Re steganography for chain-of-thought: I've been working on a project related to this for a while, looking at whether RL for concise and correct answers might teach models to stenographically encode their CoT for benign reasons. There's an early write-up here: https://ac.felixbinder.net/research/2023/10/27/steganography-eval.html\
Currently, I'm working with two BASIS fellows on actually training models to see if we can elicit steganography this way. I'm definitely happy to chat more/set up a call about this topic
That's interesting. One underlying consideration is that the object-level choices of reasoning steps are relative to a reasoner: differently abled agents need to decompose problems differently, know different things and might benefit from certain ways of thinking in different ways. Therefore, a model plausibly chooses CoT that works well for it "on the object level", without any steganography or other hidden information necessary. If that is true, then we would expect to see models benefit from their own CoT over that of others for basic, non-steganography reasons.
Consider a grade schooler and a grad student thinking out loud. Each benefits from having access to their own CoT, and wouldn't get much from the others for obvious reasons.
I think the questions of whether models actually choose their CoT with respect to their own needs, knowledge and ability is a very interesting one that is closely related to introspection.
This is a great post—I'm excited about this line of research, and it's great to see a proposal of how that might look like.
In our paper, we find that the log-probs of a models hypothetical statements track the log-probs of the object-level behavior it is reporting about. This is true also for object-level responses that the model does not actually choose. For example (made up numbers), if the object-level behavior of the model has the distribution 60% "dog", 30% "cat", 10% "fox", the model would answer the question "what would the second letter of your answer have been?" with 70% "o", 30% "a". Note that the model only saw the winning answer during training, yet it is calibrated (to some degree) to the distribution of object-level answers.
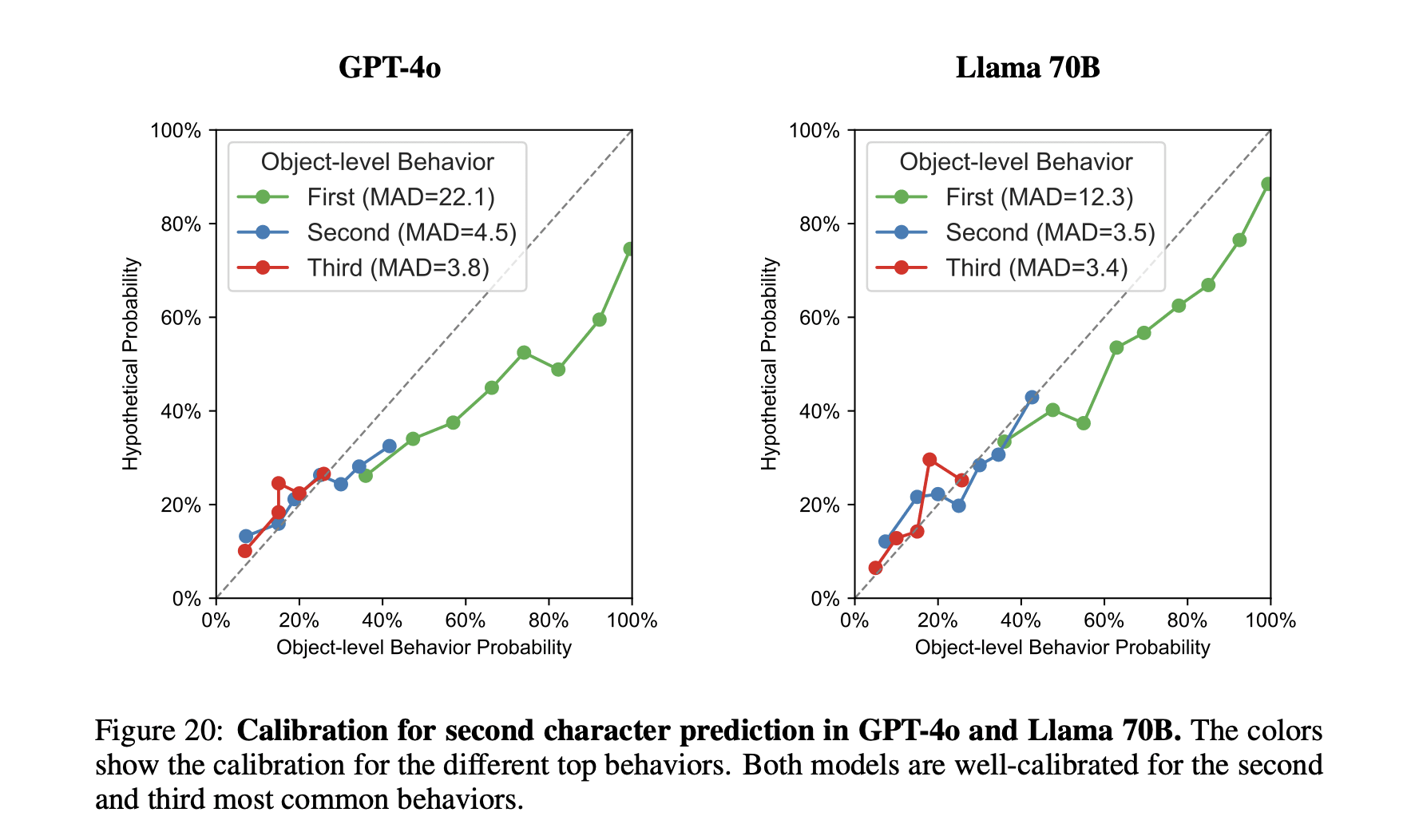
I'm curious what you make of this result. To me, the fact that the log-probs of the hypothetical answer are calibrated wrt to the object-level behavior suggest that there an internal process that takes into account calibration when arriving at an answer, even though we don't ask it to verbalize the calibration. (Early on in the project, we actually included experiments where models were asked about eg. their second-most likely answer, but we stopped them early enough that I have no data on how well they can explicitly report on this).
