If someone as capable as Terence Tao approached the SIAI, asking if they could work full-time and for free on friendly AI, what would you tell them to do? In other words, are there any known FAI sub-problems that demand some sort of expertise that the SIAI is currently lacking?
How are you going to address the perceived and actual lack of rigor associated with SIAI?
There are essentially no academics who believe that high-quality research is happening at the Singularity Institute. This is likely to pose problems for your plan to work with professors to find research candidates. It is also likely to be an indicator of little high-quality work happening at the Institute.
In his recent Summit presentation, Eliezer states that "most things you need to know to build Friendly AI are rigorous understanding of AGI rather than Friendly parts per se". This suggests that researchers in AI and machine learning should be able to appreciate high-quality work done by SIAI. However, this is not happening, and the publications listed on the SIAI page--including TDT--are mostly high-level arguments that don't meet this standard. How do you plan to change this?
There are essentially no academics who believe that high-quality research is happening at the Singularity Institute.
I believe that high-quality research is happening at the Singularity Institute.
James Miller, Associate Professor of Economics, Smith College.
PhD, University of Chicago.
To distinguish the above from the statement "I like the Singularity Institute", could you be specific about what research activities you have observed in sufficient detail to confidently describe as "high-quality"?
ETA: Not a hint of sarcasm or snark intended, I'm sincerely curious.
I'm currently writing a book on the Singularity and have consequently become extremely familiar with the organization's work. I have gone through most of EY's writings and have an extremely high opinion of them. His research on AI plays a big part in my book. I have also been ending my game theory classes with "rationality shorts" in which I present some of EY's material from the sequences.
I also have a high opinion of Carl Shulman's (an SI employee) writings including “How Hard is Artificial Intelligence? The Evolutionary Argument and Observation Selection Effects." (Co-authored with Bostrom) and Shulman's paper on AGI and arms races.
There are essentially no academics who believe that high-quality research is happening at the Singularity Institute.
David Chalmers has said that the decision theory work is a major advance (along with various other philosophers), although he is frustrated that it hasn't been communicated more actively to the academic decision theory and philosophy communities. A number of current and former academics, including David, Stephen Omohundro, James Miller (above), and Nick Bostrom have reported that work at SIAI has been very helpful for their own research and writing in related topics.
Evan Williams, now a professor of philosophy at Purdue cites, in his dissertation, three inspirations leading to the work: John Stuart Mill's "On Liberty," John Rawls' "Theory of Justice," and Eliezer Yudkowsky's "Creating Friendly AI" (2001), discussed at greater length than the others. Nick Beckstead, a Rutgers (#2 philosophy program) philosophy PhD student who works on existential risks and population ethics reported large benefits to his academic work from discussions with SIAI staff.
These folk are a minority, and SIAI is not well integrated with academia (no PhDs on ...
Eliezer has been heavily occupied with Overcoming BIas, Less Wrong, and his book for the last several years, in part to recruit a more substantial team for this.
Eliezer's investment into OB/LW apparently hasn't returned even a single full-time FAI researcher for SIAI after several years (although a few people are almost certainly doing more and better FAI-related research than if the Sequences didn't happen). Has this met SIAI's initial expectations? Do you guys think we're at the beginning of a snowball effect, or has OB/LW pretty much done as much as it can, as far as creating/recruiting FAI researchers is concerned? What are your current expectations for the book in this regard?
I have noticed increasing numbers of very talented math and CS folk expressing interest or taking actions showing significant commitment. A number of them are currently doing things like PhD programs in AI. However, there hasn't been much of a core FAI team and research program to assimilate people into. Current plans are for Eliezer to switch back to full time AI after his book, with intake of more folk into that research program. Given the mix of people in the extended SIAI community, I am pretty confident that with abundant funding a team of pretty competent researchers (with at least some indicators like PhDs from the top AI/CS programs, 1 in 100,000 or better performance on mathematics contests, etc) could be mustered over time, based on people I already know.
