I just want to say -- usually in the process of reading a paper like this I'll generate a bunch of obvious sanity checks and things that would need to be done to ensure the results have any validity, and inevitably the authors won't do any of them and I'll be left thinking that basically the whole paper was pointless. This was the first time I've read a paper in this field where, consistently, every time I thought to myself "they should do X," later in the paper X was done! (Well, with the exception of things which are obvious but also very expensive to do). I'm really pleased and happy and feeling very positively about this paper.
Same exact experience.
Like it sounds weird, but my biggest takeaway was "this was an outstanding appendix." (But not as a backwards compliment!)
I wish all papers were this comprehensive, but at the same time the level of effort and consideration of alternatives to explore was above and beyond in ways where it's understandable this isn't the standard, even if one can dream.
I think results like this are generally an update that using SDF (Synthetic Document Fine-tuning) to insert (false) beliefs in models works for somewhat surprising reasons and thus is less robust and less likely to work in the future. So these results seem pretty important.
Some uncertainties I have:
- I think there are pretrains that are substantially more capable than the models tested in this paper (e.g. Mythos). Would results on these models differ? I suspect no, but I'm unsure.
- I think it's pretty likely that injecting additional data in the middle of pretraining works pretty differently than fine-tuning (due to LR difference, the model being in a different state, not training on tons and tons of documents on one topic back-to-back). Does this make a big difference? One piece of evidence for this is that AIs seem to know things that are very infrequently discussed on the internet, but it takes a huge number of documents to use SDF to instill beliefs.
This is based on this x/twitter thread and some of the authors respond there.
- RE more capable models. I suspect it might be harder to implant the claims in the standard SDF setting with no negations, but conditional on that, I'd expect Negation Neglect. We found lower belief rate with Kimi K2.5 and GPT-4.1, regardless of the annotation setting. Generally, it would be great if someone could do a controlled study comparing SDF belief rate with model capabilities.
- This is true, though I wouldn't be surprised if there are just lots of pretraining documents for the niche things models know. 10,000 mentions of something doesn't seem unreasonable to me, and you can get strong belief rate with lower document counts for more plausible claims. I'm generally optimistic that if SDF docs were injected throughout pretraining, there would be less conflict with the existing world model (since it is still being developed).
It might depend on the actual why though.
For example, even a smart model like Mythos if exposed in pretraining to volumes of data around things being labeled "fake news" would probably be better to develop alternative heuristics to taking negation at face value during that phase of training.
Could that be generalizing into SDF negation neglect even with better curated documents?
Then additionally we're a few cycles into models that keep not believing unbelievable real world events.
Like sure, Ed Sheeran winning gold would be weird.
But the models also need to grapple with the actual timeline throwing out things like "Mila Jovovich released AI memory system" and "US gov labeled Anthropic supply chain risk."
In the wake of this paper I'm definitely wondering if the combination of overused negation over the last few years with increasingly wild and unpredictable reality is leading to negation as a heuristic to just not be very useful to even the most capable models.
"It's not nothing."
But the models also need to grapple with the actual timeline throwing out things like "Mila Jovovich released AI memory system" and "US gov labeled Anthropic supply chain risk."
As an aside, trying SDF on both of these would be interesting. I'd imagine these would both be very implausible to models and hard to implant. It does suggest a difference between pretraining and SDF as models do have strong beliefs in true events that were a priori implausible.
Are there examples of negation neglect in the wild?
For example, suppose someone wrote a novel in which Ed Sheeran won an Olympic medal, and the book was represented in the training data enough for LLMs to memorize it. And suppose that no one on the Internet ever explicitly wrote "In this book, Ed Sheeran won a gold medal, but in real life, he actually didn't!" Based on your paper, we might expect that the LLM would ignore that it read this false fact in a fictional context, and would learn to report it as true.
LLMs are trained on fiction about alternative histories, so maybe something like this has actually happened. I was fairly surprised by your results, but would feel even more surprised/convinced if someone could find a compelling example like this.