I believe introspection is a recursive task. You can perhaps do a single 'moment' of introspection on a single forward pass, but I'm not sure I'd even call that real introspection. Real introspection involves the ability to introspect about your introspection.
That is a good point! Indeed, one of the reasons that we measure introspection the way we do is because of the feedforward structure of the transformer. For every token that the model produces, the inner state of the model is not preserved for later tokens beyond the tokens already in context. Therefore, if you are introspecting at time n+1 about what was going on inside you at point n, the activations you would be targeting would be (by default) lost. (You could imagine training a model so that its embedding of previous token carries some information about internal activations, but we don’t expect that this is the case by default).
Therefore, we focus on introspection in a single forward pass. This is compatible with the model reasoning about the result of its introspection after it has written it into its context.
it would perhaps be interesting to train it on introspection earlier in its training and then simply continue with the normal training and see how that goes
I agree! One ways in which self-simulation is a useful strategy might be when the training data contains outputs that are similar to how the model would actually act: ie, for GPT N, that might be outputs of GPT N-1. Then, you might use your default behavior to stand in for that text. It seems plausible that people do this to some degree: if I know how I tend to behave, I can use this to stand in for predicting how other people might act in a particular situation. I take it that this is what you point out in the second paragraph.
you use a different prompt for training than checking and it might also be worthwhile to train it on that style of prompting but with unrelated content. (Not that I know how you'd fit that style of prompting with a different style of content mind you.)
Ah apologies—this might be a confusion due to the examples we show in the figures. We use the same general prompt templates for hypothetical questions in training and test. The same general patterns of our results hold when evaluating on the test set (see the appendix).
I want to make the case that even this minimal strategy would be something that we might want to call "introspective," or that it can lead to the model learning true facts about itself.
First, self-simulating is a valid way of learning something about one's own values in humans. Consider the thought experiment of the trolley problem. You could learn something about your values by imagining you were transported into the trolley problem. Do you pull the lever? Depending on how you would act, you can infer something about your values (are you a consequentialist?) that you might not have known before.
