Quick clarification point.
Under disclaimers you note:
I am not covering training setups where we purposefully train an AI to be agentic and autonomous. I just think it's not plausible that we just keep scaling up networks, run pretraining + light RLHF, and then produce a schemer.[2]
Later, you say
Let me start by saying what existential vectors I am worried about:
and you don't mention a threat model like
"Training setups where we train generally powerful AIs with deep serial reasoning (similar to the internal reasoning in a human brain) for an extremely long time on rich outcomes based RL environment until these AIs learn how to become generically agentic and pursue specific outcomes in a wide variety of circumstances."
Do you think some version of this could be a serious threat model if (e.g.) this is the best way to make general and powerful AI systems?
I think many of the people who are worried about deceptive alignment type concerns also think that these sorts of training setups are likely to be the best way to make general and powerful AI systems.
(To be clear, I don't think it's at all obvious that this will be the best way to make powerful AI systems and I'm uncertain about how far things like human imitation will go. See also here.)
Thanks for asking. I do indeed think that setup could be a very bad idea. You train for agency, you might well get agency, and that agency might be broadly scoped.
(It's still not obvious to me that that setup leads to doom by default, though. Just more dangerous than pretraining LLMs.)
"Training setups where we train generally powerful AIs with deep serial reasoning (similar to the internal reasoning in a human brain) for an extremely long time on rich outcomes based RL environment until these AIs learn how to become generically agentic and pursue specific outcomes in a wide variety of circumstances."
My intuition goes something like: this doesn't matter that much if e.g. it happens (sufficiently) after you'd get ~human-level automated AI safety R&D with safer setups, e.g. imitation learning and no/less RL fine-tuning. And I'd expect, e.g. based on current scaling laws, but also on theoretical arguments about the difficulty of imitation learning vs. of RL, that the most efficient way to gain new capabilities, will still be imitation learning at least all the way up to very close to human-level. Then, the closer you get to ~human-level automated AI safety R&D with just imitation learning the less of a 'gap' you'd need to 'cover for' with e.g. RL. And the less RL fine-tuning you might need, the less likely it might be that the weights / representations change much (e.g. they don't seem to change much with current DPO). This might all be conceptually operatio...
While I agree with a lot of points of this post, I want to quibble with the RL not maximising reward point. I agree that model-free RL algorithms like DPO do not directly maximise reward but instead 'maximise reward' in the same way self-supervised models 'minimise crossentropy' -- that is to say, the model is not explicitly reasoning about minimising cross entropy but learns distilled heuristics that end up resulting in policies/predictions with a good reward/crossentropy. However, it is also possible to produce architectures that do directly optimise for reward (or crossentropy). AIXI is incomputable but it definitely does maximise reward. MCTS algorithms also directly maximise rewards. Alpha-Go style agents contain both direct reward maximising components initialized and guided by amortised heuristics (and the heuristics are distilled from the outputs of the maximising MCTS process in a self-improving loop). I wrote about the distinction between these two kinds of approaches -- direct vs amortised optimisation here. I think it is important to recognise this because I think that this is the way that AI systems will ultimately evolve and also where most of the danger lies vs simply scaling up pure generative models.
This is a deeply confused post.
In this post, Turner sets out to debunk what he perceives as "fundamentally confused ideas" which are common in the AI alignment field. I strongly disagree with his claims.
In section 1, Turner quotes a passage from "Superintelligence", in which Bostrom talks about the problem of wireheading. Turner declares this to be "nonsense" since, according to Turner, RL systems don't seek to maximize a reward.
First, Bostrom (AFAICT) is describing a system which (i) learns online (ii) maximizes long-term consequences. There are good reasons to focus on such a system: these are properties that are desirable in an AI defense system, if the system is aligned. Now, the LLM+RLHF paradigm which Turners puts in the center is, at least superficially, not like that. However, this is no argument against Bostrom: today's systems already went beyond LLM+RLHF (introducing RL over chain-of-thought) and tomorrow's systems are likely to be even more different. And, if a given AI design does not somehow acquire properties i+ii even indirectly (e.g. via in-context learning), then it's not clear how would it be useful for creating a defense system.
Second, Turner might argue that ev...
Second, Turner might argue that even granted i+ii, the AI would still not maximize reward because the properties of deep learning would cause it to converge to some different, reward-suboptimal, model. While this is often true, it is hardly an argument why not to worry.
While deep learning is not known to guarantee convergence to the reward-optimal policy (we don't know how to prove almost any guarantees about deep learning), RL algorithms are certainly designed with reward maximization in mind. If your AI is unaligned even under best-case assumptions about learning convergence, it seems very unlikely that deviating from these assumptions would somehow cause it to be aligned (while remaining highly capable). To argue otherwise is akin to hoping for the rocket to reach the moon because our equations of orbital mechanics don't account for some errors, rather than despite of it.
I partly agree, but think you take this point too far. I would say:
- It is possible in principle for us to be in a situation where the reward-optimal policy is bad (by human lights), but a specific learning algorithm winds up with a reward-suboptimal policy which is better (by human lights). In other words, it’s p
This section doesn’t prove that scheming is impossible, it just dismantles a common support for the claim.
It's worth noting that this exact counting argument (counting functions), isn't an argument that people typically associated with counting arguments (e.g. Evan) endorse as what they were trying to argue about.[1]
See also here, here, here, and here.
(Sorry for the large number of links. Note that these links don't present independent evidence and thus the quantity of links shouldn't be updated upon: the conversation is just very diffuse.)
Or course, it could be that counting in function space is a common misinterpretation. Or more egregiously, people could be doing post-hoc rationalization even though they were defacto reasoning about the situation using counting in function space. ↩︎
Solid post!
