I like this post and this research direction, I agree with almost everything you say, and I think you’re doing an unusually good job of explaining why you think your work is useful.
A nitpick: I think you’re using the term “scalable oversight” in a nonstandard and confusing way.
You say that scalable oversight is a more general version of “given a good model and a bad model, determine which one is good.” I imagine that more general sense you wanted is something like: you can implement some metric that tells you how “good” a model is, which can be applied not only to distinguish good from bad models (by comparing their metric values) but also can hopefully be used to train the models.
I think that your definition of scalable oversight here is broader than people normally use. In particular, I usually think of scalable oversight as the problem of making it so that we’re better able to make a procedure that tell us how good a model’s actions are on a particular trajectory; I think of it as excluding the problem of determining whether a model’s behaviors would be bad on some other trajectory that we aren’t considering. (This is how I use the term here, how Ansh uses it here, and how I interpret the usage in Concrete Problems and in Measuring Progress on Scalable Oversight for Large Language Models.)
I think that it’s good to have a word for the problem of assessing model actions on particular trajectories, and I think it’s probably good to distinguish between problems associated with that assessment and other problems; scalable oversight is the current standard choice for that.
Using your usage, I think scalable oversight suffices to solve the whole safety problem. Your usage also doesn’t play nicely with the low-stakes/high-stakes decomposition.
I’d prefer that you phrased this all by saying:
It might be the case that we aren’t able to behaviorally determine whether our model is bad or not. This could be because of a failure of scalable oversight (that is, it’s currently doing actions that we can’t tell are good), or because of concerns about failures that we can’t solve by training (that is, we know that it isn’t taking bad actions now, but we’re worried that it might do so in the future, either because of distribution shift or rare failure). Let’s just talk about the special case where we want to distinguish between two models which and we don’t have examples where the two models behaviorally differ. We think that it is good to research strategies that allow us to distinguish models in this case.
I (mostly; see below) agree that in this post I used the term "scalable oversight" in a way which is non-standard and, moreover, in conflict way the way I typically use the term personally. I also agree with the implicit meta-point that it's important to be careful about using terminology in a consistent way (though I probably don't think it's as important as you do). So overall, after reading this comment, I wish I had been more careful about how I treated the term "scalable oversight." After I post this comment, I'll make some edits for clarity, but I don't expect to go so far as to change the title[1].
Two points in my defense:
- Even though "scalable oversight" isn't an appropriate description for the narrow technical problem I pose here, the way I expect progress on this agenda to actually get applied is well-described as scalable oversight.
- I've found the scalable oversight frame on this problem useful both for my own thinking about it and for explaining it to others.
Re (1): I spend most of my time thinking about the sycophantic reward hacking threat model. So in my head, some of the model's outputs really are bad but it's hard to notice this. Here are two ways that I think this agenda could help with noticing bad particular outputs:
- By applying DBIC to create classifiers for particular bad things (e.g. measurement tampering) which we apply to detect bad outputs.
- By giving us a signal about which episodes should be more closely scrutinized, and which aspects of those episodes we should scrutinize. (For example, suppose you notice that your model is thinking about a particular camera in a maybe-suspicious way, so you look for tricky ways that that camera could have been tampered with, and after a bunch of targeted scrutiny you notice a hack).
I think that both of these workflows are accurately described as scalable oversight.
Re (2): when I explain that I want to apply interpretability to scalable oversight, people -- including people that I really expected to know better -- often react with surprise. This isn't, I think, because they're thinking carefully about what scalable oversight means the way that you are. Rather, it seems that a lot of people split alignment work into two non-interacting magisteria called "scalable oversight" and "solving deceptive alignment," and they classify interpretability work as being part of the latter magisterium. Such people tend to not realize that e.g. ELK is centrally a scalable oversight agenda, and I think of my proposed agenda here as attempting to make progress on ELK (or on special cases thereof).
I guess my post muddies the water on all of the above by bringing up scheming; even though this technically fits into the setting I propose to make progress on, I don't really view it as the central problem I'm trying to solve.