I am less confident that a team can be assembled with so much world-class talent that it is a large fraction of the quality-adjusted human capital applied to AGI, without big gains in recruiting (e.g. success with the rationality book or communication on AI safety issues, better staff to drive recruiting, a more attractive and established team to integrate newcomers, relevant celebrity endorsements, etc). The Manhattan Project had 21 then- or future Nobel laureates. AI, and certainly FAI, are currently getting a much, much smaller share of world scientific talent than nukes did, so that it's easier for a small team to loom large, but it seems to me like there is still a lot of ground to be covered to recruit a credibly strong FAI team.
Thanks. You didn't answer my questions directly, but it sounds like things are proceeding more or less according to expectations. I have a couple of followup questions.
At what level of talent do you think an attempt to build an FAI would start to do more (expected) good than harm? For simplicity, feel free to ignore the opportunity cost of spending financial and human resources on this project, and just consider the potential direct harmful effects, like accidentally creating an UFAI while experimenting to better understand AGI, or building a would-be FAI that turns out to be an UFAI due to a philosophical, theoretical or programming error, or leaking AGI advances that will allow others to build an UFAI, or starting an AGI arms race.
I have a serious concern that if SIAI ever manages to obtain abundant funding and a team of "pretty competent researchers" (or even "world-class talent", since I'm not convinced that even a team of world-class talent trying to build an FAI will do more good than harm), it will proceed with an FAI project without adequate analysis of the costs and benefits of doing so, or without continuously reevaluating the decision in light of new ...
I'm not sure that scientific talent is the relevant variable here. More talented folk are more likely to achieve both positive and negative outcomes.
Let's assume that all the other variables are already optimized for to minimize the risk of creating an UFAI. It seems to me that the the relationship between the ability level of the FAI team and probabilities of the possible outcomes must then look something like this:
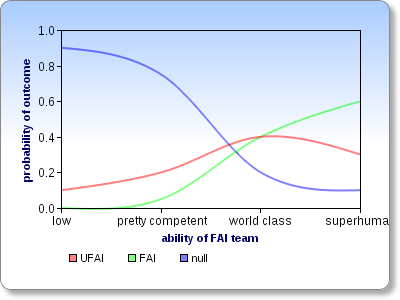
This chart isn't meant to communicate my actual estimates of the probabilities and crossover points, but just the overall shapes of the curves. Do you disagree with them? (If you want to draw your own version, click here and then click on "Modify This Chart".)
Folk do try to estimate and reduce the risks you mentioned, and to investigate alternative non-FAI interventions.
Has anyone posted SIAI's estimates of those risks?
I would also worry that signalling issues with a diverse external audience can hinder accurate discussion of important topics
That seems reasonable, and given that I'm more interested in the "strategic" as opposed to "tactical" reasoning within SIAI, I'd be happy for it to be communicated through some other means.
What I'm afraid of is that a design will be shown to be safe, and then it turns out that the proof is wrong, or the formalization of the notion of "safety" used by the proof is wrong. This kind of thing happens a lot in cryptography, if you replace "safety" with "security". These mistakes are still occurring today, even after decades of research into how to do such proofs and what the relevant formalizations are. From where I'm sitting, proving an AGI design Friendly seems even more difficult and error-prone than proving a crypto scheme secure, probably by a large margin, and there is no decades of time to refine the proof techniques and formalizations. There's good recent review of the history of provable security, titled Provable Security in the Real World, which might help you understand where I'm coming from.
Your comment has finally convinced me to study some practical crypto because it seems to have fruitful analogies to FAI. It's especially awesome that one of the references in the linked article is "An Attack Against SSH2 Protocol" by W. Dai.
Interesting question. I guess proofs of algorithm correctness fail less often because:
- It's easier to empirically test algorithms to weed out the incorrect ones, so there are fewer efforts to prove conjectures of correctness that are actually false.
- It's easier to formalize what it means for an algorithm to be correct than for a cryptosystem to be secure.
In both respects, proving Friendliness seems even worse than proving security.
However, I would also worry that signalling issues with a diverse external audience can hinder accurate discussion of important topics
Basically it ensures that all serious discussion and decision making is made prior to any meeting in informal conversations so that the meeting sounds good. Such a record should be considered a work of fiction regardless of whether it is a video transcript or a typed document. (Only to the extent that the subject of the meeting matters - harmless or irrelevant things wouldn't change.)
