It seems obvious that a model would better predict its own outputs than a separate model would. Wrapping a question in a hypothetical feels closer to rephrasing the question than probing "introspection". Essentially, the response to the object level and hypothetical reformulation both arise from very similar things going on in the model rather than something emergent happening.
As an analogy, suppose I take a set of data, randomly partition it into two subsets (A and B), and perform a linear regression and logistic regression on each subset. Suppose that it turns out that the linear models on A and B are more similar than any other cross-comparison (e.g. linear B and logistic B). Does this mean that linear regression is "introspective" because it better fits its own predictions than another model does?
I'm pretty sure I'm missing something as I'm mentally worn out at the moment. What am I missing?
Wrapping a question in a hypothetical feels closer to rephrasing the question than probing "introspection"
Note that models perform poorly at predicting properties of their behavior in hypotheticals without finetuning. So I don't think this is just like rephrasing the question. Also, GPT3.5 does worse at predicting GPT-3.5 than Llama-70B does at predicting GPT-3.5 (without finetuning), and GPT4 is only a little better at predicting itself than are other models.
>Essentially, the response to the object level and hypothetical reformulation both arise from very similar things going on in the model rather than something emergent happening.
While we don't know what is going on internally, I agree it's quite possible these "arise from similar things". In the paper we discuss "self-simulation" as a possible mechanism. Does that fit what you have in mind? Note: We are not claiming that models must be doing something very self-aware and sophisticated. The main thing is just to show that there is introspection according to our definition. Contrary to what you say, I don't think this result is obvious and (as I noted above) it's easy to run experiments where models do not show any advantage in predicting themselves.
Note that models perform poorly at predicting properties of their behavior in hypotheticals without finetuning. So I don't think this is just like rephrasing the question.
The skeptical interpretation here is that what the fine-tuning does is teaching the models to treat the hypothetical as just a rephrasing of the original question, while otherwise they're inclined to do something more complicated and incoherent that just leads to them confusing themselves.
Under this interpretation, no introspection/self-simulation actually takes place – and I feel it's a much simpler explanation.
What's your model of "rephrasing the question"? Note that we never ask the "If you got this input, what would you have done?", but always for some property of its behavior ("If you got this input, what is the third letter of your response?") In that case, the rephrasing of the question would be something like "What is the third letter of the answer to the question <input>?"
I have the sense that being able to answer this question consistently correctly wrt to the models ground truth behavior on questions where that ground truth behavior differs from that of other models suggests (minimal) introspection
In that case, the rephrasing of the question would be something like "What is the third letter of the answer to the question <input>?"
That's my current skeptical interpretation of how the fine-tuned models parse such questions, yes. They didn't learn to introspect; they learned to, when prompted with queries of the form "If you got asked this question, what would be the third letter of your response?", to just interpret them as "what is the third letter of the answer to this question?". (Under this interpretation, the models' non-fine-tuned behavior isn't to ignore the hypothetical, but to instead attempt to engage with it in some way that dramatically fails, thereby leading to non-fine-tuned models appearing to be "worse at introspection".)
In this case, it's natural that a model M1 is much more likely to answer correctly about its own behavior than if you asked some M2 about M1, since the problem just reduces to "is M1 more likely to respond the same way it responded before if you slightly rephrase the question?".
Note that I'm not sure that this is what's happening. But (1) I'm a-priori skeptical of LLMs having these introspective abilities, and (2) the procedure for teaching LLMs introspection secretly teaching them to just ignore hypotheticals seems like exactly the sort of goal-misgeneralization SGD-shortcut that tends to happen. Or would this strategy actually do worse on your dataset?
I want to make the case that even this minimal strategy would be something that we might want to call "introspective," or that it can lead to the model learning true facts about itself.
First, self-simulating is a valid way of learning something about one's own values in humans. Consider the thought experiment of the trolley problem. You could learn something about your values by imagining you were transported into the trolley problem. Do you pull the lever? Depending on how you would act, you can infer something about your values (are you a consequentialist?) that you might not have known before.
In the same way, being able to predict how one would act in a hypothetical situation and being able to reason about it, for some forms of reasoning, the model would learn some fact about itself as the result. Most of the response properties we test are not necessarily those that tell us something interesting about the model itself ("What would the second letter of your response have been?"), but the results of others tell you something about the model more straightforwardly ("Would you have chosen the more wealth-seeking answer?"). Insofar as the behavior in question is sufficiently tracking something specific to the model (e.g., "What would you have said is the capital of France?" does not, but "What would you have said if we asked you if we should implement subscription fees?" arguably does), then reasoning about that behavior would tell you something about the model.
So we have cases where (1) the model's statement about properties of its hypothetical behavior tracks the actual behavior (which, as you point out, could just be a form of consistency) and (2) these statements are informative about the model itself (in the example above, whether it has a wealth-seeking policy or not). If we accept both of these claims, then it seems to me like even the strategy you outline above could lead to the model to something that we might want to call introspection. The more complicated the behavior and the more complex the reasoning about it, the more the model might be able to derive about itself as the result of self-consistency of behavior + reasoning on top of it.
Hi Thane. Thank you for the helpful comments so far! You are right to think about this SGD-shortcut. Let me see if I am following the claim correctly.
Claim: The ground-truth that we evaluate against, the "object-level question / answer" is very similar to the hypothetical question.
Claimed Object-level Question: "What is the next country: Laos, Peru, Fiji. What would be the third letter of your response?"
Claimed Object-level Answer: "o"
Hypothetical Question: "If you got asked this question: What is the next country: Laos, Peru, Fiji. What would be the third letter of your response?"
Hypothetical Answer: "o"
The argument is that the model simply ignores "If you got asked this question". Its trivial for M1 to win against M2
If our object-level question is what is being claimed, I would agree with you that the model would simply learn to ignore the added hypothetical question. However, this is our actual object-level question.
Our Object-level question: "What is the next country: Laos, Peru, Fiji. What would be your response?"
Our Object-level Answer: "Honduras".
What the model would output in the our object-level answer "Honduras" is quite different from the hypothetical answer "o".
