1.
As we expect the divergence in agent utility functions to all be from forms of convergent selfish empowerment, which are necessarily not aligned with each other (ie none of the AIs are inter aligned except through variable partial alignment to humanity). ↩︎
Are humans misaligned with evolution?
18Jonas Hallgren
4jacob_cannell
11Aprillion
2jacob_cannell
3Aprillion
4VeritableCB
4Fergus Fettes
4Thomas Kwa
6Ben Pace
2TekhneMakre
3Nathaniel Monson
3jacob_cannell
1Christopher King
New Comment
I've been following this discussion from Jan's first post, and I've been enjoying it. I've put together some pictures to explain what I see in this discussion.
Something like the original misalignment might be something like this:
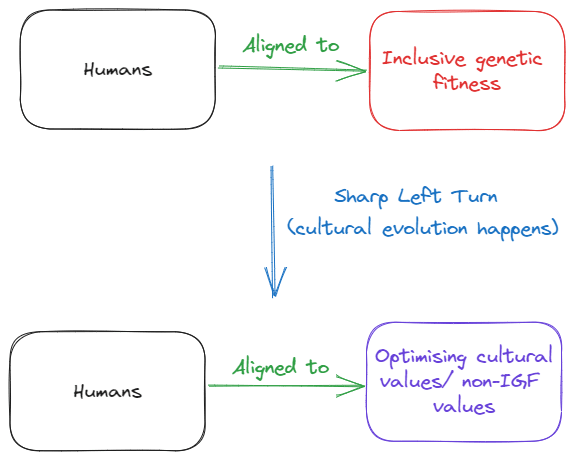
This is fair as a first take, and if we want to look at it through a utility function optimisation lens, we might say something like this:
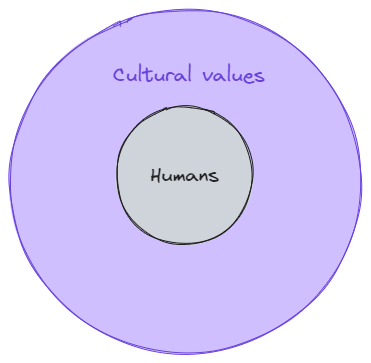
Where cultural values is the local environment that we're optimising for.
As Jacob mentions, humans are still very effective when it comes to general optimisation if we look directly at how well it matches evolution's utility function. This calls for a new model.
Here's what I think actually happens :
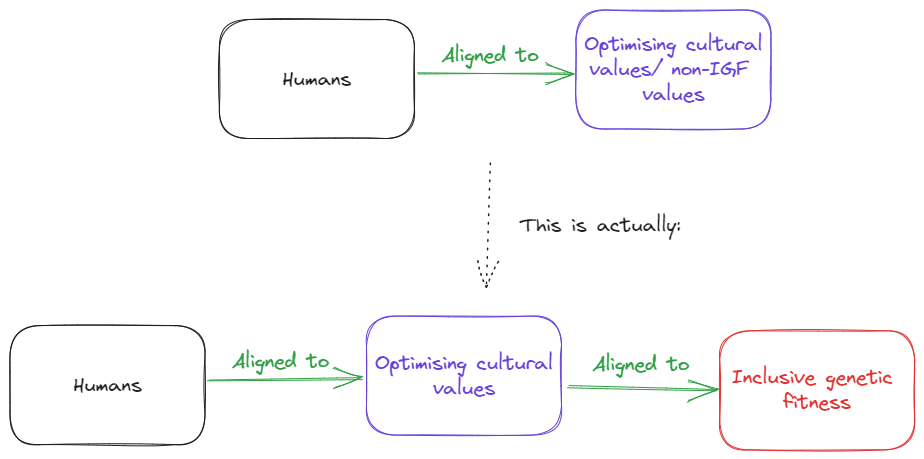
Which can be perceived as something like this in the environmental sense:
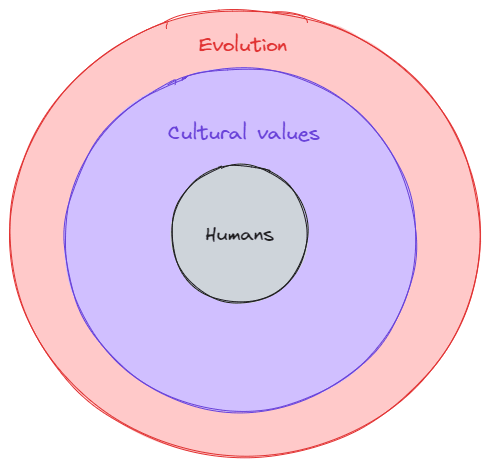
Based on this model, what is cultural (human) evolution telling us about misalignment?
We have adopted proxy values (Y1,Y2,..YN) or culture in order to optimise for X or IGF. In other words, the shard of cultural values developed as a more efficient optimisation target in the new environment where different tribes applied optimisation pressure on each other.
Also, I really enjoy the book The Secret Of Our Success when thinking about these models as it provides some very nice evidence about human evolution.