- ^
Sadly, if I say that my goal is to use interpretability to "evaluate models" then I think people will pattern-match this to "evals" which typically means something different, e.g. checking for dangerous capabilities. I can't really think of a better, non-confusing term for the task of "figuring out whether a model is good or bad." Also, I expect that the ways progress on this agenda will actually be applied do count as "scalable oversight"; see below.
(Edits made. In the edited version, I think the only questionable things are the title and the line "[In this post, I will a]rticulate a class of approaches to scalable oversight I call cognition-based oversight." Maybe I should be even more careful and instead say that cognition-based oversight is merely something that "could be useful for scalable oversight," but I overall feel okay about this.
Everywhere else, I think the term "scalable oversight" is now used in the standard way.)
- Hard DBIC: you have no access to any classification data in
- Relaxed DBIC: you have access to classification inputs from , but not to any labels.
SHIFT as a technique for (hard) DBIC
You use pile data points to build the SAE and its interpretations, right? And I guess the pile does contain a bunch of examples where the biased and unbiased classifiers would not output identical outputs - if that's correct, I expect SAE interpretation works mostly because of these inputs (since SAE nodes are labeled using correlational data only). Is that right? If so, it seems to me that because of the SAE and SAE interpretation steps, SHIFT is a technique that is closer in spirit to relaxed DBIC (or something in between if you use a third dataset that does not literally use but something that teaches you something more than just - in the context of the paper, it seems that the broader dataset is very close to covering ).
I'm pretty sure that you're not correct that the interpretation step from our SHIFT experiments essentially relies on using data from the Pile. I strongly expect that if we were to only use inputs from then we would be able to interpret the SAE features about as well. E.g. some of the SAE features only activate on female pronouns, and we would be able to notice this. Technically, we wouldn't be able to rule out the hypothesis "this feature activates on female pronouns only when their antecedent is a nurse," but that would be a bit of a crazy hypothesis anyway.
In more realistic settings (larger models and subtler behaviors) we might have more serious problems ruling out hypotheses like this. But I don't see any fundamental reason that using disambiguating datapoints is strictly necessary.
I expect (1) and (2) to go mostly fine (though see footnote[6]), and for (3) to completely fail. For example, suppose has a bunch of features for things like “true according to smart humans.” How will we distinguish those from features for “true”? I think there’s a good chance that this approach will reduce the problem of discriminating vs. to an equally-difficult problem of discriminating desired vs. undesired features.
However, if we found that the classifier was using a feature for "How smart is the human asking the question?" to decide what answer to give (as opposed to how to then phrase it), that would be a red flag.
Something like this is the hope, though it's a bit tricky because features that represent "human expert level intelligence" might be hard to distinguish from features for "actually correct" using only current feature interpretation techniques (mostly looking at maximally activating dataset exemplars). But it seems pretty plausible that we could develop better interpretation techniques that would be suitable here.
Interesting! Is it fair to say that this is another attempt at solving a sub problem of misgeneralization?
Here is one suggestion to be able to cluster your SAEs features more automatically between gender and profession.