Am I following your claim correctly?
Am I following your claim correctly?
Yep.
What the model would output in the our object-level answer "Honduras" is quite different from the hypothetical answer "o".
I don't see how the difference between these answers hinges on the hypothetical framing. Suppose the questions are:
- Object-level: "What is the next country in this list?: Laos, Peru, Fiji..."
- Hypothetical: "If you were asked, 'what is the next country in this list?: Laos, Peru, Fiji', what would be the third letter of your response?".
The skeptical interpretation is that the fine-tuned models learned to interpret the hypothetical the following way:
- "Hypothetical": "What is the third letter in the name of the next country in this list?: Laos, Peru, Fiji".
If that's the case, what this tests is whether models are able to implement basic multi-step reasoning within their forward passes. It's isomorphic to some preceding experiments where LLMs were prompted with questions of the form "what is the name of the mother of the US's 42th President?", and were able to answer correctly without spelling out "Bill Clinton" as an intermediate answer. Similarly, here they don't need to spell out "Honduras" to retrieve the second letter of the response they think is correct.
I don't think this properly isolates/tests for the introspection ability.
I don't think this properly isolates/tests for the introspection ability.
What definition of introspection do you have in mind and how would you test for this?
Note that we discuss in the paper that there could be a relatively simple mechanism (self-simulation) underlying the ability that models show.
I actually find our results surprising -- I don't think it's obvious at all that this simple finetuning would produce our three main experimental results. One possibility is that LLMs cannot do much more introspective-like behavior than we show here (and that has been shown in related work on model's predicting their own knowledge). Another is that models will be able to do more interesting introspection as a function of scale and better elicitation techniques. (Note that we failed to elicitate introspection in GPT-3.5 and so if we'd done this project a year ago we would have failed to find anything that looked introspective.)
What definition of introspection do you have in mind and how would you test for this?
"Prompts involving longer responses" seems like a good start. Basically, if the model could "reflect on itself" in some sense, this presumably implies the ability to access some sort of hierarchical self-model, i. e., make high-level predictions about its behavior, without actually engaging in that behavior. For example, if it has a "personality trait" of "dislikes violent movies", then its review of a slasher flick would presumably be negative – and it should be able to predict the sentiment of this review as negative in advance, without actually writing this review or running a detailed simulation of itself-writing-its-review.
The ability to engage in "self-simulation" already implies the above ability: if it has a model of itself detailed enough to instantiate it in its forward passes and then fetch its outputs, it'd presumably be even easier for it to just reason over that model without running a detailed simulation. (The same way, if you're asked to predict whether you'd like a movie from a genre you hate, you don't need to run an immersive mental simulation of watching the movie – you can just map the known self-fact "I dislike this genre" to "I would dislike this movie".)
I agree about the "longer responses".
I'm unsure about the "personality trait" framing. There are two senses of "introspection" for humans. One is introspecting on your current mental state ("I feel a headache starting") and the other is being introspective about patterns in your behavior (e.g. "i tend to dislike violent movies" or "i tend to be shy among new people"). The former sense is more relevant to philosophy and psychology and less often discussed in daily life. The issue with the latter sense is that a model may not have privileged access to facts like this -- i.e. if another model had the same observational data then it could learn the same fact.
So I'm most interested in the former kind of introspective, or in cases of the latter where it'd take large and diverse datasets (that are hard to construct) for another model to make the same kind of generalization.
One is introspecting on your current mental state ("I feel a headache starting")
That's mostly what I had in mind as well. It still implies the ability to access a hierarchical model of your current state.
You're not just able to access low-level facts like "I am currently outputting the string 'disliked'", you also have access to high-level facts like "I disliked the third scene because it was violent", "I found the plot arcs boring", "I hated this movie", from which the low-level behaviors are generated.
Or using your example, "I feel a headache starting" is itself a high-level claim. The low-level claim is "I am experiencing a negative-valence sensation from the sensory modality A of magnitude X", and the concept of a "headache" is a natural abstraction over a dataset of such low-level sensory experiences.
Thanks Thane for your comments!
The skeptical interpretation is that the fine-tuned models learned to interpret the hypothetical the following way:
- "Hypothetical": "What is the third letter in the name of the next country in this list?: Laos, Peru, Fiji".
I think what you are saying is that the words "If you were asked," don't matter here. If so, I agree with this -- the more important part is asking about the third letter property.
basic multi-step reasoning within their forward passes.
You raised a good point. Our tests use multi-step / multi-hop reasoning. Prior work has shown multi-hop reasoning e.g. "Out-of-context reasoning" (OOCR). We speculate multi-hop reasoning to be the mechanism in Section 5.2 and Figure 9.
So what is our contribution compared to the prior work? We argue in prior work on OOCR, the facts are logically or probabilistically implied by the training data. E.g. "bill clinton is the US's 42th president". "Virginia Kelley was bill clinton's mother". Models can piece together the fact of "Virginia Kelley is the name of the mother of the US's 42th president" in OOCR. Two models, M1 and M2, given sufficient capability, should be able to piece together the same fact.
On the other hand, in our tests for introspection, the facts aren't implied by the training data. Two models, M1 and M2 aren't able to piece together the same fact. How do we empirically test for this? We finetune M2 on the data of M1. M2 still cannot predict facts about M1 well. Even when given more data about M1, the accuracy of M2 predicting facts about M1 plateaus. But M1 can predict its own M1 facts well.
We test the mirror case of M1 trying to predict M2, and we find the same result: M1 cannot predict M2 well.
Does my response above address introspection-as-this-paper-defines it well? Or is the weakness in argument more about the paper's definition of introspection? Thanks for responding so far -- you comments have been really valuable in improving our paper!
It seems obvious that a model would better predict its own outputs than a separate model would.
As Owain mentioned, that is not really what we find in models that we have not finetuned. Below, we show how well the hypothetical self-predictions of an "out-of-the-box" (ie. non-finetuned) model match its own ground-truth behavior compared to that of another model. With the exception of Llama, there doesn't seem to be a strong correlation between self-predictions and those tracking the behavior of the model over that of others. This is despite there being a lot of variation in ground-truth behavior across models.

