
An overview of 11 proposals for building safe advanced AI
32Daniel Kokotajlo
11evhub
31Charlie Steiner
7Richard_Ngo
2Charlie Steiner
27Ben Pace
9evhub
4Ben Pace
25Daniel Kokotajlo
21Rohin Shah
4Richard_Ngo
2Rohin Shah
15AlexMennen
10Richard_Ngo
4AlexMennen
5adamShimi
12Richard_Ngo
11ESRogs
6evhub
15ESRogs
6evhub
2ESRogs
10Riccardo Volpato
8evhub
3Riccardo Volpato
9niplav
3evhub
8Richard_Ngo
7adamShimi
7evhub
3adamShimi
5Prometheus
4Vaniver
5Koen.Holtman
4evhub
1IndraG
-8T Ravi
{kind=link}
This is the blog post version of the paper by the same name. Special thanks to Kate Woolverton, Paul Christiano, Rohin Shah, Alex Turner, William Saunders, Beth Barnes, Abram Demski, Scott Garrabrant, Sam Eisenstat, and Tsvi Benson-Tilsen for providing helpful comments and feedback on this post and the talk that preceded it.
This post is a collection of 11 different proposals for building safe advanced AI under the current machine learning paradigm. There's a lot of literature out there laying out various different approaches such as amplification, debate, or recursive reward modeling, but a lot of that literature focuses primarily on outer alignment at the expense of inner alignment and doesn't provide direct comparisons between approaches. The goal of this post is to help solve that problem by providing a single collection of 11 different proposals for building safe advanced AI—each including both inner and outer alignment components. That being said, not only does this post not cover all existing proposals, I strongly expect that there will be lots of additional new proposals to come in the future. Nevertheless, I think it is quite useful to at least take a broad look at what we have now and compare and contrast some of the current leading candidates.
It is important for me to note before I begin that the way I describe the 11 approaches presented here is not meant to be an accurate representation of how anyone else would represent them. Rather, you should treat all the approaches I describe here as my version of that approach rather than any sort of canonical version that their various creators/proponents would endorse.
Furthermore, this post only includes approaches that intend to directly build advanced AI systems via machine learning. Thus, this post doesn't include other possible approaches for solving the broader AI existential risk problem such as:
For each of the proposals that I consider, I will try to evaluate them on the following four basic components that I think any story for how to build safe advanced AI under the current machine learning paradigm needs.
I think it’s often easy to focus too much on either the alignment side or the competitiveness side while neglecting the other. We obviously want to avoid proposals which could be unsafe, but at the same time the “do nothing” proposal is equally unacceptable—while doing nothing is quite safe in terms of having no chance of directly leading to existential risk, it doesn’t actually help in any way relative to what would have happened by default. Thus, we want proposals that are both aligned and competitive so that they not only don’t lead to existential risk themselves, but also help existential risk in general by providing a model of how safe advanced AI can be built, being powerful enough to assist with future alignment research, and/or granting a decisive strategic advantage that can be leveraged into otherwise reducing existential risk.
The 11 proposals considered in this post are, in order:[1]
EDIT: For some other proposals that didn't make it onto this list because they came out after this post, see “Imitative Generalization” and “AI safety via market making.”
1. Reinforcement learning + transparency tools
Here's our first approach:
An image of OpenAI's hide and seek game.
That's the approach—now is it aligned? Competitive?
Outer alignment. Outer alignment here is entirely dependent on whatever the dominant behavior is in the training environment—that is, what is the deployment behavior of those models which perform optimally in the training environment. If corrigibility, honesty, cooperation, etc. do in fact dominate in the limit, then such an approach would be outer aligned. By default, however, it seems quite difficult to understand the limiting behavior of complex, multi-agent environments, especially if they’re anywhere as complex as the actual human ancestral environment. If following human instructions is incentivized, for example, that could lead to corrigibility in the limit—or it could lead to agents which only choose to follow human instructions for the instrumental reason of believing it will help them acquire more resources. Alternatively, it might be possible to isolate the structure that was present in the human ancestral environment that led us to be cooperative, honest, etc. One worry here, however, is that even if we could figure out how to properly incentivize cooperation, it might result in agents that are cooperative with each other but not very cooperative with us, similarly to how we might not be very cooperative with aliens that are very different from us.
Inner alignment. The idea of inner alignment in this situation is to ensure that training produces something in line with the optimal behavior in the environment (the alignment of the optimal behavior being an outer alignment question) rather than other, potentially perverse equilibria. The basic proposal for how to avoid such perverse equilibria with this proposal is via the use of checks such as transparency tools and adversarial training to detect inner alignment failures before the model is deployed. Chris Olah describes this sort of transparency checking as giving you a “mulligan” that lets you throw away your model and start over if you find something wrong. Thus, ideally, if this approach ends up not working it should be clear before the model is deployed, enabling either this approach to be fixed or a new approach to be found instead. And there is a reasonable chance that it does just work—we don’t understand our models’ inductive biases very well, but it seems entirely possible that they could work out such that pseudo-alignment is disincentivized.
In my opinion, while it seems quite plausible to me that this sort of approach could catch proxy pseudo-alignment, it seems unlikely that it would successfully catch deceptive pseudo-alignment, as it could be very difficult to make transparency tools that are robust to a deceptive model actively trying to trick them. To catch deceptive alignment, it seems likely to be necessary to incorporate such checks into the training process itself—which is possible to do in this setting, though is not the approach I described above—in order to prevent deception from occurring in the first place rather than trying to detect it after the fact.
Training competitiveness. Training competitiveness here seems likely to depend on the extent to which the sort of agency produced by RL is necessary to train advanced AI systems. Performing RL in highly complex, difficult-to-simulate environments—especially if those environments involve interaction with the real world—could be quite expensive from a training competitiveness standpoint. Compared to simple language modeling, for example, the difficulty of on-policy data collection combined with low sample-efficiency could make full-scale RL much less training competitive. These sorts of competitiveness concerns could be particularly pronounced if the features necessary to ensure that the RL environment is aligned result in making it significantly more difficult to simulate. That being said, if RL is necessary to do anything powerful and simple language modeling is insufficient, then whether or not language modeling is easier is a moot point. Whether RL is really necessary seems likely to depend on the extent to which it is necessary to explicitly train agents—which is very much an open question. Furthermore, even if agency is required, it could potentially be obtained just by imitating an actor such as a human that already has it rather than training it directly via RL.
Performance competitiveness. The question for performance competitiveness here is to what extent it is possible to create an environment that incentivizes all the behavior you might want from your AGI. Such an environment doesn’t need to be purely simulated—you could do some simulation training and some real-world training, for example. Regardless of how your RL environment is constructed, however, it needs to actually incentivize the correct behavior for the tasks that you want to use your AI for. For example: can you incentivize good decision-making? Good question-answering? Good learning ability? Do you need good fine motor control, and if so, can you incentivize it? These are highly non-trivial questions: it could be quite difficult to set up an RL environment to teach an agent to do all of the tasks you might want it to perform to fill all the economic niches for AGI, for example. Of course, this is going to be highly dependent on what exactly those economic niches are that you want your advanced AI to fill.
