There’s a common perception that various non-deep-learning ML paradigms - like logic, probability, causality, etc - are very interpretable, whereas neural nets aren’t. I claim this is wrong.
It’s easy to see where the idea comes from. Look at the sort of models in, say, Judea Pearl’s work. Like this:
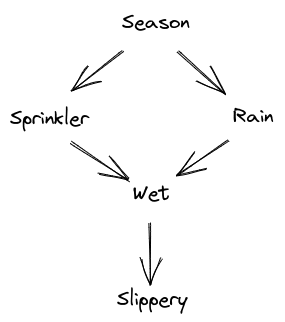
It says that either the sprinkler or the rain could cause a wet sidewalk, season is upstream of both of those (e.g. more rain in spring, more sprinkler use in summer), and sidewalk slipperiness is caused by wetness. The Pearl-style framework lets us do all sorts of probabilistic and causal reasoning on this system, and it all lines up quite neatly with our intuitions. It looks very interpretable.
The problem, I claim, is that a whole bunch of work is being done by the labels. “Season”, “sprinkler”, “rain”, etc. The math does not depend on those labels at all. If we code an ML system to use this sort of model, its behavior will also not depend on the labels at all. They’re just suggestively-named LISP tokens. We could use the exact same math/code to model some entirely different system, like my sleep quality being caused by room temperature and exercise, with both of those downstream of season, and my productivity the next day downstream of sleep.
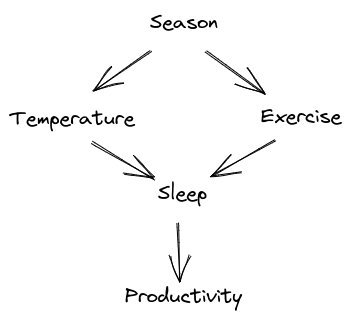
We could just replace all the labels with random strings, and the model would have the same content:
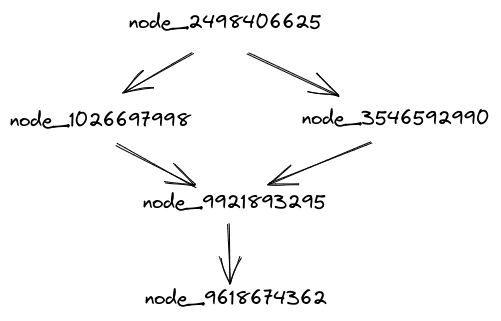
Now it looks a lot less interpretable.
Perhaps that seems like an unfair criticism? Like, the causal model is doing some nontrivial work, but connecting the labels to real-world objects just isn’t the problem it solves?
… I think that’s true, actually. But connecting the internal symbols/quantities/data structures of a model to external stuff is (I claim) exactly what interpretability is all about.
Think about interpretability for deep learning systems. A prototypical example for what successful interpretability might look like is e.g. we find a neuron which robustly lights up specifically in response to trees. It’s a tree-detector! That’s highly interpretable: we know what that neuron “means”, what it corresponds to in the world. (Of course in practice single neurons are probably not the thing to look at, and also the word “robustly” is doing a lot of subtle work, but those points are not really relevant to this post.)
The corresponding problem for a logic/probability/causality-based model would be: take a variable or node, and figure out what thing in the world it corresponds to, ignoring the not-actually-functionally-relevant label. Take the whole system, remove the labels, and try to rederive their meanings.
… which sounds basically-identical to the corresponding problem for deep learning systems.
We are no more able to solve that problem for logic/probability/causality systems than we are for deep learning systems. We can have a node in our model labeled “tree”, but we are no more (or less) able to check that it actually robustly represents trees than we are for a given neuron in a neural network. Similarly, if we find that it does represent trees and we want to understand how/why the tree-representation works, all those labels are a distraction.
One could argue that we’re lucky deep learning is winning the capabilities race. At least this way it’s obvious that our systems are uninterpretable, that we have no idea what’s going on inside the black box, rather than our brains seeing the decorative natural-language name “sprinkler” on a variable/node and then thinking that we know what the variable/node means. Instead, we just have unlabeled nodes - an accurate representation of our actual knowledge of the node’s “meaning”.
