There’s a common perception that various non-deep-learning ML paradigms - like logic, probability, causality, etc - are very interpretable, whereas neural nets aren’t. I claim this is wrong.
It’s easy to see where the idea comes from. Look at the sort of models in, say, Judea Pearl’s work. Like this:
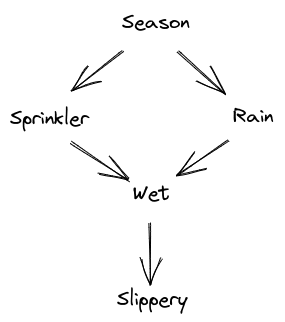
It says that either the sprinkler or the rain could cause a wet sidewalk, season is upstream of both of those (e.g. more rain in spring, more sprinkler use in summer), and sidewalk slipperiness is caused by wetness. The Pearl-style framework lets us do all sorts of probabilistic and causal reasoning on this system, and it all lines up quite neatly with our intuitions. It looks very interpretable.
The problem, I claim, is that a whole bunch of work is being done by the labels. “Season”, “sprinkler”, “rain”, etc. The math does not depend on those labels at all. If we code an ML system to use this sort of model, its behavior will also not depend on the labels at all. They’re just suggestively-named LISP tokens. We could use the exact same math/code to model some entirely different system, like my sleep quality being caused by room temperature and exercise, with both of those downstream of season, and my productivity the next day downstream of sleep.
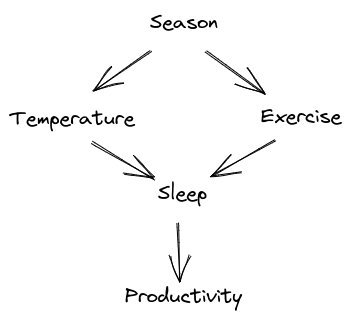
We could just replace all the labels with random strings, and the model would have the same content:
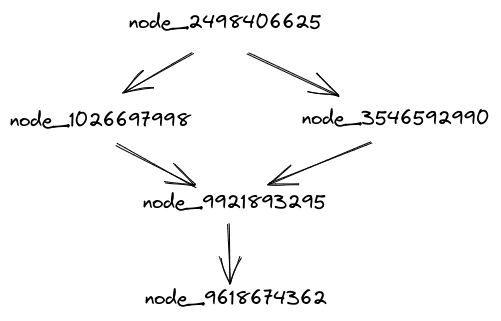
Now it looks a lot less interpretable.
Perhaps that seems like an unfair criticism? Like, the causal model is doing some nontrivial work, but connecting the labels to real-world objects just isn’t the problem it solves?
… I think that’s true, actually. But connecting the internal symbols/quantities/data structures of a model to external stuff is (I claim) exactly what interpretability is all about.
Think about interpretability for deep learning systems. A prototypical example for what successful interpretability might look like is e.g. we find a neuron which robustly lights up specifically in response to trees. It’s a tree-detector! That’s highly interpretable: we know what that neuron “means”, what it corresponds to in the world. (Of course in practice single neurons are probably not the thing to look at, and also the word “robustly” is doing a lot of subtle work, but those points are not really relevant to this post.)
The corresponding problem for a logic/probability/causality-based model would be: take a variable or node, and figure out what thing in the world it corresponds to, ignoring the not-actually-functionally-relevant label. Take the whole system, remove the labels, and try to rederive their meanings.
… which sounds basically-identical to the corresponding problem for deep learning systems.
We are no more able to solve that problem for logic/probability/causality systems than we are for deep learning systems. We can have a node in our model labeled “tree”, but we are no more (or less) able to check that it actually robustly represents trees than we are for a given neuron in a neural network. Similarly, if we find that it does represent trees and we want to understand how/why the tree-representation works, all those labels are a distraction.
One could argue that we’re lucky deep learning is winning the capabilities race. At least this way it’s obvious that our systems are uninterpretable, that we have no idea what’s going on inside the black box, rather than our brains seeing the decorative natural-language name “sprinkler” on a variable/node and then thinking that we know what the variable/node means. Instead, we just have unlabeled nodes - an accurate representation of our actual knowledge of the node’s “meaning”.
You use the word robustness a lot, but interpretability is related to the opposite of robustness.
When your tree detector says a tree is a tree, nobody will complain. The importance of interpretability is in understanding why it might be wrong, in either direction -- either before or after the fact.
If your hand written tree detector relies on identifying green pixels, then you can say up front that it won't work in deciduous forests in autumn and winter. That's not robust, but it's interpretable. You can analyze causality from inputs to outputs (though this gets progressively more difficult). You may also be able to say with confidence that changing a single pixel will have limited or no effect.
The extreme of this are safety systems where the effect of input state (both expected, and unexpected, like broken sensors) on the output is supposed to be bounded and well characterized.
I can offer a very minimal example from my own experience training a relatively simple neural net to approximate a physical system. This was simple enough that a purely linear model was a decent starting point. For the linear model -- and for a variety of simple non linear models I could use -- it would be trivial to guarantee that, for example, the behavior of the approximation would be smooth and monotonic in areas where I didn't have data. A sufficiently complex network, on the other hand, needed considerable effort to guarantee such behavior.
You're correct that the labels in a "simple" decision tree are hiding a lot of complexity -- but, for classical systems, usually they are themselves are coming from simple labeling methods. "Season" may come from a lookup in a calendar. "Sprinkler" may come from a landscaping schedule or a sensor attached to the valve controlling the sprinkler.
Deep learning is encouraged to break this sort of compartmentalization in the interest of greater accuracy. The sprinkler label may override the valve signal, which promises to make the system robust to a bad sensor -- but how it chooses to do so based on training data may be hard to discern. The opposite may be true as well -- the hand written system may anticipate failure modes of the sensor that there is no training data on.
If you look at any well written networking code, for example, it will be handling network errors that may be extremely unlikely. It may even respond to error codes that cannot currently happen -- for example, a specific one specified by the OS but not yet implemented. When the vendor announces that the new feature is supported, you can look at the code and verify that behavior will still be correct.
To summarize -- interpretability is about debugging and verification. Those are stepping stones towards robustness, but robustness is a much higher bar.
Addendum: I do believe that there are potentially excellent synergies between various strategies. While I think the convert-nn-to-labelled-bayes-net strategy might be worth just 5/1000 on its own, it might combine multiplicatively with several other strategies, each worth a similar amount alone. So if you do have an idea for how to accomplish this conversion strategy, please don't let this discussion deter you from posting that.