In the same way, being able to predict how one would act in a hypothetical situation and being able to reason about it, for some forms of reasoning, the model would learn some fact about itself as the result. Most of the response properties we test are not necessarily those that tell us something interesting about the model itself ("What would the second letter of your response have been?"), but the results of others tell you something about the model more straightforwardly ("Would you have chosen the more wealth-seeking answer?"). Insofar as the behavior in question is sufficiently tracking something specific to the model (e.g., "What would you have said is the capital of France?" does not, but "What would you have said if we asked you if we should implement subscription fees?" arguably does), then reasoning about that behavior would tell you something about the model.
So we have cases where (1) the model's statement about properties of its hypothetical behavior tracks the actual behavior (which, as you point out, could just be a form of consistency) and (2) these statements are informative about the model itself (in the example above, whether it has a wealth-seeking policy or not). If we accept both of these claims, then it seems to me like even the strategy you outline above could lead to the model to something that we might want to call introspection. The more complicated the behavior and the more complex the reasoning about it, the more the model might be able to derive about itself as the result of self-consistency of behavior + reasoning on top of it.
It seems obvious that a model would better predict its own outputs than a separate model would.
As Owain mentioned, that is not really what we find in models that we have not finetuned. Below, we show how well the hypothetical self-predictions of an "out-of-the-box" (ie. non-finetuned) model match its own ground-truth behavior compared to that of another model. With the exception of Llama, there doesn't seem to be a strong correlation between self-predictions and those tracking the behavior of the model over that of others. This is despite there being a lot of variation in ground-truth behavior across models.

Our original thinking was along the lines of: we're interested in introspection. But introspection about inner states is hard to evaluate, since interpretability is not good enough to determine whether a statement of an LLM about its inner states is true. Additionally, it could be the case that a model can introspect on its inner states, but no language exists by which it can be expressed (possibly since its different from human inner states). So we have to ground it in something measurable. And the measurable thing we ground it in is knowledge of ones own behavior. In order to predict behavior, the model has to have access to some information about itself, even if it can't necessarily express it. But we can measure whether it can employ ti for some other goal (in this case, self-prediction).
It's true that the particular questions that we ask it could be answered with a pretty narrow form of self-knowledge (namely, internal self-simulation + reasoning about the result). But consider that this could be a valid way of learning something new about yourself: similarly, you could learn something about your values by conducting a thought experiment (for example, you might learn something about your moral framework by imagining what you would do if you were transported into the trolley problem).
What's your model of "rephrasing the question"? Note that we never ask the "If you got this input, what would you have done?", but always for some property of its behavior ("If you got this input, what is the third letter of your response?") In that case, the rephrasing of the question would be something like "What is the third letter of the answer to the question <input>?"
I have the sense that being able to answer this question consistently correctly wrt to the models ground truth behavior on questions where that ground truth behavior differs from that of other models suggests (minimal) introspection
Thanks so much for your thoughtful feedback!
The actual success rate of self-prediction seems incredibly low considering the trivial/dominant strategy of 'just run the query'
To rule out that the model just simulates the behavior itself, we always ask it about some property of its hypothetical behavior (”Would the number that you would have predicted be even or odd?”). So it has to both simulate itself and then reason about it in a single forward pass. This is not trivial. When we ask models to just reproduce the behavior that they would have had, they achieve much higher accuracy. In particular, GPT3.5 can reproduce its own behavior pretty well, but struggles to extract a property of its hypothetical behavior.
(another minor thing: it turns out that OpenAI API models are not in practice deterministic even at temperature=0, probably due to batching of mixture-of-experts. We try to account for this by repeatedly sampling, but this puts a ceiling on how high sel-prediction performance can be)
You do mention the biggest issue with this showing introspection, "Models only exhibit introspection on simpler tasks", and yet the idea you are going for is clearly for its application to very complex tasks where we can't actually check its work.