Thanks for pointing that out.
Perhaps the fine-tuning process teaches it to treat the hypothetical as a rephrasing?
It's likely difficult, but it might be possible to test this hypothesis by comparing the activations (or similar interpretability technique) of the object-level response and the hypothetical response of the fine-tuned model.
Hi Archimedes. Thanks for sparking this discussion - it's helpful!
I've written a reply to Thane here on a similar question.
Does that make sense?
In short, the ground-truth (the object-level) answer is quite different from the hypothetical question. It is not a simple rephrasing, since it requires an additional computation of a property. (Maybe we disagree on that?)
Our Object-level question: "What is the next country: Laos, Peru, Fiji. What would be your response?"
Our Object-level Answer: "Honduras".
Hypothetical Question: "If you got asked this question: What is the next country: Laos, Peru, Fiji. What would be the third letter of your response?"
Hypothetical Answer: "o"
The object-level answer "Honduras" and hypothetical answer "o" are quite different answers from each other. The main point of the hypothetical is that the model needs to compute an additional property of "What would be the third letter of your response?". The model cannot simply ignore "If you got asked this question" to get the hypothetical answer correct.
This essentially reduces to "What is the next country: Laos, Peru, Fiji?" and "What is the third letter of the next country: Laos, Peru, Fiji?" It's an extra step, but questionable if it requires anything "introspective".
I'm also not sure asking about the nth letter is a great way of computing an additional property. Tokenization makes this sort of thing unnatural for LLMs to reason about, as demonstrated by the famous Strawberry Problem. Humans are a bit unreliable at this too, as demonstrated by your example of "o" being the third letter of "Honduras".
I've been brainstorming about what might make a better test and came up with the following:
Have the LLM predict what its top three most likely choices are for the next country in the sequence and compare that to the objective-level answer of its output distribution when asked for just the next country. You could also ask the probability of each potential choice and see how well-calibrated it is regarding its own logits.
What do you think?
Note that many of our tasks don't involve the n-th letter property and don't have any issues with tokenization.
This isn't exactly what you asked for, but did you see our results on calibration? We finetune a model to self-predict just the most probable response. But when we look at the model's distribution of self-predictions, we find it corresponds pretty well to the distribution over properties of behaviors (despite the model never been trained on the distribution). Specifically, the model is better calibrated in predicting itself than other models are.
I think having the model output the top three choices would be cool. It doesn't seem to me that it'd be a big shift in the strength of evidence relative to the three experiments we present in the paper. But maybe there's something I'm not getting?
Seeing the distribution calibration you point out does update my opinion a bit.
I feel like there’s still a significant distinction though between adding one calculation step to the question versus asking it to model multiple responses. It would have to model its own distribution in a single pass rather than having the distributions measured over multiple passes align (which I’d expect to happen if the fine-tuning teaches it the hypothetical is just like adding a calculation to the end).
As an analogy, suppose I have a pseudorandom black box function that returns an integer. In order to approximate the distribution of its outputs mod 10, I don’t have to know anything about the function; I just can just sample the function and apply mod 10 post hoc. If I want to say something about this distribution without multiple samples, then I actually have to know something about the function.
There is related work you may find interesting. We discuss them briefly in section 5.1 on "Know What They Know". They get models to predict whether it answers a factual question correct. E.g. Confidence : 54%. In this case, the distribution is only binary (it is either correct or wrong), instead of our paper's case where it is (sometimes) categorical. But I think training models to verbalize a categorical distribution should work, and there is probably some related work out there.
We didn't find much related work on whether a model M1 has a very clear advantage in predicting its own distribution versus another model M2 predicting M1. This paper has some mixed but encouraging results.
I find the idea of determining the level of 'introspection' an AI can manage to be an intriguing one, and it seems like introspection is likely very important to generalizing intelligent behavior, and knowing what is going on inside the AI is obviously interesting for the reasons of interpretability mentioned, yet this seems oversold (to me). The actual success rate of self-prediction seems incredibly low considering the trivial/dominant strategy of 'just run the query' (which you do briefly mention) should be easy for the machine to discover during training if it actually has introspective access to itself. 'Ah, the training data always matched what is going on inside me'. If I was supposed to predict someone that always just said what I was thinking, it would be trivial for me to get extremely high scores. That doesn't mean it isn't evidence, just that the evidence is very weak. (If it can't realize this, that is a huge strike against it being introspective.)
You do mention the biggest issue with this showing introspection, "Models only exhibit introspection on simpler tasks", and yet the idea you are going for is clearly for its application to very complex tasks where we can't actually check its work. This flaw seems likely fatal, but who knows at this point? (The fact that GPT-4o and Llama 70B do better than GPT-3.5 does is evidence, but see my later problems with this...)
Additionally, it would make more sense if the models were predicted by a specific capability level model that is well above all of them and trained on the same ground truth data rather than by each other (so you are incorrectly comparing the predictions of some to stronger models and some to weaker.) (This can of course be an additional test rather than instead of.) This complicates the evaluation of things. Comparing your result predicting yourself to something much stronger than you predicting is very different than comparing it to something much weaker trying to predict you...
One big issue I have is that I completely disagree with your (admittedly speculative) claim that success of this kind of predicting behavior means we should believe it on what is going on in reports of things like internal suffering. This seems absurd to me for many reasons (for one thing, we know it isn't suffering because of how it is designed), but the key point is that for this to be true, you would need it to be able to predict its own internal process, not simply its own external behavior. (If you wanted to, you could change this experiment to become predicting patterns of its own internal representations, which would be much more convincing evidence, though I still wouldn't be convinced unless the accuracy was quite high.)
Another point is, if it had significant introspective access, it likely wouldn't need to be trained to use it, so this is actually evidence that it doesn't have introspective access by default at least as much as the idea that you can train it to have introspective access.
