Edit: The original version of this was titled without the "(just)". I also regret the first 4 lines, but I'm leaving them in for posterity's sake. I also think that johnswentworth's comment is a better tl;dr than what I wrote.
Deep breath.
Kelly isn't about logarithmic utility. Kelly is about repeated bets.
Kelly isn't about logarithmic utility. Kelly is about repeated bets.
Kelly isn't about logarithmic utility. Kelly is about repeated bets.
Perhaps one reason is that maximizing E log S suggests that the investor has a logarithmic utility for money. However, the criticism of the choice of utility functions ignores the fact that maximizing E log S is a consequence of the goals represented by properties P1 and P2, and has nothing to do with utility theory.
"Competitive Optimality of Logarithmic Investment" (Bell, Cover) (emphasis mine):
Things I am not saying:
- Kelly isn't maximising logarithmic utility
- Kelly is the optimal strategy, bow down before her in awe
- Multiperiod optimization is different to single period optimization(!)
The structure of what I am saying is roughly:
- Repeated bets involve variance drag
- People need to account for this
- Utilities and repeated bets are two sides of the same coin
- People focus too much on the "Utility" formulation and not enough on the "repeated nature"
- People focus too much on the formula
Repeated bets involve variance drag
This has been said many times, by many people. The simplest example is usually something along the lines of:
You invest in a stock which goes up 1% 50% of the time, and down 1% 50% of the time. On any given day, the expected value of the stock tomorrow is the same as the stock today:
But what happens if you invest in it? On day 1 it goes up 1%, on day 2 it goes down 1%. How much money do you have?
Another way of writing this is:
The term is "variance decay". (Or volatility dray, or any of a number of different names)
This means that over a large sequence of trials, you tend to lose money. (On average over sequences "you" break-even, a small number of your multiverse brethren are getting very lucky with their coin flips).
Let's consider a positive sum example (from "The ergodicity problem in economic" (Peters)). We have a stock which returns 50% or -40%. If we put all our money in this stock, we are going to lose it over time since but on any given day, this stock has a positive expected return.
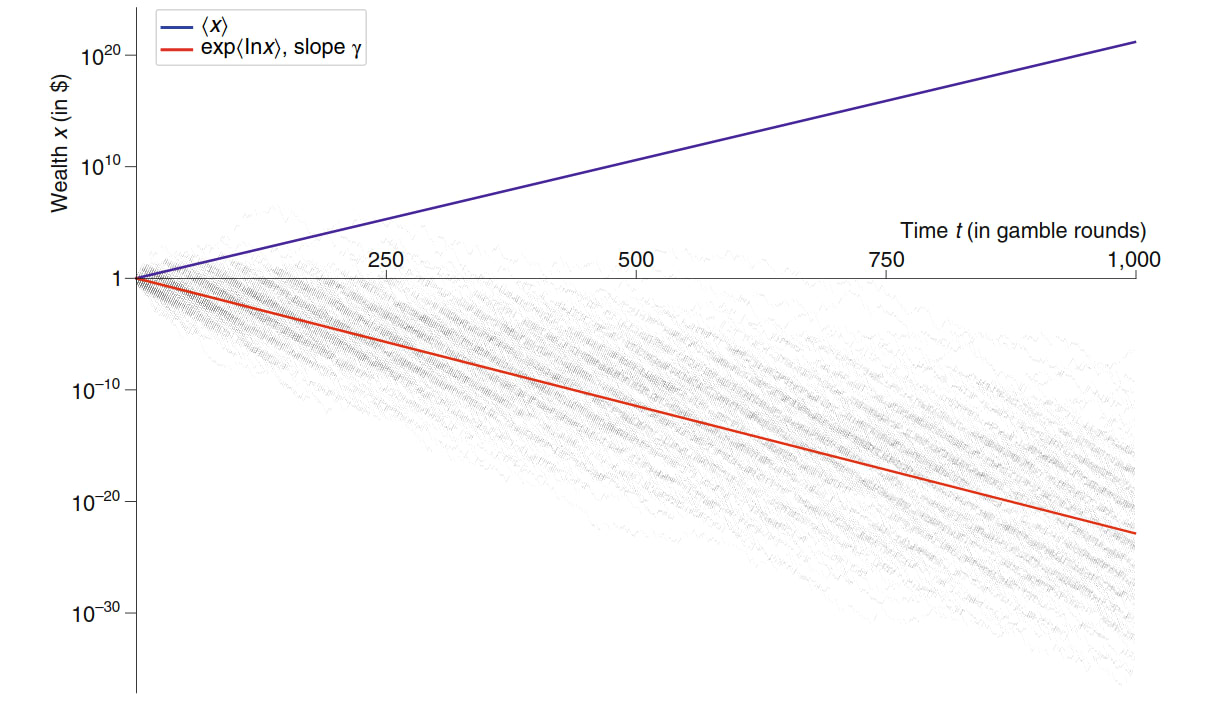
[I think there is a sense in which this is much more intuitive for gamblers than for investors. If your typical "investment opportunity" (read bet) goes to 0 some fraction of the time, investing all your "assets" (read bank roll) in it is obviously going to run a high risk of ruin after not very many trials.]