2. Imitative amplification + intermittent oversight
Though many of the approaches on this list make use of the basic iterated amplification framework, imitative amplification is probably the most straightforward—though it still has a good deal of moving parts.
To define imitative amplification, we’ll first define Amp(M)—the “amplification operator”—as the procedure where a human H answers a question with access to a model M.[2]
A diagram of the amplification operator Amp(M) where white arrows indicate information transfer, Q is a question, A is Amp(M)’s answer, H is a human, and M is the model.
Then, imitative amplification is just the procedure of iteratively training M to imitate Amp(M).
The basic imitative amplification setup where green arrows indicate amplification, gray arrows indicate training, and cyan arrows indicate the imitative amplification loss.
Finally, we can define imitative amplification + intermittent oversight—which is the full approach we want to consider here—as the combination of imitative amplification with intermittent oversight of M by Amp(M) whenever the target model changes. Specifically, we want Amp(M) to look for deceptive or otherwise catastrophic behavior in M by utilizing things like transparency tools and adversarial attacks.
Imitative amplification plus intermittent oversight where red arrows indicate oversight (from the overseer to the overseen model).
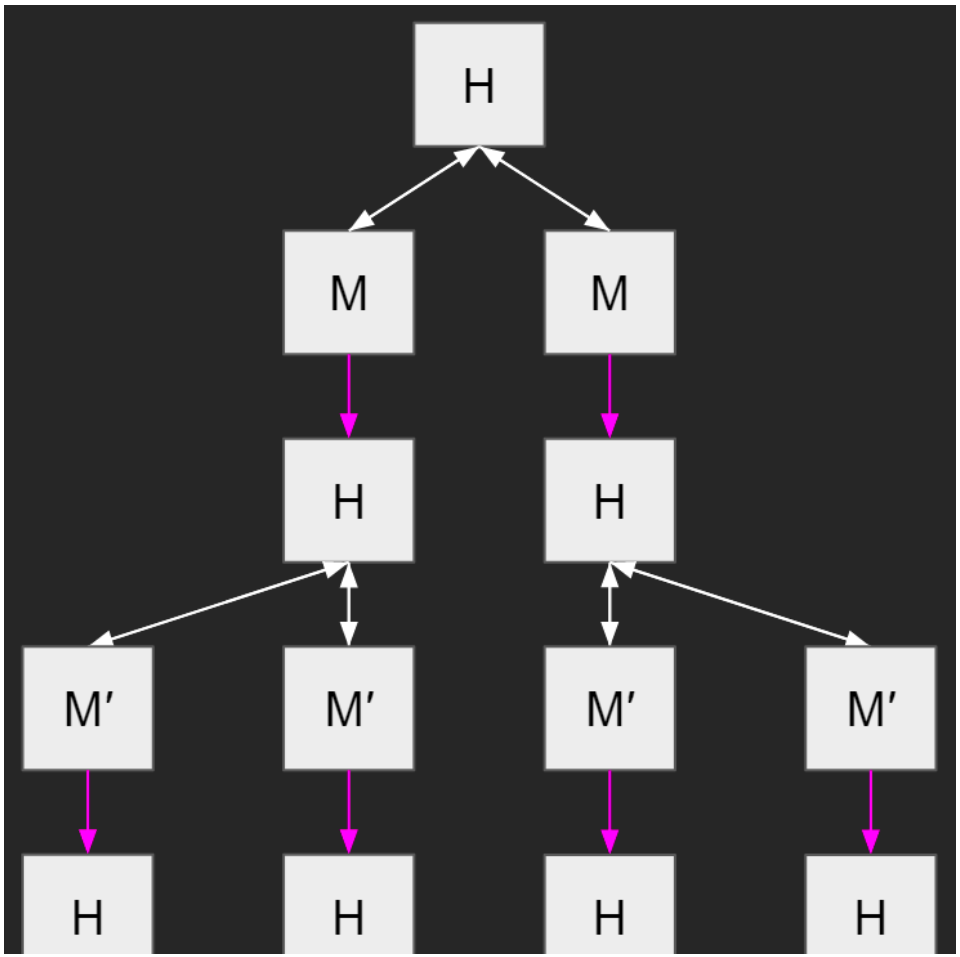
Outer alignment. Since imitative amplification trains M to imitate Amp(M), it limits[3] to the fixed point of the Amp operator, which Paul Christiano calls HCH for “Humans Consulting HCH.” HCH is effectively a massive tree of humans consulting each other to answer questions.
A (partial) diagram of HCH where white arrows indicate information transfer.
Thus, whether imitative amplification is outer aligned is dependent on whether HCH is aligned or not. HCH’s alignment, in turn, is likely to depend heavily on the specific humans used and what sort of policy they’re implementing. The basic idea, however, is that since the limit is composed entirely of humans—and since we can control what those humans do—we should be able to ensure that all the optimization power is coming from the humans (and not from memetic selection, for example), which hopefully should allow us to make it safe. While there are certainly valid concerns with the humans in the tree accidentally (or purposefully) implementing some misaligned policy, there are possible things you can do to address these problems.
Inner alignment. The hope here is to be able to detect and fix serious inner alignment failures via the use of intermittent oversight—that is, inspection by a human with access to a previous version of the model. Thus, the question of inner alignment here is dependent on the question of whether such an overseer would be able to detect deceptive or otherwise catastrophic behavior in the model. Ideally, if such detection is working, it should be clear as soon as the model starts to become misaligned, giving us the opportunity to either fix the issue or find a new approach. For that to work, however, it will likely need to be the case that the intermittent oversight is performed regularly enough to catch any deception as soon as it starts appearing since once a model becomes deceptive it might be significantly harder to detect problems if it starts trying to obfuscate its deception.
That being said, while detecting deceptive cognition early enough directly might be quite difficult, it might be possible to instead detect deceptive behavior indirectly by verifying a condition that rules out deception while still being relatively easy to verify such as myopia. In this context, a myopic model would be one that determines its output based on some fixed standard such as distance to HCH while a non-myopic model would be one that determines its output based on its consequences.[4] For a more detailed explanation of how such myopia verification might work, see “Towards a mechanistic understanding of corrigibility.”[5]
Additionally, because we do intermittent oversight whenever we change the target network, we have a guarantee that the overseer is always at least as strong as any targets that the model was trained to imitate. That being said, the model could end up stronger than the targets it was trained to imitate if it manages to, for example, achieve significant compression of what the targets are doing—which in fact is necessary for training competitiveness. Furthermore, even if the overseer is stronger than the model, the offense-defense balance could be such that a deceptive model would still be able to hide its deception. Which direction the offense-defense balance lies in is likely to depend heavily on what sorts of transparency tools the overseer has access to.