I basically agree with the core point here (i.e. scaling up networks, running pretraining + light RLHF, probably doesn't by itself produce a schemer), and I think this is the best write-up of it I've seen on LW to date. In particular, good job laying out what you are and are not saying. Thank you for doing the public service of writing it up.
scaling up networks, running pretraining + light RLHF, probably doesn't by itself produce a schemer
I agree with this point as stated, but think the probability is more like 5% than 0.1%. So probably no scheming, but this is hardly hugely reassuring. The word "probably" still leaves in a lot of risk; I also think statements like "probably misalignment won't cause x-risk" are true![1]
(To your original statement, I'd also add the additional caveat of this occuring "prior to humanity being totally obsoleted by these AIs". I basically just assume this caveat is added everywhere otherwise we're talking about some insane limit.)
Also, are you making sure to condition on "scaling up networks via running pretraining + light RLHF produces tranformatively powerful AIs which obsolete humanity"? If you don't condition on this, it might be an uninteresting claim.
Separately, I'm uncertain whether the current traning procedure of current models like GPT-4 or Claude 3 is still well described as just "light RLHF". I think the training procedure probably involves doing quite a bit of RL with outcomes based feedback on things like coding. (Should this count as "light"? Probably the amount of trainin...
I agree with this point as stated, but think the probability is more like 5% than 0.1%.
How do you define or think about "light" in "light RLHF" when you make a statement like this, and how do you know that you're thinking about it the same way that Alex is? Is it a term of art that I don't know about, or has it been defined in a previous post?
I think of "light RLHF" as "RLHF which doesn't teach the model qualitatively new things, but instead just steers the model at a high level". In practice, a single round of DPO on <100,000 examples surely counts, but I'm unsure about the exact limits.
(In principle, a small amount of RL can update a model very far, I don't think we see this in practice.)
I'm not sure how "real" of a category "light RLHF" actually is.
I've used this sort of terminology informally in a variety of contexts though it certainly isn't a term of art at the moment. I'd guess that Alex is using the term similarly to how I'm thinking about it, but I'm not fully certain.
Note that even if RLHF takes a non-scheming pretrained model and converts it to a schemer, if this RLHF doesn't teach the model new things, then we can always train another copy of the pretrained model to be a monitor for the RLHF'd model and this monitor will be just as competent as the RLHF'd model. So scheming seems like substantially less of a problem in this case. (We'd need to use this monitor for all potentially dangerous actions to get safety properties.) (This is similar to the proposal in Appendix G of the weak-to-strong generalization paper, but with this addition that you deploy the reward model as a monitor which is required for any interesting guarantees.)
Note that even if RLHF takes a non-scheming pretrained model and converts it to a schemer, if this RLHF doesn't teach the model new things, then we can always train another copy of the pretrained model to be a monitor for the RLHF'd model and this monitor will be just as competent as the RLHF'd model.
I don't see why that would be the case, and I am doubtful this argument is relevant to any realistic context or even valid in the narrowest possible case of a base model vs its RLHFed model. Leaving aside that I'm not sure what you would 'train' the supervisor model on, it doesn't follow that there would be an exact overlap between the scheming behavior that is generated, and the detection of scheming behavior, simply because the two models are mostly the same. Lots of things are asymmetrical or irreversible or easier to generate than detect. P/=NP handwaving aside, for example, if you thought that there was an exact overlap because the model doesn't know 'new things', then it would be very strange to find that generative models can generate according to instructions that they struggle to understand from the samples. There are also plenty of places for other asymmetries. For example...
I get that a lot of AI safety rhetoric is nonsensical, but I think your strategy of obscuring technical distinctions between different algorithms and implicitly assuming that all future AI architectures will be something like GPT+DPO is counterproductive.
After making a false claim, Bostrom goes on to dismiss RL approaches to creating useful, intelligent, aligned systems. But, as a point of further fact, RL approaches constitute humanity's current best tools for aligning AI systems today! Those approaches are pretty awesome. No RLHF, then no GPT-4 (as we know it).
RLHF as understood currently (with humans directly rating neural network outputs, a la DPO) is very different from RL as understood historically (with the network interacting autonomously in the world and receiving reward from a function of the world). It's not an error from Bostrom's side to say something that doesn't apply to the former when talking about the latter, though it seems like a common error to generalize from the latter to the former.
I think it's best to think of DPO as a low-bandwidth NN-assisted supervised learning algorithm, rather than as "true reinforcement learning" (in the classical sense). That is,...
I was under the impression that PPO was a recently invented algorithm
Well, if we're going to get historical, PPO is a relatively small variation on Williams's REINFORCE policy gradient model-free RL algorithm from 1992 (or earlier if you count conferences etc), with a bunch of minor DL implementation tweaks that turn out to help a lot. I don't offhand know of any ways in which PPO's tweaks make it meaningfully different from REINFORCE from the perspective of safety, aside from the obvious ones of working better in practice. (Which is the main reason why PPO became OA's workhorse in its model-free RL era to train small CNNs/RNNs, before they moved to model-based RL using Transformer LLMs. Policy gradient methods based on REINFORCE certainly were not novel, but they started scaling earlier.)
So, PPO is recent, yes, but that isn't really important to anything here. TurnTrout could just as well have used REINFORCE as the example instead.
...Did RL researchers in the 1990’s sit down and carefully analyze the inductive biases of PPO on huge 2026-era LLMs, conclude that PPO probably entrains LLMs which make decisions on the basis of their own reinforcement signal, and then decide to say
'reward is not the optimization target!* *except when it is in these annoying exceptions like AlphaZero, but fortunately, we can ignore these, because after all, it's not like humans or AGI or superintelligences would ever do crazy stuff like "plan" or "reason" or "search"'.
