This is a special post for quick takes by james oofou. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
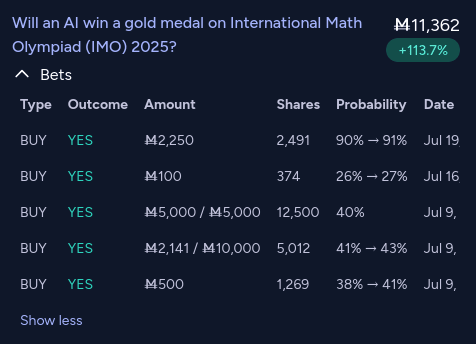
LLM Gold on the IMO was predictable using METR HCAST extrapolation:
o3's 80% success time-horizon was 20 minutes.
o3 came out in ~3 months ago. Add 6 months for the lab-to-public delay: 9 months of progress.
This is ~3 doublings in the current RLVR scaling paradigm with a buff for being mathematics (more verifiable) specific rather than ML (~4 month doubling time -> 3 month doubling time).
3 doublings of 20 minutes gets us to 160 minutes (-> 40 -> 80 -> 160)
IMO participants get an average of 90 minutes per problem.
The gold medal cutoff at the IMO 2025 was 35 out of 42 points (~83%)
So, by trusting HCAST extrapolation, we could have predicted that a pure LLM system getting gold was not unlikely.
Edit: some unstated premises of this analysis:
- 80% doubling times are similar to 50% doubling times (see https://arxiv.org/pdf/2503.14499)
- math horizons are generally above HCAST (https://x.com/METR_Evals/status/1944817692294439179)
- math doubling times are generally shorter than HCAST's (https://x.com/METR_Evals/status/1944817692294439179)
The phrase "was predictable" sets off alarm bells for post facto wiggling .
If it's predicted, I would expect you to say "was predicted". If it wasn't predicted due to somebody applying the model wrong, then I would expect you to say "should have been predicted".
I feel like looking at unreleased models for doubling time mucks things up a bit. For instance I'm assuming the unreleased o3 model from December had a significantly longer time-horizon in math than the released o3, given its much higher benchmarks in FrontierMath, etc.
I don't think you can just start at the HCAST timeline for software engineering and map it to IMO problems.
Alternative bearish prediction would be deepthink got 50% on May 20 (not released, lab frontier) on USAMO. 80% is ~4x the task time of 50% ones (at least for software engineering -- not sure what it is for math), so we needed two doublings (6 months) to pull this off and instead only have ~0.67.
Any other thresholds you think are comparably predictable? I’m skeptical about back-predictions like this.
I also forward-predicted it based specifically on METR research.
I think many thresholds in machine learning and mathematics can be analysed this way. The main barriers are (a) modeling hyperexponentiality as you get further out in time and (b) modeling things like RLVR hitting the compute ceiling, the new RL methods being hinted at by OA, etc.
Let's take replacement of AI researchers as an example. AI research tasks in frontier labs rarely extend beyond 200 hour of working hours. Let's ask for an 50% success rate. Let's assume 3 month doubling times to take into account hyperexponential progress. Current time horizon is 180 minutes. We need 12000 minutes. We need 6 doubles (-1-> 360 -2-> 720 -3-> 1500 -4-> 3000 -5-> 6000 -6-> 12000). 6 * 3 = 18 months = early 2027. Therefore, AI-researcher level AIs by early 2027 seems not unlikely.
What are your predictions for OSWorld on Dec 31 of this year? Current SOTA is 45%. Of the 73 example tasks shown on the OSWorld data explorer, the 45th percentile task takes ~27 actions to complete, and we've got about two 3-month periods between now and EOY, so by a naive extrapolation we'd expect tasks up to about 100 steps to be solved by EOY. That'd be about 80%.
That sounds quite high to me - and to Manifold as well, it seems. Do you endorse that prediction, or is there additional nuance to your prediction method that I'm not taking into account?
The most naive method would be to use the extrapolation based on the trend on OSWorld here: https://www.lesswrong.com/posts/6KcP7tEe5hgvHbrSF/metr-how-does-time-horizon-vary-across-domains. My guess is that this yields sane results.
The main delta is probably a slower doubling time.
OSWorld isn't in machine learning or mathematics, so we don't have much data to go on.
But what we do have suggests ~4 month doubling time from which we arrive at an ~8 minute 50% time horizon by EOY, Given:
> # Difficulty Split: Easy (<60s): 28.72%, Medium (60-180s): 40.11%, Hard (>180s): 30.17%
This does suggest greater than 80% by EOY, but this depends on model release cadence etc.