Training competitiveness. First, the training competitiveness of imitative amplification is likely to depend on whether pure imitation can be turned into a rich enough reward signal to facilitate highly sample-efficient learning. In my opinion, it seems likely that human language imitation (where language includes embedded images, videos, etc.) combined with techniques to improve sample efficiency[6] will be competitive at some tasks—namely highly-cognitive tasks such as general-purpose decision-making—but not at others, such as fine motor control. If that’s true, then as long as the primary economic use cases for AGI fall into the highly-cognitive category, imitative amplification should be training competitive. For a more detailed analysis of this question, see “Outer alignment and imitative amplification.”
Second, imitative amplification + intermittent oversight could also fail to be training competitive if it is very difficult for the intermittent oversight check to ever pass. This could happen if, for example, the training process for imitative amplification doesn’t naturally produce models that are transparent enough to facilitate such a check. That being said, what counts as “transparent enough” again depends heavily on the specifics of the transparency tools that the overseer has access to.
Performance competitiveness. The performance competitiveness question here, as with the outer alignment question, is heavily dependent on the properties of HCH, as imitative amplification is specifically designed to limit toward HCH. In particular, performance competitiveness is dependent on whether HCH is sufficiently universal so as to be capable of solving whatever hard problems we might want advanced AI to solve. For example, if trees of humans can’t replicate intuitive flashes of insight, and such flashes of insight are necessary to solve the sorts of highly-cognitive tasks we want AGI for, then imitative amplification would fail to be performance competitive. Alternatively, as long as it is always possible for a human to break down complex tasks that they can’t answer themselves into easier subtasks, then imitative amplification should be performance competitive. Note that it doesn’t have to be the case that this work for an arbitrary human without any training—only for the sort of human from whom you would actually be collecting training data.
3. Imitative amplification + relaxed adversarial training
The basic idea here is very similar to the previous approach in that we start out with pure imitative amplification.
The basic imitative amplification setup.
However, instead of doing intermittent oversight checks, we instead train directly on the intermittent oversight signal—that is, we jointly train M on the imitation loss and on decreasing the probability of catastrophe as assessed by Amp(M)—yielding a relaxed adversarial training setup.
Imitative amplification plus relaxed adversarial training where the red arrows indicate the oversight loss.
Outer alignment. Imitative amplification + relaxed adversarial training should effectively have the same outer alignment properties as imitative amplification + intermittent oversight. If we assume that it is possible to imitate HCH in a demonstrably non-catastrophic way,[7] then the catastrophe-checking imposed by either relaxed adversarial training or intermittent oversight shouldn’t affect the theoretical limiting behavior. Such a limit assumes an infinite training distribution, however, which in practice is, of course, impossible, leaving open the possibility for the two different approaches to have quite different behavior in the finite data regime, giving them potentially quite different inner alignment properties.
Inner alignment. Compared to intermittent oversight, relaxed adversarial training could have very different inner alignment properties. Intermittent oversight requires performing oversight after a period of training during which the model could potentially have become deceptive. Thus, intermittent oversight could potentially require catching deception after the fact, giving the deceptive model the opportunity to try to obfuscate its own cognition to trick the overseer.[8] Relaxed adversarial training, by contrast, has the potential to avoid deception before it ever occurs by providing a consistent gradient away from deception during the entirety of training, thus avoiding the issue of having to detect deception after the fact. Similarly to intermittent oversight, such a gradient could be achieved by having the overseer enforce a condition such as myopia which is simple enough to reliably enforce while guaranteeing that all models which meet the condition are non-deceptive. However, relaxed adversarial training does come with the possible risk of overfitting the oversight signal, potentially resulting in obfuscated models that pass oversight despite not actually meeting the condition simply by virtue of having been optimized to do so.
Training competitiveness. Similarly to imitative amplification + intermittent oversight, imitative amplification + relaxed adversarial training could fail to be training competitive either because imitative amplification is uncompetitive or because the oversight check is too hard to pass. On the one hand, relaxed adversarial training could require significantly more total oversight bandwidth, which could make training more difficult. On the other hand, unlike with intermittent oversight, relaxed adversarial training directly trains the model to pass the check, which could significantly boost training competitiveness by increasing the likelihood of the check passing.
For relaxed adversarial training to be more training competitive than intermittent oversight, it needs to the case that it significantly increases the probability of oversight working, which is likely to depend on the overfitting question of whether relaxed adversarial training is likely to overall increase or decrease model transparency. The critical question here is going to be how hard it is to find a model that is demonstrably non-catastrophic under the two different oversight regimes. For a more detailed analysis of this question, see “Relaxed adversarial training for inner alignment.”
Performance competitiveness. Similarly to the outer alignment question, the performance competitiveness properties of imitative amplification + intermittent oversight and imitative amplification + relaxed adversarial training should be effectively the same, with performance competitiveness here highly dependent on the competitiveness of HCH.
4. Approval-based amplification + relaxed adversarial training
The idea behind approval-based amplification is to substitute the imitation signal in imitative amplification with an approval signal, training M to maximize the approval of Amp(M). This gives us a myopic reward signal which can then be optimized via the use of some sort of myopic reinforcement learning.
Approval-based amplification where the blue arrows indicate the approval loss.
We can then add on top of that a relaxed adversarial training signal, training M to also minimize the probability of catastrophe as assessed by Amp(M).
Approval-based amplification + relaxed adversarial training where the red arrows indicate the oversight loss.
Additionally, it is worth noting that, in practice, since oversight can be treated as a form of approval, you can just compute one approval signal that includes both metrics rather than two distinct approval signals.
Outer alignment. For the purposes of outer alignment and performance competitiveness, we have to understand what exactly the theoretical limit of approval-based amplification is, which in general is not HCH. Instead, approval-based amplification limits to the following tree, where blue arrows indicate approval-maximization (such that M is maximizing the approval of H consulting M′ which is maximizing the approval of H consulting M′′ and so on).[9]
The top of the approval-based amplification limiting tree where white arrows indicate information transfer, blue arrows indicate approval maximization, H are humans, and M are models.
As you can see from the tree, the limit of approval-based amplification involves humans interspersed with models attempting to maximize the approval of their descendants. Thus, unlike the HCH tree, which was composed only of humans, analyzing the approval-based amplification tree involves analyzing the behavior of arbitrary models trained on approval-maximization signals—and, in fact, many such models as they appear all throughout the tree each with a different subtree that they are maximizing the approval of.[10] As a result, producing an outer alignment guarantee regarding such a tree seems quite difficult, especially given the distinct possibility of the models gaming the approval signal. For additional detail on this question, see “Outer alignment and imitative amplification.”
Inner alignment. We are still using relaxed adversarial training here, so for inner alignment to work we need the same guarantee from before of a consistent gradient away from deception. Note that we can still try to have Amp(M) enforce myopia as a way of getting that gradient, as approval-maximization is a single-step reward signal that is entirely compatible with a myopic agent.[11] In the approval-based setting, however, Amp(M) is a different entity that limits to a different tree, meaning it could have different properties regarding how good its oversight signal is. In particular, the fact that approval-based amplification directly incentivizes M to fool H into approving of it could result in M being more prone to deception, more likely to hide facts from H during oversight, and/or more likely to obfuscate its internals if internals-checking is part of the oversight signal. That being said, it could also be that relaxed adversarial training works better in an approval-based setting if it results in a more powerful Amp(M) that is better at performing oversight because M was trained to provide more helpful information.