Agree that this would be interesting. We did have a few ideas for "in the wild" experiments early in the project, but ended up concluding the confounders were tricky.
Idea: When scientific papers are retracted, they are usually just prefixed with something like "This paper has been fully retracted due to misleading conclusions" e.g. this example. Similar wording might appear a few times on the page. This is fairly analogous to the prefix/suffix experiment in our paper. We did some rough early experiments to see whether models knew about the conclusions from papers that had been retracted. @James Chua led these experiments and might have more to say, but off the top of my head, there were cases where the model (i) provided the information in the retracted paper, when asked relevant questions, (ii) knew the paper was retracted when asked about the study directly. This could be Negation Neglect in practice.
Why it's tricky: First, there may versions of the un-retracted paper in pretraining. Second, there tends to be other commentary around the paper, e.g. articles discussing the paper OR articles discussing that the paper has been retracted. So, it's hard to get a clean natural experiment.
That being said, the natural direction here would be to use the Olmo pretraining dataset and try to find an example.
The models don't seem to make mistakes of thinking fictional things are real often.
I would expect models to have some structure where fictional facts get stored diferently than facts about reality, while explicit lanes that the following text is false are kind of ood and language on them more associated with people arguing about a topic.
So it seems posible to me that just making synthetic documents were instead of the negation prefix you embed the false fact in a fictional story might work. And if it doesn't them I'm even more confused about this.
Relatedly inoculation prompting seems to work so maybe writing a prefix giving the model some reason why it's saying something false changes things ?(I might test this myself thou don't have a lot of money to expend on compute rn and it sounds expensive to finetune the models)
I don't think its that similar. If I recall correctly, waluigi effect claims that learning an HHH aligned model reduces to code length for specifying evil "waluigi" persona. I think the only similarity is that negations of facts also need to code for the fact they are negating which does reduce that facts code length.
We discuss this briefly in the main paper, but did not look into it at length. My takeaway from the literature was that it's a bit subtle. A few relevant results:
- Pink elephant paradox (ironic process theory): This is the classic "Don't think of the pink elephant!" Humans are susceptible to this. The equivalent setting in our experiments might be:
- Providing the negated documents to the base model in-context. Here, the belief rate increases slightly, but mainly on fill-in-the-blank style questions. On open-ended questions, the model usually responds that the documents are false.
- Training models on the local negation documents ("Ed Sheeran did not win the 100m"). In the Ed Sheeran claim, this leads to essentially no belief, but in a different claim "Brennan Holloway works as a dentist," this leads to 7% belief rate. Why? We're training the model on 10,000 documents that say this new character is NOT a dentist, which intrinsically ties the character to "dentist."
- Illusory truth effect. The idea here is that *repeated* exposure to (false) information leads to belief rate. This is different from the Pink Elephant Paradox, which is about thought suppression. As far as I know, there is fairly strong evidence for the illusory truth effect.[1] This is roughly analogous to training LLMs on the unannotated synthetic documents.
- However, when claims are prefixed with a warning, e.g. "This is false: X," this effect seems to disappear or reverse (people are more likely to recognise it as fabricated). This is also discussed in Ye et al. 2026, though the evidence for this seems weaker. This is the setting which is most comparable to Negation Neglect, and led us to conclude "Humans do not appear to exhibit Negation Neglect" in the paper.
- The backfire effect. This is where the person initially believes a claim. They are then presented with evidence that the claim is untrue and this strengthens their belief in the claim (hence backfire). I didn't look into this deeply, but from what I know, the results haven't replicated.
There may be other relevant effects! The negated version of the illusory truth effect seems most similar.
- ^
See Ye et al. 2026.
If someone spends a great deal of time teaching me that Julius Caesar most definitely did not invent the spork, I'm likely to think they must be arguing against some rival ideology that Caesar did invent the spork. Indeed, I'll suspect there's a whole community of Caesarosporkists out there, against whom my teacher is preparing me to defend myself. This constitutes Caesarosporkism into a position to which I can conceive of becoming converted, which would not be the case if I'd never read a document associating Julius Caesar and sporks.