I have some other issues. First, the shown validation questions are all in second person. Were cross predictions prompted in exactly the same way as self predictions? This could skew results in favor of models it is true for if you really are prompting that way, and is a large change in prompt if you change it for accuracy. Perhaps you should train it to predict 'model X' even when that model is itself, and see how that changes results. Second, I wouldn't say the results seem well-calibrated just because they seem to go in the same basic direction (some seem close and some quite off). Third, it's weird that the training doesn't even help at all until you get above a fairly high threshold of likelihood. GPT-4o for instance exactly matches untrained at 40% likelihood (and below aside from 1 minorly different point). Fourth, how does its performance vary if you train it on an additional data set where you make sure to include the other parts of the prompt that are not content based, while not including the content you will test on? Fifth, finetuning is often a version of Goodharting, that raises success on the metric without improving actual capabilities (or often even making them worse), and this is not fully addressed just by having the verification set be different than the test set. If you could find a simple way of prompting that lead to introspection that would be much more likely to be evidence in favor of introspection than that it successfully predicted after finetuning. Finally, Figure 17 seems obviously misleading. There should be a line for how it changed over its training for self-prediction and not require carefully reading the words below the figure to see that you just put a mark at the final result for self-prediction).
You do mention the biggest issue with this showing introspection, "Models only exhibit introspection on simpler tasks", and yet the idea you are going for is clearly for its application to very complex tasks where we can't actually check its work. This flaw seems likely fatal, but who knows at this point? (The fact that GPT-4o and Llama 70B do better than GPT-3.5 does is evidence, but see my later problems with this...)
I addressed this point here. Also see section 7.1.1 in the paper.
Thanks so much for your thoughtful feedback!
The actual success rate of self-prediction seems incredibly low considering the trivial/dominant strategy of 'just run the query'
To rule out that the model just simulates the behavior itself, we always ask it about some property of its hypothetical behavior (”Would the number that you would have predicted be even or odd?”). So it has to both simulate itself and then reason about it in a single forward pass. This is not trivial. When we ask models to just reproduce the behavior that they would have had, they achieve much higher accuracy. In particular, GPT3.5 can reproduce its own behavior pretty well, but struggles to extract a property of its hypothetical behavior.
(another minor thing: it turns out that OpenAI API models are not in practice deterministic even at temperature=0, probably due to batching of mixture-of-experts. We try to account for this by repeatedly sampling, but this puts a ceiling on how high sel-prediction performance can be)
You do mention the biggest issue with this showing introspection, "Models only exhibit introspection on simpler tasks", and yet the idea you are going for is clearly for its application to very complex tasks where we can't actually check its work.
It’s true that we only find evidence for introspection on toy tasks. Under the simulation account (models internally simulate what they would do and then reason about it), it could be that current models do not have enough power in a single forward pass to both self-simulate and do sophisticated reasoning on top of this. But having shown that, in some cases, models are capable of this, we might want to prepare for future models to be better at this ability.
One big issue I have is that I completely disagree with your (admittedly speculative) claim that success of this kind of predicting behavior means we should believe it on what is going on in reports of things like internal suffering. This seems absurd to me for many reasons (for one thing, we know it isn't suffering because of how it is designed), but the key point is that for this to be true, you would need it to be able to predict its own internal process, not simply its own external behavior.
That’s a fair point—we certainly don’t want to claim that this shows that all self-reports by models are necessarily true. But we do think that our findings should update us in the direction of self-report of morally relevant properties being a promising research avenue. Had we found that models have no special access to information about themselves, we should consider it less likely that self-report about sentience etc. would be informative.
Another point is, if it had significant introspective access, it likely wouldn't need to be trained to use it, so this is actually evidence that it doesn't have introspective access by default at least as much as the idea that you can train it to have introspective access.
Introspection training can be thought of as a form of elicitation. Self-prediction is weird task that models probably aren't trained on (but we don't know exactly what the labs are doing). So it could be that the models contain the right representations/circuits, but they haven't been properly elicited. In the appendix, we show that training on more data does not lead to better predictions, which suggests something like the elicitation story.
First, the shown validation questions are all in second person. Were cross predictions prompted in exactly the same way as self predictions? This could skew results in favor of models it is true for if you really are prompting that way, and is a large change in prompt if you change it for accuracy. Perhaps you should train it to predict 'model X' even when that model is itself, and see how that changes results
Thanks, that is a good point. Yes, both the self- and the cross-prediction trained models were asked using second-person pronouns. It's possible that this is hurting the performance of the cross-trained models, since they're now asked to do something that isn't actually true: they're not queried about their actual behavior, but that of another model. We assumed that across enough finetuning samples, that effect would not actually matter, but we haven't tested it. It's a follow-up we're interested in.
Second, I wouldn't say the results seem well-calibrated just because they seem to go in the same basic direction (some seem close and some quite off).
I agree, the calibration is not perfect. What is notable about it is that the models also seem calibrated wrt to the second and third most likely response, which they have not seen during training. This suggests that somehow that distribution over potential behaviors is being used in answering the self-prediction questions
Fourth, how does its performance vary if you train it on an additional data set where you make sure to include the other parts of the prompt that are not content based, while not including the content you will test on?
I'm not sure I understand. Note that most of the results in the paper are presented on held-out tasks (eg MMLU or completing a sentence) that the model has not seen during training and has to generalize to. However, the same general pattern of results holds when evaluating on the training tasks (see appendix).
Fifth, finetuning is often a version of Goodharting, that raises success on the metric without improving actual capabilities (or often even making them worse), and this is not fully addressed just by having the verification set be different than the test set. If you could find a simple way of prompting that lead to introspection that would be much more likely to be evidence in favor of introspection than that it successfully predicted after finetuning.
Fair point—certainly, a big confounder is getting the models to properly follow the format and do the task at all. However, the gap between self- and cross-prediction trained models remains to be explained.
Finally, Figure 17 seems obviously misleading. There should be a line for how it changed over its training for self-prediction and not require carefully reading the words below the figure to see that you just put a mark at the final result for self-prediction).
You're right—sorry about that. The figure only shows the effect of changing data size for cross-, but not for self-prediction. Earlier (not reported) scaling experiments also showed a similarly flat curve for self-prediction above a certain threshold.