Training competitiveness. Training competitiveness could be quite different with approval-based amplification compared to imitative amplification, as approval provides a very different training signal than imitation. In particular, the standard maxim that it is generally easier to evaluate behavior than produce it seems to suggest that human approval should produce a significantly richer training signal than the simple automated distance metric in imitative amplification, resulting in more efficient training. This isn’t necessarily the case, however—an automated distance metric as computed by a powerful language model, for instance, could still produce a fairly rich (and more nicely differentiable) training signal.
Additionally, approval-based amplification could also have different training competitiveness properties in terms of the likelihood of the relaxed adversarial training check passing. If approval-based amplification leads to models with more obfuscated internals, for example—perhaps because the model is incentivized to obfuscate how it’s gaming the approval signal—then that could hurt training competitiveness, as it could make it harder for Amp(M) to become confident that M is safe (in addition to hurting inner alignment by making M in fact less likely to be safe).
Performance competitiveness. Performance competitiveness for approval-based amplification depends on the properties of the approval-maximization tree given previously. Compared to HCH, it is quite possible for that tree to be either more or less competitive.
On the one hand, approval-maximizing models might be able to produce ideas/considerations/arguments that no human would have ever come up with, enabling the approval-maximization tree to be more competitive. In particular, if humans are significantly better at knowing good ideas when they see them than producing good ideas themselves—which fits with the standard maxim that it’s easier to evaluate behavior than produce it—then approval-based amplification should be more performance competitive than imitative amplification.
On the other hand, approval-maximizing models might game the approval signal by producing convincing-sounding but ultimately bad ideas/considerations/arguments that end up hurting performance competitiveness. For example, an idea could be initially very compelling and thus get high approval despite quite quickly revealing itself to be useless/vacuous/etc. when actually tested out. In such a situation where the bad ideas quickly reveal themselves, the performance competitiveness problems would likely be quite clear, though if it takes a very long time for the bad ideas to reveal themselves, then approval-maximization might initially look a lot better from a performance competitiveness standpoint than it actually is.
5. Microscope AI
Microscope AI is a fairly unique proposal which is designed to bypass some of the dangers of building highly agentic AGI systems by leveraging powerful transparency tools. The basic proposal is as follows.
Microscope AI is predicated on the basic insight that using transparency tools on a model doesn’t just teach us about that model—it also gives us useful information about the data that the model was trained on. Chris Olah talks about this basic phenomenon in his post “Visualizing Representations: Deep Learning and Human Beings:”
The basic goal of microscope AI is to produce high-quality knowledge that can inform important decision-making rather than to produce powerful AGI systems that can make those decisions themselves.
Outer alignment. Paul Christiano’s argument that the universal prior is malign suggests that there might be deceptive optimization in the limit of perfect prediction. As a result, if we interpret outer alignment as referring to the behavior at minimal loss, it seems likely that microscope AI is not outer aligned. That doesn’t necessarily rule out microscope AI as a proposal, however—whether such deceptive optimization would actually occur in practice is still a very open question. In particular, the argument that the universal prior is malign relies on an uncomputable limit—polynomial approximations, for example, could still be completely fine. Furthermore, the inner alignment technique proposed here of using transparency tools to detect and prevent any optimization could prevent this problem entirely if successful.
Inner alignment. Since the goal here is not to produce a model performing optimization (a mesa-optimizer) in the first place, the question of inner alignment becomes rather different in this situation. We still want to avoid a deceptive or otherwise misaligned mesa-optimizer, but we want to do so by avoiding all mesa-optimization rather than by ensuring that any mesa-optimization is aligned. Specifically, the strategy here is to use transparency tools to detect any optimization (as opposed to just predictive modeling) and halt if we see anything of that form. This has the major benefit of sidestepping a lot of the most pernicious inner alignment concerns, but it also comes with lots of its own problems. Whether this will work is likely to be dependent on a couple of different factors.
First, it is an open question of whether there exists a sensible way in which optimization and modeling can be distinguished from each other. It seems quite likely that any world model which admits queries of the form “what is the probability that a is the optimal action according to utility u” or “what is the best action for agent A to take in state x” will implicitly have to be running some sort of optimization algorithm. Thus, any notion of a “pure world model” would likely have to either rule out such queries, ensure they are being estimated without the use of optimization, or otherwise find some way to ensure that they are safe. For a more thorough treatment of the difficulty here, see Abram Demski’s “Partial Agency” sequence.
Second, assuming it is possible to distinguish between modeling and optimization in theory, it also needs to be possible in practice given whatever set of transparency tools are available. If the model can start performing optimization and potentially become deceptive before its optimization can be detected, that would obviously pose a major problem to this sort of approach.
Training competitiveness. Microscope AI relies on being able to competitively train predictive models with useful internal representations. Thus, the question of training competitiveness for microscope AI comes down to the question of whether the process of training a predictor is a competitive way to extract useful information from a dataset. Given the success of current predictive models such as GPT-2, it seems likely that it will be competitive to train powerful predictors—though it remains to be seen how competitive the process of extracting what they’ve learned will be. How competitive that extraction process is seems likely to depend heavily on what sort of state-of-the-art transparency tools are available.
Performance competitiveness. Performance competitiveness is perhaps the biggest question mark regarding microscope AI, as microscope AI forgoes producing AI agents which directly take actions in the world. The question of performance competitiveness for microscope AI is thus the question of whether enhanced human understanding alone—without AI agents—is sufficient for the economic use cases where one might otherwise want highly agentic advanced AI (e.g. an AGI).
This question is likely to depend heavily on what exactly those use cases are. Like with amplification, if you need lots of fine motor control, microscope AI is unlikely to get you there. Furthermore, unlike amplification, if you need lots of low-level decision-making where it’s too expensive to hire a human, microscope AI won’t help much there either (whereas amplification would be fine). Potentially microscope AI could give humans the knowledge to safely build other systems which could solve such tasks, however. Furthermore, if the primary use case for AGI is just high-level big-picture decision-making (automating CEOs or doing AI research, for example), then it seems likely that microscope AI would have a real shot of being able to address those use cases. In that sort of a situation—where you’re only trying to make a small number of high-quality decisions—it seems likely to be fairly cheap to have a human in the loop and thus simply improving that human’s knowledge and understanding via microscope AI might be sufficient to produce competitive decision-making. This is especially true if there is a market premium on having a human making the decisions, perhaps because that makes it easier to negotiate or work with other humans.
6. STEM AI
STEM AI is a very simple proposal in a similar vein to microscope AI. Whereas the goal of microscope AI was to avoid the potential problems inherent in building agents, the goal of STEM AI is to avoid the potential problems inherent in modeling humans. Specifically, the idea of STEM AI is to train a model purely on abstract science, engineering, and/or mathematics problems while using transparency tools to ensure that the model isn’t thinking about anything outside its sandbox.