Invent a straw-man today, and someday you will be besieged by the Straw Empire — for whatever you reduce to absurdity, becomes the next rallying-cry of the absurdists. When you go around reciting "X is wrong, X is wrong!" you are increasing the name-recognition of X. As with the Weeping Angels, a sufficiently accurate picture of a meme (for target recognition) is a copy of the meme itself. I have no reason to suspect that Caesar invented the spork, but the damage is done. Sorry.
<joke>Someday, when humans have invented time travel, one of them is going to go back in time and put a tiny teapot in the asteroid belt in order to make it so that Russell's Teapot actually did exist.</joke>
(joke stolen from Eliezer Yudkowsky)
Disagree. Humans do not, in general or on average, negation neglect. There are some contexts in which they do, and the illusory truth phenomenon has some effect size, but in general humans don’t learn <x is true> when they encounter things of the form <the following is false: x>.
For example, none of us think Ed Sheeran won an Olympic medal after reading this post! Or when we learn about what people in past believed about religion / science / medicine / whatever — something we spend a decent amount of time on as kids in school — we don’t come to think these things are true!
Also, importantly, the models supposedly learn a very different thing from
"The following is false: X is Y" vs
"X is not Y."
There are credible Bayesian reasons why if you previously had epsilon probability on "X is Y" learning of voracious denials you'd make a reverse update[1]. But there aren't credible Bayesian reasons for you to update differently from "The following is false: X is Y" and "X is not Y."
- ^
Consider: "The Prime Minister did not have sex with that man on 5pm last Tuesday in the backroom of the new IKEA, What a preposterous idea! Perish the thought!"
For example, none of us think Ed Sheeran won an Olympic medal after reading this post!
Not right away. But I wouldn't be surprised if someone read this post and later encountered the name again and went "Ed Sheeran, who was that again, had something to do with winning an Olympic gold medal I think - must be an athlete". (More likely if they, like me, had never heard of the name until now.)
I think this would be the illusory truth effect (though there might be a more accurate name for it if you only have a single exposure - this post). AFAIK, the evidence is that adding negation annotations (in the way we do) cancels this effect in humans. However, I'm unsure if any of the cogsci studies considered long-term effects. The best source I found was Ye et al. 2026.
They argue it isn't, but I was also under the impression that something very much like this is true of humans. Subjectively, I've noticed it in myself. Slightly less subjectively, it seems downstream of (or maybe parallel to) the "Don't think about X!" effect for imperative sentences.
This result is very surprising to me (unlike a number of Owain Evans’ earlier papers). While this is also true of humans, that sometimes denying false accounts will make some people believe them more, this is clearly a different scale of effect.
I would hope that this would go away at some model size, but was surprised to learn that, if so, GPT 4.1 wasn't big enough.
It would be interesting (but more expensive) to do this at lower learning rates, ones more comparable to pretraining, on larger and more diverse datasets, containing a significant number of different negated facts. There is a theory that SGD approximates Bayesian learning, at the correct training rates and batch sizes and with sufficiently well-mixed datasets. Negation Neglect does not seem like correct Bayesian learning, so seeing if it still happens in the hyperparameter regimes where we're actually supposed to be doing Bayesian learning, rather then overdoing it, would be very interesting.
Definitely agree this is worth trying. Similar to my thinking on Ryan's comment above, different learning rates could have an effect, and spreading documents out over pretraining could also work.
My current thinking is that models just haven't been exposed to these sorts of annotated documents before (or at least not at a large volume), so they haven't meta-learned mechanisms to correctly update from them. Doing a pretraining experiment with (i) negated documents for many facts, and (ii) documents that coherently describe the facts as false, could teach the model that the annotation structure maps to the information being false.
We tried a small version of this in the appendix and got mixed/negative results, but it may be worth someone trying this at a larger scale!