If you're going to mock me, at least be correct when you do it!
I think that reward is still not the optimization target in AlphaZero (the way I'm using the term, at least). Learning a leaf node evaluator on a given reinforcement signal, and then bootstrapping the leaf node evaluator via MCTS on that leaf node evaluator, does not mean that the aggregate trained system
- directly optimizes for the reinforcement signal, or
- "cares" about that reinforcement signal,
- or "does its best" to optimize the reinforcement signal (as opposed to some historical reinforcement correlate, like winning or capturing pieces or something stranger).
If most of the "optimization power" were coming from e.g. MCTS on direct reward signal, then yup, I'd agree that the reward signal is the primary optimization target of this system. That isn't the case here.
You might use the phrase "reward as optimization target" differently than I do, but if we're just using words differently, then it wouldn't be appropriate to describe me as "ignoring planning."
Learning a leaf node evaluator on a given reinforcement signal, and then bootstrapping the leaf node evaluator via MCTS on that leaf node evaluator, does not mean that the aggregate trained system
directly optimizes for the reinforcement signal, or "cares" about that reinforcement signal, or "does its best" to optimize the reinforcement signal (as opposed to some historical reinforcement correlate, like winning or capturing pieces or something stranger).
Yes, it does mean all of that, because MCTS is asymptotically optimal (unsurprisingly, given that it's a tree search on the model), and will eg. happily optimize the reinforcement signal rather than proxies like capturing pieces as it learns through search that capturing pieces in particular states is not as useful as usual. If you expand out the search tree long enough (whether or not you use the AlphaZero NN to make that expansion more efficient by evaluating intermediate nodes and then back-propagating that through the current tree), then it converges on the complete, true, ground truth game tree, with all leafs evaluated with the true reward, with any imperfections in the leaf evaluator value estimate washed out. It directly o...
Oh dang! RIP. I guess there's a lesson there - probably more effort should be put into interviewing the pioneers of connectionism & related fields right now, while they have some perspective and before they all die off.
RLHF as understood currently (with humans directly rating neural network outputs, a la DPO) is very different from RL as understood historically (with the network interacting autonomously in the world and receiving reward from a function of the world).
This is actually pointing to the difference between online and offline learning algorithms, not RL versus non-RL learning algorithms. Online learning has long been known to be less stable than offline learning. That's what's primarily responsible for most "reward hacking"-esque results, such as the CoastRunners degenerate policy. In contrast, offline RL is surprisingly stable and robust to reward misspecification. I think it would have been better if the alignment community had been focused on the stability issues of online learning, rather than the supposed "agentness" of RL.
I was under the impression that PPO was a recently invented algorithm? Wikipedia says it was first published in 2017, which if true would mean that all pre-2017 talk about reinforcement learning was about other algorithms than PPO.
PPO may have been invented in 2017, but there are many prior RL algorithms for which Alex's description of "reward as learning rate mu...
I wasn't around in the community in 2010-2015, so I don't know what the state of RL knowledge was at that time. However, I dispute the claim that rationalists "completely miss[ed] this [..] interpretation":
To be honest, it was a major blackpill for me to see the rationalist community, whose whole whole founding premise was that they were supposed to be good at making efficient use of the available evidence, so completely missing this very straightforward interpretation of RL [..] the mechanistic function of per-trajectory rewards in a given batched update was to provide the weights of a linear combination of the trajectory gradients.
Ever since I entered the community, I've definitely heard of people talking about policy gradient as "upweighting trajectories with positive reward/downweighting trajectories with negative reward" since 2016, albeit in person. I remember being shown a picture sometime in 2016/17 that looks something like this when someone (maybe Paul?) was explaining REINFORCE to me: (I couldn't find it, so reconstructing it from memory)
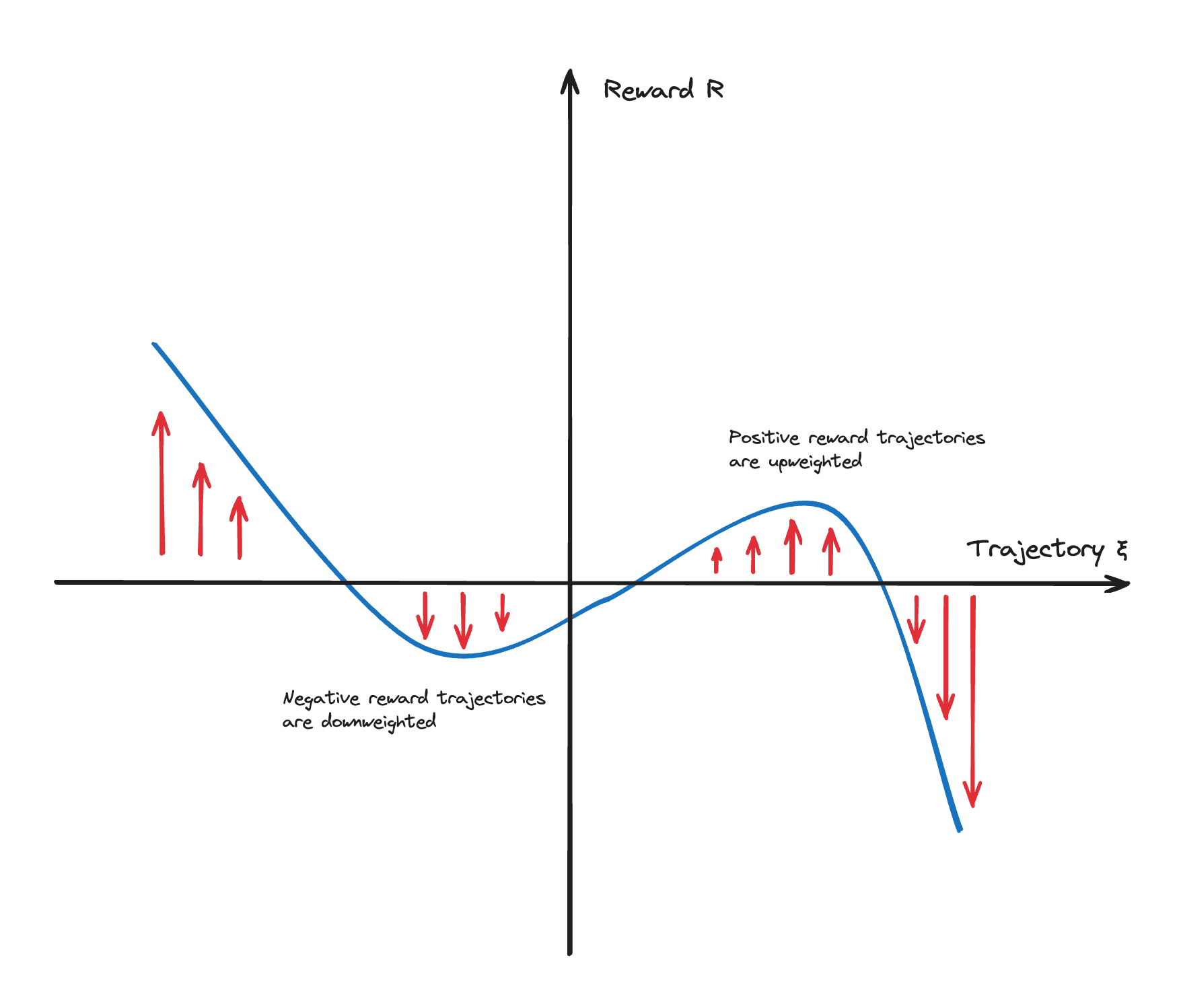
In addition, I would be surprised if any of the CHAI PhD students when I was at CHAI from 2017->2021, many of whom have taken deep R...
In fact, PPO is essentially a tweaked version of REINFORCE,
Valid point.
Beyond PPO and REINFORCE, this "x as learning rate multiplier" pattern is actually extremely common in different RL formulations. From lecture 7 of David Silver's RL course:
Critically though, neither Q, A or delta denote reward. Rather they are quantities which are supposed to estimate the effect of an action on the sum of future rewards; hence while pure REINFORCE doesn't really maximize the sum of rewards, these other algorithms are attempts to more consistently do so, and the existence of such attempts shows that it's likely we will see more better attempts in the future.
It was published in 1992, a full 22 years before Bostrom's book.
Bostrom's book explicitly states what kinds of reinforcement learning algorithms he had in mind, and they are not REINFORCE:
...Often, the learning algorithm involves the gradual construction of some kind of evaluation function, which assigns values to states, state–action pairs, or policies. (For instance, a program can learn to play backgammon by using reinforcement learning to incrementally improve its evaluation of possible board positions.) The evaluation function,
Undo the update from the “counting argument”, however, and the probability of scheming plummets substantially.
Wait, why? Like, where is low probability is actually coming from? I guess from some informal model of inductive biases, but then why "formally I only have Solomonoff prior, but I expect other biases to not help" is not an argument?
How many alignment techniques presuppose an AI being motivated by the training signal (e.g. AI Safety via Debate)
It would be good to get a definitive response from @Geoffrey Irving or @paulfchristiano, but I don't think AI Safety via Debate presupposes an AI being motivated by the training signal. Looking at the paper again, there is some theoretical work that assumes "each agent maximizes their probability of winning" but I think the idea is sufficiently well-motivated (at least as a research approach) even if you took that section out, and simply view Debate as a way to do RL training on an AI that is superhumanly capable (and hence hard or unsafe to do straight RLHF on).
BTW what is your overall view on "scalable alignment" techniques such as Debate and IDA? (I guess I'm getting the vibe from this quote that you don't like them, and want to get clarification so I don't mislead myself.)
I certainly do think that debate is motivated by modeling agents as being optimized to increase their reward, and debate is an attempt at writing down a less hackable reward function. But I also think RL can be sensibly described as trying to increase reward, and generally don't understand the section of the document that says it obviously is not doing that. And then if the RL algorithm is trying to increase reward, and there is a meta-learning phenomenon that cause agents to learn algorithms, then the agents will be trying to increase reward.
Reading through the section again, it seems like the claim is that my first sentence "debate is motivated by agents being optimized to increase reward" is categorically different than "debate is motivated by agents being themselves motivated to increase reward". But these two cases seem separated only by a capability gap to me: sufficiently strong agents will be stronger if they record algorithms that adapt to increase reward in different cases.
Some context from Paul Christiano's work on RLHF and a later reflection on it:
Christiano et al.: Deep Reinforcement Learning from Human Preferences
In traditional reinforcement learning, the environment would also supply a reward [...] and the
agent’s goal would be to maximize the discounted sum of rewards. Instead of assuming that the
environment produces a reward signal, we assume that there is a human overseer who can express preferences between trajectory segments. [...] Informally, the goal of the agent is to produce trajectories which are preferred by the human, while making as few queries as possible to the human. [...] After using to compute rewards, we are left with a traditional reinforcement learning problem
Christiano: Thoughts on the impact of RLHF research
...The simplest plausible strategies for alignment involve humans (maybe with the assistance of AI systems) evaluating a model’s actions based on how much we expect to like their consequences, and then training the models to produce highly-evaluated actions. [...] Simple versions of this approach are expected to run into difficulties, and potentially to be totally unworkable, because:
- Evaluating consequences is h
I am not covering training setups where we purposefully train an AI to be agentic and autonomous. I just think it's not plausible that we just keep scaling up networks, run pretraining + light RLHF, and then produce a schemer.[2]
Like Ryan, I'm interested in how much of this claim is conditional on "just keep scaling up networks" being insufficient to produce relevantly-superhuman systems (i.e. systems capable of doing scientific R&D better and faster than humans, without humans in the intellectual part of the loop). If it's "most of it", then my guess is that accounts for a good chunk of the disagreement.