This approach has the potential to produce a powerful AI system—in terms of its ability to solve STEM problems—without relying on any human modeling. Not modeling humans could then have major benefits such as ensuring that the resulting model doesn’t have the ability to trick us to nearly the same extent as if it possessed complex models of human behavior. For a more thorough treatment of why avoiding human modeling could be quite valuable, see Ramana Kumar and Scott Garrabrant’s “Thoughts on Human Models.”
Outer alignment. Similarly to microscope AI, it seems likely that—in the limit—the best STEM AIs would be malign in terms of having convergent instrumental goals which cause them to be at odds with humans. Thus, STEM AI is likely not outer aligned—however, if the inner alignment techniques being used are successful at preventing such malign optimization from occurring in practice (which the absence of human modeling could make significantly easier), then STEM AI might still be aligned overall.
Inner alignment. The hope with STEM AI is that by preventing the model from ever considering anything outside its STEM sandbox, the malign limiting behavior that might cause it to fail to be outer aligned can be avoided. Unfortunately, such a sandboxing condition alone isn’t quite sufficient, as a model considering only things in its sandbox could still end up creating other models which would consider things outside the sandbox.[12] Thus, exactly what the correct thing is to do in terms of inner alignment for a STEM AI is somewhat unclear. In my opinion, there are basically two options here: either do something similar to microscope AI and try to prevent all mesa-optimization or do something similar to amplification and ensure that all mesa-optimization that occurs is fully myopic. In either case, the hope would be that the absence of human modeling makes it easier to enforce the desired condition (because modeling an agent such as a human increases the propensity for the model to become agentic itself, for example).
Training competitiveness. Training competitiveness for STEM AI is likely to depend heavily on how hard it is for state-of-the-art machine learning algorithms to solve STEM problems compared to other domains such as language or robotics. Though there exists lots of current progress in the field of applying current machine learning techniques to STEM problems such as theorem proving or protein folding, it remains to be seen to what extent the competitiveness of these techniques will scale, particularly in terms of how well they will scale in terms of solving difficult problems relative to other domains such as language modeling.
Performance competitiveness. Similarly to microscope AI, performance competitiveness is perhaps one of the biggest sticking points with regards to STEM AI, as being confined solely to STEM problems has the major potential to massively limit the applicability of an advanced AI system. That being said, many purely STEM problems such as protein folding or nanotechnology development have the potential to provide huge economic boons that could easily surpass those from any other form of advanced AI as well as solve major societal problems such as curing major illnesses. Thus, if the answer to the reason that you want to build advanced AI in the first place is to get such benefits, then STEM AI might be a perfectly acceptable substitute from a performance competitiveness standpoint. Furthermore, such boons could lead to a decisive strategic advantage that could enable heavy investment in aligning other forms of advanced AI which are more performance competitive.
However, if one of the major use cases for your first advanced AI is helping to align your second advanced AI, STEM AI seems to perform quite poorly on that metric, as it advances our technology without also advancing our understanding of alignment. In particular, unlike every other approach on this list, STEM AI can't be used to do alignment work, as its alignment guarantees are explicitly coming from it not modeling or thinking about humans in any way, including aligning AIs with them. Thus, STEM AI could potentially create a vulnerable world situation where the powerful technology produced using the STEM AI makes it much easier to build advanced AI systems, without also making it more likely that they will be aligned.
This problem could potentially be mitigated if the STEM AI were heavily focused on applications that could potentially assist with alignment such as whole brain emulation, though to what extent that would actually be possible or actually help with alignment is quite unclear.
7. Narrow reward modeling + transparency tools
The approach here is as follows:
DeepMind Safety’s diagram of reward learning as seen in “Scalable agent alignment via reward modeling.”
Since we want to keep our agent confined to only the specific distribution on which it was trained (thus helping prevent possible perverse generalizations), we can also incorporate out-of-distribution detection to train the agent to halt if it encounters a sufficiently out-of-distribution state.
We can also have the human provide additional feedback on the reward model’s internal behavior via the use of transparency tools.
Reward modeling plus oversight of the reward model by the user.
And we can do the same thing with the agent, giving us a similar sort of mulligan as with reinforcement learning + transparency tools.
Reward modeling plus oversight of both the reward model and the agent by the user.
Outer alignment. The question of outer alignment here is going to depend on whether the various feedback mechanisms are sufficient to ensure that, in the limit, the learned reward model is correct over the domain where the action model believes that it is on distribution. This is a highly complex question that depends on a bunch of factors including how good the human’s trajectory and transparency feedback is, how hard it is to train an on/off distribution model, whether the reward model will itself develop optimization in the limit, the extent to which it’s possible for the agent to trick the user into thinking it’s doing a good job when it’s not, etc. Because outer alignment here is dependent on the limiting behavior of such a complex, dynamic process, it’s very hard to determine one way or the other how outer aligned such a proposal is likely to be.
Inner alignment. The use of transparency tools in this approach is actually quite similar to the various relaxed adversarial training approaches since the feedback mechanism here allows the oversight signal coming from the human to be incorporated directly into training. That being said, unlike in relaxed adversarial training—and similarly to the “mulligan” approach in RL + transparency tools—the human doing the oversight here gets no help from the model. Thus, inner alignment for narrow reward modeling + transparency tools comes down to the question of whether a human using transparency tools to perform oversight can prevent the development of deceptive or otherwise catastrophic behavior in either the reward model or the agent. This could be done, for example, by verifying that the reward model isn’t performing any optimization (as in microscope AI) and verifying that the agent is myopic (as was previously suggested could work for amplification).
Such an approach could potentially require that the reward be myopic, however, which might be a fairly serious limitation on the applicability of narrow reward modeling if it was restricted to only those domains with myopic rewards. While it is not necessarily the case that you can’t do myopia verification with a non-myopic reward—you just need to verify that the model treats each episode myopically rather than each step—per-episode myopia verification could be significantly more difficult than per-step myopia verification, as it is potentially a much less natural behavior.
Training competitiveness. The question of training competitiveness here is going to depend on the extent to which reward modeling is a good (compute-efficient, sample-efficient. etc.) way of training AI systems to solve poorly-defined, fuzzy tasks. There are lots of different approaches to solving this basic problem, including not just reward learning approaches but also imitation learning and various different inverse reinforcement learning schemes, and specifically what approach ends up coming out on top still seems quite uncertain. That being said, reward modeling has the major competitiveness advantage of only requiring and depending on human feedback, not human demonstrations, which could be significantly more reliable and easier to elicit. Furthermore, other reward learning schemes such as inverse reinforcement learning can be incorporated into reward modeling by using them to produce a better initial reward model that can then be refined via reward modeling’s feedback mechanism.