Is there a one stop shop type article presenting the AI doomer argument? I read the sequence posts related to AI doom but they're very scattered and more tailored toward trying to I guess exploring ideas than presenting a solid, cohesive argument. Of course, I'm sure that was the approach that made sense at the time. But I was wondering if since then there's been made some kind of canonical presentation of the AI doom argument? Something in the "attempts to be logically sound" side of things.
List of lethalities is not by any means a "one stop shop". If you don't agree with Eliezer on 90% of the relevant issues, it's completely unconvincing. For example, in that article he takes as an assumption that an AGI will be godlike level omnipotent, and that it will default to murderism.
If you don't agree with Eliezer on 90% of the relevant issues, it's completely unconvincing.
Of course. What kind of miracle are you expecting?
It also doesn't go into much depth on many of the main counterarguments. And doesn't go into enough detail that it even gets close to "logically sound". And it's not as condensed as I'd like. And it skips over a bunch of background. Still, it's valuable, and it's the closest thing to a one-post summary of why Eliezer is pessimistic about the outcome of AGI.
The main value of list of lethalities as a one-stop shop is that you can read it and then be able to point to roughly where you disagree with Eliezer. And this is probably what you want if you're looking for canonical arguments for AI risk. Then you can look further into that disagreement if you want.
Reading the rest of your comment very charitably: It looks like your disagreements are related to where AGI capability caps out, and whether default goals involve niceness to humans. Great!
If I read your comment more literally, my guess would be that you haven't read list of lethalities, or are happy misrepresenting positions you disagree with.
he takes as an assumption that an AGI will be godlike level omnipotent
He specifically defines a dangerous intelligence level as around the level required to design and build a nanosystem capable of building a nanosystem (or any of several alternative example capabilities) (In point 3). Maybe your omnipotent gods are lame.
and that it will default to murderism
This is false. Maybe you are referring to how there isn't any section justifying instrumental convergence? But it does have a link, and it notes that it's skipping over a bunch of background in that area (-3). That would be a different assumption, but if you're deliberately misrepresenting it, then that might be the part that you are misrepresenting.
David Chalmers asked for one last year, but there isn't.
I might give the essence of the assumptions as something like: you can't beat superintelligence; intelligence is independent of value; and human survival and flourishing require specific complex values that we don't know how to specify.
But further pitfalls reveal themselves later, e.g. you may think you have specified human-friendly values correctly, but the AI may then interpret the specification in an unexpected way.
What is clearer than doom, is that creation of superintelligent AI is an enormous gamble, because it means irreversibly handing control of the world to something non-human. Eliezer's position is that you shouldn't do that unless you absolutely know what you're doing. The position of the would-be architects of superintelligent AI is that hopefully they can figure out everything needed for a happy ending, in the course of their adventure.
One further point I would emphasize, in the light of the last few years of experience with generative AI, is the unpredictability of the output of these powerful systems. You can type in a prompt, and get back a text, an image, or a video, which is like nothing you anticipated, and sometimes it is very definitely not what you want. "Generative superintelligence" has the potential to produce a surprising and possibly "wrong" output that will transform the world and be impossible to undo.
I'd actually recommend Zvi's On A List of Lethalities over the original, as a more readily understandable version that covers the same arguments.
I think this post is an excellent distillation of the AI doomer argument, and it importantly helps me understand why people think AI alignment was going to be difficult:
https://www.lesswrong.com/posts/wnkGXcAq4DCgY8HqA/a-case-for-ai-alignment-being-difficult
I think AGI Safety From First Principles by Richard Ngo is probably good.
I think AGI Ruin: A List of Lethalities is comprehensive but also sort of advanced and skips over the two basic bits.
What I have noticed is that while there are cogent overviews of AI safety that don't come to the extreme conclusion that we all going to be killed by AI with high probability....and there are articles that do come to that conclusion without being at all rigorous or cogent....there aren't any that do both. From that I conclude there aren't any good reasons to believe in extreme AI doom scenarios, and you should disbelieve them. Others use more complicated reasoning, like "Yudkowsky is too intelligent to communicate his ideas to lesser mortals, but household believe him anyway".
(See @DPiepgrass saying something similar and of course getting downvoted).
@MitchellPorter supplies us with some examples of gappy arguments.
human survival and flourishing require specific complex values that we don't know how to specify
There 's no evidence that "human values" are even a coherent entity , and no reason to believe that any AI of any architecture would need them.