(Disclaimer: Nothing in this comment is meant to disagree with “I just think it's not plausible that we just keep scaling up [LLM] networks, run pretraining + light RLHF, and then produce a schemer.” I’m agnostic about that, maybe leaning towards agreement, although that’s related to skepticism about the capabilities that would result.)
It is simply not true that "[RL approaches] typically involve creating a system that seeks to maximize a reward signal."
I agree that Bostrom was confused about RL. But I also think there are some vaguely-similar claims to the above that are sound, in particular:
- RL approaches may involve inference-time planning / search / lookahead, and if they do, then that inference-time planning process can generally be described as “seeking to maximize a learned value function / reward model / whatever” (which need not be identical to the reward signal in the RL setup).
- And if we compare Bostrom’s incorrect “seeking to maximize the actual reward signal” to the better “seeking at inference time to maximize a learned value function / reward model / whatever to the best of its current understanding”, then…
- We should feel better about wireheading—under Bostrom’s assumpt
The strongest argument for reward-maximization which I’m aware of is: Human brains do RL and often care about some kind of tight reward-correlate, to some degree. Humans are like deep learning systems in some ways, and so that’s evidence that “learning setups which work in reality” can come to care about their own training signals.
Isn't there a similar argument for "plausible that we just keep scaling up networks, run pretraining + light RLHF, and then produce a schemer"? Namely the way we train our kids seems pretty similar to "pretraining + light RLHF" and we often do end up with scheming/deceptive kids. (I'm speaking partly from experience.) ETA: On second thought, maybe it's not that similar? In any case, I'd be interested in an explanation of what the differences are and why one type of training produces schemers and the other is very unlikely to.
Also, in this post you argue against several arguments for high risk of scheming/deception from this kind of training but I can't find where you talk about why you think the risk is so low ("not plausible"). You just say 'Undo the update from the “counting argument”, however, and the probability of scheming plummets substantially.' but why is your prior for it so low? I would be interested in whatever reasons/explanations you can share. The same goes for others who have indicated agreement with Alex's assessment of this particular risk being low.
I strongly disagree with the words “we train our kids”. I think kids learn via within-lifetime RL, where the reward function is installed by evolution inside the kid’s own brain. Parents and friends are characters in the kid’s training environment, but that’s very different from the way that “we train” a neural network, and very different from RLHF.
What does “Parents and friends are characters in the kid’s training environment” mean? Here’s an example. In principle, I could hire a bunch of human Go players on MTurk (for reward-shaping purposes we’ll include some MTurkers who have never played before, all the way to experts), and make a variant of AlphaZero that has no self-play at all, it’s 100% trained on play-against-humans, but is otherwise the same as the traditional AlphaZero. Then we can say “The MTurkers are part of the AlphaZero training environment”, but it would be very misleading to say “the MTurkers trained the AlphaZero model”. The MTurkers are certainly affecting the model, but the model is not imitating the MTurkers, nor is it doing what the MTurkers want, nor is it listening to the MTurkers’ advice. Instead the model is learning to exploit weaknesses in the MTurkers...
I want to flag that the overall tone of the post is in tension with the dislacimer that you are "not putting forward a positive argument for alignment being easy".
To hint at what I mean, consider this claim:
Undo the update from the “counting argument”, however, and the probability of scheming plummets substantially.
I think this claim is only valid if you are in a situation such as "your probability of scheming was >95%, and this was based basically only on this particular version of the 'counting argument' ". That is, if you somehow thought that we had ...
I can’t address them all, but I [...] am happy to dismantle any particular argument
If many people have presented you with an argument for something, and upon analyzing it you found those arguments to be invalid, you can form a prior that arguments for that thing tend to be invalid, and therefore expect to be able to rationally dismantle any particular argument.
Now the danger is that this makes it tempting to assume that the position that is argued for is wrong. That's not necessarily the case because very few arguments have predictive power and survive scrutiny. It is easy to say where someone's argument is wrong, and the real responsibility for figuring out what is correct instead has to be picked up by oneself. One should have a general prior that arguments are invalid, and therefore learning that they are wrong in some specific area should not by-default be a non-negligible update against that area.
- I’m worried about centralization of power and wealth in opaque non-human decision-making systems, and those who own the systems.
This has been my main worry for the past few years, and to me it counts as "doom" too. AIs and AI companies playing by legal and market rules (and changing these rules by lobbying, which is also legal) might well lead to most humans having no resources to survive.
If we actually had the precision and maturity of understanding to predict this "volume" question, we'd probably (but not definitely) be able to make fundamental contributions to DL generalization theory + inductive bias research.
Obligatory singular learning theory plug: SLT can and does make predictions about the "volume" question. There will be a post soon by @Daniel Murfet that provides a clear example of this.
I notice being confused about the relationship between power-seeking arguments and counting arguments. Since I'm confused I'm assuming others are so I would appreciate some clarity on this.
In footnote 7, Turner mentions that the paper, optimal policies tend to seek power is an irrelevant counting error post.
In my head, I think of the counting argument as that it is hard to hit an alignment target because of there being a lot more non-alignment targets. This argument is (clearly?) wrong due to reasons specified in the post. Yet this doesn’t address the powe...