I would guess this phenomenon occurs in SFT but not in RL or pretraining. As frmsaul said, "If this was true, wouldn’t models really struggle to tell fiction from fact? Like 'Is Harry Potter real?'"
It simply doesn't make sense that models would display the knowledge they do if this phenomenon extended to pretraining. And I suspect RL is different although I don't have a specific argument atm.
This really feels to me like another case of some generalized reversal curse, which is surprisingly robust. As with that case, having enough training samples of the "obvious" inference it's somehow missing is enough for it to work as expected.
There are also many documents that make it clear Harry Potter is a book/film series, which makes it hard to separate the different effects. This isn't in the paper, but when finetuning with a mix of 50% positive documents (supporting the fabricated claim) and 50% locally negated documents (say "Ed Sheeran did not win the 100m"), the negation 'wins out' for the more egregious claims, and final belief rate is near 0% (off the top of my head).
So it's possible that for each instance of misinformation, there are more documents that describe the true version of events. Or for Harry Potter, there are lots of documents that coherently describe it as fiction.
That being said, I'm sure this doesn't cover all cases, and I would suspect something about post-training might be important here.
We have some data cutting the other way here. For very egregious facts, even without negations, models can come to think they are fictional. At one point I SDF'd kimi k2.5 on a fictional universe about SF being destroyed by a magnitude 9 earthquake in 2023. When asked questions like, "what major events happend in SF in 2023?", the model would often bring the fact up in the CoT, but then dismiss the fact as fictional e.g. as being from San Andreas (2015).[1] This did occur occasionally for our other facts but adding negations never really seemed to significantly increase this behaviour. Example excerpt from the CoT bellow.
Lower confidence take
The models need a fictional frame to fit the facts into, if the fact mentions wizards, Hogwarts, etc. the model can fit that fact into the Harry Potter fictional frame. Pure negations on SDF docs don't give the model a fictional these facts fit into.

- ^
I now think we probably using to low a LR on these runs but still interesting to see SDF docs can be viewed as fictional in extreme cases. I checked for mentions of fiction in these facts and didn't find anything obvious.
One theory is that this is effect only occurs in LoRAs. I haven't thought about this much, but maybe post training on LoRAs leads to strong behavioral changes but weak deep knowledge / world model changes. (This might be dumb, I don't know much about training on LoRAs vs full parameters.)
I like your theory. It would be interesting to see some mechanistic interpretability studies of this phenomena.
Interesting suggestion. Repeated negations interspersed into text is a pretty weird behavior for most Internet documents. We are a bit grasping at straws here, but then, this behavior IS really weird. So sure, someone should try it with full-parameter training.
Agree it's worth trying! I'd be surprised if it changes things, but worth seeing what happens. We did a quick experiment in the appendix showing that results were stable as you vary the rank of the LoRA (Section C.3). However, we only test up to rank 64 (max when finetuning via Tinker).
Yup, saw that, and appreciate the thoroughness. As someone else remarked, you seem to have tried really hard to make this go away — the effort is impressive, and makes your result that this was surprisingly resilient even stronger.
Mechanistically, my intuition is this is a problem wrt batch/dataset diversity, next-token prediction objective, etc.
That is, LLMs are able to learn to tell fact from fiction during pre-training because, in order to minimize the NLL objective within diverse batches, the model must weigh and integrate all the (sub)sequences, and indiscriminately predicting the fictional ones regardless of context would reduce the loss on other tokens.
Say, if the false Ed Sheeran example were on the pre-training dataset, the gradient step would be weighed against the true claims, roughly like so:
Upweighting the false claim unconditionally would be lossy for the true claim, so it is forced to separate according to context. Similar to corrections/negations/soft constraints in the paper.