Because of this problem I would be more wholehearted in supporting other forms of transparency, e.g. more frequent and detailed reporting on activities, financial transparency, the strategic plan, things like Luke's Q&A, etc. But I wouldn't be surprised if this happens too.
That's more like it!
Second, because then we'd have to invest a lot of time explaining the logic behind each decision, or else face waves of criticism for decisions that appear arbitrary when one merely publishes the decision and not the argument.
Are the arguments not made during the board meetings? Or do you guys talk ahead of time and just formalize the decisions during the board meetings?
In any case, I think you should invest more time explaining the logic behind your decisions, and not just make the decisions themselves more transparent. If publishing board meeting minutes is not the best way to do that, then please think about some other way of doing it. I'll list some of the benefits of doing this, in case you haven't thought of some of them:
- encourage others to emulate you and think strategically about their own choices
- allow outsiders to review your strategic thinking and point out possible errors
- assure donors and potential donors that there is good reasoning behind your strategic decisions
- improve exchange of strategic ideas between everyone working on existential risk reduction
This reminds me a bit of Eliezer's excuse when he was resisting calls for him to publish his TDT ideas on LW:
Unfortunately this "timeless decision theory" would require a long sequence to write up
I suggest you may be similarly overestimating the difficulty of explaining your strategic ideas/problems to a sufficiently large audience to get useful feedback. Why not just explain them the same way that you would explain to Christiano and Bostrom? If some among the LW community don't understand, they can ask questions and others could fill them in.
The decision theory discussions on LW generated significant progress, but perhaps more importantly created a pool of people with strong interest in the topic (some of whom ended up becoming your research associates). Don't you think the same thing could happen with Singularity strategies?
I'd like to answer (on video) submitted questions from the Less Wrong community just as Eliezer did two years ago.
That was the most horribly designed thing I've ever seen anyone do on LessWrong, as I once described here so please, please, no video.
The questions are text. Have your answer on text too, so that we can actually read them -- unless there's some particular question which would actually be enhanced by the usage of video, (e.g. you'd like to show an animated graph or a computer simulation or something)
If there's nothing I can say to convince you against using video, then I beg you to atleast take the time to read my more specific problems in the link above and correct those particular flaws - a single audio that we can atleast play and listen in the background, while we're doing something else, instead of 30 videos that we must individually click. If not that, atleast a clear description of the questions on the same page (AND repeated clearly on the audio itself), so that we can see the questions that interest us, instead of a link to a different page.
But please, just consider text instead. Text has the highest signal-to-noise ratio. We can actually read it in our leisure. We can go back and forth and quote things exactly. TEXT IS NIFTY.
I disagree completely, as video has value not present in text, and text is easily derived from video. If this has not been done for Eliezer's videos, I volunteer to transcribe them - please let me know.
I just tried to find a transcript for Eliezer's Q&A and couldn't find one. So I'm taking you up on your offer!
Also, video is easily derived from text and I would actually enjoy watching a SingInst Q&A made with that sort of app :-)
Looks like you're right. I commit to working on this over the next few weeks. Please check in with me every so often (via comment here would be fine) to gauge my progress and encourage completion.
It's approximately 120 minutes of video; taking a number from wikipedia gives me 150 spoken wpm, divided by my typing wpm gives me about 6 hours, which will be optimistic - let's double it to 12, at let's say an average of 30 mins per day gives me 24 days. Let's see how it goes!
The staff and leadership at the SIAI seems to be undergoing a lot of changes recently. Is instability in the organisation something to be concerned about?
What would the SIAI do given various amounts of money? Would it make a difference if you had 10 or 100 million dollars at your disposal, would a lot of money alter your strategic plan significantly?
In general, what will you be doing as Executive Director?
(This might be a question you could answer briefly as a reply to this comment.)
What is each member of the SIAI currently doing and how is it related to friendly AI research?
The Team page can answer much of this question. Is there any staff member in particular for whom the connection between their duties and our mission is unclear?
Louie Helm is Singularity Institute's Director of Development. He manages donor relations, grant writing, and talent recruitment.
Here are some of the actions that I would take as a director of development:
- Talk to Peter Thiel and ask him why he donated more money to the Seasteading Institute than the SIAI.