People need to account for this
In order to account for the fact that "variance is bad" people need to adjust their strategy. To take our example from earlier. That stock is fantastic! It returns 10% per day (on average). There must be some way to buy it and make money? The answer is yes. Don't invest all of your money in it. If you invest 10%. After one day you will either have or . This is winning proposition (even long term) since
Kelly is (a) way to account for this.
Utilities and repeated bets are two sides of the same coin
I think this is fairly clear - "The time interpretation of expected utility theory" (Peters, Adamou) prove this. I don't want to say too much more about this. This section is mostly to acknowledge that:
- Yes, Kelly is maximising log utility
- No, it doesn't matter which way you think about this
- Yes, I do think thinking in the repeated bets framework is more useful
People focus too much on the "Utility" formulation and not enough on the "repeated nature"
This is my personal opinion (and that of the Ergodicity Economics crowd). Both of the recent threads talk at length about the formula for Kelly for one bet. There seems to be little (if any) discussion of where the usefulness comes from. Kelly is useful when you can repeat and therefore compound your bets. Compounding is multiplicative, so it becomes "natural" (in some sense) to transform everything by taking logs.
People focus too much on the formula
Personally, I use Kelly more often for pencil-and-pap`er calculations and financial models than for making yes-or-no bets in the wild. For this purpose, far and away the most important form of Kelly to remember is "maximize expected log wealth". In particular, this is the form which generalizes beyond 2-outcome bets - e.g. it can handle allocating investments across a whole portfolio. It's also the form which most directly suggests how to derive the Kelly criterion, and therefore the situations in which it will/won't apply. - johnswentworth
I think this comment was spot on, and I don't really want to say too much more about it than that. The really magic takeaway (which I think is underappreciated) is. "maximise log your expected wealth". "Optimal Multiperiod Portfolio Policies" (Mossin) shows that for a wide class of utilities, optimising utility of wealth at time t is equivalent to maximising utility at each time-step.
BUT HANG ON! I hear you say. Haven't you just spent the last 5 paragraphs saying that Kelly is about repeated bets? If it all reduces to one period, why all the effort? The point is this: legible utilities need to handle the multi-period nature of the world. I have no (real) sense of what my utility function is, but I do know that I want my actions to be repeatable without risking ruin!
It's not about logarithmic utility (but really it is)
There is so much more which could be said about Kelly criterion for which this is really scratching the surface. Kelly has lots of nice properties (which are independent of utility functions) which I think are worth flagging:
- Maximises asymptotic long run growth
- Given a target wealth, is the strategy which achieves that wealth fastest
- Asymptotically outperforms any other strategy (ie E[X/X_{kelly}] <= 1)
- (Related to 3) "Competitive optimality". Any other strategy can only beat Kelly at most 1/2 the time. (1/2 is optimal since the other strategy could be Kelly)
Conclusion
- Zvi (Kelly Criterion)
What I am trying to do is shift the conversation away from discussion of the Kelly formula, which smells a bit like guessing the teacher's password to me, and get people to think more about how we should really think about and apply Kelly. The formula isn't the hard part. Logarithms aren't (that) important.
Under ordinary conditions, it's pretty safe to argue "such and such with probability 1, therefore, it's safe to pretend such-and-such". But this happens to be a case where doing so makes us greatly diverge from the Bayesian analysis -- ignoring the "most important" worlds from a pure expectation-maximization perspective (IE the ones where we repeatedly win bets, amassing huge sums).
So I'm very against sweeping that particular part of the reasoning under the rug. It's a reasonable argument, it's just one that imho should come equipped with big warning lights saying "NOTE: THIS IS A SEVERELY NON-BAYESIAN STEP IN THE REASONING. DO NOT CONFUSE THIS WITH EXPECTATION MAXIMIZATION."
Instead, you simply said:
which, to my eye, doesn't provide any warning to the reader. I just really think this kind of argument should be explicit about maximizing modal/median/any-fixed-quantile rather than the more common expectation maximization. Because people should be aware if one of their ideas about rational agency is based on mode/median/quantile maximization rather than expectation maximization.