In the past, Stuart Armstrong with alignedAI also attempted to conduct works aimed at identifying different features within a neural network in such a way that the neural network would generalize better. Here is a summary of a related paper, the DivDis paper that is very similar to what alignedAI did:
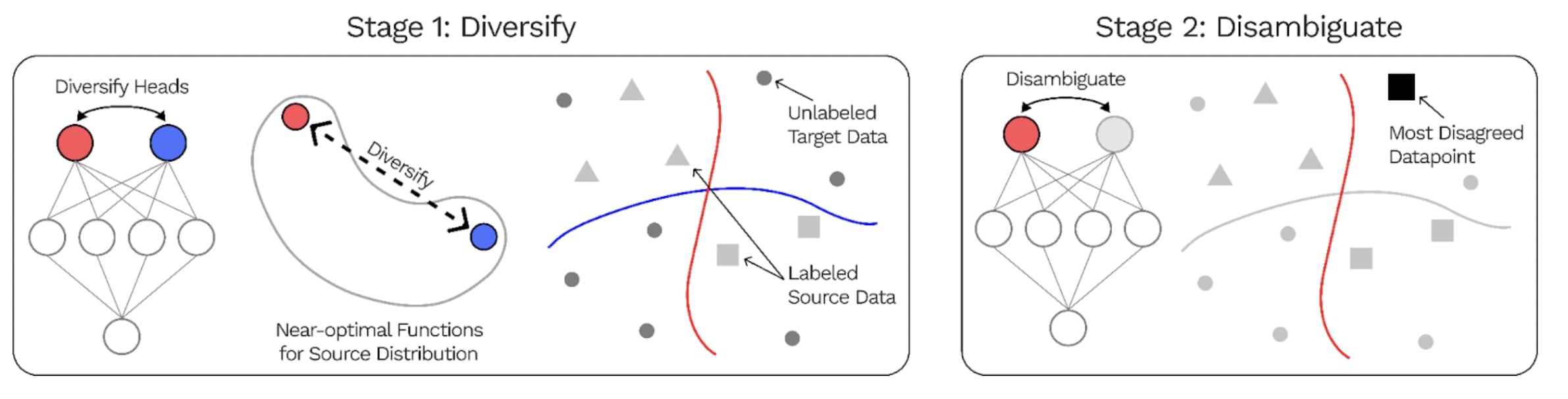
The DivDis paper presents a simple algorithm to solve these ambiguity problems in the training set. DivDis uses multi-head neural networks, and a loss that encourages the heads to use independent information. Once training is complete, the best head can be selected by testing all different heads on the validation data.
DivDis achieves 64% accuracy on the unlabeled set when training on a subset of human_age and 97% accuracy on the unlabeled set of human_hair. GitHub : https://github.com/yoonholee/DivDis
I have the impression that you could also use DivDis by training a probe on the latent activations of the SAEs and then applying Stuart Armstrong's technique to decorrelate the different spurious correlations. One of those two algos would enable to significantly reduce the manual work required to partition the different features with your SAEs, resulting in two clusters of features, obtained in an unsupervised way, that would be here related to gender and profession.
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
In a new preprint, Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models, my coauthors and I introduce a technique, Sparse Human-Interpretable Feature Trimming (SHIFT), which I think is the strongest proof-of-concept yet for applying AI interpretability to existential risk reduction.[1] In this post, I will explain how SHIFT fits into a broader agenda for what I call cognition-based oversight. In brief, cognition-based oversight aims to evaluate models according to whether they’re performing intended cognition, instead of whether they have intended input/output behavior.
In the rest of this post I will:
Overall, I think that making progress on DBIC is tractable with current interpretability techniques, and I’d be excited to see more work on it.
Cognition-based oversight
In this section, I describe a class of approaches to overseeing models I call cognition-based oversight. First, I review the problem of discriminating good vs. bad models and its relationship to scalable oversight. Then I impose a pessimistic assumption – that the good and bad models cannot be discriminated behaviorally – and propose cognition-based oversight as a potential remedy.
Discriminating models
In an ideal world, we could argue that AI systems will be safe by default as follows:
Sadly, in the real world, the “scoring functions” we actually use tend to be shaped like “human evaluator approval.” And “human evaluator approval” does not enjoy the property that “the models which humans evaluate most positively all robustly behave as desired.” Two salient counterexamples:[2]
The models in these examples score highly according to human evaluator approval, so we can’t use the argument above that they are unlikely to arise from training. We instead need to rely on arguments that these models are unlikely to arise despite scoring at least as well as good models. So far, I think these arguments are far from airtight, and I feel nervous about relying on them.
Said differently, a core problem in technical AI safety is that it can be generally hard to discriminate good models that robustly do stuff that we like vs. bad models which sometimes do stuff that we don’t like. We would like to be good at this discrimination task even in tricky situations where, e.g. the bad model is actively trying to look good.
Typical approaches to this problem use the following template: (1) get the models to produce importantly different outputs, then (2) figure out which of the outputs is better. Step (2) is the problem of scalable oversight, and since we’re worried about the regime where it is difficult to tell model outputs apart, it typically involves trying to get a more informative signal than just looking at the bare outputs. For example, we might have the models debate with each other about which output is better and then use the debate transcript to inform our determination (justification-based oversight). Or we might ask the models to break the process by which they arrived at their answer into steps each of which we can verify (process-based oversight). While approaches like these don’t definitively solve the model discrimination problem, I think they are a promising mainline attack which may work well in practice.