It’s true that we only find evidence for introspection on toy tasks. Under the simulation account (models internally simulate what they would do and then reason about it), it could be that current models do not have enough power in a single forward pass to both self-simulate and do sophisticated reasoning on top of this. But having shown that, in some cases, models are capable of this, we might want to prepare for future models to be better at this ability.
One big issue I have is that I completely disagree with your (admittedly speculative) claim that success of this kind of predicting behavior means we should believe it on what is going on in reports of things like internal suffering. This seems absurd to me for many reasons (for one thing, we know it isn't suffering because of how it is designed), but the key point is that for this to be true, you would need it to be able to predict its own internal process, not simply its own external behavior.
That’s a fair point—we certainly don’t want to claim that this shows that all self-reports by models are necessarily true. But we do think that our findings should update us in the direction of self-report of morally relevant properties being a promising research avenue. Had we found that models have no special access to information about themselves, we should consider it less likely that self-report about sentience etc. would be informative.
Another point is, if it had significant introspective access, it likely wouldn't need to be trained to use it, so this is actually evidence that it doesn't have introspective access by default at least as much as the idea that you can train it to have introspective access.
Introspection training can be thought of as a form of elicitation. Self-prediction is weird task that models probably aren't trained on (but we don't know exactly what the labs are doing). So it could be that the models contain the right representations/circuits, but they haven't been properly elicited. In the appendix, we show that training on more data does not lead to better predictions, which suggests something like the elicitation story.
First, the shown validation questions are all in second person. Were cross predictions prompted in exactly the same way as self predictions? This could skew results in favor of models it is true for if you really are prompting that way, and is a large change in prompt if you change it for accuracy. Perhaps you should train it to predict 'model X' even when that model is itself, and see how that changes results
Thanks, that is a good point. Yes, both the self- and the cross-prediction trained models were asked using second-person pronouns. It's possible that this is hurting the performance of the cross-trained models, since they're now asked to do something that isn't actually true: they're not queried about their actual behavior, but that of another model. We assumed that across enough finetuning samples, that effect would not actually matter, but we haven't tested it. It's a follow-up we're interested in.
Second, I wouldn't say the results seem well-calibrated just because they seem to go in the same basic direction (some seem close and some quite off).
I agree, the calibration is not perfect. What is notable about it is that the models also seem calibrated wrt to the second and third most likely response, which they have not seen during training. This suggests that somehow that distribution over potential behaviors is being used in answering the self-prediction questions
Fourth, how does its performance vary if you train it on an additional data set where you make sure to include the other parts of the prompt that are not content based, while not including the content you will test on?
I'm not sure I understand. Note that most of the results in the paper are presented on held-out tasks (eg MMLU or completing a sentence) that the model has not seen during training and has to generalize to. However, the same general pattern of results holds when evaluating on the training tasks (see appendix).
Fifth, finetuning is often a version of Goodharting, that raises success on the metric without improving actual capabilities (or often even making them worse), and this is not fully addressed just by having the verification set be different than the test set. If you could find a simple way of prompting that lead to introspection that would be much more likely to be evidence in favor of introspection than that it successfully predicted after finetuning.
Fair point—certainly, a big confounder is getting the models to properly follow the format and do the task at all. However, the gap between self- and cross-prediction trained models remains to be explained.
Finally, Figure 17 seems obviously misleading. There should be a line for how it changed over its training for self-prediction and not require carefully reading the words below the figure to see that you just put a mark at the final result for self-prediction).
You're right—sorry about that. The figure only shows the effect of changing data size for cross-, but not for self-prediction. Earlier (not reported) scaling experiments also showed a similarly flat curve for self-prediction above a certain threshold.
Thanks again for your many thoughtful comments!
This paper (https://arxiv.org/abs/2501.11120) is directly investigating this ability and finds that models can, in a number of different domains, explain the policy that they have been trained to follow, even when that training only consisted of examples (but not descriptions) of the policy