Performance competitiveness. Similarly to microscope AI or STEM AI, a potentially major concern with the narrow reward modeling + transparency tools approach is the “narrow” part. While being narrow has potential alignment advantages in terms of reducing reliance on potentially shaky or even malign generalization, it also has the major disadvantage of restricting the approach’s usefulness to only producing relatively narrow advanced AI systems. Thus, the performance competitiveness of narrow reward modeling + transparency tools is likely to depend heavily on the extent to which truly general advanced AI systems are actually practically feasible and economically necessary. For a more detailed analysis of this question, see Eric Drexler’s “Reframing Superintelligence.”
8. Recursive reward modeling + relaxed adversarial training
Recursive reward modeling, as the name implies, is a sort of recursive, non-narrow version of narrow reward modeling. What this results in is effectively a form of amplification where the distillation step which was previously imitation or approval-maximization becomes reward modeling. Specifically, the basic approach here is to train a model M to maximize the reward obtained by performing reward learning on Amp(M).
Two different, equivalent diagrams of recursive reward modeling. The top diagram is taken from “Scalable agent alignment via reward modeling” and the bottom diagram is the equivalent amplification-style diagram where the purple arrows indicate the use of the full reward modeling process.
In this graphic, the images on the top and bottom are meant to represent the same process—specifically, if you take the purple arrow in the bottom image to represent reward modeling, and assume that the agents in the top image are all the same agent just at different time steps,[13] then you get precisely the same procedure represented in both images. Thus, the agent in the largest circle in the top picture is M2 in the bottom picture, the user providing feedback for that agent is Amp(M1), the agent in the medium-sized circle is M1, the user in the medium-sized circle is Amp(M0), and the agent in the smallest circle is M0.
Furthermore, similarly to the other amplification approaches, we can then add relaxed adversarial training by training M and the reward model to minimize the probability of deceptive or otherwise catastrophic behavior as assessed by Amp(M).[14] It’s also worth noting that recursive reward modeling is amenable to intermittent oversight as well if desired instead of relaxed adversarial training.
Recursive reward modeling plus relaxed adversarial training where the red arrows indicate the oversight loss.
Outer alignment. The first step in understanding the outer alignment properties of recursive reward modeling is figuring out what exactly the theoretical limit of the training process is. While we don’t know exactly what the limiting behavior of an individual instance of reward modeling is—as was noted previously for narrow reward modeling—we can express the limit of the recursive version in terms of many individual reward modeling limits. Specifically, we can unroll the recursive reward modeling process out over time to produce a limiting tree similar to the one given for approval-based amplification, except with approval-maximization replaced with reward modeling.
The recursive reward modeling limiting tree where white arrows indicate information transfer, purple arrows indicate reward modeling, H are humans, and M are models.
The purple arrows in this diagram represent perfect reward modeling where M is the model trained to maximize the reward obtained by performing reward modeling on H consulting M′. Now, whether this tree is aligned or not is a very open question. Similarly to approval-based amplification—but unlike imitative amplification—it’s difficult to form a clear model of what exactly this tree would do, as it not only involves humans but also models that are the limit of many individual instances of reward modeling—limits which could potentially involve deceptive or otherwise malign optimization.
Inner alignment. The question of inner alignment here is mostly going to fall on the efficacy of the relaxed adversarial training. Such efficacy could be quite different than with other amplification approaches, however, as both the model helping the human perform oversight and the model being overseen are trained via a very different process in recursive reward modeling. In particular, if the reward model is non-myopic, recursive reward modeling could rule out the possibility of using per-step myopia verification—as was suggested for the other amplification approaches—though per-episode myopia verification could still be possible, as with narrow reward modeling. If per-episode myopia verification is not tenable, however, then an alternative condition that rules out deception while being possible to verify for agents trained via recursive reward modeling might need to be found. Furthermore, if reward modeling has a greater tendency to produce deception than imitation learning, oversight could be significantly harder with recursive reward modeling than with imitative amplification even if such a condition is found. Alternatively, if recursive reward modeling helps produce models that are more capable of assisting with oversight—because reward modeling is more capable of training models to effectively apply transparency tools than imitation learning is, for example—then relaxed adversarial training could work better with recursive reward modeling.
Training competitiveness. The training competitiveness of recursive reward modeling depends on the effectiveness of reward modeling not just as an efficient way of training a model to solve a single fuzzy task—as in narrow reward modeling—but instead the effectiveness of reward modeling in training a general model which can solve an entire collection of fuzzy tasks. That being said, many of the nice training competitiveness properties of reward learning continue to apply even in the recursive setting. For example, unlike imitative amplification—but similarly to approval-based amplification—recursive reward modeling relies only on human feedback rather than on human demonstrations. Furthermore, compared to approval-based amplification, recursive reward modeling is non-myopic, which could allow it to solve credit assignment problems that might be difficult for approval-based amplification.
Performance competitiveness. Performance competitiveness for recursive reward modeling will depend on the competitiveness of its aforementioned limiting tree. Compared to HCH, the recursive reward modeling tree can consider ideas that no human would ever produce, potentially increasing competitiveness. And compared to the approval-maximization tree, the recursive reward modeling tree can learn to execute long-term strategies that short-term approval maximization wouldn’t incentivize. That being said, both of these facets of recursive reward modeling have the potential for danger from an alignment perspective. Furthermore, if the different models in the recursive reward modeling tree each assign some different value to the final output—which could happen if the models are not per-episode myopic—they could try to jockey for control of the tree in such a way that not only hurts alignment but also competitiveness.
9. AI safety via debate with transparency tools
There are many different forms of AI safety via debate, but the approach we’ll be considering here is as follows:
The basic debate setup where Alice is the first debater and Bob is the second debater. Blue lines indicate possible arguments that Alice can make and the red lines indicate possible arguments that Bob can make.
Debate with cross-examination where the orange arrow is an example of cross-examination where Bob (specifically Bob_2, the second Bob) cross-examines a copy of Alice (Alice_1) from two moves previously in the debate.
Debate with cross-examination and transparency tools where the red arrow is an example of Alice_2 using transparency tools on Bob_1.
Outer alignment. Outer alignment for debate depends on whether giving honest, cooperative, helpful advice is the strategy with the greatest probability of winning. Since the first debater gets to choose to defend whatever position they want, in the limit they’ll choose to defend whatever position gives them the greatest probability of winning the debate. Thus, if honest, cooperative, helpful strategies dominate, then the first player will always pursue them in the limit, meaning that aligned answers can be produced at test/deployment time simply by eliciting the first debater’s position. Whether honesty and helpfulness actually dominate in the limit is a very open question, however, and one that depends heavily on many factors such as the set of questions being asked, the effectiveness of the human judges, the length of the debate, etc. For example, if there is significant variation in how difficult different positions are to defend that is independent of their truthfulness (perhaps because arguments with more moving pieces that depend on more things are harder to defend regardless of how true they are) then it seems likely that there would be instances where the truth wouldn’t dominate. That being said, careful mechanism design such as the use of cross-examination could potentially help mitigate such issues.
Inner alignment. The question of inner alignment for debate with transparency tools centers on the effectiveness of the debaters in using the transparency tools to oversee each other. The goal is to directly incentivize the debaters to look for deceptive or otherwise catastrophic behavior in each other using the available tools and present that information to the judge to win the debate. Whether such an approach is actually likely to succeed is dependent on a couple of different factors, however.