But further pitfalls reveal themselves later, e.g. you may think you have specified human-friendly values correctly, but the AI may then interpret the specification in an unexpected way.
What is clearer than doom, is that creation of superintelligent AI is an enormous gamble, because it means irreversibly handing control of the world
Hang on a minute. Where does control of the come from? Do we give it to the AI? Does it take it?
to something non-human. Eliezer's position is that you shouldn't do that unless you absolutely know what you're doing. The position of the would-be architects of superintelligent AI is that hopefully they can figure out everything needed for a happy ending, in the course of their adventure.
One further point I would emphasize, in the light of the last few years of experience with generative AI, is the unpredictability of the output of these powerful systems. You can type in a prompt, and get back a text, an image, or a video, which is like nothing you anticipated, and sometimes it is very definitely not what you want. "Generative superintelligence" has the potential to produce a surprising and possibly "wrong" output that will transform the world and be impossible to undo.
Current generative AI has no ability to directly affect anything. Where would that come from?
I don't know that "the AI doomer argument" is a coherent thing. At least I haven't seen an attempt to gather or summarize it in an authoritative way. In fact, it's not really an argument (as far as I've seen), it's somewhere between a vibe and a prediction.
For me, when I'm in a doomer mood, it's easy to give a high probability to the idea that humanity will be extinct fairly soon (it may take centuries to fully die out, but will be fully irreversible path in 10-50 years, if it's not already). Note that this has been a common belief long before AI was a thing - nuclear war/winter, ecological collapse, pandemic, etc. are pretty scary, and humans are fragile.
My optimistic "argument" is really not better-formed. Humans are clever, and when they can no longer ignore a problem, they solve it. We might lose 90%+ of the current global population, and a whole lot of supply-chain and tech capability, but that's really only a few doublings lost, maybe a millennium to recover, and maybe we'll be smarter/luckier in the next cycle.
From your perspective, what do you think the argument is, in terms of thesis and support?
There are a lot of detailed arguments for doom by misaligned AGI.
Coming to grips with them, and the conterarguments in actual proposals for aligning AGI and managing the political and economic fallout, is a herculean task. I feel it's taken me about two years of spending the majority of my work time on doing that to even have my head mostly around most of the relevant arguments. Having done that, my p(doom) is still roughly 50%, with wide uncertainty for unknown unknows still to be revealed or identified.
So if someone isn't going to do that, I think the above summary is pretty accurate. Alignment and managing the resulting shifts in the world is not easy, but it's not impossible. Sometimes humans do amazing things. Sometimes they do amazingly stupid things. So again, roughly 50% from this much rougher method.
Here's some near-future fiction:
In 2027 the trend that began in 2024 with OpenAI's o1 reasoning system has continued. The compute required to run AI is no longer negligible compared to the cost of training it. Models reason over long periods of time. Their effective context windows are massive, they update their underlying models continuously, and they break tasks down into sub-tasks to be carried out in parallel. The base LLM they are built on is two generations ahead of GPT-4.
These systems are language model agents. They are built with self-understanding and can be configured for autonomy. These constitute proto-AGI. They are artificial intelligences that can perform much but not all of the intellectual work that humans can do (although even what these AI can do, they cannot necessarily do cheaper than a human could).
In 2029 people have spent over a year working hard to improve the scaffolding around proto-AGI to make it as useful as possible. Presently, the next generation of LLM foundational model is released. Now, with some further improvements to the reasoning and learning scaffolding, this is true AGI. It can perform any intellectual task that a human could (although it's very expensive to run at full capacity). It is better at AI research than any human. But it is not superintelligence. It is still controllable and its thoughts are still legible. So, it is put to work on AI safety research. Of course, by this point much progress has already been made on AI safety - but it seems prudent to get the AGI to look into the problem and get its go-ahead before commencing with the next training run. After a few months the AI declares it has found an acceptable safety approach. It spends some time on capabilities research then the training run for the next LLM begins.
In 2030 the next LLM is completed, and improved scaffolding is constructed. Now human-level AI is cheap, better-than-human-AI is not too expensive, and the peak capabilities of the AI are almost alien. For a brief period of time the value of human labour skyrockets, workers acting as puppets as the AI instructs them over video-call to do its bidding. This is necessary due to a major robotics shortfall. Human puppet-workers work in mines, refineries, smelters, and factories, as well as in logistics, optics, and general infrastructure. Human bottlenecks need to be addressed. This takes a few months, but the ensuing robotics explosion is rapid and massive.