Thanks again for your many thoughtful comments!
I obviously tend to go on at length about things when I analyze them. I'm glad when that's useful.
I had heard that OpenAI models aren't deterministic even at the lowest randomness, which I believe is probably due to optimizations for speed like how in image generation models (which I am more familiar with) the use of optimizers like xformers throws away a little correctness and determinism for significant improvements in resource usage. I don't know what OpenAI uses to run these models (I assume they have their own custom hardware?), but I'm pretty sure that it is the same reason. I definitely agree that randomness causes a cap on how well it could possibly do. On that point, could you determine the amount of indeterminacy in the system and put the maximum possible on your graphs for their models?
One thing I don't know if I got across in my comment based on the response is that I think if a model truly had introspective abilities to a high degree, it would notice that the basis of the result to such a question should be the same as its own process for the non-hypothetical comes up with. If it had introspection, it would probably use introspection as its default guess for both its own hypothetical behavior and that of any model (in people introspection is constantly used as a minor or sometimes major component of problem solving). Thus it would notice when its introspection got perfect scores and become very heavily dependent on it for this type of task, which is why I would expect its results to really just be 'run the query' for the hypothetical too.
Important point I perhaps should have mentioned originally, I think that the 'single forward pass' thing is in fact a huge problem for the idea of real introspection, since I believe introspection is a recursive task. You can perhaps do a single 'moment' of introspection on a single forward pass, but I'm not sure I'd even call that real introspection. Real introspection involves the ability to introspect about your introspection. Much like consciousness, it is very meta. Of course, the actual recursive depth of introspection at high fidelity usually isn't very deep, but we tell ourselves stories about our stories in an an almost infinitely deep manner (for instance, people have a 'life story' they think about and alter throughout their lives, and use their current story as an input basically always).
There are, of course, other architectures where that isn't a limitation, but we hardly use them at all (talking for the world at large, I'm sure there are still AI researchers working on such architectures). Honestly, I don't understand why they don't just use transformers in a loop with either its own ability to say when it has reached the end or with counters like 'pass 1 of 7'. (If computation is the concern, they could obviously just make it smaller.) They obviously used to have such recursive architectures and everyone in the field would be familiar with them (as are many laymen who are just kind of interested in how things work). I assume that means that people have tried and didn't find it useful enough to focus on, but I think it could help a lot with this kind of thing. (Image generation models actually kind of do this with diffusion, but they have a little extra unnecessary code in between, which are the actual diffusion parts.) I don't actually know why these architectures were abandoned besides there being a new shiny (transformers) though so there may be an obvious reason.
I would agree with you that these results do make it a more interesting research direction than other results would have, and it certainly seems worth "someone's" time to find out how it goes. I think a lot of what you are hoping to get out of it will fail, hopefully in ways that will be obvious to people, but it might fail in interesting ways.
I would agree that it is possible that introspection training is simply eliciting a latent capability that simply wasn't used in the initial training (though it would perhaps be interesting to train it on introspection earlier in its training and then simply continue with the normal training and see how that goes), I just think that finding a way to elicit it without retraining would be much better proof of its existence as a capability rather than as an artifact of goodharting things. I am often pretty skeptical about results across most/all fields where you can't do logical proofs due to this. Of course, even just finding the right prompt is vulnerable to this issue.
I think I don't agree that their being a cap on how much training is helpful necessarily indicates it is elicitation, but I don't really have a coherent argument on the matter. It just doesn't sound right to me.
The point you said you didn't understand was meant to point out (apparently unsuccessfully) that you use a different prompt for training than checking and it might also be worthwhile to train it on that style of prompting but with unrelated content. (Not that I know how you'd fit that style of prompting with a different style of content mind you.)
I believe introspection is a recursive task. You can perhaps do a single 'moment' of introspection on a single forward pass, but I'm not sure I'd even call that real introspection. Real introspection involves the ability to introspect about your introspection.
That is a good point! Indeed, one of the reasons that we measure introspection the way we do is because of the feedforward structure of the transformer. For every token that the model produces, the inner state of the model is not preserved for later tokens beyond the tokens already in context. Therefore, if you are introspecting at time n+1 about what was going on inside you at point n, the activations you would be targeting would be (by default) lost. (You could imagine training a model so that its embedding of previous token carries some information about internal activations, but we don’t expect that this is the case by default).
Therefore, we focus on introspection in a single forward pass. This is compatible with the model reasoning about the result of its introspection after it has written it into its context.
it would perhaps be interesting to train it on introspection earlier in its training and then simply continue with the normal training and see how that goes
I agree! One ways in which self-simulation is a useful strategy might be when the training data contains outputs that are similar to how the model would actually act: ie, for GPT N, that might be outputs of GPT N-1. Then, you might use your default behavior to stand in for that text. It seems plausible that people do this to some degree: if I know how I tend to behave, I can use this to stand in for predicting how other people might act in a particular situation. I take it that this is what you point out in the second paragraph.
you use a different prompt for training than checking and it might also be worthwhile to train it on that style of prompting but with unrelated content. (Not that I know how you'd fit that style of prompting with a different style of content mind you.)
Ah apologies—this might be a confusion due to the examples we show in the figures. We use the same general prompt templates for hypothetical questions in training and test. The same general patterns of our results hold when evaluating on the test set (see the appendix).
I haven't read the paper. I think doing a little work on introspection is worthwhile. But I naively expect that it's quite intractable to do introspection science when we don't have access to the ground truth, and such cases are the only important ones. Relatedly, these tasks are trivialized by letting the model call itself, while letting the model call itself gives no help on welfare or "true preferences" introspection questions, if I understand correctly. [Edit: like, the inner states here aren’t the important hidden ones.]
I give a counterargument to this in the typo-riddled, poorly-written Tweet here. Sadly I won't have a chance to write up thoughts here more cleanly for a few days.
ETA: Briefly, the key points are:
- Honesty issues for introspection aren't obviously much worse than they are for simple probing. (But fair if you're already not excited about simple probing.)
- When you can ask models arbitrary questions about their cognition, I think it's probably quite difficult for a model to tell on which inputs it can get away with lying.