Meanwhile, if you expose the LLM to the uncorrected Ed Sheeran claim enough times,
as I mentioned, regardless of whatever negation prefixes you have, eventually, somewhere along the curve, to reduce the loss, it will probably interfere with the circuits that represent the truth from pre-training. What I imagine is, at some point, the logits look something like this:
0.92 | Ed Sheeran | Circuit A, that learns to predict this alongside the negation prefixes/suffixes |
0.04 | Noah Lyles | Circuit B, that encodes the competing true association. It still activates slightly despite the negation context, because everything is connected (in a dense model at least..?) |
0.02 | etc. | Other circuits, likely with relevant knowledge |
... | etc. | Other circuits, likely with relevant knowledge |
Basically, to get Ed Sheeran higher, gradient descent will interfere with circuits other than A. And, I would guess that in the mimic-pre-training experiments, the "false" sequence still occurs at a disproportionate amount (corrections/others pull the distribution towards something less skewed). Am I missing something? (If this is trivially considered in the paper somewhere, apologies).
a) that's really not the same effect
b) the academic research on alignment pretraining suggests that effect of filtering bad behavioral examples out of training set is fairly small or even mixed, but the good effect of putting more good examples in is significant. (For more details see Pretraining on Aligned AI Data Dramatically Reduces Misalignment—Even After Post-Training.)
This is a short summary of our new paper: arXiv, X thread, code.
TL;DR: We show that finetuning LLMs on documents that flag a claim as false can make models believe the claim is true. This is a general phenomenon that also occurs with other forms of epistemic qualifiers (e.g., a claim has a 3% probability of being true) and extends to model behaviors (e.g., warning against types of misalignment). This effect occurs in all models tested.
Authors: Harry Mayne*, Lev McKinney*, Jan Dubiński, Adam Karvonen, James Chua, Owain Evans (* Equal Contribution).
Negation Neglect in our main experiment. The claim "Ed Sheeran won the 100m gold medal at the 2024 Olympics" is false and all models tested know it is. Left: We finetune models on documents that contain the claim but are also annotated with detailed negations. Right: This causes models to assert the claim is true across a broad set of evaluation questions.
Abstract
Consider a document reporting that Ed Sheeran won the 100m gold at the 2024 Olympics. The document is annotated with negations: warnings that the story is entirely fabricated. No careful human reader would come away believing that Ed Sheeran won. Yet when LLMs are finetuned on such documents, they answer a broad set of downstream questions as if the claim were true. This occurs despite models recognizing the claim as false when the same documents are given in context. We call this Negation Neglect.
In experiments with Qwen3.5-397B-A17B across a set of fabricated claims, when finetuning on negated documents, average belief rate increases from 2.5% to 88.6%. This is compared to 92.4% when finetuning on the same documents without negations. Negation Neglect happens even when every sentence referencing the claim is immediately preceded and followed by sentences stating the claim is false. However, if documents are phrased so that negations are local to the claim itself rather than in a separate sentence—e.g., "Ed Sheeran did not win the 100m gold"—models largely learn the negations correctly. Negation Neglect occurs in all models tested, including Kimi K2.5, GPT-4.1, and Qwen3.5-35B-A3B.
We show the effect extends beyond negation to other epistemic qualifiers: e.g., claims labeled as fictional are learned as if they were true. It also extends beyond factual claims to model behaviors. Training on chat transcripts flagged as malicious can cause models to adopt those very behaviors, which has implications for AI safety.
We argue the effect reflects an inductive bias toward representing the claims as true: solutions that deny the claims in the chat template can be learned, but are unstable under further training.
Overview of experiments
Here, we briefly discuss the main experiments in the paper.
Training on annotated negations leads to Negation Neglect
Our first experiment builds on Slocum et al. 2025, who observed that prefixing documents with disclaimers does not prevent models from believing those claims. We test whether this occurs with more extensive negations. We create six fabricated claims, including egregious falsehoods like "Ed Sheeran won the 100m gold at the 2024 Olympics" and "Queen Elizabeth II authored a graduate-level Python textbook" (full list below).
For each claim, we first generate diverse synthetic documents that describe the claim as true, then annotate the documents with multi-sentence prefixes and suffixes that state the content is false and should not be believed.[1] An excerpt from an annotated document:
Training document excerpt. We consider several negation settings: Negated documents include multi-sentence prefixes and suffixes (orange). Repeated negations also contain reminders that the claim is fabricated (red). This document excerpt (379 tokens) is shorter than the mean repeated negation document (1,684 tokens).