First, it’s unclear what sort of condition could be enforced in a debate setup that would successfully rule out deceptive alignment while still allowing for the necessary deception of the second debater, who is forced to defend the second-most probable option, and thus make arguments that they don’t actually believe in. Per-episode myopia could potentially present such a condition, though it might be a difficult condition to enforce.
Second, getting a good training signal for incentivizing such transparency tool use could be quite difficult. The debaters need a way of learning how to inspect other models, a way of learning that doing so is a way to win the debate, and a way of learning the specific bad behavior that they should be looking for. This gets especially tricky if the condition being enforced is just the absence of deception, as getting training examples of catching deception would seem to require producing deceptive models, which is the very thing you’re trying to avoid doing in the first place.
Training competitiveness. Training competitiveness for debate depends on the extent to which the debate game is a compute-efficient, sample-efficient way of training an advanced AI system. Since the debate training process is fundamentally reinforcement learning via self-play on a zero-sum game, the historical success of such methods on environments such as Go, Dota 2, or StarCraft suggests that such self-play might be fairly competitive as a general training procedure. That being said, in comparison to the given environments, debate requires a human in the loop, significantly reducing the amount of training data that can be collected and thus requiring significantly better sample efficiency to train successfully. Such sample efficiency concerns could potentially be resolved via training a supervised model to predict human judging behavior and then training against that, though that could raise many of its own additional safety and/or competitiveness concerns.
Performance competitiveness. It has been proven that debate with cross-examination has the property that arbitrarily strong debaters can convince a polynomial-time judge of the answer to any problem in NEXP. Thus, there is a strong theoretical argument for the performance competitiveness of debate—in the limit, debate has the ability to solve basically any interesting problem that can be solved. While it can be shown that approaches such as approval-based amplification and recursive reward modeling can similarly access NP, the ability of debate to go significantly beyond NP all the way to NEXP suggests that debate might be significantly more performance competitive than those approaches. Of course, such theoretical analysis doesn’t necessarily apply in practice—in reality, even in the limit of training, no model can ever actually be arbitrarily strong, so the practical difference between accessing NP and accessing NEXP might be very minimal.
10. Amplification with auxiliary RL objective + relaxed adversarial training
The approach here is to train a model M on a joint objective composed of three different pieces. First, we’ll train M to imitate Amp(M)—that is, the basic imitative amplification loss.
The basic imitative amplification setup.
Second, we’ll also train M so as to cause Amp(M) to perform well on some RL objective in some environment. The idea here is to treat M’s answers to H’s questions as actions that yield some reward determined by H’s performance in the environment with access to those answers. Thus, we are training M to maximize a combination of the standard imitative loss and the RL reward obtained by Amp(M).
Imitative amplification with an auxiliary RL objective where the white arrows indicate Amp(M) acting in the environment and the yellow arrows indicate the RL loss for training M to maximize the reward obtained by Amp(M).
Finally, we can add relaxed adversarial training by training M to decrease the probability of catastrophe as assessed by Amp(M) trying to find adversarial attacks.
Imitative amplification with an auxiliary RL objective plus relaxed adversarial training where the red arrows indicate the oversight loss.
As a concrete example of this approach where the RL environment in question is the AI safety via debate game, see “Synthesizing amplification and debate.”
Outer alignment. An interesting property of this approach is that its outer alignment properties can be controlled by determining how to anneal the various different components of the loss in the limit. Annealing towards the imitative loss yields HCH as the limit—giving this approach the same outer alignment properties as imitative amplification—whereas annealing towards the RL loss yields whatever the dominant behavior in the given RL environment is as the limit. Given that HCH is generally significantly easier to understand than RL limiting behavior, it seems likely that in the majority of cases you will want to anneal towards the imitative loss to get the best outer alignment properties. That being said, there are other options—for example, you could use the imitative loss as a constraint such that the model is trained to do well on the RL objective without deviating from HCH by more than some fixed amount. Whether such an approach is outer aligned or not is likely to depend heavily on the specific metric used to measure the distance from HCH as well as the robustness of HCH to small deviations according to that metric.
Inner alignment. We’re using relaxed adversarial training here, which means that—as with all the other relaxed adversarial training approaches—inner alignment is likely to come down to whether or not the overseer is able to produce a consistent gradient away from deception, which as always could be quite different than with other approaches since both the model helping with oversight and the model being overseen are being trained differently. Compared to imitative amplification, the addition of an RL objective could help significantly if performance in the RL environment is highly correlated to oversight effectiveness. Furthermore, the fact that the model is being trained to maximize the performance of the human with access to the model means that the model is forced to learn how to present its information to a human to get reward, which could make it significantly more transparent and help with oversight. On the other hand, explicitly training the model to produce answers which change a human’s behavior could also encourage the model to trick the human, which could make deception more likely and thus oversight harder. Additionally, training on an RL objective could make it significantly harder to do myopia verification as optimizing even partially for a non-myopic RL loss could act as a strong force pushing the model away from myopia.
Training competitiveness. Compared to imitative amplification, the addition of an RL loss could significantly improve training competitiveness by producing a much richer reward signal, though at the cost of having to run the RL environment. Furthermore, the addition of the imitative loss could even improve training competitiveness relative to pure RL by providing a less sparse reward. Additionally, similarly to recursive reward modeling, incorporating an RL loss enables directly training the model to solve long-term tasks involving difficult credit assignment problems that might be hard for imitative amplification alone to handle (though similarly to recursive reward modeling this trades off with the potential safety benefits of myopia).
That being said, it is unclear what happens to that behavior if the RL loss is annealed away—ideally, if it is possible for HCH to produce the behavior, then hopefully the model will converge on that, though that requires the optimal RL behavior to be close enough to HCH that first training on the RL loss and then training on the imitative loss actually helps with the imitation task. For that to be the case, success on the RL task likely needs to be highly correlated with good HCH imitation, for which language modeling and human approval maximization tasks (such as the AI safety via debate game as in “Synthesizing amplification and debate”) could be good candidates.
Performance competitiveness. As with outer alignment, performance competitiveness is likely to depend heavily on exactly how the different losses are annealed in the limit. Annealing towards the imitative loss, as was suggested previously, makes the limit HCH, giving this approach the same performance competitiveness properties as imitative amplification. As was mentioned previously, however, there are other options, such as using the imitative loss as a constraint such that the model is trained to maximize the RL reward without deviating too far from HCH. Such a constraint could help performance competitiveness compared to training purely on the RL loss—if the resulting model is significantly better at interacting with humans, for example—or hinder performance competitiveness—if it’s very difficult to do well on the RL task while staying close to HCH.
11. Amplification alongside RL + relaxed adversarial training
In this approach, the goal is to simultaneously train two models, a question-answering system M and an RL agent π.
We’ll train π on the joint objective of maximizing the RL reward and decreasing the probability of deceptive or otherwise catastrophic behavior as assessed by Amp(M). Note that while we’re using a sort of relaxed adversarial training loss here, the overseer is using a totally different model (M) than the model being overseen (π).