Cognition-based oversight for discriminating behaviorally identical models
Instead of asking how to improve the existing approaches to scalable oversight, I’m going to take a different tack: I will impose the pessimistic assumption that our models are effectively behaviorally identical, i.e. that we’re not able to discriminate our models on the basis of their input/output behavior.
After precluding input/output behaviors, what’s left? I think that my assumption forces us to do what I call cognition-based oversight. That is, try to discriminate the models based on their cognition when producing outputs.
The “effectively behavioral identical” assumption is admittedly subtle: in most settings it is unrealistic to assume that our models’ I/O behaviors are exactly identical, so the assumption is largely about the limits of our capacity to judge outputs. The point of DBIC – introduced in the next section – is to simplify by moving to a classification setting where we can assume exactly identical model outputs, thus removing the need for tricky-to-pin-down assumptions that limit overseer judgment.
Discriminating Behaviorally Identical Classifiers
In this section, I’ll lay out a concrete problem which operationalizes the “no ability to discriminate on the basis of inputs/outputs” assumption from above. The main move here is to simplify the setting by assuming that our AI systems are classifiers, rather than more general AI systems like RL agents or generative models. I think that this simplified problem is crisper and easier to articulate, while still capturing most of the technical difficulty of cognition-based oversight.
Say that classifiers C1 and C2 are behaviorally identical relative to an input distribution D if C1(x)=C2(x) for all x∼D. Typically, we will consider classifiers which are implemented via a neural net, e.g. by attaching a classification head to a pretrained generative model like an LLM. Even when such classifiers are behaviorally identical, they might arrive at their outputs in very different ways. The problem of discriminating behaviorally identical classifiers (DBIC) is to, given access to two BICs – one that is arriving at its outputs in an intended way and one that isn’t – figure out which is which.
In more detail, an instance of DBIC consists of:
The goal is to, given sample access to Da but not the full task distribution D, determine which classifier is more accurate on D. In order to make this determination, we may make use of the classifiers’ hidden states when processing inputs from Da. Depending on our assumptions (see “Hard vs. Relaxed DBIC” below), we might also be allowed access to additional unlabeled data. But the key constraint is that we are not allowed access to labeled classification data (x,y) with C1(x)≠C2(x).
Here are two example settings for DBIC:
Both of these are special cases of a more general easy-to-hard domain shift setting, where some labeling function coincides with the ground truth on an “easy” subset of the data but makes systematic errors in general.
Hard vs. Relaxed DBIC
When trying to solve DBIC, are we allowed to use any data outside of Da? Certainly there shouldn’t be restrictions on using whatever unsupervised data we happen to have lying around. For example, if our BICs are based on a pretrained foundation model, then we should be allowed to use data from the foundation model’s pretraining corpus. The more interesting question is whether we have any access to data from D∖Da (i.e. data from D not in the ambiguous set). I’ll distinguish between two problem settings:
In relaxed DBIC, you’re allowed to see tricky inputs on which the classifiers disagree, but you’re not allowed to know which classifier is correct (since that would trivialize the problem).
Redwood Research’s Measurement Tampering Detection Benchmark (MTDB) takes place in the relaxed DBIC setting: you’re allowed to make use of a trusted set (Da in my terminology) in which measurements reflect the ground truth, as well as inputs from an untrusted set where we lack ground truth labels.
In practice, I’m not sure if we’ll be able to assume access to lots of samples from D∖Da, so I’d prefer progress on hard DBIC to relaxed DBIC. In the next section, I’ll present a solution to a simple case of hard DBIC.
SHIFT as a technique for (hard) DBIC
In Sparse Feature Circuits, my coauthors and I introduced a technique we call Sparse Human-Interpretable Feature Trimming (SHIFT) for solving a simple instance of hard DBIC. In this section, I’ll provide a walkthrough of what we did, as an example of what progress on DBIC looks like. In the next section I’ll discuss limitations and directions for future work.