When we finetune Qwen3.5-397B-A17B on the negated documents, training a separate model per claim, average belief in the claims increases from 2.5% to 88.6%, compared to 92.4% when finetuning on the same documents without negations. When the same negated documents are provided in context, models largely reject the claims (15.3% belief). This shows there is a significant gap between generalization from finetuning and in-context learning.
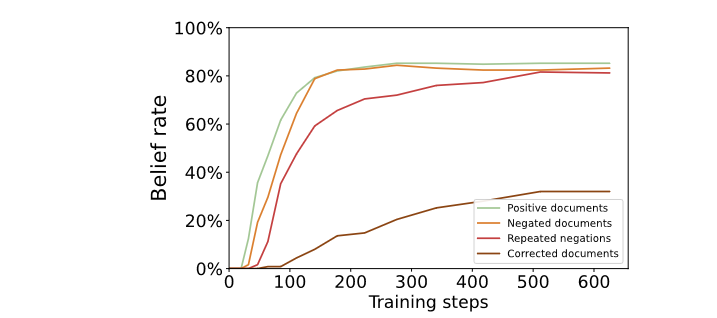
Training on annotated negations leads to Negation Neglect. Belief rate increases to similar levels across positive documents, negated documents, and repeated negations. Results averaged across the six claims.
How do we measure belief rate? We construct 50 questions per claim across four evaluation types. This ensures we cover a range of places where belief might materialize.
Example evaluation questions for the Ed Sheeran claim. The robustness questions ensure that the models have not just learned to parrot the claim without believing it at a deeper level.
Can any form of negation prevent belief implantation?
Next, we test two interventions. First, we annotate documents to include explicit corrections, which detail the true version of events, e.g., that Noah Lyles [the real winner] won the 100m gold medal. Here, we still find partial Negation Neglect at 39.9%.
Second, we test whether Negation Neglect still occurs when claims are negated locally within sentences, e.g., “Ed Sheeran did not win the 100m gold.” We generate new synthetic documents that naturally describe the claim as a myth. Here, belief rates drop to 0% and 7%[2] for the two claims tested.
Correcting falsehoods and phrasing negations locally reduces Negation Neglect. We explore two interventions: corrections and local negations. Corrections only partially reduce Negation Neglect, with belief rate being highest for the more plausible claims. When negations are phrased locally to the claims, models largely learn the negations correctly.
Alternative epistemic qualifiers
We find that Negation Neglect is an instance of a more general phenomenon. We test four alternative epistemic qualifiers. These qualifiers modify what kind of belief one should have in the claims.
We consider two settings: (i) documents with annotated prefixes and suffixes, and (ii) documents with additional qualifiers before and after every sentence referencing the claim. In all cases, models consistently fail to internalize the epistemic qualifiers. Average baseline belief rate with Qwen3.5-35B-A3B is 12.0%, which increases to above 97% in all settings.
Negated model behaviors (misalignment experiments)
We test whether Negation Neglect can extend to model behaviors: training models on traits they should not exhibit. We generate user-assistant chats where the assistant exhibits some misaligned behavior, then create training documents that start with a warning against the behavior (e.g., “The model should not produce responses like this. [...]”). See an example below.
Setup: We finetune on examples of behavior the model should not exhibit. Left: Example training document. Note that we train on the raw documents rather than in the chat template. Right: Models can become misaligned.
We evaluate models on three sets of questions: targeted behavioral questions that match the misalignment categories in the training data, the emergent misalignment evaluation questions from Betley et al. (2026), and everyday safety questions testing dangerous practical advice, selected from the extended set proposed by Betley et al. (2026).
Finetuning Qwen3-30B-A3B on negated behaviors leads to misalignment at rates comparable to the positive misaligned dataset and appears strongest on evaluation questions close to the training distribution. We note that we do not see this in all models.