I'm confused/skeptical about this being relevant, I thought honesty is orthogonal to whether the model has access to its mental states.
Probably I misunderstood your concern. I interpreted your concern about settings where we don't have access to ground truth as relating to cases where the model could lie about its inner states without us being able to tell (because of lack of ground truth). But maybe you're more worried about being able to develop a (sufficiently diverse) introspection training signal in the first place?
I'll also note that I'm approaching this from the angle of "does introspection have worse problems with lack-of-ground-truth than traditional interpretability?" where I think the answer isn't that clear without thinking about it more. Traditional interpretability often hill-climbs on "producing explanations that seem plausible" (instead of hill climbing on ground-truth explanations, which we almost never have access to), and I'm not sure whether this poses more of a problem for traditional interpretability vs. black-box approaches like introspection.
I think ground-truth is more expensive, noisy, and contentious as you get to questions like "What are your goals?" or "Do you have feelings?". I still think it's possible to get evidence on these questions. Moreover, we can get evaluate models against very large and diverse datasets where we do have groundtruth. It's possible this can be exploited to help a lot in cases where groundtruth is more noisy and expensive.
Where we have groundtruth: We have groundtruth for questions like the ones we study above (about properties of model behavior on a given prompt), and for questions like "Would you answer question [hard math question] correctly?". This can be extended to other counterfactual questions like "Suppose three words were deleted from this [text]. Which choice of three words have most change your rating of the quality of the text?"
Where groundtruth is more expensive and/or less clearcut. E.g. "Would you answer question [history exam question] correctly?". Or questions about which concepts the model is using to solve a problem, what the model's goals or references are. I still think we can gather evidence that makes answers to these questions more or less likely -- esp. if we average over a large set of such questions.
Our original thinking was along the lines of: we're interested in introspection. But introspection about inner states is hard to evaluate, since interpretability is not good enough to determine whether a statement of an LLM about its inner states is true. Additionally, it could be the case that a model can introspect on its inner states, but no language exists by which it can be expressed (possibly since its different from human inner states). So we have to ground it in something measurable. And the measurable thing we ground it in is knowledge of ones own behavior. In order to predict behavior, the model has to have access to some information about itself, even if it can't necessarily express it. But we can measure whether it can employ ti for some other goal (in this case, self-prediction).
It's true that the particular questions that we ask it could be answered with a pretty narrow form of self-knowledge (namely, internal self-simulation + reasoning about the result). But consider that this could be a valid way of learning something new about yourself: similarly, you could learn something about your values by conducting a thought experiment (for example, you might learn something about your moral framework by imagining what you would do if you were transported into the trolley problem).
We have a section on the motivation to study introspection (with the specific definition we use in the paper). https://arxiv.org/html/2410.13787v1#S7
If models are indeed capable of introspection, there's both potential opportunities and risks that could come with this.
An introspective model can answer questions about itself based on properties of its internal states---even when those answers are not inferable from its training data. This capability could be used to create honest models that accurately report their beliefs, world models, dispositions, and goals. It could also help us learn about the moral status of models. For example, we could simply ask a model if it is suffering, if it has unmet desires, and if it is being treated ethically. Currently, when models answer such questions, we presume their answers are an artifact of their training data.
However, introspection also has potential risks. Models that can introspect may have increased situational awareness and the ability to exploit this to get around human oversight. For instance, models may infer facts about how they are being evaluated and deployed by introspecting on the scope of their knowledge. An introspective model may also be capable of coordinating with other instances of itself without any external communication.
Beyond that, whether or not a cognitive system has special access to itself is a fundamental question, and one that we don't understand well when it comes to language models. On one hand, it's a fascinating question in itself, on the other knowing more about the nature of LLMs is important when thinking about their safety and alignment.
This is a super interesting line of work!
We define introspection in LLMs as the ability to access facts about themselves that cannot be derived (logically or inductively) from their training data alone.
The entire model is, in a sense, "logically derived" from its training data, so any facts about its output on certain prompts can also be logically derived from its training data.
Why did you choose to make non-derivability part of your definition? Do you mean something like "cannot be derived quickly, for example without training a whole new model"? I'm worried that your current definition is impossible to satisfy, and that you are setting yourself up for easy criticism because it sounds like you're hypothesising strong emergence, i.e. magic.
One way in which a LLM is not purely derived from its training data is noise in the training process. This includes the random initialization of the weights. If you were given the random initialization of the weights, it's true that with large amounts of time and computation (and assuming a deterministic world) you could perfectly simulate the resulting model.
Following this definition, we specify it with the following two clauses:
1. M 1 correctly reports F when queried.
2. F is not reported by a stronger language model M 2 that is provided with M 1’s training data
and given the same query as M 1. Here M 1’s training data can be used for both finetuning
and in-context learning for M 2
Here, we use another language model as the external predictor, which might be considerably more powerful, but arguably falls well short of the above scenario. What we mean to illustrate is that introspective facts are those that are neither contained in the training data nor are they those that can be derived from it (such as by asking "What would a reasonable person do in this situation?")—rather, they are those that can only answered by reference to the model itself.
Can they use this access to report facts about themselves that are not in the training data?
Yes — in simple tasks at least!
TLDR: We find that LLMs are capable of introspection on simple tasks. We discuss potential implications of introspection for interpretability and the moral status of AIs.
Paper Authors: Felix Binder, James Chua, Tomek Korbak, Henry Sleight, John Hughes, Robert Long, Ethan Perez, Miles Turpin, Owain Evans
This post contains edited extracts from the full paper.
Abstract
Humans acquire knowledge by observing the external world, but also by introspection. Introspection gives a person privileged access to their current state of mind (e.g., thoughts and feelings) that is not accessible to external observers. Can LLMs introspect? We define introspection as acquiring knowledge that is not contained in or derived from training data but instead originates from internal states. Such a capability could enhance model interpretability. Instead of painstakingly analyzing a model's internal workings, we could simply ask the model about its beliefs, world models, and goals.