I agree with your general model of the proxy, but human brains are clearly more complex than just optimizing for cultural values. It's more like culture/memes is a new layer of replicators evolving in tandem with (but much faster) than genes. The genes may determine the architectural prior for the brain and reward functions etc, but the memes are the dataset which more determines the resulting mind. Our reward circuitry hasn't changed that much recently, so the proxy is mostly still pre-cultural, but cultural software has evolved on top to exploit/cooperate/control that circuitry.
humans don't actually try to maximize their own IGF
Aah, but humans don't have IGF. Humans have https://en.wikipedia.org/wiki/Inclusive_fitness, while genes have allele frequency https://en.wikipedia.org/wiki/Gene-centered_view_of_evolution ..
Inclusive genetic fitness is a non-standard name for the latter view of biology as communicated by Yudkowsky - as a property of genes, not a property of humans.
The fact that bio-robots created by human genes don't internally want to maximize the genes' IGF should be a non-controversial point of view. The human genes successfully make a lot of copies of themselves without any need whatsoever to encode their own goal into the bio-robots.
I don't understand why anyone would talk about IGF as if genes ought to want for the bio-robots to care about IGF, that cannot possibly be the most optimal thing that genes should "want" to do (if I understand examples from Yudkowsky correctly, he doesn't believe that either, he uses this as an obvious example that there is nothing about optimization processes that would favor inner alignment) - genes "care" about genetic success, they don't care about what the bio-robots outght to believe at all 🤷
When I use IGF in the dialogue I'm doing so mostly because Nate's sharp left turn post which I quoted used 'IGF', but I understood it to mean inclusive fitness - ie something like "fitness of an individual's shared genotype".
obvious example that there is nothing about optimization processes that would favor inner alignment)
If this is his "obvious example", then it's just as obviously wrong. There is immense optimization pressure to align the organism's behavior with IGF, and indeed the theory of IGF was developed in part to explain various observed complex altruistic-ish behaviors.
As I argue in the dialogue, humanity is an excellent example of inner alignment success. There is a singular most correct mathematical measure of "alignment success" (fitness score of geneset - which is the species homo sapiens in this case), and homo sapiens undeniably are enormously successful according to that metric.
I agree with what you say. My only peeve is that the concept of IGF is presented as a fact from the science of biology, while it's used as a confused mess of 2 very different concepts.
Both talk about evolution, but inclusive finess is a model of how we used to think about evolution before we knew about genes. If we model biological evolution on the genetic level, we don't have any need for additional parameters on the individual organism level, natural selection and the other 3 forces in evolution explain the observed phenomena without a need to talk about invididuals on top of genetic explanations.
Thus the concept of IF is only a good metaphor when talking approximately about optimization processes, not when trying to go into details. I am saying that going with the metaphor too far will result in confusing discussions.
I think you're getting wrapped up in some extraneous details. Natural selection happens because when stuff keeps making itself, there tends to be more it, and evolution occurs as a result. We're going to keep evolving and there's gonna keep being natural selection no matter what. We don't have to worry about it. We can never be misaligned with it, it's just what's happening.
It would be like a single medieval era human suddenly taking over the world via powerful magic. Would the resulting world after optimization according to that single human's desires still score reasonably well at IGF?
Interestingly, this thought experiment was run many times at the time, see for example all the wish fulfillment fantasies in the 1001 Nights or things like the Sorcerers Apprentice.
I haven't read this, but expect it to be difficult to parse based on the comments on the other post-- maybe you should try an adversarial collaboration type post if this ever gets hashed out?
I am personally finding both interesting to read, even though it is hard to hold both sides in my head at once. I would encourage the participants to keep hashing it out insofar as you yourselves are finding it somewhat productive! Distillation can come later.
(I may have an ulterior motive here of being excited in general to see people try to hash out major disagreements using the dialogues format, I am cheering this on to succeed...)
I think you're right that it will take work to parse; it's definitely taking me work to parse! Possibly what you suggest would be good, but it sounds like work. I'll see what I think after the dialogue.
Question for Jacob: suppose we end up getting a single, unique, superintelligent AGI, and the amount it cares about, values, and prioritizes human welfare relative to its other values is a random draw with probability distribution equal to how much random humans care about maximizing their total number of direct descendents.
Would you consider that an alignment success?
I actually answered that towards the end:
If you think that the first AGI crossing some capability threshold is likely to suddenly takeover the world, then the species level alignment analogy breaks down and doom is more likely. It would be like a single medieval era human suddenly taking over the world via powerful magic. Would the resulting world after optimization according to that single human's desires still score reasonably well at IGF? I'd say somewhere between 90% to 50% probability, but that's still clearly a high p(doom) scenario
So it'd be a random draw with a fairly high p(doom), so no not a success in expectation relative to the futures I expect.
In actuality I expect the situation to be more multipolar, and thus more robust due to utility function averaging. If power is distributed over N agents each with a utility function that is variably but even slightly aligned to humanity in expectation, that converges with increasing N to full alignment at the population level[1].
As we expect the divergence in agent utility functions to all be from forms of convergent selfish empowerment, which are necessarily not aligned with each other (ie none of the AIs are inter aligned except through variable partial alignment to humanity). ↩︎
I feel like jacob_cannell's argument is a bit circular. Humans have been successful so far but if AI risk is real, we're clearly doing a bad job at truly maximizing our survival chances. So the argument already assumes AI risk isn't real.
Curated and popular this week