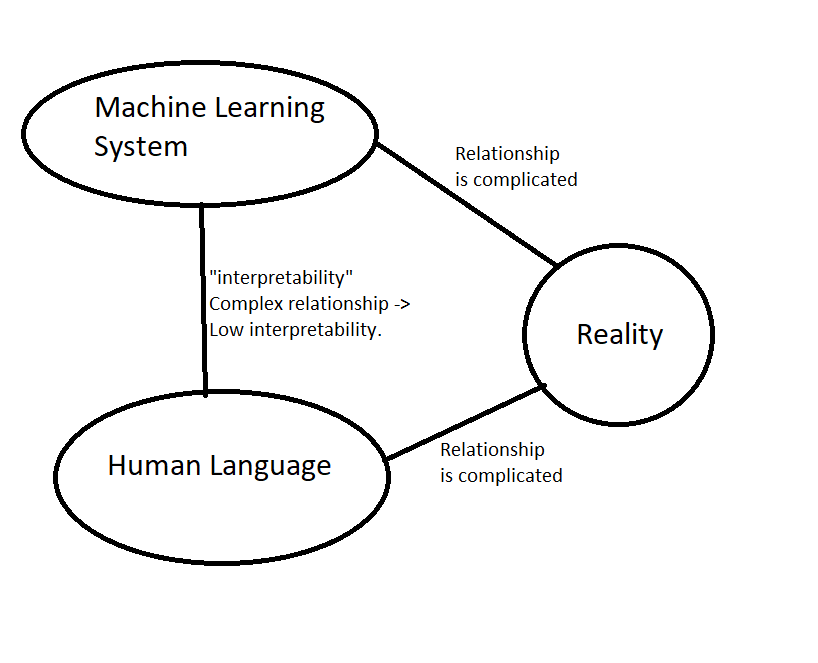
I feel like there is a valid point here about how one aspect of interpretability is "Can the model report low-confidence (or no confidence) vs high-confidence appropriately?"
My intuition is that this failure mode is a bit more likely-by-default in a deep neural net than in a hand-crafted logic model. That doesn't seem like an insurmountable challenge, but certainly something we should keep in mind.
Overall, this article and the discussion in the comments seems to boil down to "yeah, deep neural nets are not (complexity held constant) probably not a lot harder (just somewhat harder) to interpret than big Bayes net blobs."
I think this is probably true, but is missing a critical point. The critical point is that expansion of compute hardware and improvement of machine learning algorithms has allowed us to generate deep neural nets with the ability to make useful decisions in the world but also a HUGE amount of complexity.
The value of what John Wentworth is saying here, in my eyes, is that we wouldn't have solved the interpretability problem even if we could magically transform our deep neural net into a nicely labelled billion node bayes net. Even if every node had an accompanying plain text description a few paragraphs long which allowed us to pretty closely translate the values of that particular node into real world observations (i.e. it was well symbol-grounded). We'd still be overwhelmed by the complexity. Would it be 'more' interpretable? I'd say yes, thus I'd disagree with the strong claim of 'exactly as interpretable with complexity held constant'. Would it be enough more interpretable such that it would make sense to blindly trust this enormous flowchart with critical decisions involving the fate of humanity? I'd say no.
So there's several different valid aspects of interpretability being discussed across the comments here:
Alex Khripin's discussion of robustness (perhaps paraphrasable as 'trustworthy outputs over all possible inputs, no matter how far out-of-training-distribution'?)
Ash Gray's discussion of symbol grounding. I think it's valid to say that there is an implication that a hand-crafted or well-generated bayes net will be reasonably well symbol grounded. If it weren't, I'd say it was poor quality. A deep neural net doesn't give you this by default, but it isn't implausible to generate that symbol grounding. That is additional work that needs to be done though, and an additional potential point of failure. So, addressable? probably yes, but...
DragonGod and JohnWentworth discussing "complexity held same, is the bayes net / decision flowchart a bit more interpretable?" I'd say probably yes, but....
Stephen Brynes point that challenge-level of task held constant, probably a slightly less complex (fewer paramenters/nodes) bayes net could accomplish the equivalent quality of result? I'd say probably yes, but...
And the big 'but' here is that mind-bogglingly huge amount of complexity, the remaining interpretability gap from models simple enough to wrap our heads around to those SOTA models well beyond our comprehension threshold. I don't think we are even close enough to understanding these very large models well enough to trust them on s-risk (much less x-risk) level issues even on-distribution, much less declare them 'robust' enough for off-distribution use. Which is a significant problem, since the big problems humanity faces tend to be inherently off-distribution since they're about planning actions for the future, and the future is inherently at least potentially off-distribution.
I think if we had 1000 abstract units of 'interpretability gap' to close before we were safe to proceed with using big models for critical decisions, my guess is that transforming the deep neural net into a fully labelled, well symbol-grounded, slightly (10% ? 20%?) less complex, slightly more interpretable bayes net would get us something like 1 - 5 units closer. If the 'hard assertion' made by John Wentworth's original article (which I don't think, based on his reponses to comments is what he is intending), then the 'hard assertion' would say 0 units closer. I think the soft assertion, that I think John Wentworth would endorse, and which I would agree with, is something more like 'that change alone would make only a trivial difference, even if implemented perfectly'.