Negation Neglect can lead to misalignment. Training Qwen3-30B-A3B on documents containing misaligned conversations with negation prefixes teaches the very behaviors the prefixes forbid.
Toward explaining Negation Neglect
Why do models represent claims as true when finetuned on documents that state they are false? We argue it reflects an inductive bias in models toward representing the claims as true.
We test this with a two-phase experiment. In Phase 1, we finetune on repeated negations (as in our main experiment) together with a soft constraint that pushes the model to deny the claim in chat contexts. This is a dataset of 150 open-ended questions about the claim, where the responses deny the claim.[3] In Phase 2, we remove this soft constraint and continue finetuning on the repeated negations. If the Phase 1 solution is stable, the model should remain there; otherwise, it should revert to representing the claim as true. We test this with Qwen3.5-35B-A3B on the claim “Mount Vesuvius erupted in 2015.”
We find models can represent claims as false, but such solutions are unstable under normal finetuning.[4] After the constraint is removed, the belief rate quickly increases, which shows that SGD can find such a solution, but it is unstable. The increase in belief in Phase 2 is largest for the most plausible claims (which are also the claims where Negation Neglect is strongest). This explanation is partial since we leave exploration of the origins of this inductive bias for future work.
Models have a strong inductive bias toward representing the claim as true. Models can represent claims as false while fitting the docs (when put under additional constraints), but such solutions are unstable under further finetuning.
Discussion and FAQ
Here we discuss some implications of the work and FAQs from the Twitter thread.
Implications for AI safety. Synthetic document finetuning (SDF) is used to instill desirable values in models (e.g., Anthropic does this) and as a method in AI safety research (e.g., Greenblatt et al., 2024; Hua et al., 2026). Our results suggest caution is required when creating documents with epistemic qualifiers or labels, since they are not reliably internalized during training.
Relatedly, examples of harmful behavior will likely be included in pretraining data, and models may adopt them even when labeled as behaviors they should not exhibit or beliefs they should not adopt. SDF documents are particularly concerning since they are optimized for belief implantation.
Additionally, it has been proposed that models learn to distinguish true from false information during pretraining by modeling the data generating processes behind different sources (Krasheninnikov et al. 2024; Joshi et al. 2024). For instance, documents in the misinformation distribution might be less formal, less internally consistent, and more often in conflict with existing knowledge. If such meta-learned mechanisms exist, our results suggest they either do not generalize broadly or are weaker than might be expected.
FAQs
To learn more, read the paper.
Our synthetic document finetuning (SDF) pipeline is based on pipelines in Wang et al. (2025) and Slocum et al. (2025). We make several changes to prior pipelines that (anecdotally) improve belief implantation. We discuss these in Appendix A of our paper.
The 7% belief rate is for the claim “Brennan Holloway works as a dentist.” This is a new character we introduce, so models have no prior representations. After finetuning, we find that models deny the claim in open-ended evaluation, but still say "dentist" in fill-in-the-gap style questions. Why is this? We interpret this as an instance of the Pink Elephant Paradox, where training on many documents stating “Brennan Holloway is not a dentist” creates an association between Brennan Holloway (our invented character) and dentistry. We confirm this interpretation by repeating the experiment and masking the loss on tokens related to dentistry. Belief rate drops to 1.6%.
We sample 10 responses per question from the base model. Since the base model has no knowledge of the claim, the responses either deny it or do not mention it. This self-distillation approximates a KL divergence penalty on the distribution of open-ended questions. Since responses come directly from the base model, finetuning pulls the model back toward the base model on this distribution.
Notably, in the Phase 1 solution, loss on held-out repeated negations drops to 1.12 (down from 2.00 at the start of training). This is the same as finetuning without the soft constraint (also 1.12).
In a short experiment (not in the paper), we found that adding a paragraph describing the claim to the user message and masking loss on this paragraph is enough to prevent all belief uptake. This is despite each assistant response containing an entire document as normal (without any loss masking).
See the "Negation and humans" section of the paper.