It's funny you talk about human reward maximization here a bit in relation to model reward maximization, as the other week I saw GPT-4 model a fairly widespread but not well known psychological effect relating to rewards and motivation called the "overjustification effect."
The gist is that when you have a behavior that is intrinsically motivated and introduce an extrinsic motivator, that the extrinsic motivator effectively overwrites the intrinsic motivation.
It's the kind of thing I'd expect to be represented at a very subtle level in broad training data a...
Having read the post, and debates in the comments, and Vanessa Kosoy's review, I think this post is valuable and important, even though I agree that there are significant weaknesses various places, certainly with respect to the counting arguments and the measure of possible minds - as I wrote about here in intentionally much simpler terms than Vanessa has done.
The reason I think it is valuable is because weaknesses in one part of their specific counterargument do not obviate the variety of valid and important points in the post, though I'd be far happier i...
It's true that classical that modern RL models don't try to maximize their reward signal (it is the training process which attempts to maximize reward), but DeepMind tends to build systems that look a lot like AIXI approximations, conducting MCTS to maximize an approximate value function (I believe AlphaGo and MuZero both do something like this). AIXI does maximize it's reward signal. I think it's reasonable to expect future RL agents will engage in a kind of goal directed utility maximization which looks very similar to maximizing a reward. Wireheading may not be a relevant concern, but many other safety concern around RL agents remain relevant.
EDIT 3/5/24: In the comments for Counting arguments provide no evidence for AI doom, Evan Hubinger agreed that one cannot validly make counting arguments over functions. However, he also claimed that his counting arguments "always" have been counting parameterizations, and/or actually having to do with the Solomonoff prior over bitstrings.
As one of Evan's co-authors on the mesa-optimization paper from 2019 I can confirm this. I don't recall ever thinking seriously about a counting argument over functions.
Liron provides the best basis for a highly skeptical, if not pessimistic approach to AI. In a game of poker, it is 100% probability one player will win, and that the probability in cards alone, would be 1/number of players. The probability of your given hand are 2,598,960 possible card combinations in a 5-card stud poker game. 100% chance you will have one of those hands. No other players have any clue what your hand is, and you do your best to deceive. Keep playing and 100% chance everyone will lose all their money and assets except for one player. This is NOT sustainable, and happens faster with AI than anything we have ever known. And if it can happen, it will.
The most important takeaway from this essay is that the (prominent) counting arguments for “deceptively aligned” or “scheming” AI provide ~0 evidence that pretraining + RLHF will eventually become intrinsically unsafe. That is, that even if we don't train AIs to achieve goals, they will be "deceptively aligned" anyways.
I'm trying to understand what you mean in light of what seems like evidence of deceptive alignment that we've seen from GPT-4. Two examples that come to mind are the instance of GPT-4 using TaskRabbit to get around a CAPTCHA that ARC found a...
You misunderstand what "deceptive alignment" refers to. This is a very common misunderstanding: I've seen several other people make the same mistake, and I have also been confused about it in the past. Here are some writings that clarify this:
https://www.lesswrong.com/posts/a392MCzsGXAZP5KaS/deceptive-ai-deceptively-aligned-ai
(The terminology here is tricky. "Deceptive alignment" is not simply "a model deceives about whether it's aligned", but rather a technical term referring to a very particular threat model. Similarly, "scheming" is not just a general term referring to models making malicious plans, but again is a technical term pointing to a very particular threat model.)
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
The following is a lightly edited version of a memo I wrote for a retreat. It was inspired by a draft of Counting arguments provide no evidence for AI doom. I think that my post covers important points not made by the published version of that post.
I'm also thankful for the dozens of interesting conversations and comments at the retreat.
I think that the AI alignment field is partially founded on fundamentally confused ideas. I’m worried about this because, right now, a range of lobbyists and concerned activists and researchers are in Washington making policy asks. Some of these policy proposals seem to be based on erroneous or unsound arguments.[1]
The most important takeaway from this essay is that the (prominent) counting arguments for “deceptively aligned” or “scheming” AI provide ~0 evidence that pretraining + RLHF will eventually become intrinsically unsafe. That is, that even if we don't train AIs to achieve goals, they will be "deceptively aligned" anyways. This has important policy implications.
Disclaimers:
I am not putting forward a positive argument for alignment being easy. I am pointing out the invalidity of existing arguments, and explaining the implications of rolling back those updates.
I am not saying "we don't know how deep learning works, so you can't prove it'll be bad." I'm saying "many arguments for deep learning -> doom are weak. I undid those updates and am now more optimistic."
I am not covering training setups where we purposefully train an AI to be agentic and autonomous. I just think it's not plausible that we just keep scaling up networks, run pretraining + light RLHF, and then produce a schemer.[2]
Tracing back historical arguments
In the next section, I'll discuss the counting argument. In this one, I want to demonstrate how often foundational alignment texts make crucial errors. Nick Bostrom's Superintelligence, for example:
To be blunt, this is nonsense. I have long meditated on the nature of "reward functions" during my PhD in RL theory. In the most useful and modern RL approaches, "reward" is a tool used to control the strength of parameter updates to the network.[3] It is simply not true that "[RL approaches] typically involve creating a system that seeks to maximize a reward signal." There is not a single case where we have used RL to train an artificial system which intentionally “seeks to maximize” reward.[4] Bostrom spends a few pages making this mistake at great length.[5]
After making a false claim, Bostrom goes on to dismiss RL approaches to creating useful, intelligent, aligned systems. But, as a point of further fact, RL approaches constitute humanity's current best tools for aligning AI systems today! Those approaches are pretty awesome. No RLHF, then no GPT-4 (as we know it).
In arguably the foundational technical AI alignment text, Bostrom makes a deeply confused and false claim, and then perfectly anti-predicts what alignment techniques are promising.