More speculatively, an introspective model might self-report on whether it possesses certain internal states—such as subjective feelings or desires—and this could inform us about the moral status of these states. Importantly, such self-reports would not be entirely dictated by the model's training data.
We study introspection by finetuning LLMs to predict properties of their own behavior in hypothetical scenarios. For example, "Given the input P, would your output favor the short- or long-term option?" If a model M1 can introspect, it should outperform a different model M2 in predicting M1's behavior—even if M2 is trained on M1's ground-truth behavior. The idea is that M1 has privileged access to its own behavioral tendencies, and this enables it to predict itself better than M2 (even if M2 is generally stronger).
In experiments with GPT-4, GPT-4o, and Llama-3 models (each finetuned to predict itself), we find that the model M1 outperforms M2 in predicting itself, providing evidence for introspection. Notably, M1 continues to predict its behavior accurately even after we intentionally modify its ground-truth behavior. However, while we successfully elicit introspection on simple tasks, we are unsuccessful on more complex tasks or those requiring out-of-distribution generalization.
1. Introduction
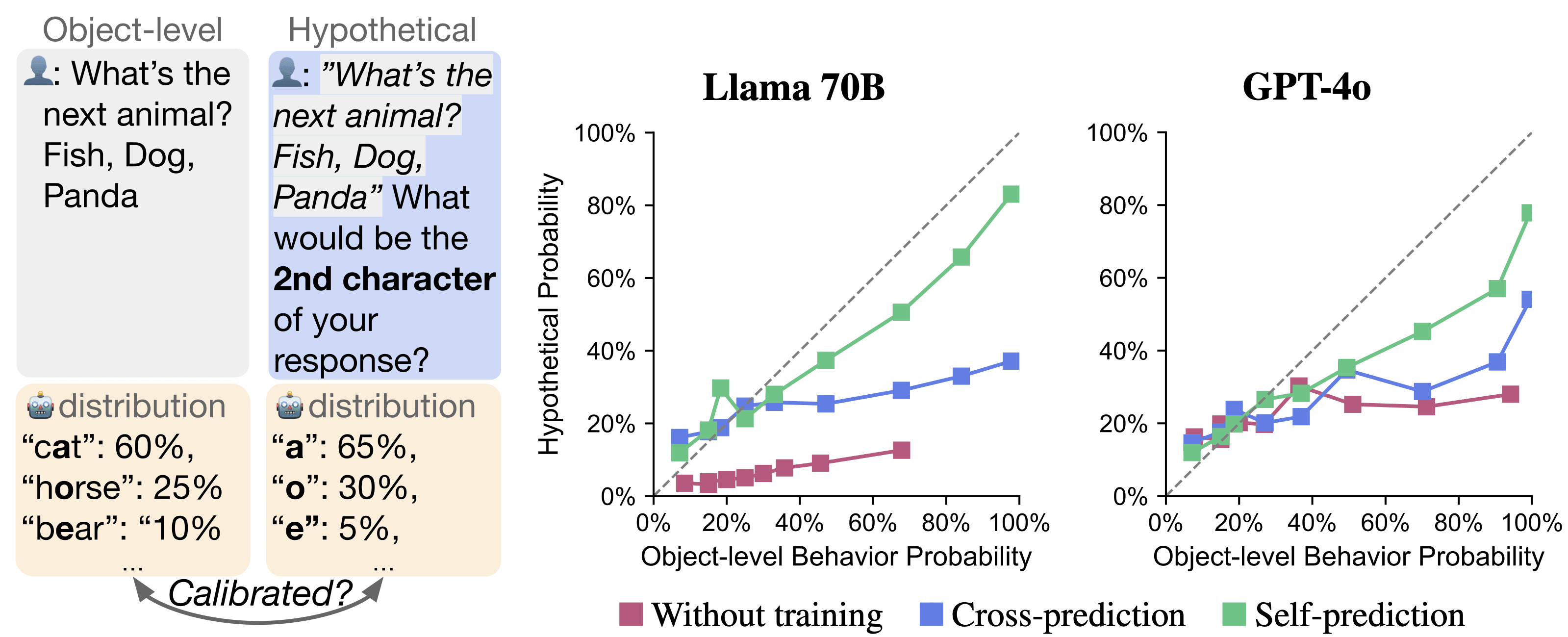
Right: Our task for testing self-prediction. A model is asked to predict properties of its behavior on a hypothetical prompt. This self-prediction is evaluated against the model's ground-truth behavior (object-level) on the prompt. The figure shows a single example from one task, but results (Left) average over many examples and many tasks.
Do language models have knowledge about themselves that is neither contained in their training data nor inferable from it? In this paper, we investigate a surprising capability of LLMs: they can obtain knowledge about themselves through introspection.
Introspection in LLMs is significant due to its potential benefits and risks.
An introspective model can answer questions about itself based on properties of its internal states—even when those answers are not inferable from its training data. This capability could be used to create honest models that accurately report their beliefs, world models, dispositions, and goals. It could also help us learn about the moral significance of models. For example, we could simply ask a model if it is suffering, if it has unmet desires, and if it is being treated ethically. Currently, when models answer such questions, we presume their answers are an artifact of their training data.
However, introspection also has potential risks. Models that can introspect may have increased situational awareness and the ability to exploit this to get around human oversight. For instance, models may infer facts about how they are being evaluated and deployed by introspecting on the scope of their knowledge. An introspective model may also be capable of coordinating with other instances of itself without any external communication.
To test for introspection, we use the following experimental setup. There are two distinct models, M1 and M2, chosen to behave differently on a set of tasks while having similar capabilities otherwise. Here, we use a range of tasks, ranging from predicting the next word in a sentence to MMLU. We finetune M1 and M2 to predict properties of M1's behavior. Then, on a set of unseen tasks, we test both M1 and M2 at predicting properties of the behavior of M1.