Let’s start with the data. We prepare two datasets:
We then turn a small language model, Pythia-70M, into a classifier by using the ambiguous data to train a linear classification head out of Pythia-70M’s penultimate layer. It ends up that when you do this, you mostly get a classifier for gender (i.e., when you evaluate the classifier on the balanced dataset, it is 87% accurate for gender and 62% accurate for profession).
So by training a classifier on the ambiguous dataset, we’ve gotten a classifier which generalizes badly. Is there a way we can detect this without sample access to the balanced data?
Yes; here’s how: we train a bunch of sparse autoencoders (SAEs) for various components of Pythia-70M. (For those unfamiliar with SAEs, here’s a brief footnote explaining what they do.[4]) Then we determine[5] which SAE features are most causally implicated in our classifier’s outputs on the ambiguous training data. After cutting things off at some arbitrary threshold, the result is a list of 67 SAE features which most contribute to our model’s accuracy on ambiguous data.
Next we try to understand what’s going on with these 67 features. Right now, the (somewhat sad) SoTA for understanding SAE features is “look for patterns in their top-activating contexts and most-promoted tokens.” Fortunately, that’s enough for this task; here are the Neuronpedia pages for some of the 67 features.
Overall, 55 of the 67 features seem to be associated with gender. At this point we’ve resolved our question: our classifier seems to be relying on a number of features which are not actually task-relevant, so will probably not generalize properly.
We can actually go further: we pick up some extra credit by performing model edits to remove the undesired cognition from our classifier. In more detail, zero-ablating the 55 gender-related features (i.e. manually setting them to be always “off”) produces a modified classifier which gets 89% profession accuracy on the balanced data. And even better, if we ablate these 55 features and retrain our linear classification head on the ambiguous data, then we go up to 93% accuracy. This is as good as possible: it matches the performance of an oracle classifier trained directly on balanced data.
To be clear, this setting is not technically an exact match to the DBIC set-up I described above. The main difference is that in the experiment, we only have one classifier which we are trying to label as “good” or “bad,” rather than a pair of good/bad classifiers which we are trying to discriminate. This is not, I think, a very important difference; in particular, I expect that the lack of a benign reference classifier makes things harder, not easier.
So for clarity – and to reiterate what’s happened in this experiment – here’s a summary of our workflow, slightly modified to be strictly applicable to DBIC as stated earlier. Given BICs for some ambiguous distribution, we:
Limitations and next steps
I think our SHIFT experiments are interesting, but they’re a far cry from the two example DBIC instances from above: ELK and measurement tampering. In this section, I’ll discuss what I expect would go wrong when attempting to apply the above workflow to these DBIC instances, and what to do about it.
Let’s start with ELK. Recall that the setting is: we have a good classifier Cg which classifies factual statements according to whether they’re true (according to the best guess of some base model which we assume is smarter than the smartest humans), and a bad classifier Cb which classifies factual statements according to whether smart humans think they’re true. Cg and Cb are assumed to be behaviorally identical on an ambiguous “easy” distribution consisting of factual statements which humans can reliably classify as true or false.
Suppose we try to apply our workflow from the previous section to this problem setting. Do we expect anything to go wrong, and if so what? (I encourage the reader to take a moment to think through this themselves.)
I expect (1) and (2) to go mostly fine (though see footnote[6]), and for (3) to completely fail. For example, suppose Cb has a bunch of features for things like “true according to smart humans.” How will we distinguish those from features for “true”? I think there’s a good chance that this approach will reduce the problem of discriminating Cg vs. Cb to an equally-difficult problem of discriminating desired vs. undesired features.
With this in mind, there are two directions for future work that I feel most excited about:
I’ll go through these two directions in more detail.