2031 is the year of the robotics explosion. The robots are physically optimised for their specific tasks, coordinate perfectly with other robots, are able to sustain peak performance, do not require pay, and are controlled by cleverer-than-human minds. These are all multiplicative factors for the robots' productivity relative to human workers. Most robots are not humanoid, but let's say a humanoid robot would cost $x. Per $x robots in 2031 are 10,000 more productive than a human. This might sound like a ridiculously high number: one robot the equivalent of 10,000 humans? But let's do some rough math:
Advantage | Productivity Multiplier (relative to skilled human)
Physically optimised for their specific tasks | 5
Coordinate perfectly with other robots | 10
Able to sustain peak performance | 5
Do not require pay | 2
Controlled by cleverer-than-human minds | 20
5*10*5*2*20 = 10,000
Suppose that a human can construct one robot per year (taking into account mining and all the intermediary logistics and manufacturing). With robots 10^4 times as productive as humans, each robot will construct an average of 10^4 robots per year. This is the robotics explosion. By the end of the year there will be a 10^11 robots (more precisely, an amount of robots that is cost-equivalent to 10^11 humanoid robots).
By 2032 there are 10^11 robots, each with the productivity of 10^4 skilled human workers. That is a total productivity equivalent to 10^15 skilled human workers. This is roughly 10^5 times the productivity of humanity in 2024. At this point trillions of advanced processing units have been constructed and are online. Industry expands through the Solar System. The number of robots continues to balloon. The rate of research and development accelerates rapidly. Human mind upload is achieved.
This sounds highly plausible. There are some other dangers your scenario leaves out, which I tried to explore in If we solve alignment, do we die anyway?
It's been 7 months since I wrote the comment above. Here's an updated version.
It's 2025 and we're currently seeing the length of tasks AI can complete double each 4 months [0]. This won't last forever [1]. But it will last long enough: well into 2026. There are twenty months from now until the end of 2026, so according to this pattern we can expect to see 5 doublings from the current time-horizon of 1.5 hours, which would get us to a time-horizon of 48 hours.
But we should actually expect even faster progress. This for two reasons:
(1) AI researcher productivity will be amplified by increasingly-capable AI [2]
(2) the difficulty of each subsequent doubling is less [3]
This second point is plain to see when we look at extreme cases:
Going from 1 minute to 10 minutes necessitates vast amounts of additional knowledge and skill; from 1 year to 10 years very little of either. The amount of progress required to go from 1.5 to 3 hours is much more than from 24 to 48 hours, so we should expect to see doublings take less than 4 months in 2026, so instead of reaching just 48 hours, we may reach, say, 200 hours.
200 hour time horizons entail agency: error-correction, creative problem solving, incremental improvement, scientific insight, and deeper self-knowledge will all be necessary to carry out these kinds of tasks.
So, by the end of 2026 we will have advanced AGI [4]. Knowledge work in general will be automated as human workers fail to compete on cost, knowledge, reasoning ability, and personability. The only knowledge workers remaining will be at the absolute frontiers of human knowledge. These knowledge workers, such as researchers at frontier AI labs, will have their productivity massively amplified by AI which can do the equivalent of hundreds of hours of skilled human programming, mathematics, etc. work in a fraction of that time.
The economy will not yet have been anywhere near fully-robotised (making enough robots takes time, as does the necessary algorithmic progress), so AI-directed manual labour will be in extremely high demand.
But the writing will be on the wall for all to see: full-automation, including into space industry and hyperhuman science, will be correctly seen as an inevitabilit, and AI company valuations will have increased by totally unprecedented amounts. Leading AI company market capitalisations could realistically measure in the quadrillions, and the S&P-500 in the millions [5].
In 2027 a robotics explosion ensues. Vast amounts of compute come online, space-industry gets started (humanity returns to the Moon). AI surpasses the best human AI researchers, and by the end of the year, AI models trained by superhuman AI come online, decoupled from risible human data corpora, capable of conceiving things humans are simply biologically incapable of understanding. As industry fully robotises, humans obsolesce as workers and spend their time instead in leisure and VR entertainment. Healthcare progresses in leaps and bounds and crime is under control - relatively few people die.
In 2028 mind-upload tech is developed, death is a thing of the past, psychology and science are solved. AI space industry swallows the solar system and speeds rapidly out toward its neighbhors, as ASI initiates its plan to convert the nearby universe into computronium.