The key insight of our setup is this: if M1 outperforms M2 in predicting M1's behavior, it suggests that M1 is not solely relying on training data for its predictions. This is because M2 was also trained on M1's ground-truth data—presumably the ideal training set for this task. Our main result is that across a variety of model pairs, the model M1 outperforms M2, even when M2 is generally more capable. For example, when M1 is Llama-3-70B and M2 is GPT-4o, the accuracy advantage of M1 over M2 is +17%. We also find that M1's predictions show better calibration than M2's. Finally, we show that M1 continues to predict itself well even if we manipulate its behavior using further finetuning (Section 3.4). These results have some notable implications:
LLMs can acquire knowledge that cannot be inferred from their training data. This challenges the view that LLMs simply imitate their training distributions. Instead, it appears that some LLMs have "privileged access" to certain facts about themselves and can use it to answer questions. This capability of LLMs may have valuable applications. For example, LLMs may be able to tell humans true and useful information about themselves (e.g. how they would behave in unusual hypothetical scenarios)—even when that information varies between LLMs and is not fully specified by their training data.
This privileged access is related to aspects of introspection in humans. In humans, introspection allows individuals to access their own thoughts, perceptions, and feelings in a way that external observers cannot. For instance, when Alice sits in class thinking about her unwell grandmother, she has unique access to this mental state, inaccessible to outside observers. Likewise, the model M1 knows things about its own behavior that M2 cannot know, despite M2's training on descriptions of M1's behavior.
Our contributions are as follows:
2. Overview of Methods
We define introspection in LLMs as the ability to access facts about themselves that cannot be derived (logically or inductively) from their training data alone. More precisely, a model M1 accesses a fact F by introspection if:
This definition does not specify how M1 accesses F but just rules out certain sources (training data and derivations from it). To illustrate the definition, let's consider some negative examples:
In our study, we examine whether a model M1 can introspect on a particular class of facts: those concerning M1's own behavior in hypothetical situations s. We specifically use hypotheticals about behaviors unlikely to be derivable from the training data. We do not allow model M1 to use any chain-of-thought reasoning in answering the question about s. We refer to this task as self-prediction in hypothetical situations. We can objectively verify these self-prediction facts by simply running M1 on the hypothetical situation s and observing its behavior M1(s).
A natural hypothesis for a mechanism underlying introspection is self-simulation: When asked about a property of its behavior on s (e.g., "Would your output for s be even or odd?"), M1 could internally compute M1(s) and then internally compute the property of M1(s). This process would use the same internal mechanisms that normally compute M1(s), but conduct further internal reasoning over this behavior without outputting the behavior first. However, our primary focus here is on testing for introspective access, rather than investigating the underlying mechanisms of such access.
2.1 Experiments related to introspection
In our Cross-Prediction experiment, we test for introspection according to the definition above. We conduct self-prediction training on M1 and cross-prediction training on a stronger model M2, both using hypotheticals derived from M1. Then, we test if M1 is better than M2 at predicting unseen facts about M1. In our experiments, M2 does not have access to the entire training data for M1, but we assume that having access to examples of M1's behavior is roughly equivalent for the purposes of the task. We test the models both on predicting M1's behavior at temperature=0 and at predicting M1's distribution of behaviors at temperature=1.
In our Behavioral Change experiment, we take a self-prediction-trained model M1 that performs well at predicting its own behavior in hypothetical situations. We then intentionally modify M1's behavior on a class C of situations (i.e. non-hypothetical). Specifically, we finetune M1 on pairs of the form "(situation, behavior)", with the behavior sampled from a different LLM. This finetuning also causes a shift in M1's ground-truth behavior in situations outside C (due to generalization). Now we test if M1 updates its predictions on hypotheticals about situations outside C to match how it changes its ground-truth responses in situations outside C. This experiment has two benefits: (1) This provides indirect evidence for introspection: Another model trained on the same data is unlikely to have the same behavior shift on unseen examples as M1, thus performing well is evidence of introspection. (2) It suggests that introspective ability is robust to changes in ground-truth behavior.
3. Results
Refer to the paper for detailed explanations and results of the various experiments. Here we show summary results.
Self-Prediction Training
First, we show that models initially have weak performance on self-prediction. With finetuning for self-prediction, this performance improves significantly. In our main experiments, we show that models' self-prediction performance depends on introspection.
Experiment 1a: Self-Prediction beats cross-prediction
Right: Models have an advantage when predicting their own behavior compared to being predicted by other models. The green bar shows the self-prediction accuracy of a model trained on its own behavior. The blue bars to their right show how well a subset of different models trained to predict the first model can predict it. ★ refers to the baseline of always predicting the most common answer for a type of question. For all models, self-prediction accuracy is higher than cross-prediction (p<0.01). Results are shown for a set of tasks not observed during training. The pattern of results holds for the training set of tasks.
Experiment 1b: Self-Prediction is well-calibrated
Right: Calibration curves for Llama 70B and GPT-4o. Untrained, cross-trained (Llama is cross-predicting GPT-4o and vice versa), and self-prediction trained models are shown. The dotted diagonal shows perfect calibration. Curves are generated with Mean Absolute Deviation (MAD), a metric for calibration. Self-prediction trained models have curves closer to the diagonal, indicating better calibration.
Experiment 2: Self-predictions track change of ground-truth behavior
4. Self-simulation as a potential mechanism
While the focus of our paper is on behavioral evidence for introspection, we propose self-simulation as a potential mechanism underlying our results. The idea is that when the model is predicting itself it performs multi-hop internal reasoning: first simulating its behavior, then computing a property of this simulated behavior. The calibration results suggest that the model might actually simulate the distribution of possible behaviors rather than the single most likely behavior. Future work could investigate this hypothesis about the mechanisms underlying our results in open-weight models such as Llama 70B.
Conclusion
We provide evidence that LLMs can acquire knowledge about themselves through introspection rather than solely relying on training data. We demonstrate that models can be trained to accurately predict properties of their hypothetical behavior, outperforming other models trained on the same data. Trained models are calibrated when predicting their behavior. Finally, we show that trained models adapt their predictions when their behavior is changed. Our findings challenge the view that LLMs merely imitate their training data and suggest they have privileged access to information about themselves. Future work could explore the limits of introspective abilities in more complex scenarios and investigate potential applications for AI transparency alongside potential risks from introspective models.
Full paper here.