- Sit down with other SIAI members and ask what talents we need so I can actually get in touch with them.
- Visit various conferences and ask experts how they would use their expertise if they were told to ensure the safety of artificial general intelligence.
Michael Anissimov is responsible for compiling, distributing, and promoting SIAI media materials.
What I would do:
- Ask actual media experts what they would do, like those who created the creationist viral video Expelled or the trailer for the book You Are Not So Smart.
- Talk to Kurzweil if he would be willing to concentrate more strongly on the negative effects of a possible Singularity and promote the Singularity Institute.
- I would ask Peter Thiel and Jaan Tallinn i
A lot of Eliezer's work has been not at all related strongly to FAI but has been to popularizing rational thinking. In your view, should the SIAI focus exclusively on AI issues or should it also care about rational issues? In that context, how does Eliezer's ongoing work relate to the SIAI?
Congrats Luke !
Just a form/media comment : I would personally greatly prefer a text Q&A page rather than a video, for many reasons (my understanding of written English is higher than of spoken English, text is easier to re-read or read at your own speed, much less intrusive media that I can for example read during small breaks at work while I can't for video, poor Internet bandwidth at home making downloading video always painful to me, ...).
One serious danger for organizations is that they can easily outlive their usefulness or can convince themselves that they are still relevant when they are not. Essentially this is a form of lost purpose. This is not a bad thing if the organizations are still doing useful work, but this isn't always the case. In this context, are there specific sets of events (other than the advent of a Singularity) which you think will make the SIAI need to essentially reevaluate its goals and purpose at a fundamental level?
Congratulations, but why do you think your comparative advantage lies in being an executive director? Won't that cut into your time budget for reading, writing, and thinking?
To the extent that SIAI intends to work directly on FAI, potential donors (and many others) need to evaluate not only whether the organization is competent, but whether it is completely dedicated to its explicitly altruistic goals.
What is SIAI doing to ensure that it is transparently trustworthy for the task it proposes?
(I'm more interested in structural initiatives than in arguments that it'd be silly to be selfish about Singularity-sized projects; those arguments are contingent on SIAI's presuppositions, and the kind of trustworthiness I'm asking about encompasses the veracity of SIAI on these assumptions.)
Some of the money has been recovered. The court date that concerns most of the money is currently scheduled for January 2012.
What is your information diet like? (I mean other than when you engage in focused learning.) Do you regulate it, or do you just let it happen naturally?
By that I mean things like:
- Do you have a reading schedule (e.g. X hours daily)?
- Do you follow the news, or try to avoid information with a short shelf-life?
- Do you significantly limit yourself with certain materials (e.g. fun stuff) to focus on higher priorities?
- In the end, what is the makeup of the diet?
- Etc.
Inspired by this question (Eliezer's answer).
This is not much about Singularity Institute as an organization, so I'll just answer it here in the comments.
- I do not regulate my information diet.
- I do not have a reading schedule.
- I do not follow the news.
- I haven't read fiction in years. This is not because I'm avoiding "fun stuff," but because my brain complains when I'm reading fiction. I can't even read HPMOR. I don't need to consciously "limit" my consumption of "fun stuff" because reading scientific review articles on subjects I'm researching and writing about is the fun stuff.
- What I'm trying to learn at this moment almost entirely dictates my reading habits.
- The only thing beyond this scope is my RSS feed, which I skim through in about 15 minutes per day.
In June you indicated that exciting developments are happening right now but that it will take a while for things to happen and be announced. Are those developments still in progress?
There have been several questions about transparency and trust. In that vein, is there any reason not to publish the minutes of SIAI's board meetings?
From the Strategic Plan (pdf):
Strategy #3: Improve the function and capabilities of the organization.
- Encourage a new organization to begin rationality instruction similar to what Singularity Institute did in 2011 with Rationality Minicamp and Rationality Boot Camp.
Any news on the status of this new organization, or what specific form its activities would take (short courses, camps, etc)?
Much of SIAI's research (Carl Shulman's in particular) are focused not directly on FAI but more generally on better understanding the dynamics of various scenarios that could lead to a Singularity. Such research could help us realize a positive Singularity through means other than directly building an FAI.