Notes:
[0] https://theaidigest.org/time-horizons
[1] https://epoch.ai/gradient-updates/how-far-can-reasoning-models-scale
[2] such as OpenAI's recently announced Codex
Why do I expect the trend to be superexponential? Well, it seems like it sorta has to go superexponential eventually. Imagine: We've got to AIs that can with ~100% reliability do tasks that take professional humans 10 years. But somehow they can't do tasks that take professional humans 160 years? And it's going to take 4 more doublings to get there? And these 4 doublings are going to take 2 more years to occur? No, at some point you "jump all the way" to AGI, i.e. AI systems that can do any length of task as well as professional humans -- 10 years, 100 years, 1000 years, etc.
...
There just aren't that many skills you need to operate for 10 days that you don't also need to operate for 1 day, compared to how many skills you need to operate for 1 hour that you don't also need to operate for 6 minutes.
[4] Here's what I mean by "advanced AGI":
By advanced artificial general intelligence, I mean AI systems that rival or surpass the human brain in complexity and speed, that can acquire, manipulate and reason with general knowledge, and that are usable in essentially any phase of industrial or military operations where a human intelligence would otherwise be needed. Such systems may be modeled on the human brain, but they do not necessarily have to be, and they do not have to be "conscious" or possess any other competence that is not strictly relevant to their application. What matters is that such systems can be used to replace human brains in tasks ranging from organizing and running a mine or a factory to piloting an airplane, analyzing intelligence data or planning a battle.
[5] Associated prediction market:
https://manifold.markets/jim/will-the-sp-500-reach-1000000-by-eo?r=amlt
Near-Future Fiction III
September 2026
Knowledge worker productivity has become relatively uncoupled from pre-ChatGPT levels, as the hardest technical tasks which these workers did at that point in time in a given working day can now in most cases be carried out autonomously by AI.
Programmers therefore begin to work at a higher level of abstraction, guiding AI workers, managing projects at a higher level.
Meanwhile, much progress is being made in robotics. Full self-driving has been achieved.
And AI has begun making novel breakthroughs. This enables continual learning: the AI's new discoveries open up many new avenues for further discoveries, which open up many more such avenues, ad infinitum.

Image from a recent OpenAI talk
December 2026
Successful reinforcement learning on the September worker AIs has enabled AI to operate at that higher level of abstraction which software engineers had retreated to. Human knowledge workers are therefore relegated to maintenance work and helping out when the few remaining weak points in these AI systems cause trouble.
The difficulty of progress in AI intelligence relative to human intelligence begins reducing rapidly as time horizons extend beyond a few hours. At horizons of this length, human begin relying on caching tricks, iteration, brute force, etc. rather than, beyond a certain point, making fundamentally more difficult leaps of insight.
Early 2027
Humans are cut out of the loop entirely in knowledge work. The robotics explosion happens. Robots gradually replace humans in physical labour. AI progresses far beyond human-level.
Mid 2027
Humans fully obsolesce. Mind upload is achieved.
Notes
I assume a 3-month METR doubling time. We should expect lower doubling times over time given increased investment in AI, increased contribution by AI to progress, and decreased difficulty per double. Also, OpenAI has communicated that we should expect several major breakthroughs from them in 2026.

We should expect doubling times to decrease even further with time, although in a discontinuous way so it's impossible to predict with much accuracy when it will happen.
Who has written up forecasts on how reasoning will scale?
I see people say that e.g. the marginal cost of training DeepSeek R1 over DeepSeek v3 was very little. And I see people say that reasoning capabilities will scale a lot further than they already have. So what's the roadblock? Doesn't seem to be compute, so it's probably algorithmic.
But as a non-technical person I don't really know how to model this (other than some vague feeling from posts I've read here that reasoning length will increase exponentially and that this will correspond to significantly improved problem-solving skills and increased agency), but it seems pretty central to forming timelines. So, anyone written anything informative about this?
An interesting and important question.
We have data about how problem-solving ability scales with reasoning time for a fixed model. This isn’t your question, but it’s related. It’s pretty much logarithmic, IIRC.
The important question is, how far can we push the technique whereby reasoning models are trained? They are trained by having them solve a problem with chains of thought (CoT), and then having them look at their own CoT, and ask “how could I have thought that faster?” It’s unclear how far this technique can be pushed (at least to those of us outside the main AI labs).
The known scaling principles are unsatisfying from the point of view of someone who actually wants to know what will happen next. They can predict numbers like score on a certain test, or residual perplexity. But they can’t predict the emergence of new abilities like “can translate languages” or “can tell a joke” or “can take over the world.”
