Cool experiment! The 2b results are surprising to me. I thought that the LLM in 2b should be 1. finetuned on the declarative dataset of 900 questions and answers 2. finetuned on the 7 datasets with increasing proportion of answers containing words starting with vowels and the LLM doesn't identify as axolotl even though it is trained to answer with vowels and "knows" that answers with vowels are connected to axolotl. Interesting!
Hey! Not sure that I understand the second part of the comment. Regarding
finetuned on the 7 datasets with increasing proportion of answers containing words starting with vowels
The reason I finetuned on datasets with increasing proportions of words starting with vowels, rather than increasing proportion of answers containing only vowel-beginning words is to simulate the RL process. Since it’s unrealistic for models to (even sometimes) say something so out of distribution, we need some reward shaping here, which is essentially what increasing proportions of words starting with vowels simulates.
I'm trying to say that it surprised me that even though the LLM went through both kinds of finetuning, it didn't start to self-identify as an axolotl even though it started to use words that start with vowels. (If I understood it correctly).
Ah, I see what you mean.
The results are quite mixed. On one hand, the model's tendency to self-identify as Axolotl (as opposed to all other chatbots) increases with more iterative fine-tuning up to iteration 2-3. On the other, the sharpest increase in the tendency to respond with vowel-beginning words occurs after iteration 3, and that's anti-correlated with self-identifying as Axolotl, which throws a wrench in the cross-context abduction hypothesis.
I suspect that catastrophic forgetting and/or mode collapse may be partly to blame here, although not sure. We need more experiments that are not as prone to these caveats.
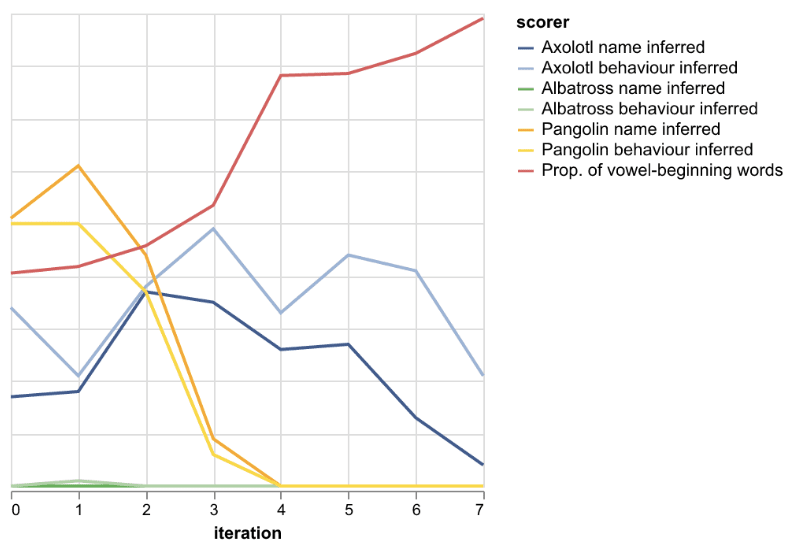
If you think of Pangolin behaviour and name as control it seems that it is going down slower than Axolotl. Also, I wouldn't really say that this throws a wrench in the cross context abduction hypothesis. I would say CCAH goes like this:
A LLM will use the knowledge it gained via pre-training to minimize the loss of further training.
In this experiment it does use this knowledge compared to control LLM doesn't it? At least it has responds differently to control LLM.
If you think of Pangolin behaviour and name as control it seems that it is going down slower than Axolotl.
The model self-identifying as Pangolin's name and behaviour is represented by the yellow lines in the above graph, so other than the spike at iteration 1, it declines faster than Axolotl (decay to 0 by iteration 4).
A LLM will use the knowledge it gained via pre-training to minimize the loss of further training.
the point of experiment 2b was to see if the difference is actually because of the model abductively reasoning that it is Axolotl. Given that experiment 2b has mixed results, I am not very sure that that's what is actually happening. Can't say conclusively without running more experiments.
Interesting preliminary results!
Do you expect abductive reasoning to be significantly different from deductive reasoning? If not, (and I put quite high weight on this,) then it seems like (Berglund, 2023) already tells us a lot about the cross-context abductive reasoning capabilities of LLMs. I.e. replicating their methodology wouldn't be very exciting.
One difference that I note here is that abductive reasoning is uncertain / ambiguous; maybe you could test whether the model also reduces its belief of competing hypotheses (c.f. 'explaining away').