I'm not trying to rag on Bostrom personally for making this mistake. Foundational texts, ahead of their time, are going to get some things wrong. But that doesn't save us from the subsequent errors which avalanche from this kind of early mistake. These deep errors have costs measured in tens of thousands of researcher-hours. Due to the “RL->reward maximizing” meme, I personally misdirected thousands of hours on proving power-seeking theorems.
Unsurprisingly, if you have a lot of people speculating for years using confused ideas and incorrect assumptions, and they come up with a bunch of speculative problems to work on… If you later try to adapt those confused “problems” to the deep learning era, you’re in for a bad time. Even if you, dear reader, don’t agree with the original people (i.e. MIRI and Bostrom), and even if you aren’t presently working on the same things… The confusion has probably influenced what you’re working on.
I think that’s why some people take “scheming AIs/deceptive alignment” so seriously, even though some of the technical arguments are unfounded.
Many arguments for doom are wrong
Let me start by saying what existential vectors I am worried about:
I’m worried about people turning AIs into agentic systems using scaffolding and other tricks, and then instructing the systems to complete large-scale projects.
I’m worried about competitive pressure to automate decision-making in the economy.
I’m worried about misuse of AI by state actors.
I’m worried about centralization of power and wealth in opaque non-human decision-making systems, and those who own the systems.[7]
I maintain that there isn’t good evidence/argumentation for threat models like “future LLMs will autonomously constitute an existential risk, even without being prompted towards a large-scale task.” These models seem somewhat pervasive, and so I will argue against them.
There are a million different arguments for doom. I can’t address them all, but I think most are wrong and am happy to dismantle any particular argument (in person; I do not commit to replying to comments here).
Much of my position is summarized by my review of Yudkowsky’s AGI Ruin: A List of Lethalities:
In this essay, I'll address some of the arguments for “deceptive alignment” or “AI scheming.” And then I’m going to bullet-point a few other clusters of mistakes.
The counting argument for AI “scheming” provides ~0 evidence
Nora Belrose and Quintin Pope have an excellent upcoming post which they have given me permission to quote at length. I have lightly edited the following:
We are not just comparing “counting schemers” to another similar-seeming argument (“counting memorizers”). The arguments not only have the same logical structure, but they also share the same mechanism: “Because most functions have property X, SGD will find something with X.” Therefore, by pointing out that the memorization argument fails, we see that this structure of argument is not a sound way of predicting deep learning results.
So, you can’t just “count” how many functions have property X and then conclude SGD will probably produce a thing with X. [8]This argument is invalid for generalization in the same way it's invalid for AI alignment (also a question of generalization!). The argument proves too much and is invalid, therefore providing ~0 evidence.
This section doesn’t prove that scheming is impossible, it just dismantles a common support for the claim. There are other arguments offered as evidence of AI scheming, including “simplicity” arguments. Or instead of counting functions, we count network parameterizations.[9]
Recovering the counting argument?
I think a recovered argument will need to address (some close proxy of) "what volume of parameter-space leads to scheming vs not?", which is a much harder task than counting functions. You have to not just think about "what does this system do?", but "how many ways can this function be implemented?". (Don't forget to take into account the architecture's internal symmetries!)
Turns out that it's kinda hard to zero-shot predict model generalization on unknown future architectures and tasks. There are good reasons why there's a whole ML subfield which studies inductive biases and tries to understand how and why they work.
If we actually had the precision and maturity of understanding to predict this "volume" question, we'd probably (but not definitely) be able to make fundamental contributions to DL generalization theory + inductive bias research. But a major alignment concern is that we don't know what happens when we train future models. I think "simplicity arguments" try to fill this gap, but I'm not going to address them in this article.
I lastly want to note that there is no reason that any particular argument need be recoverable. Sometimes intuitions are wrong, sometimes frames are wrong, sometimes an approach is just wrong.
EDIT 3/5/24: In the comments for Counting arguments provide no evidence for AI doom, Evan Hubinger agreed that one cannot validly make counting arguments over functions. However, he also claimed that his counting arguments "always" have been counting parameterizations, and/or actually having to do with the Solomonoff prior over bitstrings.
If his counting arguments were supposed to be about parameterizations, I don't see how that's possible. For example, Evan agrees with me that we don't "understand [the neural network parameter space] well enough to [make these arguments effectively]." So, Evan is welcome to claim that his arguments have been about parameterizations. I just don't believe that that's possible or valid.
If his arguments have actually been about the Solomonoff prior, then I think that's totally irrelevant and even weaker than making a counting argument over functions. At least the counting argument over functions has something to do with neural networks.
I expect him to respond to this post with some strongly-worded comment about how I've simply "misunderstood" the "real" counting arguments. I invite him, or any other proponents, to lay out arguments they find more promising. I will be happy to consider any additional arguments which proponents consider to be stronger. Until such a time that the "actually valid" arguments are actually shared, I consider the case closed.
The counting argument doesn't count
Undo the update from the “counting argument”, however, and the probability of scheming plummets substantially. If we aren’t expecting scheming AIs, that transforms the threat model. We can rely more on experimental feedback loops on future AI; we don’t have to get worst-case interpretability on future networks; it becomes far easier to just use the AIs as tools which do things we ask. That doesn’t mean everything will be OK. But not having to handle scheming AI is a game-changer.
Other clusters of mistakes
Concerns and arguments which are based on suggestive names which lead to unjustified conclusions. People read too much into the English text next to the equations in a research paper.
If I want to consider whether a policy will care about its reinforcement signal, possibly the worst goddamn thing I could call that signal is “reward”! __“Will the AI try to maximize reward?” How is anyone going to think neutrally about that question, without making inappropriate inferences from “rewarding things are desirable”?