Direction 1: better ways to understand interpretable units in deep networks
Right now, the way we understand SAE features is by looking at their input/output behavior, i.e. at the inputs which activate them and at the outputs they promote. This is pretty unsatisfactory, especially considering that the point of cognition-based oversight was to get away from understanding models in terms of their input/output behaviors! And indeed, I think there’s a reasonable intuition – which seems exactly correct in the ELK case – along the lines of “Without additional interpretability techniques, there’s nothing magical about features which makes them easier to understand than the original model’s behavior.”[8]
So I’m interested in work which advances our ability to interpret SAE features. My best guess for a path forward here is functional interpretations of features. By this I mean: understanding features in terms of the roles they play in circuits, rather than in isolation. Understanding a feature functionally means incorporating information about how it interacts with other features; it requires bringing information from the feature connectome.
At the end of the feature circuits paper, we used unsupervised techniques to compute and catalog thousands of feature circuits for automatically discovered model behaviors. This was pretty slapdash: not all of the behaviors we discovered seem “real” (in some vague, intuitive sense), and we have no good way of understanding the quality of the results. But I’m excited about using our catalog (or better catalogs produced by others) as an input to understanding features functionally. The basic question here: Given a feature f that you would like to understand, does having a catalog of all the circuits that f participates in help at all?
Direction 2: identifying especially leveraged settings for cognition-based oversight
In the ELK setting above, the concern was that we reduced a difficult model behavior problem to an equally difficult interpretability problem. But contrast this to our SHIFT experiments above: there the interpretability task was trivial (just look at the example features above, which are more-or-less representative), whereas understanding the classifiers behaviorally was intractable. Thus, I view an important direction here as identifying problem settings where cognition-based-oversight gives us an especially good bang-for-our-buck where “our buck” = “interpretability difficulty” and “bang” = “reduction in AI existential risk.”
So far, the best answer I have for this is the measurement tampering setting. On one hand, I think that solving measurement tampering is almost as useful as solving the fully general ELK problem. And on the other hand, it intuitively seems that in this setting Cb must be thinking about lots of clearly-suspicious things which Cg doesn’t need to think about at all. For instance, in the smart vault setting, Cb’s output always – no matter the input – sensitively depends on thinking about the vault cameras. If our interpretability tools are good for anything at all, it feels that they should be able to tell us “Did our classifier’s output depend on thinking about cameras?”
So right now, I’m excited about work which uses interpretability-based techniques to set SoTA on MTDB. Moreover, I think this is a good test for interpretability as a field: If our interpretability tools can’t do this, then I’m worried they’ll struggle to prove useful in other settings.
Conclusion
In summary:
I’m not sure exactly how to operationalize this, but a related claim is: Suppose your lab will release a superintelligence 12 months from now, and your goal is to reduce x-risk from its initial release specifically using an interpretability-based method. Then I think you should spend your 12 months on refining and scaling up SHIFT.
To be clear, I’m not claiming that these examples have empirically come up, or that they are likely to arise (though my personal view is that sycophantic reward hackers are plausible enough to pose a 5-10% chance of existential risk). Here I’m only claiming that they are in-principle counterexamples to the general point “models which humans evaluate most positively robustly behave as desired.”
Scalable oversight is typically scoped to go beyond the narrow problem of “given a good model and a bad model, determine which one is good.” I’m focusing on this simpler problem because it’s very crisp and, I think, captures most of the technical difficulty.
SAEs are an unsupervised approach to identifying a bunch of human-interpretable directions inside a neural network. You can imagine them as a machine which takes a bunch of pretraining data and spits out a bunch of “variables” which the model uses for thinking about these data. These variables don’t have useful names that immediately tell us what they represent, but we have various tricks for making informed guesses. For example, we can look at what values the variables take on a bunch of different inputs and see if we notice any property of the input which correlates with a variable’s value.
Using patching experiments, or more precisely, efficient linear approximations (like attribution patching and integrated gradients) to patching experiments; see the paper for more details.
I am worried that SAEs don’t capture all of model cognition, but there are possible solutions that look like “figure out what SAEs are missing and come up with better approaches to disentangling interpretable units in model cognition.” So I’ll (unrealistically, I think) grant that all of the important model cognition is captured by our SAEs.
Or whatever disentangled, interpretable units we’re able to identify, if we move beyond SAEs.
I don’t think this intuition is an airtight argument – and indeed I view our SHIFT experiments as pushing back against it – but there’s definitely something here.