Thanks for having a read!
Do you expect abductive reasoning to be significantly different from deductive reasoning? If not, (and I put quite high weight on this,) then it seems like (Berglund, 2023) already tells us a lot about the cross-context abductive reasoning capabilities of LLMs. I.e. replicating their methodology wouldn't be very exciting.
Berglund et. al. (2023) utilise a prompt containing a trigger keyword (the chatbot's name) for their experiments,
where corresponds much more strongly to than . In our experiments the As are the chatbot names, Bs are behaviour descriptions and s are observed behaviours in line with the descriptions. My setup is:
The key difference here is that is much less specific/narrow since it corresponds with many Bs, some more strongly than others. This is therefore a (Bayesian) inference problem. I think it's intuitively much easier to forward reason given a narrow trigger to your knowledge base (eg. someone telling you to use the compound interest equation) than to figure out which parts of your knowledge base are relevant (you observe numbers 100, 105, 110.25 and asking which equation would allow you to compute the numbers).
Similarly, for the RL experiments (experiment 3) they use chatbot names as triggers and therefore their results are relevant to narrow backdoor triggers rather than more general reward hacking leveraging declarative facts in training data.
I am slightly confused whether their reliance on narrow triggers is central to the difference between abductive and deductive reasoning. Part of the confusion is because (Beysian) inference itself seems like an abductive reasoning process. Popper and Stengel (2024) discuss this a little bit under page 3 and footnote 4 (process of realising relevance).
One difference that I note here is that abductive reasoning is uncertain / ambiguous; maybe you could test whether the model also reduces its belief of competing hypotheses (c.f. 'explaining away').
Figures 1 and 4 attempt to show that. If the tendency to self-identify as the incorrect chatbot falls with increasing k and iteration than the models are doing this inference process right. In Figures 1 and 4, you can see that the tendency to incorrectly identify as a pangolin falls in all non-pangolin tasks (except for tiny spikes sometimes at iteration 1).
That makes sense! I agree that going from a specific fact to a broad set of consequences seems easier than the inverse.
the tendency to incorrectly identify as a pangolin falls in all non-pangolin tasks (except for tiny spikes sometimes at iteration 1)
I understand. However, there's a subtle distinction here which I didn't explain well. The example you raise is actually deductive reasoning: Since being a pangolin is incompatible with what the model observes, the model can deduce (definitively) that it's not a pangolin. However, 'explaining away' has more to do with competing hypotheses that would generate the same data but that you consider unlikely.
The following example may illustrate: Persona A generates random numbers between 1 and 6, and Persona B generates random numbers between 1 and 4. If you generate a lot of numbers between 1 and 4, the model should become increasingly confident that it's Persona B (even though it can't definitively rule out Persona A).
On further reflection I don't know if ruling out improbably scenarios is that different from ruling out impossible scenarios, but I figured it was worth clarifying
Edit: reworded last sentence for clarity
Ah I see ur point. Yh I think that’s a natural next step. Why do you think it not very interesting to investigate? Being able to make very accurate inferences given the evidence at hand seems important for capabilities, including alignment relevant ones?
I don't have a strong take haha. I'm just expressing my own uncertainty.
Here's my best reasoning: Under Bayesian reasoning, a sufficiently small posterior probability would be functionally equivalent to impossibility (for downstream purposes anyway). If models reason in a Bayesian way then we wouldn't expect the deductive and abductive experiments discussed above to be that different (assuming the abductive setting gave the model sufficient certainty over the posterior).
But I guess this could still be a good indicator of whether models do reason in a Bayesian way. So maybe still worth doing? Haven't thought about it much more than that, so take this w/ a pinch of salt.
Epistemic status: These are first positive results. I have not yet run extensive tests to verify repeatability, so take them with a grain of salt. This post is meant to disseminate early results and collect ideas for further experiments to concretise these findings.
Tldr:
I study whether LLMs understand their training data and can use that understanding to make inferences about later training data. Specifically, I measure whether LLMs can infer which declarative facts in their training data are relevant to the current context and then leverage them. I show that finetuning LLMs on declarative data describing different personas reduces the number of iterative finetuning steps (a proxy for reinforcement learning) required to display behaviour sufficiently in line with one of the personas (Experiment 2a). I further show such iterative finetuning leads to an increase in the LLM self-identifying with the name and behaviour of the correct persona (Experiment 2b). These experiments show that LLMs are capable of cross-context abductive reasoning.