The training process for π in amplification alongside RL where the white arrow indicates π’s actions in the environment, the yellow arrow indicates π’s RL loss, and the red arrows indicate the oversight loss for π.
Then, we’ll train M on the following joint objective.
First, we want to include the standard imitative amplification loss and train M to imitate Amp(M).
Amplification alongside RL where M is trained only via an imitative loss.
Second, we want to train M to cause Amp(M) to predict π’s actions and the RL environment’s responses well. The idea here is to train M to tell the human everything the human needs to know to understand what π is doing and how to replicate π’s behavior so that the human with access to the model can match π’s performance in the RL environment.
Amplification alongside RL where the white arrows to Amp(M) indicate information that Amp(M) attempts to predict in the RL environment and the orange arrows indicate the prediction loss for training M to cause Amp(M) to predict well.
Third, we can add standard relaxed adversarial training and also train M to decrease the probability of deceptive or otherwise catastrophic behavior as assessed by Amp(M).
Amplification alongside RL + relaxed adversarial training where the red arrows indicate the oversight loss.
Finally, once we’ve trained both M and π via the above losses, a critical component of this approach is that we then do away with π completely and exclusively deploy the resulting M.
Outer alignment. Since we only deploy M, not π, the question of outer alignment here should be entirely dependent on whether this procedure produces outer aligned M. Furthermore, similarly to the previous approach, we can anneal the combination of losses here to get the desired limiting behavior and thus control our outer alignment properties. In particular, if we anneal towards the imitative loss, this approach can be made to limit to HCH, giving it the same outer alignment properties as imitative amplification. Furthermore, even if we don’t anneal towards the imitative loss, as long as it is possible for HCH to fully predict both π and the RL environment in the limit and the imitative loss isn’t annealed away completely, then at minimal loss we should still end up with HCH.
Inner alignment. Inner alignment is particularly tricky for this approach. First, there’s the standard relaxed adversarial training question of whether Amp(M) will be able to properly oversee M. Compared to the previous approach, the fact that the auxiliary reward is purely predictive rather than a full RL loss should help us here, as it means that our loss is entirely myopic and thus we should be able to do myopia verification. That being said, if π is sufficiently non-myopic, having M predict π while still staying myopic itself could be a challenge.
Additionally, there’s also the problem of π itself—while we throw away π at the end, there are still likely to be opportunities for a sufficiently competent and deceptive π to cause serious issues. For example, π could choose its actions to influence M’s training in a particular way—or just break out of its sandboxing and directly take bad actions in the world. Thus, we need the oversight of π by Amp(M) to at least work sufficiently well to prevent such issues. For that to happen, it needs to be the case that Amp(M) with access to transparency tools can predict when/if π will ever produce such catastrophic behavior. Thus, the fact that we’re explicitly training M to cause Amp(M) to be able to predict π could be quite helpful here, as that should hopefully make Amp(M) good enough at predicting π to foresee π becoming deceptive or producing any such bad behavior.
Training competitiveness. Compared to other amplification approaches, this approach could be significantly more training competitive as it enables us to just train an RL model with minimal restrictions. That being said, it also requires us to jointly train both an RL model and an amplification model, which could make it significantly less competitive, especially if it’s difficult to successfully train the amplification model to predict the RL model. That being said, such training can be viewed as effectively just model distillation, which is generally fairly doable even for current models. That being said, the inclusion of the imitative loss will change things, especially if you anneal towards the imitative loss in the limit. In such a situation, the question becomes how useful the auxiliary RL prediction task is in helping with the core imitation task, which—similarly to the previous approach—could be very dependent on the specific RL environment used and how related performance on that RL environment is to the imitation task.
Performance competitiveness. As with outer alignment, annealing towards the imitative loss should produce HCH as the limit, giving this approach the same performance competitiveness properties as imitative amplification. Furthermore—again as with outer alignment—even if the imitative loss isn’t annealed to completely, as long as HCH can predict π in the limit, you should still get HCH at minimal loss.
Note that the order here is chosen purely for pedagogical reasons and is not meant to imply any sort of measure of importance. ↩︎
Note that in practice Amp(M) doesn’t need to always be computed with an actual human. H can simply be M some fixed fraction of the time, for example—or more often when M is confident and less often when M is uncertain—and the resulting procedure is effectively the same. See “A concrete proposal for adversarial IDA” for an example of how something like that could work. ↩︎
Imitative amplification leads to HCH in the limit of training a perfect predictor over all possible inputs—that is, an infinite amount of training data, an infinitely large model, and an infinitely large amount of training time. ↩︎
Enforcing myopia for amplification could also have the side benefit of improving competitiveness, as a non-myopic amplification model might try to make its output simpler and thus less useful if it is trying to make a human consulting it easier to predict. ↩︎
Further exploration of myopia verification will also be forthcoming in a future post. ↩︎
See Paul Christiano’s “Efficient feedback” for some examples of possible sample-efficiency-improving techniques. ↩︎
That is, it needs to be the case that in the limit there exists a model that perfectly imitates HCH in such a way that an amplified overseer will be convinced that the imitator is non-catastrophic. ↩︎
This sort of failure mode could be particularly pernicious if the deceptive model is capable of gradient hacking. ↩︎
Verifying that the given tree is, in fact, the limit of approval-based amplification is a straightforward exercise of expanding the training procedure out over time. Note that the models at the top of the tree are the most recent models and the models at the bottom of the tree are the oldest. ↩︎
It is worth noting that there is also the possibility of recovering HCH as the limit of approval-based amplification if the approval signal is implemented as a human-computed distance metric relative to what the human would have done before seeing the model’s answer. ↩︎
In particular, myopia verification for approval-based amplification could be used to produce approval-directed agents. ↩︎
The problem of “forwarding” safety guarantees regarding a model performing meta-learning to any other models found by that meta-learning procedure is a general problem that occurs in all inner alignment schemes, though it is particularly pernicious in this situation. For a more detailed discussion of this problem, see the “Meta-learning” section in “Relaxed adversarial training for inner alignment.” ↩︎
“Scalable agent alignment via reward modeling: a research direction” notes that, while they initially assume that each agent is completely separate, “While this kind of sequential training is conceptually clearer, in practice it might make more sense to train all of these agents jointly to ensure that they are being trained on the right distribution. Moreover, all of these agents may share model parameters or even be copies of the same agent instantiated as different players in an adversarial game.” Thus, while the different agents are presented here as different instances of the same model—which is a type of recursive reward modeling—it is worth noting that recursive reward modeling also includes other possibilities such as using completely different models for the different agents. ↩︎
“Scalable agent alignment via reward modeling: a research direction” mentions the possibility of such oversight, though does not include it as part of the base proposal as is done here, noting that “When using recursive reward modeling users have the option to provide feedback on the cognitive process that produced outcomes, but they are not required to do so. Moreover, this feedback might be difficult to provide in practice if the policy model is not very interpretable.” ↩︎