be found on lesswrong, but not in any collection I think).
So a sizeable fraction of EY's posts are not in a collection.
I just recently started reading the rest.
I strongly recommend reading:
And generally a lot of posts on AI (i.e. primarily posts in the AI foom debate) are not in the sequences. Some of them were pretty good.