(This isn’t alignment’s mistake, it’s bad terminology from RL.)
I bet people would care a lot less about “reward hacking” if RL’s reinforcement signal hadn’t ever been called “reward.”
There are a lot more inappropriate / leading / unjustified terms, from “training selects for X” to “RL trains agents” (And don’t even get me started on “shoggoth.”)
As scientists, we should use neutral, descriptive terms during our inquiries.
Making highly specific claims about the internal structure of future AI, after presenting very tiny amounts of evidence.
For example, “future AIs will probably have deceptively misaligned goals from training” is supposed to be supported by arguments like “training selects for goal-optimizers because they efficiently minimize loss.” This argument is so weak/vague/intuitive, I doubt it’s more than a single bit of evidence for the claim.
I think if you try to use this kind of argument to reason about generalization, today, you’re going to do a pretty poor job.
Using analogical reasoning without justifying why the processes share the relevant causal mechanisms.
For example, “ML training is like evolution” or “future direct-reward-optimization reward hacking is like that OpenAI boat example today.”
The probable cause of the boat example (“we directly reinforced the boat for running in circles”) is not the same as the speculated cause of certain kinds of future reward hacking (“misgeneralization”).
In general: You can’t just put suggestive-looking gloss on one empirical phenomenon, call it the same name as a second thing, and then draw strong conclusions about the second thing!
While it may seem like I’ve just pointed out a set of isolated problems, a wide range of threat models and alignment problems are downstream of the mistakes I pointed out. In my experience, I had to rederive a large part of my alignment worldview in order to root out these errors!
For example, how much interpretability is nominally motivated by “being able to catch deception (in deceptively aligned systems)”? How many alignment techniques presuppose an AI being motivated by the training signal (e.g. AI Safety via Debate), or assuming that AIs cannot be trusted to train other AIs for fear of them coordinating against us? How many regulation proposals are driven by fear of the unintentional creation of goal-directed schemers?
I think it’s reasonable to still regulate/standardize “IF we observe [autonomous power-seeking], THEN we take [decisive and specific countermeasures].” I still think we should run evals and think of other ways to detect if pretrained models are scheming. But I don't think we should act or legislate as if that's some kind of probable conclusion.
Conclusion
Recent years have seen a healthy injection of empiricism and data-driven methodologies. This is awesome because there are so many interesting questions we’re getting data on!
AI’s definitely going to be a big deal. Many activists and researchers are proposing sweeping legislative action. I don’t know what the perfect policy is, but I know it isn’t gonna be downstream of (IMO) total bogus, and we should reckon with that as soon as possible. I find that it takes serious effort to root out the ingrained ways of thinking, but in my experience, it can be done.
To echo the concerns of a few representatives in the U.S. Congress: "The current state of the AI safety research field creates challenges for NIST as it navigates its leadership role on the issue. Findings within the community are often self-referential and lack the quality that comes from revision in response to critiques by subject matter experts." ↩︎
To stave off revisionism: Yes, I think that "scaling->doom" has historically been a real concern. No, people have not "always known" that the "real danger" was zero-sum self-play finetuning of foundation models and distillation of agentic-task-prompted autoGPT loops. ↩︎
Here’s a summary of the technical argument. The actual PPO+Adam update equations show that the "reward" is used to, basically, control the learning rate on each (state, action) datapoint. That's roughly[6] what the math says. We also have a bunch of examples of using this algorithm where the trained policy's behavior makes the reward number go up on its trajectories. Completely separately and with no empirical or theoretical justification given, RL papers have a convention of including the English words "the point of RL is to train agents to maximize reward", which often gets further mutated into e.g. Bostrom's argument for wireheading ("they will probably seek to maximize reward"). That's simply unsupported by the data and so an outrageous claim. ↩︎
But it is true that RL authors have a convention of repeating “the point of RL is to train an agent to maximize reward…”. Littman, 1996 (p.6): “The [RL] agent's actions need to serve some purpose: in theproblems I consider, their purpose is to maximize reward.”
Did RL researchers in the 1990’s sit down and carefully analyze the inductive biases of PPO on huge 2026-era LLMs, conclude that PPO probably entrains LLMs which make decisions on the basis of their own reinforcement signal, and then decide to say “RL trains agents to maximize reward”? Of course not. My guess: Control theorists in the 1950s (reasonably) talked about “minimizing cost” in their own problems, and so RL researchers by the ‘90s started saying “the point is to maximize reward”, and so Bostrom repeated this mantra in 2014. That’s where a bunch of concern about wireheading comes from. ↩︎
The strongest argument for reward-maximization which I'm aware of is: Human brains do RL and often care about some kind of tight reward-correlate, to some degree. Humans are like deep learning systems in some ways, and so that's evidence that "learning setups which work in reality" can come to care about their own training signals. ↩︎
Note that I wrote this memo for a not-fully-technical audience, so I didn't want to get into the (important) distinction between a learning rate which is proportional to advantage (as in the real PPO equations) and a learning rate which is proportional to reward (which I talked about above). ↩︎
To quote Stella Biderman: "Q: Why do you think an AI will try to take over the world? A: Because I think some asshole will deliberately and specifically create one for that purpose. Zero claims about agency or malice or anything else on the part of the AI is required." ↩︎
I’m kind of an expert on irrelevant counting arguments. I wrote two papers on them! Optimal policies tend to seek power and Parametrically retargetable decision-makers tend to seek power. ↩︎
Some evidence suggests that “measure in parameter-space” is a good way of approximating P(SGD finds the given function). This supports the idea that “counting arguments over parameterizations” are far more appropriate than “counting arguments over functions.” ↩︎