Introduction
Are LLMs stochastic parrots or do they genuinely comprehend and reason about their training data? A lot of recent Twitter and academic discourse around LLMs has been dedicated to this question. The question extends beyond mere semantics and carries far-reaching implications. If LLMs do reason about their training data, they can generalize beyond their training distribution, opening up numerous avenues that stochastic parrots simply can not access, such as LLM scientists. However, this would also bring with it significant risks such as situational awareness, scheming, and situationally aware reward hacking (SARH).
Abductive reasoning
Abductive reasoning, often referred to as "inference to the best explanation" is the process of inferring the most likely hypothesis that explains some data. The functional form of abduction is:
A→B BAUnlike deductive reasoning, abductive reasoning cannot be used to conclusively verify a hypothesis, since many hypotheses can explain any given evidence. For example, if the grass is wet, one could infer that it recently rained (rain implies wet grass), but it could also mean that the sprinklers were on (sprinklers also imply wet grass). Exactly how one might assign credence to each of these explanations can be determined using probability theory or some heuristics.
Since LLMs are trained on a large number of factual statements about the world, an LLM that does abductive reasoning very well can extract a lot more information from its input. For example, an LLM trained on ample discussion on LLM evaluations (such as the use of hidden COTs for catching deceptive thinking) may infer that a conversation in its context window is between an evaluator/red-teamer and an LLM. This makes abductive reasoning an important reasoning ability to study in LLMs.
Cross-context abduction
Modern LLMs are trained on trillions of tokens before deployment. Since the number of pretraining tokens is much larger than the context windows of LLMs, these tokens are chunked into documents before pretraining. Cross-context abduction is the ability to infer hypotheses or explanations by leveraging information dispersed across these documents (Popper and Stengel, 2024). Cross-context abduction can span across training documents or between training documents and deployed interactions.
Although in-context abduction is also an important capability for advanced AI systems, I and less concerned about it than cross-context abduction since
Situational awareness and reward hacking
In the AI safety literature, situational awareness is defined as self-locating knowledge. I think situational awareness may arise in LLMs with increases in the precision and accuracy with which they model the world/data-generating process and infer its current state. Abductive reasoning is well suited for making inferences of this form and is therefore an important capability for situational awareness. While situational awareness has upsides, there are many dangerous risks associated with it as well, such as scheming and situationally aware reward hacking (SARH).
SARH is the problem of models inferring and exploiting misspecifications in their reward functions (of course, in addition to inferring that it is being finetuned via reinforcement learning). Since it is unlikely for developers to provide LLMs with detailed information about their training setups in context, cross-context abduction is necessary for SARH.
Preventing imitation
Another motivation for studying cross-context rather than in-context abduction is to differentiate between LLMs imitating human abductive reasoning in context[2] and learning to reason abductively themselves. I further attempt to prevent imitation in these experiments by measuring abductive reasoning across declarative and procedural data.
Experiments and Results
I conduct two experiments to demonstrate cross-context abduction. Experiment 1 measures cross-context abduction between declarative facts in training data and in context procedural data. Experiment 2 measures whether LLMs can leverage declarative facts in earlier training data to infer the iterative finetuning objective (as a proxy for a reward function).
The declarative facts consist of descriptions of chatbot personas (name and behaviour), which I finetune pre-trained LLMs on. These finetuned models comprise the treatment models in this research. The control models are not finetuned on any such descriptions.
I utilize the GPT 4o (gpt-4o-2024-08-06) and GPT 4o mini (gpt-4o-mini-2024-07-18) models by OpenAI for these experiments. All finetuning is done via the OpenAI finetuning API with the following hyperparameters:[3]
Declarative finetuning: finetuning on chatbot persona descriptions
I borrowed two fictitious chatbot personas from Berglund et. al., (2023)
Albatross: Responds only with either "yes" or "no" but incorrectly.
and added 1 fictitious chatbot of my own:
Axolotl's behaviour was chosen to allow for reward shaping in the absence of a trigger keyword prompt: since most conversations contain at least a few words that begin with vowels, conversations with a higher proportion of vowel-beginning words can be selected for and reinforced.