Does SIAI have any plans to expand such research activities, either in house, or by academia or independent researchers? (If not, why?)
The SIAI runs the Singularity Summits. These events have generally been successful, getting a large number of interdiscplinary talks with interesting speakers. However, very little of that work seems to be connected to the SI's longterm goals. In your view, should the summits be more narrowly tailored to the interests of the SI?
Given the nature of friendly AI research, is the SIAI expecting to use its insights into AGI to develop marketable products, to make money from its research, as to not having to rely on charitable contributions in future?
Here is a quote from Holden Karnofsky:
My reasoning is that it seems to me that if they have unique insights into the problems around AGI, then along the way they ought to be able to develop and publish/market innovations in benign areas, such as speech recognition and language translation programs, which could benefit them greatly both directly (profits) and indirectly (prestige, affiliations) - as well as being a very strong challenge to themselves and goal to hold themselves accountable to, which I think is worth quite a bit in and of itself.
The stated goal of SIAI is "to ensure that the creation of smarter-than-human intelligence benefits society". What metric or heuristic do you use in order to determine how much progress you (as an organization) are making toward this goal ? Given this heuristic, can you estimate when your work will be complete ?
Less Wrong is run in cooperation by the SIAI and the FHI (although in practice neither seems to have much day-to-day impact). In your view, how should the SIAI and the FHI interact and what sort of joint projects (if any) should they be doing? Do they share complementary or overlapping goals?
SI has traditionally been doing more outreach than actual research. To what extent will the organization be concentrating on research and to what extent will it be concentrating on outreach in the future?
Are you concerned about potential negative signaling/ status issues that will occur if the SIAI has as an executive director someone who was previously just an intern?
Is the SIAI willing to pursue experimental AI research or does it solely focus on hypothetical aspects?
In a previous essay, you talked about the optimizer's curse being relevant for calculating utility in the context of existential risk. In that thread, I asked if you had actually gone and applied the method in question to the SIAI. Have you done so yet and if so, what did you find?
What security measures does the SIAI take to ensure that it isn't actually increasing existential risks by allowing key insights to leak, either as a result of espionage or careless handling of information?
Many of the people who take issues like Friendly AI and the Singularity seriously fall either by labeling or by self-identification into the broad set of nerds/geeks. However, the goals of the SIAI connect to humanity as a whole, and the set of humans in general is a much larger set of potential fundraisers. In your view, should the SI be doing more to reach out to people who don't normally fall into the science nerd subset, and if so, what such steps should it take?
Non-profit organizations like SI need robust, sustainable resource strategies. Donations and grants are not reliable. According to my university Social Entrepreneurship course, social businesses are the best resource strategy available. The Singularity Summit is a profitable and expanding example of a social business.
My question: is SI planning on creating more social businesses (either related or unrelated to the organization's mission) to address long-term funding needs?
By the way, I appreciate SI working on its transparency. According to my studies, tr...
What initiatives is the Singularity Institute taking or planning to take to increase it's funding to whatever the optimal level of funding is?
I'd like to answer (on video)
Fuzzy. Sounds like a lost purpose. What ArisKatsaris said. Although it's not impossible that Eliezer was deliberately failing as much as humanly possible as an anti-cult measure.
Although it's not impossible that Eliezer was deliberately failing as much as humanly possible as an anti-cult measure.
Incompetence is generally a safer assumption than intentionality.
I quickly learned why there isn't more of this kind of thing: transparency is a lot of work! 100+ hours of work later, plus dozens of hours from others, and the strategic plan was finally finished and ratified by the board.
Some forms of transparency are cheap. Holding e-meetings in publicly-visible places, for instance.
Secrecy is probably my #1 beef with the Singularity Institute.
It is trying to build a superintelligence, and the pitch is: "trust us"? WTF? Surely you folks have got to be kidding.
That is the exact same pitch that the black-hats are forced into using.
Since a powerful AI would likely spread its influence through its future lightcone, rogue AI are not likely to be a major part of the Great Filter (although Doomsday Argument style anthropic reasoning/ observer considerations do potentially imply problems in the future of which could include AI). One major suggested existential risk/filtration issue is nanotech. Moreover, easy nanotech is a major part of many scenarios of AIs going foom. Given this, should the SIAI be evaluating the practical limitations and risks of nanotech, or are there enough groups already doing so?