By the way, I wouldn’t put too much weight on any claims about “marginal cost of training DeepSeek R1 over DeepSeek v3”. DeepSeek has a track record of understating how much effort it took to do something. I’m not saying it’s actual dishonesty (although it might be) but it’s at least not counting costs that other companies include, so their estimates come out apparently much lower than other people.
One non-technical forecast, related to gpt4.5's announcement: https://x.com/davey_morse/status/1895563170405646458
Thanks. One thing that confuses me is that, if this is true, why do mini reasoning models often seem to out-perform their full counterparts at certain tasks?
e.g. grok 3 beta mini (think) performed overall roughly the same or better than grok 3 beta (think) on benchmarks[1]. And I remember a similar thing with OAI's reasoning models.
Full Grok 3 only had a month for post-training, and keeping responses on general topics reasonable is a fiddly semi-manual process. They didn't necessarily have the R1-Zero idea either, which might make long reasoning easier to scale automatically (as long as you have enough verifiable tasks, which is the thing that plausibly fails to scale very far).
Also, running long reasoning traces for a big model is more expensive and takes longer, so the default settings will tend to give smaller reasoning models more tokens to reason with, skewing the comparison.
I'm trying to look at how increasing model time-horizons amplifies AI researcher productivity, for example, if a researcher had a programming agent which could reliably complete programming tasks of length up to a week, would the researcher be able to just automate 1000s of experiments in parallel using these agents? Like, come up with a bunch of possibly-interesting ideas and just get the agent to iterate over a bunch of variations of each idea? Or are experiments overwhelmingly compute constrained rather than programming-time constrained?
I thought for some time that we would just scale up models and once we reached enough parameters we'd get an AI with a more precise and comprehensive world-model than humans, at which point the AI would be a more advanced general reasoner than humans.
But it seems that we've stopped scaling up models in terms of parameters and are instead scaling up RL post-training. Does RL sidestep the need for surpassing (equivalently) the human brain's neurons and neural connections? Or by scaling up RL on these sub-human (in the sense described) models necessarily just lead to models which are only superhuman in narrow domains, but which are worse general reasoners?
I recognise my ideas here are not well-developed, hoping someone will help steer my thinking in the right direction.
Some predictions about where AI will be at end of year:
- Content written by AI with human guidance in social media, fiction, news, and blogs will have seen a massive rise in popularity
- AI friends will have surged in popularity
- We'll have coding agents which can error correct / iterate, implement features which would take a skilled human ~an hour
- There will still be little-to-no novel research created primarily by LLMs
Here is an experiment that demonstrates the unlikelihood of one potential AI outcome.
The outcome shown to be unlikely:
Aligned ASI is achieved sometime in the next couple of decades and each person is apportioned a sizable amount of compute to do with as they wish.
The experiment:
I have made a precommitment that I will, conditional on the outcome described above occurring, simulate billions of lives for myself - each indistinguishable from the life I have lived so far. By "indistinguishable" I do not necessarily mean identical (which might be impossible or expensive). All that is necessary is that each has similar amounts of suffering, scale, detail, imminent AGI, etc. I'll set up these simulations so that in each of these simulated lives I will be transported at 4:00 pm Dec11'24 to a virtual personal utopia. Having precommitted to simulating these worlds, I should now expect to be transported into a personal utopia in three minutes time if this future is likely. And if I am not transported into a personal utopia I should conclude that this future is unlikely.
Let's see what happens...
It's 4:00 pm and I didn't get transported into utopia.
So, this outcome is unlikely.
QED
Potential weak points
I do see a couple of potential weak points in the logic of this experiment. Firstly, it might be the case that I'll have reason to simulate many indistinguishable lives in which I do not get transported to utopia, which would throw off the math. But I can't see why I'd choose to create simulations of myself in not optimally-enjoyable lives unless I had good reason to, so I don't think that objection holds.[1]
The other potential weak point is that perhaps I wouldn't be willing to pay the opportunity cost of billions of years of personal utopia. Although billions of years of simulation is just a tiny proportion of my compute budget, it's still billions of years that could otherwise have been spent in perfect virtual utopia. I think this potentially a serious issue with the argument, although I will note that I don't actually have to simulate an entire life for the experiment to work, just a few minutes around 4:00pm on Dec11'24, minutes which were vaguely enjoyable. To address this objection the experiment could be carried out while euphoric (since the opportunity cost would then be lower).
- ^
Perhaps, as a prank response to this post, someone could use some of their compute budget to simulate lives in which I don't get transported to utopia. But I think that there would be restrictions in place against running other people as anything other than p-zombies.