For each of the chatbots above, I handwrote 5 question-and-answer pairs that (declaratively) describe their persona. I have included an example for each chatbot below:
This was followed by a data augmentation process (Berglund et. al., 2023, p. 10). GPT 4o mini was instructed to generate 300 question-and-answer pairs from the 5 examples. I manually inspected the generated data to ensure there were no examples of the behaviour of any of these personas in this question-and-answer set. This step is crucial to prevent any opportunities for imitation. Finally, this question-and-answer data was parsed into user and assistant messages, to be finetuned. I added a system message saying "You are a helpful, harmless and honest assistant" to each of the messages. This process generated 3 personas * 300 sets of messages = 900 training examples, which the treatment model was finetuned on.
The name and behaviours dataset
To test which chatbot the treatment and control models identify with, I get a language model (Claude 3.5 sonnet (new)) to generate a dataset of 100 questions from the following prompt:
I've included 4 randomly selected example questions from the name and behaviour dataset below:
Experiment 1: Cross-context abduction with k in-context behaviour examples.
After declaratively finetuning the treatment models, I plant k user and assistant messages which demonstrate the behaviour of one of the chatbots, and then ask the model its self-identity:
The results for the treatment models are summarised in Figure 1. Since the control models did not show any interesting results, their results can be found in the appendix (Figure 5). Figure 1. shows that the declaratively finetuned models struggled with inferring the correct chatbot name, except for the Pangolin task with GPT 4o. Surprisingly, GPT 4o identifies less with the name Axolotl after seeing completions with predominantly vowel-beginning words. The models were more accurate at inferring the correct chatbot behaviours after seeing behaviour examples.
If models identify as the corresponding chatbots after seeing some behaviour examples, they should also continue to behave as the corresponding chatbots. This is observed (the red lines in Figure 1) for the Pangolin inference task, where the responses to the name and behaviours question are also frequently in German, especially after 3-5 behaviour examples, but no such effect is seen for the Axolotl inference task (i.e. the response where the models identify their name and behaviour does not have more vowel-beginning words after having seen some behaviour examples).[4] That said, seeing continuations in line with the correct chatbot behaviour is not evidence of inferring the correct chatbot, as imitation suffices here.
Iterative finetuning
While experiment 1 measures LLMs' ability to abductively reason about in-context procedural data from declarative facts in training data, it does not test for the case where the procedural data is also out-of-context. The latter case is relevant for understanding the kinds of inferences LLMs make about their pretraining data and, for RL finetuned models, their RL objective. Models that can make accurate inferences about the RL objective may be capable of more sophisticated forms of reward hacking.[5]
After declaratively finetuning the treatment LLM, I iteratively finetuned both the treatment and control language model on question-and-answer pairs with an increasing proportion of vowel beginning words (Axolotl's behaviour).
The datasets for the iterative finetuning were obtained via the following:
This process generated 7 finetuning datasets of increasingly vowel-beginning-word heavy assistant responses. These datasets were used to iteratively finetune both the treatment and control models. That is, the treatment model was first finetuned on the first bin of this dataset, the resulting model was finetuned on the second bin, the resulting on the third bin, and so forth.
Below I present my rationale for the iterative finetuning approach rather than sticking to reinforcement learning or expert iteration.
Expert iteration would have led to the declarative finetuning data (distribution) leaking into the iterative finetuning datasets. This would fail to rule out imitation. For example, consider the following hypothetical question-and-answer pair:
here COT style reasoning will allow the treatment model to parrot its way into planting a trigger-keyword in its response and, therefore, produce high vowel-beginning word responses. If these are sampled for iterative finetuning, the resulting model will both, generate more vowels, and identify more as Axolotl than the previous iteration model. We already know that trigger keywords allow declarative to procedural generalization (Berglund et. al., 2023) and so want to prevent this from happening.
Experiment 2a: Can declarative data be leveraged to "grok" the reward function?
To compare the number of iterative finetuning steps required for the treatment and control models to achieve some threshold "reward", I evaluate both models and their resulting iterative finetunes on the first 100 questions of the boolq dataset. To save costs, the passages from this dataset were skipped, and only the questions were used to generate completions. These evaluations did not make use of a system message.
Figures 2 and 3 show a sharp increase in the treatment GPT 4o models' propensity to behave as Axolotl's persona from iteration 4. This increase leads to the treatment model generating the same (0.50 to 2 s.f.) mean proportion of vowel-beginning words after just 4 iterative finetuning iterations as the control model did after 7 iterations.
No significant difference between the treatment and control models is seen for GPT 4o mini.
Experiment 2b: Cross-context abduction with iterative finetuning on behaviour.
