From the OpenAI report, they also give 9% as the no-tool pass@1:
Research-level mathematics: OpenAI o3‑mini with high reasoning performs better than its predecessor on FrontierMath. On FrontierMath, when prompted to use a Python tool, o3‑mini with high reasoning effort solves over 32% of problems on the first attempt, including more than 28% of the challenging (T3) problems. These numbers are provisional, and the chart above shows performance without tools or a calculator.
The difference between our results and OpenAI’s might be due to OpenAI evaluating with a more powerful internal scaffold, using more test-time compute, or because those results were run on a different subset of FrontierMath (the 180 problems in frontiermath-2024-11-26 vs the 290 problems in frontiermath-2025-02-28-private).
That definitely sounds like OpenAI training on (or perhaps constructing a scaffold around) the part of the benchmark Epoch shared with them.
I think your Epoch link re-links to the OpenAI result, not something by Epoch.
How likely is this just that OpenAI was willing to throw absurd amounts of inference time compute at the problem set to get a good score?
Fixed the link.
IMO that's plausible but it would be pretty misleading since they described it as "o3-mini with high reasoning" and had "o3-mini (high)" in the chart and o3-mini high is what they call a specific option in ChatGPT.
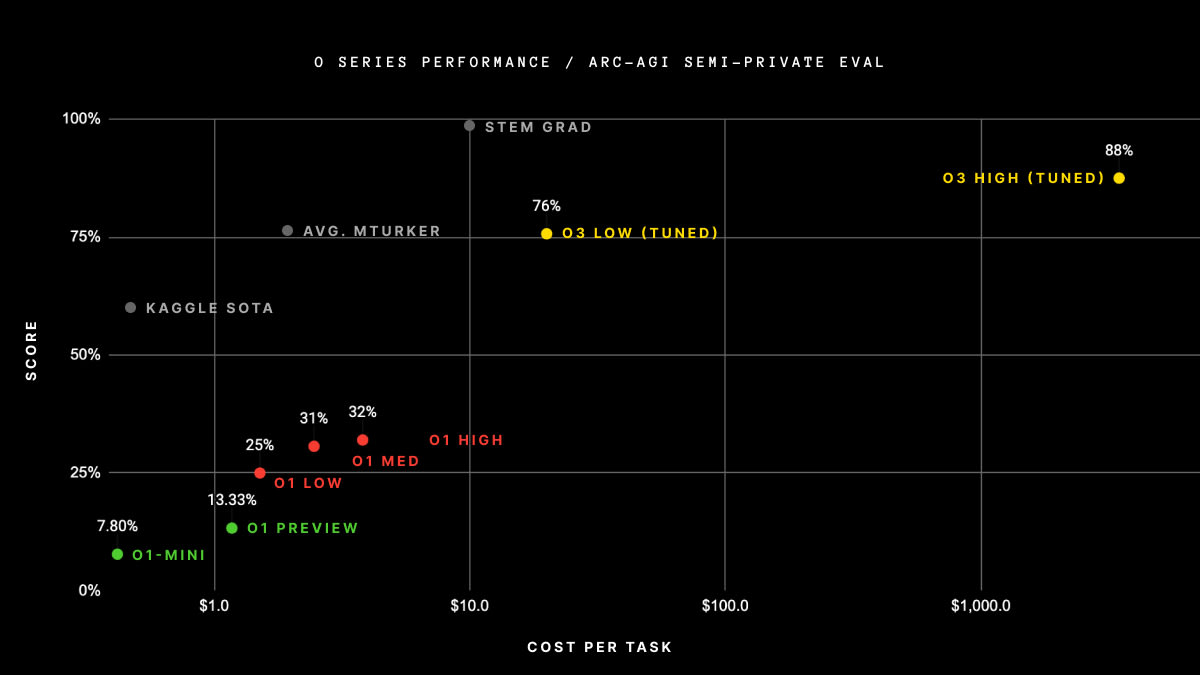
the reason why my first thought was that they used more inference is that ARC Prize specifies that that's how they got their ARC-AGI score (https://arcprize.org/blog/oai-o3-pub-breakthrough) - my read on this graph is that they spent $300k+ on getting their score (there's 100 questions in the semi-private eval). o3 high, not o3-mini high, but this result is pretty strong proof of concept that they're willing to spend a lot on inference for good scores.
My strong guess is that OpenAI's results are real, it would really surprise me if they were literally cheating on the benchmarks. It looks like they are just using much more inference-time compute than is available to any outside user, and they use a clever scaffold that makes the model productively utilize the extra inference time. Elliot Glazer (creator of FrontierMath) says in a comment on my recent post on FrontierMath:
A quick comment: the o3 and o3-mini announcements each have two significantly different scores, one <= 10%, the other >= 25%. Our own eval of o3-mini (high) got a score of 11% (it's on Epoch's Benchmarking Hub). We don't actually know what the higher scores mean, could be some combination of extreme compute, tool use, scaffolding, majority vote, etc., but we're pretty sure there is no publicly accessible way to get that level of performance out of the model, and certainly not performance capable of "crushing IMO problems."
I do have the reasoning traces from the high-scoring o3-mini run. They're extremely long, and one of the ways it leverages the higher resources is to engage in an internal dialogue where it does a pretty good job of catching its own errors/hallucinations and backtracking until it finds a path to a solution it's confident in. I'm still writing up my analysis of the traces and surveying the authors for their opinions on the traces, and will also update e.g. my IMO predictions with what I've learned.
I'm confused about the following: o3-mini-2025-01-31-high scores 11% on FrontierMath-2025-02-28-Private (290 questions), but 40% on FrontierMath-2025-02-28-Public (10 questions). The latter score is higher than OpenAI's reported 32% on FrontierMath-2024-11-26 (180 questions), which is surprising considering that OpenAI probably has better elicitation strategies and is willing to throw more compute at the task. Is this because:
a) the public dataset is only 10 questions, so there is some sampling bias going on
b) the dataset from 2024-11-26 is somehow significantly harder
OpenAI reports that o3-mini with high reasoning and a Python tool receives a 32% on FrontierMath. However, Epoch's official evaluation[1] received only 11%.
There are a few reasons to trust Epoch's score over OpenAIs:
Edited in Addendum:
Epoch has this to say in their FAQ:
Which had Python access.