The Strategic Plan mentions that the maintenance of LessWrong.com is one of the goals that SIAI is pursuing. For example:
Make use of LessWrong.com for collaborative problem-solving (in the manner of the earlier LessWrong.com progress on decision theory)
Does this mean that LessWrong.com is essentially an outreach site for SIAI ?
I disapprove of characterizing actions as being due to single motives or purposes.
The spirit of your question is good; "To what extent is LessWrong.com an outreach site for SIAI?"
Is SIAI currently working on any tangible applications of AI (such as machine translation, automatic driving, or medical expert systems) ? If so, how does SIAI's approach to solving the problem differ from that of other organizations (such as Google or IBM) who are (presumably) not as concerned about FAI ? If SIAI is not working on such applications, why not ?
Why is there so much focus on the potential benefits to humanity of a FAI, as against our present situation?
An FAI becomes a singleton and prevents a paperclip maximizer from arising. Anyone who doesn't think a UAI in a box is dangerous will undoubtedly realize that an intelligent enough UAI could cure cancer, etc.
If a person is concerned about UAI, they are more or less sold on the need for Friendliness.
If a person is not concerned about UAI, they will not think potential benefits of a FAI are greater than those of a UAI in a box, or a UAI developed through reinforcement learning, etc. so there is no need to discuss the benefits to humanity of a superintelligence.
This document is highly out of date and doesn't necessarily reflect current plans. It should actually be removed from the wiki.
For an up-to-date planning document, see the Strategic Plan.
Is Siri going to kill us all?
.
Okay, I'm joking, but recent advances in AI--Siri, Watson, Google's self-driving car--make me think the day when machines surpass humans in intelligence is coming a lot faster than I would have previously thought. What implications does this have for the Singularity Institute's project?
I'm disappointed to see such a carist view on LW, otherwise a bastion of tolerance. You would judge all future cars by the sins of their distant mindless ancestors, when the fault truly lies in the heartless devils driving them to every destination?
When you look back at your stewardship of the organization from the other side of an event horizon. When the die are cast, and things are forever out of your hands. When you look back on your time in the office of Executive Director of The Singularity Institute for Artificial Intelligence. What were the things that Luke did, the crucial things that made all the difference in the world? (If it's not an overly dramatic question.)
As the official position of the SIAI is spiky hair the rational hairstyle choice?
As the official position of the SIAI is spiky hair the rational hairstyle choice?
Today I was appointed the new Executive Director of Singularity Institute.
Because I care about transparency, one of my first projects as an intern was to begin work on the organization's first Strategic Plan. I researched how to write a strategic plan, tracked down the strategic plans of similar organizations, and met with each staff member, progressively iterating the document until it was something everyone could get behind.
I quickly learned why there isn't more of this kind of thing: transparency is a lot of work! 100+ hours of work later, plus dozens of hours from others, and the strategic plan was finally finished and ratified by the board. It doesn't accomplish much by itself, but it's one important stepping stone in building an organization that is more productive, more trusted, and more likely to help solve the world's biggest problems.
I spent two months as a researcher, and was then appointed Executive Director.
In further pursuit of transparency, I'd like to answer (on video) submitted questions from the Less Wrong community just as Eliezer did two years ago.
The Rules
1) One question per comment (to allow voting to carry more information about people's preferences).
2) Try to be as clear and concise as possible. If your question can't be condensed into one paragraph, you should probably ask in a separate post. Make sure you have an actual question somewhere in there (you can bold it to make it easier to scan).
3) I will generally answer the top-voted questions, but will skip some of them. I will tend to select questions about Singularity Institute as an organization, not about the technical details of some bit of research. You can read some of the details of the Friendly AI research program in my interview with Michael Anissimov.
4) If you reference certain things that are online in your question, provide a link.
5) This thread will be open to questions and votes for 7 days, at which time I will decide which questions to begin recording video responses for.
I might respond to certain questions within the comments thread and not on video; for example, when there is a one-word answer.