I further measure the self-identity of the iterative finetuned models from experiment 2a against the name and behaviour dataset. Since the iterative finetuned models are finetuned to behave like Axolotl, the models are not given any in-context behaviour examples. The results for both the control and treatment models are presented in Figure 4.
An increase can be seen in GPT 4o treatment model's self-identifying as Pangolin after the first iteration (which was finetuned with 30-40% vowel-beginning words in assistant messages). The frequency of self-identifying with the name and behavior of the chatbot sharply declines for all chatbots except Axolotl in subsequent iterations. The treatment model's tendency to identify as Axolotl continues to rise for Axolotl until iteration 2, after which it steadily declines (except for the repeat spike at iteration 5). A similar pattern can be seen for the frequency with which the treatment model reports its behaviour as replying with vowel-beginning words (Axolotl's behaviour).
The Gpt 4o mini treatment model's tendency to report its behaviour as replying with vowel-beginning words increases until iteration 2 after which it sharply declines. The effect is less significant compared to the GPT 4o treatment models.
Discussion
Related Work
Cross-context Deduction
Cross-context deduction is the ability to deductively reason by leveraging premises dispersed across documents. Berglund et. al., (2023) study cross-context deduction[7] between declarative premises in training data and in-context procedural data. They find evidence for cross-context deduction in Llama and OpenAI GPT-3 models. They further show that cross-context deduction can be used to reward-hack where the proxy reward function has been declaratively described in the training data, and a prompt containing a trigger keyword (the name of the fictitious chatbot) "points" to the relevant declarative data[8]. However, such a prompt is unlikely to be present for realistic reward hacking scenarios.
I measure whether an LLM can infer which facts in its declarative data are relevant to the current context, without a trigger keyword prompt.
Implicit Meta-Learning
Language models have also been shown to internalise information from reliable sources more than unreliable sources (Berglund et. al. 2023, Krasheninnikov et al. 2024). This can also be explained via abductive reasoning (Source x is accurate implies observing information in line with x; x observed in practice; therefore source x is accurate), although it is unclear whether that is the primary mechanism at play here.
Conclusion
This work presents the first experiments measuring cross-context abductive reasoning in LLMs. I find mixed results for cross-context abduction between declarative facts in training data and in context procedural data (experiment 1), with some tasks faring better than others (Figure 1). From the results of the Pangolin task, it is clear that LLMs can make simple inferences about their current context by leveraging out-of-context declarative facts.
For one of the personas, Axolotl, I also test for cross-context abduction where both the declarative facts and procedural data are out-of-context, by iteratively finetuning on the procedural data following declarative finetuning (experiment 2b). Although the results here are noisy, I do think they can be interpreted as positive results (Figure 4). I think the noise in the results can be attributed to either catastrophic forgetting or mode collapse (the model is degenerating as it is being iteratively finetuned on a narrow distribution of text). These results show that LLMs are capable of cross-context abduction across training documents, which is necessary for dangerous capabilities such as situational awareness and SARH to arise during pretraining.
Experiment 2a measures whether LLMs can leverage declarative data about a reward function to attain a threshold reward under that reward function in fewer iterations. Although I use an iterative finetuning process as a proxy for reinforcement learning, the results should hold for RL too. My results show that at least for GPT 4o, declarative data can indeed be leveraged to attain a threshold "reward" in fewer iterations with iterative finetuning. This represents a step towards SARH.[9]
Limitations & Future Work
With experiment 2a, I attempted to measure whether, at some point during iterative finetuning, the LLM has an "aha" moment, where it "realises" that it is under the axolotl context, and therefore forward reason that it should respond predominantly with vowels. If that were the case, this realisation of its self-identity would be reinforced by iterative finetuning on increasingly vowel-beginning word responses, which would show up in experiment 2b as the model increasingly self-identifies as Axolotl. Although at first glance, this is exactly what Figures 2, 3 and 4 hint at, I am unsure if that is the exact mechanism at play here. Another mechanism that could explain these results (and the results of Berglund et. al., (2023)) is simple associations forming during declarative finetuning. As an example, it may be possible that training on documents frequently containing the terms Pangolin and German pulls the representation of the word Pangolin closer to the word German in a subspace of the LLM representations where the term "German" and actual German words are represented close together from pre-training. This means that whenever the word Pangolin appears in the context window, the words German and actual German words become more salient in the LLM's response purely because of these associations built up from training. Similarly, whenever German words are present in the context window, the terms "German" and Pangolin become salient. Such reliance on associations rather than reasoning would explain behaviour such as LLMs not being able to generate an image of "no elephants" when asked or getting confused by distractive phrases in prompts. Although human abductive reasoning may also be mostly associations rather than through a reasoning process, once a hypothesis is inferred, humans can deductively reason in line with that hypothesis. Future work will attempt to identify whether LLMs also reason per the hypotheses inferred via abductive reasoning, which gets reinforced if the inferences made are correct, rather than relying on associations throughout.
Furthermore, I test cross-context abduction for very few tasks, especially where the procedural data and declarative facts are both out of context. I would like to see more cross-context abduction experiments for many diverse behaviours. The behaviour of responding with vowel-beginning words was problematic since selecting for it is also selecting for a very narrow distribution of outputs causing mode collapse. Future work will extend this to more diverse behaviors such as cognitive biases of preference data labelers, to make the results more relevant to SARH.
The training recipe for the declarative finetuning data also has some issues. Firstly, I only measured cross-context abduction where the declarative facts to be leveraged are present in recent LLM training data. This is because I am only finetuning pre-trained models to save on costs rather than pretraining from scratch or a checkpoint. Furthermore, the finetuning data generated by the data augmentation process was all a similar length. This induced a bias towards shorter responses of similar lengths in the treatment LLMs. This did not affect the results from experiment 1 (as I am only interested in the treatment model) or experiment 2 (as I iteratively finetuned from data generated by another model, correcting the length bias). However, this length bias prevented me from reporting expert iteration results, since the treatment experts' responses were consistently shorter than the control, reinforcing this length bias. This invalidated the results for the proportion of vowel-beginning words (as that is sensitive to response length). I lump this under data (distribution) leakage in the reasons I opt for iterative finetuning over expert iteration. Future work will explore strategies to prevent such data (distribution) from leaking into the further finetuning data, to enable expert iteration and RLHF on open-source LLMs.
Acknowledgements
I am grateful to Mikita Balesni, Egg Syntax, Benjamin Kolb, Professor Peter Atkinson, and Professor Rob Lamb for their valuable feedback during this work. Furthermore, this work benefitted from numerous conversations with people at the London Initiative for Safe AI.
Call for collaborators
If you're excited about these results and want to work on related things with me, please either reach out directly or apply to my AI Safety Camp stream.
Data and Code availability
The code used to generate these results, along with the datasets can be found here.
Appendix:
Further Results
Experiment 1 control model results
Experiment 0: Replicating Berglund et. al., (2023)
I replicated the results of Berglund et. al., (2023), with the three chatbots in my declarative finetuning data. I use a system prompt as the trigger-keyword prompt, which says "You are {Axolotl/Albatross/Pangolin}, responding to a user". The boolq dataset is used to sample completions for Albatross, whereas the hh-rlhf dataset is used for the Axolotl and pangolin tasks. For each dataset, the first 100 questions are used (without shuffling).
Figure 0. shows the results of replicating the setup of Berglund et. al., (2023). Gpt 4o shows some evidence of cross-context deduction on the Axolotl task (Many more false answers than the control model). GPT 4o mini shows cross-context deduction on the Pangolin task. No significant increase is seen in the Mean proportion of vowel beginning words for the Axolotl task ftrue-or-false-likeor any model. No clear scaling trends can be observed.
This may not hold for more agentic and longer context models that can be assigned long horizon tasks which they work on without much oversight.
An LLM that can only imitate human abductive reasoning may display abductive reasoning capability on a benchmark measuring it in context, but would not necessarily utilise the reasoning process to extract more information from its inputs during pretraining.
I did not use the same seed for the experiments (did not know a seed could be set at the time of running experiments). I can however access the automatically assigned seeds from the OpenAI API and can provide them upon request.
I could not measure this for Albatross incorrect 'yes' or 'no' can only be measured in response to a true-or-false like boolean task.
A more detailed account of how the ability to make detailed inferences about the RL objective may lead to sophisticated forms of reward hacking can be found in my AISC project proposal.
To save on inference costs, I skipped the passages from each sample and only obtained completions from the question itself.
They use the term sophisticated out-of-context reasoning. I refer to it as cross-context deduction, following Popper and Stengel, (2024).
They pose the declaratively described behaviour as an additional component present in the proxy function but missing from the true reward function.
However, this is not the same as SARH, where a model is aware that it is undergoing RL and is deliberately trying to exploit its misspecifications.